改進SteGAN的嵌入式圖像隱寫方案
2022-09-01 08:54:34楊忠鵬李啟南
蘭州交通大學學報 2022年4期
楊忠鵬,李啟南
(蘭州交通大學 電子與信息工程學院,蘭州 730070)
在信息安全隱藏領域中,隱寫技術作為提高通信過程中安全性的最主要方式,已成為了近年來在網絡安全領域的熱點研發方向之一.傳統的自適應隱寫術算法可以使嵌入信息對載體圖像中的統計性特征所產生的失真盡可能的較小,但也無法減少在人為設計隱寫術算法時嵌入信息對載體圖像產生的改動痕跡,所以在隱寫術計算仍未可知的情形下,隱寫技術分析可以通過反復檢查,測試隱寫圖像中是否存在著秘密信號.在這樣的過程中,隱寫技術和隱寫分析技術的相互競爭、互補,直接驅動了信息隱藏技術的發展.
隨著計算機硬件的進步,計算機性能逐年提高,而基于計算機性能的深度學習近年來也得到了迅速發展,出現了各式各樣的深度學習模型,如卷積神經網絡、生成對抗網絡等各種神經網絡模型,并在很多領域進行應用,諸如計算機視覺、機器翻譯、數據挖掘等領域都取得了很多成果,解決了很多傳統方法無法處理的問題.因此,研究者們將信息隱寫理論與深度學習相關技術結合起來,使得信息隱寫相關理論技術更為快速地發展,其中與生成對抗網絡的結合尤為密切,其生成對抗的特點與信息隱寫和隱寫分析的對立思想十分相似,這為兩者的結合提供了思路[1].
文獻[2]首次提出了SGAN(steganographic generative adversarial networks)模型,將GAN(generative adversarial networks)應用于圖像隱寫,通過輸入隨機噪聲,生成盡可能真實的載體圖像,嵌入方法使用傳統的1算法實現,最后對載密圖像進行隱寫分析.文獻[3]提出的隱寫生成對抗網絡(steganography generative adversarial network,SteGAN)將編碼-解碼網絡應用到隱寫領域,編碼器負責嵌入信息,解碼器則提取嵌入的信息,并判斷提取信息的準確性,隱寫分析器則對載密圖像的安全性做出評估,但生成圖像使用DCGAN,使得載密圖像生成質量較差.文獻[4]提出使用無載體的隱寫方法來嵌入秘密信息,通過建立一種嵌入信息與圖像類別標簽之間的映射關系,將載體圖像與類別標簽融合,由ACGAN(auxiliary classifier GAN)中的生成器生成載密圖像,而重構秘密信息通過提取載密圖像中的類別標簽來完成,但該方法因其類別標簽數量較少,導致模型的隱寫容量較低.文獻[5]通過將秘密信息映射成噪聲向量,從DCGAN(deep convolution generative adversarial networks)生成的載密圖像中提取輸入噪聲,從而恢復秘密消息,但模型訓練消耗時間與成本大幅增加.文獻[6]在SGAN基礎上,用WGAN(wasserstein GAN)將DCGAN 替換,相較于原始的SGAN,生成的載體圖像質量更好,抗隱寫分析的能力增強,但未對隱寫容量做出提高.文獻[7]將灰度圖像隱藏在彩色圖像中,通過引入對抗模型和新的隱藏位置來提高隱蔽性和安全性,對隱寫信息做出了改變,有效地緩解了梯度消失問題.文獻[8]提出了可以抵抗噪聲等攻擊的隱寫模型HiDDeN(hiding data with deep networks),使用卷積網絡來構造編碼-解碼結構,并且考慮到載密圖像在通信傳輸過程中的安全性問題,在編碼-解碼結構中加入噪聲層進行噪聲訓練,以抵抗噪聲攻擊,但是,將秘密信息轉換成數據時存在維數過大的問題,從而導致隱寫容量最高只能達到0.2位/像素左右.
為解決SteGAN訓練時圖像特征信息丟失,生成的載密圖像質量較差的問題,本文提出基于改進SteGAN的圖像隱寫模型(improved steganography generation adversarial network,ISteGAN),該模型使用密集連接改變SteGAN網絡內的連接方式,加強特征的傳遞,引入注意力機制來獲取圖像深層特征,并在判別器中引入譜歸一化的方法,以此提高模型訓練的穩定性,使得生成的載密圖像更加接近載體圖像.
1 相關算法
1.1 SteGAN
圖1為SteGAN模型圖,SteGAN是一個由生成器(Alice)、判別器(Bob)和隱寫分析(Eve)組成的三方對抗模型.生成器Alice通過融合載體圖像與隨機二進制序列的秘密消息,生成載密圖像,并傳遞給判別器Bob,使其從載密圖像中提取出秘密信息;而Eve則作為隱寫分析器進行竊聽,并判斷接收到的圖像中是否有秘密消息的存在,從而評價隱寫安全性.
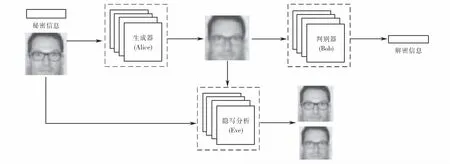
圖1 SteGAN模型圖Fig.1 SteGAN model diagram
在不斷的對抗學習中,Alice學會了在任意的載體圖像中隱藏秘密信息,Bob通過解析Alice的載密圖像使隱寫算法更加成熟,所以它可以準確地恢復信息;而Eve不斷的優化網絡結構,更容易判斷兩種類型的圖像是載體圖像還是隱寫圖像,通過對抗博弈反作用于Alice和bob,使其學習能力不斷提高,在雙方之間達一個納什均衡[9].

SteGAN的信息嵌入過程在訓練生成器網絡時完成,秘密信息的提取過程在訓練判別器網絡時實現,它們各自的損失函數可寫為:
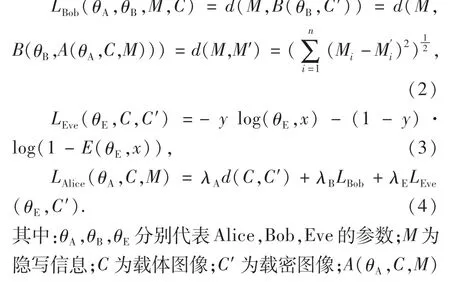

隱寫分析器在模型中起著鑒別分類的作用,它接收載體圖像和載密圖像作為輸入,并從這兩種類型的圖像中判斷該圖像是載體圖像還是載密圖像.
1.2 密集連接
密集連接網絡DenseNet(densely connected convolutional networks)的出現,加強了網絡中特征的流動,從而緩解網絡中梯度消失和網絡退化的問題.DenseNet并不是復雜的公式和模型,它只是簡單的與CNN(convolutional neural networks)連接方式有所不同.CNN采用的是一對一的連接方式,網絡中某層的輸入是前一層網絡的輸出;密集連接則是將之前網絡層輸出的特征圖通過在通道上的連接操作,連接在一起作為該層的輸入,再進行網絡中的操作.密集連接塊將每層網絡提取到的不同程度的特征緊密的連接在一起,使得數據的特征完整的保留下來,使模型學習到更豐富的數據特征[10].密集連接過程如圖2所示,其中:BN(batch normalization)代表批量歸一化層;ReLU(rectified linear unit,ReLU)為激活函數;Conv2D代表卷積層.

圖2 密集連接塊Fig.2 Dense connection module
1.3 譜歸一化原理
基于GAN的深度學習模型訓練較為困難,主要體現在:1)模式坍塌,即最后生成的對象僅有少數幾個模式;2)不收斂,即在訓練過程中,判別器較早就進入了收斂狀態,能很容易地分辨出真假,所以無法使生成器網絡梯度更新而導致訓練無法進行.譜歸一化技術在不破壞矩陣結構的情況下,只需讓每層網絡的網絡參數除以該層參數矩陣的譜范數即可滿足Lipschitz的約束[11].
為了穩定判別網絡的訓練,使其映射函數滿足Lipschitz的約束,引入譜歸一化技術,通常使用SN(spectral normalization)代表譜歸一化,它在計算上既輕便又有效.如式(5)所示,W表示神經網絡的權值,σ(W)是權矩陣W 的譜范數,用它規范判別器網絡的每一層,它等于W 的最大奇異值.
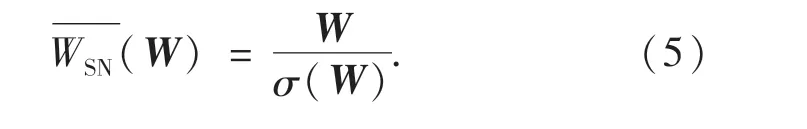
1.4 注意力機制
為了提升模型對載體圖像與秘密信息的關注能力,在網絡結構中結合卷積注意力模塊[11],即通道注意力模塊和空間注意力模塊以串聯的方式組合,使其特征傳遞的過程中,加強對圖像樣本紋理細節的處理能力.
如圖3所示的通道注意力模塊,在圖像特征到達后,通過全局兩個不同的池化操作,分別為最大池化和平均池化對輸入的特征進行壓縮,此時壓縮的特征屬于空間維度上的特征,通過該操作得到兩個不同的描述符;接著經過共享的兩層全連接層的處理,將兩個輸出值進行疊加,經過激活函數處理就得0~1之間的權重系數;將最初的輸入特征圖與權重系數逐元素相乘,完成通道注意力的操作.

圖3 通道注意力模塊Fig.3 Channel attention module
空間注意力模塊結構如圖4所示.在圖4中,與通道注意力相似,依然使用全局兩個池化操作,不同之處在于此時壓縮通道維度上的特征,通過該操作將兩個不同的全局特征描述拼接在一起,同樣的使用卷積將拼接的描述符進行處理,使用激活函數得到空間權重系數;將初始輸入特征圖與空間權重系數相乘,得到新的特征圖,此時的特征圖含有空間注意力.
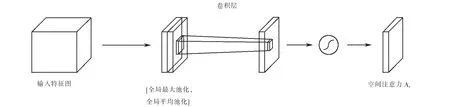
圖4 空間注意力模塊Fig.4 Spatial attention module
2 本文方案
2.1 ISteGAN總體架構
本文改進的模型如圖5所示,使用密集連接來改變SteGAN網絡中生成器與判別器的連接方式,保護圖像信息固有特征的完整性;在網絡之間加入卷積注意力模塊來獲取圖像的深層次特征,減少特征的丟失[12];在判別器中引入譜歸一化的方法,以此提高模型訓練的穩定性.
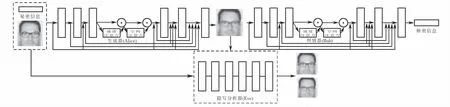
圖5 ISteGAN模型圖Fig.5 ISteGAN model diagram
2.2 生成網絡模型
生成器Alice通過學習來獲取真實樣本的分布,使輸入載體圖像與秘密信息能夠通過微步卷積的方式生成真實樣本.Alice的網絡結構如圖6所示,Alice接受載體圖像與秘密信息作為輸入,將圖像與信息融合,先使用BN層對數據進行歸一化處理,接著連續應用五個具有相同網絡結構層的組.每個組包含密集連接與卷積神經網絡構成的連續卷積層;每個卷積層后面都跟著一個LReLU(leaky-ReLU)激活函數,通過結合密集連接的方式,加強特征傳遞,加速網絡訓練,進一步增強生成器對真實圖像深層次特征的提取能力;而卷積注意力模塊使得網絡獲取到真實圖像的復雜紋理區域特征,從而生成高質量的載密圖像.

圖6 Alice網絡結構圖Fig.6 Alice′s network structure diagram
本文所使用圖像為3×H×W的載體圖像,Alice接受載體圖像與秘密信息后,通過第一層卷積將載體圖像與秘密信息融合,利用網絡第二層中的卷積注意力模塊提取復雜紋理區域特征,而引入密集連接可以保留前面網絡提取到的特征與后面提取到的特征相結合,這樣可以更有效利用圖像特征,得到3×H×W的隱寫圖像.生成器Alice的具體網絡結構見表1.

表1 生成器Alice具體網絡結構Tab.1 Generator concrete network structure
2.3 判別網絡模型
判別器Bob接受來自生成器Alice的載密圖像.圖7Bob網絡使用4個C2D-SN-LR(Conv2D-spectral normalization-leaky ReLU)卷積網絡組合與注意力機制提取圖像特征,并且通過構造譜歸一化的卷積層,使得判別器參數更新更加穩定,減緩了判別器的收斂速度,從而提升了網絡訓練的穩定性.Bob不斷學習優化自己的神經網絡[13],準確的從載密圖像中解析出消息M′,通過與原始秘密信息M比較來判斷Bob的學習能力.

圖7 Bob網絡結構圖Fig.7 Bob′s network structure diagram
隱寫圖像通過Bob的多層卷積后獲得一個與秘密消息M相同大小的M′,同時判別器網絡采用與生成器網絡相同的結構,引入密集連接網絡,保留圖像特征.判別器產生M′,試圖恢復秘密信息M.判別器Bob的具體網絡結構見表2.

表2 判別器Bob具體網絡結構Tab.2 Discriminator Bob concrete network structure
2.4 隱寫分析網絡模型
隱寫分析器Eve的網絡結構如圖8所示,將載體圖像與載密圖像均輸入到該網絡結構中,經過每層的卷積操作(共四層),得到一個判斷該類圖像的概率值.因此隱寫分析網絡的最后一層是含有一個輸出通道的卷積層,其分類任務由Alice影響,不需要加入密集連接與注意力機制,這樣就降低了內存的消耗.隱寫分析器Eve的具體網絡結構見表3.

表3 隱寫分析器Eve具體網絡結構Tab.3 Concrete network structure of the steganography analyzer Eve

圖8 Eve網絡結構圖Fig.8 Eve′s network structure diagram
2.5 信息的嵌入與提取
信息的嵌入過程包含在生成器的訓練中,生成模型由兩部分內容組成:一部分是預處理,另一部分為編碼.預處理部分將嵌入的秘密信息進行轉換,以便與載體圖像進行融合.首先,將載體圖像與秘密信息融合后,利用卷積網絡第一層擴充為三維張量,最后得到32×H×W的特征圖;其次,在嵌入過程中,將每一層的特征向量與預處理后的秘密信息進行拼接,將新得到的張量輸入到下一層的多層編碼網絡,實現載體圖像與秘密信息的融合.
提取模型是判別器模型對載密圖像中每個像素位中嵌入的秘密信息進行提取,這個數據包含每個像素位中的所有數據,并將數據進行平均,得到重構的秘密信息.判別網絡首先通過一個3×3卷積核的卷積層將載密圖像擴充為通道數為32個的特征向量;通過預處理模塊對特征向量映射的數據進行聚集,在空間維度上恢復嵌入數據;最后通過模型的最后的平均池化層和線性層進行映射,將恢復的數據轉換為嵌入的秘密信息.
3 實驗結果與分析
運行實驗的設備為使用64 GB內存的服務器,操作系統為NVIDIA Tesla T4 GPU和Ubuntu 16.04.本實驗數據集采用公共數據集CelebA與Animals-10.CelebA數據集包含10 177個名人身份的202 599張圖像;Animals-10數據集包含10種動物.本文優化器采用Adam,學習率為0.000 2,批大小為32,迭代次數根據需求不同來設置.從四個方面分析載密圖像的性能:不可感知性、隱寫容量、解碼準確率和隱寫安全性.
3.1 隱寫容量
本文隱寫容量的計算公式如式(6)所示.
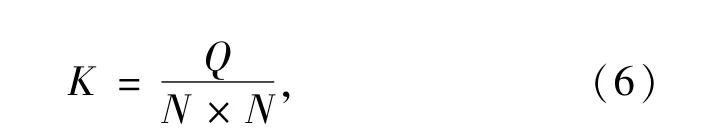
其中:Q為秘密信息(隨機信息)的位數;N為圖像的像素值.
將Q位隨機消息與每個數據集的每個樣本連接起來,改變信息的大小Q,以測試可以有效隱藏在載體圖像中的信息量的極限.采用的數據集由32像素×32像素的圖像組成,當將Q設置為100位到700位時,相當于隱寫容量大約在0.1位/像素到0.7位/像素之間.
ISteGAN與其他模型隱寫容量對比結果見表4.以95%的準確率為閾值,ISteGAN最大容量可以達到0.6位/像素,其他隱寫模型最大容量為0.4位/像素,也就是說,ISteGAN模型嵌入容量相較于其他模型能夠提高50%.

表4 模型容量比較Tab.4 Model capacity comparison
3.2 不可感知性
不可感知性是隱寫術最基本和最直觀的指標,采用均方誤差(mean square error,MSE)反應圖像變化的整體質量,峰值信噪比(peak signal to noise ratio,PSNR)用來比較圖像的壓縮質量,結構相似性(structural similarity index,SSIM)顯示兩個圖像相似性的指標,結合這三種指標來評估圖像質量.MSE越低越好,而PSNR與SSIM越高越好[14],結果見表5.

表5 不同模型的圖像質量評估Tab.5 Image quality assessment based on different models
為了便于與原模型進行比較,使用與原模型相同的迭代次數,均采用500次.從表5可以看出:橫向比較來看,ISteGAN模型在CelebA數據集上表現的更好,尤其是MSE指標,遠小于在Animals-10數據集上的值;縱向比較來看,改進模型的MSE均小于其他模型,ISteGAN模型的PSNR與SSIM均大于其他模型,特別是MSE指標,改進的模型遠低于其他模型,說明了改進模型的有效性.
如圖9所示,隨機選取載體圖像,將其訓練后生成載密圖像,嵌入容量分別為0.4位/像素、0.5位/像素、0.6位/像素和0.7位/像素.
觀察圖9可知:0.7位/像素嵌入容量的載密圖像出現明顯失真,已經沒有使用價值;從0.4位/像素到0.6位/像素圖像不能通過人類的感知系統直接區分載體圖像和載密圖像,說明圖像質量都具有很好的不可感知性,可以選擇0.6位/像素作為嵌入容量的閾值.
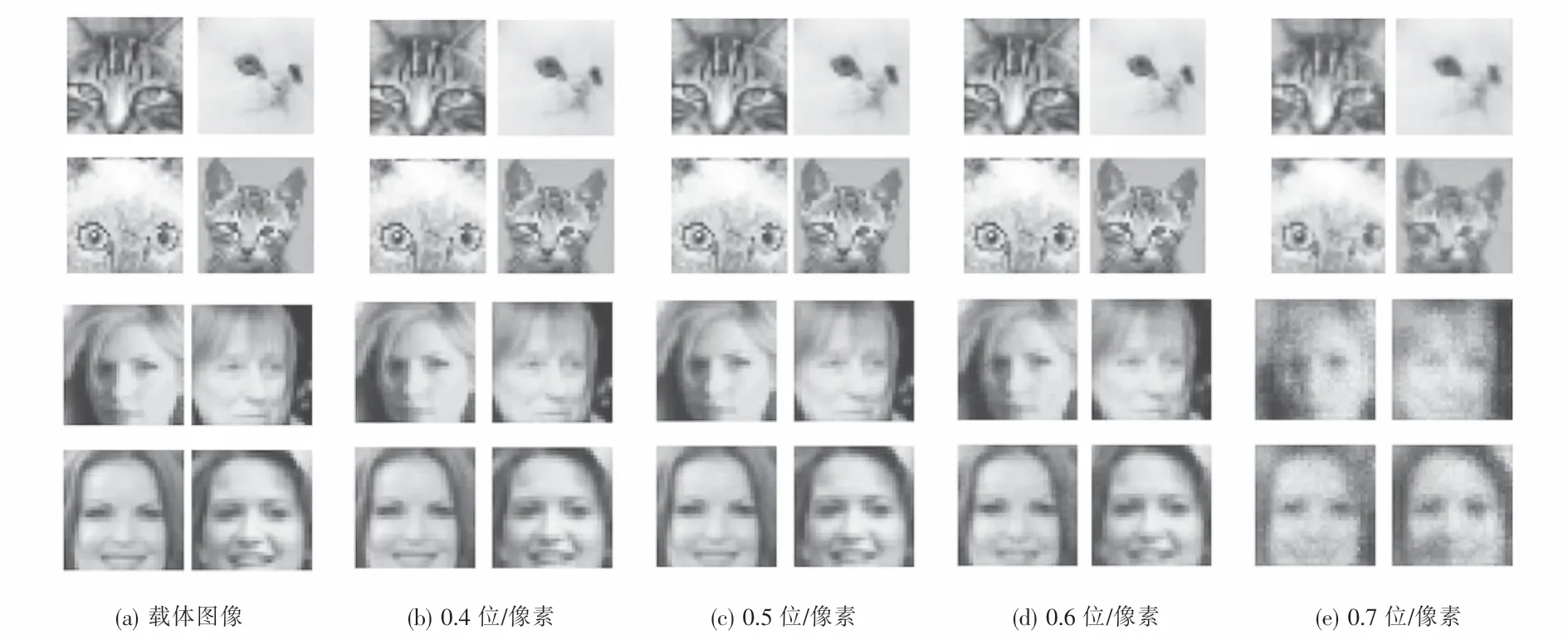
圖9 ISteGAN在不同嵌入容量下的載密圖像Fig.9 Dense load image of ISteGAN under different embedding rates
為了進一步定量確定嵌入容量的閾值,對ISteGAN模型在不同的嵌入容量下進行質量評估,結果見表6.從表6可以看出:和定性分析一致,嵌入容量為0.7位/像素時,圖像的各個指標表現差,說明此時的載密圖像已經沒有使用價值;當嵌入容量為0.6位/像素時,圖像的質量有所降低,但載密圖像依然具有使用價值.因此ISteGAN模型圖像的容量在嵌入容量達到0.6位/像素時達到最大.

表6 ISteGAN模型圖像質量評估Tab.6 Improved SteGAN model for image quality assessment
ISteGAN與SteGAN比較結果見圖10與表7,雙方的模型均在CelebA數據集上生成載密圖像.通過人類的感知系統來看,ISteGAN在嵌入隱寫信息更多的情況下與SteGAN生成的載密圖像沒有區別.

圖10 在CelebA數據集生成的圖像Fig.10 The image generated in the CelebA dataset
進一步通過數據對比來看(見表7),ISteGAN在高嵌入容量的情況下,不可感知性均優于SteGAN,進一步證明改進模型的有效性.
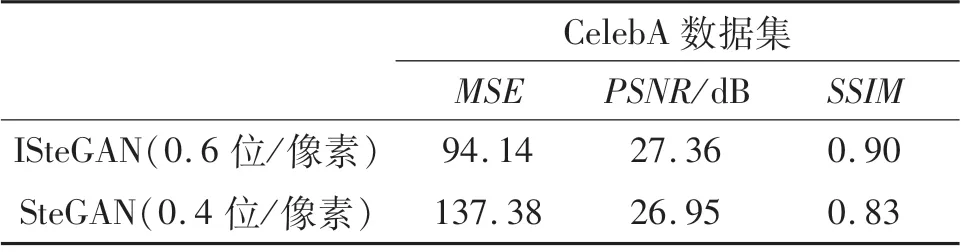
表7 在CelebA數據集上圖像質量評估Tab.7 Image quality assessment on CelebA dataset
從圖11與表8可以看出:在Animals-10數據集上,ISteGAN模型依然可以生成大容量的載密圖像,但是在不可感知性上效果略差于CelebA數據集,這是因為Animals-10數據集使用的均為全身動物圖像,圖像特征分布過多,難以提取,而CelebA數據集均為人臉圖像,圖像特征更容易提取.
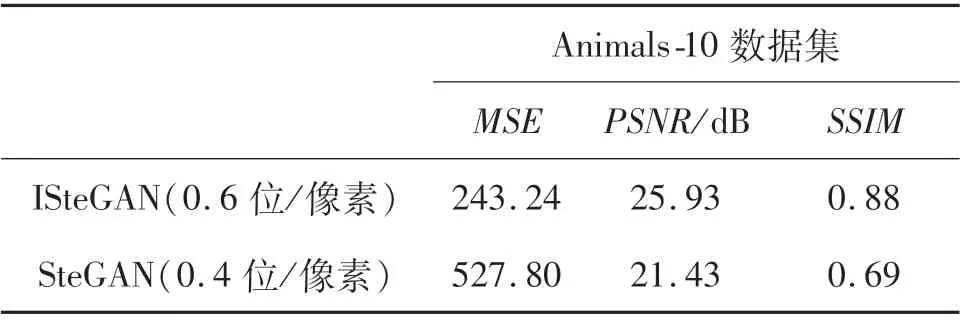
表8 在Animals-10數據集上圖像質量評估Tab.8 Image quality assessment on Animals-10 dataset

圖11 在Animals-10數據集上生成的圖像Fig.11 Image generated in the Animals-10 dataset
3.3 解碼準確率
圖像隱寫的最終目的就是為了安全準確的傳輸信息,所以對于秘密信息接收方來說,信息的準確率尤為重要,ISteGAN在不同的嵌入容量下,Bob解碼準確率如圖12所示.
由圖12可知:隨著訓練次數增加,Bob解碼準確率能夠達到95%以上的準確率閾值,滿足隱寫信息的要求,達到了提高嵌入容量的目標;而且嵌入容量由0.4位/像素增加到0.5位/像素.
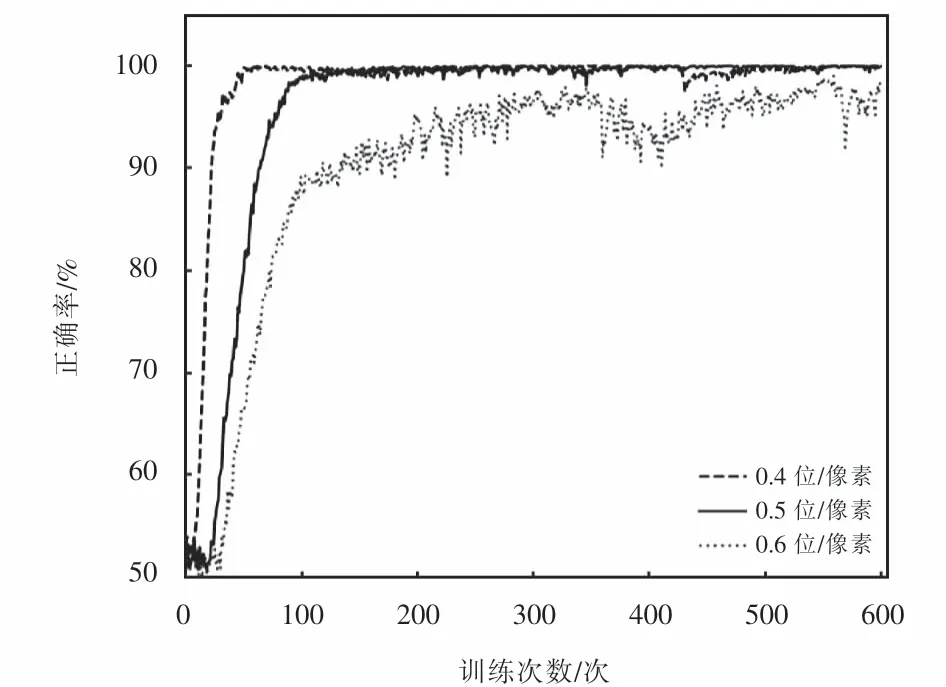
圖12 不同Q值下Bob解碼成功率Fig.12 Success rate of Bob decoding under different Q values
在實際應用中,應根據不同應用場景選擇不同的嵌入容量:在秘密通信應用場景,應選取嵌入容量為0.5位/像素的載密圖像,以降低嵌入容量換取秘密通信100%的安全性;而在圖像隱寫應用場景,則可以選擇嵌入容量為0.6位/像素的載密圖像,通過提高嵌入容量來完成隱寫任務.
3.4 隱寫安全性
傳統的自適應隱寫算法大多通過人為經驗來設計最小嵌入失真代價,去尋找載體圖像中最優的嵌入位置,不僅需要花費大量的時間精力,而且涉及到嵌入后的圖像失真及安全性問題,載體圖像中可選嵌入位置有限[15].現階段基于深度學習的圖像隱寫模型,將秘密信息嵌入到噪聲或紋理復雜區域,使得 隱寫圖像的隱蔽性更強,隱寫分析更加困難.
為了驗證SteGAN生成的隱寫圖像抗隱寫分析性能,本文使用一種開源的隱寫分析工具StegExpose.從CelebA,Animals-10兩個測試集中分別隨機選擇1 000張載體圖像,使用嵌入容量分別為0.4位/像素、0.5位/像素、0.6位/像素的載密圖像,檢測后的結果見表9.
從表9可以看出:使用StegExpose工具僅僅比隨機猜測出隱寫圖像略微有效,這表明ISteGAN模型在進行隱寫安全檢測時可以成功達到檢測標準,滿足信息隱寫算法的可行性,但是在最大的嵌入容量0.6位/像素下檢測率已超過60%,可見本文提出的網絡的抗隱寫分析能力仍然不足.
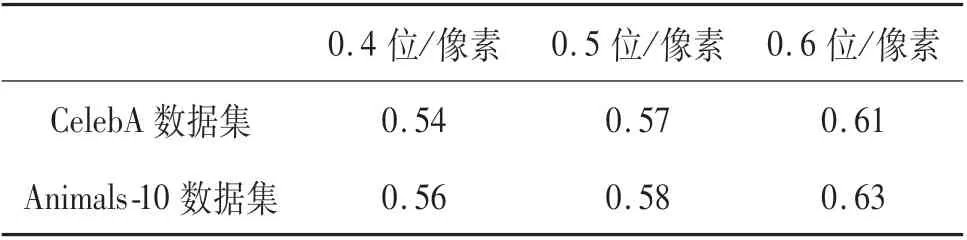
表9 StegExpose在不同嵌入容量下的檢測率Tab.9 Detection rates of StegExpose at different embedded capacities
4 結論
本文利用密集連接來改變SteGAN網絡內的連接方式,加強圖像特征傳遞,并使用卷積注意力模塊獲取圖像的深層次特征,保證載密圖像的質量,并在判別器中引入譜歸一化方法來緩解SteGAN訓練的不穩定性.將原始模型與改進模型進行比較,仿真實驗結果表明:在保證傳輸信息準確性的情況下,載密圖像的不可感知性和隱寫容量均有所提升,隱寫容量從0.4位/像素提高到0.6位/像素,并能有效地抵抗隱寫分析器的檢測;然而,ISteGAN在嵌入容量為0.6位/像素時,解碼成功率僅達到95%,還需要進一步改進,并且隨著圖像隱寫容量提高,圖像的不可感知性與抗隱寫分析性能并沒有提高很多.在今后的工作中,將進一步研究對于載密圖像不可感知性以及抗隱寫分析性能的提高.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
