基于差分隱私的健康醫療數據保護方案
2022-09-07 03:20:32白伍彤陳蘭香
計算機應用與軟件 2022年8期
白伍彤 陳蘭香
(福建師范大學數學與信息學院 福建 福州 350117)(福建省網絡安全與密碼技術重點實驗室 福建 福州 350117)
0 引 言
國務院辦公廳于2016年6月頒發的《關于促進和規范健康醫療大數據應用發展的指導意見》(下簡稱為《意見》)指出國家重要的基礎性戰略資源是健康醫療大數據,健康醫療大數據相關應用的發展將為健康醫療模式帶來深刻改變,為健康醫療大數據的發展定下基調。
2016年10月,中共中央、國務院印發了《“健康中國2030”規劃綱要》,提出要加強并推進基于區域人口健康信息的醫療大數據開放挖掘和各類應用體系的建設。《意見》中指出,針對法律法規和隱私安全問題,要求完善數據開放共享支撐服務體系,針對健康醫療數據安全體系加快建設,同時對于人口健康醫療信息的工程技術、內容安全等多方面進行規劃制定以確保各類關鍵信息以及核心系統的安全可控與穩定[1]。
從隱私保護的角度來說,隱私的主體是單個用戶,只有涉及到某個特定用戶的敏感信息才叫隱私,如果是發布群體用戶的信息(一般叫聚集信息)不算泄露隱私。因此,充分利用并挖掘大數據的價值可以不需要涉及到任何用戶的個人隱私。
在健康醫療大數據領域即是如此,利用這些大數據對于優化資源配置、提供臨床決策與精準醫學研究等方面具有重要的價值,但怎樣合理合法地利用這些數據的同時又能保障用戶的隱私信息,是當前亟待解決的問題。
針對傳統隱私保護模型存在的問題,本文提出利用基于Laplace機制與指數機制的差分隱私保護方法,對健康醫療數據中的數值型與非數值型數據提供高強度的隱私保護。通過大量的實驗分析,針對差分隱私保護參數ε對數據的可用性與隱私保護水平兩者的平衡進行評估,得到不同類型的健康醫療數據的適當的參數取值。
1 相關工作
早在20世紀80年代初,Cox[2]首次提出了匿名化的概念,并指出這種方法可應用于隱私信息的保護。Sweeney[3]提出k-匿名(k-anonymity)模型的數據匿名化隱私保護方法,考慮的是數據擁有者想與其他用戶共享其私有數據,但是不能泄露他的身份的應用場景。針對這個問題,他們通過泛化與分解等方式對原始私有數據進行匿名化處理,有效地解決了隱私保護的問題。k-匿名模型的核心思想是:所發布的數據中任意一條記錄(也稱之為一個等價類)都被要求與另外的至少k-1條記錄是不可區分的,則稱該系統提供k-匿名保護。在k-匿名處理后的數據被攻擊者獲得的同時會至少得到不同的k個記錄數據,這樣便使得攻擊者即使通過攻擊得到了數據,但其也無法做出相應的準確判斷。該匿名模型中隱私保護的強度被表示為參數k,隨著k值的增大,隱私保護的強度也隨之增強,但因此會使得更多的信息丟失,數據的可用性也會越來越低。
Machanavajjhala等[4]在研究中發現了k-匿名模型中存在著對于敏感屬性未進行有效制約的不足,因此攻擊者就可以通過背景知識攻擊以及一致性攻擊等多種不同方法來推斷出數據中的敏感信息與某個人之間的關系來得到攻擊者所關心的個人隱私數據,這導致了數據記錄中的個人隱私信息發生泄露。例如攻擊者使用一致性攻擊時,當一個攻擊者獲得了k-匿名化數據,當被攻擊者所處的記錄中都是患有某一類傳染疾病的病人,那么攻擊者很輕易做出被攻擊者是確定患有此類傳染疾病的判斷。那么為了防止這種一致性攻擊,Machanavajjhala等對于k-匿名模型進行改進,提出了新的隱私保護模型:l-多樣性(l-diversity),它保證了任意一個等價類中的敏感屬性都至少有l個內容不同的值,一定程度上避免了敏感屬性所取值單一的情形。
針對l-多樣性模型在一些特殊情況下不適用的問題,Li等[5]提出了t-近鄰(t-closeness)模型,它對準標識符屬性與敏感信息的全局分布之間的聯系進行了約束限定,將特定敏感信息與半標識列屬性之間的聯系減弱了,這樣便使得對敏感信息的分布信息進行屬性泄露攻擊的可能性有所減少,但同時也會使得信息有一定程度的丟失。
所有匿名機制試圖盡量減少信息丟失,然而這種嘗試卻為攻擊提供了漏洞,Wong等[6]稱之為“最小性”攻擊,他們提出的m-機密性(m-confidentiality)模型可以在較小的開銷和信息丟失情況下抵制此類攻擊。
然而k-匿名模型及其改進方法存在兩個主要的缺陷:(1) 這些模型總是因為新型攻擊方法的出現而需要不斷改進,從而陷入一個無休止的循環中;(2) 該類型的模型對攻擊者的攻擊模型和背景知識給出了過多的些許在現實中不完全成立的假設,所以攻擊者是可以找到多種不同的攻擊方法進行攻擊以達到其竊取隱私信息的目的。其根本原因是對于其隱私保護的水平無法通過嚴格有效的方法得到證明,同時無法定量地分析其隱私保護水平。
因此,找到一種魯棒性更好的新的隱私保護模型,使得它能夠在攻擊者所掌握最大背景知識的條件下抵御不同形式的攻擊就是研究者需要解決的問題。差分隱私保護模型就是在這樣的需求下提出的。
差分隱私(Differential Privacy,DP)在2006年時被微軟研究院的Dwork[7]提出,這是一種新的隱私保護模型。此方法定義了一個嚴格的隱私保護模型,在數據中加入干擾噪聲來保護數據中的用戶隱私。如此,即便假設攻擊者已經獲得了最大背景知識的攻擊條件之下,也無法獲得記錄的隱私信息數據;同時對隱私保護水平給出了嚴格的數學證明和量化評估方法,給出了一個數學描述來測量一個擾動機制究竟能夠帶來多大程度上的保密性。這解決了傳統隱私保護模型中的一些缺陷。此后,還給出了差分隱私保護模型的綜述[8]。
因差分隱私保護模型相較于其他模型的諸多優勢,使其引起了計算機科學、密碼學等諸多領域的關注和研究,成為了當前隱私保護的研究熱點,也迅速地取代了一些傳統的隱私保護模型。
差分隱私保護基于數據失真技術將某種特定分布的隨機噪聲添加進需要處理的數據集中,進而得到被擾動后的新的數據集來達到對數據隱私保護的目的。因為數據集的大小對所加入的噪聲強度不影響,噪聲量只與全局敏感度相關,因此即便是大型的數據集,使用差分隱私也只需通過添加較為少量的噪聲干擾就可以使數據集得到很好的隱私保護。差分隱私中常用的兩種機制有拉普拉斯Laplace機制[9]和指數exponential機制[10]。
文獻[11]將差分隱私模型相比于傳統隱私模型的優勢進行了分析,并針對差分隱私的基礎理論和差分隱私在數據分享等應用的研究進行了綜述。文獻[12-13]對差分隱私在數據發布與數據分析兩個領域的應用進行了綜述。文獻[14]介紹了本地化差分隱私的原理與特性,并對本地化差分隱私保護技術進行綜述。文獻[15-16]對差分隱私的基礎理論和目前的研究進展進行了綜述。
傳統隱私保護模型以及差分隱私保護模型的研究成果豐碩,但是在健康醫療領域,關于隱私保護的有效方案還比較缺乏。特別地,具有量化特征以及強隱私保護特點的差分隱私保護機制也存在一個弱點:由于對于背景知識的假設很強,需要在數據的查詢結果中添加進大量的隨機數據,這使得數據的可用性大大降低。為了在數據隱私保護強度與可用性之間取得平衡,本文對差分隱私保護參數ε對數據隱私保護強度與可用性的影響進行評估,通過實驗分析給出不同類型的健康醫療數據的適當的ε取值。
2 預備知識
2.1 符號定義
本文使用的符號定義如表1所示。
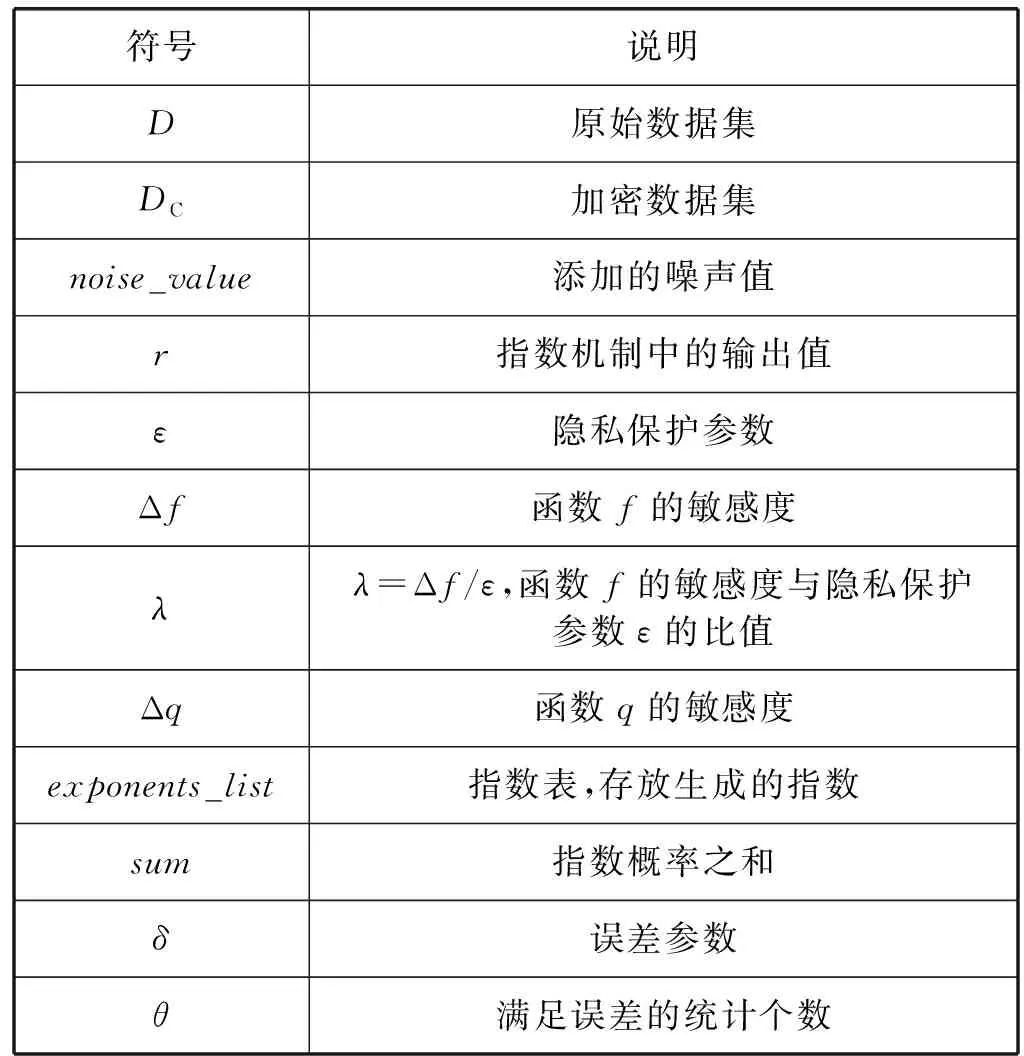
表1 符號說明
2.2 差分隱私保護
對于一個隨機算法S,PS為S所有可能輸出的集合,對于任意的兩個相鄰數據集D和D′及PS的任意子集AS,滿足:
Pr[S(D)∈AS]≤exp(ε)Pr[M(D′)∈AS]
(1)
則稱算法S滿足ε-差分隱私。在這個定義中,當某個數據記錄發生變化時,數據庫的統計分析結果對于此變化是不敏感的,意味著在數據集中單條記錄的存在與否對計算結果的影響可忽略不計,所以攻擊者無法通過向數據庫遞交多次查詢后根據返回結果而獲取個體隱私信息。
差分隱私算法針對不同的數據類型可以使用不同的實現機制,在最常用的兩種機制中Laplace機制常用于記錄中數值型數據的隱私保護,指數機制則常用于對非數值型數據進行處理。
2.2.1Laplace機制
Laplace機制是將服從Laplace分布的噪聲數據添加在輸出結果上,使得原始數據發生一定的擾動,使得接收者無法分辨在兩個相鄰的數據集D和D′上所產生的輸出結果的差異,其定義如下。
給定函數f:D→Rd,若算法S的輸出滿足式(2),則稱S滿足ε-差分隱私。
(2)
(3)
Laplace機制的概率密度函數如圖1所示,在不同參數的Laplace分布中,隱私保護參數ε越小,隱私保護水平越高,數據的可用性就越低。當ε=0時,算法S輸出的結果則不能反映出有關數據集的任何有用信息。

圖1 Laplace機制的概率密度函數
2.2.2指數機制
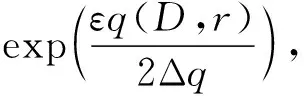
(4)
指數機制中參數q對于單個記錄的敏感性低,其函數敏感性公式如式(5)所示。
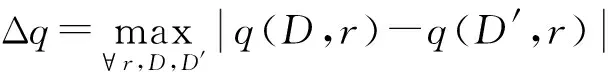
(5)
3 基于差分隱私的健康醫療數據保護
3.1 基于差分隱私的數據處理框架
針對健康醫療數據的高敏感性特征,根據數據類型對數據加入不同類型的噪聲對數據進行一定程度的擾動。但是在加入噪聲過程中要平衡數據的可用性與安全性,使得發布后的數據在依然保留整體統計信息可用性的前提下保護單個用戶的隱私信息。本文提出的基于差分隱私保護的健康醫療數據保護方案的數據處理框架如圖2所示。

圖2 基于差分隱私的數據處理框架
首先將健康醫療數據庫中直接關聯個體用戶的敏感內容,如姓名、身份證號及電話等個體標識信息去除。然后將數據分為數值型與非數值型數據兩類,數值型數據采用Laplace機制,非數值型數據則采用指數機制,分別對數據添加噪聲。為了同時保證數據的可用性和安全性,進一步平衡設置了誤差參數δ和滿足誤差的統計個數θ,通過控制δ和θ的取值來滿足在不同數據集上對可用性和安全性的不同需求。為了保護數據的機密性,數據以加密形式存儲,當數據發布給使用者時,使用者根據授權解密數據,然后對加了噪聲的數據進行分析處理。
在使用Laplace機制和指數機制時,需要根據數據的用途設置隱私保護參數ε以平衡數據可用性和隱私保護程度。
3.2 方案詳細設計
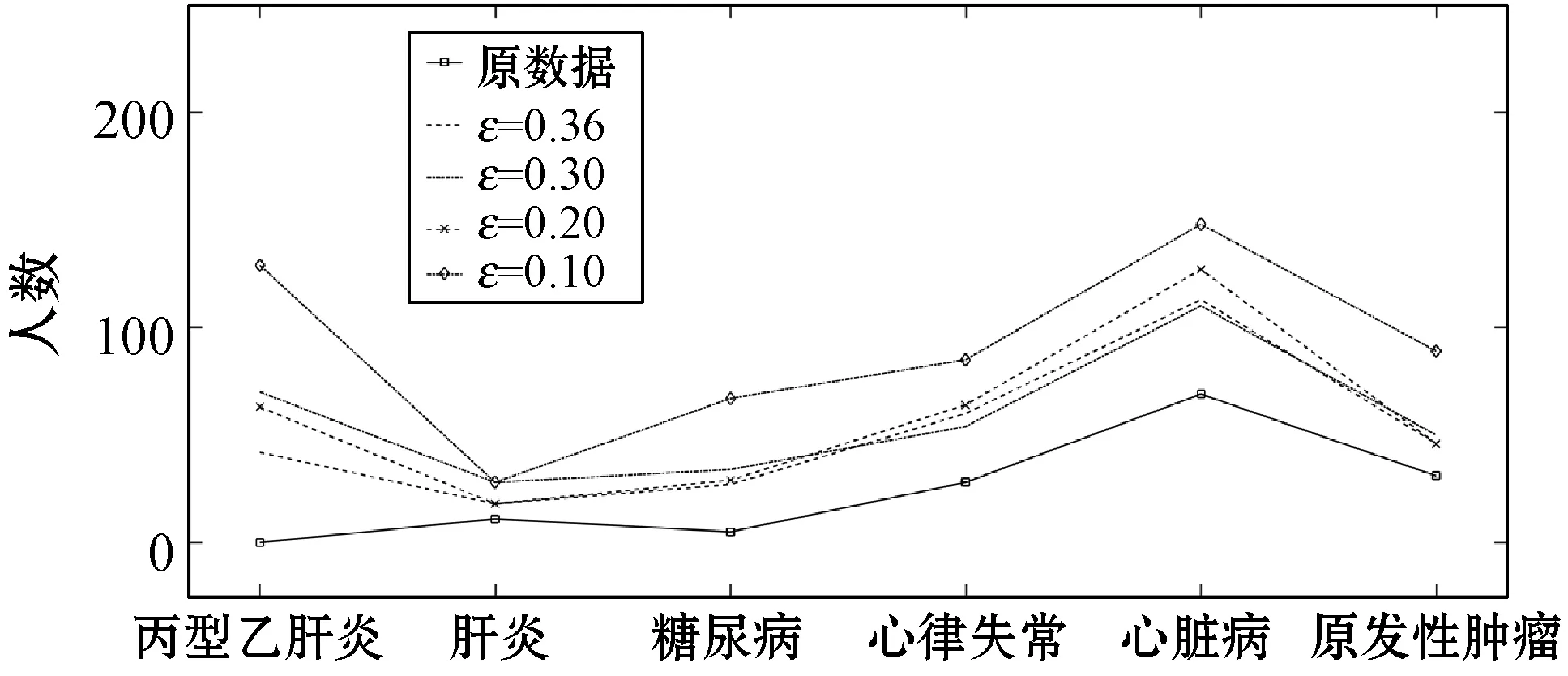
為了對健康醫療數據的隱私保護強度與可用性進行評估,我們對數值型與非數值型兩類健康醫療數據設計了Laplace機制與指數機制分別對數據進行基于差分隱私的保護,按對不同數據的安全性和可用性需求進一步設定誤差參數δ(即處理前后統計數之差與原數據比值)和滿足誤差的統計個數θ,同時引入皮爾遜相關系數來進一步判定數據在處理前后的相似度來保障處理后數據的可用性(0.8~1.0極強相關)。我們以身體質量指數(Body Mass Index,BMI)和年齡作為數值型數據的案例,對其應用Laplace機制添加噪聲;而非數值型數據則以性別為例,對其應用指數機制加入噪聲,然后將處理后的數據加密后發布,使數據使用者得到數據后解密再進行相關的數據統計分析。
在針對不同類型的數據使用差分隱私處理時,因為差分隱私的定義表明對于隱私保護參數ε的取值與對原始數據的擾動影響程度成反比,即對隱私保護參數的取值越小,加入原始數據的噪聲量越大,對于原始數據的擾動也就越大。對于健康醫療數據而言,要求數據在用于數據分析時的統計結果波動不大的同時使數據的隱私得到保護,即數據的可用性和安全性都有保障,因而對于隱私保護參數ε數值的設置就需要根據數據的不同來進行調整以達到較好的效果。
針對數值型數據的Laplace機制的處理算法如算法1所示,因為算法采用Python語言實現,因此其算法的偽代碼中有Python中的常用函數,其中np是Python的一個運算函數庫,random()表示生成隨機數函數,按所設置的Δf和ε隨機生成噪聲,將噪聲添加在原始數據中得到加噪數據,同時判斷經過噪聲處理后的數據是否滿足了δ和θ預先設定的要求。
算法1Laplace機制擾動算法
輸入:數據庫中的數值域age,BMI,ε,δ和θ。
輸出:加入噪聲的age_d和BMI_d。
2)u1=np.random.random(),
u2=np.random.random()
//生成取值范圍為[0,1)的隨機浮點數u1和u2
3) ifu1≤0.5
noise_value=-λ*np.log(1-u2)
else
noise_value=λ*np.log(u2)
4)age_d=age+noise_value1;(ε=ε1)
BMI_d=BMI+noise_value2;(ε=ε2)
5) pearson(age,age_d)
pearson(BMI,BMI_d)
6)θ1=0
ifδ1>δandδ2>δ
數據處理誤差不符合要求
else
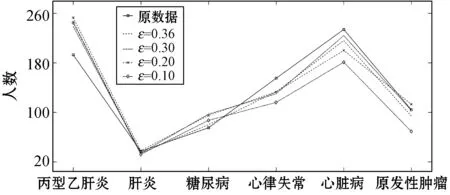
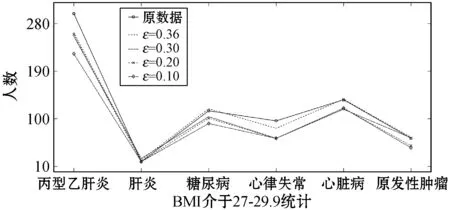
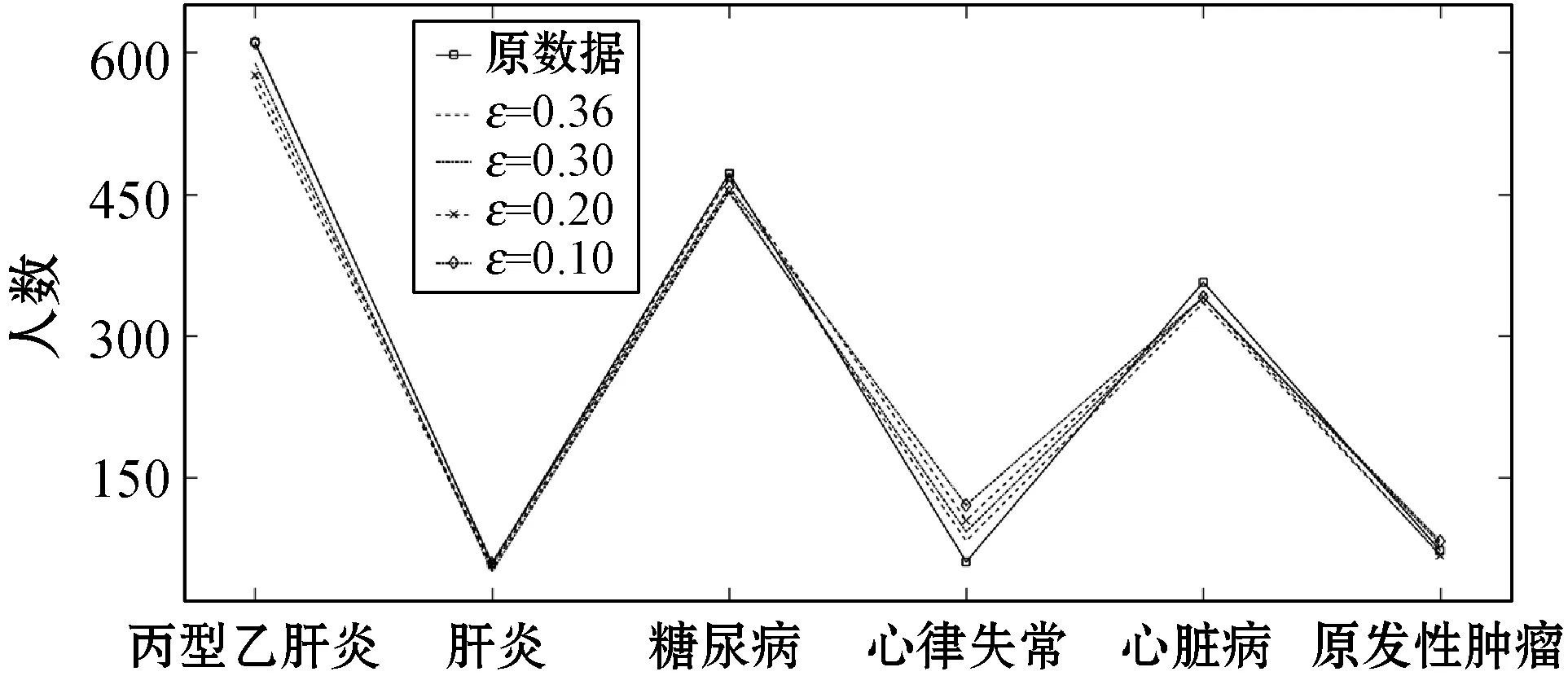
θ1=θ1+1
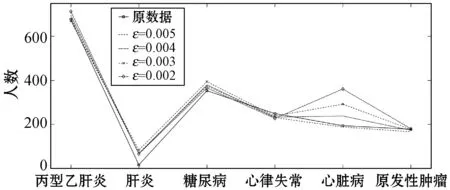
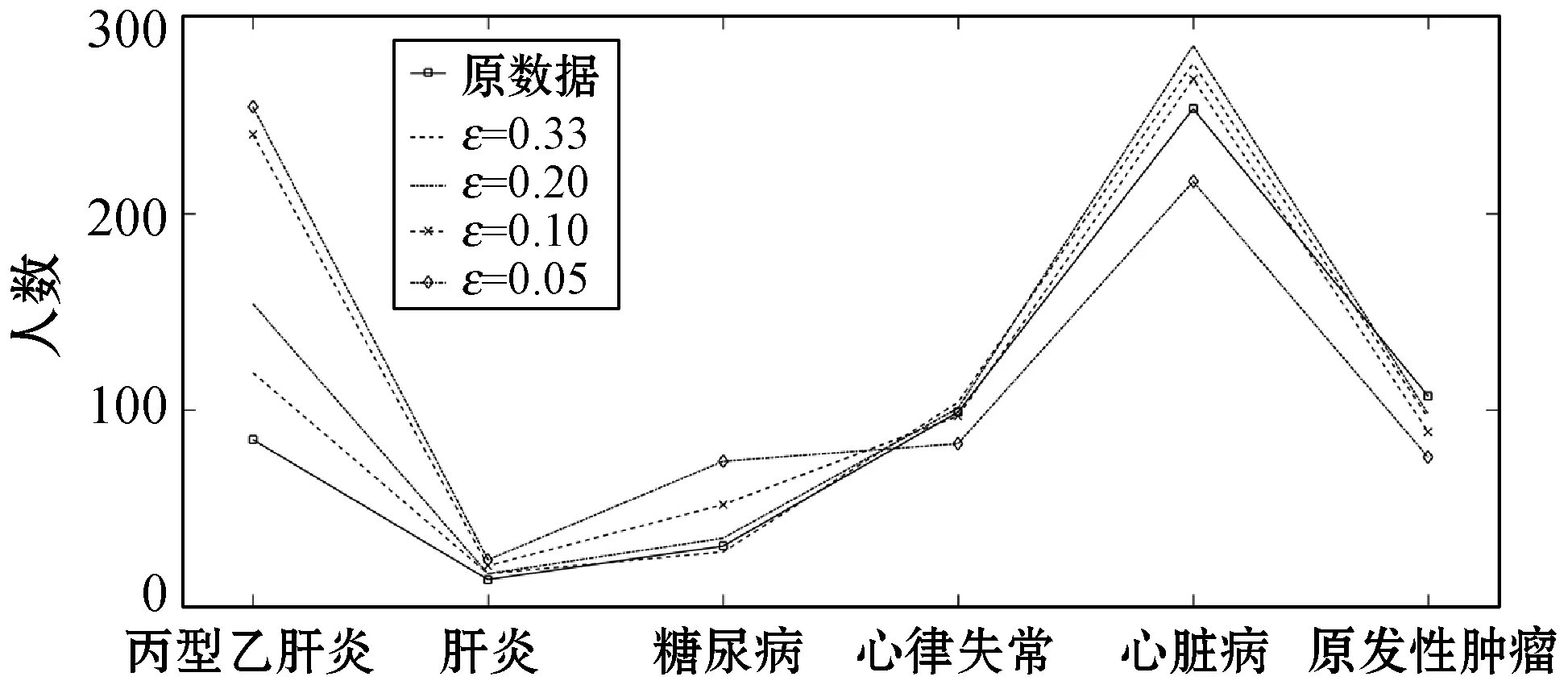
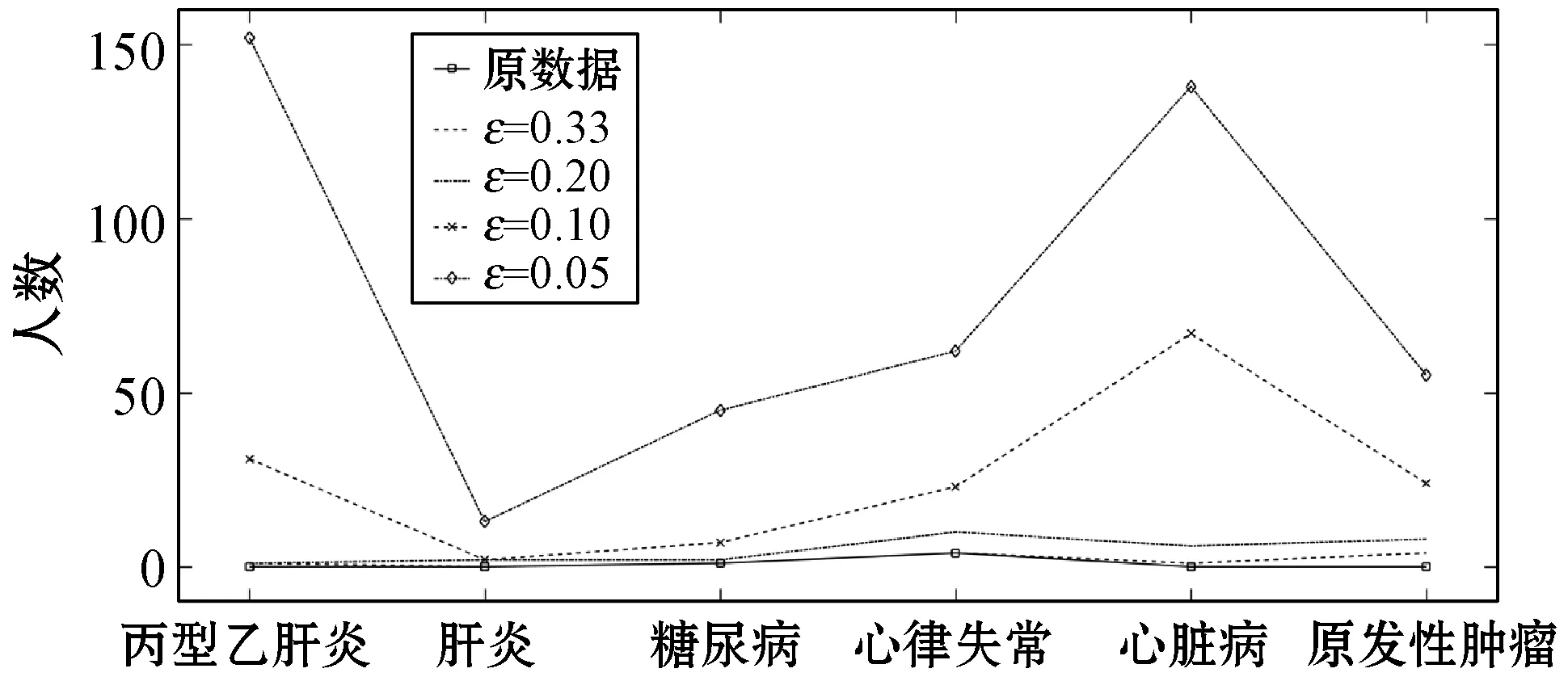
ifθ1≥θand 0.8 處理前后數據相似度很高且數據處理滿足要求 else 數據處理未滿足要求 ε=ε+0.01 Laplace() 針對非數值型數據的指數機制的處理算法如算法2所示,健康醫療數據中非數值型域比較多,在這里以個體性別為例。算法中round()表示取指定位數的小數,random_pick()表示以指定概率從列表中取值。通過δ和θ的判斷來檢驗處理后的數據能否達到處理要求。 算法2指數機制擾動算法 輸入:數據庫中的非數值域gender,ε,δ,θ。 輸出:加入噪聲的gender_d。 1) setsum=0,Δq,ε 3)exponents_list: exponents_list.append(math.exp(expo)) //將各項對應的expo存入exponents_list 4)sum=exponents_list[0]+exponents_list[1] foriinexponents_list 5)some_list=[′female′,′male′] disease_list=dict[disease] 6)gender_d=random_pick(some_list,disease_list) 7) pearson(age,age_d) pearson(BMI,BMI_d) 8)θ1=0 ifδ3>δ 數據處理誤差不符合要求 else θ1=θ1+1 ifθ1≥θand 0.8 處理前后數據相似度很高且數據處理滿足要求 else 數據處理未滿足要求 ε=ε+0.01 Exponential() 對數據進行加噪處理后,再利用常用對稱加密算法,比如AES對加噪數據加密,密文數據就可以發布。而用戶要想利用這些發布的數據,仍然要從數據持有者得到授權才可以得到密文數據并解密數據進行分析,對密文數據的授權不是本文的研究重點,利用已有的數據授權方法即可。 實驗部分我們在64位Windows 10操作系統個人電腦上使用MATLAB R2016b軟件進行了數值模擬,個人電腦具有16 GB的隨機存取存儲器(RAM)和2.20 GHz的Intel Core i7- 6650U CPU。數據為存儲在MySQL數據庫中的11 640條健康醫療數據記錄(數據集來源: (1) https://archive.ics.uci.edu/ml/index.php; (2) https://github.com/susanli2016/Machine-Learning-with-Python數據量為4 019條)。同時根據不同的數據我們測試了不同的隱私保護參數ε取值對于數據安全性和可用性的差別。在實驗中為能夠細致地保障數據處理后可用性和安全性,將隱私保護參數ε的變化幅度分別進行設置。因非數值型分組只有男性和女性兩種,組中數據量相較于數值型較多,在ε數值較小時統計后的數據差異較小,因此將對非數值型數據隱私保護參數變化幅度設置為0.001(指數機制),在數值型數據分組中,因分組較多,每個分組中的部分數據量會較小,在參數ε設置較小的情況下會出現數據波動很大而導致數據可用性不高,所以將數值型數據的隱私保護參數變化幅度設置為0.01(Laplace機制)。實驗中ε的初始值設定為中間量0.5,依次根據調整幅度進行測試以找到安全性與可用性的一個平衡。再根據進行實驗的數據分析將實驗中誤差參數δ設為20%,數值型和非數值型數據根據不同區間劃分后的統計個數分別為30、12,因分組后部分組內數據較少,在進行數據處理時數據波動情況相較于其他分組較大,故而將滿足誤差的統計個數θ分別設置為20、10以保證數據的可用性較好。數據發布者可以根據對于不同數據的不同需求對ε、δ、θ進行設定和處理來達到對于不同數據使用者的數據隱私保護通用性。 根據性別分類在ε=0.005, 0.004, 0.003與0.002時的加噪前后的疾病統計分布如圖3表示。分別在性別為男與女情況下采用不同ε時的數據加噪前后的疾病統計分布,經過多次實驗測試發現與年齡數據處理不同的是當ε=0.005時,我們得到的擾動后的數據統計結果與原始數據的統計結果十分相近,而當ε=0.002時,其統計結果誤差非常大。 (a) 男性 (b) 女性圖3 按性別在不同ε取值下加噪前后的疾病統計分布 根據BMI數據在ε=0.36, 0.3, 0.2與0.1時的加噪前后的疾病統計分布如圖4所示,分別統計在BMI<18.5,BMI取值為18.5~23.9、24.0~26.9、27.0~29.9,以及BMI≥30的不同條件下數據加噪前后的疾病統計分析結果分布。 (a) BMI小于18.5 (b) BMI介于18.5~23.9 (c) BMI介于24.0~26.9 (d) BMI介于27.0~29.9 (e) BMI大于30圖4 BMI在不同ε取值下加噪前后的疾病統計分布 在實驗對比測試中發現當ε=0.36時統計結果與原始數據統計結果逼近且數據的安全性也得到了保障,當ε=0.1時統計結果的波動十分明顯,尤其是在BMI小于18.5的數據上非常明顯。原因可能是因為小于18.5的統計數據量過少而添加的噪聲過大。 根據年齡數據在ε=0.33, 0.2, 0.1與0.05時的加噪前后的疾病統計分布如圖5所示,分別統計在年齡小于20歲、年齡在20~39歲、40~59歲、60~79歲,以及年齡大于80歲的不同條件下數據加噪前后的疾病統計分析結果分布。 (a) 年齡小于20 (b) 年齡介于20~39 (c) 年齡介于40~59 (d) 年齡介于60~79 (e) 年齡大于等于80圖5 年齡在不同ε取值下加噪前后的疾病統計分布 可以看出,當ε=0.33時統計結果與原始數據統計結果相近,當ε=0.05時數據的統計結果波動較大,尤其當年齡小于20歲和大于80歲時,疾病的數據差異非常明顯,統計誤差較大,原因可能與原始數據統計量較小和添加的噪聲過大有關。 按差分隱私的定義,當ε取值越小對原數據所添加的噪聲值越大,數據的安全性越高,但可用性會降低。實驗中我們研究了不同的隱私保護參數ε的取值對于統計結果的影響程度,通過圖3-圖5的對比實驗發現在按性別分類統計時ε取值為0.005時、在按BMI分類統計時ε取值為0.36時、在按年齡分類統計時ε取值為0.33時加噪后的數據誤差較小,故而安全性和可用性相對較好。 本節對以上方案的時間開銷進行對比,按性別、BMI、年齡不同屬性進行差分隱私保護時的時間開銷如圖6所示。其中:斜線填充表示性別數據為不同ε取值時的時間開銷,最大時間開銷是7.858 s,最小時間開銷是7.835 s;深灰填充表示BMI數據為不同ε取值時的時間開銷,最大時間開銷是0.299 s,最小時間開銷是0.296 s;白色填充表示年齡數據為不同ε取值時的時間開銷,最大時間開銷是0.305 s,最小時間開銷是0.290 s。因為對隱私保護參數的取值和采用的加噪機制不同,時間開銷也有所不同,但從實驗數據可以看出,不同隱私保護參數取值時的時間開銷差異比較小。 圖6 性別、BMI、年齡不同屬性在不同ε取值時的時間開銷 本文提出一種基于差分隱私的可根據不同隱私保護需求進行不同參數設定的健康醫療數據隱私保護方法,該種方法的優點在于相較于傳統的隱私保護方法,在當攻擊者擁有強大背景知識的情況下差分隱私依舊能夠有效地保護隱私信息,同時它嚴謹的統計學模型對隱私保護強度進行量化,從而可以較好地在隱私保護強度與可用性之間進行權衡。我們通過針對不同類型的數據使用不同的差分隱私機制對其進行加噪處理,同時根據數據類型的不同選取控制隱私保護參數ε的取值使得數據在可用性和安全性上取得一個相對的平衡,控制誤差參數δ和滿足誤差的統計個數θ的取值以保證數據的可用性和安全性更進一步依據處理需求的得到平衡。在數據采取不同的機制進行差分隱私處理之后,數據擁有者可把處理后的數據發布給數據使用者用于數據挖掘相關的分析研究。通過實驗分析發現,在誤差參數δ和數值型與非數值型數據滿足誤差的統計個數θ的取值分別為20%、20和10的要求下,對于年齡字段的ε取值為0.33,對于BMI字段ε的取值為0.36,對于性別字段ε的取值為0.005時,在數據的可用性和安全性上有個相對好的平衡。該方法改變對原始數據的擾動程度進而平衡數據的可用性和安全性,使得發布后的醫療數據在仍舊保留整體信息可研究性的前提下保護數據擁有者的隱私。未來的研究工作將探究健康醫療數據共享時動態數據的隱私保護方法。4 實驗結果與性能分析
4.1 實驗結果





4.2 性能分析

5 結 語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38四川勞動保障(2021年9期)2022-01-18 05:11:08中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24文苑(2018年21期)2018-11-09 01:23:06中國衛生(2016年9期)2016-11-12 13:28:08光學精密工程(2016年6期)2016-11-07 09:07:19中國衛生(2015年9期)2015-11-10 03:11:12核科學與工程(2015年4期)2015-09-26 11:59:03中國衛生(2014年3期)2014-11-12 13:18:12
