基于CPD算法與筆段權重的楷體字筆畫提取研究
2022-09-06 13:17:12劉相聰李壯峰
計算機應用與軟件 2022年8期
關鍵詞:實驗
劉相聰 李壯峰 姜 杰 李 藝
(南京師范大學教育科學學院 江蘇 南京 210023)
0 引 言
本文關注漢字筆畫骨架提取的問題。以常見漢字圖片為例,所謂筆畫骨架提取,首先要在剝離出漢字整體骨架的基礎上,將每一個筆畫的骨架分解出來并使之與每個筆畫一一對應。所謂骨架,針對漢字圖片而言,一般指漢字筆畫與運筆方向相垂直的切面(線)上的中間點所連成的線,骨架可以保留筆畫的部分形態信息,可以作為判斷漢字是否正確的依據。
已有對于漢字正確與否的自動判斷大部分都是依賴于漢字筆畫信息的,如洪洋[1]提出的基于結構描述的漢字書寫正確性自動化判斷方法,韓青[2]在此基礎上所提出的基于模板匹配的手寫漢字正確性判斷方法,主要通過量化漢字筆畫形態、長度、位置等信息從而進行正確性判斷。Sun等[3]提出一種基于結構的相干點漂移算法進行筆畫的匹配,其核心思想是利用結構信息,將全局點和局部點注冊結合起來,改進原相干點漂移算法(CPD算法)。首先針對給出的兩組點集利用帶局部算子的CPD算法(CPDLO算法)進行對齊,隨后將目標點集分成幾個子集,并將CPDLO算法應用于每個子集,最后執行上述兩個過程,直到收斂。研究者提到由于關鍵點的匹配失敗對于整字結構提取可能造成嚴重影響,簡單地用正確率來評估是不合理的,因此在該研究中采用四個等級計算綜合得分,針對四種實驗字體提取結果進行評估,最終結果顯示該算法明顯優于CPD算法。但是該研究對于映射錯誤的信息沒有提及,提取效果也較難評估,對于提取錯誤的修正也未提及。Lin等[4]首先提取出漢字的骨架,根據一定的規則找出漢字筆畫的端點、連接點和分叉點,然后根據每個分叉點所連接的筆畫方向建立一個筆畫關系圖,應用一個雙向連接規則進行筆畫提取。該方法的原理是以分叉點為界,對筆段進行拆分與組合,不能處理類似“口”這樣封閉的、不存在三叉點的筆畫拆分。該方法對工整簡單字體的筆畫提取效果較好,研究中采用了10個學生書寫的共3 039個漢字進行實驗,將錯誤種類分為三類,其中結構性錯誤有127個漢字,三叉點不能識別錯誤有24個漢字,斷裂錯誤有31個漢字,共識別錯誤182個漢字,提取成功率為94%。但是由于該方法無法識別三叉點,因此對于復雜漢字以及不同字體的筆畫提取還有待研究和推進。
本文基于漢字骨架結合一致點漂移算法(CPD 算法)與關鍵點筆段的劃分等方法,提出一種基于骨架的硬筆漢字的筆畫提取方法。要提取漢字筆畫,必須確定筆畫提取的字集。本文首先獲取合理的實驗圖片字集,對其進行降噪、二值化等優化后提取出映射所需要的漢字骨架;毛刺是漢字骨架中常見的問題,因此本文繼續優化漢字骨架,去除骨架中的毛刺;進行CPD映射需要模板點集與數據點集兩組樣本。明確模板點集的選擇后將兩組點集輸入CPD算法進行映射,這種簡單的映射結果并不理想;分析原因后,進一步提出基于筆段權重的優化提取方案。最終分析筆畫提取的實驗結果,總結得出本算法提取效率優于CPD算法,能夠有效提取大部分硬筆漢字筆畫。本文算法主要思路如圖1所示。

圖1 筆畫提取邏輯
1 實驗字集獲取與圖像預處理
1.1 實驗字集獲取
本文提出筆畫提取算法后進行實驗驗證,合理選取實驗字集、高效獲取高質量字集圖片是十分重要的。本文對于三種字體進行了映射實驗,由于采取了楷體字為模板,此處將主要以楷體字為例進行闡述。
1.1.1實驗字集選擇
在進行筆畫提取之前,需要一個實驗字集來評估筆畫提取的成功率,實驗字集選取的合理性決定了對于筆畫提取成功率評估的有效性。實驗字集的合理性應當包含以下兩個方面:
(1) 實驗字體最好是筆畫較細的字體。筆畫細的情況下,提取到的漢字骨架質量更高,毛刺較短,容易去除,便于突出關注本研究工作的重點。
(2) 選擇的實驗字集應當盡量包含所有的漢字筆畫和漢字結構;漢字筆畫數應該由少到多;適當覆蓋不同字體,如此使實驗結果更具普遍意義。
根據以上要求,本研究選取了40個字的實驗字集及26個備用漢字,涵蓋了28種基本筆畫,9種漢字結構。備用漢字主要是為了避免實驗字集圖像預處理效果較差時以作替換使用,本研究中并未出現此種情況;部分備用漢字結構較為清晰,作為研究圖片具有較好的表現特征,其中部分研究圖像來源于備用漢字的實驗過程。將這40個實驗漢字列入表1。

表1 實驗字集選擇

續表1
由于漢字使用中左右結構與上下結構漢字較多,因此字集中選取左右結構與上下結構的漢字較多。本文將字集按照筆畫數量和結構復雜程度分為三個數量相似部分,方便在后續實驗中對比統計實驗結果。
(1) 漢字筆畫0~5畫且結構簡單為簡單漢字,共有12個漢字:卜、乃、女、隊、風、六、內、專、打、饑、甩、四。
(2) 漢字筆畫6~10畫且結構復雜程度中等為一般漢字,共有15個漢字:級、設、眾、還、國、果、畫、昏、彪、樹、思、彎、高、競、圓。
(3) 漢字筆畫11畫及以上且結構較為復雜的為復雜漢字,共有13個漢字:淋、爽、斌、鼎、猴、晶、森、媛、鵪、熬、癌、翼、靄。
這樣做是由于CPD算法是一種空間分布概率上的統計,當漢字字形更為復雜時,空間點集密度的上升,本文猜測漢字字形的復雜程度會對映射結果或許會造成一定的影響,通過對三個復雜程度漢字實驗結果的統計對比,能夠體現出字形的復雜程度與筆畫提取成功率是否存在著一定聯系。
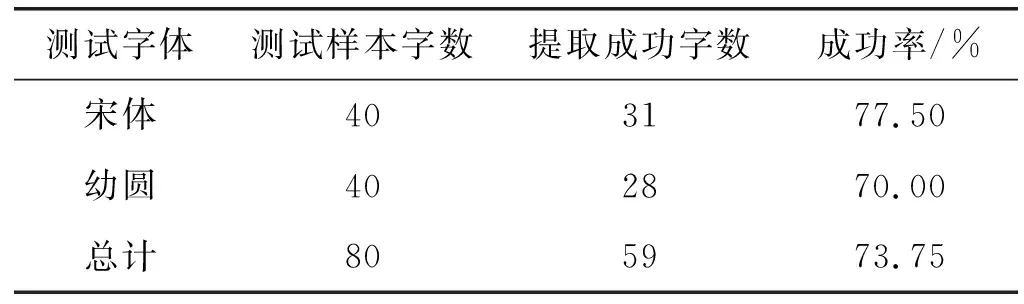
為了使實驗字集更具普遍性,本文在楷體字的基礎上還選擇了其余兩種較為常見且漢字形態差異較大的字體宋體、幼圓進行實驗,這三種字體采用計算機常用字庫中的楷體、宋體、幼圓體。三種字體筆畫較細、筆畫形態結構清晰、各自風格明顯,有助于結果的統計分析,如圖2所示。本文將主要以楷體為例進行闡述。

圖2 楷體、宋體與幼圓的“靄”字
1.1.2實驗環境與數據獲取
本文主要通過脫機方式獲取形態規范的硬筆漢字字集:脫機在本研究中是指通過圖片的方式采集規范硬筆漢字的所有信息,規范符合國家漢字規范要求,并形態清晰、筆畫分明的漢字。
本研究對設備并無特殊要求,主要使用了搭載Windows 10系統的離線計算機為實驗設備,基于eclipse使用Java進行算法編寫。
本研究將目標聚焦于基于漢字骨架的筆畫提取工作,為了獲取高質量的實驗字集,本研究中在系統中添加所需字體后,利用Photoshop CC統一生成400×400像素且分辨率為96 dpi的黑白漢字圖片。這樣生成的圖片盡可能地避免了圖像品質、光照等無關因素對于映射造成的影響。本研究中共生成了楷體、宋體、幼圓三種字體的漢字,漢字大小都為60點,每個漢字生成為獨立的JPG文件。
1.2 圖像預處理
盡管通過軟件生成了高質量的黑白圖片,但是由于研究最終需要的是漢字骨架圖片,因此還需要對字集進行處理使其達到實驗要求。
1.2.1圖像二值化
盡管實驗生成了高質量的黑白圖片,但是由于像素變動和存儲形式等還不能直接進行使用。為了方便數據處理,將點集信息存在二維數組中,0代表白色,1代表黑色。本研究采用區域動態灰度閾值法[5]進行圖片的二值化。首先將圖片進行分區,每個區域所設定灰度值閾值,該區域內大于該閾值的點設為黑色,反之設為白色。在圖片質量難以控制時,該方法二值化成功率較高。
本研究中采用了資源質量較高的黑白圖片,因此二值化過程較為簡單,肉眼幾乎難以看出差別。但是圖片若不經過二值化可能會產生點集丟失的情況,因此進行二值化操作是必要的。圖3中左邊為二值化之前漢字筆畫圖片,右邊為二值化后效果圖,邊界較為模糊處二值化效果較為明顯。

圖3 二值化效果對比圖
1.2.2整字骨架提取
漢字的骨架中包含了進行筆畫提取與漢字正確性判斷所需要的必要信息,且其形態簡單,便于計算機處理。通過骨架點集與模板點集進行映射從而提取到漢字的筆畫信息。硬筆書法作品單字圖像骨架一般是對字形的細化,現有的細化算法已經非常成熟,本研究使用了常用且效果比較好的索引表法[6]。
本研究中采用的字集圖片筆畫較細、圖片質量較高、筆畫清晰,因此細化效果較好,圖4所示為漢字細化效果圖。

圖4 “靄”字細化效果
與圖片質量無關的是細化算法由于自身的問題會產生許多毛刺:楷體字筆畫較為圓潤,產生毛刺較少,但在頓筆處不可避免地產生了少量毛刺,盡管楷體細化中毛刺產生較少,但是毛刺的存在仍舊會對映射造成影響。
1.2.3去除毛刺
在硬筆漢字字體中,漢字筆畫較細,所以不會生成特別長的毛刺導致混淆筆畫的整體形態。短毛刺只需要使用閾值法[7-8]進行去除。硬筆漢字毛刺較短一般不會大于筆畫寬度,因此可以對閾值法進行改進,根據筆畫的寬度設置一個閾值,小于該閾值的毛刺進行剔除。細化過程產生的毛刺遠小于最短筆畫長度,因此將閾值擴大為1.5倍筆畫寬度。
此處需要說明的是:本次實驗中三種字體細化產生的毛刺現象各有不同,其中幼圓字體在細化后因為筆畫圓滑且筆畫較細,因此不會產生毛刺,不需要進行去除毛刺;楷體細化會產生少量毛刺;宋體毛刺較為嚴重,后兩種需要進行去除毛刺。實驗字集中“淋”“專”“級”三個字毛刺去除不徹底,毛刺去除成功率為92.5%,“鵪”“畫”二字因字形或筆畫粘連問題會有細微畸變,但是可以認定去除成功,如圖5所示。
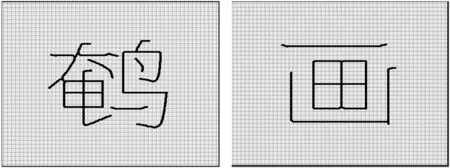
圖5 細化后細微畸形的漢字骨架去除毛刺
圖6所示為楷體“靄”字去除毛刺的效果。至此實驗字集處理完成,基本達到了繼續推進工作的預期效果,后續即進行筆畫提取。

圖6 “靄”字去除毛刺效果
2 基于骨架點集映射與筆段權重的筆畫提取
2.1 骨架點集與模板點集映射
點集映射是圖形圖像學領域所研究的問題,其中的點匹配問題是當前研究的一個熱點。點集映射就是對兩組具有空間位置相關性的點集A和B,求二者的映射關系,使樣本點集與模板點集在映射之后能夠建立起對應關系,從而獲得對樣本點集的認識。本研究中骨架點集與模板點集的匹配與對應就屬于點匹配的問題,通過將骨架點集與標準漢字骨架模板點集建立一一對應的關系,從而確定骨架點集中的點屬于哪一筆畫。一致性點漂移算法(CPD 算法)[9]是點集配準的主要算法。通過給定一個模板點集在另一個相關點集中尋找對應的點。若將這種對應關系用概率來進行描述,就能夠獲得一個較為合適的點集配準結果。因此本文使用一個概率值來描述這個對應關系:對應關系愈強的點對應概率越接近于1,反之則接近于0。當問題涉及到概率時,必須對于概率模型進行選擇:如果針對一個點與一個點的對應關系,可以使用正態分布(高斯分布)來描述,那個當存在多個點時,恰好可以使用混合高斯模型(Gaussian Mixture Model,GMM)來進行描述。CPD算法正是采用GMM來求解這個關系。
2.1.1點集匹配優化與現存方法的不足
由上文可知,模板點集與數據點集的映射是一種位置上的概率關系,如果數據點集的位置確定,這種映射就是確定的。由于漢字筆畫具有的連續性,某一段筆畫點集的映射后筆畫歸屬基本相同,因此我們可以通過減少部分同類點的映射從而提升算法效率。通過等距去點的方法,本文每隔三個點取一個數據點,這樣不會改變筆畫形態而且進行映射的數據點數量變為原始點集的1/4,從而大幅度提升算法的執行效率。[5]
盡管優化后映射速度能夠提升,由于漢字形態不同引起的點集數量不同、交接或臨近處點集位置相近等原因,CPD算法會有較多失準的情況出現。且漢字是有字體之分的,不同字體形態略有不同。一方面,即使待映射樣本和模板為同樣字體,映射效果也未能盡如人意,若為不同字體,直觀上看,效果應該更差。即輸入不同字體樣本點集與輸入同種字體模板點集時,由于形態的相異或相近,兩種映射效果的差異就會較大。文獻[10]提出的面向矢量字形的漢字筆畫自動提取方法中,將數據點集、模板點集以及模板點集的筆畫歸屬關系輸入優化后的CPD算法獲取數據點集的筆畫歸屬關系,隨后對于字形輪廓進行閉合。在該方法中對于CPD算法做了局部優化來提升映射效果,但是并未提及映射失準時如何進一步處理。本文在點集映射中只輸入模板點集與樣本點集,在映射結束后再賦予數據點集筆畫歸屬關系,從而在映射失準時更加方便進行修正。
2.1.2模板點集獲得與基于CPD的直接映射
根據CPD算法的原理可以知道,要進行實驗字集的筆畫提取,首先需要一套模板字集進行映射。本文采用了書法家在電子設備上書寫的楷體漢字作為映射的模板,書寫完成的模板字以可擴展標記語言(XML:Extensible Markup Language)的形式進行存儲,該文件中包含了漢字筆畫的筆畫歸屬、點集坐標及時間信息。[11]重點是,模板是待提取筆畫骨架與該漢字筆畫建立一一對應關系的依據。在映射過程中,起作用的是模板字的點集坐標與點集的筆畫歸屬信息,因此本文只讀取模板字的點集坐標與筆畫歸屬進行儲存,以備研究使用。
一般而言,映射后便可獲得樣本點集與模板點集間的對應關系,邏輯上可以將模板點集的筆畫歸屬賦予與其對應的樣本數據點,從而使每個數據點獲得筆畫歸屬。如圖7的局部放大圖所示,圖中A、B兩點已經形成了映射關系,這時將模板點A的筆畫歸屬賦予B點,使得數據點B獲得與A相同的筆畫歸屬。
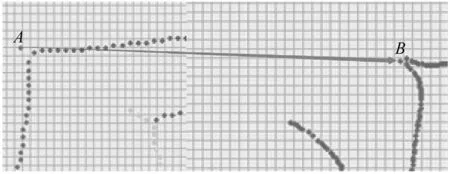
圖7 映射局部放大圖
本文使用了CPD算法直接進行映射,表2展示了三種字體的映射結果。

表2 CPD算法映射結果
根據統計結果可以看出,直接使用CPD算法進行映射的成功率偏低,即使形態相近的楷體字也會有點集映射關系發生漂移。圖8為直接使用CPD算法映射后所出現問題的效果圖。

圖8 “饑”字映射結果
可以看到由于CPD算法本身的問題,小部分點集映射失準的問題較為常見,如圖8中“饑”字所示:筆畫映射后點集有輕微漂移,映射錯誤點數較少。盡管只在一個筆畫段中占很小的一部分,但是提取的筆畫依舊沒有實際意義。總結部分實驗數據后發現,映射結果中往往是有小部分點集映射失準,但是一個筆畫段大部分的點集匹配是正確的。正如上文所提到的,本文映射后再賦予的筆畫歸屬具有一定的修正空間。從而進一步采用了權重的思想,采用筆段中映射頻率最高的點作為當前筆段的筆畫代碼能夠有效糾偏,這種思想認為一個筆畫段中所占比重比例最高的點所對應的筆畫也應當是本段所對應的筆畫。獲取到本筆畫段的歸屬信息后,將本段中所有的點集歸屬進行修正,使其對應正確的筆畫。這種基于筆段中數據點權重的修正方式首先需要進行筆段劃分,下文將介紹本研究中映射與筆段權重結合的方法。
2.2 映射結果與筆段權重結合
映射與筆段權重結合核心思想是,在一個筆段中,每個點對應了一個筆畫,大部分的點映射正確,對應了正確的筆畫;尋找這個筆段中映射為相同筆畫最多點的筆畫歸屬作為本筆段所有點的對應筆畫,將其他小部分點的對應筆畫全部修正為本筆段中占權重最高的點所對應的筆畫。部分方法如下:
for (int j=0; j num=partList.get(i).get(j).num; pointnum[Qsort[CPDpart[num]] - 1]++; } 此處主要是為了將映射后的點集與筆畫對應關系進行轉存,獲取到點與筆畫對應清晰的邏輯關系,其中partList中存儲了筆段信息,pointnum[i]中存儲了每個筆段中筆畫編碼為i的點集數量。 for (int k=0; k if (pointnum[k]>max) { max=pointnum[k]; maxStroke[i]=k;} } 在獲取到每個點映射到的筆畫后,接下來需要找出當前筆段中筆畫出現頻率最高的筆畫代碼進行存儲,將其存儲于maxStroke[]。 將合成算法主要邏輯概述如下: (1) 讀取筆畫段; (2) 記錄該筆段中筆畫歸屬不同的點的數量; (3) 選取對應關系最多的筆畫作為本段的正確筆畫; (4) 將錯誤的對應關系修正為當前筆段對應的筆畫; (5) 遍歷所有筆畫段,重復執行以上操作。 經過以上的邏輯,能夠將所有筆段內的點集按照權重進行歸一,獲取更加有效的映射結果。 筆段劃分是指在已經獲取筆畫骨架的基礎之上,對漢字骨架按照端點、交點和接點為界限進行分段。[5]進行筆段劃分的目的是為了更好地優化漢字骨架點集與模板點集進行映射后的結果。此處分段方法主要依據八臨域是否存在相鄰像素點,當中心點的八臨域中存在像素點,我們就可以認為它是連續的筆畫。再通過關鍵點將其分段,就能夠得到筆段。在研究初期采用交接點與端點為關鍵點進行筆段的劃分,方法如下: 2.3.1獲取關鍵點 對于漢字骨架點集進行遍歷,獲取端點、交點、接點三種類型的關鍵點同時將八臨域內點的數量進行標記。關鍵點分別具有以下特征:端點八臨域內只存在一個黑色像素點(標記為1的點);交接點八臨域內黑色像素點為3~4個。而其余普通點八臨域內均存在2個黑色像素點,因此將普通點標記為2,交接點標記為3或4。最后將獲取到的關鍵點存儲于隊列List中。 2.3.2依據關鍵點分段 從List隊列中取出第一個關鍵點,以取出的點為中心點,按照順時針順序掃描該點的八臨域,將其八臨域內遇到的第一個未讀取過的普通點A作為蔓延方向,將其存入筆段數據結構Part中,將該普通點A標記為已讀。再將點A作為中心點,掃描其八臨域內下一個普通點。 其中主要涉及了對關鍵點的標識,利用不同的標識判斷關鍵點的種類,并驗證是否能夠遍歷: while (null !=(tempoint=FindNext(arrcopy, m, n))) { if(Check2Go(arrcopy, tempoint.x, tempoint.y)) { part.add(tempoint); arrcopy[tempoint.x][tempoint.y]=5;} } 其中FindNext()方法用以查找一個可遍歷的方向點,Check2Go檢查是否為新遍歷點,若是則加入筆段part,并將其標記。如此循環往復,直到遇到下一個關鍵點時,即可認定獲取了一個筆段Part,將這個筆段存入數據結構筆段組Parts中。 2.3.3完成分段 遍歷關鍵點隊列中所有的點,重復2.3.2節中一步分段的過程,將所有關鍵點讀取完成,此時筆段組Parts中存放了該漢字中所有的筆畫段信息。此時硬筆字骨架分段已經完成。將不同段進行標記顯示,所得到的結果如圖9所示。 圖9 “代”字分段結果 2.3.4第一次分段映射結果 在實驗中發現,運用以上分段的方法能夠解決一部分的分段問題,并成功結合映射,但是依然有許多筆畫段無法劃分,從而導致映射結果結合筆畫段后筆畫提取錯誤。表3展示了利用交叉點分段后進行實驗的結果。 表3 第一次分段后提取結果 通過實驗數據可以發現,筆畫提取的成功率相較于CPD算法直接映射的結果有了一定的提升,提取成功率相對較高,基本可以面向應用。但是分段中有一類問題較為突出,由于部分筆畫相對圓滑且連貫,不具備分叉等特性,因此無法被識別,從而導致了無法分段,嚴重的還會影響最終的提取結果。圖10所示為無法分段的示例與其導致的映射錯誤。 圖10 “饑”字分段與映射結果 可以看到圖中由于分段不徹底的原因,右邊幾字兩筆被識別為一筆。在漢字中由于某些字字形圓滑,筆畫沒有較剛性的拐點,所以僅僅依賴分叉點與始末點無法分段,導致提取錯誤。由此可見分段算法并不完善。通過觀察發現,這些未能分段的筆畫大部分在拐點處未能識別。在之前研究關鍵點的思路上,本文加入了拐點的判斷與分割來完善分段算法。 2.4.1最大距離法求拐點 上文提出的筆段劃分方法針對棱角分明、具有交接點的字體適應性較好,但是針對部分交接點或端點不突出的漢字字體適應性較差。通過觀察總結發現,針對拐點的位置進行分段,可以解決第一次分段中產生的問題。通過拐點進行劃分筆段,其中一個代表性的方法是最大距離法提取拐點[12]。其思路是:對于存在一個拐點的筆畫,連接該筆畫的起點和終點作為直線,尋找本筆畫上距離該直線距離最遠的一個點,該點作為此筆畫的拐點 。但是該方法存在一定問題:(1) 對于輕微變向的筆畫識別敏感,對部分不需要分段的筆畫進行分段;(2) 只能處理單拐點筆劃,不能處理多拐點筆劃,也不能判斷筆劃上拐點的個數。 2.4.2拐點分段優化 針對前文提到的最大距離法求拐點所存在的問題,本文對最大距離設定一個閾值,當拐點到筆畫起末點連線的距離大于該閾值再進行筆段劃分。同時優化最大距離法算法,輸入所有分段后,檢測并對于存在多個拐點的筆段進行迭代分割,直到該筆段中檢測不到拐點,其核心過程在于檢測最大距離點:partList中存儲了某筆段中所有點集,dth為設定閾值,ds為當前點與遍歷起點之間的距離,maxPdis與maxp分別存儲了最大距離與最大距離點,當檢測到最大距離點時進行賦值或者更新最大距離點。 for (int j=0; j p=partList.get(i).get(j); double ds=Math.abs(a*p.x+b*p.y+c)/Math.sqrt(a*a+b*b); if (ds>dth) { if(maxPdis==0){ maxp=partList.get(i).get(j); maxPdis=ds;} else if(ds>maxPdis){ maxp=partList.get(i).get(j); maxPdis=ds;} }} 識別到最大距離點后,對于第一次分段結果進行二次分段: for (int n=0; n if(partList.get(m).get(n) != maxp){ part.add(partList.get(m).get(n));} else{ part.add(partList.get(m).get(n)); if (part.size() != 0){ tempPartList.add(part); part=new ArrayList } } 以最大距離點為分界點,前半部分將相同的點復制存儲,在拐點出進行分割,剩下的點作為一段新段。在所有分段結束后,遞歸調用自身,重新檢測是否需要再次分段。 可以將算法邏輯簡要概述如下: (1) 將第一次關鍵點分段結果Parts[]輸入第二次拐點分段算法。 (2) 獲取第一個筆段Part進行遍歷,使用最大距離法判斷是否存在拐點,并記錄最大距離點P。 (3) 若最大距離大于閾值,則認為該筆畫中存在拐點,以最大距離點進行筆段分割。 (4) 將P點前后進行分段,將這兩段存入臨時分段組TempParts[]。 (5) 將臨時分段組TempParts[]再次輸入二次分段算法,進行檢測分段。 (6) 直到所有筆段中不再存在拐點,將最終的臨時分段組返回原程序,獲取拐點分段結果。 (7) 將筆段組Parts[]中所有分段二次分段結果進行合并,重新存入筆段組Parts[]。 該優化后方法能夠有效識別第一次交叉點分段后未能分段的筆畫,最大距離法中的閾值的設定與具體分段結果相關,當遇到拐點不明顯的字體時可以適當降低閾值設定,盡可能多進行分段。由于映射結果與筆段進行結合,因此對于部分筆段劃分寬容度相對較高,閾值設定相對靈活,部分漢字可能會多分割出1到2段,對于最終映射結果基本沒有影響。實際分段結果如圖11所示。 圖11 “昏”字二次分段效果 為驗證本文算法的有效性,對選取的楷體字集進行一系列實驗。根據漢字的結構,筆畫的覆蓋度,漢字的復雜程度等因素選取了40個字的實驗漢字字集。采用同一種專家書寫的楷體字作為映射的模板字集。對于筆畫提取成功的標準設定為:實驗字中的每個筆畫都能夠形態清晰地與其他筆畫進行分辨。根據設定的標準對漢字筆畫進行提取,結果統計如表4所示。 表4 楷體脫機筆畫提取結果 由結果可知,40個樣本字中,成功提取39個,成功率達97.5%。與之前兩次實驗結果進行對比發現算法成功率提升明顯,基本能夠達到實驗預期。對于提取錯誤原因的統計如表5所示。 表5 提取失敗原因統計 結果顯示,筆畫提取失敗的主要原因是映射失敗,而映射失敗的主要原因為字體形態有所差異,空間位置分布不定等原因。分析結果發現,楷體字的成功率較高,此處猜測是由于使用了楷體模板字進行映射楷體字時成功率會相對較高,為驗證該猜想,接著采用了三種形態有所差異楷體字測試進一步驗證猜測。 經過分析以上的實驗結果,本文猜測可能因為模板字是楷體字的原因,楷體字的提取成功率較高,因此又選取了文鼎特顏楷(顏楷)、方正蘇新詩柳楷簡體(柳楷)、方正北魏楷書(北魏楷書)三種不同風格的楷體字進行實驗,這三種字體形態與計算機常用的楷體有一定差異。如圖12所示,從左到右,從上到下分別為標準楷體、顏楷、柳楷、北魏楷書。 圖12 “靄”字四種楷書效果圖 與之前的實驗采用相同實驗字集與模板字集。實驗結果如表6所示。 表6 三種楷體字提取結果 由結果可知,120個樣本字中,成功提取107個,綜合成功率達89.17%,可以看出本次實驗中對于楷體字的筆畫提取效果較為顯著,一定程度上可以驗證之前的猜想,由于模板字選定為楷體字,因此對于楷體字的提取效果更為顯著。對于提取錯誤原因的統計如表7所示。 表7 提取失敗原因統計 結果顯示,雖然大部分錯誤還是由于映射錯誤導致的,但是分段的問題也有所上升,這是由于選取的三種測試字體相對接近于軟筆模板,筆畫相對較粗,細化分段可能會有細微的問題產生。其中顏真卿體由于筆畫圓潤,風格突出,因此提取錯誤相較于其他兩者更多,但是這并不影響楷體整體提取成功率相對較高的實驗結果。 在此次實驗中發現:柳楷的提取成功率較低,觀察發現其形態與標準的計算機楷體字差異較大。 為了檢驗字形差異對于映射的影響,本文還選擇了宋體、幼圓兩種字體進一步分析其映射結果。結果如表8所示。 表8 脫機筆畫提取結果 可以看出,使用楷體作為映射模板時,其他字體的筆畫提取成功率明顯偏低,不足以面向應用。首先從圖像的來源與字體大小來看,二者均與楷體字實驗中參數相同,因此可以排除圖像質量的原因;其次從字形上來看,宋體字頓筆極多,因而產生的毛刺也較多,去除毛刺后字形顯得相對僵硬,筆畫位置也不盡相似,幼圓筆畫極其圓滑,細化不會產生毛刺,但是字形較為夸張、空間分布較散,與楷體字形相距甚遠,在不明確時序的情況下,分割難度較大。因此二者提取率低主要是由于模板字與實驗字字形差異較大的原因。 漢字具有其特殊性,不同漢字字形差異較大,筆畫數量越多的漢字其筆畫分布也會更加密集,漢字也就更加復雜。由于本算法是基于平面點集位置概率意義上的計算與調整,漢字復雜程度越高,筆畫數量相對應會增加,漢字點集密度也會有所提升,研究者猜測或許在一定程度上會影響映射的結果與分段的效果,為了探究字形復雜程度對于算法的影響,對于前文中提到的不同復雜程度的漢字提取結果進行了統計,觀察實驗結果中成功率,匯總如表9所示。 表9 漢字復雜程度與提取成功占比 結果可見,漢字錯誤樣本總數為35個,其中簡單漢字錯誤6個,成功率為82.9%,一般漢字錯誤15個,成功率57.1%,復雜漢字錯誤14個,成功率60%,由此可知,漢字字形的復雜程度作為單一因素幾乎不對映射造成影響。簡單漢字筆畫較少因此成功率較高,但是一般漢字與復雜漢字字形差異較大,且筆畫數目差異大,錯誤率相似,因此不能認為單純的漢字復雜程度對于映射造成影響。在實際映射中,漢字的復雜度不會對于結果造成決定性影響,但是也會有所作用。 通過分析數據可以總結出,針對楷體字模板進行的楷體字筆畫提取成功率已經能夠達到面向應用的程度,可以進行不同楷體字的筆畫進行提取,對軟筆字體也具有一定的適應性。與此同時研究者發現該算法在針對模板字與待提取字字體不同時,成功率會相應降低,距離面向應用還有發展的空間,尤其是面對字體形態差異較大的字體,復雜漢字的出錯率更高。因此對于不同字體而言,具有較大的提升空間,可以采用不同模板字來提取不同字體的方法來提升算法的成功率。本研究中也還有許多工作亟待改善,例如交畸變修復、毛刺去除等等。 在實際應用中,本研究對于漢字計算的各項研究給出了一定的支持,例如在漢字的正確性判斷中,漢字的筆畫骨架是必要的,圖13展示部分提取效果圖。 圖13 楷體字筆畫提取效果圖(左側為模板,右側為提取效果) 本文提出了一種基于點集匹配與筆段權重的脫機漢字筆畫提取方法,對脫機多種硬筆字體漢字的識別效果有了較大的提高,邏輯簡單易懂,執行速度快,需要一套標準模板字作為標準,筆畫提取的效率較高。但是與此同時,脫機硬筆漢字筆畫提取是一個極具挑戰性的工作,很多方面還亟待完善。要真正達到較高的準確率,點集映射的方法與劃分筆段方法都具有較大的提升空間。2.3 交接端點劃分筆段與映射



2.4 拐點識別與筆段劃分

3 實驗結果
3.1 楷體字筆畫提取結果分析


3.2 不同楷體字實驗提取結果分析



3.3 其他字體筆畫提取實驗分析
3.4 字形復雜程度結果分析

3.5 應用價值與研究前景展望

4 結 語
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00作文·小學低年級(2024年2期)2024-04-29 00:00:00作文·小學低年級(2023年3期)2023-04-29 00:00:00小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42小主人報(2022年4期)2022-08-09 08:52:06中學生數理化·中考版(2022年11期)2022-02-16 07:01:20小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50發明與創新(2016年38期)2016-08-22 03:02:52太空探索(2016年5期)2016-07-12 15:17:55
