基于強化學習補償的地面無人戰車行進間跟瞄自適應控制
2022-08-27 09:39:22魏連震龔建偉陳慧巖李子睿龔乘
兵工學報 2022年8期
關鍵詞:動作
魏連震, 龔建偉, 陳慧巖, 李子睿,3, 龔乘
(1.北京理工大學 機械與車輛學院, 北京 100081; 2.北京理工大學 長三角研究院, 浙江 嘉興 314019;3.代爾夫特理工大學 交通與規劃系, 荷蘭 代爾夫特 2628 CN)
0 引言
現代局部戰爭的實踐反復證明,高新技術已經成為現代戰爭的制勝因素。隨著自主智能、網絡協同、云處理等高新技術的發展,作戰模式正在發生重要轉變,以地面無人戰車為代表的無人作戰系統能夠執行多種特殊任務,是應對未來不確定形勢的重要突破口,具有廣泛的應用前景。
在執行打擊任務時,地面無人戰車通常可采取靜態射擊與行進間射擊兩種作戰方式。相比靜態射擊的作戰方式,行進間射擊能夠縮短任務完成時間以提升作戰效率,降低被反裝甲武器命中的概率從而提升戰場生存能力,是地面無人戰車未來發展的重要方向。行進間射擊的關鍵技術之一是跟瞄鏡對目標準確、穩定地跟瞄。現代坦克主流采用穩像式火控系統:火炮與瞄準鏡分別穩定,瞄準鏡對目標實時跟瞄并調動火炮,火控計算機根據跟瞄角速度、目標距離、炮彈彈種、風速等值計算射擊諸元以實現射擊。然而,無論跟瞄系統處于穩像狀態還是自動跟蹤狀態,底盤運動和路面起伏都會對瞄準帶來平移誤差,這給跟瞄控制系統帶來了挑戰。
為提升戰車行進間跟瞄的準確性與穩定性,不同研究人員提出了各自的技術方案。如鐘洲等建立了車載防空導彈的行進和發射一體化多柔性體動力學模型,并分析了路面和車速對防空導彈行進間發射精度的影響,但僅重點關注動力學模型的創建與分析,并未給出合適的控制方法。慕巍等利用光電跟蹤儀、火炮、載體慣導系統、視頻跟蹤器和激光測距機輸出的相關參數,完成瞄準線坐標系下方位速度環和俯仰速度環跟蹤前饋補償參數的計算,以提升對高速目標跟瞄控制的準確性。熊珍凱等針對機動快速目標的跟蹤問題,采用基于當前統計模型的改進卡爾曼濾波算法預測出目標運動狀態參數,并采用自適應滑模的解算控制方法,實現伺服系統的位置控制,提升跟瞄精度。這些方法沒有涉及本車運動狀態的分析,在動對靜、動對動場景受限。郝強等采集目標距離、火炮相對車體角度和車體速度等信息,循環解算瞄準線的補償角速度,減小了跟瞄誤差。但是,該方法僅考慮底盤速度影響,忽略了路面起伏影響,在地形復雜的越野場景中跟瞄補償的效果不佳。張衛民等以自行火炮與敵遭遇時緊急直瞄場景為研究對象,提出一種自行火炮自動直瞄控制方法,以提高火炮直瞄時快速反應能力和射擊精度。然而,該方法側重于瞄準的快速性,沒有充分考慮各種非線性干擾對瞄準穩定性的影響。朱斌等考慮系統內部擾動和外部擾動對穩瞄系統速度跟蹤精度的影響,提出了采用自抗擾的控制方案。不過,該方法側重于穩定性,仍然沒有有效消除底盤運動與路面起伏因素帶來的瞄準線平移誤差。
針對跟瞄控制存在的上述問題,本文從整車角度進行研究,提出一種基于強化學習補償的地面無人戰車行進間跟瞄自適應控制方法。將感知模塊感知得到的地形信息與規劃模塊規劃得到的未來軌跡傳輸至上裝跟瞄控制模塊,上裝跟瞄控制模塊利用Dueling 深度Q網絡(DQN)強化學習算法對這些信息處理后得到補償控制量,以削弱底盤運動與路面起伏對跟瞄的影響,提升戰車跟瞄的準確性與穩定性。首先建立地面無人戰車一體化運動學模型,之后對補償控制方法進行細節性描述,最后利用仿真實驗證明方法的有效性。
1 系統模型
針對地面無人戰車行進間跟瞄自適應控制問題,提出問題場景模型、地面無人戰車一體化運動學模型以及強化學習模型。
1.1 問題場景描述
地面無人戰車行進間跟瞄平面示意如圖1所示。無人戰車接收上級指揮端下發的打擊任務,從起點位置規劃戰車的運動軌跡,而后自主跟蹤運動軌跡并且實時搜索打擊目標,跟瞄系統對可疑目標識別并在自動跟蹤狀態對其瞄準。跟瞄控制的目標是迅速、準確、穩定地減小跟瞄鏡與打擊目標隨動角度誤差。
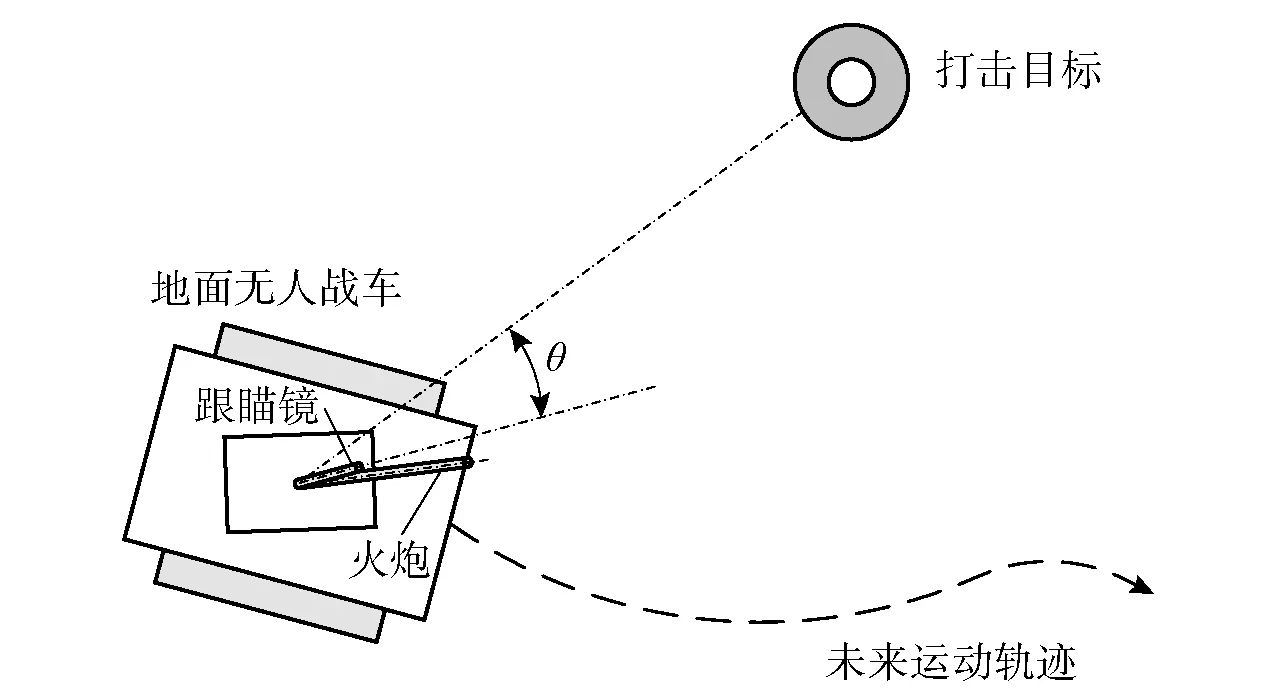
圖1 問題場景描述Fig.1 Problem scenario description
1.2 地面無人戰車一體化運動學模型
地面無人戰車采用履帶式移動底盤,可通過調節左、右兩側主動輪的轉速或轉矩控制整車航向和速度。戰車配備無人炮塔,其中升降式搜索鏡用于識別周圍可疑目標,跟瞄鏡對搜索到的敵方目標實時跟瞄,火炮隨動,而后火控計算機計算射擊諸元,控制火炮在閾值內完成射擊。考慮戰車底盤的平移、俯仰、橫擺、側傾等會對上裝跟瞄與打擊模塊產生影響,基于履帶式無人車運動學模型, 推導出右手坐標系的地面無人戰車底盤與上裝一體化運動學模型,如圖2所示。
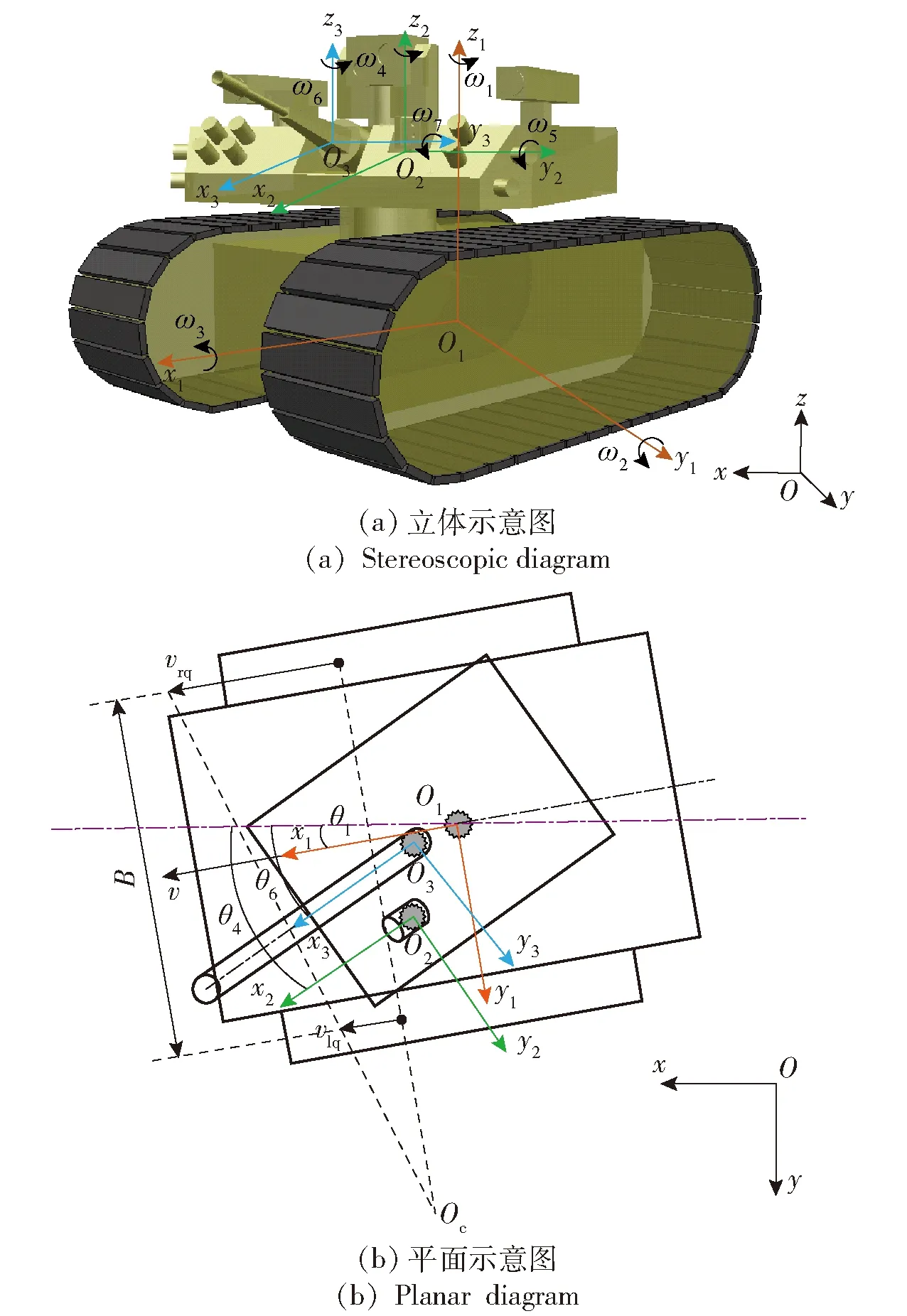
圖2 地面無人戰車一體化運動學模型Fig.2 Integrated kinematics model of unmanned combat ground vehicle
圖2中,為世界坐標系,為底盤坐標系,為跟瞄坐標系,為火炮坐標系。如2(a)中同時給出了可旋轉方向,記代表底盤在世界坐標系中的橫擺角速度,代表底盤在世界坐標系中的俯仰角速度,代表底盤在世界坐標系中的側傾角速度,代表跟瞄鏡在底盤坐標系中的方位角速度,代表跟瞄鏡在底盤坐標系中的高低角速度,代表火炮在底盤坐標系中的方位角速度,代表火炮在底盤坐標系中的高低角速度。圖2(b)中、分別為左、右兩側履帶或驅動輪的牽連速度,為底盤在世界坐標系中的橫擺角,為跟瞄鏡在世界坐標系中的方位角,為火炮在世界坐標系中的方位角,為戰車底盤履帶中心距,為底盤瞬時轉向中心,為底盤運動速度。
由于差速轉向戰車在轉向時,兩側履帶或驅動輪不可避免地會發生滑移滑轉,定義左右兩側的滑移滑轉系數分別為
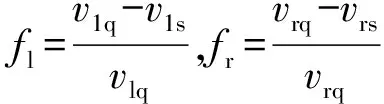
(1)
式中:、分別為左、右兩側履帶或驅動輪相對于車體的卷繞縱向線速度。考慮到滑轉滑移,底盤的運動速度、橫擺角速度分別為
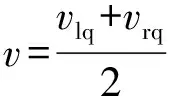
(2)
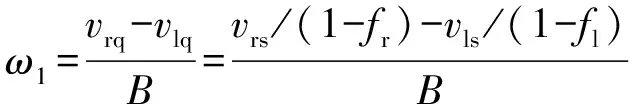
(3)
由上述定義與推導,可得地面無人戰車的數學模型為

(4)
式中:、、、分別為底盤在世界坐標系中的俯仰角、側傾角、跟瞄鏡在世界坐標系中的高低角以及火炮在世界坐標系中的高低角。
1.3 強化學習模型
強化學習是機器學習的一個重要分支,它模擬的是生物學中的行為主義,即自然界中的生物體在一定的正向或負向刺激下,通過不斷學習形成一套應對刺激的策略,從而實現自身利益最大化。強化學習任務通常利用馬爾可夫決策過程(MDP)進行描述,它滿足馬爾可夫性質:系統下一時刻狀態只與當前時刻狀態有關,與過往時刻狀態無關。MDP的基本組成是五元組(,,,,),其中為智能體在交互環境中的狀態集,為智能體在交互環境中對應的動作集,為智能體的狀態轉移概率,為獎勵的折現因子,為智能體在交互環境中采取特定動作的回報獎勵。強化學習過程是智能體從初始狀態開始,不斷從動作集中選取動作進行狀態的轉移,之后利用獎賞函數對選取的動作進行評價從而更新參數直到累計獎勵最大化的過程,核心思想是試錯與學習,具體如圖3所示。
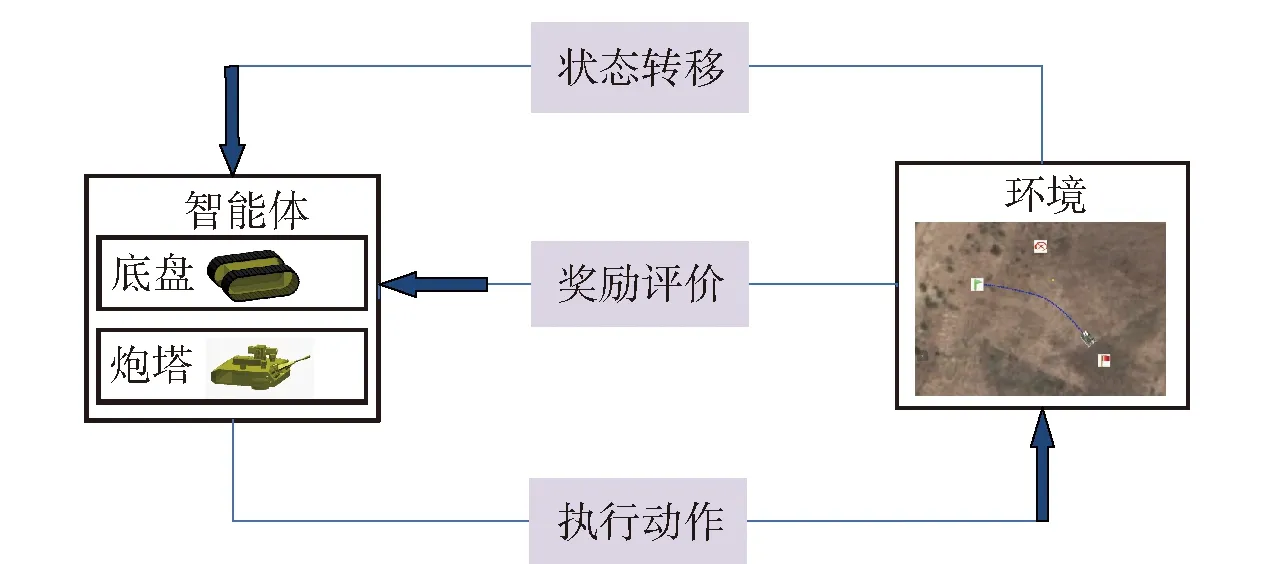
圖3 強化學習過程Fig.3 Process of reinforcement learning
強化學習主體框架包括智能體、環境、動作、獎勵4個內容。本文主要涉及地面無人戰車跟瞄控制方法:由強化學習控制的智能體為地面無人戰車的炮塔;環境指代的是戰車周圍態勢;動作指代的是炮塔方位角控制量、炮塔高低角控制量;獎勵指代的是人為設定的獎賞函數。通過獎賞函數的獎賞值引導智能體進行學習,下面闡述了強化學習模型的基本要素:
1)累積獎勵。智能體每次執行動作后系統都會對該步操作進行評價,該評價值是單步獎勵,累積獎勵是智能體在一個回合之后所有動作單步獎勵的折扣加權和,如(5)式所示:
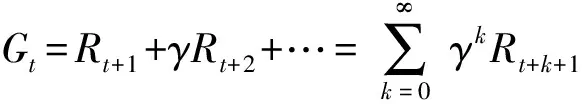
(5)
式中:代表時刻后開始的累積獎勵;+1代表+1時刻的單步獎勵。需要注意的是:累積獎賞實際上是一個隨機變量,對它求期望可以得到價值函數。
2)策略。策略代表智能體在每種狀態下執行某種動作的概率,是狀態空間到動作空間的映射,如(6)式所示:
(|)=[=|=]
(6)
式中:(|)為狀態時執行動作的概率;為時刻可選動作集;為時刻狀態集。
3)狀態價值函數。為評價智能體所在狀態的優劣,需獲得智能體從當前狀態轉移到結束狀態的累積獎勵,在當前狀態下按照一個固定策略求得的累積獎勵期望是狀態價值函數,如(7)式所示:
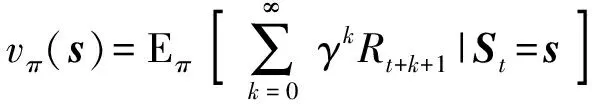
(7)
4)動作價值函數。在當前狀態下執行某個動作后按照某固定策略求得的累積獎勵期望即是動作價值函數,如(8)式所示:

(8)
5)貝爾曼方程。貝爾曼方程是將多層決策轉化為多個決策的動態規劃過程,根據迭代公式求解狀態價值函數與動作價值函數,狀態價值函數與動作價值函數對應的貝爾曼方程分別為
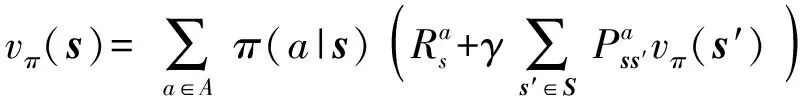
(9)

(10)
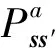
2 控制方法
跟瞄控制問題的核心在于跟瞄系統能夠快速、準確、穩定地對目標實時瞄準,其難點在于目標點運動、己方戰車運動、路面起伏等因素帶來的非線性干擾。針對此,本文提出一種基于強化學習補償的地面無人戰車跟瞄控制方法,以減小跟瞄誤差,提升跟瞄性能。
控制方法架構如圖4所示。PID控制器根據當前跟瞄偏差得到主控制量;Dueling DQN控制器將底盤局部規劃路徑點與目標的相對位置、局部規劃路徑點附近的起伏梯度、車輛運動速度、當前跟瞄誤差等信息作為輸入,利用神經網絡處理得到補償控制量;主控制量與補償控制量加權之和為最終控制量,共包括方位控制量與高低控制量兩個輸出。主控制量保證跟瞄的大致方向性,補償控制量用于對主控制量進行修正,從而提升地面無人戰車行進間跟瞄對底盤速度變化以及路面起伏的自適應能力。需要說明的是:該控制方法得到的控制量是跟瞄系統下一時刻相對轉動的角度增量,并非底層的轉矩控制量。本文中強化學習算法的學習機制與網絡結構能夠針對復雜動態信息分析和處理,并且具備持續學習效果,隨著訓練次數的增多,跟瞄效果的準確性與穩定性可逐步提升。圖4中,、分別為方位角度偏差值與高低角度偏差值,、、、、、分別為方位角和高低角對應的比例、積分、微分權重系數,是方位角增量,是高低角增量。
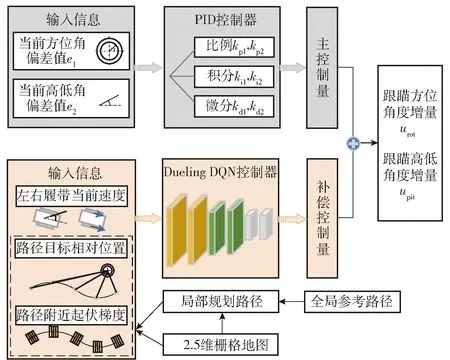
圖4 基于強化學習的補償控制方法架構圖Fig.4 Framework of compensation control method based on reinforcement Learning
戰車對目標的實時跟瞄偏差角度值可以由目標在跟瞄坐標系中位置求解得到,角度計算如(11)式所示:
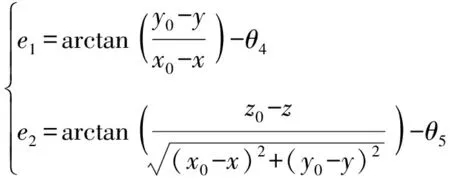
(11)
式中:、、代表跟瞄目標在世界坐標系中坐標;、、代表車輛跟瞄鏡在世界坐標系中坐標。
最終的控制量(當前控制時刻相對于上一控制時刻,其跟瞄方位角度增量與跟瞄高低角度增量)的數學表達如(12)式所示:
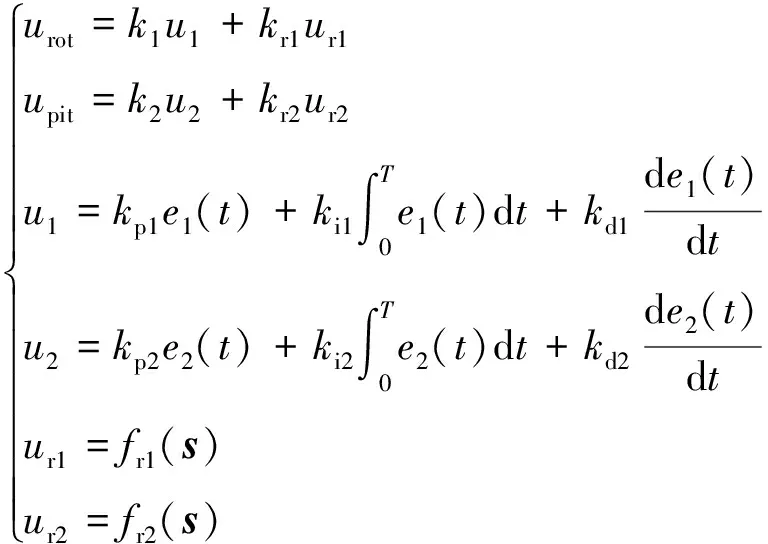
(12)
式中:、分別為方位角和高低角主控制量權重系數;、分別為方位角和高低角主控制量;、分別為方位角和高低角補償控制量權重系數;、分別為方位角和高低角補償控制量;代表積分時間;r()、()分別為強化學習神經網絡擬合的方位角和高低角非線性函數。
本文采用的強化學習算法參考了Dueling DQN算法思路,它屬于值迭代算法的一種,是基于傳統DQN算法的一種改進算法,如圖5所示。圖5中,()代表第條數據對應的誤差值,代表一次性處理的數據條數。
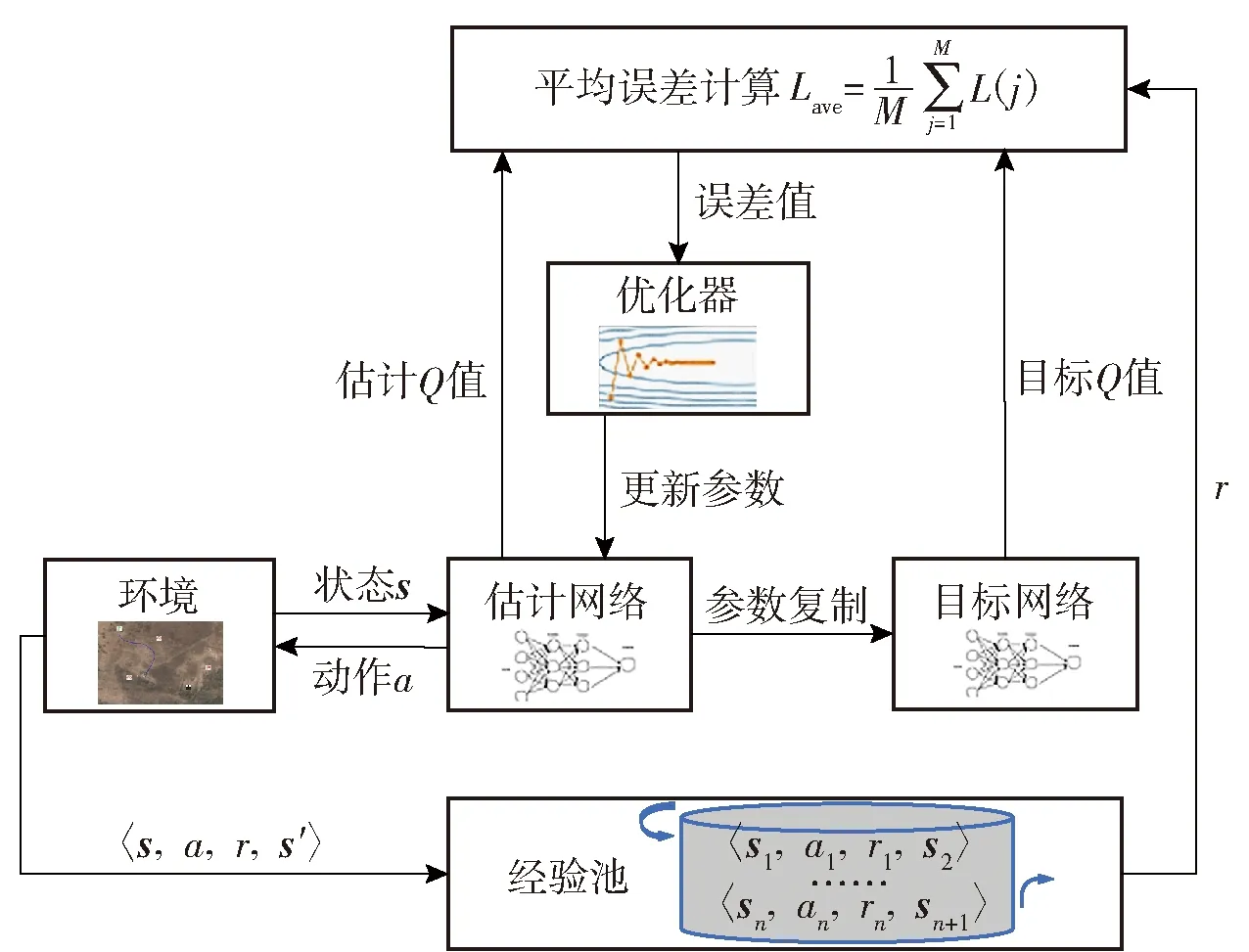
圖5 強化學習算法思路圖Fig.5 Algorithm diagram of reinforcement learning
圖5中,估計網絡與目標網絡在網絡結構上一致,區別在于估計網絡實時更新參數,目標網絡非實時更新,算法值計算如(13)式所示:
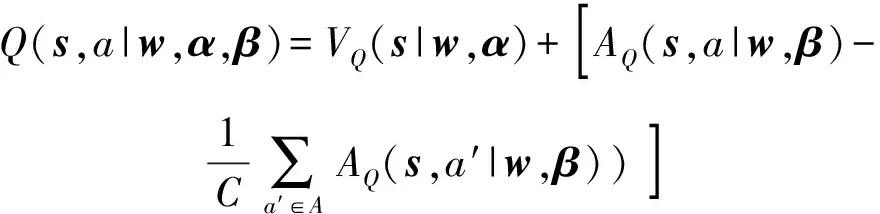
(13)
式中:(|,) 為狀態值函數,用于衡量狀態價值,僅與狀態有關,為公有網絡參數,為狀態值函數特有網絡參數;(,|,)是動作優勢函數,用于衡量不同動作相對于所處狀態的價值,同時與狀態以及動作有關,是動作優勢函數特有網絡參數;為離散動作空間元素個數。
本文中使用的神經網絡結構如圖6所示,其中方位角度補償控制網絡與高低角度補償控制網絡類似,區別在于神經網絡的輸入信息、輸出信息以及神經元個數。方位角度補償控制網絡的輸入為底盤局部規劃路徑點與目標的相對位置、左右履帶速度、方位跟瞄誤差;高低角度補償控制網絡的輸入為局部規劃路徑點附近的起伏梯度、左右履帶速度、高低跟瞄誤差。其中,路徑附近起伏梯度指的是“一定數目的未來路徑點以及對應的左右偏移路徑點集合”前后相鄰點之間高度差值構成的矩陣。輸入信息先經過若干層全連接層,之后分為狀態值網絡以及動作值網絡,最后得到每種動作對應的值。此外,本文對部分全連接層進行了處理,即在訓練階段隨機將部分神經元丟棄從而削弱訓練中的發生過擬合現象。
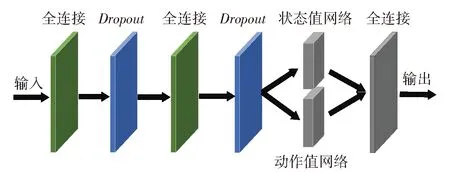
圖6 Dueing DQN神經網絡結構圖Fig.6 Structure of Dueing DQN neural network
程序訓練過程:先隨機探索一定步數以獲得多組數據并將其存儲在經驗池中,每一次從經驗池中抽出若干條數據并不斷更新網絡參數值,直至模型滿足要求或訓練次數達到閾值。Dueling DQN算法是通過最小化時序差分誤差實現網絡更新,其數學表達如(14)式所示:
=(+max′′(′,′|′,′,′)-
(,|,,))
(14)
式中:′代表下一狀態的目標值。因實際進行參數更新是同時對若干條數據進行處理,平均后的誤差值如(15)式所示:
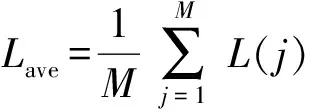
(15)
利用TD誤差對網絡參數的更新原理是借助梯度下降算法,本文在實驗時采用了Adam優化器實現參數梯度下降,相比傳統的隨機梯度下降算法能夠更快地實現參數收斂。
3 仿真實驗與結果分析
3.1 V-REP三維仿真實驗設置
底盤運動是影響地面無人戰車行進間跟瞄誤差的一個重要非線性干擾,當速度大小或者速度方向發生變化時會對跟瞄的穩定性產生影響,即使戰車保持勻速直線運動,也會對戰車跟瞄帶來瞄準線的平移。路面起伏是影響地面無人戰車行進間跟瞄誤差的另一個重要非線性干擾因素。基于單獨PID控制的跟瞄算法不能對戰車未來階段的起伏信息進行預判,這種被動跟隨控制策略在起伏路面時跟瞄效果不佳;并且,由于路面起伏的復雜性,傳統的前饋補償方法難以針對性開展設計。本章基于V-REP動力學仿真軟件進行強化學習網絡參數訓練與測試,通過觀察訓練過程中獎賞值的上升和對比單獨PID控制方法與補償控制方法跟瞄誤差角數值來驗證本文提出的補償控制方法有效性,仿真實驗流程如圖7所示,仿真軟硬件環境如表1所示。
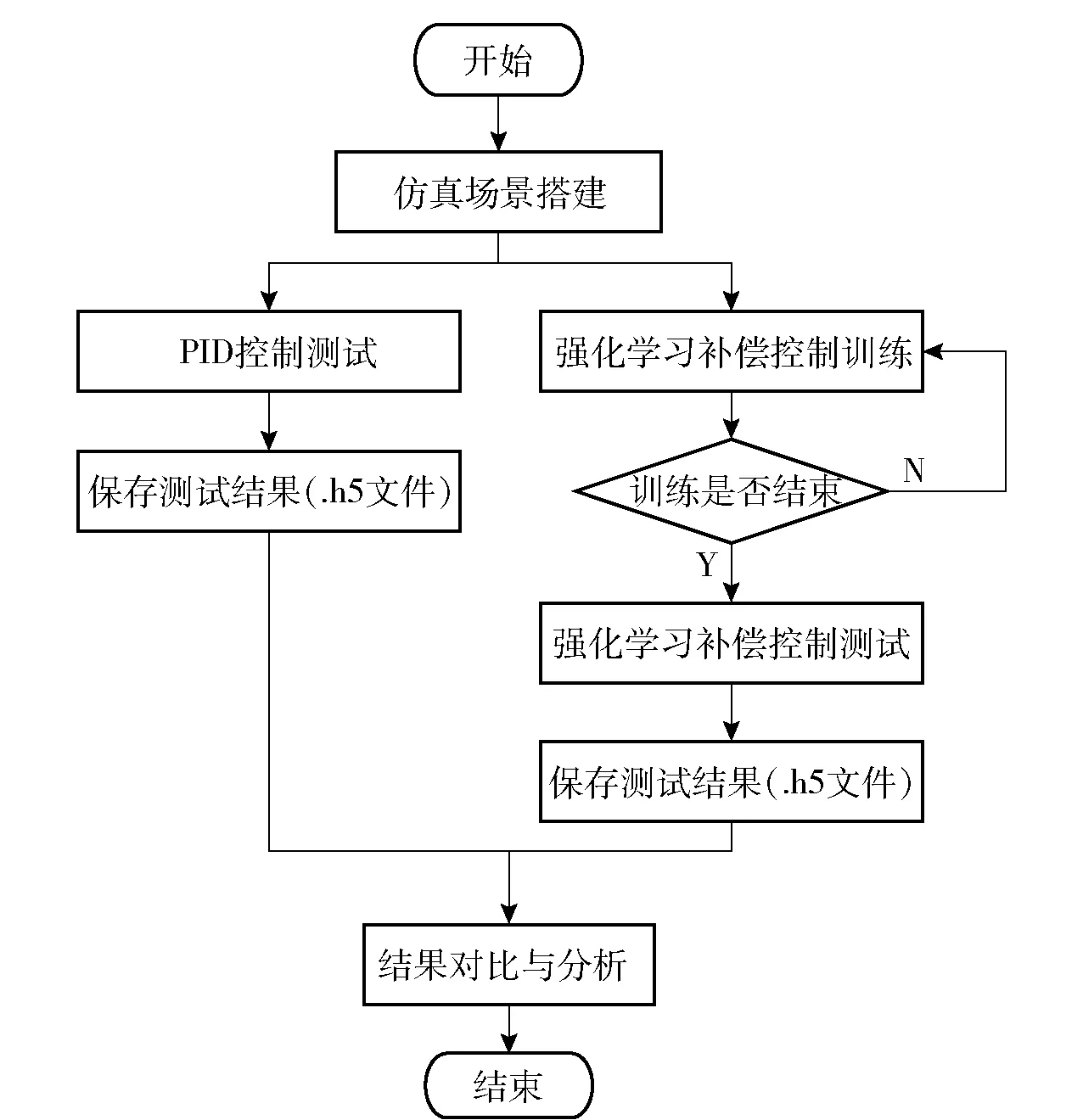
圖7 仿真實驗流程圖Fig.7 Flow chart of simulation

表1 仿真軟硬件環境
為在V-REP動力學軟件中搭建路面起伏環境,采用Perlin噪聲算法構建近似于自然環境的起伏路面,并將地形文件、車輛模型、打擊目標導入V-REP仿真軟件,再利用ROS接口實現與程序端的通信,最終完成起伏路面仿真環境搭建,如圖8所示。仿真中設定車輛運動速度為15 km/h,方位角速度閾值為40°/s,高低角速度閾值為40°/s。設計兩個強化學習神經網絡分別對方位角與高低角進行補償控制,強化學習的基本信息如表2所示。
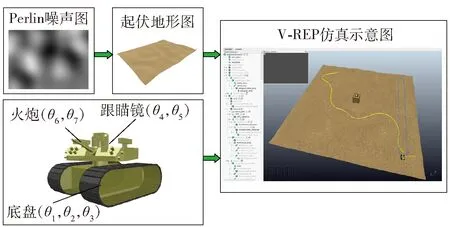
圖8 三維仿真環境搭建過程Fig.8 Construction process of 3D simulation environment

表2 強化學習基本設置
3.2 實驗結果分析
由表2可以看出,獎賞函數是關于目標跟瞄角誤差值的二次函數,當誤差角越小時對應的獎賞值越大,因此可通過觀察訓練過程中獎賞值變化分析跟瞄效果。圖9繪制出了無人戰車從起始位置自主運動到目標位置的前500次訓練過程中高低角網絡平均獎賞值的變化情況,為便于觀察進行了均值濾波。由圖9看出:隨著訓練次數地增多,平均獎賞值呈現整體上升的趨勢,這代表Dueling DQN控制器對于跟瞄誤差補償效果隨著訓練增多而提升。

圖9 平均獎賞值變化圖Fig.9 Variation diagram of average reward values
地面無人戰車在從起點位置到終點位置的運行中,不同跟瞄控制方法對應的跟瞄角度誤差均值能夠反映控制效果的好壞。
將戰車從跟瞄穩定位置到終點位置運動過程中上裝跟瞄角度誤差的變化情況進行記錄,并對比基于PID控制與強化學習補償控制兩種方法的跟瞄角度誤差變化情況,對比結果如圖10所示,其中圖10(a)為方位角度誤差變化,圖10(b)為高低角度誤差變化。由圖10可知:基于強化學習補償的控制方法平均跟瞄誤差明顯更小,控制效果更優。
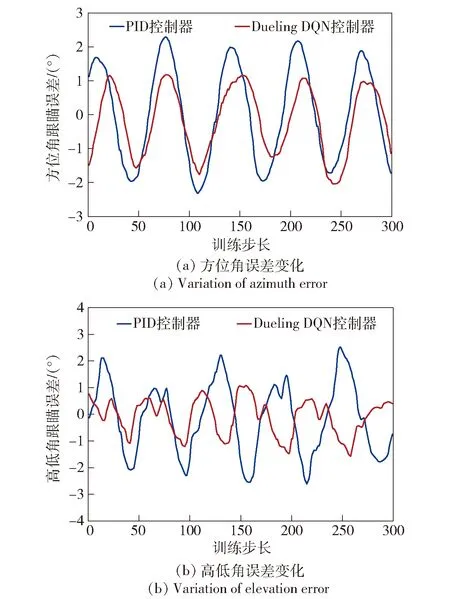
圖10 跟瞄角誤差變化圖Fig.10 Variation diagram of tracking/aiming error
4 結論
本文提出一種基于強化學習補償的地面無人戰車行進間跟瞄自適應控制方法,有效地提升了地面無人戰車的動態作戰性能。首先建立地面無人戰車一體化運動學模型以及強化學習模型,然后具體介紹了基于強化學習補償的跟瞄控制方法架構,最后基于V-REP動力學仿真軟件進行了控制方法效果對比,得出結論:強化學習補償能夠較好地削弱速底盤運動以及路面起伏對上裝跟瞄的非線性干擾。不過,目前的工作仍是初步的:1)在跟瞄系統建模方面采用了簡單運動學模型,后續會針對該模型進行完善并深入分析底盤運動與路面起伏對跟瞄性能的影響特性;2)后續將補充開展與上裝載荷任務相協同的底盤運動規劃研究。
猜你喜歡
作文周刊·小學一年級版(2022年16期)2022-05-07 11:28:30
作文周刊·小學一年級版(2021年8期)2021-07-07 11:00:47
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語文·低年級(2014年10期)2015-01-14 14:46:27
