基于MDSCLDNN-HAN的調制識別算法
2022-09-09 01:58:36李天宇李昀喆郝彥超
無線電工程 2022年9期
李天宇,侯 進,李昀喆,郝彥超
(1.西南交通大學 信息科學與技術學院 智能感知智慧運維實驗室,四川 成都 611756;2.西南交通大學 唐山研究院,河北 唐山 063000;3.西南交通大學 綜合交通大數據應用技術國家工程實驗室,四川 成都 611756)
0 引言
無線信號調制識別在各種領域都有著重要的應用。在信號調制自動識別的研究中,主要有3個技術方向:一是基于決策理論的調制模式識別;二是基于統計機器學習理論的調制模式識別;三是基于深度學習的調制模式識別[1-3]。
隨著深度學習在各個領域中展現的突出性能,O’Shea等[4-8]首次將卷積神經網絡(Convolutional Neural Network,CNN)應用于調制識別領域,并提出了公開調制信號數據集RadioML2016.10a。
文獻[9]設計了基于CNN的長短期記憶(Long Short-Term Memory,LSTM)全連接深度神經網絡(Convolutional Long Short-Term Memory Fully Connected Deep Neural Networks,CLDNN)模型,文獻[10]設計了一種時空多通道網絡(Multi-Channel Convolutional Long Short-Term Memory Fully Connected Deep Neural Networks,MCLDNN)模型,文獻[11]提出了Dual-CNN-LSTM模型,使用信號的同相正交(In-phase Quadrature,IQ)數據和幅度相位(Amplitude Phase,AP)作為輸入。文獻[12-14]將信號數據進行預處理轉化為星座圖、時頻圖等圖像數據,使用圖像分類的深度學習算法對調制信號進行分類。以上研究,在調制信號識別精度上表現出較好的性能,但都存在模型參數量和復雜度過大的問題,難以在實際通信環境中應用。
針對以上問題,設計了一種改進的MCLDNN模型——MDSCLDNN-HAN(Multi-Channel Depthwise Separable Convolution Long Short-Term Memory Dense Neural Network with Hierarchical Attention Networks),該模型中使用深度可分離卷積(Depthwise Separable Convolution,DSC)代替標準卷積,同時引入了分層注意力機制(Hierarchical Attention Networks,HAN),識別精度略優于現有模型,同時參數量和計算量大量減少。
1 算法建模
1.1 數據處理
本文算法模型考慮單輸入單輸出通信系統,使用信號的原始IQ數據和AP數據作為輸入。接收信號r(t)可表示為:
(1)
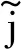
接收信號r(t)由同相分量rI和正交分量rQ組成,離散信號r[n]可以表示為:
(2)
信號的AP數據計算如下:
(3)
(4)
式中,XA[n]為信號的幅度;XP[n]為信號的相位。
1.2 MDSCLDNN-HAN模型框架
MDSCLDNN-HAN模型框架如圖1所示,分為多通道特征提取融合模塊、LSTM-HAN模塊和全連接層3個模塊,利用模塊間的互補性和協同性,對時域和頻域特征進行提取融合,最后將調制信號進行分類。
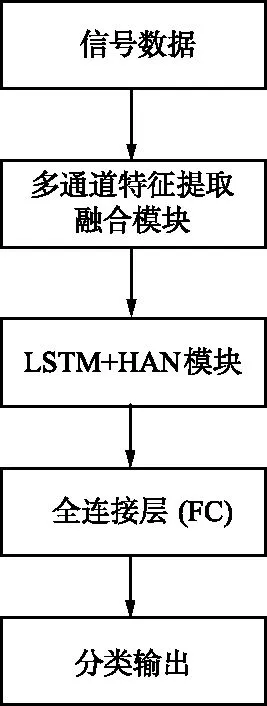
圖1 MDSCLDNN-HAN模型框架Fig.1 Framework of MDSCLDNN-HAN model
1.3 多通道特征提取融合模塊
多通道特征提取融合模塊網絡結構如圖2所示,由3個一維卷積層和2個二維卷積層組成。首先,將信號IQ數據分為獨立的I通道、Q通道和I/Q通道分別輸入Conv1,Conv2和Conv3,學習信號數據的單通道和多通道特征。然后在連接層1中對單通道特征進行融合,在連接層2中對單通道和多通道特征進行融合提取并輸入Conv5。信號的AP數據采用與IQ數據同樣的卷積模塊進行特征提取,在連接層5處將IQ和AP數據的特征輸出進行融合,再通過Conv11進行特征提取后送入下一模塊。模塊有效利用了信號的IQ數據和AP數據,同時設計使用分離通道,有效提取不同尺度下輸入的特征。
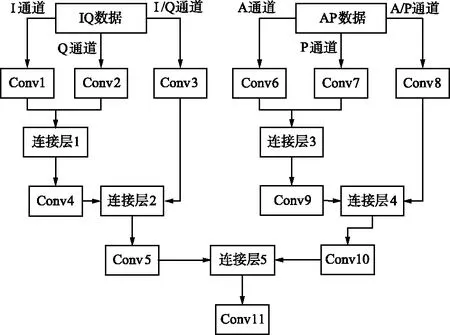
圖2 多通道特征提取融合模塊結構Fig.2 Structure diagram of multi-channel feature extraction and fusion module
為加快網絡的訓練和收斂的速度,控制梯度爆炸,防止梯度消失、過擬合,每層DSC后加入了批歸一化層(Batch Normalization,BN),使用線性整流函數(Rectified Linear Unit,ReLU)作為激活函數。該模塊卷積層參數如表1所示。
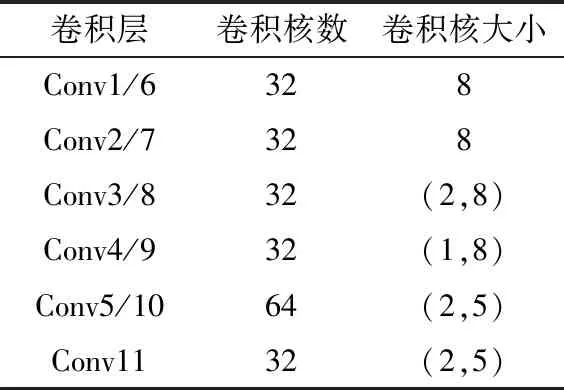
表1 多通道特征提取融合模塊參數
DSC具有參數量少和計算量小的優點,本模塊使用DSC層代替標準卷積層。
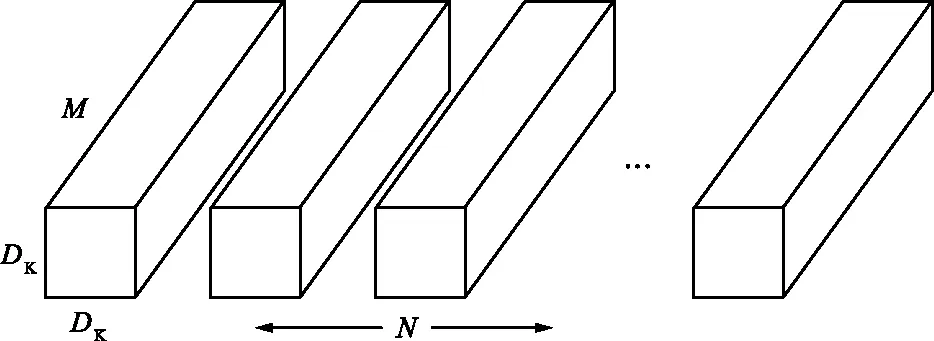
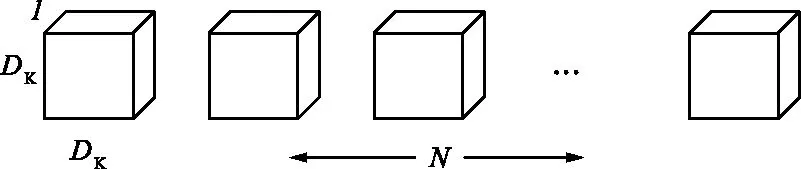
文獻[15]提出使用DSC層替代標準卷積層。在標準卷積層中,卷積濾波器同時學習空間和通道相關性。DSC將上述過程分解為2層。在第1層中,使用標準的深度(通道)卷積以學習空間相關性;在第2層逐點卷積(1×1卷積),通過組合第1層的輸出來學習通道相關性。標準卷積層和DSC層濾波器如圖3所示。
(a) 標準卷積濾波器
(b) 深度可分離卷積濾波器
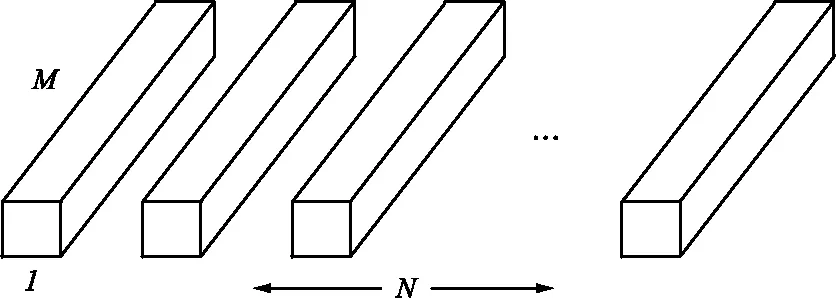
(c) 逐點卷積圖3 標準卷積層和DSC層濾波器Fig.3 Schematic diagram of standard convolution and depthwise separable convolution filters
標準卷積層和DSC層參數量為:
P=(DK×DK×M)×N,
(5)
P=(DK×DK×M)+M×N,
(6)
式中,P為參數量;DK為輸出特征圖的大小;M為輸入通道的大小;N為輸出通道的大小。
標準卷積與DSC的參數量之比為:
(7)
可以看出,DSC層的參數量較標準卷積減少許多。
1.4 LSTM-HAN模塊
LSTM是一種特殊的循環神經網絡(Recurrent Neural Network,RNN),擅長處理具有時間序列關系的數據,可以有效提取數據中的時序特征。LSTM的計算如下:
it=σ(Wxtxt+Whiht-1+bi),
(8)
ft=σ(Wxfxt+Whfht-1+bf),
(9)
ot=σ(Wxoxt+Whiht-1+bo),
(10)
(11)
(12)
ht=ot·tanh(ct),
(13)
式中,it,ot,ft分別為輸入門、輸出門和遺忘門當前狀態;W為權重;b為偏差;σ為Sigmoid函數。
近年來,注意力機制廣泛應用于自然語言處理、圖像識別和文本處理等領域[16]。文獻[17]提出了一種用于文檔分類的HAN網絡結構。HAN通過在詞層級和句子層級中使用注意力機制,找到對句子特征貢獻最大的詞語和對整篇文本特征貢獻最大的句子,提取整篇文本中的高頻特征。通過加大高頻特征的權重和抑制低頻特征的權重來提高神經網絡的特征提取能力。
本文所提模型中使用一層單元數為128的LSTM層,為進一步提取信號的高頻特征,在LSTM層后加入HAN網絡結構,從而提升網絡性能。
1.5 輸出層
本文模型中,信號數據經過多通道特征提取融合模塊和LSTM-HAN模塊的特征輸出,輸入到一層單元數為64,使用ReLU激活函數的全連接層進行降維得到特征節點,再將特征節點輸入到使用Softmax激活函數的全連接層進行分類,得到調制信號最終的分類結果。
2 實驗結果及性能分析
2.1 實驗數據
實驗使用開源數據集RadioML2016.10a和RadioML2016.10b。RadioML2016.10a中共有220 000個調制信號,包含了WBFM,AM-DSB,AM-SSB,BPSK,CPFSK,GFSK,4-PAM,16-QAM,64-QAM,QPSK和8PSK等11種常見調制信號。RadioML2016.10b是RadioML2016.10a的更清晰、規范的拓展版本,每種信號數量是RadioML2016.10a的6倍,共有1 200 000個調制信號,不包含AM-SSB信號。二者中信號數據的信噪比取值在-20~18 dB,信號數據為IQ數據,數據格式為128×2的浮點數字。為模擬現實環境,信號數據在考慮了AWGN、多徑衰落、采樣率偏移和中心頻率偏移等惡劣的傳播條件下,使用GNU Radio模擬生成。2個數據集都是按照6∶2∶2的比例劃分成訓練集、測試集和驗證集進行實驗和測試。
2.2 實驗環境
實驗使用了Python3.8編程語言和TensorFlow 2.5內置的Keras框架搭建神經網絡模型,使用NVIDA RTX 3080Ti GPU進行訓練和測試。軟硬件詳細信息如表2所示。
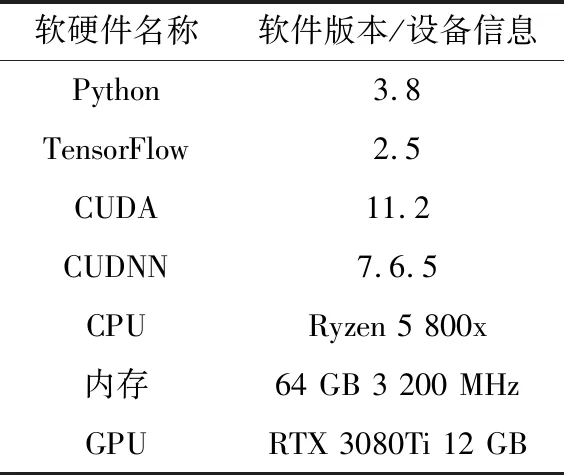
表2 實驗軟硬件詳細信息
2.3 消融實驗
為驗證MDSCLDNN-HAN模型中各模塊對網絡模型的影響,在RadioML2016.10a數據集上,使用8種模型進行消融實驗。模型1~6使用IQ數據作為輸入,模型7使用AP數據作為輸入,模型8使用IQ數據和AP數據作為輸入。8種網絡模型識別準確率、參數量和計算量如表3所示,其中計算量使用指浮點運算數(Floating Point Operations,FLOPs)衡量,單位為百萬(M)。圖4展示了不同信噪比下各網絡模型識別準確率。
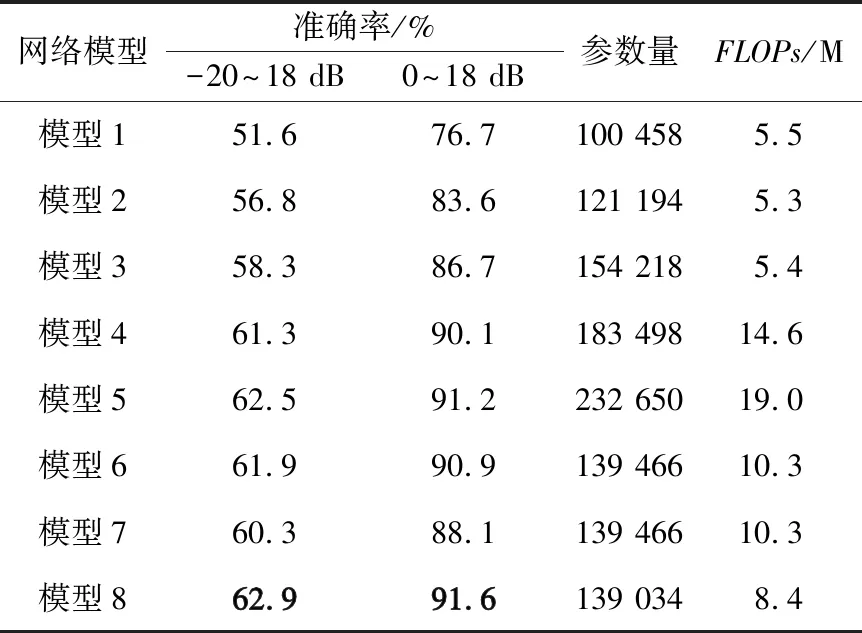
表3 基于RadioML2016.10a數據集的消融實驗
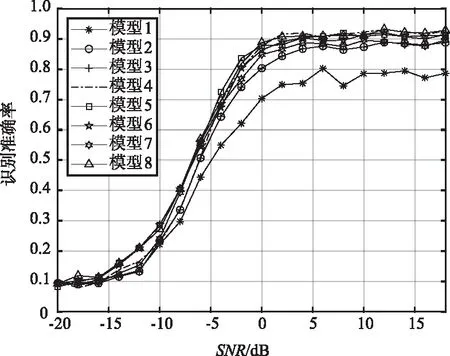
圖4 基于RadioML2016.10a的消融實驗識別準確率Fig.4 Ablation experiment recognition accuracy curve based on RadioML2016.10a dataset
模型1使用由2層卷積層構成的CNN做基礎網絡架構。模型2在模型1后加入LSTM層,學習信號的時域特征,識別準確率較模型1提升5.2%。模型3在LSTM模塊后加入全連接層,可以將特征空間映射到更容易分類的輸出層,識別準確率較模型2提高1.5%。模型4在模型3的基礎上增加信號的分離通道I通道和Q通道,通過學習I通道、Q通道和IQ通道的互補信息,識別準確率較模型3提高3%。模型5加入了HAN網絡結構,進一步學習IQ信號數據的高頻特征,識別準確率達到62.5%。由于使用了DSC,模型6識別準確率較模型5下降0.6%,這是因為使用DSC提取特征時,會較標準卷積層缺失部分特征,但同時模型6的參數量和計算量較模型5分別下降49%和87%。模型7網絡結構與模型6一致,只是輸入數據改用AP數據,會缺失部分信號特征,故模型7識別率下降2.6%,AP數據較IQ數據會缺失部分信號特征。
模型8使用IQ和AP數據和它們的分離通道共六通道作為輸入,IQ,AP數據提取的特征節點通過連接融合后,通過一層卷積核數較小的DSC層進行降維,模型8的參數量和FLOPs分別是模型5的59%和44%,識別準確率達到62.9%,略優于模型5。
2.4 對比實驗
為進一步驗證本文模型的性能,使用Radio-ML2016.10a和RadioML2016.10b數據集,選取了文獻[9]的CLDNN、文獻[10]的MCLDNN和文獻[11]的Dual-CNN-LSTM 4種模型進行對比實驗。文獻[9]的CLDNN模型使用3層卷積層、1層LSTM層和1層全連接層,卷積核數設置為50,卷積核大小分別為(2,7),(1,7)和(1,7),LSTM的單元參數設置為250,全連接層單元數設置為128。文獻[10]的MCLDNN模型將IQ數據分為3路輸入進網絡,通過卷積層對信號特征進行提取融合,經過2層LSTM和2層全連接層輸入Softmax層進行分類輸出。文獻[11]的Dual-CNN-LSTM模型使用了2路CNN-LSTM網絡結構,將信號的IQ數據和AP數據分2路輸入網絡。每一路CNN-LSTM網絡都由3層卷積層和2層LSTM層組成。卷積層卷積核數分別為256,256和80,卷積核大小為(1,3),(2,3)和(1,3),LSTM層的單元數分別設置為100和50,通過扁平層后,2路特征輸出在連接層融合,最后通過全連接層和Softmax層進行分類輸出。
4種模型在RadioML2016.10a上的實驗結果和識別曲線如表4和圖5所示。在RadioML2016.10a數據集上,文獻[9]模型的識別準確率為58.1%,當SNR在0 dB以上時模型的識別準確率為86.3%,明顯低于其他網絡模型。文獻[10]的MCLDNN模型識別準確率達到62.7%,SNR在0 dB以上識別準確率達到91.4%,文獻[11]的Dual-CNN-LSTM模型識別準確率和SNR在0 dB以上識別準確率分別為62.1%和90.8%。本文模型識別準確率為62.9%,SNR在0 dB以上識別準確率為91.6%,2項識別準確率略高于文獻[10]的62.7%和91.4%。
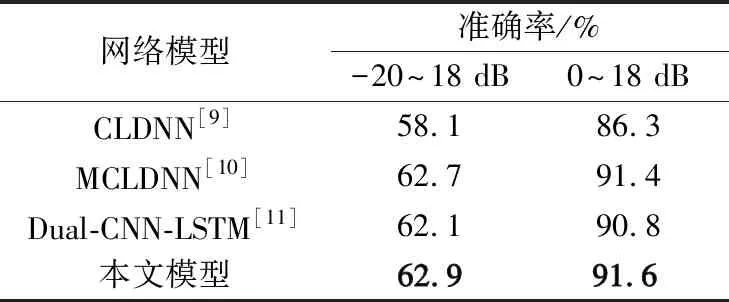
表4 基于RadioML2016.10a數據集的對比模型實驗結果
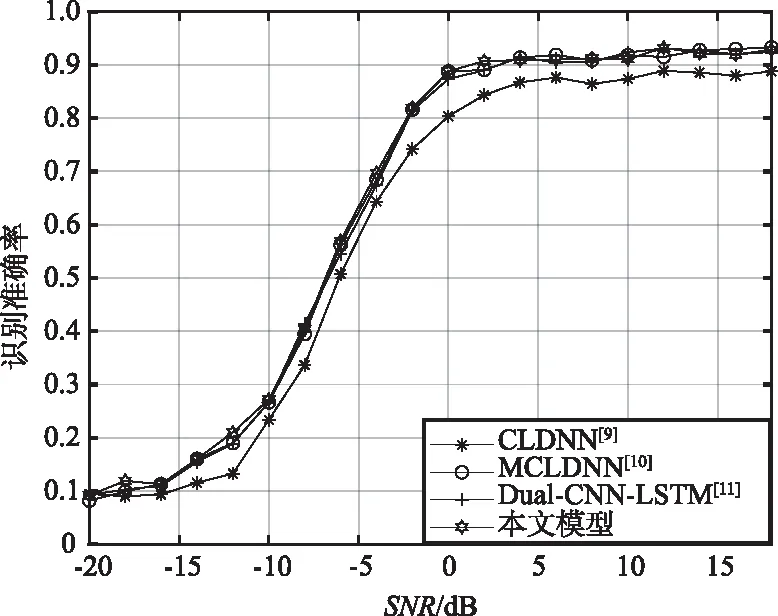
圖5 RadioML2016.10a數據集上對比模型識別準確率Fig.5 Comparison of model recognition accuracy curves based on RadioML2016.10a dataset
4種模型在RadioML2016.10b數據集上的實驗結果和識別準確率曲線如表5和圖6所示。在RadioML2016.10b數據集上,文獻[9]模型識別準確率最低,只有60.9%,本文模型識別準確率達到64.9%,比文獻[10]高0.4%,比文獻[11]高0.6%。SNR在0 dB以上時,本文所提模型識別準確率穩定在92%以上。
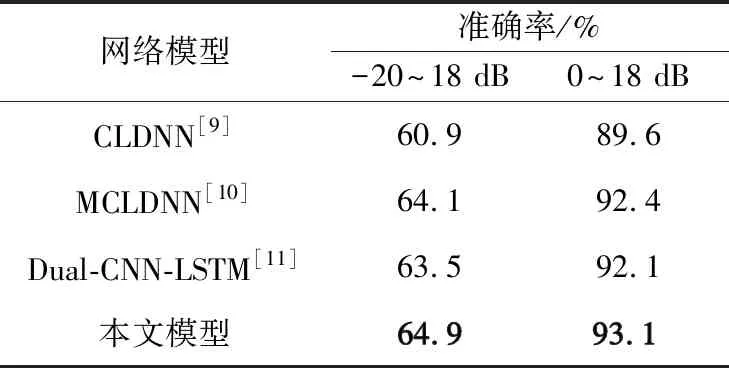
表5 基于RadioML2016.10b數據集的對比模型實驗結果
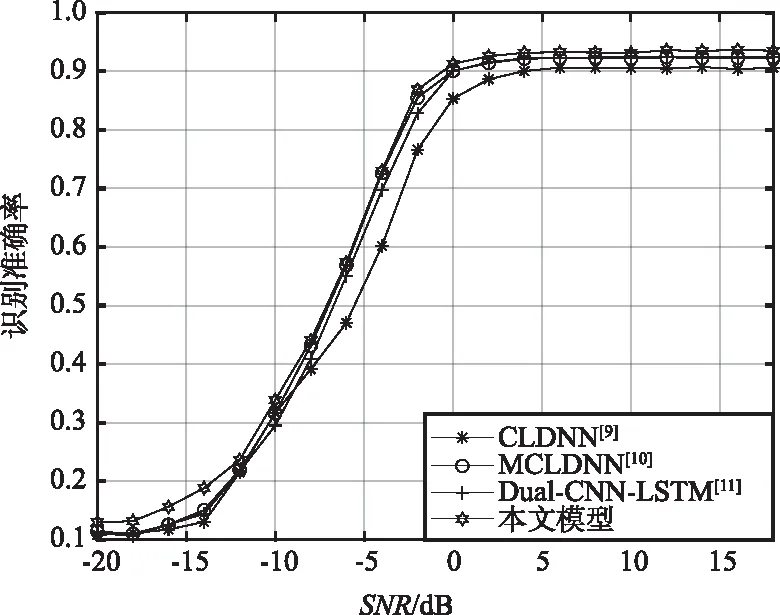
圖6 RadioML2016.10b數據集上對比模型識別準確率Fig.6 Comparison of model recognition accuracy curves based on RadioML2016.10b dataset
4種模型的參數量和計算量如表6所示。文獻[9]模型的參數量超過69萬,FLOPs為13.1 M。文獻[10]使用的MCLDNN模型設計了3路輸入,參數量超過40萬,FLOPs為35.8 M。文獻[11]模型使用的Dual-CNN-LSTM模型同時將信號的IQ和AP數據送入神經網絡模型,取得了較好的識別準確率,但同時犧牲了模型的參數量和計算復雜度,模型參數量超過118萬,FLOPs超過285 M。本文所提模型通過使用DSC和參數優化,使用6路輸入設計,在模型的識別準確率優于其他模型的同時,本文所提模型的參數量和FLOPs遠小于文獻[9-11]的模型。本文所提模型的參數量為113 497,僅為文獻[10]的34.3%,文獻[11]的11.7%,模型的FLOPs為8.4 M,是文獻[10]的23.4%,文獻[11]的2.9%。

表6 對比模型參數量和計算量
在所有文獻提供的模型中,文獻[9-10]中所提供的模型結構都存在一定缺陷和不足,文獻[9]中提到的CLDNN僅在原始CNN網絡中加入了LSTM結構,雖然該模型有效提高對時序特征的學習,但是原始信號存在I,Q兩個通道,不同通道間的特征信息存在差異,而僅使用CLDNN模型難以對2個不同通道數據的特征各自進行提取,因此在文獻[10]中設計了MCLDNN模型,針對這一問題進行了相應的改進。但是文獻[9-10]都存在參數量較大的問題,會大大降低模型的運行效率,在硬件設備性能較差時,模型的實時性難以得到保證。
文獻[11]在原始IQ數據的基礎上,加入AP數據用于提取新的特征,該方式雖然有效提高了信號的識別率,但是該模型也存在參數量過大等問題。因此在綜合考量各模型優勢及缺點后,本文提出了一種新型的低參量模型,該模型在保持較高識別率的前提下,大大降低了模型的參數量和模型復雜度。
2.5 MDSCLDNN-HAN性能分析
MDSCLDNN-HAN模型在0 dB時,對Radio-ML2016.10a中各類信號識別準確率如圖7所示。
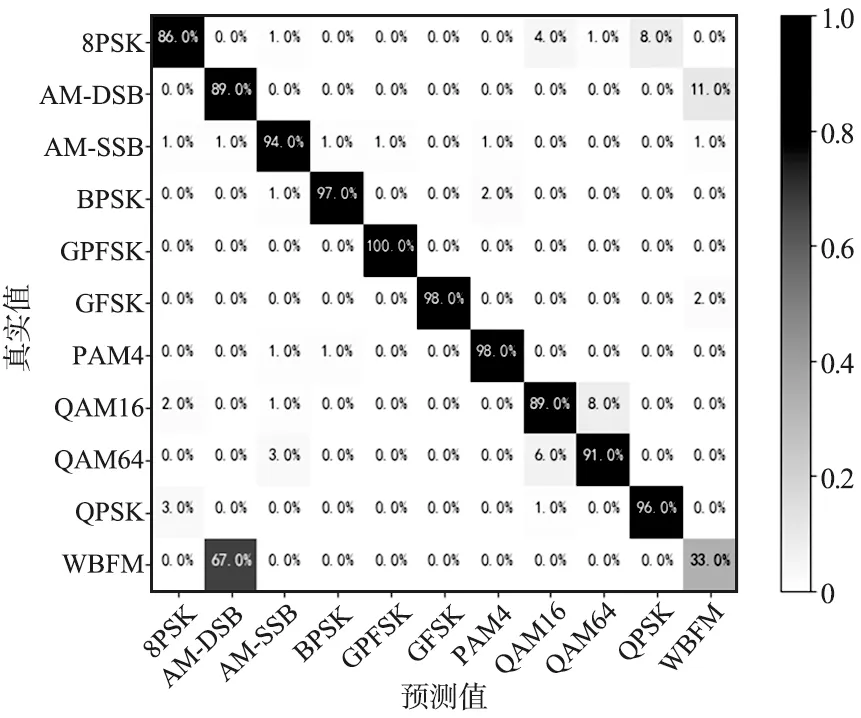
圖7 RadioML2016.10a,SNR=0 dB,混淆矩陣Fig.7 Confusion matrix based on RadioML2016.10a dataset,where SNR=0 dB
由圖7可以看出,WBFM的識別準確率最低,只有33%,其中有67%的WBFM信號被錯誤地識別成AM-DSB信號。對8PSK,AM-DSB,QAM16和QAM64四種信號識別準確率均達到86%以上,對AM-SSB,BPSK,CPFSK,GFSK,PAM4和QPSK六種信號識別準確率均達到94%以上。
MDSCLDNN-HAN模型在0 dB時,對Radio-ML2016.10a中各類信號識別準確率如圖8所示。由圖8可以看出,當SNR=10 dB時,本文模型在RadioML2016.10a中,對WBFM識別準確率較低,少部分QAM64信號被識別成QAM16信號,除WBFM和QAM64以外的信號識別準確率均超過98%。
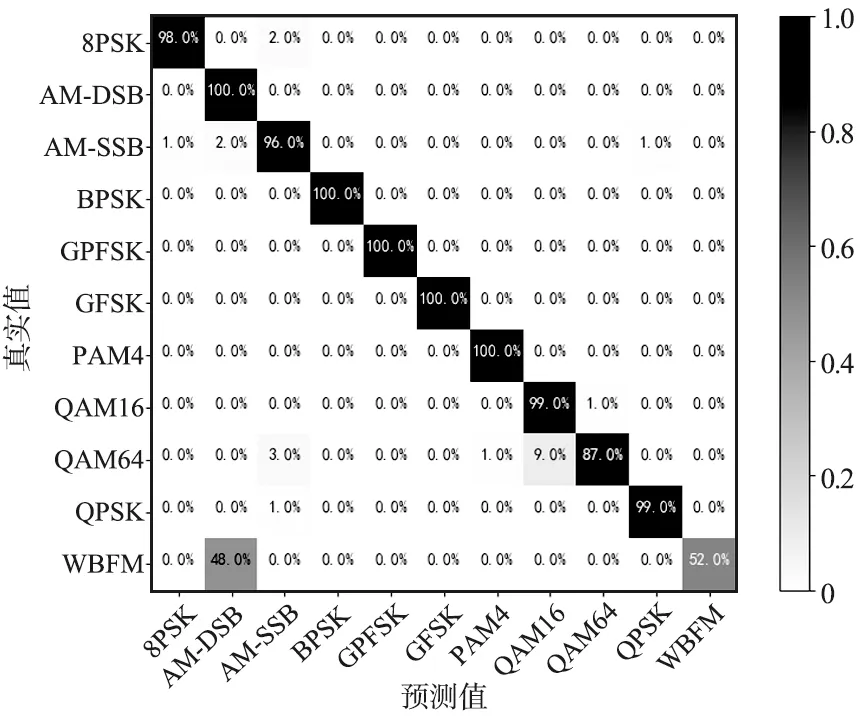
圖8 RadioML2016.10a,SNR=10 dB,混淆矩陣Fig.8 Confusion matrix based on RadioML2016.10a dataset,where SNR=10 dB
模型對RadioML2016.10b中各類信號在SNR=0 dB時識別準確率混淆矩陣如圖9所示。本文模型對WBFM的識別準確率最低,只有48.6%,對8PSK,AM-DSB信號識別準確率分別達到92%和86.6%,對BPSK,CPFSK,GFSK,PAM4,QPSK,QAM16和QAM64七種信號識別準確率均超過96%。
模型對RadioML2016.10b中各類信號在SNR=12 dB時識別準確率混淆矩陣如圖10所示。模型對除WBFM外的9種信號識別準確率均超過98.5%。
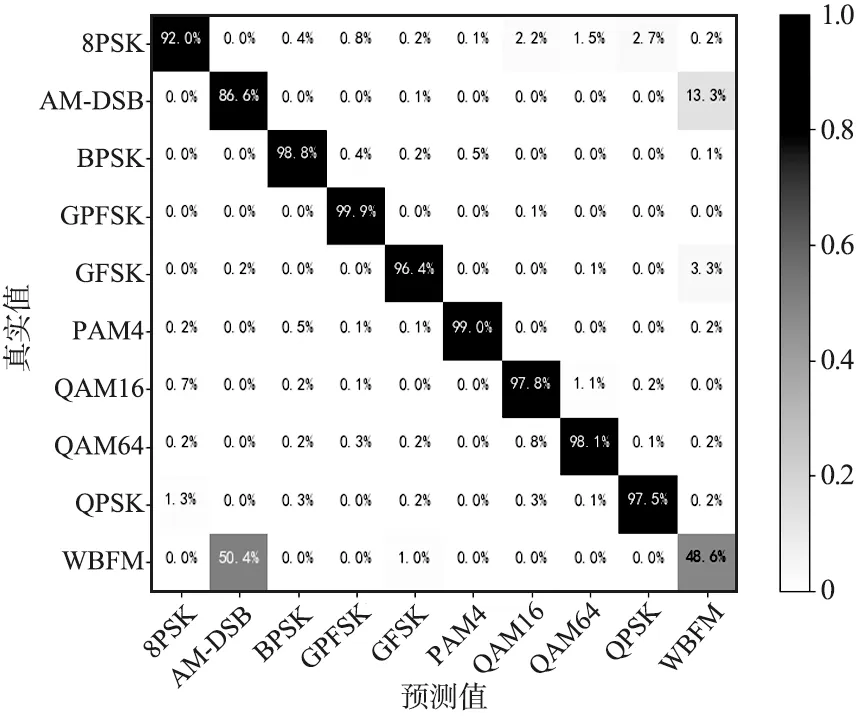
圖9 RadioML2016.10b,SNR=0 dB,混淆矩陣Fig.9 Confusion matrix based on RadioML2016.10b dataset,where SNR=0 dB
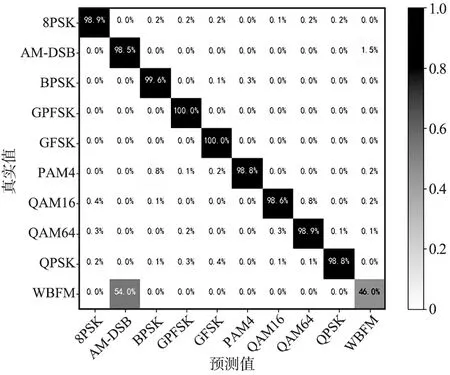
圖10 RadioML2016.10b,SNR=12 dB,混淆矩陣Fig.10 Confusion matrix based on RadioML2016.10b dataset,where SNR=12 dB
在對2個數據集的實驗中,均出現將大量WBFM信號錯誤地識別成AM-DSB信號,SNR在0 dB以上時,模型對除WBFM的各類信號實現較高的識別精度。由于AM-DSB和WBFM信號都屬于連續調制,因此它們之間的特征區別較小。此外,數據集中WBFM和AM-DSB是通過采樣模擬音頻信號生成的,數據中間存在信號的靜默期導致2種信號更加難以區分,即使隨著SNR的提高,WBFM的識別精度依然不能達到理想精度。如何使用深度學習的方法提高WBFM信號的識別精度,是后期需要改進的方向。
3 結束語
針對目前基于神經網絡的調制識別算法中神經網絡模型復雜和計算量大等問題,設計使用IQ和AP數據的6通道神經網絡模型MDSCLDNN-HAN,使用信號的IQ和AP數據和其分離通道數據,有利于獲得更有效的特征對信號進行分類。同時,在模型中使用注意力機制提取高頻特征,使用DSC層代替普通卷積層,減少模型參數量和計算量。理論分析和實驗結果表明,設計高效的模型結構和使用信號不同維度的數據提取融合特征,可以有效提高模型識別精度和降低模型復雜度。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
