基于 LSTM 循環神經網絡的排產預測
2022-08-19 08:19:36上海市建筑科學研究院有限公司上海建筑機械安全智能控制工程技術研究中心上海0003上海市建筑科學研究院科技發展有限公司上海01506
綠色建筑 2022年4期
關鍵詞:模型
周 恒 (1. 上海市建筑科學研究院有限公司上海建筑機械安全智能控制工程技術研究中心, 上海 0003;. 上海市建筑科學研究院科技發展有限公司, 上海 01506)
在“雙碳”目標日益緊迫的背景下,中國信息通信研究院發布《企業數字化轉型藍皮報告—新 IT 賦能實體經濟低碳綠色轉型》,聚焦石油石化、電力和制造 3 個碳排放能耗大戶,對其數字化最新進展、轉型成效、痛點難點、相關技術、業務場景與轉型路徑進行了深度剖析。工信部智能制造試點示范項目數據顯示,相關制造企業在數字化、智能化轉型后,其能源利用率平均提升 16.1%,最高達到 1.25 倍,節能降耗正向賦能作用顯著。通過以上數據可以看到,在推進“雙碳”工作實施落地的過程中,新 IT 相關數字技術正成為驅動產業綠色低碳改造、實現節能降耗減排的重要引擎,正成為促進能源效率提升、能源結構優化的重要動力,正成為推動企業發展模式綠色低碳轉型、實現人與自然和諧共生的重要手段。
推進數字化轉型升級和實現智能制造,是傳統制造業的必經之路,制造業的核心是生產,數字化生產是指企業應用新 IT 數字技術如數字孿生、人工智能、大數據等,從計劃、質量、物料、設備等多維度實現自感知、自決策,以達到智能化的目標。作為數字化生產的源頭,全面準確地預測分析客戶的需求,對于計劃調度的優化和產能的合理配置都是極其重要的,能夠有效降低市場的不確定性對生產的沖擊,對歷史客戶需求數據的分析以及對未來一段時間內的需求預測,是發揮大數據輔助決策功能的重要基礎。
生產需求預測具有典型的時間序列數據特征,具有不穩定性、隨機性、復雜性等特征。針對時間序列預測問題,現有的主要研究成果方向,主要包括經典的線性回歸模型和基于機器學習的預測模型。由于時間序列數據基本屬于非線性,因此機器學習的預測模型效果要遠好于線性回歸模型。本文選擇機器學習中的 LSTM 循環神經網絡,它具有出色的非線性擬合能力,能夠有效提升預測效果。
1 循環神經網絡
1.1 基礎循環神經網絡(RNN)
RNN 網絡結構如圖 1 所示,RNN 模型在 t 時刻的輸入為 Xt,上一時刻的狀態 zt-1傳遞到當前時刻,并與參與當前運算,獲得當前時刻的輸出 Yt和狀態 zt,并將 zt傳遞到下一時刻,影響下一時刻的運算,運算公式簡化如式(1)和(2)所示,其中的 a、b、c、u、v、w 為參數,通過模型訓練后獲得最優解。
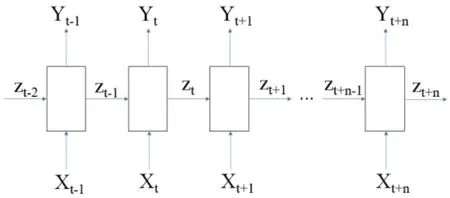
圖1 RNN 網絡結構圖

1.2 長短期記憶循環神經網絡(LSTM)
相較于傳統循環神經網絡無差別的記憶所有信息,導致重要信息經過長期迭代后丟失,LSTM 采用了“門控制”的思想,忘記門將部分無用信息剔除,更新門確定給記憶細胞添加哪些信息,輸出門篩選需要輸出的信息[1]。因此,在深層次網絡結構中,也能留下重要信息并傳遞下去,可以解決長期時序信息處理時梯度消失的問題[2]。LSTM 的單元網絡結構如圖 2 所示。
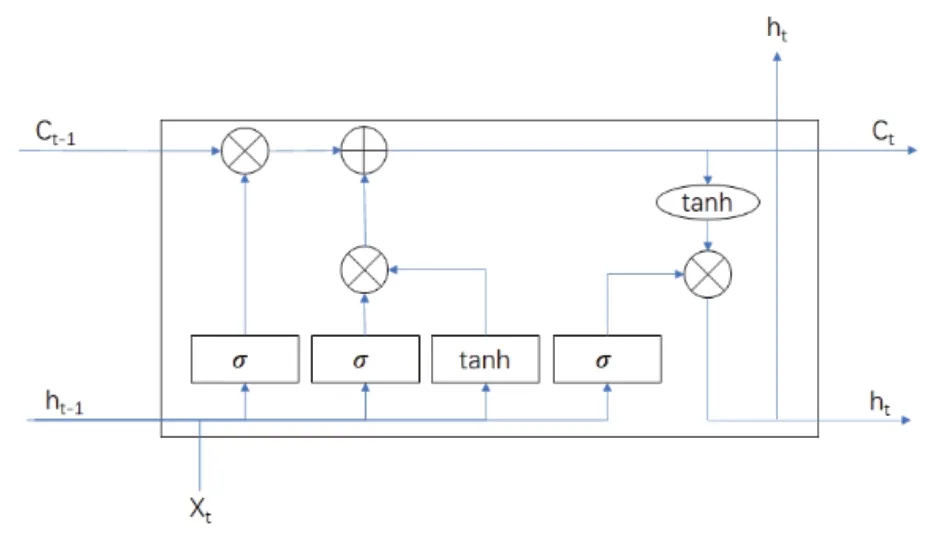
圖2 LSTM 網絡結構圖
其中 LSTM 的核心部分為單元狀態如式(3)所示。

遺忘門原理:ft是一個[0,1]的向量如公式(4)所示,通過單位乘運算,將上個單元的 Ct-1的部分特征信息保留到 Ct中。通常使用 sigmoid 作為激活函數,sigmoid 的輸出是一個 [0,1] 區間內的值,計算公式如式(5)所示。

輸入門原理: it如公式(6)所示,和 ft一樣也是一個[0,1]的向量,用于控制將 Ct有用的特征更新 Ct,同樣由 Xt和 ht-1經由 sigmoid 激活函數計算而成。Ct表示單元狀態更新值如式(7)所示,由輸入數據 Xt和隱節點 ht-1經由一個神經網絡層得到,單元狀態更新值的激活函數通常使用 tanh 如圖 2 所示 。
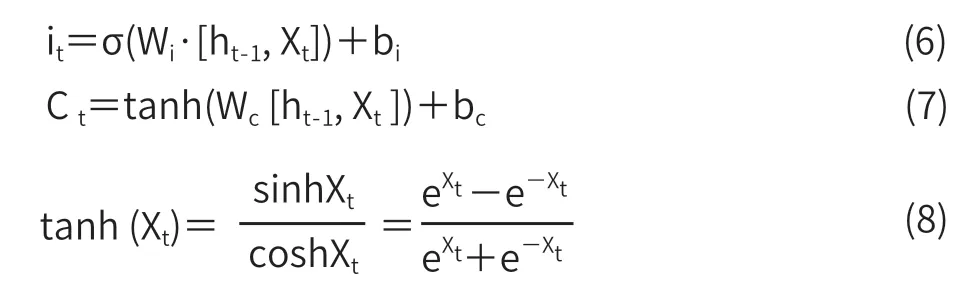
輸出門原理:輸出 ht由 ot和單元狀態 Ct計算得到,其中 ot的計算方式和 ft以及 it相同,ot、ht計算如式(9)、式(10)所示。

以上公式中的 Wf、Wi、Wo為隨機權重參數,bf、bi、bo為偏置參數。
2 循環神經網絡的產品排產預測模型
2.1 建模流程及方法
本文通過某建筑機械制造工廠的實際數據做分析,使用神經網絡模型實現排產預測,建模和訓練主流程如圖 3 所示。收集 2019—2022年的某客戶的銷售數據,將 2019年和 2020年的數據作為訓練數據集,2021年和 2022年的數據作為測試數據集,為了數據更快收斂將數據進行歸一化處理。首先進行數據預處理,把數據轉換成可以用于 RNN 輸入的數據。接著建立 RNN 模型,通過訓練數據集訓練 RNN 模型,得到預測模型,再將測試數據導入預測模型獲得預測結果,并將預測結果與實際數據做對比。
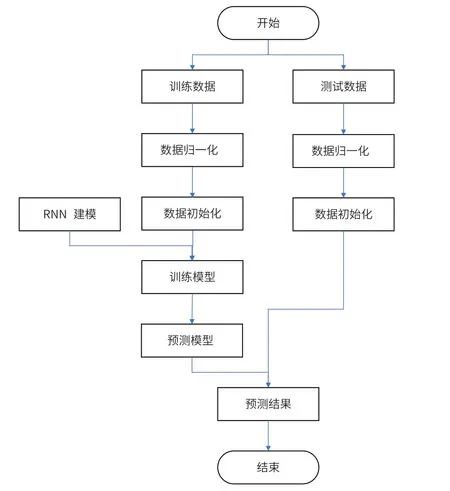
圖3 建模和訓練流程圖
數據初始化:選用長度為 7 個數據的窗口,對第 8 個數據進行預測,對未來一周的產品銷售情況進行預測。提取數據方法如圖 4 所示,形成樣本數 250 個,序列長度為 7 ,數據維度為 1。
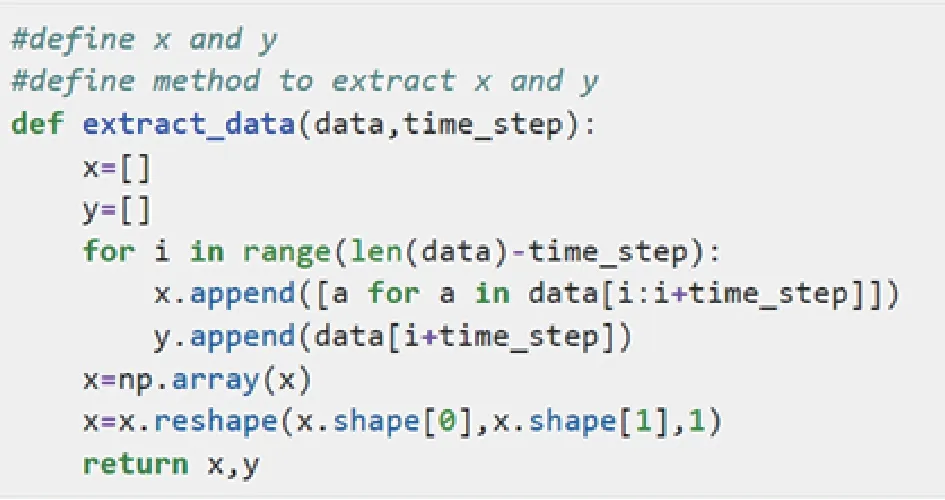
圖4 數據初始化方法
2.2 基礎 RNN 建模及結果
首次建模參數采用單層 RNN 結構,輸出 5 個神經元,激活函數選用 ReLU,輸出層選用單神經元,激活函數選用 linear,配置參數中優化器選用 adam,損失函數選用最小均方誤差(MSE)。
30 個樣本計算一次梯度下降,經過 1000 次訓練后,損失函數值為 0.0107,效果不是很理想。如圖 5 所示,藍色為測試數據集的實際曲線,黃色為預測數據曲線,在徒增和陡降時擬合的效果不佳。利用訓練后的模型對測試組數據進行預測,結果如圖 6 所示,兩條曲線也是欠擬合狀態。

圖5 訓練數據集預測結果圖
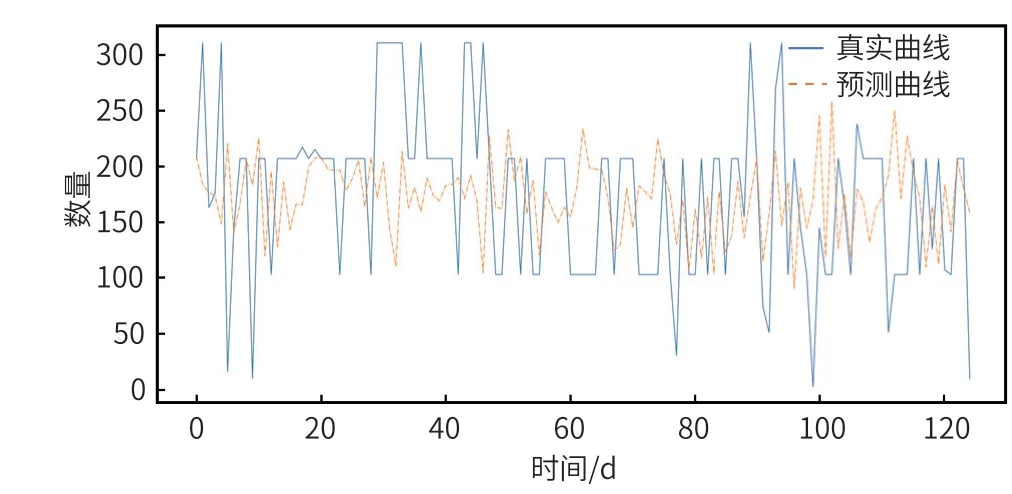
圖6 測試數據集預測結果圖
2.3 LSTM 循環神經網絡建模及結果
設置模型常量:采用函數式構造流程,設置 2 層 LSTM,1 層全連接,1 層 dropout,最后連接 1 層全連接。預測輸入神經元個數為 5 個,LSTM 單元中的神經元個數為 10,LSTM 單元個數為 7,輸出神經元個數為 1,學習率為 0.0007。
神經網絡變量:隨機產生輸入和輸出層的權重,以及 dropout 參數。
LSTM 的輸入樣本為(samples, timesteps, features),根據訓練集生成時間序列樣本數據集為(249,7,1)共 249 個樣本,測試集生成時間序列樣本數據集為(125,7,1)共 125 個樣本,lookback 設置為 7,用前 7 天的數據來預測下一天的數據。
32 個樣本計算一次梯度下降,經過 100 次訓練后,損失函數值為 3.0750×10-8,效果較理想。如圖 7 所示,為訓練集預測數據,藍色為訓練數據集的實際曲線,黃色為預測數據曲線,曲線擬合度較高。如圖 8 所示,為測試集預測情況,效果也較為理想。
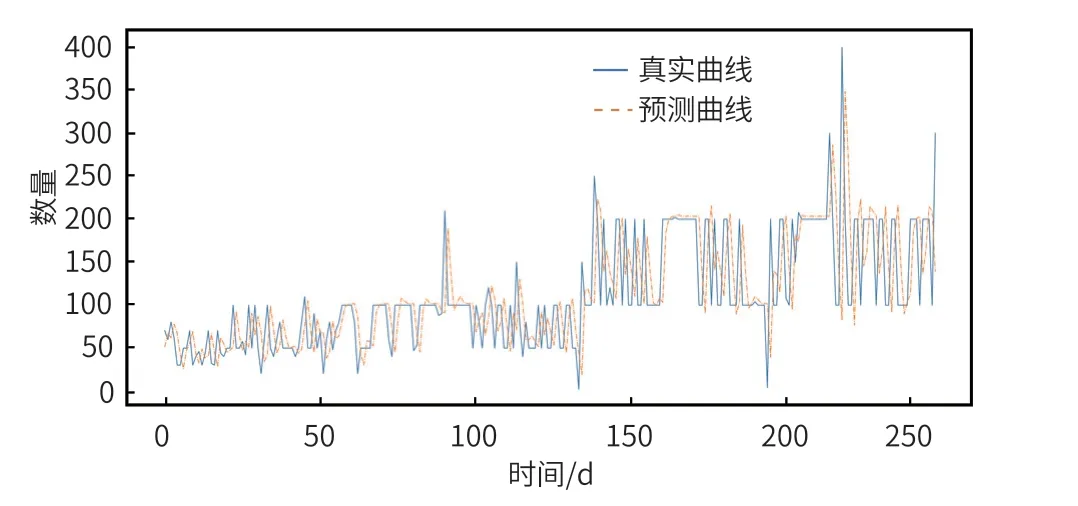
圖7 訓練數據集預測結果圖
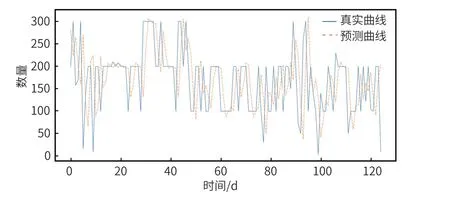
圖8 測試數據集預測結果圖
2.4 RNN 建模與 LSTM 建模比較與優化
對建筑機械制造工廠的 2019—2022年的某客戶的銷售數據運用 RNN 和 LSTM 分別進行建模分析,通過損失函數對兩個模型進行評價,結果如下表 1。

表1 RNN 與 LSTM 模型效果比較表
從兩者預測結果圖中可以看到兩種模型都有預測滯后問題,把測試集的真實值及預測值畫出來對比一下,就會發現 t 時刻的預測值往往是 t-1 時刻的真實值,也就是模型傾向于把上一時刻的真實值作為下一時刻的預測值,導致兩條曲線存在滯后性,也就是真實值曲線滯后于預測值曲線,就像圖 6 和圖 8 所顯示的那樣。之所以會這樣,是因為序列存在自相關性,如一階自相關指的是當前時刻的值與其自身前一時刻值之間的相關性[2]。因此,如果一個序列存在一階自相關,模型學到的就是一階相關性。而消除自相關性的辦法就是進行差分運算,也就是我們可以將當前時刻與前一時刻的差值作為我們的回歸目標。
3 結語
基于 LSTM 雙向循環神經網絡算法的排產預測模型能夠有效精準的預測客戶的需求,提前量有利于生產計劃安排,也助于產能的合理規劃,錯峰用電節約成本,提高抵抗疫情、氣候、市場、原料等不確定因素的影響,使得企業具有更高的生產管理韌性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
