基于校園上網行為感知的學生成績預測方法
2022-08-12 14:28:10崔超然馬樂樂王飛超馬玉玲尹義龍
計算機研究與發展 2022年8期
姚 麗 崔超然 馬樂樂 王飛超,3 馬玉玲 陳 勐 尹義龍
1(山東大學軟件學院 濟南 250100)2(山東財經大學計算機科學與技術學院 濟南 250014)3(齊魯師范學院網絡信息中心 濟南 250001)4(山東建筑大學計算機科學與技術學院 濟南 250101)
教育是立國之本,強國之基.隨著互聯網技術的快速發展,收集教育相關數據變得更為方便快捷,對教育大數據的分析、挖掘和應用是教育發展的重要需求和必然趨勢[1].學生成績預測,又稱為學生學業表現預測,是指利用學生的相關信息預測其在未來的學業表現[2],包括課程成績、學期末綜合成績以及是否存在退學風險等.借助學生成績預測技術,教師可以清晰洞察學生的學習狀態與質量,并以此為基礎開展差異化教學,滿足學生的個性化學習需求,真正達到“以評促學”的目的.此外,學生成績預測技術也有助于高校開展學業預警工作,特別是根據對學生成績的實時預測結果建立動態的預警機制,及時發現可能無法正常完成學業的學生,引導他們走出困境,順利實現人才培養的目標.因此,無論是從提升教學效果還是從強化學生管理的角度來看,學生成績預測技術都具有重要的研究價值和實踐意義.
近年來,學生成績預測受到國內外學者的廣泛關注,涌現出了一系列卓有成效的研究工作.早期的研究大多集中在教育學和心理學領域,試圖探索影響學生學業表現的關鍵因素,例如性格構成、學習動機、家庭環境等.這類研究主要依據部分學生提供的自我評估報告,在樣本規模、時效性等方面存在較大的缺陷,所得出的結論也易受到受訪個體主觀意識的影響.部分研究采用學生在學習過程中的表現信息,例如出勤情況[3]、作業完成情況[4]、階段性測試成績[5]等,對學生的課程最終成績進行預測.由于課程學習過程的表現信息與最終成績存在較強的關聯性,所得模型往往可以取得較好的預測性能.但是,此類研究需要課程開展之后一段時間方可進行,因而無法預測學生在課程初始階段的學習表現,導致預測結果存在一定的滯后性[6].
值得注意的是,隨著我國高校信息化建設的持續推進,大學校園網絡認證系統越來越完善,學生可以通過個人電腦或者移動設備在校園內方便地接入校園網絡,各高校也逐步積累了豐富的學生校園上網行為數據.教育心理學領域的研究已經表明:人的外在行為表現和學習能力密切相關.受此啟發,我們認為不同的上網行為可能也在一定程度上反映了學生不同的學習狀態.例如,課余時間頻繁訪問教育類型網站表明學生持續保持學習狀態,因而在考試中更有可能取得優異的成績.因此,本文提出以校園上網行為感知為切入點,對學生成績預測問題展開研究,通過分析挖掘學生的上網行為日志,構建有效的學生行為特征,進而預測學生未來的學業表現.
然而,在實現上述目標時仍面臨著諸多挑戰:
1) 學生的上網行為通常按照時間順序被記錄,因而對上網行為進行分析可以被看作是一個典型的行為序列建模問題[7].但是,上網行為往往持續發生,導致行為序列的長度很大,傳統的序列分析方法難以對長序列數據進行有效分析.
2) 現有的相關工作[8-9]需要通過特征工程對學生行為序列進行處理并提取特征,特征的可靠性高度依賴于人工經驗和領域先驗知識,設計合理有效的序列特征具有很高的難度.
3) 由于很難準確地預測學生的具體成績分值,現有方法大多關注于預測學生在成績上的相對排名.但是,對于學生數量有限的專業,如何在訓練時有效緩解數據稀疏性問題是一個亟待解決的問題.
針對上述問題,本文提出了一種雙層自注意力網絡(dual-level self-attention network, DEAN)來建模學生的上網行為特征.受到近年來自注意力機制在諸多序列建模任務上的良好表現[10],該深度學習模型可以端到端地學習學生上網行為特征,避免引入特征工程.具體來說,首先利用低層級的自注意力層來建模學生一天內不同時間段的上網行為,構建局部上網行為特征;進一步地,利用高層級的自注意力層將學生在不同日期的局部上網行為進行融合,最終構建全局上網行為特征.相比于傳統的循環神經網絡等方法[11],自注意力網絡被證明可以更為有效地捕獲序列數據之間的長時依賴關系[10],而本文進一步引入級聯式架構來分別提取學生的局部上網行為特征和全局上網行為特征,從而可以更好地解決長序列數據建模問題.
此外,本文引入多任務學習策略[12].通過共享雙層自注意力層的模型參數,實現在統一的框架下同時訓練面向不同專業的學生成績預測模型,從而有效緩解部分專業訓練樣本不足的問題.最后,設計了一個基于學生排名差的代價敏感損失函數(cost-sensitive loss)[13],進一步提升了預測方法的準確性.
本文工作的主要貢獻有3個方面:
1) 與傳統方法基于學生歷史學習表現或校園一卡通刷卡記錄等數據進行研究的思路不同,本文從校園上網行為感知的角度來進行學生成績預測,為后續研究提供了新思路、新視角.
2) 構建了一個端到端的雙層自注意力網絡來有效建模學生的上網行為序列數據,進而預測學生成績;同時,引入多任務學習策略將面向不同專業的學生成績預測問題進行關聯,并設計了基于學生排名差的代價敏感損失函數進一步提高預測性能.
3) 收集構建了一個真實的校園上網行為數據集,并將學生上網行為數據和成績數據相關聯.在該數據上的實驗結果表明,相比于傳統的序列分析方法,本文所提出的方法具有更好的性能.
1 相關工作
學生成績是衡量教育質量和教學水平的關鍵指標.學生成績預測研究對于實現個性化教學、提升教學質量具有重要意義,因而近年來受到研究人員的廣泛關注.
1.1 在線教學場景中的學生成績預測
面向在線教學場景,Ren等人[14]基于學生在慕課平臺上的視頻觀看時長、每日學習的模塊數目以及完成測驗的次數等信息,采用多元線性回歸模型預測學生在課程上的最終成績.Jiang等人[15]根據學生開課后第一周的學習行為來預測他們最終的課程成績等級.He等人[16]根據學生每周的課程參與情況,采用遷移學習方法在每一周預測學生中途放棄課程學習的可能性.Macfadyen等人[17]考慮學生在課程討論區中的發帖數量和評測完成情況,分別利用回歸和分類方法預測學生最終的成績分值以及是否存在不及格的風險.蔣卓軒等人[18]針對中文慕課中學習行為的特點將學生分類,并選擇開課后前幾周的學習行為特征,采用線性分類器預測學生是否能順利獲得課程結業證書.Li等人[19]將不同的在線學習行為看作學生的多視圖特征,利用半監督多視圖學習算法預測學生是否能完成課程.Feng等人[20]基于學習行為對學生進行聚類,并利用卷積神經網絡融合學生個人學習行為、同一類別中的他人學習行為和課程信息來預測學生是否能完成課程.
在線教育更加需要個性化、多樣性以及適應性的學習.在學生數量龐大的情況下,跟蹤和了解每個學生的學習情況對于老師來說困難很大.因此,知識追蹤(knowledge tracing, KT)近年來受到越來越多的關注.知識追蹤的流行算法有貝葉斯知識追蹤(Bayesian knowledge tracing, BKT)[21]、深度知識追蹤(deep knowledge tracing, DKT)[22]等.當學生完成一個練習后,模型會動態地更新學生的知識狀態.從這個角度來看,知識追蹤的基本思想與典型的序列行為挖掘[23]相似,基于學生相關的靜態數據,如考試數據[24]等,發現和建模學生的潛在特征或技能熟練程度.Yu等人[25]收集了學生的練習記錄和習題信息,LSTM結合注意力機制來關注學生對于類似題目的訓練情況.Chen等人[26]提出的KPT(knowledge proficiency tracing)模型通過加入教育先驗知識提高了模型的可解釋性.
1.2 在校園教學場景中的學生成績預測
面向校園教學場景,Huang等人[5]根據學生在前導課程和開課后過程性考核中的成績,分別采用4種常見的機器學習模型來預測學生在期末考試中的成績.類似地,Polyzou等人[27]根據學生的過往成績,利用多種機器學習模型來嘗試在學期開始之前對學生的課程期末成績進行預測.黃建明[28]根據不同課程之間的依賴關系以及學生在先導課程上的成績,提出了一種基于貝葉斯網絡模型的課程成績預測方法.Ma等人[29]在前期基于學生在已完成課程上的學習情況來預測其在新學期待開設課程上的成績.針對學生已完成課程不一致的問題,采用多示例學習方法將學生表示為包含不同課程的集合;并且采用多標記學習方法同時建立多門待開設課程的預測模型,使得課程間的關聯關系得到潛在的利用.
考慮到人的外在行為表現和學習能力密切相關,目前已有少量研究將校園行為信息引入到學生成績預測中.例如Lian等人[30]根據學生的借書記錄數據,利用矩陣分解算法為學生推薦書目并預測學生的平均學分績點(grade point average, GPA)成績.此外,該研究組通過統計不同學生在同一地點共同出現的次數來度量學生之間的關系親密程度,并采用圖傳播算法預測學生的GPA等級[31].Cao等人[8]和Yao等人[32]根據校園一卡通刷卡記錄數據,人為定義了代表學生校園行為規律性、學習勤奮程度和睡眠習慣的指標,并依據這些指標預測學生的GPA排名.
對于學生上網行為,Cao等人[33]統計分析了505名手機社交網站用戶收集的日志數據,發現過度使用手機社交網站會對學業成績產生負面影響.Chen等人[34]利用問卷調查的方法探討了大學生網絡使用情況與學業成績、人際關系、社會心理適應及自我評價之間的關系,發現輕度上網用戶的學業成績以及對學習狀況的滿意度均優于重度上網用戶.Xu等人[9]人為定義了上網時間、上網頻率、上網流量和分時段上網時間4種特征,基于淺層機器學習的方法來預測學生成績.
近些年,深度學習發展迅速,大家開始將深度學習與時間序列的傳統模型結合起來,出現了一些新的時間序列建模方法.Salinas等人[35]在深度學習的基礎上,提出了深度自回歸模型(DeepAR)對時間序列數據進行深度學習,設計了基于LSTM(long short-term memory)的自回歸RNN架構來解決概率預測問題.Vaswani等人[10]提出Transformer模型,該模型使用注意力機制來處理數據,Transformer模型可以使用任意的歷史數據,更加適合具有長期依賴的數據.曹洪江等人[7]發現學生學習知識的時間是動態的,提出利用LSTM模型預測學生成績.
如上所述,盡管文獻[9,33-34]已經從校園上網行為感知的角度開展學生成績預測工作,也有序列建模的方式來進行學生成績預測,但在實現時都采用基本的統計分析方法或基于特征工程的淺層機器學習方法.與之相反,本文構建了一個端到端的雙層自注意力網絡來有效建模學生的上網行為序列.
2 數據收集與分析
為了支撐研究順利開展,本文收集構建了學生校園上網行為數據集,并將學生的上網行為數據和成績數據相關聯.本節首先介紹數據集的收集過程,然后通過相關性分析來說明不同校園上網行為和學生成績之間的關系.
2.1 數據收集
隨著教育信息化的發展,校園網絡認證系統在各高校內迅速普及,每個學生海量的細粒度校園上網行為以一種完全隱蔽的方式被記錄下來.學生通過學生ID可接入校園網,一旦學生發出網絡訪問請求,都會在網絡日志文件中產生有良好格式和標識符的相應記錄,包括一個加密的學生ID、請求的URL、請求的時間、應用類型、具體應用、源和目標IP地址,以及一些終端、服務器端口等信息.結合這些記錄可以將學生ID和他們的上網行為進行一一對應.
本文中的學生校園上網行為數據來自于國內一所公立大學,經過網絡中心批準,我們收集了7個不同的專業共519名學生80天內的校園上網行為數據,時間跨度是從2020-10-01—2020-12-19.我們對上網行為數據進行脫敏處理,用偽學號代替真實學號從而達到匿名化效果,把偽學號作為主鍵把其他不相關的字段刪除,確保不會泄露網絡用戶的隱私.具體專業以及各專業學生數量如表1所示:
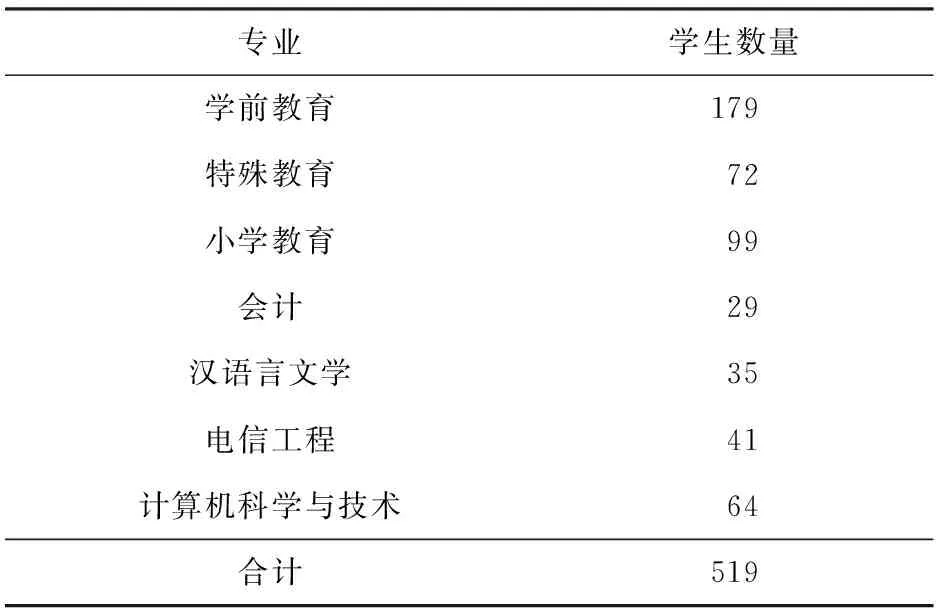
Table 1 Number of Students of Different Majors表1 不同專業學生數量
在對學生的校園上網行為進行分析的過程中發現,學生日常訪問站點的數量龐大,為了便于理解學生的上網行為模式,我們按照訪問站點的類型對學生的上網行為進行了分類,分別將學生對于新聞、IT相關、教育、娛樂、Web應用、生活相關、經濟、流媒體、社交、網購、導航、移動下載以及其他類別網站的訪問作為13種不同類型的上網行為.考慮到絕大多數學生在夜晚休息期間較少進行上網操作,本文以1 h為單位時間段,僅統計學生在每天早上6點至晚上12點共計18個時間段內產生不同類型上網行為的頻次.
對于成績信息,我們通過學校教務系統獲取了全部學生在2020—2021學年秋季學期末在不同課程上取得的考試成績和課程學分,并進一步計算得到學生的GPA.直接對學生的絕對GPA分數進行估計是相當困難的,相比之下,更為可行的方式是預測學生在成績上的相對排名[8,32].為此,本文按照GPA分數遞減的順序對學生進行排序,即成績較好的學生被排在較靠前的位置.
2.2 學生校園上網行為與成績的相關性分析
在獲取數據后,本文對學生的上網行為和成績進行了相關性分析.圖1(a)和圖1(b)分別展示了各專業學生對于教育類型網站和娛樂類型網站的訪問頻率與他們成績排名之間的相關關系散點圖.
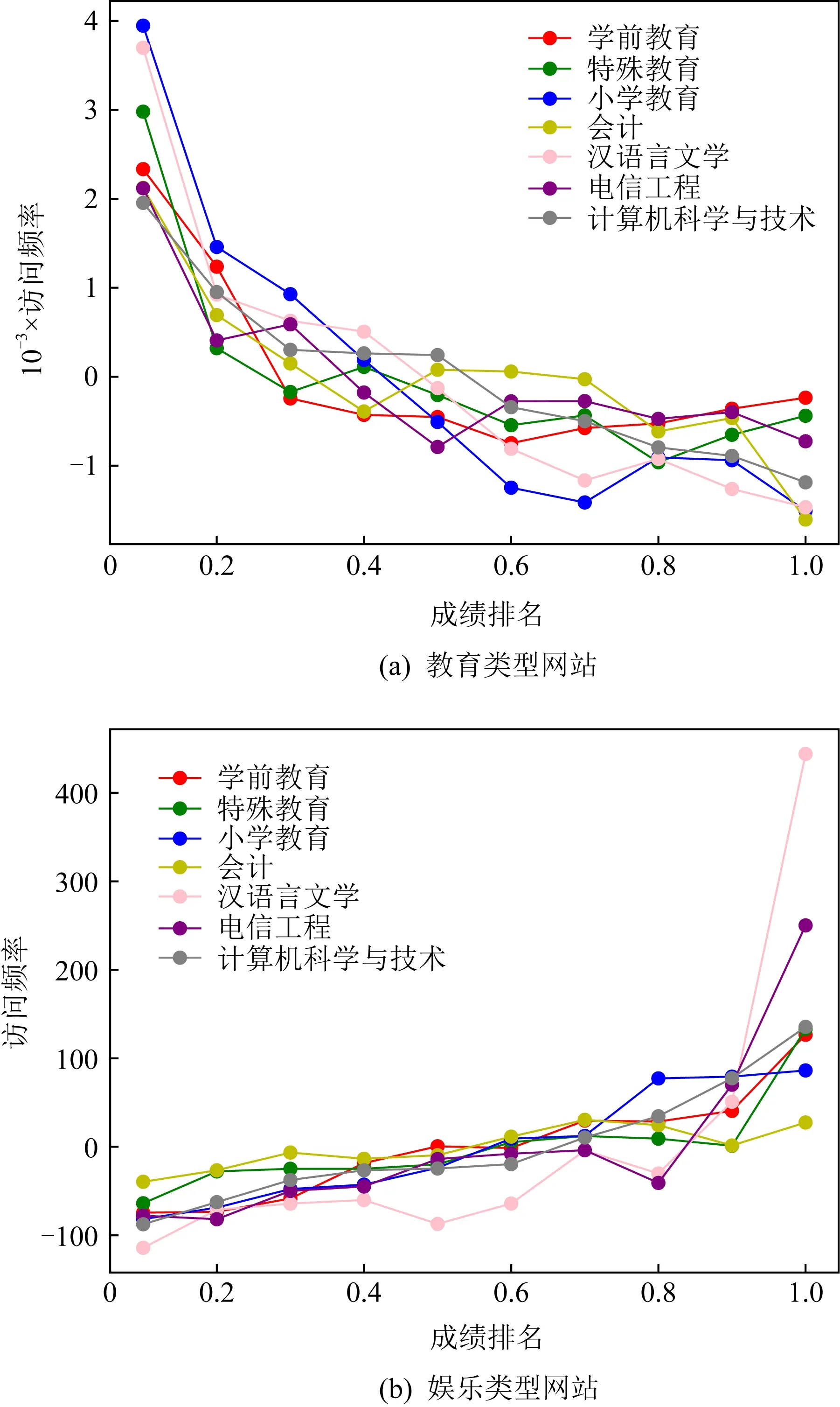
Fig. 1 The relationship between interview rating and score ranking圖1 訪問頻率與成績排名之間的關系
為了方便展示,我們對網站訪問頻率進行了去均值化操作,即先統計出同一專業所有學生對某類型網站訪問頻率的平均值,再將該專業每一位學生對此類型網站訪問頻率減去平均值.同時,采用離差標準化(min-max normalization)方法將成績排名變量變化到0~1之間,即成績排名值越接近0,意味著成績越好.從圖上可以觀察到,越頻繁訪問教育類型網站的學生通常會取得更好的成績,而娛樂類型網站的訪問頻率卻與學生成績排名呈現明顯的負相關關系.
其次,本文統計了任意兩名學生在相同時間段產生同一種上網行為的頻率,以及他們在學期末成績排名上的差值.進一步地,將成績排名差值相同的學生集合在一起,并統計集合內每一對學生相同上網行為頻率的中位數.圖2展示了學前教育專業的學生的成績排名差值與相同上網行為頻率中位數之間的相關關系散點圖.這里依舊采用了離差標準化方法將2個變量的值變化到0~1之間.可以看到,成績排名越接近的學生會更頻繁地在同一時間段內產生相同類型的上網行為.這再次驗證了,學生的校園上網行為和學習成績之間具有密切的關聯性.
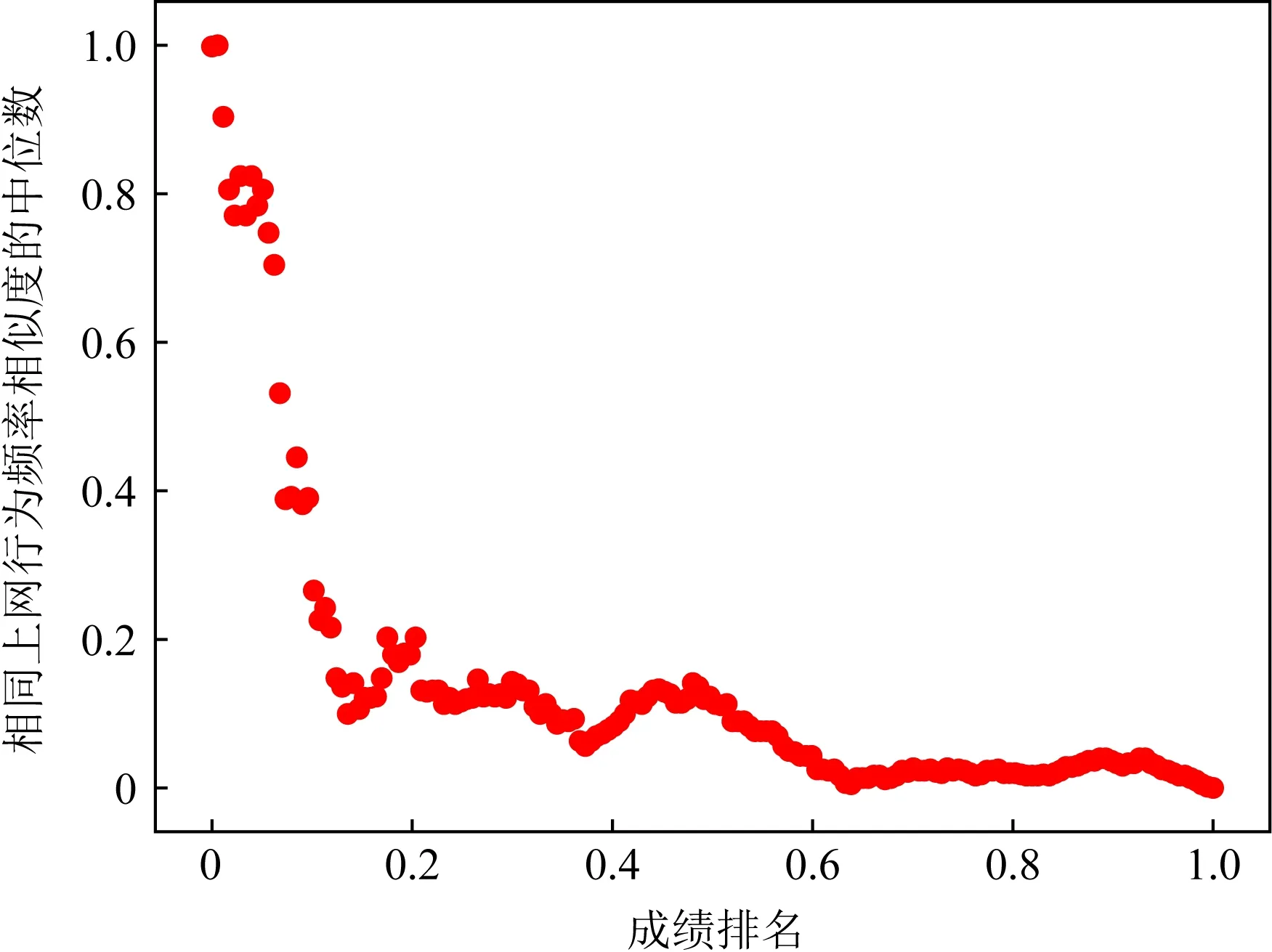
Fig. 2 The relationship between the median of the same online behavior frequency and the ranking difference圖2 相同上網行為頻率的中位數與排名差值之間的關系
3 方 法
為了有效利用學生上網行為數據來預測他們的成績,本文構建了一個端到端的雙層自注意力網絡DEAN.同時,引入多任務學習機制,將面向不同專業學生的成績預測問題進行關聯,并設計了一個代價敏感損失函數來進一步提高方法的性能.
3.1 問題定義
給定一個學生,本文收集該學生連續n天的上網行為記錄,即學生對于不同類型網站的訪問頻率.具體來說,可以用矩陣Ai∈l×m編碼學生在第i天的上網行為,其中m表示一天中時間段的個數,l表示網站的類別個數.設l為Ai的第j列,其進一步表示了學生在第i天第j個時間段的上網行為,它的第k個元素代表了學生在該時間段內對于第k種類型網站的訪問頻率.
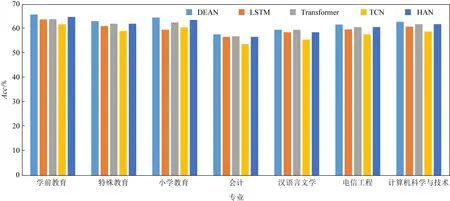
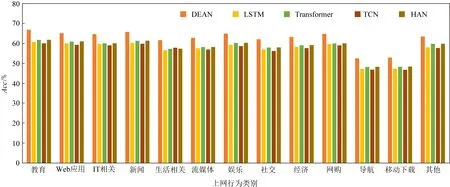
遵循現有工作中的問題設定[8,32],本文旨在預測學生之間在成績上的相對排名.形式上,方法需要找到一個映射函數f,該函數將一個學生的上網行為表示映射為一個成績值,并根據該值對學生進行排序.設u和v代表2個學生,yuv∈{+1,-1}代表兩者之間真實的成績相對關系,即yuv=+1表示u的成績優于v,yuv=-1表示u的成績落后于v.在訓練中,方法的目標是使得映射函數f的輸出盡可能地滿足學生u和v之間的成績相對關系.也就是說,若yuv=+1,則應使得f(u)>f(v);否則,則應使得f(u) (1) 其中S表示訓練學生集合. 由于學生上網行為序列的長度很大,傳統的序列建模方法難以對長序列數據進行有效分析.為了解決該問題,本文提出的DEAN包含一個由局部自注意力層和全局自注意力層構成的級聯式架構,分層次建模學生一天內的局部上網行為特征和整個時間跨度上的全局上網行為特征. DEAN的框架圖如圖3所示: Fig. 3 Architecture of the proposed DEAN圖3 本文提出的DEAN架構圖 3.2.1 局部自注意力層 (2) (3) (4) 其中,Vl∈d×l是另一個需要學習的變換矩陣. 本文采用多頭自注意力機制(multi-head self-attention mechanism),學習h組不同的變換矩陣Ql,Kl和Vl,即同時在h個潛在空間內進行特征變換,然后將結果進行拼接以實現信息互補,并通過參數矩陣Wl∈hd×d與它們相乘,獲取多頭注意力機制的輸出,計算過程: (5) (6) 3.2.2 全局自注意力層 (7) 最終,經過求和操作整合不同天的上網行為特征以獲得學生的全局行為特征表示: (8) 其中,n為總天數. 3.2.3 預測層 給定學生u,DEAN將u的全局行為特征表示輸入一個帶有sigmoid激活函數的全連接層來預測u的成績水平,即: f(u)=σ(wpg+b), (9) 其中,σ代表sigmoid函數,wp代表權重向量,b代表偏置量. 由于不同專業的課程設置以及考試內容不一致,不同專業的學生的成績無法進行直接比較.本文將對各專業學生的成績預測問題視為一項單獨的任務,并引入多任務學習策略[38-39],在一個統一的框架中同時建模多個任務.遵循經典的硬參數共享(hard parameter sharing)策略[40],使不同任務共享局部自注意力層和全局自注意力層的模型參數,但分別構建各自的預測層以實現特定任務的成績預測.通過多任務學習,DEAN可以利用不同任務之間潛在的關聯性,而且可以緩解由于某些專業的學生人數較少而導致的訓練樣本不足的問題. 在模型實現過程中,我們發現模型可以較好地判斷2個排名差距較大的學生之間的成績相對關系,但對于排名較為接近的2個學生,在預測時卻經常出現錯誤.本文將前者稱為簡單樣本,將后者稱為困難樣本.直觀上解釋,困難樣本會導致更大的樣本損失和更多的反向傳播梯度;相反,簡單樣本在訓練過程中的貢獻較小,在學習模型參數時作用有限.有鑒于此,本文進一步引入代價敏感學習(cost-sensitive learning)的思想[41],根據成績排名差距為不同的學生樣本對分配不同的權重.給定2個學生u和v,定義他們組成的學生樣本對的權重: (10) 其中,r(u)和r(v)表示u和v真實的成績排名,|S|代表專業內的學生總數.式(10)表明若r(u)和r(v)的差別越小,則u和v構成了一個困難樣本,對應的權重wuv越大,在訓練過程中更應優先確保對u和v之間成績相對關系預測的準確性.相應地,模型的損失函數被修改: (11) 本文數據集為隨機抽取的20萬對學生對,實驗過程中數據集的正負樣本比為1∶1.本文進行了一系列實驗,從不同角度對本文所提出的學生成績預測方法的有效性進行了驗證.數據集統計情況如表2所示.所有的實驗均在配置有2核2.4 GHz Intel Xeon處理器和1塊NVIDIA Titan XP顯卡的工作站上進行. Table 2 Dataset Statistics表2 數據集統計情況 實驗分別從每個專業中隨機挑選出70%和10%的學生用于訓練和驗證,將剩余20%的學生作為測試對象.基于深度學習框架Pytorch[42]對網絡模型進行訓練和測試.在訓練時,采用Adam優化器[43],設批處理大小為32,所有網絡層的初始學習率為10-5.在訓練過程中,每20個周期將學習率減半,總共訓練50個周期. 準確率(accuracy,Acc)和ROC曲線下方的面積大小(area under curve,AUC)都是被經常采用的評價模型分類性能的評價指標.面向學生成績預測任務,本文遵循了先前工作[30-32]的做法,選擇了Acc和斯皮爾曼等級相關系數評價模型的好壞.本文首先度量算法對于成對學生之間成績好壞判斷的Acc.給定測試學生集合S,Acc指標定義: (12) 同時,采用斯皮爾曼等級相關系數[44]來度量算法預測的學生成績排序和真實成績排序之間的相關性.斯皮爾曼等級相關系數越高,表明算法對于學生成績排序的預測性能越好.斯皮爾曼等級相關系數ρ定義: (13) Fig. 4 Performance comparison between the methods across students of different majors圖4 不同專業學生在不同方法上的準確率比較 4.3.1 對比實驗 在實驗中,將本文所提出的雙層自注意力網絡DEAN與3種傳統的深度序列建模方法進行對比,包括:長短期記憶神經網絡(long short-term memory, LSTM)[45]、時序卷積網絡(temporal convolutional network, TCN)[46]以及Transformer網絡[10].此外,實驗還選擇分層注意力網絡(hierarchical attention network, HAN)[47]作為基線方法. 與DEAN類似,HAN基于LSTM采用雙層注意力機制首先融合學生一天內不同時間段的上網行為,進而將學生在不同天的上網行為進行融合.不同方法之間的性能對比如表3所示: Table 3 Performance Comparison of Different Methods表3 不同方法的性能比較 % 從表3中可以看出,相比其他4種方法,本文所提出的DEAN模型在學生成績預測任務上取得了最好的結果.具體地說,DEAN在準確率和斯皮爾曼等級相關系數上分別達到了74.06%和65.85%的成績,大幅超過了次優模型Transformer,在2個指標上分別獲得了3.78%和4.68%的相對提升. 比較而言,LSTM,TCN和Transformer直接將學生長時間連續的行為序列作為輸入進行學習,但如前文所分析,對長序列數據直接建模面臨著較大的困難.HAN和DEAN都采用了級聯式架構,分別對學生每一天的局部上網行為特征和整體時間跨度上的全局上網行為特征進行建模.我們認為,DEAN優于HAN的原因可能包括:1)HAN以LSTM作為模型主框架,而過往的工作[7,10]已經證明LSTM在許多序列建模任務上的性能落后于DEAN所采用的自注意力網絡;2)DEAN引入了多頭注意力機制,從而可以同時在多個不同的潛在空間內進行特征學習,并通過融合不同空間的特征實現信息互補,有效提升了模型的預測能力. 不同專業的學生數量不同,會影響到實驗結果.本文進一步討論了不同方法對不同專業的學生進行成績預測時的性能比較,圖4展示了實驗結果.正如預期的那樣,本文所提出的DEAN在全部專業的預測結果都優于其他的方法. 4.3.2 消融實驗 為了進一步驗證本文所提方法中關鍵部件的有效性,我們進行了一系列消融研究: 1) 級聯式自注意力架構的有效性 本實驗對比了DEAN的變體,即僅考慮學生在各時間段局部上網行為的單層自注意力網絡DEAN-Local和僅融合學生在不同天上網行為的單層自注意力網絡DEAN-Global.DEAN-Local是指直接將學生在整個時間跨度上的上網行為按照時間段展開為一個長序列數據,輸入單層自注意力網絡進行成績預測.DEAN-Global則是指直接統計學生在每一天訪問不同類型網站的頻次來獲得日期級別的行為特征,通過單層注意力網絡融合不同日期的上網行為進行成績預測. 表4列出了DEAN,DEAN-Local以及DEAN-Global之間的性能對比.可以看到,DEAN在2個評價指標上均明顯優于僅基于單層注意力網絡的DEAN-Local和DEAN-Global,這表明DEAN中的級聯式自注意力網絡架構可以有效提高模型的特征學習能力. Table 4 Effect of Hierarchical Self-Attention Architecture表4 級聯式自注意力架構的影響 % 2) 多任務學習的有效性 本文通過引入多任務學習策略來緩解面向單個專業的學生成績預測任務中訓練數據較小的問題.表5比較了引入和不引入多任務學習策略的DEAN方法在性能上的差異.可以看到,前者在準確率和斯皮爾曼等級相關系數上分別提高了2.16%和1.12%.這說明多任務學習策略確實使得模型可以充分利用不同任務之間潛在的關聯性,并在一定程度上緩解了數據不足的問題. Table 5 Effect of Multi-Task Learning表5 引入多任務學習的影響 % 3) 代價敏感學習的有效性 為了緩解困難樣本帶來的預測準確率低的問題,本文引入了基于學生排名差的代價敏感損失函數,即根據成對樣本中2個學生的成績排名差距,自適應地為其生成一個權重,排名越相近的樣本權重越大.表6展示了在使用和沒有使用代價敏感損失的情況下所提出的DEAN方法的結果,即分別通過最小化式(1)和式(11)中的損失函數來訓練模型.可以看到,基于學生排名差的代價敏感損失函數確實對方法性能提升起到了正向作用. Table 6 Effect of Cost-Sensitive Loss表6 使用代價敏感損失的影響 % 4.3.3 不同類型上網行為對成績的影響比較 如2.2節所述,學生不同類型的上網行為與學習成績之間的關聯性是不同的.為了進一步定量地分析這種差異性,我們分別利用單一類型上網行為數據進行成績預測.圖5展示了各方法在利用不同類型上網行為時的預測準確率. Fig. 5 Performance comparison between different methods when using each type of online behavior data圖5 不同方法在利用單一類型上網行為數據時的性能比較 從圖5中可以得到3個結論:1)相比于表3中的結果,當僅利用單一類型上網行為數據時,各方法的性能均出現了顯著下降,這說明有效融合多種類型的上網行為數據對于提升學生成績預測的精度至關重要;2)無論使用何種類型的上網行為數據,DEAN均優于其他對比方法,再次驗證了本文所提方法的有效性;3)基于學生對于教育、IT相關、新聞以及娛樂類型站點的訪問數據可以相對更為準確地預測學生的成績,這與之前我們進行數據分析的結果大致吻合.直觀上理解,頻繁地訪問教育、IT相關或新聞類型網站,可能代表學生在持續地擴充自己的知識面,反映了學生良好的學習態度,因而與學生成績密切相關;相反,長時間瀏覽娛樂類型站點的學生可能無法在學習中投入足夠的精力,導致相對落后的成績,這種負相關關系也可以幫助我們更好地進行學生成績預測. 本文提出以校園上網行為感知為切入點,對學生成績預測問題展開研究,通過分析挖掘學生的上網行為日志,構建有效的學生行為特征,進而預測學生未來的學業表現.本文提出了一種端到端的雙層自注意力網絡,引入級聯式的自注意力機制來分別提取學生每一天的局部上網行為特征和長時間的全局上網行為特征.同時,引入多任務學習策略將面向不同專業的學生成績預測問題進行關聯,并設計了基于學生排名差的代價敏感損失函數進一步提高預測性能.在真實數據集上的實驗結果證明了本文提出的雙層自注意力網絡在學生成績預測問題上的有效性. 我們希望通過本研究,能夠激發人們對校園上網行為與學習成績關聯性的研究興趣.進一步的研究可以通過分析更多類型的上網行為,為教育者開展學生學習管理提供更全面的參考.在未來的研究中,可以參考課程學習的思想,使模型先從容易的樣本開始學習,再逐漸進階到困難的樣本并進一步驗證方法在更大規模數據集上的有效性. 作者貢獻聲明:姚麗為論文所述工作的主要完成人,負責收集數據、實驗設計與實施、文章撰寫;崔超然對論文提出針對性修改意見,負責文章校審;馬樂樂負責處理數據、構建數據集,并完善課題思路和實驗設計;王飛超負責提供數據、收集數據、分析數據;馬玉玲負責論文排版與圖形繪制;陳勐負責對實驗部分提供技術性指導;尹義龍對論文的方法缺陷提出改進意見并完善最終版修訂.3.2 雙層自注意力網絡
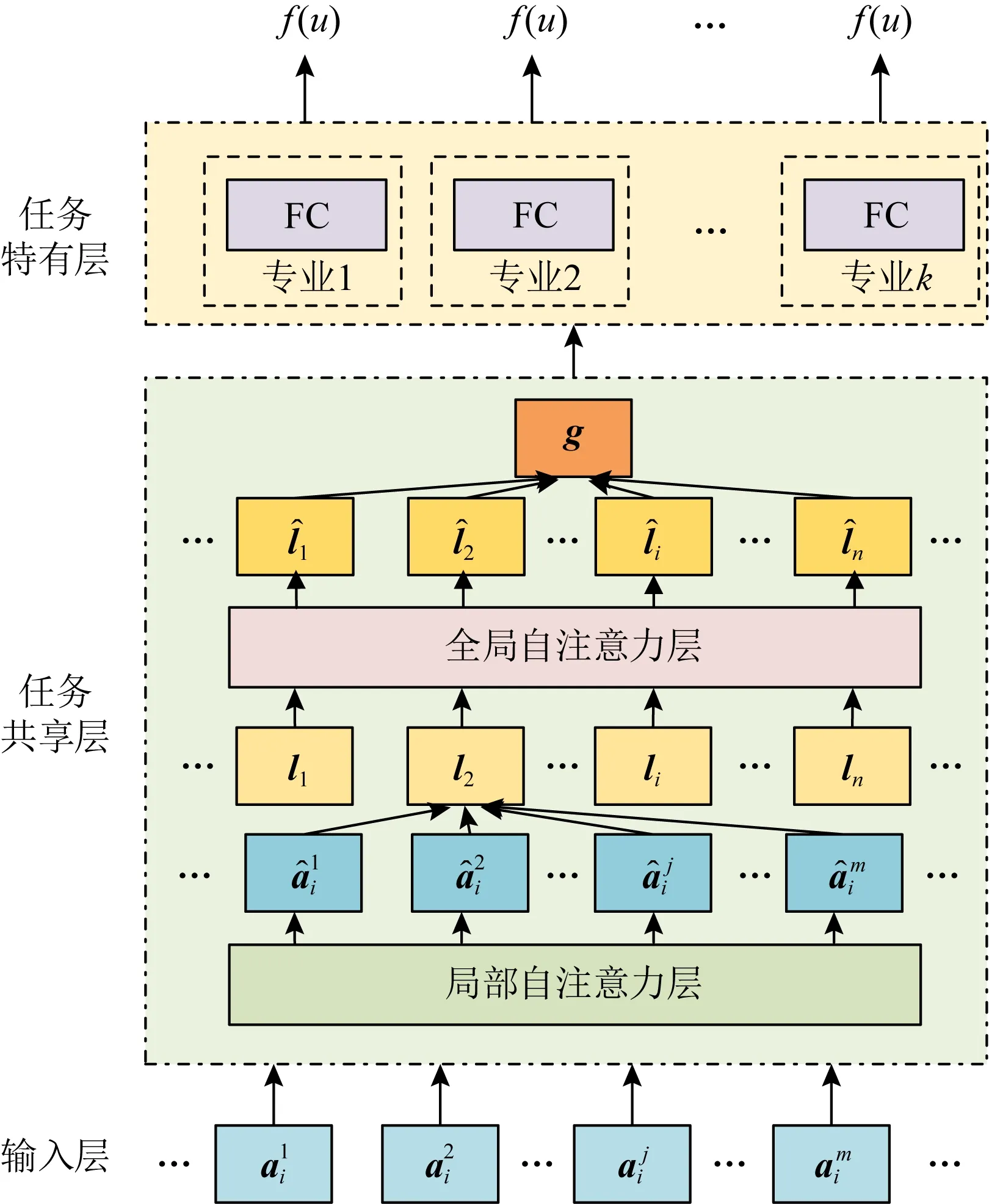
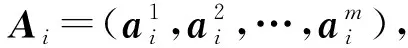
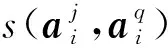
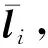
3.3 多任務學習
3.4 代價敏感學習
4 實 驗

4.1 實驗設置
4.2 評價指標
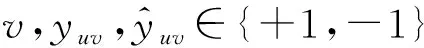
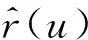
4.3 實驗結果與分析
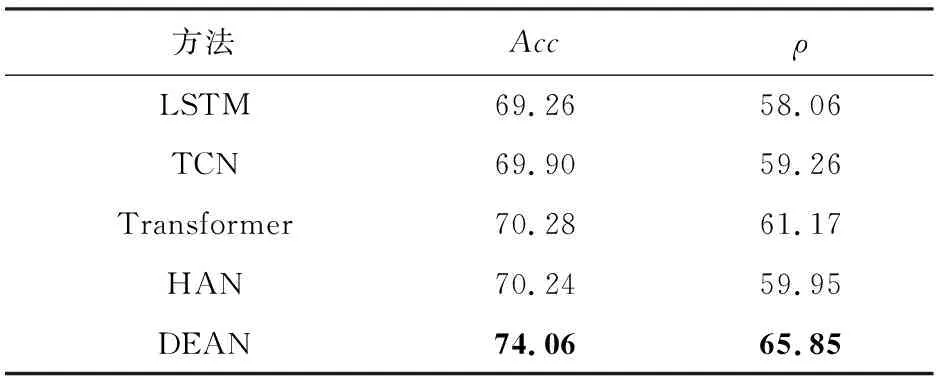
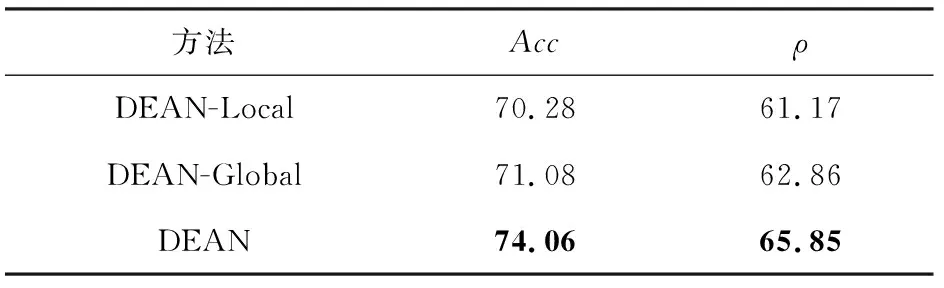
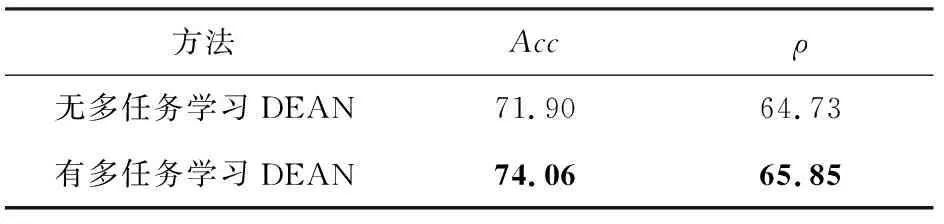
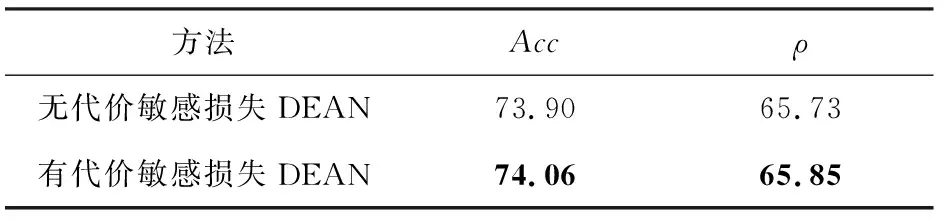
5 總結與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
琴童(2017年3期)2017-04-05 14:49:04
小天使·二年級語數英綜合(2017年3期)2017-04-01 17:17:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
中學生天地(A版)(2015年5期)2015-06-01 02:46:03
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
