人機對話中自然語言任務命令的識別和計劃①
2022-08-25 02:52:46王曉旭
計算機系統應用 2022年8期
王 杉, 丁 磊, 王曉旭
(云南大學滇池學院 理工學院, 昆明 650228)
隨著智能設備和人機交互技術的發展, 如“Siri”“小度”等使用自然語言的人機對話系統逐漸出現在各類型智能設備中, 給人們的生活帶來了便利[1]. 近年來, 得益于NLP技術的發展, 在人機對話系統中能夠使用自然語言進行表達和交互. 然而, 自然語言中存在的歧義使對話系統很難完全理解命令任務并執行符合人類意圖的任務. 因為人們日常習慣的交談大多使用短句, 對任務的上下文通常隱含著許多的假設, 對話系統難以準確地識別人類所傳達的命令任務. 為了解決此類問題, 一些研究提出了基于受限的自然語言交互[2]. 可以在一定程度上減輕交互對話中可能出現的歧義, 而且也能適當簡化計劃任務的生成過程, 和執行任務的過程. 但是, 在多功能的人機對話系統中, 功能集可能非常大, 針對每個任務的編程會帶來巨大的工作量. 另外,還有一些研究表明對自然語言的限制會降低人機對話系統的可用性和可接受性, 尤其是在問詢、聊天等日常的對話環境中[3,4].
一個人機對話系統在獲得自然語言指令后, 通常會按以下的步驟進行任務識別和處理, 如圖1所示.
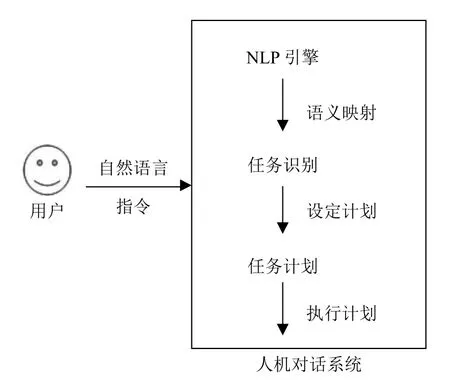
圖1 自然語言人機對話系統基本構架
圖1表述了基于自然語言的人機對話系統的基本構架, 其中NLP引擎是重要的組成部分. 除此之外, 還有一些問題需要解決. 首先, 通用的NLP引擎往往僅提供自然語言指令的語法細節, 不處理句子的歸類和分級, 也不提供任務類型以及歸納隱藏在句子中的參數集的機制. 因為這需要對系統所運行的領域和對話系統所處領域的功能集有所了解. 其次, 在自然語言對話中, 單向互動會產生歧義, 系統不能很準確識別人類的意圖. 因此, 需要基于雙向對話進行設計, 在對話系統上有許多工作[5–7]進行了嘗試, 但在有效率和準確性方面仍存在不足. 針對以上問題和不足, 本次研究提出了一個“對話任務代理”器模型, 以不受限制的自然語言接收用戶發出的任務指令, 并將其轉換為計劃程序.該模型主要包括有以下模塊: 對話引擎、基礎NLP工具集、任務分類器、計劃器. 對話引擎和基礎NLP工具集用于對接收到的自然語言指令和對話進行語法分析和任務識別. 任務分類器使用一組已知的任務進行訓練, 并把這些任務映射到對話系統的任務功能中. 任務分類器使用了“Temporal Grounding Graph”模型[8], 提供了類似的知識庫和任務模板, 每個任務都與一個模板相關聯, 這個模板會由前置條件和后置條件組成. 在給出自然語言指令的情況下, 編碼生成一組基礎邏輯命題, 這些命題代表任務預期范圍內的初始狀態和最終狀態, 然后基于邏輯的符號狀態進行推理. 最后, 提出了任務計劃問題, 并設計一個“計劃器”以解決該問題.
1 相關工作
在自然語言理解方面已經有了大量研究和工作,在這里著重探討關于人機交互指令的理解, 以及在處理模棱兩可或不完整任務指令的問題.
在早期的一些研究中, Lauria等人嘗試了自然語言給出的導航指令, 其中將任務轉換為一階邏輯形式和語義樹結構, 以提取動作過程和相應的參數[9]. 之后,有研究將監督學習方法用于學習語義解析器, 該語義解析器將路由指令映射到原始動作和控制表達式[4]. 這些研究在理解自然語言指令方面提供了有價值的指導,但僅通過導航操作卻有著很大的限制.
將基于豐富詞法資源的語義解釋器用于理解通用的自然語言指令也有嘗試, 例如FrameNet[10]. FrameNet通過框架元素、詞元、詞義類型等各項信息表達了詞匯的本質屬性, 并結合深層句法和語義分析, 以實現對自然語言指令的解析[11]. 但是, 因為僅將語言信息作為輸入, 而沒有考慮用世界模型的細節去設置上下文, 所以這些解析器很難在人機系統執行指令之前完全消除歧義. 判別重排序模型(DRMs)在一定程度上解決了歧義問題[12], 但是在實際的人機對話場景中, 機器所定義的動作程序相對“低級”, 而自然的人類命令通常包含較高級的任務目標, 這使得此類映射的學習比較困難. 在不同的上下文中, 很難預測任務的所有原始動作的順序. 因此, 將非結構化的自然語言輸入生成計劃器仍然是研究的焦點.
Thomas等人提出了RoboFrameNet[13], 該框架可以將人類指令解析為FrameNet的語義框架, 然后生成原始動作序列. 他們使用手工制作的詞匯資源來預測任務, 并使用通用的依賴解析器來提取動作參數. 但這會使語言的理解能力受到限制, 而且使用隨機搜索來找到動作序列相對低效, 并且較難擴展到真實場景.
在近期的一些研究中, Antunes等人提出了一種基于概率計劃的體系結構, 以嘗試針對子任務失敗以及子目標的重新排序而采取不同的措施, 從而生成復雜任務的計劃[14]. Misra等人也提出了一種通過在相似情況下從學習樣本中添加、刪除和替換動作來實現動作序列接地的方法[15]. 這些研究雖然較之前的方法有了進步, 但是因為需要大量的精力來創建新的數據集和訓練數, 所以這種學習給定任務的原始動作序列的方法, 并不能很好地在新的人機對話領域和具有不同功能的對話系統中應用.
在實際應用中, 經常會基于WordNet通過單詞相似性度量來處理理解包含新動詞的指令[16]或通過使用特定于環境的訓練數據[17]消除歧義. 但我們的模型提出了一種對話策略來理解新詞匯和模棱兩可的指令,以實現更好的指令解釋和更短的交互. 并且系統以PDDL形式語言生成輸入, 減少了在新的對話域中重構系統的工作量. 我們還在語義解析信息轉換計劃器正式語言方法[18]的基礎上, 將其擴展為一個完整的框架, 使用人機對話和上下文相關的任務計劃, 將自然語言指令更準確地轉換為計劃的原始動作序列.
2 系統概述
“對話任務代理”器模型由4個主要部分組成.
(1) 處理對話系統與用戶之間雙向交互的對話引擎;
(2) 任務標識符, 該標識符標識預期任務和交互中的相關參數;
(3) 一個計劃生成器, 用于為給定任務生成有效的計劃;
(4) 知識庫, 其中包含對話系統正在運行的世界規則模型以及用于計劃生成的任務模板.
2.1 對話引擎
對話引擎由一組通用的NLP工具集組成(可以使用基于深度學習的TensorFlow或者PaddlePaddle等框架), 該工具集對用戶發出的自然語言指令進行分詞和功能提取, 并且設定一個問題框架制定相關問題, 以解決任務理解中的歧義. 例如, 如果用戶說“播放一首王某的歌”, 則NLP工具會對其進行分詞處理, 得到以下具有語法特征的輸出:
(播放, 動詞, 中心詞), (一首, 數量詞, 定語), (王某,名詞, 定語), (的, 助詞, 定語), (歌, 名詞, 賓語)
2.2 任務標識符
為了消除歧義并理解NLP工具集提供的語義信息, 對話系統和人類必須形成順暢的溝通, 即使人類用自然語言發出指令, 也可以將其轉換為計算機可以存儲和處理的中間表示形式. 我們使用了基于FrameNet框架[19,20]關系來實現任務標識符的建模. 框架語義把現實世界中的事件建立為框架模型, 模型使用事件的參與實體(稱為框架元素)全面地描述事件, 框架元素包括主題和來源, 主題表示受事件影響的對象, 來源表示存在主題的位置. 因此, 當任務標識符處理NLP工具的輸出時, 將產生以下輸出:
[播放]激活[一首王某的]來源[歌]主題
同時可以設計一個分類器來識別框架和框架元素.如果分類器無法獲取足夠的判別信息, 則會向用戶詢問相關問題, 以解決歧義和信息不足的問題.
2.3 計劃生成器
在人類預期的任務指令與計算機所能支持的原始動作之間通常無法進行一對一映射, 因為某些高級任務目標會包含一系列子任務. 所以, 為實現任務計劃,必須讓計算機理解用戶真實意圖, 使任務能夠以初始狀態遷移至不同的目標狀態.
規劃域定義語言(PDDL)[21], 是一種標準化的人工智能規劃語言, 提供了一種以形式化的語言對世界的初始狀態和目標狀態進行編碼的方法. 為了能夠執行計劃的動作序列, 每個動作都要映射到PDDL狀態轉換運算符. 在PDDL中, 把謂詞、參數變量和狀態轉換運算符集定義為域, 而基礎的初始條件和目標條件集稱為問題. 這樣形式化的計劃器就可以解決給定領域中的計劃問題, 從而找到滿足人類預期任務目標的機器動作序列.
2.4 知識庫
知識庫存儲世界規則模型和任務模板. 與“Temporal Grounding Graph”模型的世界狀態的感知基礎模型相似[8], 世界規則模型包含了對話系統正在操作的世界規則和環境, 并表示為當前狀態的符號. 知識庫還提供了在任務計劃生成器生成計劃問題時需要考慮的任務上下文. 并在機器執行動作后, 還會考慮更新知識庫. 另一方面, 任務模板用于存儲生成任務計劃問題時需要的前提條件和后置條件, 這些條件與FrameNet框架語義相符. 如果對于給定的任務指令難以判別, 則對話系統將會發起與用戶的對話以收集更多信息.
3 系統的核心功能
為了實現對任務命令識別和計劃的目標, 以及保持技術的先進性, 本次研究提出了3個核心的組成功能.
3.1 任務和命令識別
任務標識符的作用是在給定一段句法標記的文本后, 識別預期的任務及其相應的參數, 并將單詞或短語分類為任務類型或任務參數. 為此, 我們參考了“條件隨機場” (CRF)模型, 該模型結合了最大熵模型和隱馬爾可夫模型的特點, 近年來在分詞、詞性標注和命名實體識別等序列標注任務中取得了很好的效果[22]. 解析過程分為兩個連續的階段——任務類型預測和參數提取. 任務類型預測階段預測給定文本中可能的詞序列. 然后, 在給出前一階段可能出現的詞的預測情況下,參數提取階段將預測文本中詞元素的序列. 通過預測文本中每個詞標記的IOB標簽來標記預測的序列, 表示是在內部(I), 外部(O)還是在開頭(B).
在任務類型識別階段, 訓練數據如下表示:
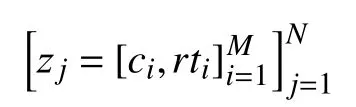
句子zj由一個M×2的矩陣構成,ci表示句子中的單詞,rti表示單詞所對應的任務類型的IOB標簽,N表示訓練數據中此類句子的數量.
在參數提取階段, 訓練數據如下表示:
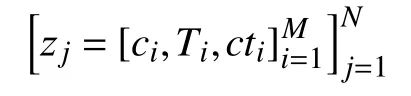
其中,Ti表 示與單詞ci關聯的預測任務類型, 而cti表示參數類型的IOB標簽.
用于任務類型識別的CRF模型定義了如下的條件概率分布:
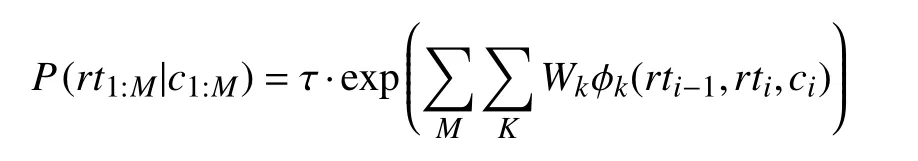
其中, φk是特征函數的第k項分量,k是特征數,Wk是第k項特征的權重, τ是歸一化因子. 使用梯度下降優化從訓練數據中學習權重.
對于參數提取階段, CRF模型定義以下條件概率分布:
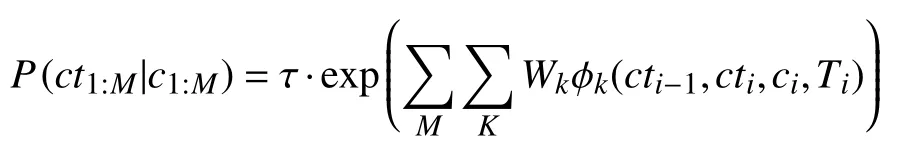
最后, 使用詞匯和語法特征來預測任務和參數類型. 詞匯特征包括單詞本身、詞根以及單詞的上下文.語法特征包括詞和上下文詞的詞性以及句法依賴性.
3.2 基于對話理解任務
即使準確定義了任務標識符, 但當用戶以自然語言進行指令傳遞時, 仍有可產生歧義而導致識別失敗或錯誤預測. 現有的任務識別模型通常使用指令中存在的動詞和動詞周圍的語言特征進行訓練[15,18]. 但是當用戶為非專業人士時, 用戶可能會使用未登記詞匯, 那么任務識別模型可能會無法進行有效地預測, 導致錯誤地預測任務類型. 由于任務類型識別處于處理流程的前期階段, 因此需要解決其故障和錯誤, 才能夠往后執行指令. 通常在這種情況下, 對話系統會在與人類的對話中進行互動交流, 以能在錯誤預測的情況下確定指令的含義或正確的任務類型[3]. 但是, 非專業用戶可能不知道對話系統使用的術語, 所以也不能直接給出提問的正確回答. 例如對話系統如果提問“這是什么類型的任務?”, 用戶是完全無法回答的, 因為用戶根本不知道系統是如何對指令歸類. 為此, 對話系統可以采用一些提示問題, 例如“這是類似于…嗎?”, 然后用戶給出肯定或否定的回答. 然而, 這又會引發兩個新問題.首先, 對話系統儲存的任務類型數量通常有很多, 如果機器人一一提出建議, 則會嚴重降低用戶體驗. 其次,非專業用戶可能仍然無法理解該建議的意思, 需要對話系統進一步解釋.
針對以上情況, 這里提出一種對話策略以解決上述問題. 對于給定的指令, 識別任務可以通過動詞和充當動詞自變量的名詞短語共同表征, 并利用數據集中存在的這些任務與參數關系(使用訓練解析器的同一數據集)來估計已知任務被傳遞的可能性. 給定一個句子Z和一組所有可能的任務類型T={T1,T2,···,Tn},然后定義一個n元組T′, 每個元素Ti′表示T中的一個任務類型,Ti′成為給定句子的真實任務類型的可能性決定了T′的 順序, 即P(Ti|C).
可以使用以下過程估算T′: 首先, 使用參數類型預測模型, 該模型用于查找指令中可能存在的參數類型.參數類型預測模型也使用CRF來實現:
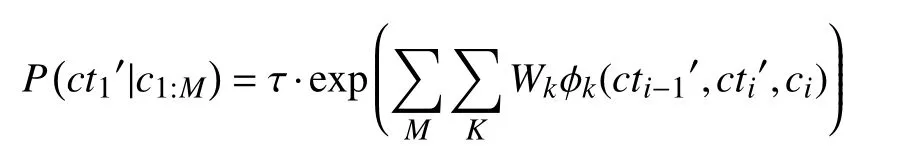
這個模型與參數提取模型的不同之處在于, 該模型可預測每個單詞(ci)的參數(cti′)的IOB標簽, 而不用考慮句子的任務類型.
然后, 將預測的cti′里轉換為句子中的一個參數類型集合, 并定義為CTP. 再定義另一個集合CTD表示一個任務類型的參數類型, 該類型出現于訓練數據集中.接下來對訓練數據集所有指令中, 滿足CTP?CTD的任務類型Ti的實例數量進行統計, 生成一個n元組, 其中元素來自集合T, 由相應的計數排序. 將計數歸一化并將其轉換到概率分布, 然后按概率對n元組進行排序, 最終得到T′.
為了回答用戶有關任務類型定義的問題, 模型為每種任務類型設置一個問題模板, 可以將參數類型預測模型預測的結果填充到模板中. 例如, 如果要求非專業用戶清楚查詢任務的含義, 則使用模板“是否要我在[主 題 ]中查詢[目 標 ]”. 例如:
詢問1: 查詢張三
回答1: 這個任務類似于查找嗎?
詢問2: 我不明白
回答2: 你要我在通訊錄中查詢張三名片嗎?
詢問3: 是的
回答3: 明白了
當確定對話缺少參數時, 就可以使用類似的模板來提問. 非專業用戶指定的高級任務也可以由已知任務組成, 這時模型具有與用戶進行交互以提取已知任務序列的能力. 在這種對話情況下, 系統會要求用戶說出執行高級任務的步驟. 然后, 將響應視為包含多個序列化任務的單個指令, 將其作為輸入來生成計劃.
3.3 計劃問題的形式化
一個任務其實就是自然語言指令表示的一個可被實現的目標, 任務也可被假定為由任務的初始狀態表示的世界狀態給出. 為了更好表達和實現任務計劃, 我們采用PDDL進行任務計劃的描述, 并且按PDDL規則將每種任務類型的初始狀態和目標狀態的模板存儲在知識庫中. 表1顯示了此類模板的一些實例.

表1 在PDDL中生成初始狀態和目標狀態的模板示例
在此類模板中, 可以通過使用從指令中提取的參數將抽取的變量進行定義, 然后再用世界模型進行驗證, 從而生成計劃問題的初始狀態和目標狀態. 通常基于PDDL域的謂詞并根據建模任務的框架的定義來創建模板.
如果人機對話系統能自主工作, 那么它將持續接受來自人類用戶的新任務并執行這些任務. 在為新任務生成計劃問題時, 將使用世界模型來驗證假定的初始狀態, 并能使計劃中的狀態轉換算子后置條件建模和世界狀態的編碼更加流暢.
算法1顯示了生成計劃任務的完整過程. 對于一個已序列化, 且包含要實現的多個任務目標說明, 可以通過保留指令中所有任務的世界狀態上下文來處理此類復合指令. 存儲的模板機制還可以對新任務的集成或遷移進行簡化, 并通過引入新模板以及PDDL域中的謂詞和狀態轉換運算符來添加新任務.

算法1. 生成PDDL計劃任務1) 輸入: 目標狀態模板: Ts, 初始狀態模板: T0 , 世界狀態: H, 已解析的參數: K 2) 初始化: 初始狀態=φ, 目標狀態=φ 3) while(T0!=φ){從T0中獲得c;grounded_atom = ground(template_atom, K);while(H!=φ){從H中獲得fluent;if(fluent與grounded_atom矛盾){新增fluent到初始狀態;}else{新增grounded_atom到初始狀態;}}while(Ts!=φ){從Ts中獲得template_atom;grounded_atom = ground(template_atom, K);新增template_atom到目標狀態;}}4) 輸出: 初始狀態, 目標狀態
4 測試與評估
為了驗證和評估系統, 我們使用了中文公開對話語料庫chinese_chatbot_corpus[23]的部分數據進行測試. 該庫對目前市面上已有的開源中文對話語料進行了整理, 包含8組公開閑聊與對話的常用語料. 在測試中, 選取4組較有代表性的語料庫中的部分數據作為輸入, 以測試和評估系統對任務的理解和計劃能力. 并與僅使用基本功能的基準系統、以及加入部分功能的試驗系統進行比較, 以顯示系統在解決問題時的能力.表2顯示了使用不同的方法模塊的不同系統.

表2 任務識別和計劃生成的不同方法
通過與中文公開對話語料庫數據集中的注解進行比較, 系統的框架語義解析器可以從389個類指令語句中識別到436個任務, 且經過比對, 其中412個任務符合正確含義, 平均總正確率為94.49% (如表3所示).所以系統解析器從自然語言指令中預測任務類型是較為準確的.
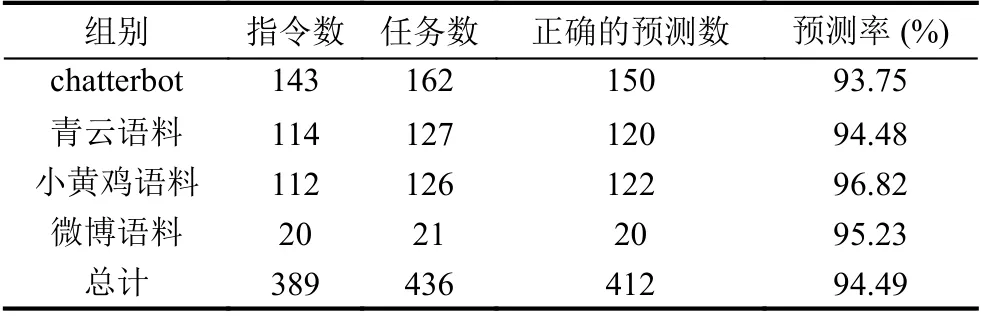
表3 系統在中文公開對話語料庫上進行任務識別的性能
在任務識別的基礎上, 我們進一步進行了任務計劃生成的測試(如表4所示).
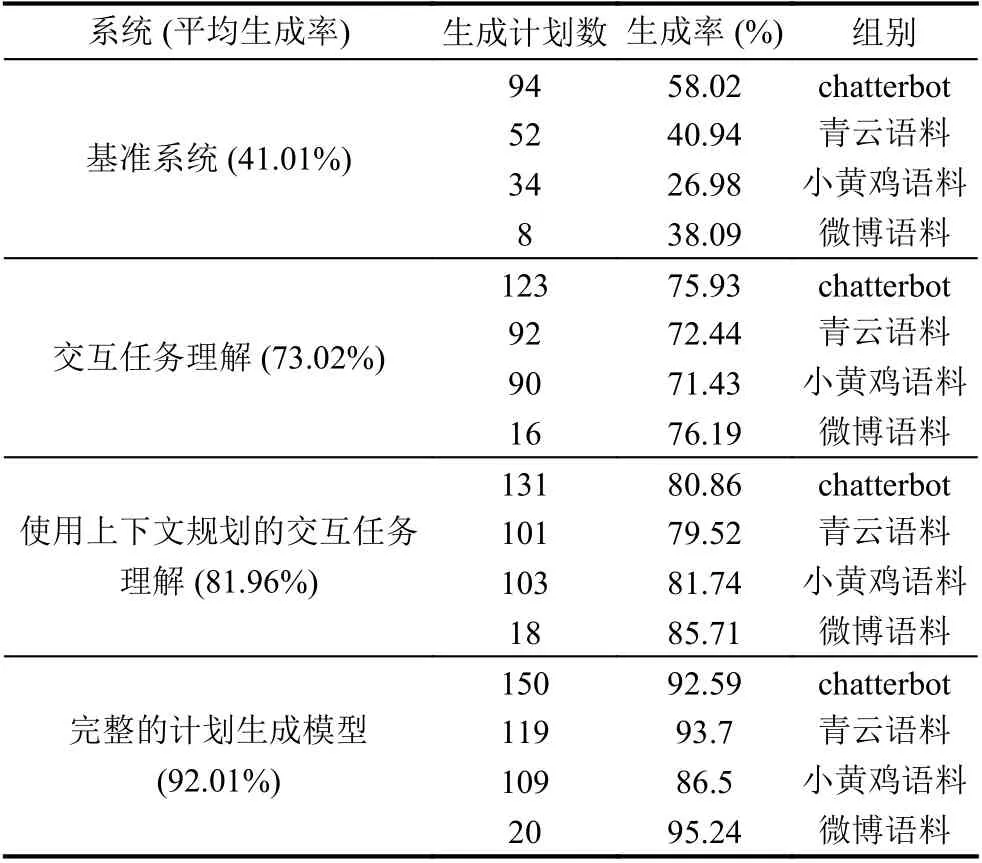
表4 系統在中文公開對話語料庫上進行計劃生成的性能
從測試可以發現即使有較高的任務預測率, 但是由于基準系統不使用對話來獲取缺少的信息, 并且使用了靜態模板, 不會為多個目標狀態沖突的任務指令生成計劃. 基所以準系統的計劃生成性能較低(平均生成率僅41.01%).
在交互任務理解系統中, 通過添加對話模塊以獲取缺少的參數可以在一定程度上解決了指令不完整的問題, 系統使用對話策略來引導模糊指令的識別分析,生成計劃的有效率得到了提高(平均生成率為58.75%),一定程度上解決了指令不完整的問題. 但是使用靜態模板無法處理需要上下文相關計劃的復雜指令, 于是在增加了上下文規劃的交互任務理解模型中, 并使用了基于世界模型的動態更新模板, 使得計劃生成率進一步提高(平均生成率為73.04%).
最后, 通過在系統中使用了共引解析, 把指代相同對象的名詞歸類指向同一個實體. 系統生成了353個任務計劃, 獲得了較好的計劃生成率(平均生成率為92.01%), 這也與正確的任務識別率(94.49%)相接近.
我們也尋求了正確預測任務但未生成有效計劃的原因, 主要是包含在測試數據中已經存在的參數未能有效地析出; 其次在某些情況下, 由于錯誤地假定上下文, 任務的計劃失敗會導致同一指令中的從屬任務也失敗.
5 結論與展望
在本次工作中, 研究了人機對話系統的任務對話代理模型, 該代理根據自然語言指令執行任務計劃, 并提出了一種方法來整合自然語言解析器和對話代理的自動計劃器. 為了實現該方法, 我們開發了一種語言理解模型來識別預期的任務和相關的參數, 同時研究了一種對話策略, 對模棱兩可的指示進行識別, 以完成與人機對話的互動. 測試和評估表明系統能基于知識庫的上下文感知推理完成與生成計劃的對話, 并且能以較少的詢問獲得有意義的問題. 在后續的研究中, 可以對該系統進行進一步的擴展, 例如加入概率和分層計劃, 還可以基于更豐富的知識庫進行推理, 以期獲得更好的對話效果和任務計劃識別.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
