農業在線學習資源知識圖譜構建與推薦技術研究
2022-09-06 13:17:00趙繼春孫素芬郭建鑫王洪彪
計算機應用與軟件 2022年8期
趙繼春 孫素芬 郭建鑫 鐘 瑤 王洪彪 王 敏 秦 瑩
(北京市農林科學院 北京 100097)(北京市農村遠程信息服務工程技術研究中心 北京 100097)
0 引 言
信息傳播從文字、聲音、圖像、視頻等單一媒體形式向復合化融合發展,各種信息源之間存在著相互融合的多種形態,內容間存在著一定語義關聯,不同信息從某種角度表達相同的語義。復合信息作為信息檢索和組織研究在計算機科學、圖書情報學等領域得到了高度重視,但如何將這些異構、關聯的信息精確地挖掘并組織建構為知識成為新的挑戰。知識圖譜的出現為復合信息的有效組織和管理應用提供了技術支撐。
知識圖譜(Knowledge Graph)概念最初由Google公司于2012年提出,初衷在于改善搜索引擎效率,使搜索結果智能化[1]。知識圖譜由“實體-關系-實體”、實體及“屬性-值”對組成,實體間通過關聯關系相互結合,構成網狀知識集合,具備從關聯關系的角度分析解決問題的能力[2-3]。近年來,知識圖譜被學術界廣泛關注,通過推理實現概念檢索,從語義方面理解用戶意圖[4],為用戶提供完整、系統和清晰的知識體系結構,從而改進信息化系統服務質量[5]。具有代表性的知識圖譜包括WordNet、OpenCyc、Freebase、DBpedia、YAGO2、Freebase、NELL、Probase[6-9],從大量的數據中抽取、組織、管理信息[10],廣泛應用到智能問答[11]、信息推薦[12]、智能診斷[13]等領域,成為人工智能技術發展的重要推動力。
本文面向農業在線學習領域,首先基于LDA標簽生成的領域知識圖譜構建方法,針對北京市農業網絡在線學習多媒體資源分散雜亂的現狀,研究從學習資源標簽中挖掘潛在主題信息并以此為基礎進行擴展,構建涉農學習資源領域知識圖譜,將分散、無序、海量的信息進行聚合、結構化處理,最終形成關聯的知識體系。在此基礎上,設計開發了基于知識圖譜的協同過濾推薦系統,并通過實驗驗證,提高了學習資源推薦準確率和效率,為知識圖譜構建及其應用研究提供新的視角。
1 相關研究
1.1 領域知識圖譜構建方法
知識圖譜構建主要包含數據提取、信息融合、數據加工和數據更新。數據提取是從大量數據庫及文件中抽取構建知識圖譜的元素,應用技術涉及實體、關系及其概念提取等自然語言處理技術,如馬建紅等[14]提出一種具有反饋機制的聯合模型用以改進實體識別及關系提取的關聯性。信息融合的主要作用是去除實體的歧義及其錯誤表述,確保知識圖譜構建的質量,包含實體鏈接汲取數據合并。趙暢等[15]提出應用候選實體類別、關系及其鄰近實體作為候選實體表示方法,解決數據庫實體描述信息不充分的問題。數據加工是網狀化和結構化知識圖譜構建的重要步驟,包括知識推理及效率評估,如俞揚信[16]提出基于知識推理的信息檢索方法,有效提升數據返回的效率和質量。知識圖譜的實體和關系需要不斷補充與擴展,因此知識圖譜需要持續迭代更新。
知識圖譜構建方法通常有自下而上、自上而下及兩者結合方法。自下而上是從底層數據中抽取實體與關系并逐層向上匯聚概念,自上而下是從最頂層開始定義領域的實體和關系,兩者相結合的方法是先在底層數據抽取基礎上構建模式層,然后對新生成的數據進行梳理并更新模式層,再重新對實體進行填充[17]。自下而上的知識圖譜構建方法速度快,對大量的底層數據支持好,缺點是知識的準確程度不高。自上而下構建方法的概念和關系準確,缺點是需要人為干預工作量大。混合方法靈活性強,但模式層構建難度大。
1.2 知識圖譜與推薦系統相結合
知識圖譜應用于智能推薦系統主要優勢在于能夠對多源異構的信息資源進行整合與提取[18],可以獲得細粒度的用戶與項目之間的特征數據,能夠精確計算用戶與項目的關聯性,從而獲得更加好的推薦效果[19]。知識圖譜具有較好的語義支持,CoLResg[20]構建音樂知識圖譜并應用推薦系統,采用鏈接數據庫方式得到較好的語義信息。王冬青等[21]針對學習者的學習條件差異,結合學習內容知識點、難易程度、用戶學習歷史記錄,構建基于知識圖譜的用戶學習試題推薦系統,為用戶推薦準確的學習內容。王一成等[22]在農業電子商務領域,通過構建多語言商品知識圖譜庫,以多源數據關聯實現電子商務的數據分析和內容推薦。
以上研究表明,將知識圖譜技術運用到個性化推薦系統,在語義支持下可提高推薦系統效率,顯著提升個性化服務水平。目前,在涉農網絡學習領域知識圖譜構建及信息推薦方面的研究還比較少,本文可以為網絡在線個性化學習應用研究提供有益的補充。
2 方法流程
本文提出一種基于LDA標簽生成的領域知識圖譜構建方法,采用機器學習方法為主、人工修正為輔,構建步驟包括實體抽取、關系提取、標簽生成、圖譜遷移、圖譜可視化與維護等步驟,實現過程如圖1所示。

圖1 領域知識圖譜構建流程
(1) 實體抽取。采用N-gram方法對領域資源進行分詞,利用TF-IDF計算關鍵詞與文檔聯系及相應權重。運用機器分類和人工校準相結合,進行標準詞庫實體提取與確認。
(2) 關系提取。通過LSTM神經網絡特征提取模型,減少人工標注句子關系的工作量,能夠得到較好的次序語義支持。
(3) 標簽生成。通過LDA模型和實體間的關聯關系表達資源特征,從全局所有關鍵詞中自動抽取出有概括性的關鍵詞作為標簽。
(4) 圖譜遷移。將通用知識圖譜中實體遷移到領域知識圖譜,并對領域的實體、概念、屬性、關系等關鍵知識識別,從通用知識圖譜中模糊匹配出領域三元組知識。
(5) 圖譜可視化與管理更新。通過軟件工程方法,研發知識圖譜可視化展示與管理更新工具,實現實體、概念、屬性、關系等知識圖譜元素的可視化展示、關聯查詢和更新維護。
3 涉農學習資源領域知識圖譜構建
北京農業在線學習涉農資源內容豐富、形式多樣,包含1.6萬余部視頻、0.5萬余音頻和5萬余條圖文。對于視頻和音頻數據主要提取描述屬性信息,將離散分布的學習素材數據歸一化處理,基于LDA標簽生成的領域知識圖譜構建方法,按照實體抽取、關系提取、標簽生成、圖譜遷移、可視化與維護管理等步驟,最終形成具有屬性的實體和概念并通過關系鏈接成網狀知識圖譜,為智能推薦提供應用支撐。知識圖譜構建框架如圖2所示。

圖2 農業在線學習資源知識圖譜構建框架
3.1 實體提取
首先構建涉農學習資源特征詞庫,結合現有的涉農資源標簽庫,運用人工校準與機器分類相結合,進行標準詞庫的提取與確認。從學習素材信息中提煉主題詞庫,如種植技術、養殖技術、病蟲害防治、休閑農業、鄉村振興等。初期的特征詞庫根據現有的涉農資源類別歸納、總結,再根據關鍵詞解析、標題解析、描述解析、評論解析得到特征詞集,后期隨著解析詞匯增加,特征詞庫集不斷豐富,具體實現步驟如下。
(1) 采用N-gram方法實現分詞(式(1)),為避免將“中央一號文”長詞切分,保證這類長詞能被正確采集,將農業資源特定關鍵詞加入特定詞典再進行分詞。
P(T)=P(W1W2…Wn)=
P(W1)P(W2|W1)P(W3|W1W2)…
P(Wn|W1W2…Wn-1)
(1)
設T由詞序列W1,W2,…,Wn構成,整個句子出現概率為各個詞出現概率之積。
(2) 應用停用詞表去除噪聲關鍵詞,通過條件隨機場對文本詞性標注,提高中文分詞效果準確性。
(3) 利用現有詞庫進行檢驗,去除無意義的詞,如“國辣椒”。
(4) 利用TF-IDF計算關鍵詞與文檔聯系和相應的權重。
(2)

(3)
式中:IDF為逆向文件頻率;|D|為文檔的數量和;|{j:ti∈dj}|為含有關鍵詞ti文檔數量。
TF-IDF=TF×IDF
(4)
式中:TF-IDF為詞頻TF和逆向文件頻率IDF之積。
以文檔學習資源《辣椒春季保護地栽培技術》為例,從文檔中解析出“辣椒、春季、保護地、栽培技術、辣椒、幼苗越冬、大棚管理、施肥、澆水、病蟲害防治、瘡痂病、炭疽病”等實體。
3.2 關系抽取
從文本中提取關系是構建三元組重要部分。傳統的關系抽取需要人工標注大量數據來訓練關系抽取模型,成本太高無法實現大數據量關系抽取。本文通過LSTM(Long Short Term Memory network)神經網絡端到端模型實現實體關系抽取[23],為每個關系獨立訓練雙向LSTM抽取模型(圖3)。采用弱監督標注方法為每個關系自動構造標注數據,模型將文本中的離散詞語映射成特定維度向量,實現層次化向量表達,LSTM引入神經網絡記憶單元概念,某一時刻信息輸出與當前次特征輸入和之前的詞輸出共同決定,有效解決提取序列特征問題,適合句子的詞序語義表示。
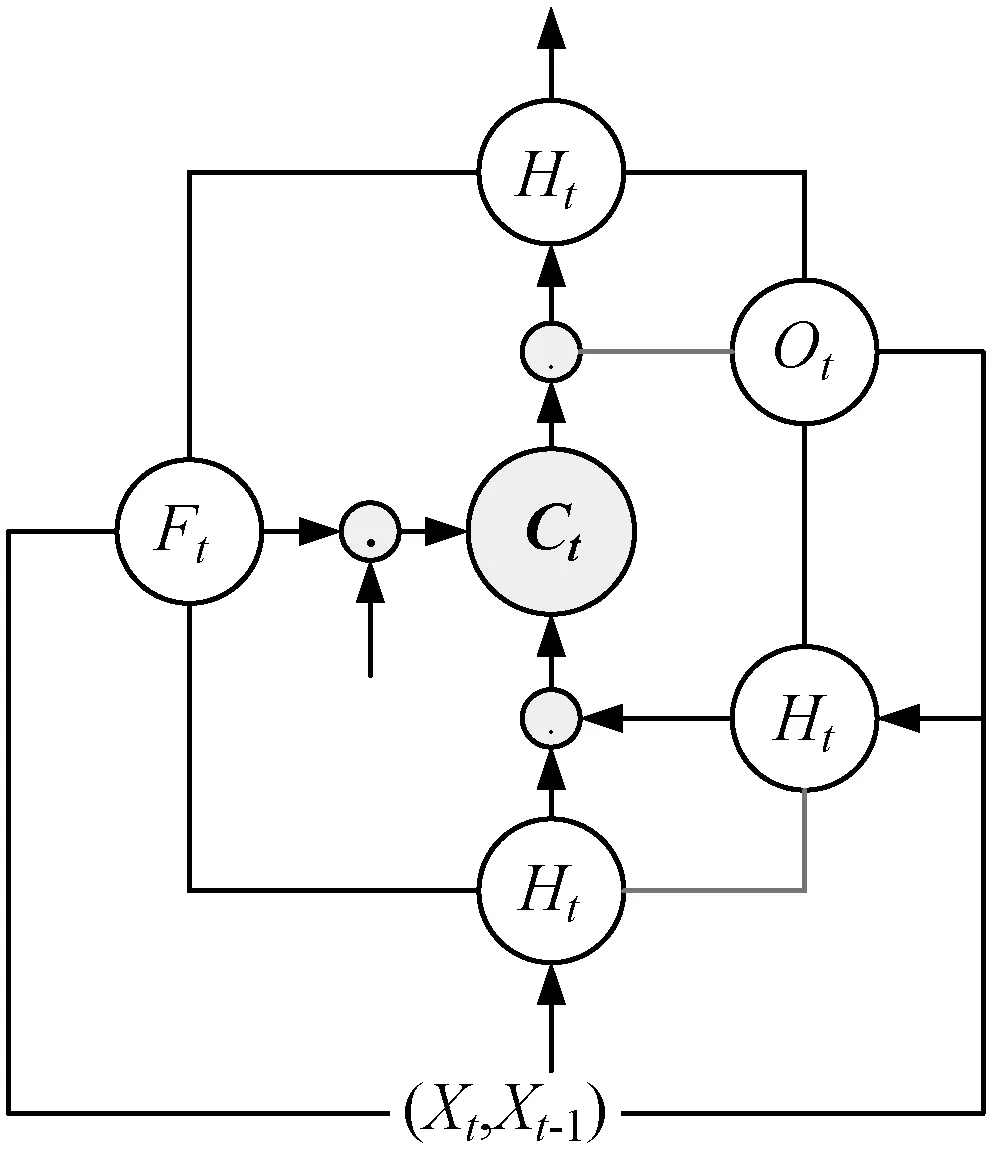
圖3 基于LSTM的端到端抽取模型
結合詞性、句法樹結構等語義特征,構建實體之間關系,通過關系對事件描述有助于分析事件演變過程,關系屬性示例如表1所示。

表1 實體關系屬性示例
3.3 標簽生成
采用LDA(Latent Dirichlet Allocation)模型對學習資源標簽化,將資源庫中的文檔主題以概率分布的形式給出,通過抽取主題分布實現主題聚類和文本分類,同時也是詞袋模型,一篇文檔由一系列詞語組成,詞語之間無先后順序。從全局所有關鍵詞中自動抽取具有概括性的關鍵詞作為標簽,每個標簽下包含一個關鍵詞袋,并且標簽具有層級關系,標簽樹與關鍵詞袋如圖4所示。
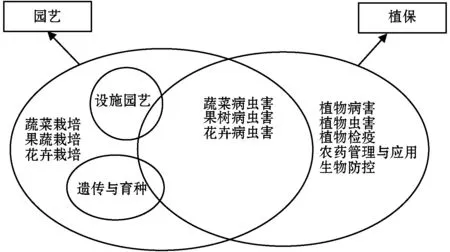
圖4 標簽樹與關鍵詞袋示例
涉農學習資源標簽化本質是一個多標簽文本分類任務,根據語義將學習資源分類到一組預先定義好的類別標簽中并多個維度分析標簽的覆蓋度和精細度,得到有效支撐知識庫的標簽集。通過建標簽鏈接和擴展,實現對標簽集中的每一個標簽映射在知識庫中對應的實體。標簽生成過程中,下層標簽含義上包含上層標簽,每個標簽的關鍵詞袋中所有關鍵詞都可激活該標簽;最底層的標簽能包含所有的文檔。標簽初步生成僅依賴于文檔,文檔數量越多,標簽質量越高,并引入圖譜中的實體補充標簽信息。當涉農學習資源素材發生改變時,系統的關鍵詞也會發生變化。當添加一篇新文檔時,標簽系統自動分析并生成標簽,每個標簽都有一個權重值,僅輸出分數在一定閾值內的標簽。自動生成的標簽可人工干預,提高系統的靈活性。如針對《著力提高國家糧食和物資儲備安全保障水平》資源,提取的標簽和權重為{糧食,0.249 57}、{儲備,0.227 08}、{糧食安全,0.140 81}、{堅持,0.077 38}、{國家,0.076 05}、{物資,0.068 34}、{優糧,0.056 81}。
3.4 圖譜遷移
本文構建的知識圖譜實體與CN-DBPedia關聯,將CN-DBPedia通用知識圖譜中實體遷移到領域知識圖譜,對領域的實體、概念、屬性、關系等關鍵知識進行識別,并以此為標準從通用知識圖譜中模糊匹配出領域三元組知識,實現實體遷移,完善領域知識圖譜內容。知識圖譜儲存采用Mongodb內置的分布式儲存機制,設置一定量的Replica作為備份,具有快速查詢、自動分片、支持云級擴展性、內置MapReduce等優點,適合作為知識圖譜存儲數據庫。
3.5 圖譜可視化與管理
應用Python集成開發環境,研發了涉農領域知識圖譜可視化展示與管理系統,實現實體、概念、屬性、關系等圖譜元素的可視化展示與查詢管理。運用標簽樹展示整個標簽系統,進入實體關系首頁,界面展示畫圓效果如圖5所示。標簽權重可以直觀展示出不同實體之間的關系,實體之間的距離反映實體與標簽間的緊密程度。點擊實體標簽可自動連接到CN-dbpedia的相關頁面(圖6),例如點擊“經濟發展”實體,鏈接到CN-dbpedia的經濟發展實體。

圖5 知識圖譜可視化效果
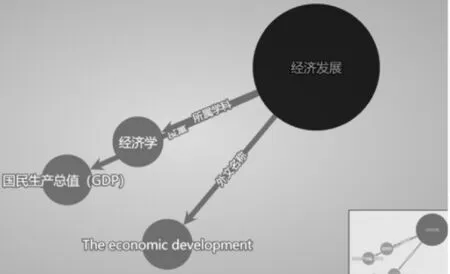
圖6 標簽鏈接到CN-dbpedia的示例
知識圖譜后端管理系統實現了資源素材管理、關鍵詞生成和標簽的處理,具體功能包括:學習資源檢測、生成關鍵詞、關鍵詞解析;修改自動生成標簽以及關鍵詞權重、屬性、關聯關系等;支持自動添加關鍵詞、關聯關系。管理界面如圖7所示。
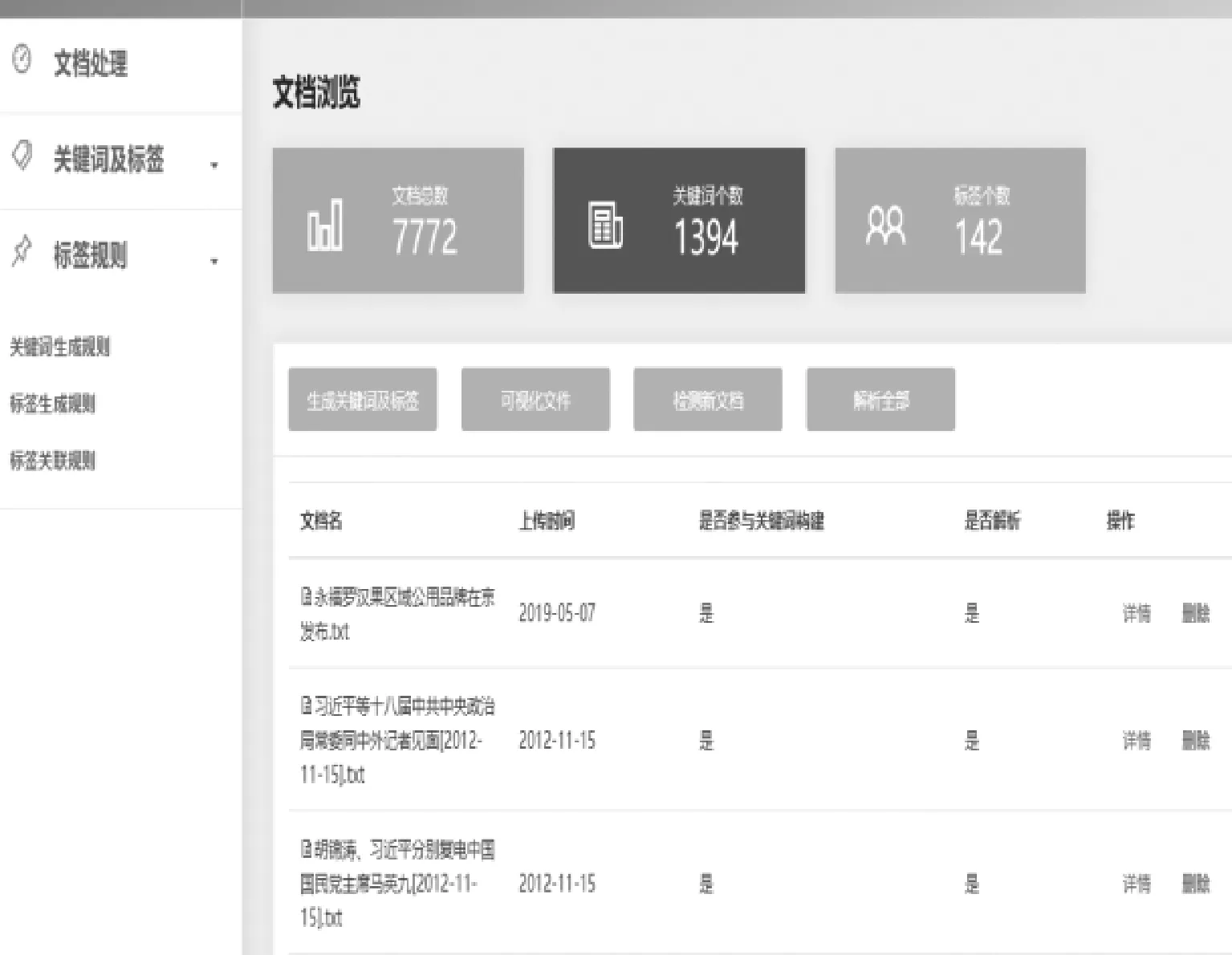
圖7 知識圖譜后臺管理原型
4 基于知識圖譜語義相似度的協同過濾推薦
4.1 標簽語義查詢
在涉農學習資源知識圖譜構建基礎上,實現基于語義理解的描述信息的解析。本文將用戶查詢語句分為兩類:(1) 給定一個類型或概念,返回該類型的實體列表;(2) 給定實體集合,返回與輸入相關的實體列表。
對于類型查詢,給定類型或概念,根據查詢長度分兩種情況:(1) 查詢類型為名詞或者一個名詞加上一個修飾詞組成,如“病蟲害”和“番茄病蟲害”。系統直接返回在知識圖譜中該查詢類型下的實體。(2) 查詢類型由一個名詞加上多個修飾詞組成,如“農村社會公共事業建設”,直接從知識圖譜中獲取結果不現實,通過對查詢語句進行解析,將其拆解為三個簡單類型,即{“農村建設”,“社會建設”,“公共事業建設”},這些類型在知識圖譜中具有較高的覆蓋率,通過查詢這些類型實體,并通過交集操作方式作為返回結果。
對于特定實體集查詢,返回的實體要符合用戶潛在查詢的類型,滿足用戶的查詢意圖。如用戶輸入{“作物生產技術”,“林業生產技術”,“畜禽養殖技術”},用戶意圖可能是“農村先進適用技術”數據類型,因此,返回結果應是知識圖譜中“實用技術”及其鄰近節點的實體。對于實體集的查詢,返回與查詢實體經常出現的實體,使用共現次數作為返回結果。同時利用知識圖譜中已有關聯關系(如上下位詞)對輸入的實體進行概念化語義匹配,理解用戶查詢意圖,并返回該語義下相關實體。
為減少查詢圖操作的復雜度,系統對查詢的文本信息進行預先過濾,主要策略是基于實體、類型、屬性、關系過濾并建立典型路徑和頻度模式分類索引,從而加快查詢算法速度。
4.2 推薦算法設計
提出基于知識圖譜語義相似度的協同過濾推薦算法,對涉農領域知識圖譜標簽權重進行相似度計算,并對標簽的權重聚合,通過矩陣分解得到一個包含一系列語義相關標簽基的標簽子空間,使得同義及相關的標簽聚合于同一標簽基,且一詞多義的標簽歸類到語義不同的標簽基,從而實現標簽語義的近義歸類和多義辨析。
針對不同學習資源設定的不同專題,對于具有描述文本的資源采用TF-IDF方法提取資源描述關鍵詞作為特征詞。對于設定類別目錄的資源,將目錄路徑上出現的名稱都作為特征詞,層級越細的目錄名賦予更高的權值。用戶標注標簽的資源,直接將標簽作為特征詞,標注頻率作為標簽的權值。根據涉農學習資源領域知識圖譜中存在大量的上下位詞關系,計算兩個標簽的相似性時,通過計算兩個節點的共享父概念和子概念的頻數,構建相應的概念向量,根據相似度的大小為用戶推薦學習資源。
在領域知識圖譜相似度計算時,用戶感興趣的特定標簽具有相應權重值,結合知識圖譜及其用戶對標簽的評分信息計算相似度。用戶感興趣標簽數據集ID={D1,D2,…,Dn},ND(Dm,Dn)為兩個感興趣標簽Dm與Dn在涉農學習資源知識圖譜中關于同一類別節點最近一個,興趣標簽Dm與Dn在知識圖譜中的語義相似度計算公式如下:
(5)
式中:IDsim(Dm,Dn)為興趣標簽Dm和Dn的語義相似度;Depth(Dm)為從圖譜中同類資源根節點到用戶標簽Dm路徑深度;Depth(Dn)為從圖譜中同類資源根節點到用戶標簽Dn路徑深度;Depth(ND(Dm,Dn))是圖譜中同類資源根節點到Dm和Dn最臨近共祖先節點路徑長度。IDsim(Dm,Dn)數據范圍[0,1],Dm=Dn時,即兩個標簽相同,IDsim(Dm,Dn)=1。興趣標簽相似度數值隨著共祖先節點深度增加而變大。
5 實驗與分析
5.1 實驗數據與設置
從北京農業在線學習平臺中提取數據:總計5 000條用戶學習應用數據,其中包含423個用戶及832個學習資源,用戶對學習資源評分分為3個等級,評分等級的數值反映用戶對學習內容的喜好程度。
將實驗數據劃分為訓練集和測試集,在數據集中隨機抽取一定的比例作為實驗訓練集,我們按照數據總量的20%、40%、60%和80%抽取,剩下數據是測試集,采用用戶對學習資源的打分值和相似度分析預測測試數據的學習資源評分數據,分別采用基于涉農資源知識圖譜的協同過濾推薦與傳統系統過濾方法推薦。同時計算稀疏度SPA(式(6))、準確率MAE(式(7))和覆蓋率COV(式(8))。
(6)
式中:SPA為稀疏度;M為用戶已經評分資源梳理;U是用戶數量;N是學習資源數量。
(7)
式中:{L1,L2,…,Li}為預測評分數據集;{M1,M2,…,Mi}為用戶實際打分數據集;N為集合的數量。
(8)
式中:Md是測試數據集合中預測評分數據的數量;M為測試數據集合中的預測評分數據的總量。
5.2 實驗結果及分析
通過不同測試訓練集劃分,計算基于涉農學習資源知識圖譜語義相似度的協同過濾推薦(方法一)與基于傳統資源庫推薦方法(方法二)的稀疏度SPA、準確率MAE和覆蓋率COV,數據見表2。

表2 不同訓練集占比條件的SPA、MAE和COV
訓練集所占比例由20%提高到40%過程中,方法一和方法二的MAE都有所下降,也表明SPA數值增加,推薦MAE數值下降,推薦COV數值在增加;在SPA數值相對較大時,MAE和COV數值變化趨向于平緩。方法一的平均MAE高于方法二,方法一的平均COV接近方法二。基于知識圖譜語義相似度的協同過濾推薦與基于傳統資源庫推薦方法相比,推薦的準確率MAE大幅提升,推薦覆蓋率COV基本保持一致。變化趨勢如圖8所示。因此,通過知識圖譜的底層數據支持,與傳統的資源庫推薦方式相比具有更好的推薦準確率。
6 結 語
本文是在北京市農業網絡在線學習平臺的學習資源基礎上,通過對學習資源系統化和體系化梳理,采用LDA標簽提取方法構建了北京市涉農學習資源領域知識圖譜,通過軟件和數據庫技術,研發構建了涉農領域知識圖譜可視化與管理維護系統,實現知識圖譜的實體、概念和關系的可視化展示及查詢管理。本文知識圖譜構建及其特征標簽提取方法具有一般性,研發知識圖譜可視化及維護管理工具,在信息資源的實體關系抽取、標簽管理和特征提取方面具有靈活性,可以擴展應用到其他領域。
在涉農領域知識圖譜構建基礎上,設計研發基于知識圖譜語義相似度的協同過濾推薦系統,實驗結果表明,推薦準確率達到84.27%,與基于傳統的資源庫推薦方式相比,大幅提升了推薦準確率,經過北京市涉農地區用戶的應用反饋與迭代更新,證實該系統具有較好的易用性、安全性、穩定性和可靠性,具有廣闊的市場應用前景。然而作為農業在線學習背景下的涉農領域知識圖譜構建與應用探索,仍有很多需要改進的方面,僅為知識圖譜的構建和應用研究提供新的視角。知識圖譜的實體及關系在涉農學習領域覆蓋還不全面,部分實體和關系抽取信息的準確率還需進一步提升,構建知識圖譜過程中還需大量人為干預工作,期望后續進一步探索完善這些方面的研究。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
