一種面向實體關系聯合抽取中緩解曝光偏差的方法
2022-09-06 07:30:56范紅杰柳軍飛
計算機研究與發展 2022年9期
王 震 范紅杰 柳軍飛
1(北京大學軟件與微電子學院 北京 100871)
2(中國政法大學科學技術教學部 北京 102249)
3(北京大學軟件工程國家工程研究中心 北京 100871)
(wang.zh@pku.edu.cn)
知識圖譜中的關鍵要素是實體和實體之間的關系[1].關系事實由有語義關系連接的實體對組成,其一般形式為(主語,關系,賓語),稱為實體-關系(entity-relation)三元組(triplets).從無結構文本中抽取具有關系的實體對是自然語言處理(natural language processing, NLP)中信息抽取的一項基本任務[2-4],也是知識圖譜構建(knowledge graph construction, KGC)的關鍵步驟[5-6].
現有的實體和關系抽取方法主要分為2類:流水線(pipeline)方法和聯合抽取方法.流水線方法將任務分解為2個獨立的子任務:命名實體識別[7-9]和關系抽取[10-12].該方法首先識別命名實體,然后為抽取的每一對實體選擇一個關系.流水線方法的優點是簡單、靈活、易于執行,可以自由地替換其中一個抽取組件而不需要考慮另一個抽取組件.然而,流水線方法忽略了這2個子任務之間潛在的相關性和相互作用[13-14],從而導致命名實體任務中的錯誤信息會傳播到關系抽取任務中,或者來自一個任務的有用信息卻未被另一個任務利用,進而影響關系抽取的效果.
近年來,越來越多的研究致力于在單個抽取組件中同時實現實體和關系抽取.這種抽取方式通常稱為聯合抽取方法.與流水線方法相比,聯合抽取方法整合了實體和關系的信息,有效地減少了誤差傳播,取得了更好的抽取性能[15-16].最初的聯合抽取方法嚴重依賴特征工程[17],需要較為復雜的預處理過程,導致引入額外的錯誤信息.為了減少對特征工程的依賴,許多研究者將神經網絡應用到關系抽取任務中[18-19].
Miwa等人[20]提出了一種基于循環神經網絡(recurrent neural network, RNN)的聯合抽取方法,該方法使用雙向長短期記憶(bi-directional long-short term memory, Bi-LSTM)網絡先對實體進行編碼,并在此基礎上使用Tree-LSTM建模詞對之間的語法依賴.Adel等人[21]利用卷積神經網絡(convolutional neural network, CNN),結合線性鏈條件隨機場同時預測實體和實體之間的關系.Ren等人[17]結合遠程監督(distant supervision)和弱監督(weakly supervision)學習方法對文本中的實體和關系進行聯合抽取.
理想的聯合抽取系統應能自適應地處理多種情況,特別是在實體重疊情況下的三元組抽取,即多個關系共享一個公共實體,而這些方法無法處理實體重疊問題.最近出現了一些針對該問題的研究[22-23].Fu等人[22]采用圖卷積網絡(graph convolutional network, GCN)對單詞圖進行建模.Takanobu等人[23]應用分層強化學習框架來增強實體之間的交互.盡管目前基于神經網絡的三元組抽取方法可以在一定程度上解決實體重疊問題,但是這些方法都將三元組抽取任務分解成存在內部依賴性步驟的方法.這使得任務易于執行,但同時引入了曝光偏差(exposure bias),即模型對于頻繁出現的標簽組合出現過擬合,從而影響模型的泛化性能.
當前解決實體重疊三元組(entity overlapped triplet, EOT)抽取問題的方法存在訓練和推理搜索空間不一致的問題.在訓練時采用真實標簽作為輸入,搜索空間源自數據的靜態分布,而推理時采用模型的前一步輸出作為輸入,搜索空間來自模型的分布.此外,由于模型當前的解碼輸出依賴于前一時刻的解碼結果,從而導致誤差累積.特別是當實體重疊現象比較嚴重和句內三元組數量較多時,解碼序列會隨之加長,所產生的誤差累積問題也會更加嚴重.
針對曝光偏差和誤差累積的問題,本文提出了融合關系表達向量(fusional relation expression embedding, FREE)的先驗特征提取方法,豐富了先驗特征的語義表達,彌補了訓練與推理搜索空間不一致的問題,緩解了曝光偏差.此外,本文提出的條件層規范化方法相較于傳統加和與拼接的特征嵌入方法,可以更加有效地進行特征嵌入.方法在公開的實體關系抽取數據集上進行了大量的實驗評估.實驗結果表明,相較于現有最強基線模型,本文提出的模型分別獲得了91.7%和92.5%的F1值,并在諸多性能指標上優于現有抽取模型.同時,對結果的深入分析表明該方法能夠更有效地適應多種三元組抽取任務.
本文的主要貢獻包括3個方面:
1) 提出了一種融合關系表達向量的先驗特征提取方法,豐富了先驗特征的語義表達,彌補了訓練與推理搜索空間不一致的問題,緩解了曝光偏差;
2) 提出了更有效嵌入和融合特征的條件層規范化層,并將先驗特征融入到賓語抽取的參數表示中;
3) 在NYT和WebNLG數據集上的實驗評估表明提出的方法可以有效地解決三元組抽取問題,特別是面向實體重疊的三元組抽取.
1 相關工作
早期的關系抽取工作一般采用流水線方法,即先對非結構化文本進行命名實體識別(named entity recognition, NER)[7-9]任務,再進行關系抽取(relation extraction, RE)[10-12,24]任務,即先抽取實體再確定實體對之間的關系,例如Nadeau等人[7]和Zelenko等人[24]的工作.但這些方法忽略了子任務之間的相關性和聯系[25-26],且存在著誤差傳遞問題.實體識別的錯誤會導致后續三元組整體抽取結果的錯誤.此外,由于采用先對抽取的實體兩兩組合再確定其關系的方法,導致無意義關系的實體較多時會出現冗余計算.
為了克服誤差累積弊端,逐漸有學者提出了聯合抽取模型.它是指只用一個模型即可抽取出文本中的實體關系三元組,增強了實體抽取和關系抽取2個子任務間的聯系,緩解了誤差傳遞的問題[15-16].目前主流的聯合模型分為基于語法分析的模型[27]、基于特征工程的模型[17]和基于神經網絡的模型[18-19,27].Ren等人[17]使用包括詞性和實體層級以及知識庫在內的多種特征約束,并且運用了文本集的信息和句子級別的局部信息將實體識別和關系抽取聯合起來.Roth等人[26]使用信念網絡建模句子內實體與關系間的語義和句法依賴,結合貝葉斯推斷模型得到實體關系標簽組合.Miwa等人[28]提出一種基于歷史的結構化學習方法,通過合并全局特征并選擇合適的學習方法和搜索順序取得了優于流水線方案的結果.Liu等人[29]提出綜合利用依賴解析樹、核心謂詞和詞嵌入特征來優化支持向量機等傳統機器學習模型的性能.Jiang等人[30]使用漢語句法特征作為啟發式規則擴充和過濾基于規則建立的三元組數據.Hasan等人[31]提出將詞性標記、依賴關系和語義類型等傳統特征與詞向量特征結合的方法進一步提升模型性能.在基于神經網絡的模型方面,Zeng等人[32]和Xu等人[33]使用基于卷積神經網絡的方法來解決關系分類問題,其F1值比以往的機器學習模型具有明顯的提升.葉育鑫等人[34]針對遠監督關系抽取任務中的標記噪聲,構建了基于噪聲分布和帶噪觀測層的新型關系抽取模型.Zheng等人[15]采用基于長短期記憶網絡的實體關系聯合抽取模型,將三元組抽取任務創新性地定義為序列標注任務,采用基于就近原則的關系鏈接序列標注方法抽取實體關系三元組.作為改進,Miwa等人[20]提出了一種基于循環神經網絡的聯合抽取模型,該模型使用雙向長短期記憶網絡先對實體進行編碼,并使用考慮基于依賴樹信息的Tree-LSTM對實體之間的關系進行建模.然而該模型無法處理實體重疊三元組,即一個實體可能參與到多個三元組的構成中.
當前處理實體重疊三元組抽取任務的模型可分為2類:基于解碼器優化和基于分解策略.基于解碼器優化的模型通常采用編碼器解碼器結構,解碼器一次抽取1個單詞或1個完整三元組.Zeng等人[35]基于序列到序列(sequence-to-sequence, Seq2Seq)的思想提出了融合拷貝機制的聯合抽取模型,但其模型解碼器只拷貝實體的尾字節,導致了多字節實體不能完整抽取.Nayak等人[36]采用Seq2Seq框架一次解碼一個完整實體.由于句內多個三元組的存在,Zeng等人[37]認為三元組抽取順序會影響抽取結果,并使用強化學習模型學習抽取順序.基于分解策略的模型首先抽取所有可能與目標關系相關的頭實體,然后為每個抽取的主語標記相應關系和尾實體.Yu等人[38]提出采用頭實體和關系尾實體抽取雙階段的序列標注方法.Wei等人[39]提出了一種基于級聯二進制的標注框架,即首先采用指針標注主語識別起始和終止位置,抽取句子中所有可能的主語實體,再采用指針標注識別主語的所有可能關系和賓語.
然而這些方法中普遍存在嚴重的曝光偏差現象.Zhang等人[40]從三元組解碼順序和解碼長度問題入手,通過無序樹解碼方式并將解碼長度限制為3步來解決順序依賴問題,同時輸出句內包含的多個三元組.Wang等人[41]針對模型訓練時的階段性問題,設計了一種稱為握手的數據標注方式將頭實體和尾實體序列標注問題轉換為1階段的序列標注問題,緩解曝光偏差的同時可以處理嵌套實體,但由于引入了更多的標簽,從而導致訓練較為困難.Sui等人[42]同樣認為傳統的序列到序列框面臨三元組生成順序對最終抽取結果的影響,設計了多任務學習框架,采用非自回歸解碼策略并行生成順序無關三元組,并設計了基于2部圖匹配的集合損失函數來衡量模型輸出集合與真實集合的差距.
2 方法描述
2.1 模型整體結構
如圖1所示,本文的融合關系表達向量聯合抽取模型包括5部分,分別是表示層、頭實體向量抽取層、關系表達向量抽取層、條件層規范化層及關系尾實體抽取層.模型接收輸入文本后,根據句子抽取主語,通過頭尾字向量的平均得到主語向量,然后將該先驗信息通過條件層正則化嵌入到文本表達中;在此之后,基于該文本表達預測得到各文本參與到當前主語關系表達的概率,并依概率相乘得到關系表達向量;在此基礎上,通過門控機制控制來自主語向量和關系表達向量信息的比例,主語向量和關系表達向量加和得到最終的融合關系向量表達;最后再將該先驗信息通過條件層正則化嵌入到文本表達中,預測該主語關系表達類別及對應的賓語.
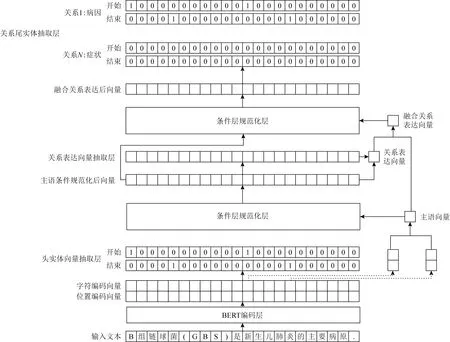
Fig. 1 The structure of joint extraction model with fusional relation expression embedding圖1 融合關系表達向量的聯合抽取模型結構
本文繼承Wei等人[39]提出的基于CasRel三元組抽取模型設計思路,依照Seq2Seq模型先抽取主語,再跟據主語先驗信息和關系表達抽取三元組中所對應關系和賓語.Seq2Seq模型解碼為
P(Y1,Y2,…,Yn|X)=P(Y1|X)P(Y2|X,Y1)…
P(Yn|X,Y1,…,Yn).
(1)
式(1)中,給定先驗句子X對標簽序列Y建模,使其生成Y1,Y2,…,Yn序列的概率最大似然.模型從輸入的X得到第1個Y1標簽,再將X和Y1標簽作為特征再輸入到Seq2Seq模型解碼出Y2,以此類推,依次解碼出Y3,Y4,…,Yn.由此可以類比得到三元組抽取式(2):
P(s,p,o|X)=P(s|X)×P(t|X,s)×
P(o|X,s,t).
(2)
式(2)中,給定輸入句子X,抽取主語s并獲取融合先驗向量,再基于先驗信息和句子X解碼出關系p和賓語o.為抽取實體重疊三元組,本文采用分層標注方法,即在抽取主語時采用二進制序列標注方式,在抽取p和o時,每層標注序列產生的p和o都對應一種提前設定好的關系,保證最終生成的標注序列和預定義關系數量相同.
2.2 標注策略
本文在頭實體和尾實體抽取過程中采用相同的頭尾標注策略,結合標簽信息進行解碼抽取.圖1的表示層和頭實體向量抽取層是抽取主語時經過序列標注生成標簽序列的一個示例.給定句子“B組鏈球菌(GBS)是新生兒肺炎的主要病原”,模型輸出的主語開始序列中“新”對應的開始標簽為1,代表其是主語的開頭字符,然后從主語結束標簽序列中的對應位置開始向后搜尋下一個字符對應的標簽是否為1.如果對應標簽為1,說明當前字符是主語的結束字符,主語提取完畢.最終從輸入文本中提取出來的主語為“新生兒肺炎”.圖1的關系表達向量抽取層、條件層規范化層及關系尾實體抽取層則是結合抽取的主語“新生兒肺炎”與關系表達的融合先驗特征.模型再對句子序列進行標注并生成與主語關系表達相關的賓語標簽序列,其標注方案同樣采用頭尾標注策略.基于賓語標簽序列,采用相同的解碼方法提取出輸入文本對應的句子賓語“B組鏈球菌”,再根據賓語標簽序列確定對應的關系類別“病因”,最終抽取出三元組(“新生兒肺炎”,“病因”,“B組鏈球菌”).從代表某一關系類別的賓語標簽序列中提取的賓語表示該賓語和先驗主語之間的關系為該類別.如果“B組鏈球菌”被判斷為主語,模型會重復以上操作抽取出對應的三元組.由于該模型作用于限定域關系抽取,因此事先預定義的關系類型是固定的.
2.3 BERT編碼層
本文使用bert_base_cased[43]作為預訓練模型編碼獲得句子語義向量.先將輸入文本的原始句子序列按字節對進行編碼和分段標記.BERT模型處理后的輸出是單詞的上下文語義向量.通過詞向量表將文本轉換成包含語義信息的向量再輸入到下層.例如對于“B組鏈球菌(GBS)是新生兒肺炎的主要病原”的樣例文本,經過編碼分段后得到每個字在詞典中的序號和分段標號.此后,可以通過查詢模型的詞向量表得到對應位置的語義向量表示.
2.4 融合先驗信息
受高速網絡[44]啟發,融合先驗信息fusione由主語向量subjecte和關系表達向量triggere兩部分組成,由H控制信息來源比例.獲取融合先驗信息時,各部分的計算為
subjecte=average(ehead+etail),
(3)
其中,ehead與etail分別表示主語頭尾位置處的字向量,average()函數表示取平均.
pi=σ(Wsubject·xi+bsubject),
(4)
其中,pi表示序列中各個字參與到主語關系表達中的概率,xi表示文本各處的字向量表示,Wsubject表示主語變換向量,bsubject表示主語變換偏置.
(5)
H=sigmoid(W1·subjecte+W2·triggere),
(6)
其中,W1表示主語的變換向量,W2表示關系表達的變換向量.
fusione=(1-H)·subjecte+H·triggere.
(7)
式(3)用于獲取主語向量,式(4)中的pi可以作為當前主語關系表達“觸發詞”的概率,式(5)用于獲取關系表達向量,最終得到式(7)所示的融合先驗信息fusione.
2.5 條件層規范化層
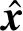
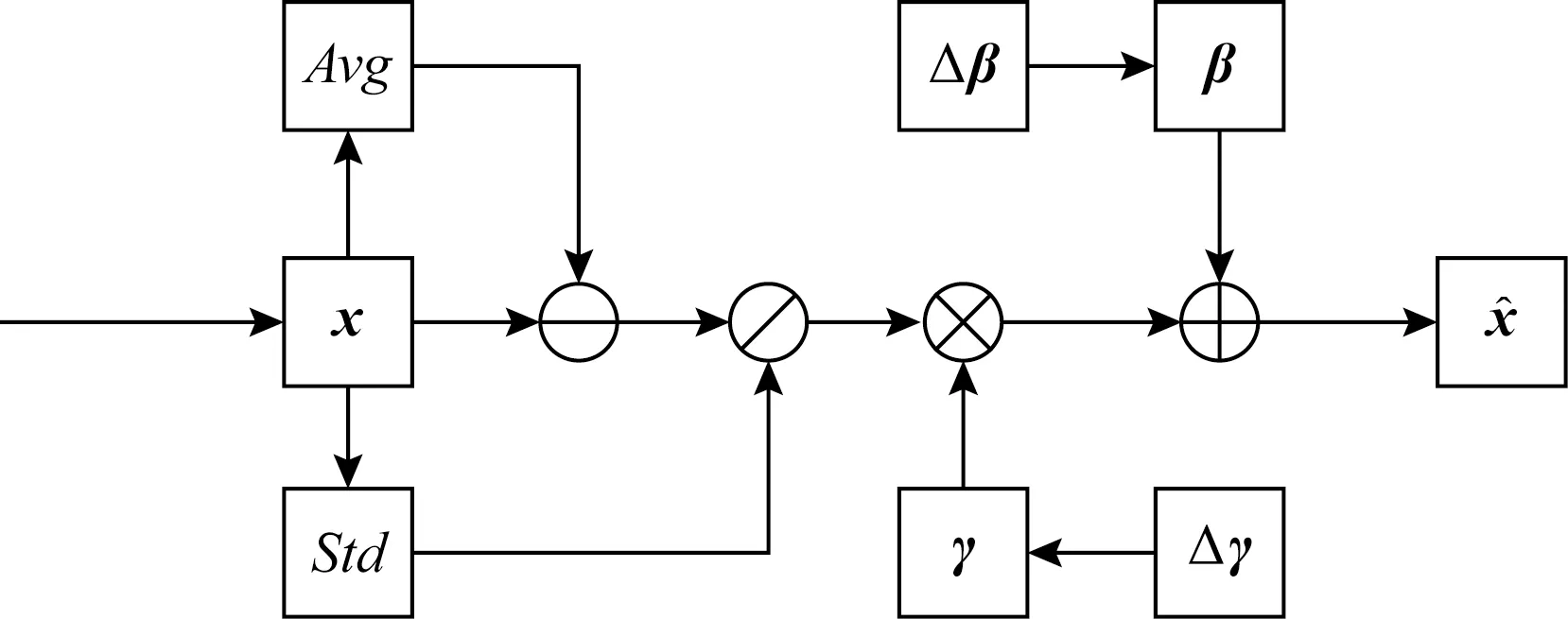
Fig. 2 The structure of conditional layer normalization圖2 條件層規范化層的結構
由于BERT等預訓練模型已經采用了層規范化層,使用了無條件的β和γ,且都是長度固定的向量.本文可以通過2個不同的變換矩陣,將輸入條件變換到與β和γ一樣的維度,然后將2個變換結果分別與β和γ相加.實現公式分別為:
Δγ=Wγ·fusione,
(8)
Δβ=Wβ·fusione,
(9)
γnew=γ+Δγ,
(10)
βnew=β+Δβ,
(11)
(12)
其中,Wγ和Wβ分別為γ和β維度對應的變換矩陣,用于先驗向量維度轉換;ε為輔助常量.
2.6 解碼器
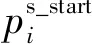
(13)
(14)
(15)
(16)
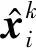
2.7 目標函數
對于數據集D和預定義關系集R,式(2)展開為
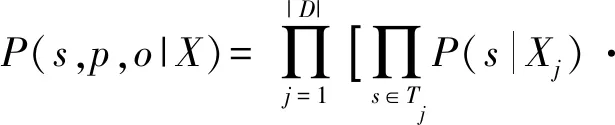
(17)
抽取頭實體時采用句子原始向量,抽取頭實體對應的關系和尾實體時采用先驗信息融合的句子向量.
模型訓練的目標函數為最大似然:
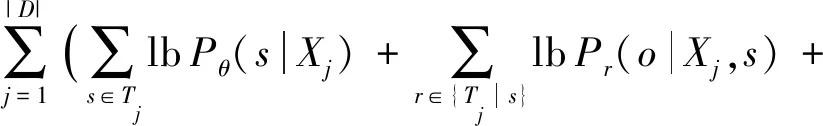
(18)
頭實體和尾實體抽取時采用相同的頭尾標注方式,其中頭尾位置標記為1,其他標記為0.
其中Pθ(s|Xj),Pr(o|Xj,s),P?r(o|Xj,s)可展開為:
Pθ(s|Xj)=
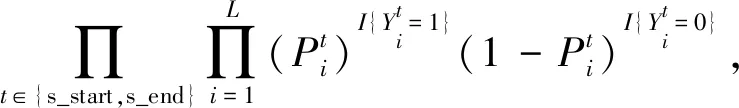
(19)
Pr(o|Xj,s)=P?r(o|Xj,s)=
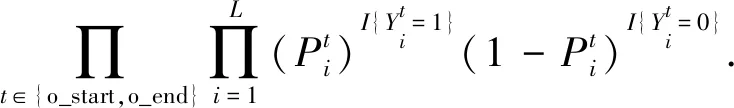
(20)
3 實驗與結果
3.1 實驗準備與實驗背景
本文采用NYT[48]和WebNLG[49]數據集進行實驗評估.其中,NYT數據集采用遠程監督方式抽取自1987—2007年期間的118萬個新聞句子,包含了24個預定義關系類型;WebNLG數據集最初為自然語言理解任務所創建,之后被改編在三元組抽取任務中,采用人工標注方式涵蓋了171個預定義關系類型.NYT和WebNLG句子通常包含多個實體重疊三元組,因此采用這2個數據集作為基準,非常適合用于評估實體重疊三元組抽取的模型性能.
NYT和WebNLG數據集統計信息如表1和表2所示.實體三元組重疊類型包括常規實體(normal entity)、單實體重疊(single entity overlapping, SEO)和完全實體重疊(entity pair overlapping, EPO)三種類型.各類別示例如表3所示.值得說明的是,由于部分句子既包括單實體重疊又包括完全實體重疊,因此最后得到的所有類別實體總數會略小于以上3種類型之和.
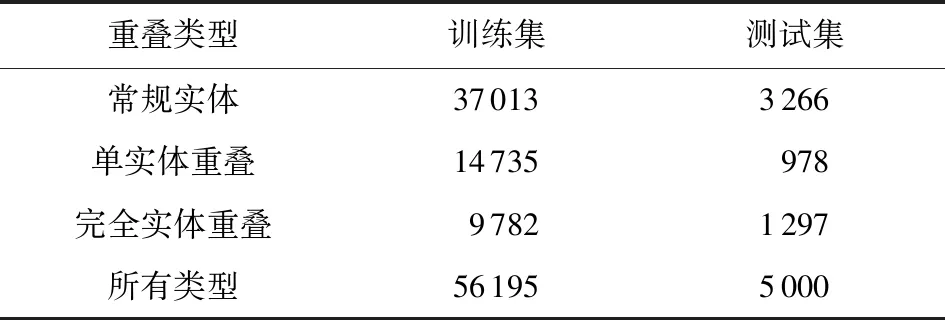
Table 1 Information of NYT Dataset表1 NYT數據集信息

Table 2 Information of WebNLG Dataset表2 WebNLG數據集信息
本文使用精確率(precision,P)、召回率(recall,R)和F1值(F1 score)三個指標驗證模型的有效性,其中F1值是綜合性評價指標.評價過程采用精確匹配,因此當且僅當預測產生的三元組與真實三元組的實體名稱和類別完全匹配時,才看作正確識別的三元組預測.
本實驗采用小批量梯度下降方式訓練模型,批大小為6,使用Adam[50]優化器,學習率設置為10-5,在驗證集上確定超參數,通過訓練100輪,選取在驗證集上效果表現最好的模型.使用的預訓練BERT模型為[bert-base_cased],包含1.1億個參數.概率閾值設置為0.5,句子最大長度設置為100,其CPU為8核Intel Core i9-9900k,內存為96 GB,GPU為GeForce GTX 2080Ti.

Table 3 Types of Entity Overlapping Examples表3 各類實體重疊示例
3.2 與其他三元組抽取方法的比較
由于本文著重解決聯合抽取方法中的曝光偏置問題,因此將對比提出模型與各聯合抽取模型的性能差異.基于此進行了3個實驗驗證模型的有效性.
第1個實驗是對比所提出模型與其他模型在NYT和WebNLG上的整體性能評估來驗證模型的有效性.實驗結果如表4和表5所示.
從表4和表5中可以觀察到,相較于現有的針對重疊三元組抽取模型,提出的模型在NYT上取得了最高的精確率、召回率及F1值,且在不損失或少損失精確率的前提下,模型在WebNLG上取得了目前最高的召回率和F1值,這表明本模型有更好的泛化能力.由于WDec模型只在NYT上進行了測試,故在WebNLG上缺失實驗結果.
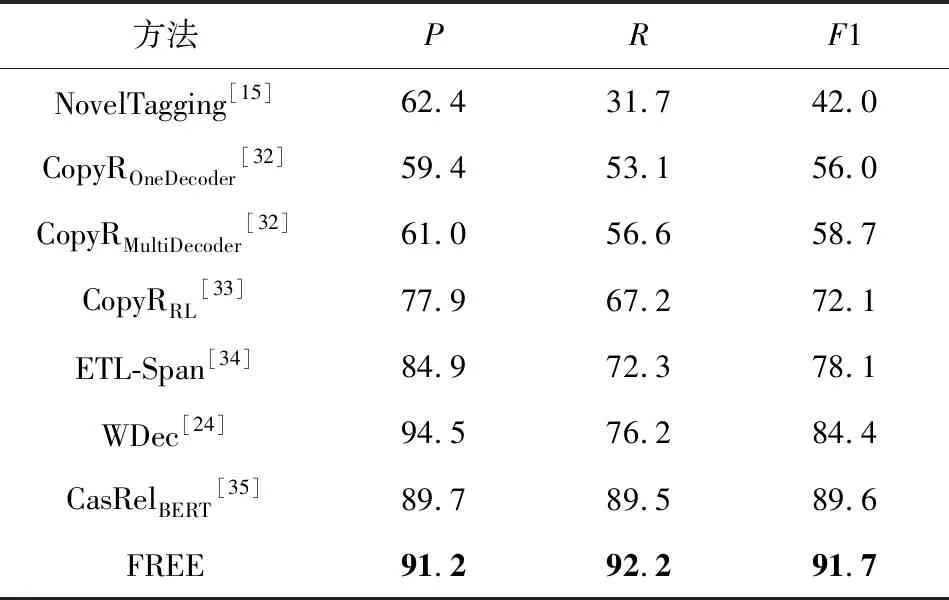
Table 4 The Overall Evaluation Results of Different Methods on NYT表4 不同方法在NYT上的整體性能評估 %

Table 5 The Overall Evaluation Results of Different Methods on WebNLG表5 不同方法在WebNLG上的整體性能評估 %
第2個實驗是評估模型在應對不同實體重疊情況下的表現.進一步分析了模型在曝光偏差更為嚴重的實體重疊和句內存在若干個三元組情況下帶來的性能影響.從圖3~5可以發現,模型在3種不同三元組重疊情況下都取得了最高的F1值.
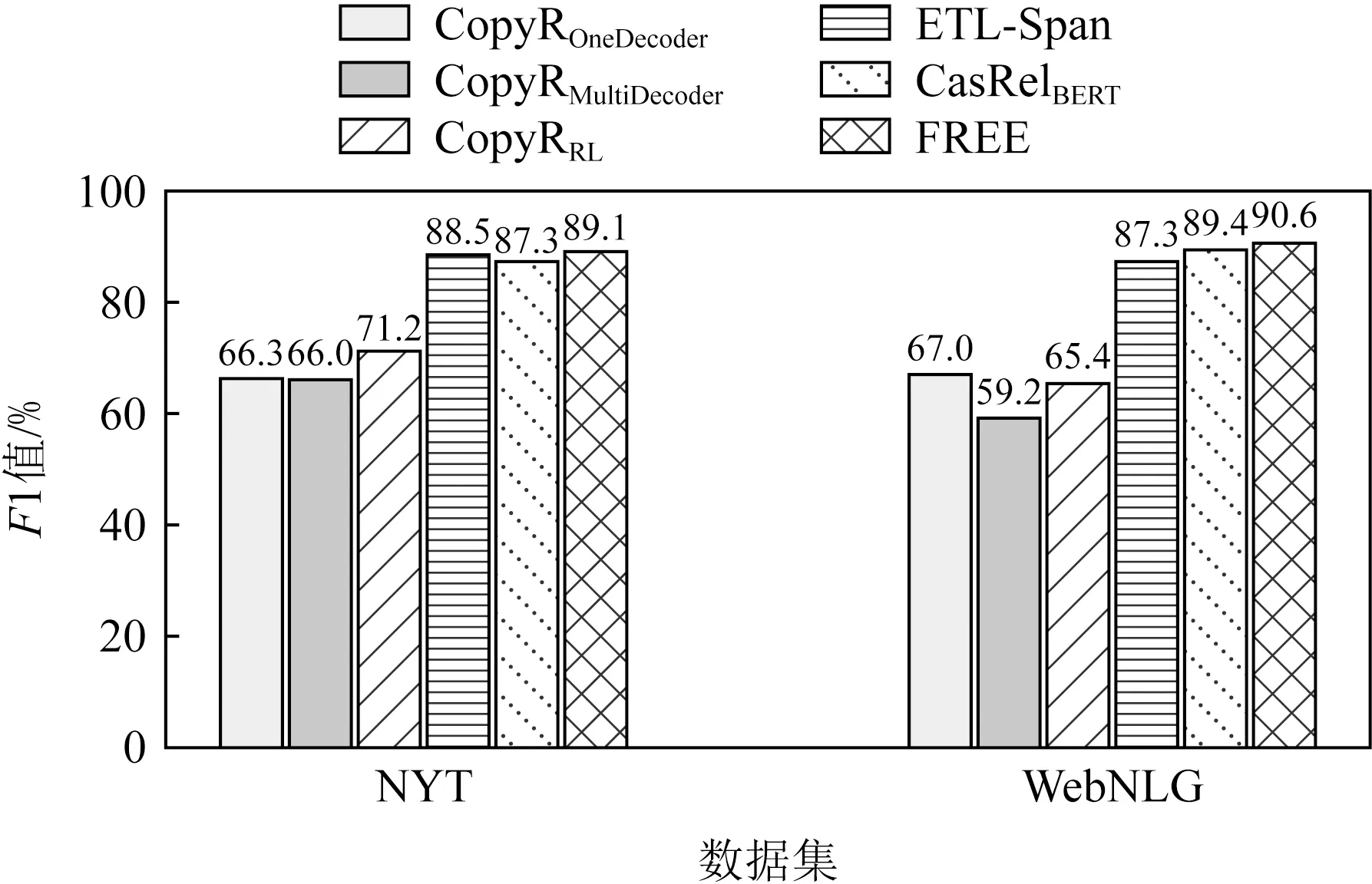
Fig. 3 F1 score of different methods on normaltype entities triplets圖3 不同方法在常規實體三元組上的F1值
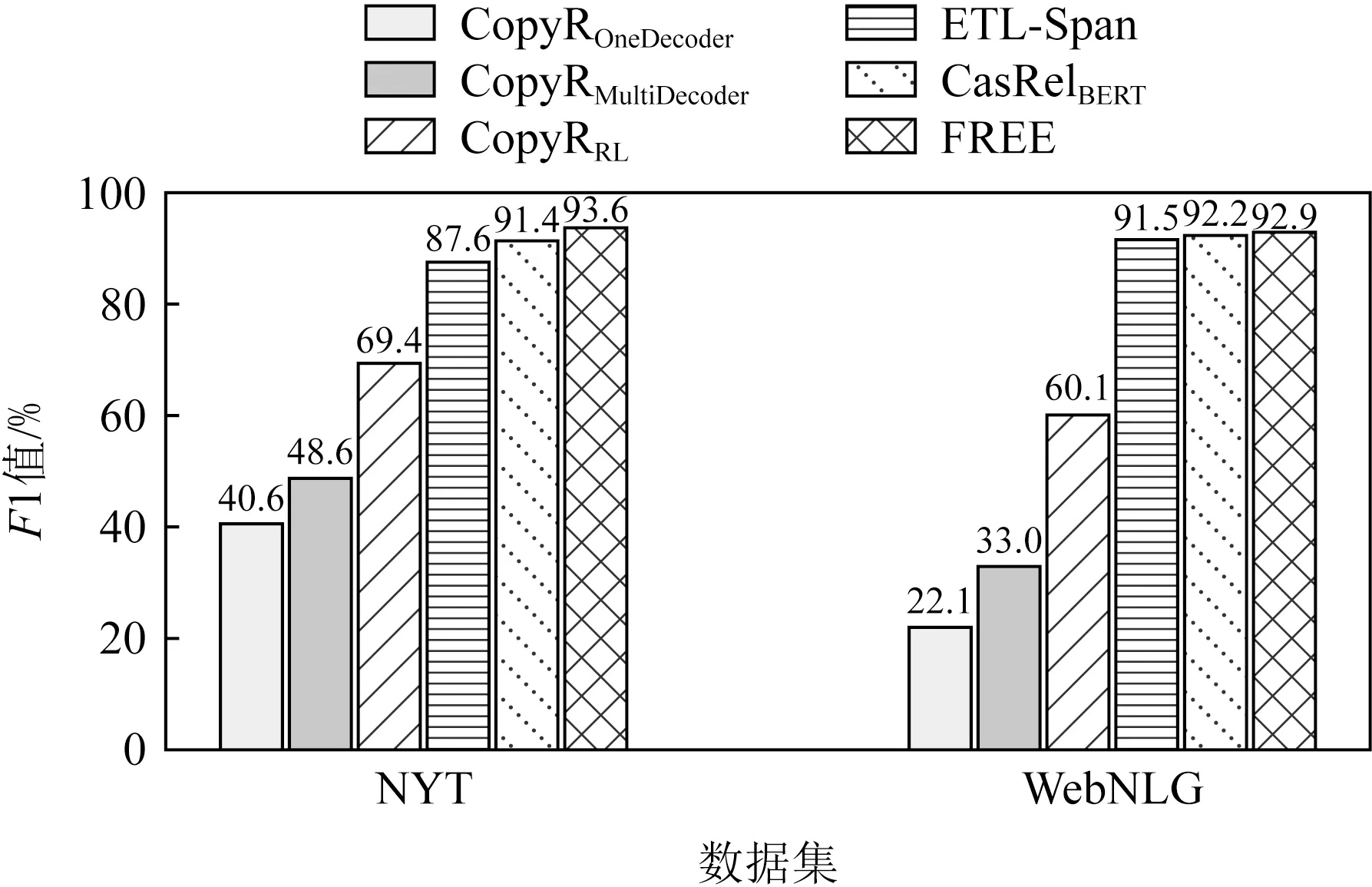
Fig. 4 F1 score of different methods on SEO type entities triplets圖4 不同方法在單實體重疊三元組上的F1值
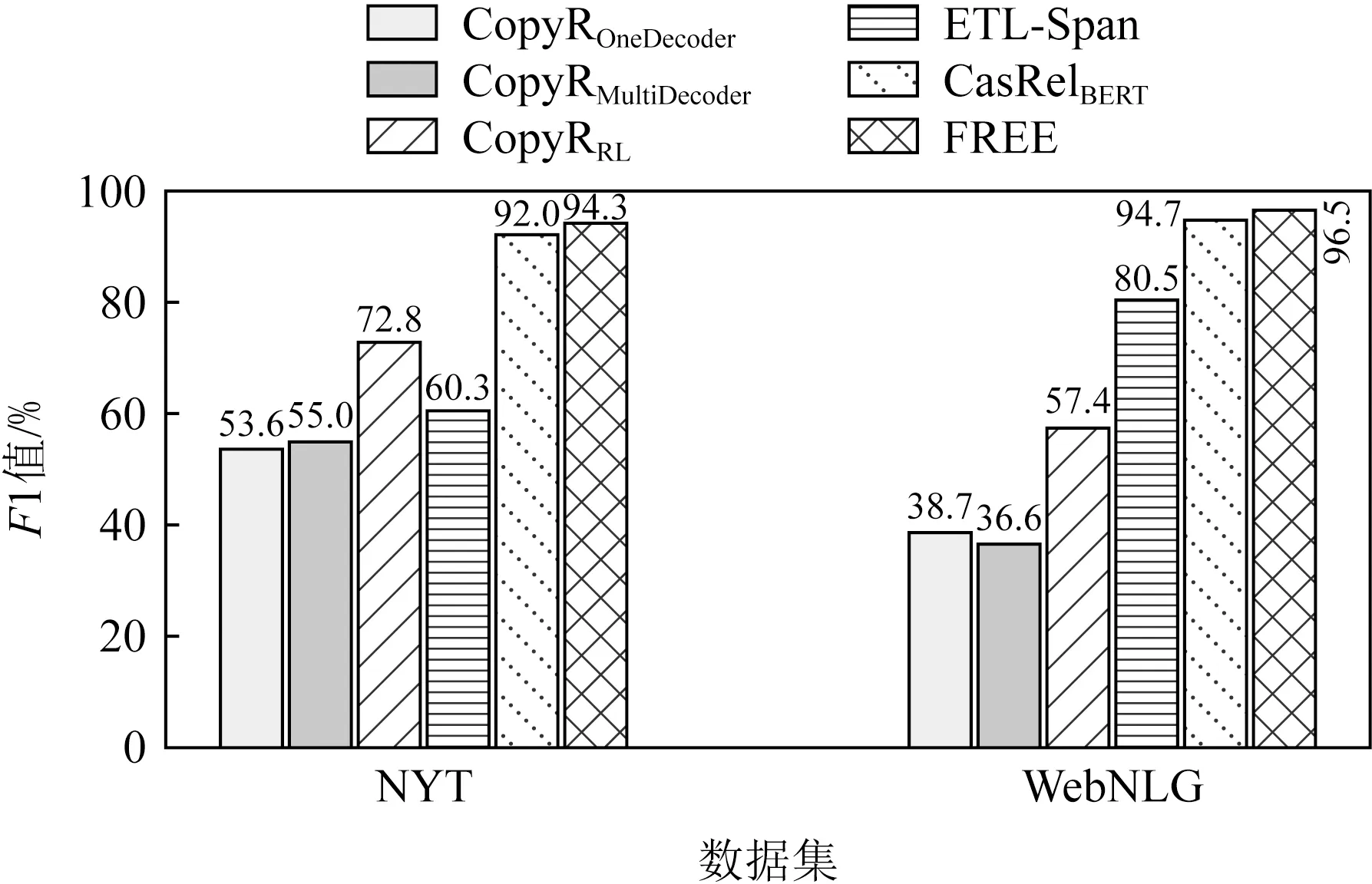
Fig. 5 F1 score of different methods on EPO type entities triplets圖5 不同方法在完全實體重疊三元組上的F1值
通過實驗分析,可以發現模型在不重疊的常規實體三元組上,分別帶來了1.8%和1.2%的F1值提升.此外,模型基于單實體重疊和完全實體重疊也有較高的性能提升.相比目前最優的CasRelBERT模型,本文模型在單實體重疊情況下分別獲得了2.2%和0.7%的F1值提升,在完全實體重疊情況下分別獲得了2.3%和1.8%的F1值提升.由此可以觀察到在實體重疊情況下的性能提升要高于常規情況.由于實體重疊時正確抽取三元組對模型的性能要求更高,這表明FREE能有效緩解曝光偏差,抽取出更加準確和完整的三元組.
第3個實驗是評估了不同模型在處理句內存在多個三元組時的性能差異.如表6和表7所示,隨著三元組數量的增多,所有模型的F1值都呈現了先升高后下降的趨勢.但是本文所提出的模型在多數情況下表現出了最好或次好的性能.隨著句內三元組個數的增多,模型表現穩定,特別是句內三元組個數大于4時帶來了明顯的性能提升.相比目前最優的CasRelBERT模型,本文模型分別取得了6.9%和1.4%的F1值提升.這表明本文通過引入關系表達信息使得模型可以更好地應對句內存在多個三元組的情況,具有更強的泛化能力.
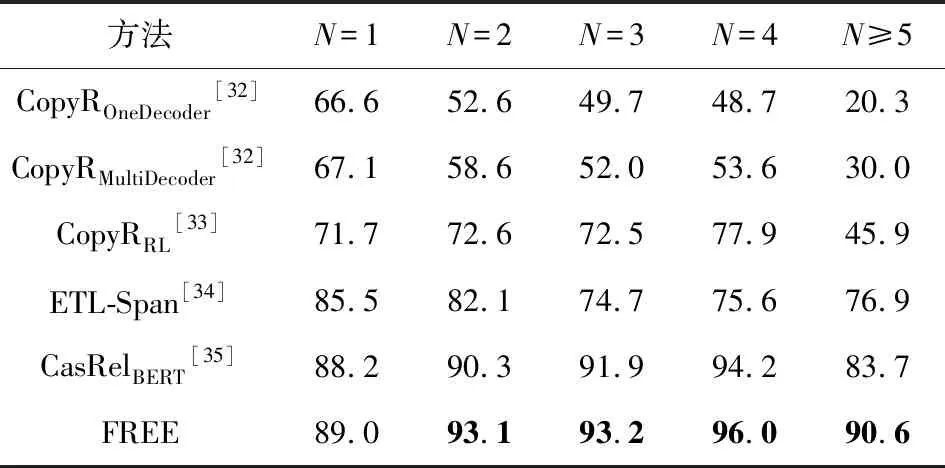
Table 6 F1 Score of Different Methods on Different Triplet Number N in NYT表6 不同方法在NYT中不同三元組數量N上的F1值 %
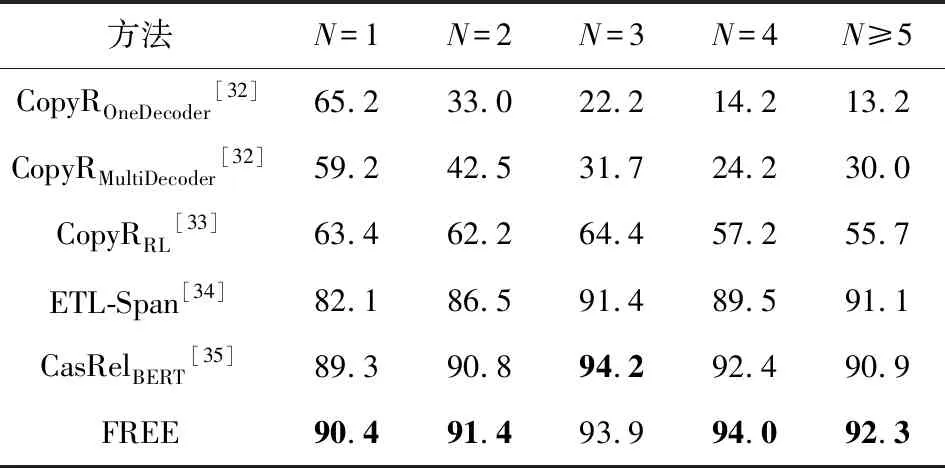
Table 7 F1 Score of Different Methods on Different Triplet Number N in WebNLG表7 不同方法在WebNLG中不同三元組數量N上的F1值 %
3.3 消融實驗
為了分析模型各部分所起的作用,本文分別在NYT和WebNLG上進行了消融實驗.實驗結果如表8和表9所示:
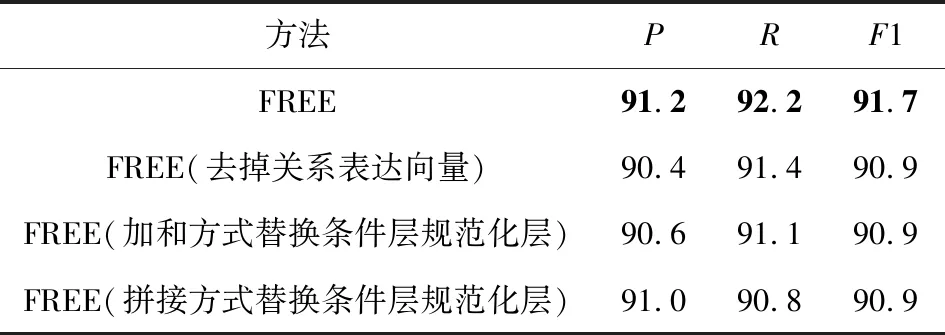
Table 8 Ablation Experiment Evaluations of Different Methods on NYT表8 不同方法在NYT上的消融實驗評估 %
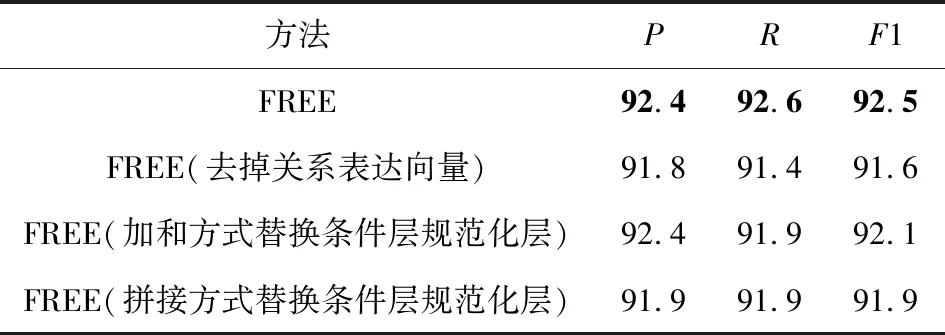
Table 9 Ablation Experiment Evaluations of Different Methods on WebNLG表9 不同方法在WebNLG上的消融實驗評估 %
從表8和表9中可以看出,所提出的完整模型在2個數據集上都取得了最高的精確率、召回率和F1值.本模型由于添加關系表達向量,在2個數據集上的F1值分別提升了0.8%和0.9%.因為采取了條件層規范化層,F1值分別提升了0.8%和0.6%.這表明關系表達向量的引入可以進一步提高模型的召回率和準確率,條件層規范化層的引入可以更有效地實現特征融合,表明了模型有效地減少曝光偏差的影響,具有更好的泛化能力,可以抽取更多的三元組,同時進一步說明了模型各模塊的有效性.
3.4 誤差因素分析
通過3.2節和3.3節所述的實驗分析,發現本文模型針對知識三元組抽取問題具有更好的性能.為了進一步探究影響模型提取關系三元組的因素,本文分析了模型針對三元組(E1,R,E2)中不同元素的預測性能,其中E1代表頭實體,E2代表尾實體,R代表頭尾實體之間的關系.
從表10可以觀察到隨著元素抽取復雜程度的提高,其精確率、召回率和F1值都呈下降趨勢,這意味著在構建頭實體、關系及尾實體三者間的交互中還有較大的提升空間.此外,相比CasRelBERT模型,本文模型通過引入關系表達信息,在不損失或較少損失精確率的前提下,召回率明顯提升(>2.7%,>2.5%),從而取得了更高的F1值(>1.7%,>0.7%),即模型可以抽取出頭實體所參與表達的更多關系.這表明模型減少了曝光偏差影響,具有更好的泛化能力.
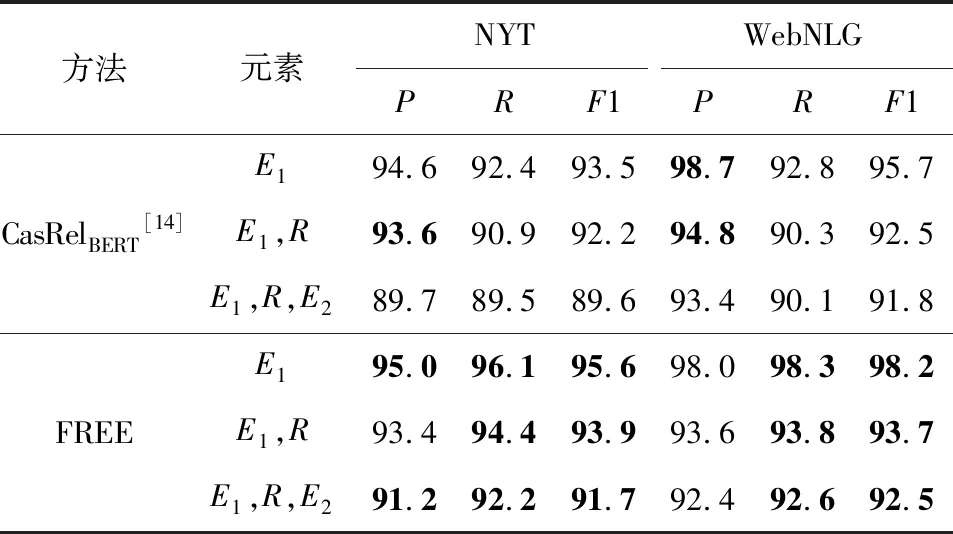
Table 10 Results of Different Methods on Triple Elements Extraction表10 不同方法在三元組元素抽取上的結果 %
3.5 與其他模型的對比分析
本文選取了2個具有代表性的模型TPLinker和SPN,從采取的策略、模型表現和參數量以及訓練和推理效率等方面進行了對比和分析.由于Seq2UMTree模型使用Bi-LSTM作為編碼器,且使用了不同的評價指標,故本文并未將其納入比較對象.如表11所示,本模型在這2個數據集上都取得了較好的表現.
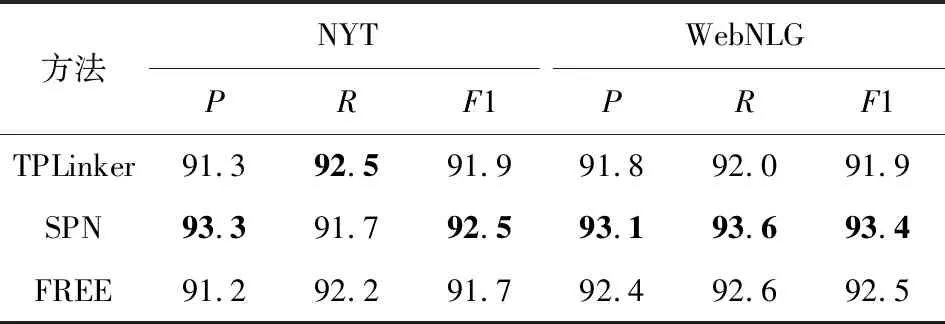
Table 11 Results of Different Methods on Triple Elements Extraction表11 不同方法在三元組元素抽取上的結果 %
從圖6和圖7中可以觀察到,本文所提模型在驗證集上取得了與SPN模型相當的性能,模型收斂速度也基本保持一致,且均優于TPLinker模型.
此外,從表12和表13中可以觀察到,本文所提模型FREE的參數用量最少,在訓練時效率也最高,而且并不需要額外的、復雜的預處理工作.
3.6 實例分析
本文挑選了3個具有代表性的例句進一步觀察和說明本文模型與CasRelBERT[24]模型在2個數據集上對三元組的抽取結果差異,如表14所示.
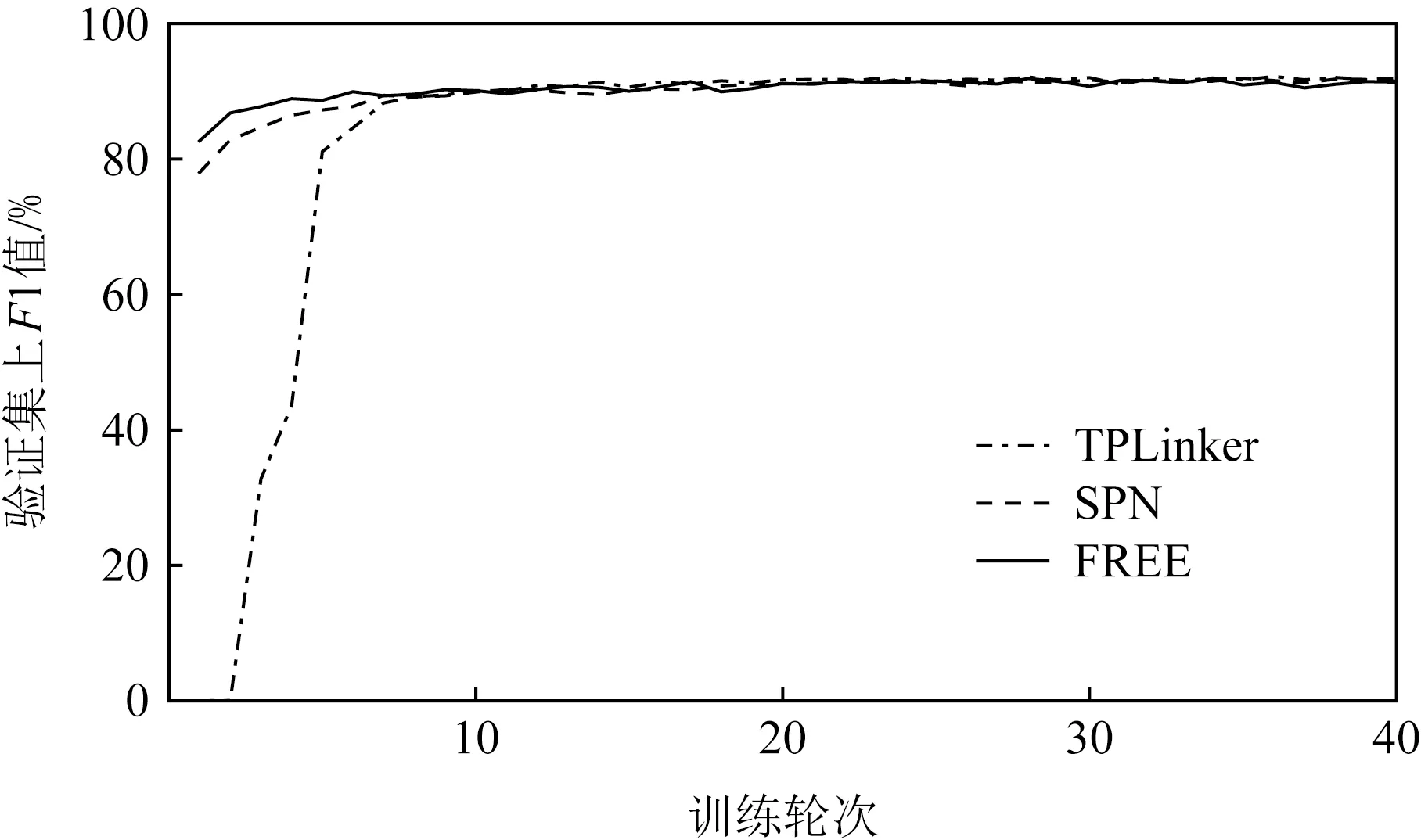
Fig. 6 F1 score of different methods on NYT圖6 不同方法在NYT上的F1值
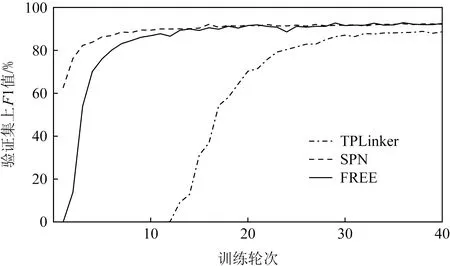
Fig. 7 F1 score of different methods on WebNLG圖7 不同方法在WebNLG上的F1值
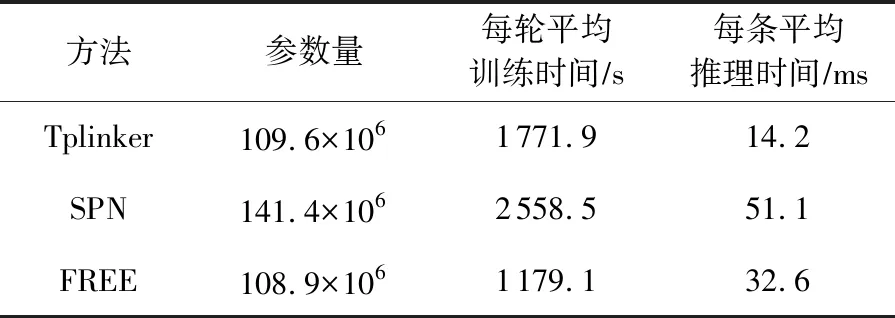
Table 12 Number of Parameters and Training Inference Time of Different Methods in NYT表12 不同方法在NYT上的參數量及訓練推理時間
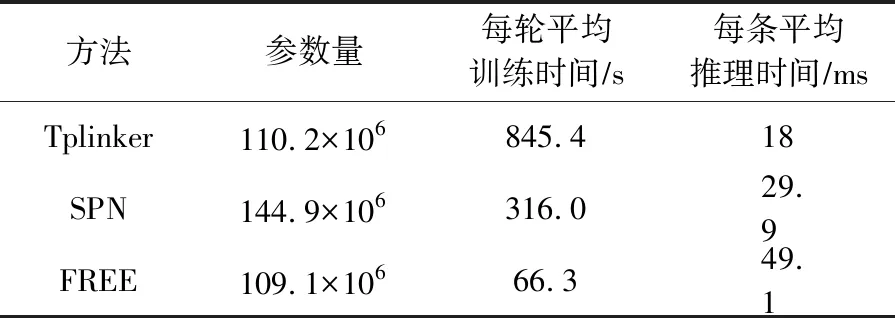
Table 13 Number of Parameters and Training Inference Time of Different Methods in WebNLG表13 不同方法在WebNLG上的參數量及訓練推理時間
針對例句1,CasRelBERT模型由于存在曝光偏差所帶來的誤差累積和過擬合于頻繁出現的標簽組合問題,導致存在主語Dancer的抽取錯誤進而引起整體三元組的抽取錯誤,同時也無法抽取所有三元組.而本文模型由于融合了關系表達向量,可以正確地抽取所有頭實體,并基于此抽取出正確的三元組.
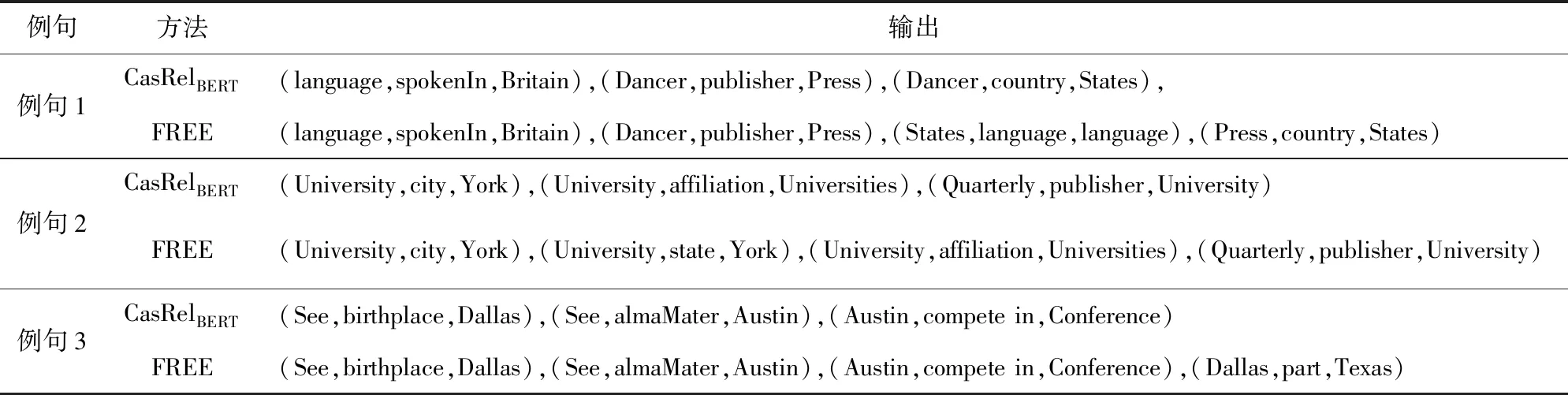
Table 14 The Case Study Results表14 不同方法實例結果
例句1:English is the language in Great Britain and United States. A Loyal Character Dancer was published by Soho Press in the United States.
(language,spokenIn,Britain),(Dancer,publisher,Press),(States,language,language),(Press,country,States)
例句2:Cornell University in Ithaca,New York is the publisher of Administrative Science Quarterly. The University is affiliated with the Association of American Universities.
(University,city,York),(University,state,York),(University,affiliation,Universities),(Quarterly,publisher,University)
例句3:Elliot See was born in Dallas,which is a country in Texas. He attended the University of Texas at Austin,which is affiliated to the University of Texas system. The University of Texas at Austin will be part of the Big 12 Conference competition.
(See,birthplace,Dallas),(See,almaMater,Austin),(Austin,compete in,Conference),(Dallas,partsType,Texas)
在例句2中,由于單詞University涉及到多個三元組,且city與state這2個關系較難區分,CasRelBERT模型只能考慮主語的先驗信息,故此只能抽取部分三元組.而本文模型引入的關系表達信息進一步豐富先驗信息,使得模型可以完整地抽取出所有的三元組.
從例句3的結果中可以發現,所提模型雖然彌補了部分CasRelBERT模型中頭實體識別不完全的問題,識別出了正確的頭實體和尾實體,但由于錯誤識別二者所屬關系類別,因此得到了最后一行錯誤的三元組.本文認為導致該錯誤的原因,一方面是由于句子表達信息的缺失,另一方面是由于沒有將包含尾實體約束的雙向約束考慮在內.未來可以考慮構建雙向約束,進一步提升模型的魯棒性和泛化性能.
4 總 結
現有的聯合抽取模型往往采用階段式的聯合抽取方法,存在嚴重的曝光偏差現象,同時傾向于過擬合頻繁出現的標簽組合,進而影響泛化性能.本文提出了一種名為融合關系表達向量(FREE)的新方法,通過融合關系表達信息來有效緩解曝光偏差問題.此外,提出了一種稱為條件層規范化層的新特征融合層來有效地融合先驗信息.本文在2個公開的實體關系抽取數據集上進行了大量實驗.實驗結果表明,在NYT和WebNLG數據集上分別取得了91.7%和92.5%的F1值.對實驗結果深入分析表明,FREE相較于當前的基線模型具有顯著優勢,可以有效地緩解曝光偏差.本文與其他模型的對比分析發現,本模型在訓練參數用量最少且訓練時間最少的情況下,取得了較好的表現.同時,針對3個具有代表性的例句,進一步觀察和分析本模型與其他模型在三元組抽取結果中的差異.綜上表明,本文方法FREE能夠有效地適應多種三元組抽取任務.
未來將探索詞性、句法依存等額外特征對聯合抽取的影響,同時深入研究頭尾實體的雙向約束以及關系之間的約束機制來進一步提升模型性能.
作者貢獻聲明:王震完成本研究的實驗設計和執行,完成數據分析與論文初稿的寫作;范紅杰指導實驗設計,完成論文寫作與修改;柳軍飛指導實驗設計與數據分析.全體作者都閱讀并同意最終的文本.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
