評論情感分析增強的深度推薦模型
2022-09-06 13:17:16田添星
計算機應用與軟件 2022年8期
田 添 星
(復旦大學軟件學院 上海 201203)(數據分析與安全實驗室 上海 201203)
0 引 言
隨著互聯網的發展,網絡平臺上信息也呈爆炸性增長,但是用戶的關注程度卻并不隨之增長,主要原因在于用戶依賴搜索技術和系統難以從繁多信息中尋找到自己所需要的。為了解決該問題,推薦系統應運而生。推薦系統通過分析用戶歷史行為數據,理解用戶需求和興趣,為用戶及時提供最可能接受的信息。
協同過濾[1]是推薦系統領域最早也最成功的技術之一,該方法假定歷史上具有相同興趣的用戶,在未來也會有類似的喜好。傳統協同過濾方法通過矩陣分解[2]模型實現。這類模型使用用戶對物品的評分作為訓練數據。評分數據能直觀地體現用戶對物品的態度。但是,這類方法存在數據稀疏、冷啟動[3]等問題。研究者們嘗試利用其他數據作為補充來解決問題,比如商品的元屬性[4]、用戶地理位置[5]等。
隨著人工智能、機器學習和自然語言處理等領域的發展,計算機逐漸能夠自動地分析文本并從中提取有價值的信息,研究者也隨之開始探索用戶評論數據作為一種新的補充數據的可能性。比如,McAuley等[5]就利用主題模型,從物品的評論中提取出物品的屬性作為矩陣分解方法的補充,提升了推薦的準確性。另外一方面,情感分析是分析用戶生成的文本內容的重要手段,該技術可以有效幫助商品或服務的提供者理解用戶們在網上留下的評論。近些年來,情感分析作為比較基礎的自然語言處理任務,可以使用各種前沿的深度學習技術來完成,比如根據文本的局部性對文本進行分析的TextCNN[7]、根據語言的連續性對文本進行從左到右和從右到左兩個方向分析的雙向LSTM網絡[8]。近些年來,研究者意識到在深度學習任務中,學習過程里的眾多信息對當前任務目標的重要程度是不同的,因此提出了注意力機制[9]。該機制也隨后被運用到了各個模型及各個任務中,情感分析任務自然也可以運用到該技術,比如李松如等[10]提出一種采用循環神經網絡的情感分析注意力模型。
推薦系統和情感分析技術都在嘗試從評論中提取用戶的意見。盡管它們提取用戶意見用于不同的目標:前者目標是補充用戶和物品的特征,幫助預測用戶對物品的喜好度;后者根據一段文字判斷其中隱藏的情感。顯而易見的是,這兩種技術都需要對文本有準確的理解。事實上,目前已有的推薦系統大多欠缺對評論的良好理解,這是由這類推薦系統的學習模式決定。對于利用主題模型理解文本的系統,它僅會從評論中提取最顯著的詞,而不關注提取主題詞與推薦之間的關系。對于利用深度學習技術理解文本的系統,它會根據用戶或物品的全部評論綜合理解用戶,對用戶已有屬性或物品特征進行補充,而后進行評分預測。這種模式雖然使得文本中提取的信息與推薦高度相關,但在低層卻缺乏對單篇評論文本的準確理解,從而影響高層對用戶和物品的理解。與此同時,情感分析能夠有效地對每篇評論進行分析,是一種更專注于語言理解的技術。
因此,本文提出SERS,該模型通過情感分析技術幫助推薦系統理解評論文本,從而有效提高推薦性能。SERS使用兩個同結構不同參數的基于多頭注意力的循環神經網絡進行用戶偏好和物品特征的提取,同時進行情感分析任務(以用戶評分作為指示器)。對于每個用戶-物品對,提取的文本特征會與用戶和物品固有的特征向量結合得到新的特征向量。而后通過神經網絡,對用戶和物品的交互建模,進行評分預測。本文在真實數據集上與現有模型進行對比,證明了該模型擁有強大的推薦性能。
1 相關工作
隱因子模型是在推薦系統中廣泛使用的一種協同過濾技術的實踐成果。隱因子模型從已有的評分數據中觀察用戶的偏好和商品特征,將每個用戶和商品表征為固定維度的向量,并依此向用戶推薦新商品。
在眾多隱因子模型中,矩陣分解方法[2]無疑是最經典的一種,它將推薦任務轉變為一個矩陣補全問題。至今,眾多的先進模型都是構建在矩陣分解的技術基礎上的。比如,概率矩陣分解[11]方法就是一個擁有可靠性能,被廣泛采納的推薦框架。該方法從概率的角度實現了矩陣分解方法,并且在大型稀疏數據集上取得了很好的成績。
純粹的矩陣分解方法有一定的問題。沒有觀測到的用戶-物品的評分對與用戶數量和物品數量的乘積成線性相關,而已知的評分數據一般只與用戶數量成線性相關。因此,隨著如今網絡平臺商品數量的快速增長,數據的稀疏性也不斷增長,這成為了限制傳統模型推薦性能的關鍵問題。
解決稀疏問題的一個辦法是利用有價值的用戶生產的內容,如用戶評論、電影插圖和物品使用指南等。比如,HFT(Hidden Factors and Hidden Topics)模型[6]使用主題模型LDA[12]從評論中抽取特征,然后矩陣分解方法可以從中獲取到分布參數的先驗知識。基于傳統主題模型的方法存在的一個問題是,無法為推薦任務針對性地從評論中提取屬性,只能提取文本中通用的高價值主題。
近些年來,深度學習網絡結構開始被應用于自然語言處理。這股熱潮源自深度網絡結構在學習表示性詞向量上的成功,最著名的有Word2Vec[13]和Glove[14]。這些方法通過訓練模型中的詞嵌入層,將數據集中的詞知識存儲在對應的詞向量中。通過使用有意義的詞嵌入向量,幾乎所有被用于閱讀理解、機器翻譯、語音識別的技術都能被無縫地應用到自然語言處理當中。基于評論的推薦系統也得益于自然語言技術的進步,將深度學習技術運用到了對評論文本的處理當中,獲得了很大的進步。
Kim等[15]首先在推薦系統領域使用了深度卷積網絡,以N-gram的方式對評論文本進行建模,抽取出有價值的特征。該方法的一個局限在于,只對物品的評論文本進行建模提取屬性,而沒有意識到用戶的評論同樣可以為用戶提供屬性上的補充。
Lu等[16]進一步使用雙向循環神經網絡以及注意力機制從評論中抽取出主題性的文本特征,并將其引入到概率矩陣分解方法中。該方法同時對用戶和物品評論,并且運用了更前沿的自然語言處理技術,因此取得很好的成績。但是該方法沒有真正對語言知識進行很好的建模,缺乏對評論的準確理解。
與此同時,He等[17]將神經網絡技術應用到了推薦系統核心的用戶-物品交互上,提出了神經協同過濾框架,驗證了深度學習在該方面的有效性。本文在該方法基礎上,通過情感分析任務引入了用戶和物品的補充特征,提高了其預測性能。另一個常見的推薦模型是分解機(Factorization Machines,FM)[18],該方法在模型中手動添加特征的多階交叉交互,是一種簡單有效的模型。
2 模型設計
2.1 問題定義
給定一個數據集D,數據集中每個初始樣本為(i,j,di,j,ri,j),包含用戶i對物品j的一條評論di,j及對應評分ri,j。對于情感分析任務,需要根據評論文本di,j預測對應的評分ri,j,這里,本文將評分數據作為評論文本的情感指示器。對于推薦系統的評分預測任務,則需要根據用戶u、物品v及用戶u和物品v擁有的全部評論,對未知的用戶-物品對進行評分預測。在這里,兩個任務都利用評分數據作為指示器,但是情感分析任務利用語言知識對當前的評論進行評分;而推薦任務則是利用評分和評論數據學習到每個用戶和物品的屬性,然后對給定的用戶-物品對進行評分預測。
2.2 基于多頭注意力的循環神經網絡
本文設計一種基于多頭注意力的循環神經網絡進行評論文本的情感分析模型,并且為推薦任務提供文本特征,網絡結構如圖1所示。該網絡結構的輸入為評論文本,輸出有兩個:該段評論的情感分數s和文本特征向量f。值得注意的是,對用戶和物品使用兩個結構相同但參數不同的網絡來處理。因為,用戶和物品對評論的關注點是不同的,需要用不同的方式去從評論中提取觀點。比如,如果一個用戶頻繁提到“價格”,那么說明該用戶對價格非常敏感,一般而言更偏好高性價比的物品;而對于一個物品而言,評論中經常出現“價格”一詞本身代表不了什么,更需要關注的是“價格高”或者“價格低”。

圖1 基于注意力的循環神經網絡結構
(1) 詞嵌入層。在輸入模型之前,一段文本會先通過預處理步驟變成一個詞的id序列(x1,x2,…,xn),每個id都對應著建立的詞典里的一個單詞。詞id序列先通過詞嵌入層,轉變為稠密詞向量(w1,w2,…,wn),詞向量中包含著單詞的信息。本文通過使用Word2Vec對使用的數據集進行訓練,得到預訓練的詞向量。該詞向量用以初始化詞嵌入層,隨后詞嵌入層隨著模型一起微調。這樣的詞向量訓練方式,比起直接使用網絡上利用其他數據集已經訓練好的詞向量,擁有更好的性能。因為根據使用的數據集訓練的詞向量擁有更多領域知識,對在對應數據集上的特定任務更有幫助。比如,“經理”在通用知識中是一個中性詞,而在商品評論中出現時,通常是貶義詞:一般只有用戶在抱怨時才會提到“經理”。

(1)
(2)
ut=Sigmoid(Wuxxt+Wuhht-1+bu)
(3)
rt=Sigmoid(Wrxxt+Wrhht-1+br)
(4)
式中:⊙是元素點乘操作;tanh和Sigmoid是兩種不同的非線性激活函數;W和b分別是參數矩陣與計算偏置項;更新門ut決定了過去信息將有多少被新的信息所取代;而重置門rt則決定了上一步的激活單元將為當前候選激活單元提供多少的信息。在時刻t,單詞向量wt通過前饋GRU和反向GRU可以獲得兩個不同的語義向量,將兩者拼接后得到最終的語義向量ht。直到這一步,模型已經得到了對文本本身的理解,接下來需要根據任務對抽取出的語義向量序列做進一步處理。換言之,以上已經介紹的結構是情感分析任務與推薦任務共享參數的部分,因為它們都需要對模型的基本語義進行準確的建模。
(3) 注意力層。得到了文本的動態語義信息后,模型通過兩個不同參數的注意力結構,分別為情感分析任務與推薦任務,尋找文本中值得注意的信息。事實上,用戶對物品會有不同的關注角度,同時一條評論最終的情感分數也是從多個角度綜合得出的,而普通的注意力機制難以解決處理這類問題,因此本文參考了Transformer[9]中的多頭注意力機制,多角度地尋找文本信息與對應任務的相關性。首先是對已有的語義向量進行轉換,同時對向量進行降維,得到:
zt=tanh(Wht+b)
(5)
然后,將轉換后的語義向量與語境向量v相乘得到注意力分布,并通過Softmax函數進行歸一化,得到:
(6)
將該注意力分布向量與轉換后的語義向量序列進行加權和就得到了文本的語義信息摘要,表示為:
(7)
假設共有k個頭,則總的信息摘要為:
c=[c1,c2,…,ck]
(8)
即總的信息摘要向量為各個不同頭的信息摘要的拼接向量。
通過兩個不同參數的注意力網絡,可以分別得到情感語義摘要cs和推薦語義摘要cf。
(4) 映射層。在得到了針對兩個不同任務的文本信息摘要后,需要通過映射層做進一步處理。對于情感分析任務,可以直接根據摘要進行情感分數s的預測。對于推薦任務,則需要根據對應用戶和物品的屬性的維度,通過映射得到文本特征f。這些操作都可以通過全連接層(Fully Connected Layer,FC)完成。
s=tanh(Wcscs+bs)
(9)
f=tanh(Wcfcf+bf)
(10)
情感分數s作為輔助任務的結果加入到模型的損失函數中,幫助模型理解評論;而用戶和物品都可以根據其評論文本得到文本特征,在與其固有屬性e融合后進行評分預測。
2.3 文本特征擴展的神經協同過濾網絡
通過情感分析任務,每篇文檔都可以得到一個特征表示。本文對屬于特定用戶或者特定物品的全部評論的特征表示取均值,作為該用戶或特征的文本特征,并將該步驟記為encoder以便后文表示。本節介紹如何利用這些提取的特征進行推薦任務。
推薦部分的算法流程如圖2所示。

圖2 文本特征擴展的神經協同過濾算法模型
模型主要包括三個部分:特征獲取、特征融合和評分預測。
(1) 在特征獲取部分,模型將輸入值轉換為稠密向量。具體而言,用戶根據其id在嵌入層得到固有的屬性eu,i,并且通過encoder流程從其全部評論中提取出文本特征fu,i。物品通過類似的步驟得到屬性ev,j和文本特征fv,j。
(2) 在特征融合步驟,需要將固定特征e與文本特征f結合,以便用戶和物品的特征交互。為了提高性能,研究者提出了不同的特征融合方式,比如相加、拼接。參考已有的相關工作[20-21],本文采用了相加的方式將從評論中提取的特征與固有特征相結合得到新的用戶特征Fu,i與物品特征Fv,j,具體計算公式為:
Fu,i=eu,i+fu,i
(11)
Fv,j=ev,j+fv,j
(12)
(3) 在評分預測階段,則是根據用戶和物品的屬性,模擬它們之間的屬性交互,以此推測用戶對物品的看法,即評分。最傳統的評分預測方式是矩陣分解法,但這種方式存在線性的限制。隨著深度學習的發展,Rendle[18]和He等[17]分別提出了經典的分解機器模型(FM)和神經協同過濾框架(NCF),這兩種方法都能很好地模擬用戶和物品的復雜交互,進行準確的推薦預測。本文參考NCF的框架,這一階段的輸入值為用戶融合特征Fu,i和物品融合特征Fv,j,兩者拼接后通過多層的全連接層和tanh激活函數,以計算交互向量,最后一層使用ReLU作為激活函數得到最終的預測分數:
(13)
式中:σ(x)=tanh(Wx+b)。
2.4 模型優化方式
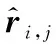
(14)
(15)
ltotal=(1-γ)lrec+γlsen
(16)
訓練時,本文采用Adam[22]作為優化器,Adam可以根據訓練過程迭代地更新神經網絡的權重,有效減少學習率的調整難度。另外,本文使用余弦退火(Cosine Annealing Learning Rate)[23]的學習率衰減控制機制,利用cosine曲線更新學習率,更容易找到參數中的最優點。
3 實 驗
3.1 數據集與評估方式
為了分析模型在不同數據集上的表現,在四個真實世界的數據集上進行了實驗。數據集為公開可下載的亞馬遜產品數據集[24]中的“Sports and Outdoors”“Grocery and Gourmet Food”“Baby”“Home and Kitchen”。在完整的數據集中,部分用戶只有一兩條的評論,這使得模型難以從評論中抽取出意見。為此,本文使用5-核的數據集:只保留評論數量大于等于5的物品和用戶以及對應的評論數據。實驗數據集的細節如表1所示。

表1 數據集統計信息
為了驗證本文提出模型的性能,采用了在評分預測相關工作中被廣泛采用的均方差(Mean Square Error,MSE)作為模型評價指標:
(17)
MSE分數越低,代表預測評分越接近真實值,推薦性能就越高。模型在測試集上以不同隨機種子計算5次結果,取均值作為最后分數。
3.2 基準模型
為了評估SERS的推薦性能,本文選擇了若干經典推薦模型作為對比模型,包括:PMF[11]、HFT[6]、ConvMF[7]和TARMF[16]。
(1) PMF:概率矩陣分解法(Probabilistic Matrix Factorization)是矩陣分解方法從概率的角度出發的一個經典的實現。它在大型的稀疏數據集上表現優秀。
(2) HFT:隱因子主題模型(Hidden Factor as Topics)將LDA(Latent Dirichlet Allocation)主題模型并入了矩陣分解中。它是利用主題模型進行推薦任務中文本分析的經典模型。
(3) ConvMF:卷積矩陣分解法(Convolutional Matrix Factorization)是首個引入神經網絡以處理評論文本的推薦模型,它通過應用卷積神經網絡從物品的評論中抽取物品的特征,并以此擴展矩陣分解方法。
(4) TARMF:此模型通過基于注意力機制的循環神經網絡從評論中提取主題信息,并將該信息引入傳統矩陣分解方法中。
3.3 超參數調整
參照對比模型,本文對數據集按8 ∶1 ∶1的比例進行訓練集/驗證集/測試集的劃分。各個模型在訓練集上進行訓練,并根據驗證集挑選最優參數,最后在測試集上進行性能評估。每個分數都會以5個不同的隨機種子進行測試后取均值。
在實驗中,為避免過度調參,參數搜索范圍被限制在較小的范圍內,并且將在不同數據集上擁有較好性能的超參固定。模型中詞向量維度固定為256維,GRU編碼層維度固定為128維,注意力層的狀態變量維度為16維,共有4個頭。這些參數都屬于情感分析部分,在不同數據集上都擁有接近最佳的性能,這是因為不同數據集的評論是類似的,其語法結構、包含的語言知識都比較接近。
物品和用戶的嵌入層向量維度取相同的值,記為m,取值范圍為:[4,8,16,32]。SERS中神經協同過濾網絡的多層全連接層可以調試的范圍極大,但通過多次實驗,發現固定為4層,每層維度為(8m,4m,2m,m)即可得到較優的結果。
訓練時,批大小固定為64就可以得到較優的結果,該參數過小會影響最終收斂結果,而參數過大則會導致訓練效率低下;學習率的設置則對結果影響較大,該參數的搜索范圍為:[1e-2,5e-3,3e-3,1e-3]。
調節系數γ的搜索范圍為0.1到0.9,間隔0.1。通過在不同數據集上的測試,發現情感損失與推薦評分損失的調節系數γ為0.5時,推薦任務的評分預測損失最低。
3.4 性能比較
SERS模型與基準模型在四個數據集的測試集上的評估分數如表2所示,粗體表示在對應數據集上的最佳結果。

表2 各模型測試結果
可以看出,SERS的MSE分數超過了對比模型,說明了SERS擁有強大的推薦性能。
通過觀察可以發現,利用評論信息的模型的表現都大幅優于只能接觸到評分數據的模型PMF。這說明評論信息中,確實包含了能夠指導推薦的信息,因此如何從評論中更好地提取信息是一個值得研究的問題。
HFT模型通過傳統主題模型LDA,從評論文本中提取出重要的主題信息,用以解決評分數據稀疏問題,比起只利用評分數據的模型PMF取得了很大的進步。但基于概率的傳統主題模型無法動態地捕捉推薦所需要的信息,容易提取與用戶偏好或者物品屬性無關的特征。
模型ConvMF采用了神經網絡模型,通過卷積神經網絡建模物品的評論文本,根據推薦任務的評分指示器動態地為矩陣分解方法補充特征,因此性能超過了HFT。該方法的問題在于,僅僅考慮了物品的評論,而忽視了利用評論來補充用戶的屬性。
模型TARMF一方面提出利用兩個不同的編碼器處理用戶評論文本和物品評論文本,同時為用戶和物品提供動態特征;另一方面通過基于注意力的循環神經網絡,捕捉評論中的主題信息,該網絡結構優于傳統的卷積神經網絡,因此其性能超過了ConvMF。但是該方法沒有對語言通用知識的訓練,因此難以準確理解文本信息。
參考了以上模型的優缺點,SERS采用了基于多頭注意力的循環神經網絡,同時為用戶和物品從其評論文本中抽取推薦所需要的特征;并且增加了對文本進行評分預測的任務輔助推薦模型對語言進行更精確的理解。因此,SERS在測試的四個數據集中穩定超過了其他模型。
3.5 情感分析任務的影響
本文在MSE比較接近的Food和Sport數據集上調節損失函數中的平衡系數γ,以觀察SERS中情感分析任務對推薦任務的影響。γ越接近0,訓練目標越偏向推薦系統,當γ為0時,情感分析任務不起作用。實驗結果如圖3所示。
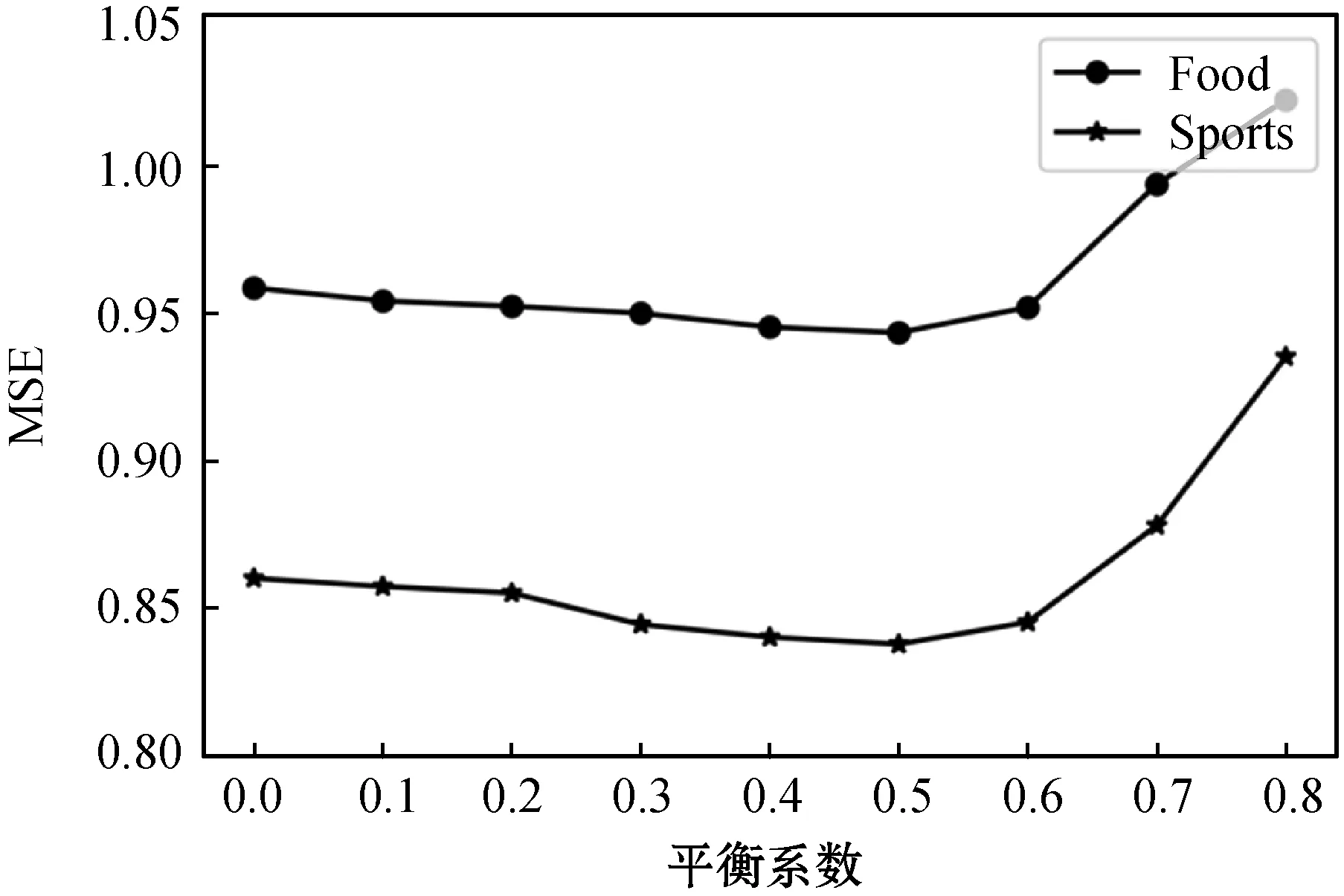
圖3 推薦任務的MSE隨平衡系數變化而變化的過程
可以發現,當γ從0變化至0.5的過程中,推薦模型的損失是逐漸降低的,而后快速上升。這說明,當情感分析任務在所占比重合適時,確實能夠對推薦任務有所幫助。這是因為,這兩個任務的進行都需要從評論中挖掘觀點,因此兩者底層的語言知識一定程度上可以互通。在其他數據集上也可以觀察到與圖中類似的趨勢。當γ系數過高時,模型更關注情感分析任務,因此推薦任務的性能有所下降。
4 結 語
以往的基于評論的推薦系統中,通常直接利用從評論中提取的特征以補充用戶和物品屬性,缺乏對評論文本的準確理解。因此,本文提出一種利用情感分析任務輔助推薦系統理解語言的方法。在4個公開數據集上進行了測試,驗證了該方法的有效性。
未來的工作方向有兩個。首先是增強用戶屬性與物品屬性的交互建模。本文的重心在于增強對評論文本的理解,而未對用戶和物品之間的屬性交互做進一步探索,其中存在很大的進步空間,比如利用注意力機制幫助用戶更好地關注物品的重要屬性。其次,則是加強對評論文本的理解。ELMO[25]和BERT[26]等的“預訓練+下游任務”的模式在自然語言領域取得了重大的進步,該如何有效地利用這種模式幫助推薦系統理解評論文本是一個值得探索的問題。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
