基于殘差融合網絡的定量磁敏感圖像與T1加權圖像配準①
2022-08-25 02:51:08田梨梨程欣宇王麗會
計算機系統應用 2022年8期
關鍵詞:模型
王 毅, 田梨梨, 程欣宇, 王麗會
(貴州大學 計算機科學與技術學院 貴州省智能醫學影像分析與精準診斷重點實驗室, 貴陽 550025)通信作者: 程欣宇, E-mail: ai.cxy@qq.com
1 引言
醫學圖像配準是醫學圖像分析處理任務中最基本的步驟, 是指通過對一幅圖像經過一系列的幾何變換,使變換后圖像與參考圖像處于相同的坐標空間, 以達到兩幅圖像中相同的組織結構在空間位置上一一對齊.配準算法的配準精度和配準效率將直接影響后續的醫療診斷分析和研究結果. 因此, 研究快速、精準的醫學圖像配準算法具有重要的理論意義和臨床實用價值.
傳統的配準算法框架主要包含4個部分[1]: 特征空間、搜索空間、搜索策略和相似性度量. 特征空間是指從參考圖像和浮動圖像中提取可用于配準的特征;搜索空間定義了圖像變換的范圍和方式, 即線性變換或非線性變換; 搜索策略是指采用合適最優化算法在搜索空間中尋找最優的配準參數; 相似性度量用于評估每次變換結果的優劣, 為搜索策略的搜索方向提供依據. 在此基礎上, 已有大量的配準算法被提出并被廣泛用于實際臨床應用, 如SyN[2]、Demons[3]、FSL[4]等.盡管這些配準算法都能取得較好的配準效果, 但是都面臨著一個共同的問題: 對于每一對待配準圖像對, 傳統配準算法均需要從零開始迭代優化目標函數, 嚴重影響了配準效率[5], 難以滿足臨床實時的配準需求.
近年來, 深度學習技術被廣泛應用于醫學圖像配準. 目前, 基于深度學習的配準技術主要被分為兩大類:有監督學習配準算法和無監督學習配準算法. 有監督學習配準算法是利用已知幾何變換的待配準圖像對訓練網絡, 并通過計算網絡估計的幾何變換和已知幾何變換的均方誤差 (mean squared error, MSE) 更新網絡的權重參數. 如Miao等人[6]在ConvNet的最后一層設計一個回歸器去預測二維X光和三維CT圖像的剛性配準參數, 解決了現有基于灰度的二維/三維配準算法速度慢、捕獲范圍小等兩個缺陷. 不同于回歸的方法,Yang 等人[7]采用已知幾何變換的待配準圖像對訓練深度編解碼網絡, 使其能夠精準預測大變形微分同胚度量映射 (large deformation diffeomorphic metric mapping, LDDMM) 配準模型[8]中的動量, 隨后通過貝葉斯概率網絡求得DVF. Sokooti等人[9]則直接使用多尺度ConvNet去估計待配準圖像對的DVF, 而無需將幾何變換約束至具體的配準模型. 一些作者也嘗試利用ConvNet估計薄板樣條模型[10]的參數, 如Cao等人[11]和Eppenhof等人[12], 他們分別使用模板樣條模型實現了大腦MRI圖像和胸部CT圖像的可變形配準. 與傳統配準算法相比, 有監督學習配準算法極大地提高了配準效率, 但這類方法的配準性能十分依賴帶有標簽的訓練數據. 然而, 獲得帶有標簽的醫學圖像數據成本非常高, 并且標記信息通常利用傳統配準算法獲得或者人工合成, 并不精準, 因此, 限制了有監督配準算法的發展.
基于無監督學習的配準算法不需要任何標簽, 其通過最小化給定的損失函數約束神經網絡預測最優的DVF. Jaderberg等人[13]提出的空域變換網絡 (spatial transformer network, STN) 因其能對圖像重采樣并且可微而極大推動了無監督配準算法的發展. 自STN提出后, 大量無監督配準算法涌現出來. 如Balakrishnan等人[14]提出了一個優秀的無監督配準框架VoxelMorph,該框架使用一個類似Unet的架構估計稠密的DVF, 然后在訓練過程中借助STN模塊對浮動圖像重采樣, 并通過計算重采樣后的圖像和參考圖像的相似性度量指導網絡訓練, 最終在Dice分數評價指標上取得了與SyN配準算法相當的精度. Zhao等人[15]和Tang等人[16]基于VoxelMorph分別設計了無監督配準框架VTN (volume tweening network) 和 ADMIR (affine and deformable medical image Registration), 他們均在可變形網絡框架中新增仿射預配準模型, 使得網絡能夠同時執行仿射配準和可變形配準, 真正地做到端到端配準. 但是他們也存在區別, VTN框架能夠級聯多個可變形配準的子網絡, 遞進式提高配準性能. 實驗結果證明了級聯策略能夠處理大位移形變, 提高配準的精度. 除了模型上的創新, 一些學者也致力于探索幾何變換映射的微分同胚性質. 如Zhang[17]提出使用逆一致正則化項來約束相應逆映射的差異, 并在損失函數中引入逆一致性損失和防折疊損失來保證DVF的平滑屬性. Mok等人[18]使用類似SyN算法的思想, 利用ConvNet輸出一對微分同胚映射, 用于將兩幅圖像從兩條測地線映射到兩幅圖像的中間地帶, 實驗結果表明, 該方法能夠獲得平滑且拓撲保持的DVF.
盡管無監督學習配準算法不需要標簽數據, 并且在多個數據集上也取得了十分優秀的配準性能, 但仍存在以下問題: 1)現存的大多數無監督配準算法僅能配準單模態圖像, 在多模態圖像配準上, 性能低下, 且針對QSM圖像和T1加權圖像的配準算法仍鮮見報道. 2)現存的配準算法大多采用全局相似度量如MSE、NCC (normalized cross-correlation)、NMI (normalized mutual information)[19]來驅動網絡學習, 但這些相似性度量并不適用于衡量QSM圖像和T1加權圖像的相似性, 難以驅動網絡學習.
為了解決以上問題, 本文設計了RF-RegNet用于QSM圖像和T1加權圖像配準, 通過編碼金字塔提取QSM圖像和T1加權圖像特征, 兩個解碼器分別用于估計圖像對之間的局部和全局幾何形變, 最后利用局部特征相似損失和DVF的正則化共同指導網絡模型訓練, 完成高效精確地配準.
2 RF-RegNet配準方法
分別定義F,M為在n維空間? ?Rn的參考圖像和浮動圖像, 圖像配準旨在尋找到一個最優的變形場使得浮動圖像與參考圖像處于同一空間并且相同的組織結構在空間位置上一一對齊. 這一過程可表示為式(1):
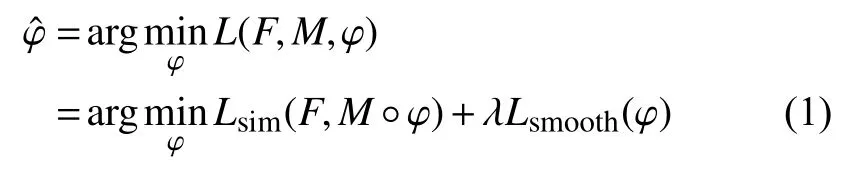
其中,M°φ 代表浮動圖像經過變形場φ 重采樣后所得到的圖像,Lsim(·,·)函數用于衡量兩幅圖像之間的相似性,Lsmooth(·)函 數用于約束變形場平滑, λ為兩個函數之間的平滑系數. 傳統配準算法通過優化每對配準圖像的目標函數尋找最優變形場, 盡管能夠取得較好的配準效果, 但也極大地影響了配準效率. 本文通過深度卷積模型共享全局參數尋找最優變形場來代替特定配準對的優化過程, 這意味著只要深度卷積網絡模型一旦收斂, 輸入任意待配準圖像對均能快速精準得到最優的變形場, 這一過程可表示為:

其中,f代表深度卷積模型學習到的映射函數, θ為網絡模型參數即卷積神經網絡每層的核權重系數. 通過最小化損失函數指導網絡訓練, 以求得最優網絡權重參數本文在U-Net網絡結構的基礎上, 設計了RF-RegNet實現快速精準的T1加權圖像和QSM圖像配準, 配準框架如圖1所示. RF-RegNet的核心架構由一個編碼金字塔和兩個解碼器構成, 編碼金字塔用于提取圖像的細節特征, 兩個解碼器分別用于估計圖像對之間細小結構區域、紋理細節的局部形變和大腦整體形狀、位置、大小、角度等全局形變, 通過結合局部形變和全局形變得到最優的變形場, 隨后利用重采樣層對浮動圖像進行重采樣得到配準后的圖像, 并通過計算重采樣后的圖像和參考圖像的特征相似性驅動網絡學習.
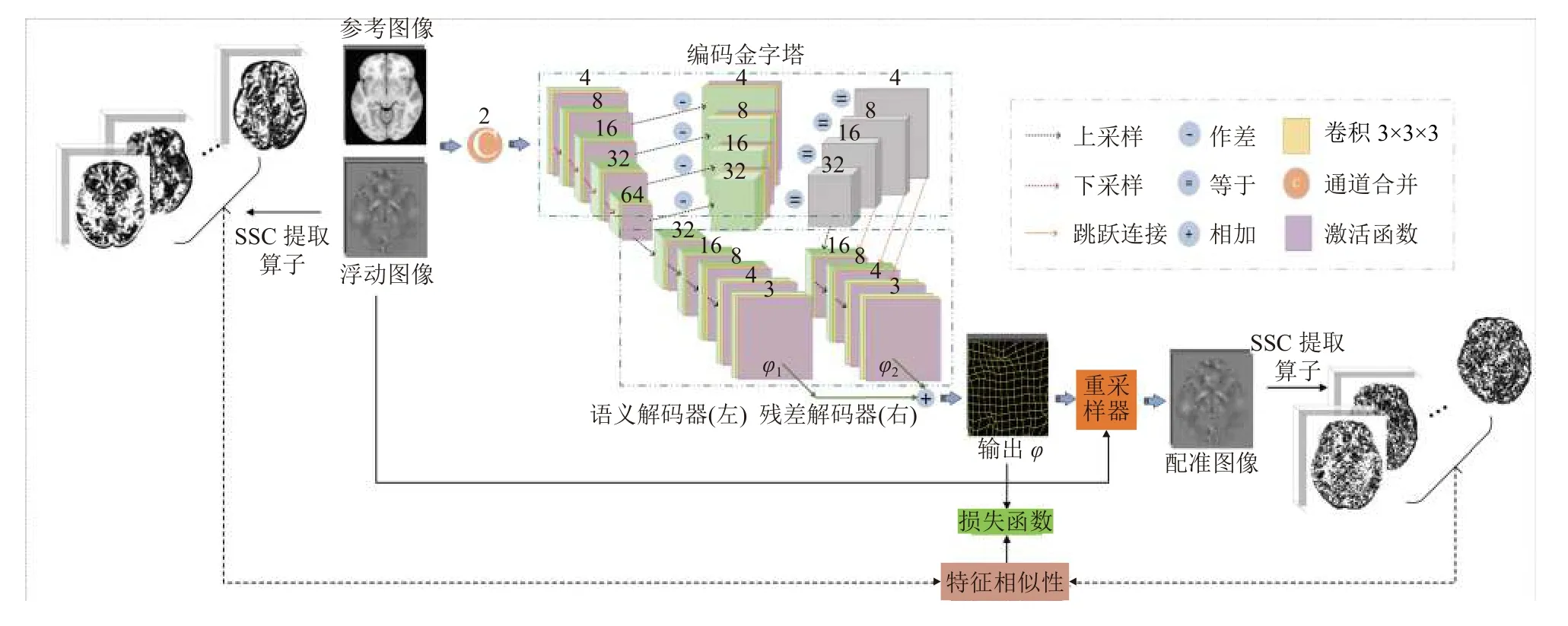
圖1 RF-RegNet配準框架圖
2.1 編碼金字塔
編碼金字塔結構類似于拉普拉斯金字塔, 它是由一系列殘差圖像L0,L1,···,Ln-1組成, 每一層圖像均是高斯金字塔兩個層次之間的差異, 如圖2所示.
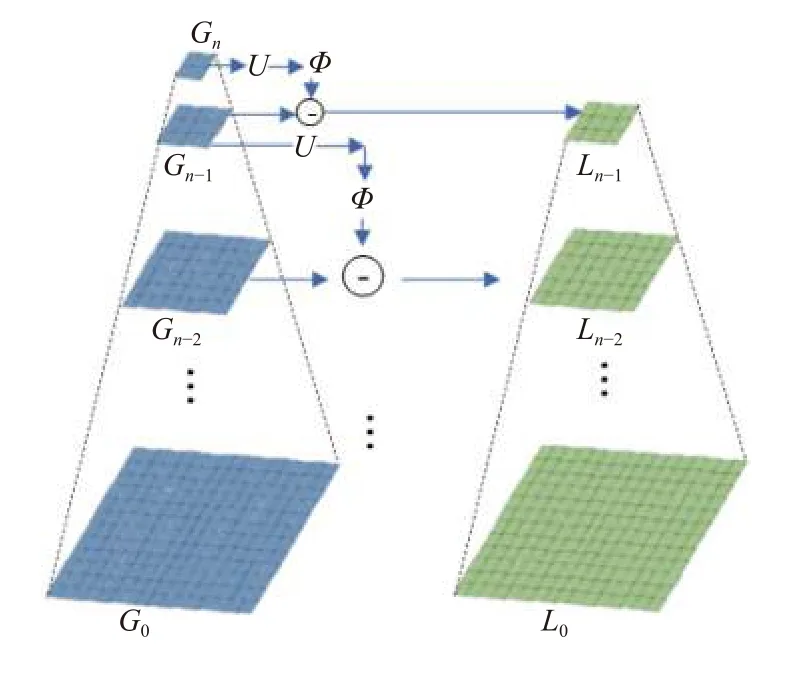
圖2 編碼金字塔網絡結構
構建高斯金字塔是構建拉普拉斯金字塔的前提,高斯金字塔是通過對原始圖像逐級高斯濾波再下采樣得到的, 圖2中G0表示初始圖像(i=0),Gi表示第i(1≤i≤n)次高斯濾波并下采樣得到的圖像, 高斯金字塔的計算過程如式(3)所示:

其中, Φ表示高斯濾波算子,D表示下采樣操作. 拉普拉斯金字塔每一層Li是由高斯金字塔中每一層圖像Gi+1經 過上采樣、濾波之后與上一層圖像Gi相減得到,這一過程被描述為:
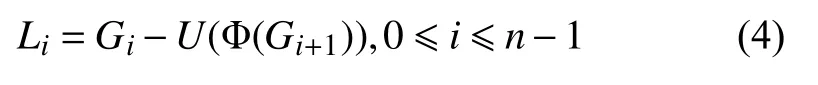
其中,U表示圖像上采樣操作. 原始圖像經過下采樣后壓縮了圖像信息, 在去除噪聲的同時也保留了部分圖像特征信息, 但是將圖像經過上采樣, 往往通過插值填補缺失的像素值, 導致難以完全恢復至原始圖像. 拉普拉斯金字塔通過差值將丟失的信息記錄作為圖像特征,能夠捕獲圖像的細節和邊緣特征, 因此被廣泛用于圖像融合、圖像重建等領域.
本文使用可學習的卷積核代替編碼金字塔中的高斯核, 讓本文所提出的編碼金字塔不僅能夠捕獲待配準圖像對的紋理細節差異, 還能夠捕獲大腦微小結構的特征差異. 編碼金字塔由語義編碼和殘差編碼兩部分組成, 其中, 語義編碼部分將參考圖像和浮動圖像堆疊形成一個二通道圖像作為輸入, 并通過一個步長為1、4個卷積核為3 ×3×3的卷積對其進行卷積運算, 再經過一個LeakyReLU激活函數得到初始特征圖, 記為S0. 隨后再通過步長為2、卷積核為3 ×3×3的步幅卷積和LeakyReLU激活函數逐級下采樣, 以捕獲不同特征圖下的全局語義信息. 語義編碼階段共經過4次下采樣, 每次下采樣均使得圖像尺寸減半, 圖像通道數增加一倍, 將經過下采樣得到的圖像分別標記為Si,i=1,2,3,4, 如圖1編碼金字塔中左半部分所示. 殘差編碼部分使用步長為2、卷積核為3 ×3×3的反卷積和Leaky-ReLU激活函數將語義編碼器所獲得的特征圖Si,i=1,2,3,4 進行上采樣得到Ui,i=1,2,3,4, 隨后與對應的上一層特征圖Si,i=0,1,2,3做 差值得到差分特征圖像Dk,k=1,2,3,4 即Dk=Sk-1-Uk,k=1,2,3,4, 如圖1編碼金字塔中右半部分所示.
2.2 殘差解碼器和語義解碼器
醫學圖像配準的目標旨在尋找最優的像素級幾何形變參數, 需要將編碼金字塔學習到的特征映射至像素空間, 因此本文使用與語義編碼器和殘差編碼器對應的語義解碼器和殘差解碼器去完成這一過程. 語義解碼器和殘差解碼器均是通過步長為2、卷積核為3×3×3的反卷積和LeakyReLU激活函數完成上采樣操作, 但不同于語義解碼器, 殘差解碼器利用跳躍連接層融合了殘差淺層特征和殘差深層特征, 加強密集預測. 在語義解碼器和殘差解碼器的最后一層均使用一個步長為1、3個核為3 ×3×3的卷積回歸出像素級的幾何形變參數, 即DVF. 最后, 將分別得到的局部DVF與全局DVF相加得到最終的DVF, 如圖1解碼器部分所示.
2.3 損失函數
2.3.1 上下文自相似性度量
本文使用上下文自相似性度量 (self-similarity context, SSC) 衡量重采樣后的QSM圖像與參考圖像T1圖像的相似性從而驅動卷積神經網絡學習全局共享參數. 自相似性是用于描述一幅圖像內的兩個圖像塊之間的距離度量, 對于三維圖像I中任意像素點x,x∈I, 本文定義以x為 中心, 鄰域半徑為p的圖像塊為xp, 在三維方向上與圖像塊xp的 距離為r的圖像塊被定義為i=1,2,···,6, 如圖3所示.
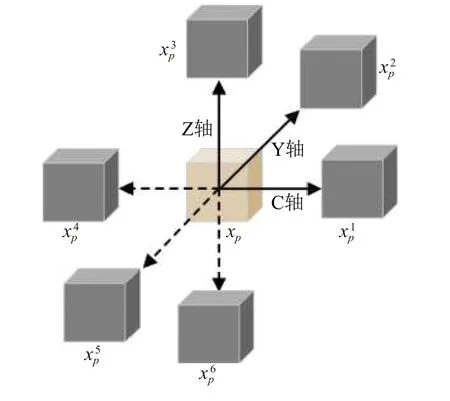
圖3 自相似性鄰域結構圖
則在像素點x的自相似性特征能夠用與xp相鄰且互不為對角的圖像塊=1,2,···,6兩兩之間的高斯核距離表示, 即:

其中, 對于以圖像塊xp為中心任意兩個鄰域圖像塊且j≠i/2×2+(1-i%2)的高斯核距離可表示為式(6):
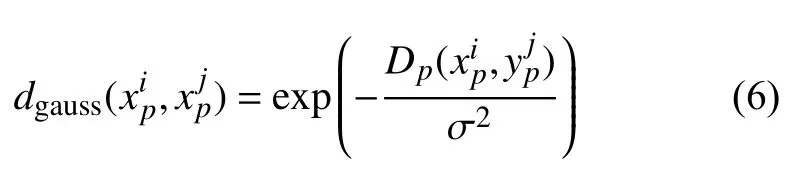
其中,Dp(·,·)表示兩個圖像塊的像素值的均方誤差之和, σ2為所有成對圖像塊均方歐式距離的均值, 即:
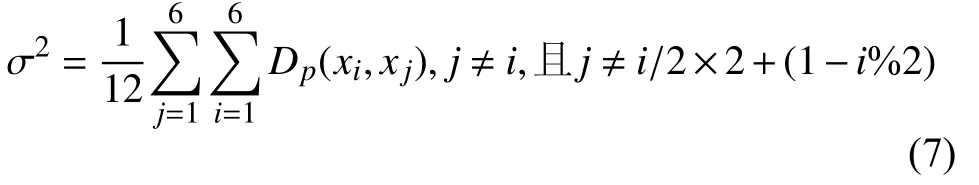
提取了兩幅圖像的自相似特征后, 則SSC損失函數可計算為:
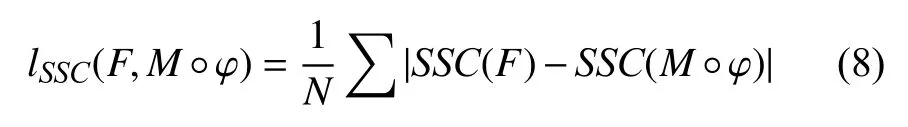
其中,F為參考圖像,M°φ 為浮動圖像經過變形場φ 重采樣后所得到的圖像,N為圖像體素總個數.
2.3.2 正則化約束
圖像配準不僅要使得配準結果與參考圖像盡可能相似, 同時還需要使得幾何變換盡可能平滑. 不平滑的幾何變換不滿足微分同胚性質, 表明配準后的組織結構被破壞. 為了解決這一問題, 本文采用正則項R(φ)來約束變形場平滑, 其定義如下:
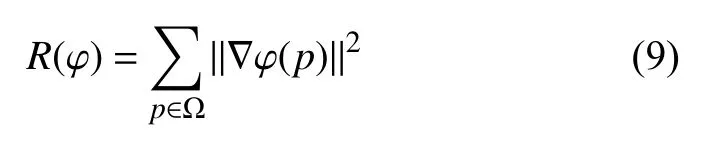
其中, ||·||為 矩陣的Frobenius范數, ? φ(p)為在體素點p處的DVF的空間梯度, 即:
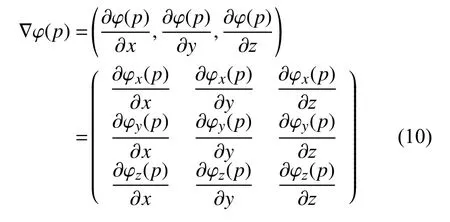
因此, 網絡模型所使用的總損失ltotal如下所示:
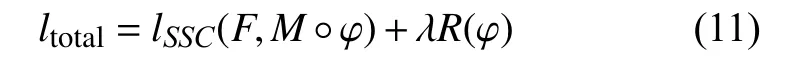
其中, λ為正則系數, 用于平衡相似性度量和變形場正則化.
3 實驗設置及評價標準
3.1 數據描述及其預處理
本文研究所采用的模板圖像為MNI152的T1加權圖像, 分辨率為1 mm×1 mm×1 mm. QSM圖像數據采集自貴州省人民醫院, 共計104名受試者. 所有采集數據均在3T MRI (GE 750w)掃描, 使用16通道磁頭線圈. 其采集參數如下: 重復采集時間/回波時間/翻轉角度 =2.7ms/31.7ms/12°, 圖像大小和分辨率分別為256 mm×256 mm×22 mm, 1 mm×1 mm×1 mm, 掃描時間約為3分鐘. 此外, 所采集的QSM相位圖還需經過相位解纏繞、背景相位去除和反演重建得到重建后的圖像才能用于配準. 本文首先對相位圖像進行拉普拉斯變換再進行傅里葉變換得到解纏繞相位的頻域空間表示[20], 隨后利用可變卷積核半徑的復雜諧波偽影去除算法進行背景相位去除[21], 最后使用最小平方QR分解法求得磁化率[22], 得到重建的QSM圖像.
3.2 訓練階段
本文將采集自貴州省人民醫院的90幅QSM圖像作為訓練集, 剩余的14幅QSM圖像作為測試集. 訓練集用于網絡模型預測, 測試集用于評估模型的性能和泛化能力. 本文所提出的方法均在Keras中實現, 使用Adam優化器, 在32 GB的NVIDIA Tesla V100 GPU上進行加速訓練, 共迭代5 000次, 訓練約18小時左右, 初始學習率設置為0.000 1, BatchSize設置為1, 訓練的總輪數Epoch設置為50, 每輪迭代次數Iteration設置為100. 訓練RF-RegNet模型的步驟如算法1.

算法1. RF-RegNet網絡模型訓練算法初始化:F參考圖像S訓練數據集lr:=10-4學習率Batchsize:=1批次大小Iteration:=100迭代次數epoch:=50訓練輪數λ:=1.0損失函數:ltotal=lSSC(F,M°φ)+λR(φ)訓練開始:1. For epoch=1 to 500 do 2. 隨機打亂訓練數據集3. For iteration=1 to 100 do隨機選擇數據集中的一幅圖像作為浮動圖像M;4. 利用網絡模型預測位移矢量場DVF;M 5. 依據DVF對浮動圖像 進行幾何變換;Θi 6. 計算損失值并更新網絡參數(每一個 是配準網絡模型中的可學習參數):Θi:=Θi-lr?loss?Θi 7. End for each 8. End for epoch
3.3 評價標準
為了有效評估QSM圖像和T1加權圖像配準的性能, 本文采用目標配準誤差 (target registration error,TRE)[23]、Dice分數[24]、Hausdorff距離 (Hausdorff distance,HD) 和平均對稱表面距離 (average symmetric surface distance,ASD)[25]來評估圖像之間的表面相似性. 其中,TRE表示同一個標注點在參考圖像和配準后圖像的差異, 其計算方法如式 (12) 所示:
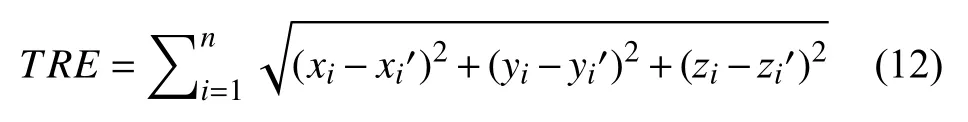
其中, (x,y,z)代 表參考圖像標記點的坐標, (x′,y′,z′)代表配準結果對應于參考圖像標記點的坐標,n代表標注點的數目, 本文共標注了6個標注點.
HD用于反映兩個區域的最大差異, 其定義如下:
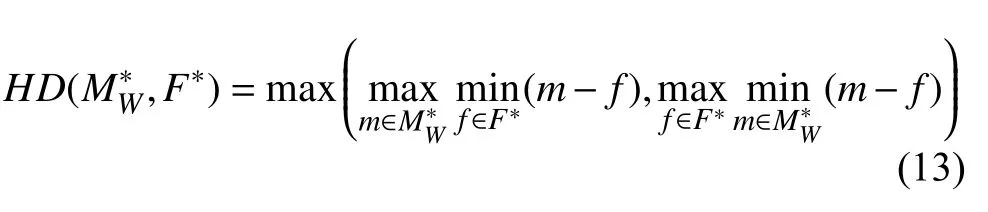
其中,和F*分別表示配準結果和參考圖像中對應的解剖結構區域,HD值越低意味著兩個區域越相似. 類似于HD,Dice分數用于表示兩個結構區域之間的重疊程度, 其定義如下:
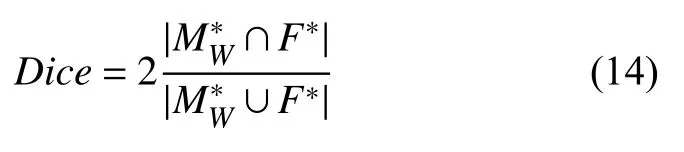
Dice分數的取值范圍為0–1, 越高的Dice分數值意味著更好配準性能.
最后, 本文也利用ASD來評估圖像之間的表面相似性, 其計算方法如式(15)所示:
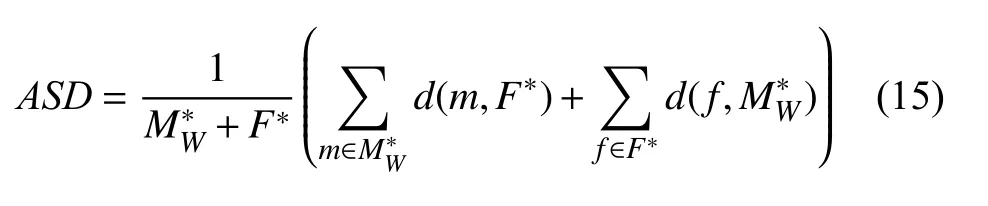
其中,d(x,Y) 為 體素點x到圖像區域Y的最小歐式距離:
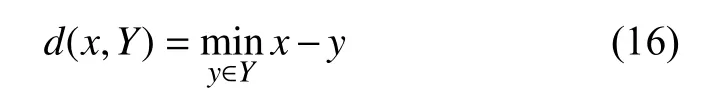
由于QSM是功能圖像, 難以分割出圖像局部解剖結構, 因此本文僅在全局腦部結構上進行定量評估配準的性能.
4 實驗結果與定量分析
為了評估本文模型的性能, 本文與VoxelMorph、ADMIR、VTN、Cascaded[26]4種先進的深度學習配準算法進行了比較. 在對比實驗中, 由于對比算法均是針對單模態圖像配準的, 因此, 本文采用對比算法中的網絡結構, 而損失函數和插值方式與本文提出的算法相同. 不同網絡模型的訓練過程迭代曲線如圖4所示.
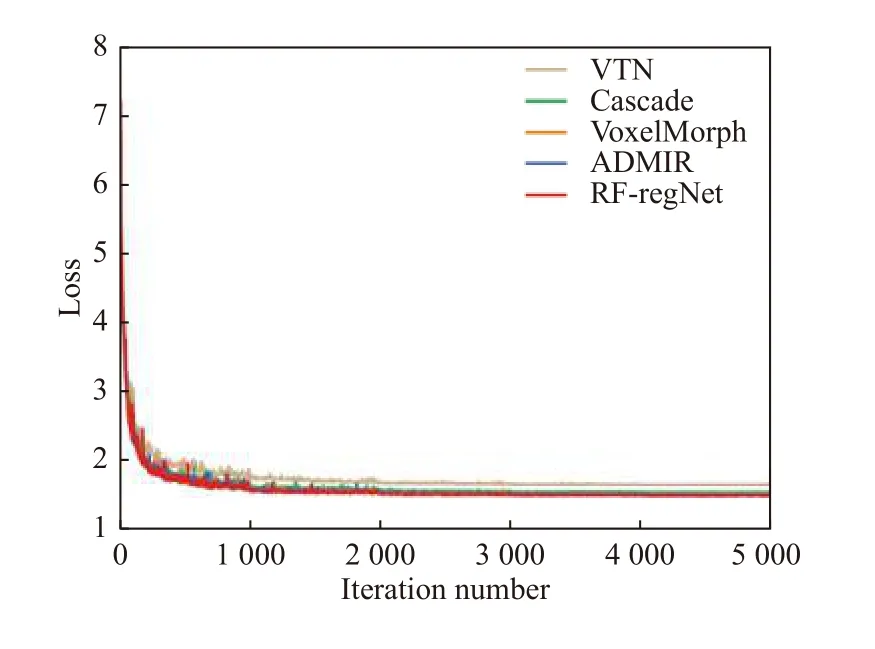
圖4 不同方法訓練損失下降圖
從圖4可以看出, 相比與其他4種方法, RF-RegNet損失下降速度最快且最低. Cascade、VoxelMorph、ADMIR的損失收斂曲線有大量重疊部分, VTN的損失收斂速度最慢且難以收斂至最優值.
4.1 可視化結果
圖5為5種配準算法的可視化結果, 其中第1、2列分別為參考圖像和浮動圖像, 后續5列分別為5種方法的配準結果并使用綠色橢圓框標記出本文方法明顯改善的部分解剖區域. 從圖中可以直觀地看出,5種方法在全局腦部結構上均取得了較好的配準效果, 但各個方法之間也存在明顯差異. VTN、Cascaded兩種方法的配準結果更為平滑, 丟失了許多的高頻細節信息. VoxelMorph、ADMIR兩種方法相比于VTN和Cascaded, 配準效果有一定的提升, 但依然丟失較多的細節信息. 本文所提出的方法取得了最好的視覺效果.
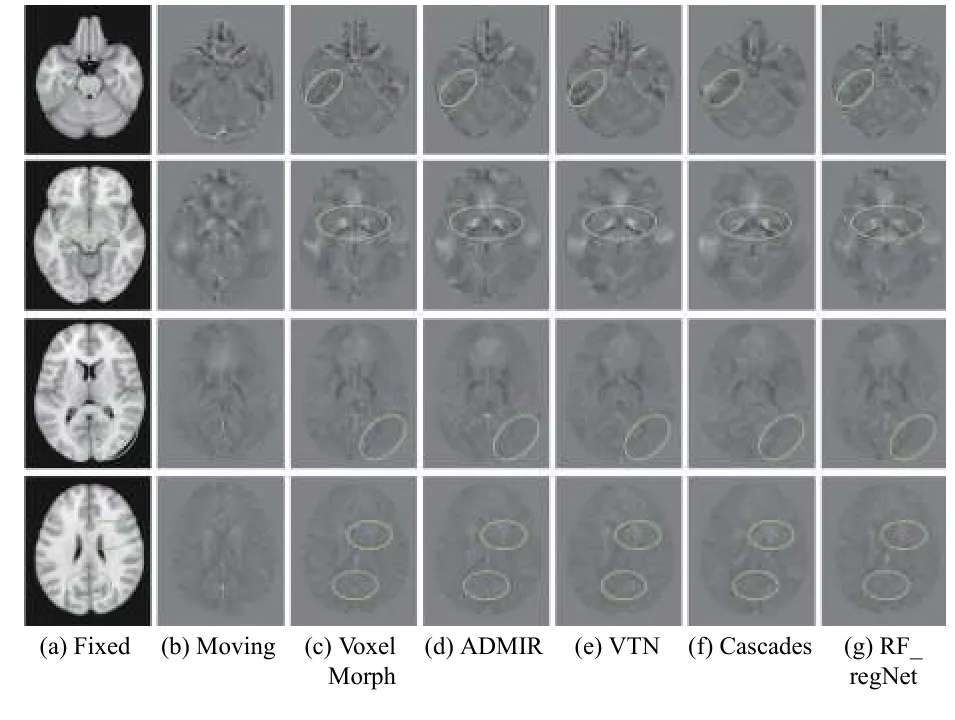
圖5 不同方法配準結果的可視化圖
4.2 定量分析
為了進一步驗證本文所提出的模型RF-RegNet的性能, 本文使用TRE、Dice分數、HD和ASD四種評價指標在測試集上對全局的配準結果進行了定量分析.定量結果如表1所示.
從表1中可以直觀地觀察到, 本文的方法取得了最佳的平均TRE、Dice分數、HD, 其中,TRE相較于其他4種方法分別下降了35.5%、20%、5.4%、6.4%;Dice分數較其他方法分別提高了1.7%、1.1%、0.5%、0.4%;HD較其他幾種方法分別降低了2.9%、3%、1.9%、1.6%;ASD較VTN、Cascaded、Voxel-Morph降低了6.2%、4.7%、1.2%, 較ADMIR方法升高了1.9%. 越高的Dice分數和越低的TRE、HD、ASD意味著更好的配準效果. 因此, 本文所提出的模型顯示了最好的配準性能. 從配準所需的時間上看,VoxelMorph的網絡結構最為簡單, 僅包含一個編碼器和一個解碼器, 因此取得了最快的運行時間. VTN、ADMIR和Cascaded的設計思想均是通過堆疊多個網絡模型來實現由粗到細配準, 模型參數量大, 因此需要耗費更多的時間, 本文所提出的方法所需配準時間略高于VoxelMorph, 低于其他方法, 滿足臨床實時的配準需求.

表1 幾種方法的定量分析結果
圖6展示了5種方法分別在Dice分數、ASD、HD、TRE四個評價指標上的箱線圖, 可以直觀地看出,本文提出的方法相比于其他方法的性能更為穩定, 進一步證明了RF-RegNet的優越性.
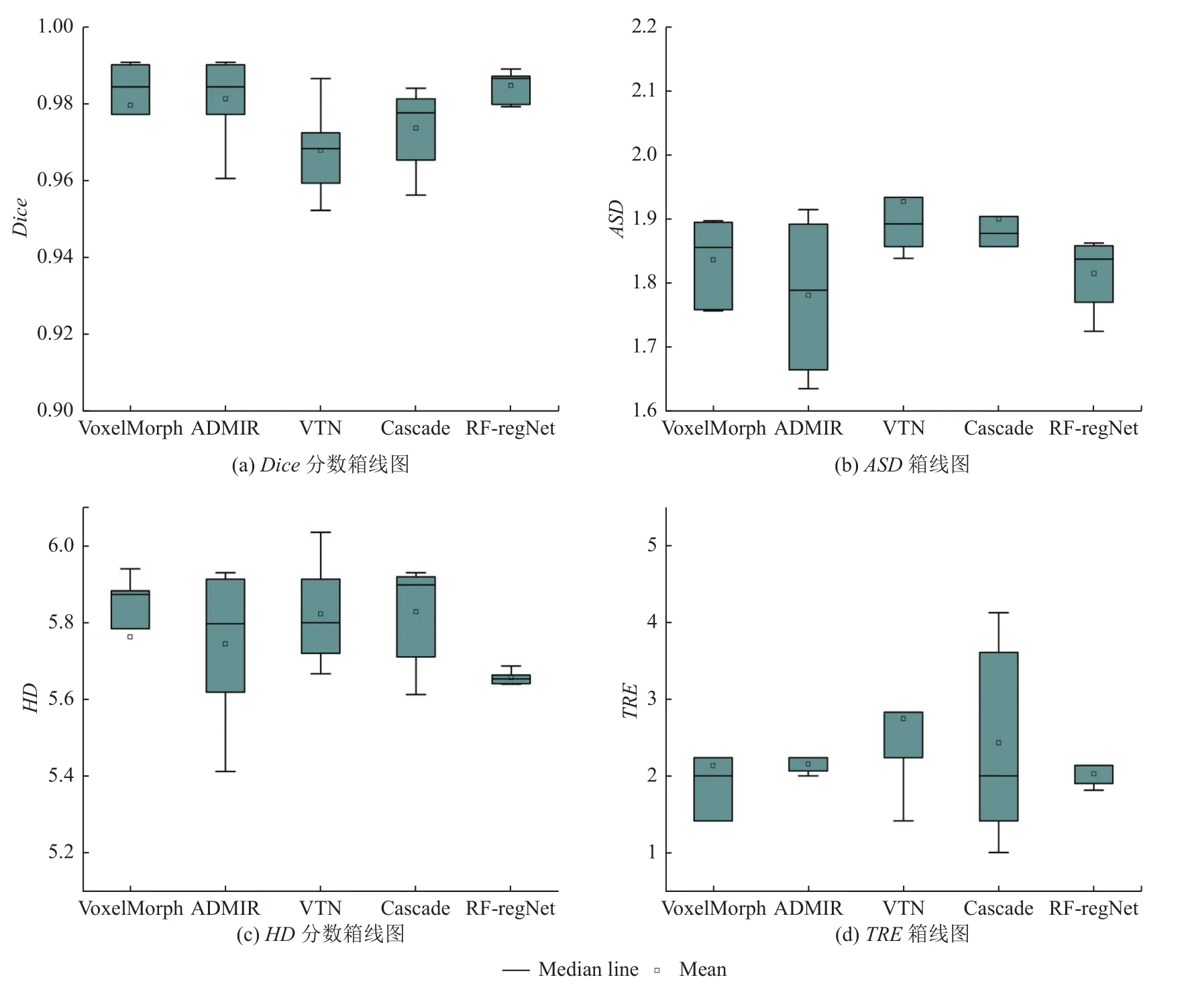
圖6 4種評價指標的箱線圖
5 結論
本文針對QSM紋理結構特點, 借鑒拉普拉斯金字塔的思想, 設計了殘差編碼器和語義編碼器, 用于提取和學習配準圖像對之間的局部紋理和邊緣信息的匹配變形參數. 最后, 通過重采樣層重建以得到最后的配準結果. 在網絡優化的過程中, 本文采用SSC的特征相似性作為損失函數驅動網絡模型學習. 實驗結果表明, 本文提出的方法顯著提升了QSM圖像和T1加權圖像的配準精度. 但仍存在些許不足, 主要體現在: 在配準之前需要使用外部工具包進行預對齊, 降低了配準效率.其次, 本文使用SSC特征相似性作為損失函數, 雖然能夠較好衡量T1加權圖像和QSM圖像的相似性, 但是計算復雜, 致使網絡訓練速度緩慢.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
