基于LightGBM-SVR-LSTM的停車(chē)區(qū)車(chē)位預(yù)測(cè)
2022-08-24 05:52:06楊培紅哈元元余智鑫趙建東
科學(xué)技術(shù)與工程 2022年20期
楊培紅, 哈元元, 余智鑫, 趙建東*
(1.青海省高速公路運(yùn)營(yíng)管理有限公司, 西寧 810008; 2.北京交科公路勘察設(shè)計(jì)研究院有限公司, 北京 100083; 3.北京交通大學(xué)交通運(yùn)輸學(xué)院, 北京 100044)
中國(guó)汽車(chē)保有量處于持續(xù)增長(zhǎng)的狀態(tài),停車(chē)難和交通擁擠的現(xiàn)象愈演愈烈。停車(chē)區(qū)附近的誘導(dǎo)指示牌上會(huì)顯示當(dāng)前時(shí)刻的剩余車(chē)位信息,但停車(chē)信息隨時(shí)間動(dòng)態(tài)變化,剩余車(chē)位信息時(shí)與車(chē)輛到達(dá)停車(chē)地點(diǎn)后的實(shí)際剩余車(chē)位可能存在差異[1]。此外,駕駛員在尋找泊車(chē)位時(shí)的無(wú)效巡游會(huì)產(chǎn)生無(wú)效交通[2],進(jìn)而可能增加擁擠程度,制約城市的發(fā)展[3]。準(zhǔn)確地預(yù)測(cè)停車(chē)區(qū)剩余空車(chē)位,可以為駕駛員提供更加全面的誘導(dǎo)信息,從而協(xié)助他們做出合理的停車(chē)判斷,縮短無(wú)效交通時(shí)間,改善交通狀況。
針對(duì)停車(chē)區(qū)剩余車(chē)位的預(yù)測(cè),目前主要有基于數(shù)理統(tǒng)計(jì)的方法和基于非線(xiàn)性理論的方法。基于數(shù)理統(tǒng)計(jì)的方法是指采用統(tǒng)計(jì)理論對(duì)歷史數(shù)據(jù)進(jìn)行分析,從而預(yù)測(cè)未來(lái)的可用停車(chē)位數(shù)據(jù)。此類(lèi)模型預(yù)測(cè)方法步驟簡(jiǎn)單,然而難以精確擬合歷史的復(fù)雜非線(xiàn)性數(shù)據(jù)。Caicedo等[4]提出了基于自回歸移動(dòng)平均(autoregressive integrated moving average,ARIMA)模型的停車(chē)區(qū)剩余停車(chē)位預(yù)測(cè)模型,但停車(chē)位占用率較高時(shí),預(yù)測(cè)精度較低。張雷等[5]提出了基于向量自回歸預(yù)測(cè)的泊位預(yù)測(cè)算法,以重慶市為實(shí)驗(yàn)對(duì)象,驗(yàn)證了算法的可行性。湯俊欽[6]根據(jù)停車(chē)區(qū)間的不確定性關(guān)系,建立了多元線(xiàn)性回歸模型,通過(guò)對(duì)廈門(mén)市不同停車(chē)區(qū)的停車(chē)需求研究驗(yàn)證了算法的可行度。
非線(xiàn)性預(yù)測(cè)模型指以神經(jīng)網(wǎng)絡(luò)、決策樹(shù)等理論為基礎(chǔ),建立相應(yīng)的預(yù)測(cè)模型。此類(lèi)預(yù)測(cè)模型能夠很好地?cái)M合停車(chē)區(qū)空閑停車(chē)位與時(shí)間的非線(xiàn)性特征,但計(jì)算過(guò)程非常復(fù)雜。裘瑞清等[7]用長(zhǎng)短時(shí)記憶神經(jīng)網(wǎng)絡(luò)(long short-term memory neural network,LSTM)循環(huán)神經(jīng)網(wǎng)絡(luò),對(duì)區(qū)域內(nèi)泊位需求進(jìn)行預(yù)測(cè),能夠比傳統(tǒng)方法在結(jié)果上更加接近實(shí)際值,并且精度較為滿(mǎn)意,表明該預(yù)測(cè)方法可行有效。韓錕等[8]通過(guò)關(guān)聯(lián)積分法(cross-correlation,C-C)進(jìn)行相空間重構(gòu),并利用遺傳算法優(yōu)化小波神經(jīng)網(wǎng)絡(luò),實(shí)驗(yàn)證明,該方法具有良好的預(yù)測(cè)精度。劉東輝等[9]提出了一種利用粒子群優(yōu)化算法(particle swarm optimization algorithm,PSO)優(yōu)化LSTM的剩余車(chē)位預(yù)測(cè)模型,在不同場(chǎng)景下,精度均優(yōu)于LSTM模型。Mei等[10]將傅里葉變換(fourier transform,F(xiàn)T)的思想與機(jī)器學(xué)習(xí)方法中的最小二乘支持向量回歸(least squares support vector regression,LSSVR)相結(jié)合進(jìn)行剩余車(chē)位的多步預(yù)測(cè),效果優(yōu)于傳統(tǒng)的LSSVR模型。
由于深度學(xué)習(xí)和機(jī)器學(xué)習(xí)領(lǐng)域的發(fā)展,相關(guān)模型在智慧交通領(lǐng)域應(yīng)用變得更加廣泛。對(duì)于停車(chē)區(qū)剩余車(chē)位的預(yù)測(cè),目前主要是通過(guò)單個(gè)模型或者利用啟發(fā)式算法優(yōu)化單個(gè)模型進(jìn)行預(yù)測(cè),但是這些預(yù)測(cè)方式存在一定的不足:一是難以找到合適的特征,模型效果不能充分發(fā)揮;二是容易受噪聲點(diǎn)的影響,難以準(zhǔn)確擬合停車(chē)區(qū)剩余車(chē)位在不同場(chǎng)合的變化情況;三是對(duì)預(yù)測(cè)過(guò)程中產(chǎn)生的數(shù)據(jù)未能有效利用。
為此,提出了一種LightGBM-SVR-LSTM的預(yù)測(cè)模型,[輕量級(jí)梯度提升機(jī)(light gradient boosting machine,LightGBM)、支持向量回歸模型(support vector regression,SVR)、LSTM]。首先利用小波分析對(duì)異常數(shù)據(jù)進(jìn)行識(shí)別,并利用KNN模型修復(fù)異常值;然后相比于傳統(tǒng)的單變量預(yù)測(cè)或者通過(guò)經(jīng)驗(yàn)設(shè)置特征的方法增加預(yù)測(cè)精度,采用LightGBM模型,將葉子節(jié)點(diǎn)的值作為新的特征,放入次級(jí)的SVR模型進(jìn)行預(yù)測(cè);針對(duì)組合模型預(yù)測(cè)產(chǎn)生的誤差,利用LSTM進(jìn)行誤差修復(fù);最后利用某停車(chē)區(qū)數(shù)據(jù)驗(yàn)證模型的有效性。
1 數(shù)據(jù)預(yù)處理
采集的數(shù)據(jù)中存在一些噪聲數(shù)據(jù),需要其進(jìn)行修復(fù)處理。采取小波分析與K最近鄰(K-nearest neighbor,KNN)模型結(jié)合,將數(shù)據(jù)進(jìn)行降噪處理。
小波分析(wavelet denoising, WD)是由Donoho等[11]提出的方法發(fā)展而來(lái),其原理是抑制信號(hào)中的噪聲部分,保留原始特征。通過(guò)小波分析可以讓樣本的非平穩(wěn)特征得到很好的保留;用小波變換對(duì)信號(hào)進(jìn)行去相關(guān)的操作,得到的噪聲將趨于自噪聲,從而得到更精確或理想效果。小波分析的理論中,一維噪聲模型可表示為
zst=ort+et,t=1,2,…,n
(1)
式(1)中:zst為噪聲信號(hào);ort為原始信號(hào);et為高斯噪聲;n為信號(hào)長(zhǎng)度。
將小波分析得到的高頻濾波全部置為零,則低頻分量即為重構(gòu)后的數(shù)據(jù)序列。將原始數(shù)據(jù)序列與重構(gòu)的數(shù)據(jù)相減,得到殘差數(shù)據(jù)序列。為了盡可能多的保留原始數(shù)據(jù)特征,對(duì)于殘差序列,采用3σ原則進(jìn)行異常數(shù)據(jù)識(shí)別(距離均值3倍標(biāo)準(zhǔn)差外的數(shù)據(jù)均視為異常值)。為了提高異常數(shù)據(jù)修復(fù)效果,進(jìn)一步改善數(shù)據(jù)質(zhì)量,結(jié)合KNN法對(duì)噪聲數(shù)據(jù)的敏感度較低的特性,構(gòu)建基于KNN的異常數(shù)據(jù)修復(fù)模型。
2 空車(chē)位數(shù)量預(yù)測(cè)模型搭建
構(gòu)建時(shí)間序列預(yù)測(cè)的模型時(shí),需要考慮其對(duì)整體數(shù)據(jù)的周期性、連續(xù)性和趨勢(shì)的擬合程度,還要具備一定的泛化能力,以便減小異常值對(duì)模型擬合峰值的影響。基于此,構(gòu)建了基于LightGBM-SVR-LSTM的組合模型。
2.1 LightGBM
LightGBM是梯度提升決策樹(shù)(gradient boosting decision tree,GBDT)的一種新的框架[12],相比于GBDT,LightGBM做了多個(gè)優(yōu)化:使用直方圖加速、使用leaf-wise的葉子生長(zhǎng)策略代替level-wise、支持類(lèi)別特征等。LightGBM解決了GBDT原始模型面對(duì)大量數(shù)據(jù)時(shí),計(jì)算速度慢的問(wèn)題,在訓(xùn)練過(guò)程中,LightGBM的目標(biāo)函數(shù)可表示為
(2)
(3)
(4)

2.2 SVR
SVR是一種基于統(tǒng)計(jì)學(xué)習(xí)的理論,進(jìn)行回歸計(jì)算的機(jī)器學(xué)習(xí)算法。該方法在理論上可以得到問(wèn)題的全局最優(yōu)解,且計(jì)算過(guò)程復(fù)雜程度與樣本維數(shù)無(wú)關(guān),在函數(shù)逼近、回歸預(yù)測(cè)等方面能夠達(dá)到較好的效果,其原理可表示為
(5)
式(5)中:ε為擬合精度;約束條件中的w為權(quán)值向量;b為偏移常量;x′i為輸入向量。
2.3 LSTM
LSTM是RNN的一種改進(jìn)[13],在內(nèi)部增加了門(mén)結(jié)構(gòu):輸入門(mén)、遺忘門(mén)和輸出門(mén)。通過(guò)這結(jié)構(gòu),調(diào)整輸入與隱藏層的值[14],計(jì)算過(guò)程如下。
ft=σ(Wf[ht-1,xt]+bf)
(6)
it=σ(Wi[ht-1,xt]+bi)
(7)
(8)
(9)
ot=σ(Wo[ht-1,xt]+bo)
(10)
ht=ottanh(Ct)
(11)
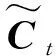
2.4 組合模型
選取合適的特征以及模型,可以最大限度地將預(yù)測(cè)值逼近真實(shí)數(shù)據(jù)。在特征選擇時(shí),如果添加的特征不足,會(huì)造成模型預(yù)測(cè)精度不高,產(chǎn)生欠擬合的情況;如果添加的特征過(guò)多,一方面,可能引入一些無(wú)關(guān)的變量,降低模型的預(yù)測(cè)效果;另一方面,當(dāng)模型輸入維數(shù)過(guò)高,可能產(chǎn)生過(guò)擬合的現(xiàn)象,降低模型的精度以及魯棒性。按照經(jīng)驗(yàn)來(lái)添加特征變量,很容易產(chǎn)生上述問(wèn)題。對(duì)于決策樹(shù)模型,在進(jìn)行預(yù)測(cè)時(shí),會(huì)首先生成葉子節(jié)點(diǎn),由葉子節(jié)點(diǎn)的值,得到最終的預(yù)測(cè)值。采用LightGBM模型,通過(guò)訓(xùn)練,獲得葉子節(jié)點(diǎn)值,作為特征向量,以解決傳統(tǒng)的按照經(jīng)驗(yàn)確定特征可能帶來(lái)的不利因素。
將LightGBM模型的葉子節(jié)點(diǎn)輸出后,數(shù)據(jù)維度較高,為了避免因?yàn)檫^(guò)擬合,降低模型效果,本文選擇使用SVR進(jìn)行預(yù)測(cè)。SVR模型可以有效地適應(yīng)高維數(shù)據(jù),且方法簡(jiǎn)單,不容易產(chǎn)生過(guò)擬合。為了進(jìn)一步提升模型精度,采用網(wǎng)格搜索,對(duì)各模型的超參數(shù)進(jìn)行尋優(yōu),確定最佳超參數(shù)。
LSTM擁有長(zhǎng)時(shí)記憶功能,能夠有效地識(shí)別數(shù)據(jù)的周期性、趨勢(shì)性,對(duì)于處理時(shí)間序列數(shù)據(jù)有良好的效果。因此將LightGBM-SVR的預(yù)測(cè)值輸出后,將其與真實(shí)數(shù)據(jù)的殘差序列提取出來(lái),利用LSTM模型進(jìn)行誤差修復(fù),并通過(guò)網(wǎng)格搜索,確定最佳的超參數(shù),提升模型的預(yù)測(cè)精度。
3 實(shí)例分析
選取某停車(chē)區(qū)在2017年10月—2018年2月的數(shù)據(jù)進(jìn)行實(shí)驗(yàn),數(shù)據(jù)為每小時(shí)統(tǒng)計(jì)一次。將數(shù)據(jù)集按照6∶2∶2劃分為訓(xùn)練集、驗(yàn)證集和測(cè)試集。
3.1 數(shù)據(jù)預(yù)處理
對(duì)于停車(chē)區(qū)剩余車(chē)位數(shù)據(jù),更好的時(shí)頻特性是主要的,為了保持?jǐn)?shù)據(jù)良好的光滑性,選擇常用的db4小波進(jìn)行去噪,效果如圖1所示。
s=d1+d2+d3+a3
(12)
式(12)中:s為原始信號(hào);a3為低頻信號(hào);d1、d2、d3為高頻信號(hào)。

圖1 小波分析結(jié)果Fig.1 Results of wavelet analysis
將分解獲得的3層高頻分量置零,低頻分量a3即為重構(gòu)后的數(shù)據(jù)序列。根據(jù)3σ原則對(duì)殘差值進(jìn)行識(shí)別異常值,利用KNN算法進(jìn)行異常數(shù)據(jù)修復(fù)。部分結(jié)果如圖2所示。

圖2 異常數(shù)據(jù)修復(fù)結(jié)果對(duì)比Fig.2 Comparison of abnormal data repair results
3.2 預(yù)測(cè)效果對(duì)比
為了檢驗(yàn)?zāi)P偷男Ч饕捎镁礁`差(root mean square error,RMSE)、平均絕對(duì)誤差(mean absolute error,MAE)、平均百分比誤差(mean absolute percentage error,MAPE)3種指標(biāo)來(lái)量化預(yù)測(cè)誤差,其計(jì)算公式分別為
(13)
(14)
(15)

將處理后的數(shù)據(jù)進(jìn)行訓(xùn)練,并通過(guò)網(wǎng)格搜索確定各預(yù)測(cè)模型的最佳超參數(shù)。其中,LightGBM超參數(shù)如下:行采樣設(shè)置為0.7, 每4次迭代執(zhí)行裝袋操作,列采樣設(shè)置為0.9, 每棵樹(shù)的葉子數(shù)量設(shè)置為25,樹(shù)的數(shù)量設(shè)置為300。SVR的超參數(shù)如下:懲罰系數(shù)設(shè)置為100,徑向基函數(shù)的系數(shù)設(shè)置為0.01;考慮到數(shù)據(jù)有限,LSTM中間層只設(shè)置一層,其余超參數(shù)設(shè)置為:訓(xùn)練次數(shù)設(shè)為50,神經(jīng)元個(gè)數(shù)設(shè)置為35,訓(xùn)練的批大小設(shè)置為16。
將提出的組合模型,與選擇常見(jiàn)的交通流預(yù)測(cè)模型SVR、LSTM、LightGBM、門(mén)控神經(jīng)網(wǎng)絡(luò)(gate recurrent unit,GRU)進(jìn)行預(yù)測(cè)效果對(duì)比。選取正常時(shí)間段,以及節(jié)假日(新年)期間,兩種場(chǎng)景進(jìn)行驗(yàn)證。
3.2.1 正常時(shí)段
從圖3中可以看出,所提出的模型相比于其他單個(gè)模型,具有更好的擬合效果。從表1中可以看出,在正常時(shí)間段,相比于常用的單個(gè)模型,LightGBM-SVR組合模型在RMSE上,提升了3.6%,MAE提升了19.6%,MAPE提升了30.5%;加入LSTM進(jìn)行誤差修復(fù)后,相比于原始組合模型,RMSE又提升了19.3%,MAE提升了11.9%,MAPE提升了14%。因此,提出的LightGBM-SVR-LSTM模型具有較高的精度。

輕量級(jí)梯度提升機(jī)(light gradient boosting machine, LGB)圖3 正常時(shí)間段預(yù)測(cè)效果對(duì)比Fig.3 Comparison of prediction results in normal conditions

表1 正常時(shí)間段預(yù)測(cè)效果對(duì)比Table 1 Comparison of prediction results in normal conditions
3.2.2 節(jié)假日期間
從圖4可以看出,所提出的模型相比于其它單個(gè)模型,具有更好的擬合效果。從表2中可以看出,在節(jié)假日時(shí)間段,相比于常用的單個(gè)模型,LightGBM-SVR組合模型在RMSE上,提升了5.5%,MAE提升了10.6%,MAPE提升了0.9%;加入LSTM進(jìn)行誤差修復(fù)后,相比于原始組合模型,RMSE提升了20.0%,MAE提升了21.7%,MAPE提升了25.0%。因此,在節(jié)假日期間,提出的LightGBM-SVR-LSTM模型也具有較高的精度。

圖4 節(jié)假日時(shí)間段預(yù)測(cè)效果對(duì)比Fig.4 Comparison of prediction results during holidays

表2 節(jié)假日時(shí)間段預(yù)測(cè)效果對(duì)比Table 2 Comparison of prediction results during holidays
4 結(jié)論
提出了一種基于LightGBM-SVR-LSTM的停車(chē)區(qū)剩余車(chē)位短時(shí)預(yù)測(cè)組合模型,并利用某停車(chē)區(qū)歷史數(shù)據(jù)進(jìn)行驗(yàn)證,根據(jù)實(shí)例分析結(jié)果,得到以下結(jié)論。
(1)通過(guò)小波分析結(jié)合3σ原則可以進(jìn)行數(shù)據(jù)清洗,并保留原始數(shù)據(jù)特征;再結(jié)合KNN模型對(duì)噪聲數(shù)據(jù)敏感性低的特點(diǎn),可以用其來(lái)進(jìn)行異常數(shù)據(jù)修復(fù)。
(2)相比于手動(dòng)構(gòu)造特征,LightGBM可以有效地進(jìn)行特征提取,將提取的特征放入SVR模型,可以提升預(yù)測(cè)精度。在正常時(shí)間段,相比于常用的單個(gè)模型,LightGBM-SVR組合模型在RMSE上,提升了3.6%,MAE提升了29.1%,MAPE提升了30.5%;在節(jié)假日時(shí)間段,相比于常用的單個(gè)模型,LightGBM-SVR組合模型在RMSE上,提升了5.5%,MAE提升了10.6%,MAPE提升了0.9%。
(3)利用LSTM進(jìn)行模型預(yù)測(cè)誤差修復(fù),能夠提升模型的預(yù)測(cè)精度,在正常條件下,相比于組合模型,RMSE提升了19.3%,MAE提升了11.9%,MAPE提升了14%;在節(jié)假日條件下,相比于組合模型,RMSE提升了20.0%,MAE提升了21.7%,MAPE提升了25.0%;該組合模型的預(yù)測(cè)精度高于其他模型,并具有較好的魯棒性。
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-11-30 02:58:01
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
攝影之友(影像視覺(jué))(2019年2期)2019-03-05 08:27:14
中華詩(shī)詞(2018年11期)2018-03-26 06:41:34
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
