基于改進掩膜循環卷積神經網絡的瀝青路面積水分布檢測*
2022-08-24 10:41:48楊煒常曉博劉哲屈曉磊
汽車技術 2022年8期
楊煒 常曉博 劉哲 屈曉磊
(1.長安大學,西安 710061;2.北京航空航天大學,北京 100191)
主題詞:瀝青路面 積水檢測 掩膜循環卷積神經網絡 實例分割
1 前言
無人駕駛車輛的車載傳感器獲取路面信息,控制系統據此調整控制策略。研究表明,路面積水與車輪的相對位置即單側車輪遇水、雙側車輪同時或交替遇水會對車輛側向穩定性產生不同影響。通過檢測路面積水分布并判斷車輪是否遇水,進一步根據檢測信息控制轉向系統,可以防止車輛出現偏駛、側滑、急轉等情況。因此,路面濕滑狀態檢測是無人駕駛車輛安全行駛必須考慮的問題。
國內外已有許多路面積水檢測方法。Ryu等提出了一種基于視覺攝像機圖像的路面狀態識別算法,首先采用極化法將路況分為干燥和潮濕,然后采用小波變換和頻率特性判別干燥和結冰狀態,并試驗驗證了其可行性。Arturo Rankin等開發了一種基于彩色相機的水體檢測器,根據水體對天空反射強度特征、圖片中水體與周圍環境間飽和度、亮度變化特性分割積水區域。但是該檢測器主要用于野外空曠區域水體的檢測,沒有對瀝青路面積水檢測實際應用進行說明。Alok Sarwal等利用積水區域發生光學偏振原理檢測水體,此方法檢測效果好,但檢測過程需要3 個標定好的攝像頭,成本較高。Park等采用光學波長濾光鏡的紅外攝像頭獲得紅外圖片,并建立多元數據模型進行路況分類,根據分類結果分割路面圖像,但需要特制攝像頭,應用成本高。陳添丁等人根據水體具有高偏振度的特性,利用攝像頭和旋轉偏振鏡提取3幅偏振角不同的圖片,通過處理得到偏振相位圖,然后采用偏振信息可視化方法提取亮度信息,進行色調、飽和度、明度(HIS)空間合成,最后通過算法分割圖片積水區域。雖然該方法識別率較高,但實時性難以滿足需求。
隨著人工智能技術的興起,通過各種神經網絡算法檢測路面狀態已經成為新趨勢。針對上述研究中實時性與成本難以滿足要求的問題,本文采用掩膜循環卷積神經網絡(Mask Recycle Convolutional Neural Network,Mask R-CNN)作為基準模型,并改進基準模型的損失函數,基于遷移學習的方法使用自建的1 753張積水圖像訓練。訓練完成后,使用單攝像頭采集積水圖片進行測試,對積水分布區域實時分割。
2 Mask R-CNN
2.1 Mask R-CNN模型
Mask R-CNN 是將典型的快速循環卷積神經網絡(Faster Recycle Convolutional Neural Network,Faster RCNN)與分割算法全卷積網絡(Fully Convolutional Network,FCN)相結合的新算法。本文采用Mask R-CNN模型不僅可以通過邊框獲取積水大致的位置信息,還可以通過分割得到積水的具體分布位置信息。圖1 所示為Mask R-CNN的模型框架,主要由殘差網絡(Residual Network,ResNet)、特征金字塔網絡(Feature Pyramid Network,FPN)、區域候選網絡(Region Proposal Network,RPN)、感興趣區域對齊(Region of Interest Align,ROI Align)和FCN 組成。首先輸入圖像,利用ResNet、FPN完成圖像特征提取(Feature Extraction);然后采用RPN判斷前景和背景,并生成候選框,通過ROI Align操作實現區域特征聚集;最后,一條分支通過全連接層(FC)完成分類回歸(Class Regression)和目標檢測框(Box)生成,另一分支通過FCN預測目標并生成掩膜(Mask)。
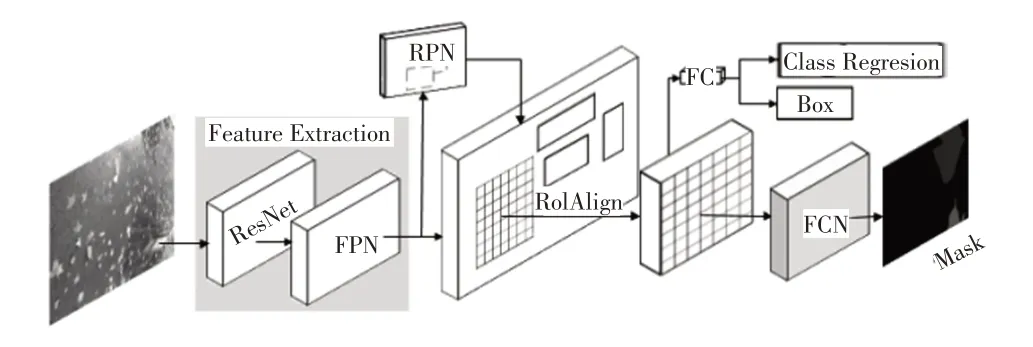
圖1 Mask R-CNN模型
2.1.1 ResNet+FPN提取特征
Mask R-CNN 采用ResNet 卷積神經網絡作為主干網絡,經過卷積、池化等操作提取圖像特征。小目標檢測對單純卷積網絡是難點,而多尺度目標檢測對小目標檢測表現較好,其中FPN 可以實現多尺度目標檢測。FPN 利用卷積神經網絡(Convolutional Neural Networks,CNN)模型高效提取圖片中各種維度的特征,是一種加強主干網絡卷積特征表達的方法,其通過自底向上處理得到特征圖,同時增強底層位置信息;再通過自頂而下和橫向連接方式將特征圖融合,生成的特征之間有關聯關系,從生成的表達特征組合中可以獲得深層和淺層特征。Mask R-CNN 將ResNet 與FPN 結合作為特征提取模塊,可以很好地獲得圖像多尺度特征。
2.1.2 RPN和ROI Align獲取候選框
RPN 是一支包含分類和回歸的多任務網絡。RPN采用滑動窗口在FPN生成的特征圖上滑動,對特征圖上的點進行分類,特征圖上每一點對應原始圖片上某一區域,根據錨框(Anchor)機制將特征圖點映射到原始圖片,并產生不同的候選感興趣區域(Region of Interest,ROI)。RPN 對候選ROI 進行前景背景分類和邊框回歸(Bounding-Box regression,BB),如圖2 所示為積水的真值(Ground-Truth,GT)框和區域候選(Region Proposal,RP)框,那么即便候選框被分類器識別為積水,由于候選框和真值框的交并比(Intersection-Over-Union,IOU)并不大,所以最后的目標檢測精度也不高。采取BB方法可以對區域候選框進行微調,使得候選框更接近真值框。

圖2 路面積水的真值框與區域候選框
同時,RPN為特征映射的每個點設置預定感興趣區域的數量,過濾部分候選ROI Align 操作,將剩余的ROI的原圖與特征圖的像素點對應,然后將特征圖與固定特征對應。Mask R-CNN 采用ROI Align 中的雙線性插值獲得坐標為浮點數的像素點上的圖像數值再進行池化,實現連續的特征聚集。ROI Align 可以很好地解決Faster R-CNN 中感興趣區域池化(Region of Interest Pooling,ROI Pooling)在提取積水區域過程中2 次量化操作(取整過程)產生候選區和回歸產生區域不匹配問題,使定位更精確,減少對掩膜操作的影響。
2.2 Mask R-CNN模型的損失函數與改進
2.2.1 模型的損失函數
Mask R-CNN 包含了目標檢測、目標分類和目標分割3個任務,因此網絡定義一個多任務的損失函數:

式中,、、分別為分類誤差、定位誤差和積水分割損失。
實際上,Mask R-CNN 共包含5 個損失函數。其中包括RPN和Mask R-CNN網絡的分類損失:
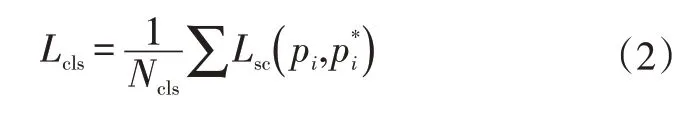
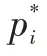
包括RPN和Mask R-CNN網絡的回歸損失:
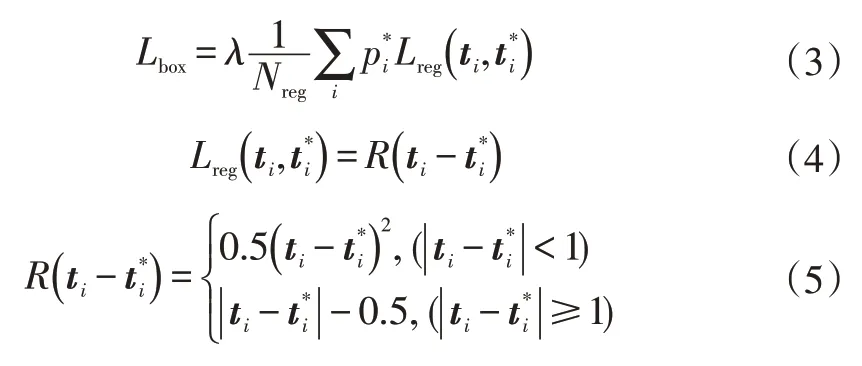
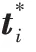
只含有Mask R-CNN網絡的掩膜損失。掩膜分支輸出是對每個類別獨立地預測一個二值掩膜,對于預測的二值掩膜輸出,對每個像素點應用S形(Sigmoid)函數,將整個掩膜損失定義為平均二值交叉熵損失。計算公式為:
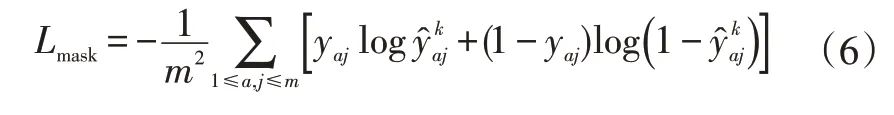
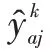
2.2.2 損失函數的改進
交叉熵損失函數過度依賴于區域信息的分割,忽略了邊界的分割。為了使Mask R-CNN 網絡在分割過程中對分割邊界更加敏感,從而獲得精確的分割結果,在損失函數中添加了一種新的邊界加權損失函數。
如圖3 所示為拉普拉斯(Laplacian)算子邊緣檢測示意,首先標出原圖積水區域后,將積水區域二值化,再利用拉普拉斯算子進行邊緣檢測,得到積水區域邊緣。

圖3 拉普拉斯算子邊緣檢測示意
在訓練過程中,邊界加權損失函數利用拉普拉斯算子分別對標記好的積水真值二值化圖像和訓練過程中預測區域二值化圖像進行邊緣檢測,捕捉邊界信息,將檢測后的結果計算差值得到距離損失,預測的積水區域越接近實際的積水區域,則距離損失越小,反之越大。隨著訓練過程中權重不斷更新,不斷減小,使得預測分割結果與標記好的積水區域相吻合,從而加強邊界損失的權重,使分割結果更為精確。拉普拉斯算子及損失定義為:
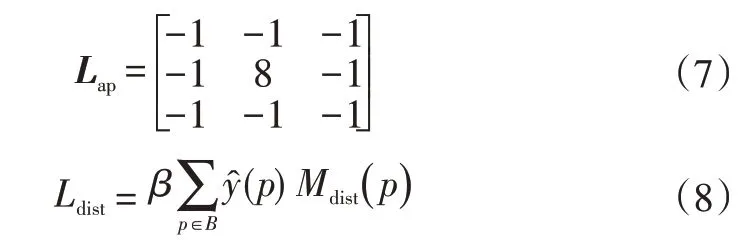
改進后的Mask R-CNN損失函數為:

3 測試與分析
3.1 模型訓練與測試
3.1.1 測試數據
本文測試使用的樣本數據是通過普通手機相機采集制作的1 753 張像素為640×640、24 位紅綠藍(Red-Green-Blue,RGB)三原色路面積水圖像,保存格式為JPG。路面積水圖像主要包括弱光、強光、有雨3種情況,樣本分別如圖4 所示。其中的1 584 張圖片作為訓練集和驗證集,169 張圖片作為測試數據。采用LabelMe 工具對樣本圖像中的積水區域進行標記,制作像素為640×640、深度為8 位、格式為PNG 的圖像。此外,采用微軟常見環境對象2014(Microsoft Common Objects in Context,CoCo2014)數據集訓 練Mask R-CNN模型的權重作為初始權重。

圖4 強光、弱光及雨中樣本示例
3.1.2 訓練和測試
對基于遷移學習的改進Mask R-CNN 模型在深度學習TensorFlow 框架下進行訓練。使用的GPU 配置為NVIDIA GeForce GTX 2060,在Windows的TensorFlow框架下,模型訓練了200輪(epoch),設置模型訓練的初始學習率為0.001,權重調節參數設置為0.000 1,動量系數為0.9。設置區域候選網絡(Region Proposal Network,PRN)產生的5 個錨點大小分別設置為32×32、64×64、128×128、256×256 和512×512。在上述訓練參數下,本文分別選擇改進MRCNN-Res101、MRCNN-Res101 和MRCNN-Res50 進行訓練。其中改進MRCNN-Res101、MRCNN-Res101 和MRCNN-Res50 分別代表以ResNet101 為特征提取網絡的改進Mask R-CNN 模型、以ResNet101為特征提取網絡的Mask R-CNN模型和以ResNet50 為特征提取網絡的Mask R-CNN 模型。其余對比模型U型神經網絡(U-Neural Network,Unet)、反卷積神經網絡(Deconvolution Network,Deconvnet)以及雙注意力神經網絡(Dual Attention Network,Danet)模型在深度學習Keras 框架下進行訓練,所有模型均訓練了200輪(epoch)。
3.1.3 對比分割網絡模型
本文將改進Mask R-CNN 模型與常見的幾種分割網絡(原始Mask R-CNN、Unet、Deconvnet以及DAnet)進行比較。Unet、Deconvnet 和Danet 均為開源網絡。其中,Unet是一個具有23個卷積層的網絡,適用于小規模的數據集訓練,目前常用于醫學圖像分割,如肝臟、乳腺等。Deconvnet 是基于牛津大學視覺幾何組網絡(Oxford Visual Geometry Group 16,VGG16)網絡中卷積部分進行改進的網絡,由反卷積層和反池化層組成,通過連續的反池化、反卷積和線性修正單元(Rectified Linear Units,ReLu)實現了像素級的語義分割。DAnet在傳統FCN上附加了2種類型的注意力模塊,學習空間與通道維度特征,可以捕捉空間特征的相互依賴性,目前常用于場景分割。
3.1.4 評價指標
在圖像分割中,常用和雅卡爾(Jaccard)系數作為評價指標。
是查準率(Precision)與查全率(Recall)的加權調和平均值,用于綜合評價模型分類效果。其中,查準率是正確預測的正樣本在預測結果為正樣本(包含正確預測的正樣本和錯誤預測的負樣本)中所占的百分比,查全率是指正確預測的正樣本在所有正樣本(包含正確預測的正樣本和錯誤預測的正樣本)中所占的百分比。各指標計算公式為:
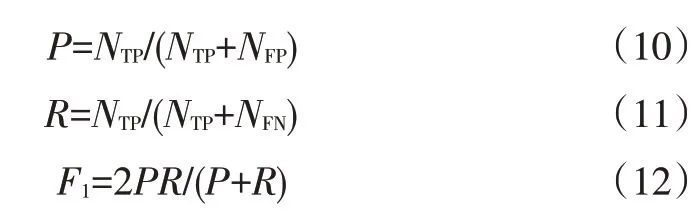
雅卡爾系數表征模型預測出的樣本集與真實樣本集的相似程度,用于評價圖片分割精度:
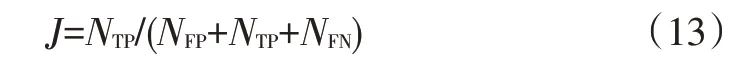
式中,為查準率;為查全率;為預測正確的正樣本數量;為預測正確的負樣本數量;為預測錯誤的負樣本數量;為預測錯誤的正樣本數量。
本文采用和作為網絡的評價指標,二者取值范圍均為0~1,數值越大,分類或分割效果越好。
3.2 測試結果與分析
3.2.1 改進MRCNN-Res101和MRCNN-Res101分割效果
用改進MRCNN-Res101和MRCNN-Res101對積水進行分割,結果如圖5 所示。從圖5 中可以看出,MRCNN-Res101 錯誤地將圖片右上角非積水部分識別為積水部分,改進MRCNN-Res101 的分割邊緣與積水的實際邊緣更相符。

圖5 原圖、MRCNN-Res101和改進MRCNN-Res101分割對比
3.2.2 改進MRCNN-Res101模型的分割速度
訓練完成后,調用訓練生成的權重對積水圖片進行分割,分別選取像素為512×512和320×320的積水圖片作為輸入,在Ubuntu 16.04 環境下利用NVIDIA GTX 2060 GPU 加速計算,得到分割時間。當模型的輸入圖片尺寸為640×640時,分割速度為229 ms/幀,當模型的輸入圖片尺寸為512×512時,分割速度為161 ms/幀,當輸入圖片尺寸為320×320時,分割速度為109 ms/幀。
3.2.3 不同模型在測試數據上的預測和分割
本文采用169張路面積水圖片作為測試數據,分別在完成訓練的Unet、Deconvnet、DAnet、MRCNN-Res50、MRCNN-Res101和改進MRCNN-Res101模型下進行測試,得到測試數據的和雅卡爾系數如表1所示。Unet和MRCNN-Res50 模型在測試集上的和雅卡爾系數在5個模型中較小,預測和分割效果較差。Deconvnet和DAnet 模型的預測和分割效果相近,效果優于Unet 和MRCNN-Res50。所有測試模型中,改進MRCNNRes101的預測效率和分割精度均最優,和最大分別為0.892 3 和0.814 6,相比于MRCNN-Res101 模型提高了1.5%和1.92%。說明改進MRCNN-Res101 模型對積水識別有很好的魯棒性和泛化能力。
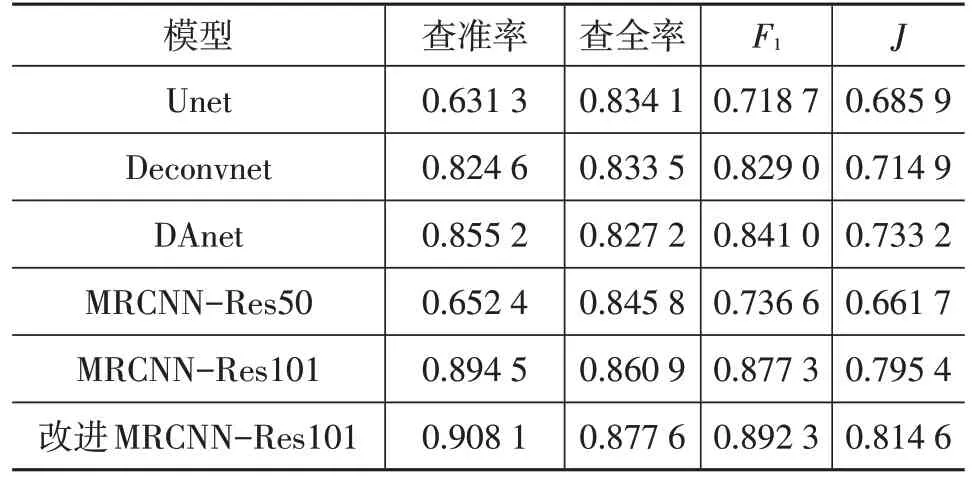
表1 不同模型在測試數據上測試結果評價指標
3.2.4 強光、弱光和雨中狀態下的測試分割效果
本文對各模型完成預測和分割的測試圖進行分析。在測試圖片中,每種積水圖片的拍攝情況主要有弱光、強光和雨中。3種拍攝情況下各模型的和雅卡爾系數如圖6所示。從圖6可以看出,圖片的拍攝情況對于分割效果有一定影響,主要表現在雨中拍攝圖片的分割效果比強光和弱光狀態下差。主要因素在于雨中的拍攝的積水形狀大多數呈現不規則現象,同時,積水區域與潮濕區域間存在較薄的水膜,算法難以辨識該水膜區域。
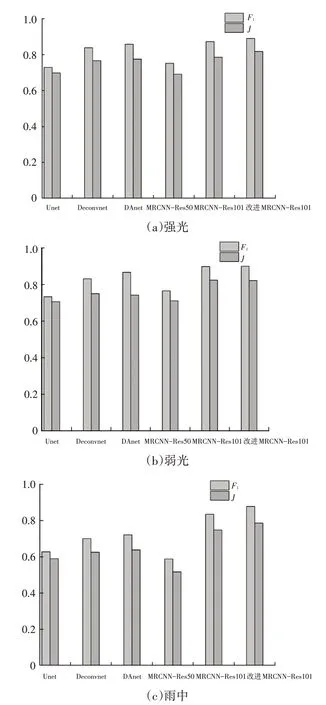
圖6 單個積水區域與多個積水區測試圖的平均F1與J
本文在測試圖中選取3張單個積水區域在弱光、強光以及雨中的拍攝圖片作為多模型對比測試圖片。
如圖7 所示為測試圖片的真實積水區域和各模型預測分割結果,從圖7 中可以看出,Unet 和MRCNNRes50 模型對單個積水區域所有情況下測試圖都出現較大面積的錯誤預測和分割現象。Deconvnet模型對弱光和雨中測試圖的分割表現較好,對強光下的積水區域出現少分割的現象。DAnet 模型對弱光和雨中的分割圖片分別出現部分區域錯誤預測和部分區域沒有被預測的現象。MRCNN-Res101 出現分割邊緣不吻合的現象,改進MRCNN-Res101模型對3種情況的測試圖的分割區域與測試圖的真實積水區域基本吻合。

圖7 單個積水區域測試圖在各模型下的分割結果
圖8所示為弱光、強光以及雨中拍攝的多個積水區域的測試圖在各模型下的分割效果。其中,3張測試圖在MRCNN-Res50模型的分割效果最差,強光下的測試圖沒有檢測到積水,所以沒有進行操作;雨中分割圖中的積水區域被錯誤檢測和分割。Unet 模型基本能夠預測和分割圖片中的多個積水區域,但也存在部分非積水區域被錯誤分割。MRCNN-Res101、Deconvnet和DAnet模型能夠完成對強光和弱光下的積水區域分割,但是積水區域間的間隙沒有被正確識別,對雨中測試圖中積水區域表現出連續不規則現象,部分區域沒有被識別和分割,不能較好地分割積水區。改進MRCNN-Res101 模型在弱光情況下不能較好地分割積水邊緣,但是在強光和雨中能夠很好地分割積水邊緣。

圖8 多個積水區域測試圖在各模型下的分割結果
從總體上看,改進MRCNN-Res101 模型對圖中積水區域的預測準確性和分割精度都比較高,能夠滿足對路面積水分割的要求。同時,與其他神經網絡模型相比,改進MRCNN-Res101 模型的掩膜分支可以通過掩膜輸出積水的位置。但是改進MRCNN-Res101模型對積水分割受到邊框的限制,無法完成對檢測框外的積水的分割。MRCNN-Res101、Deconvnet和DAnet模型能夠完成對積水的分割,但效果比改進MRCNN-Res101 模型差,對復雜不規則的積水分割表現較差。Unet模型和MRCNN-Res50 模型對積水的識別率低,因此導致分割精度也不高,顯然不適用于積水分割任務。
4 結束語
本文使用改進Mask R-CNN 從道路圖像中分割路面的積水區域。改進MRCNN-Res101模型的預測精度指標和分割精度指標分別為0.892 3和0.814 6,表現出對積水較好的分割能力,對強光、弱光以及雨中環境下積水區域的分割效果略優于Deconvnet 和DAnet 模型,明顯優于Unet 模型和MRCNN-Res50 模型,說明了改進MRCNN-Res101模型的泛化能力強。在進一步的研究中,將對圖像坐標轉換為空間平面坐標,得到路面積水分布位置的坐標信息,以更加真實地反映路面積水狀態。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
