基于IF-EMD-LSTM的數據中心CPU負載預測
2022-08-22 13:39:28李國,陳茜
計算機仿真 2022年7期
李 國,陳 茜
(中國民航大學計算機科學與技術學院,天津 300300)
1 引言
2016年12月,英國國家航空服務公司(NATS)由于兩條系統航班服務器通道均發生故障,導致數百架航班無法起飛,此次故障共造成120架航班被取消,500架航班被延誤超45分鐘,共影響約10000萬名旅客[1]。
2016年8月8日凌晨2點,達美航空公司在亞特蘭大的主數據中心發生故障,導致全球電腦和運營系統停頓。超過650各航班被取消,數千旅客滯留全球各機場,航班延誤嚴重,損失數百萬美金[2]。
一個典型的數據中心服務器可以運行成百上千資源不斷變化的作業,然而現有系統并不能適應日益增長的調度復雜性。主要原因是管理系統將工作任務低效地分配給服務器,不能在安排工作任務之前充分考慮服務器狀態。因此,高效管理數據中心資源,提高服務器負載預測精度,優化服務器資源調度至關重要。
國內外許多學者對提高資源負載預測精度問題進行了大量研究,并取得了一些研究結果。常見方法有三類,一、傳統預測方法,如 Holter-Winter,差分整合移動平均自回歸模型(ARIMA)和Prophet算法[3,5],結合歷史數據進行趨勢預測。二、人工智能方法,文獻[6]重點研究谷歌數據中心服務器CPU負載預測,使用長短期記憶網絡(LSTM)并與應用廣泛的ARIMA預測結果進行對比。結果表明,LSTM模型預測結果準確率更高,學習非線性數據的能力比ARIMA模型表現更優異。文獻[7]指出組合模型通過將兩個或多個單一模型結合起來,綜合單一模型的優點,克服了單一模型的缺點,提高了混合模型的整體預測精度。文獻[8]研究發現農業時間序列既包含線性部分又包含非線性部分,線性部分使用ARIMA建模,非線性部分使用LSTM建模。最后,得到兩種模型的混合預測結果。文獻[9]提出了EMD/EEMD-ARIMA的混合預測模型。經驗模態分解(EMD)和綜合經驗模式用于將黃河上游長期徑流預測的水文時間序列分解為不同頻率的IMF組件進行預測。
關于服務器CPU負載預測方法,相關研究主要使用傳統時間序列預測方法或單一人工智能方法。傳統時間序列預測方法雖然可變參數較少,但是對于非線性,非平穩,信噪比高的數據預測結果準確率不高,很難適應多變的時間序列預測。人工智能方法容易陷入局部最優、易發生過擬合,且模型參數不易精確獲得,導致預測精度不高。結合上述問題,本文提取某航空公司數據中心CPU負載數據,首次采用基于IF-EMD-LSTM的服務器CPU負載組合預測方法,首先對原始數據進行預處理,IF能夠去除數據中的異常點并提高原始數據信噪比;其次,LSTM的結構設計比傳統預測模型ARIMA更適合該時間序列預測,并使用BA算法優化LSTM模型,減小LSTM參數人為主觀選擇對網絡性能造成的影響。并與單一ARIMA,LSTM模型進行對比實驗。根據預測結果可知,組合模型具有更高的預測精度,對于保證系統運行不中斷,提前進行資源調度具有重要的指導意義。
2 預測模型構建
2.1 特征提取
本文采用某航空公司服務器集群數據集,該數據集詳細記錄了300+服務器從2018年11月1日至2018年11月15日,總計15天資源使用的詳細情況。然而手動為300+服務器建立資源負載預測模型不合理。因此,只為其中一臺服務器(機器ID:193)建立時間序列分析,建模和預測方法。其余服務器也是同樣的建立方法。之所以選擇數據集最活躍的機器進行研究,是因為該機器空缺值最少。以下ID為193的服務器被稱為機器A。為了提取服務器每個時間窗的工作CPU負載,考慮到某些任務只部分運行5分鐘時間窗這一事實。因此,將每相隔5分鐘時間窗任務的所有CPU讀數相加。并且觀察到一些機器不活動時期CPU讀數為0。使用線性插值方法來填充空缺值,使用空缺值的相鄰值進行填充,保持序列的連續性[10]。共計4120條數據,選取前70%的數據作為訓練集,20%的數據作為單步測試集,10%剩余數據用于驗證模型的泛化能力。提取機器A CPU負載時間序列數據”CPU_load_data.csv”文件,數據格式為{time,CPU load data},其中time代表時間,CPU load data代表CPU負載數據,具體負載數據如圖1所示。

圖1 CPU負載數據
2.2 孤立森林算法
孤立森林是基于集合的快速異常線性時間復雜度高的檢測方法。這是一種異常檢測算法滿足大數據處理的要求。孤立森林適合用于連續數據的異常檢測,并且異常被定義為“孤立的容易隔離的點,可以理解作為一個稀疏分布且遠離的點密集的人群[11]。偏遠的森林需要使用集成方法得到一個收斂值(蒙特卡羅方法),也就是說,從頭開始反復切割,然后平均每次切割的結果。孤立的森林需要使用整體方法為了得到一個收斂值(蒙特卡羅方法),也就是說,從一開始就反復地剪平均每一次切割的結果。孤立森林組成的 每一棵樹結構實現方式如下:
1)隨機選擇一個屬性A。
2)隨機選擇此屬性值的值。
3)根據A對每條記錄進行分類; 將小于A的記錄放在左邊的子樹上,并將大于或等于value的記錄放在右邊的子樹上。
4)構造左,右子樹使用遞歸方式,直到滿足以下條件:①傳入數據集僅具有一個或多個相同記錄,并且②樹的高度達到高度閾值。
對于有 4 個樣本的測試數據 1、23、29、100 遍歷一棵孤立樹,如圖2所示。從圖2中看出,樣本 100 最先被孤立出來,所以最有可能是異常數據。

圖2 測試樣本孤立樹
2.3 經驗模態分解
EMD分解可以將非平穩信號自適應地分解為一系列IMF信號和殘差。IMF滿足兩點:第一,極端點的數目和零交叉點的數目必須相等或相差不超過一。其次,在任何一點上,包絡都是由局部最大值和局部極小值點形成的。極小值點形成的包絡的平均值為零。對于給定信號,執行EMD分解的步驟如下[12]:
1)求出x(t)的上極點和下極點; 使用插值方法形成上下包絡并計算初始值m1;
2) 提取細節:
h1=x(t)-m1
(1)
3)確定h1是否滿足IMF條件。 如果滿足,則h1是x(t)的第一個成分,記錄為c1=h1,并終止分解。 如果不滿意,請對k重復以上步驟k次以獲得
h1k=h1(k-1)-m1k
(2)
其中h1k是IMF,則c1k=h1k是第一個IMF信號x(t)的分量;
1)在上述迭代滿足術語標準標準偏差(SD)之前,標準偏差通常為(0.2-0.3);
2)將c1與x(t)合并得到:
r1=x(t)-c1
(3)
3)分解c1,c2,…,cn并重復進行:組件包含不同的分量頻率段從高到低。 總而言之,原始信號的分解是

(4)
2.4 蝙蝠優化算法
蝙蝠算法是Xin-Sbe Yang 等在2010 年研發的高效生物啟發式的算法[13]。蝙蝠的回聲定位的行為可以通過與待優化的目標函數相關聯的方式進行表達,即將蝙蝠尋找最優位置的過程替換為尋找目標函數fitness和目標變量x=(x1,x2,x3,…,xd)T的最優值問題。蝙蝠算法的具體運行過程如下:
步驟一:設置蝙蝠的個數N,維度d,迭代次數r,脈沖響度A,脈沖頻率r,脈沖頻率范圍[Qmin,Qmax],位置范圍[xmin,xmax]以及適應度函數fitness。

Qi=Qmin+(Qmax-Qmin)*γ
(5)
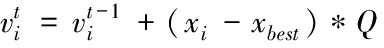
(6)

(7)
隨機產生一個數rand,比較rand與脈沖頻率r的大小關系,如果rand大于r,則通過式(16)對當前最優解xbest進行隨機干擾。如果rand比r小則直接利用式(17)引進行越界處理,具體公式如下所示

(8)

(9)
式(16)中,ρ∈[-1,1]的隨機值,AVt是t時刻蝙蝠群體脈沖n向度的平均值。
步驟四:對新位置xt;求適應度函數值fnew。 生產隨機數rand,若rand小于脈沖響度A并且fnew小于目前位置適應度函數值fitness,則把fnew賦值給fitness。
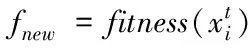
(10)


(11)

(12)

步驟六:重復步驟二至步驟五,直至達到最大法代次數或者最優適應度函數值小于設定值。
2.5 長短時記憶網絡
在閾值神經網絡中,LSTM網絡最為著名。存儲器是用來判斷的信息是否有用。與傳統時間序列預測模型相比,LSTM模型解決長期依賴問題并充分考慮時間序列數據的特點。圖2顯示了LSTM模型原理圖。
LSTM包含四個非常關鍵的元素輸入門,輸出門,遺忘門,和內存單元。下面對LSTM中各部分進行描述:
1) 輸入門
it=δ(Wi·[ht-1,xt]+bi)
(13)
式中,wt表示輸入門的權重矩陣,bt為偏置,δ為 sigmoid函數
(14)
2)輸出門
ot=δ(Wo·[ht-1,xt]+bo)
(15)
式中,W0表示輸出門的權重矩陣,b0為偏置。
3)遺忘門
ft=δ(Wf·[ht-1,,xt]+bf)
(16)
式中,Wf是遺忘門的權重矩陣,bf為偏置,δ為 sigmoid。
4)內存單元
ct=tanh(Wc·[ht-1,xt]+bc)
(17)

圖3 LSTM原理圖
ct=ft·ct-1+it·ct
(18)
式中,Wc為存儲單元的權重矩陣,bc為記憶單元的偏差項,tanh 函數表達式為:
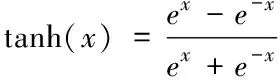
(19)
LSTM的最終輸出由輸出門和單元狀態決定
ht=ottanh(ct)
(20)
其中初始化時,c0=0,h0=0,LSTM的輸入單元為x(t),輸出單元代表h(t)。
首先本文設置LSTM除初始值和閾值之外的數,通過構造每層256個神經元的兩層LSTM,可以更改歷史序列長度,batch_size和訓練回合,以找到最適合該參數的值。 平均絕對誤差用作模型的評估指標:
將訓練回合編號設置為50; batch_size為20; 歷史序列長度為5、10、15、20、25。預測結果如表1所示。其中,當歷史序列長度為20時MAPE最小。

表1 不同歷史序列下的預測結果
將歷史記錄序列的長度設置為10;訓練數回合為50;表2中顯示了預測結果。batch_size為52時,誤差最小。

表2 不同batch_size下的預測結果
將歷史記錄序列的長度設置為10;batch_size為20時;訓練回合的數量分別為30、50、80、100,300和1000。預測結果如表3所示。其中,當訓練輪回合為80時,誤差最小。

表3 不同訓練回合下的預測結果
LSTM除初始權值和閾值外最優參數設置,如表4所示。

表4 LSTM參數設置
3 BA-LSTM模型構建流程
步驟一:首先根據本文第三部分靜態確定LSTM參數,除初始權值和其閾值;
步驟二:準備數據:利用IF進行數據預處理,EMD進行數據分解;
步驟三:BA參數初設和訓練:首先根據式(21)求出BA算法的維度,其中,j,k,l表示LSTM中輸入層,隱含層和輸出層的個數;
d=4*j*k+4*k+j*k*l
(21)
BA與LSTM目標函數相同:

(22)
其中:o是指蝙蝠中的第o個;p是指第p條數據;oip和Tip是第o只蝙蝠確定模型LSTM樣本數據p下的輸出值和真實值;m是指樣本總數。
步驟四:將步驟三得到的最優值等于LSTM的初始權值和閾值,訓練BA-LSTM模型。
4 混合算法總體流程
基于IF-EMD-LSTM的CPU負載趨勢預測方法總體流程如圖4所示。

圖4 基于IF-EMD-LSTM的CPU負載預測方法流程圖
1) 數據預處理:采用孤立森林算法對數據中的高異常點進行剔除并提高信噪比。
2) 數據分解:為了進一步提高預測精度,采用EMD算法將輸入數據分解為不同頻率的IMF組件和殘差。
3) 優化神經網絡:利用BA算法優化LSTM初始權值和閾值,利用優化的值構造BA-LSTM模型,減少人為主觀選擇參數對網絡性能的影響。
4) 神經網絡訓練:對每組IMF組件執行優化后的LSTM網絡訓練,并通過單獨的優化后的LSTM神經網絡預測每個IMF和殘差,并從每個預測值中重建預測值。
5 實驗評價指標
評價指數
模型預測量化指標使用平均相對誤差(MAPE)以及均方根誤差(RMSE)評估算法性能:

(23)

(24)
其中m是序列長度,Xj是數據的真實值,j是數據的預測值。
6 實驗結果與分析
實驗需要Keras深度學習框架下的LSTM庫,Sklearn機器學習庫,Pandas,Numpy,Matplotlib科學計算庫和繪圖庫。分別使用ARIMA,LSTM和IF-EMD-LSTM混合模型進行預測。圖5顯示了孤立森林對異常點去除情況的展示。從圖中可以看出,一些高爆炸異常數據已被消除。圖6顯示了使用EMD算法對數據進行分解的結果,將數據分解為不同頻率的IMF組件和殘差。圖7顯示了使用ARIMA模型預測,圖8顯示了使用LSTM預測模型的曲線預測結果。圖9顯示了使用IF-EMD-LSTM混合算法總體預測結果。
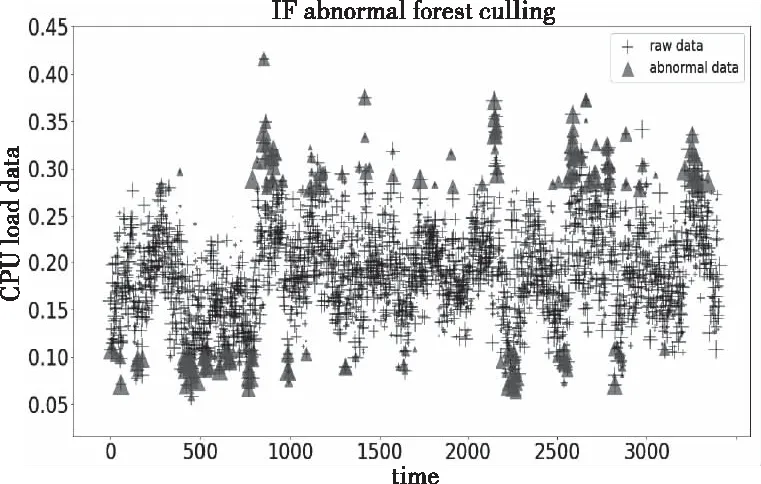
圖5 孤立森林原始數據異常點去除

圖6 EMD分解后數據曲線
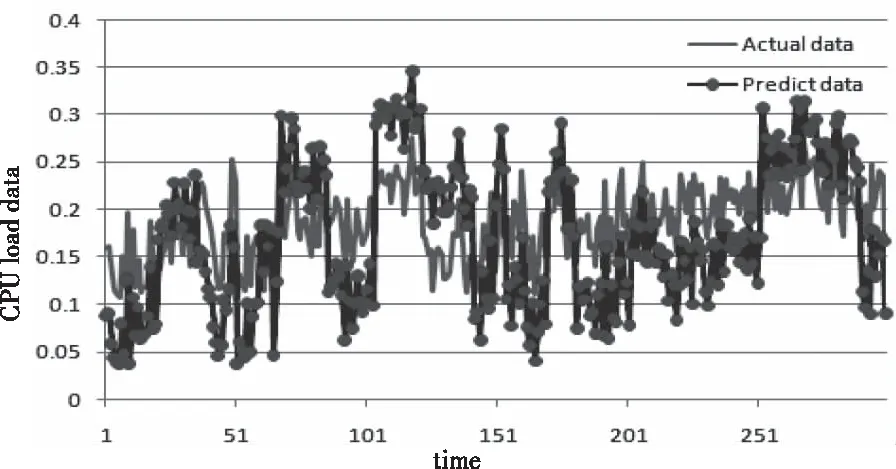
圖7 ARIMA模型預測結果

圖8 LSTM模型預測結果

圖9 IF-EMD-LSTM模型預測結果
三個預測算法使用MAPE和RMSE做為評價標準,預測結果對比如表5所示。從表中可以看出MAPE和RMSE優于ARIMA和LSTM預測模型。

表5 三種預測算法評價指標的比較
7 結語
1)根據從某航空公司服務器資源負載數據提取出的CPU負載時間序列數據特點,利用IF和EMD算法對原始數據進行預處理,解決原始數據非平穩,非線性,信噪比高對預測模型性能影響較大的問題。
2)引入蝙蝠算法(BA)優化LSTM,避免了單一理論方法的局限性,組合預測模型與單一ARIMA和LSTM模型預測相比平均相對誤差(MAPE)分別提高了18.72%和8.71%,預測效果更佳。使用組合預測模型進行服務器CPU負載預測相比單一模型有了顯著改進。
3)本文著重于研究服務器負載資源中CPU資源使用情況,未考慮其它因素,如內存,磁盤,網絡等。
接下來的研究,將結合CPU資源與其它因素對服務器負載情況進行預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
