基于Grad-CAM的Mask-FGSM對抗樣本攻擊
2022-08-10 08:12:26余莉萍
計算機應用與軟件 2022年7期
余 莉 萍
(復旦大學計算機科學技術學院 上海 201203)
0 引 言
目前,基于深度學習算法的最新進展已經在很多任務上取得突破(例如圖像分類[1]、自然語言處理[2]和語音處理[3]等領域)。但是,目前的方法通常以犧牲可解釋性為代價來提升深度神經網絡(DNN)模型的性能。如何直觀地理解復雜的DNN的推理背后的依據具有挑戰性,決策的可解釋性是關鍵的先決條件,而簡單的黑盒預測是不可信的。DNN的另一個缺點是其固有的易受對抗性,惡意制作的樣本可觸發目標DNN失效[4-6],這將造成不可預測的模型行為并阻礙其在對安全敏感的領域中使用。在諸如自動駕駛、醫療和金融決策等高風險領域,利用深度學習進行重大決策時,往往需要知曉算法所給出結果的依據。因此,透明化深度學習的“黑盒子”,使其具有可解釋性,具有重要意義。
通過提供模型級別[7-9]或實例級別[10-13]的解釋,這些方法的提出推動了DNN可解釋性領域的深入研究。這種可解釋性幫助用戶理解DNN的內部工作原理,啟用包括模型驗證、模型診斷、輔助分析、知識發現等領域的應用。在本文中,引入可解釋性工作Grad-CAM[14],利用Grad-CAM生成熱力圖觀察輸出類別和輸入的內在關系,圖1(a)所示為Grad-CAM的結果,原始輸入分類結果為“68.7% goose”,熱度越高的區域,表明該輸入部分對于類別導向起到越關鍵的作用。本文定義該熱力圖為注意力視圖,通過在注意力更加集中的地方引入噪聲,可以更高效地生成對抗樣本。如圖1(b)所示,第一排為原始FGSM的對抗樣本以及疊加的噪音,對抗并未成功并且需要擾動100%的輸入。第二排為本文方法,僅僅需要擾動1.13%的像素便可達到攻擊目的。實驗驗證了本文方法能夠潛在地挖掘最佳攻擊位置。實驗證明,本文方法平均僅需擾動3.821%的輸入特征就能達到攻擊目的。

(a)
1 相關工作
1.1 可解釋性工作
可解釋性和辨別力是DNN的兩個關鍵方面[15]。近年來,深度學習已經成功運用在計算機視覺、語音和自然語言處理等相關的特定領域。然而,這種“黑盒”模型在“端到端”的模式下,依賴數據驅動的工作機理,缺乏解釋性。研究表明,深度學習的這種模式在數據集存在偏差的情況下依然能對“biased knowledge”進行編碼,從而產生決策失誤[9]。因此,通過可解釋性的工作來可視化隱藏在卷積神經網絡(CNN)內部的知識層具有重要意義。
近年來,出現了多種方法來探索CNN內部隱藏的語義[16-17]。已經提出了許多統計方法[18-20]來分析CNN功能的特征。CNN中濾波器的可視化[15]是探索隱藏在神經單元內部的模式的最直接方法。上卷積網絡[21]將學習到的特征映射轉化為圖像。相比之下,基于梯度的可視化[13,22-23]生成能夠使得給定單元最大化類別置信度的圖像,這更接近于理解DNN的內部機制。Zintgraf等[24]通過可視化對DNN決策貢獻最大的區域從而提供視覺解釋性。CAM(Class Activation Mapping)[25]利用GAP(Global Average Pooling)的作用,保留空間信息的同時并且達到定位的目的,但是也正是由于GAP的限制,導致在一個新網絡的結構上需重新訓練模型,在實際應用中受限。Grad-CAM[14]和CAM的基本思路一致,區別在于獲取每個特征圖的權重時,采用梯度的全局平均來計算權重,該方法可以達到與CAM一樣的可解釋性效果,并且不受限于網絡結構。
1.2 對抗樣本生成
盡管深度學習在許多領域的任務中已經取得重大突破,但由于“黑盒”性質,很難確切知道它背后的決策依據,其在安全敏感任務中實際應用飽受質疑。惡意構造的對抗樣本可以輕易讓DNN決策產生偏差或錯誤[4-6]。攻擊任務一般分為兩類:黑盒攻擊和白盒攻擊。在黑盒攻擊中,攻擊者無法知悉模型的結構信息,只有模型的輸入和輸出信息[26]。Papernot等[27]利用模型蒸餾來擬合受攻擊的黑盒模型的決策結果,從而完成從黑盒模型到代理模型的知識遷移,然后利用以后的攻擊方法生成對抗樣本對黑盒模型進行遷移攻擊。Li等[26]在文本攻擊任務中,通過觀察去掉某個詞前后模型決策結果的變化來定位文本中的重要單詞,進而利用人類無法感知的噪音進行擾動直到達到攻擊目標。白盒攻擊是黑盒攻擊的重要基礎,在此類攻擊中,攻擊者可以知悉受攻擊模型的結構參數等信息。Goodfello等[28]通過計算模型輸入和輸出的敏感性映射(FGSM),并朝著敏感方向添加噪聲來生成對抗樣本。Papernot等[29]基于雅可比圖攻擊(JSMA)選擇最重要的特征進行攻擊。
可解釋性本身和攻擊是一對攻防對象,可解釋性為攻擊者提供了對類別敏感的輸入特征信息,而這一點正為進一步的研究提供攻擊方向的關注焦點。本文提出一種基于Grad-CAM生成類別相關的熱力圖,在FGSM的基礎上僅僅需要少量的噪聲擾動就能達到高效的攻擊。
2 基于Grad-CAM的對抗樣本生成
2.1 Grad-CAM

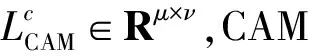
(1)
最后將其歸一化到0-1從而達到可視化的目的。但是為了應用CAM需要將全連接層替換為卷積層,并重新訓練網絡,這是CAM的局限所在。

(2)
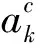
(3)
2.2 基于FGSM(快速梯度下降法)的噪音圖生成
快速梯度下降法。在已知模型結構的情況下,通過求模型對輸入的導數,利用符號函數得到具體的梯度方向,可以得到“擾動”后的輸入從而得到FGSM攻擊下的樣本。設θ為模型參數,x為輸入,y為對應的標簽,訓練損失為J(θ,x,y),那么疊加的噪音為:
(4)

2.3 基于Mask-FGSM的對抗樣本生成
如圖2所示,基于Grad-CAM可以得到對于輸入圖像擾動的方向,越是對于類別重要的特征,受到攻擊越敏感,利用這樣的結果本文算法可以對原圖施以微弱的擾動,便可進行有效攻擊。利用Grad-CAM得到輸出樣本的熱力圖,作為掩碼Mask,與FGSM生成的噪音圖進行疊加,得到最終的對抗樣本:
x′=x+F(SGrad-CAM,Pth)·η
(5)
式中:Pth為施加在掩碼上的閾值。
F(SGrad-CAM,Pth)的計算如式(6)所示。
(6)
式中:SGrad-CAM為利用Grad-CAM得到輸出樣本的熱力圖。

圖2 對抗樣本生成
2.4 評價指標
值得注意的是,控制對抗樣本和原圖的最大的L0距離,理論上給出任意距離下的對抗樣本。
(7)
一般而言,L0距離越小,擾動越小。但是,本文在保證同一個L0距離下,生成更符合人類視覺感知的擾動,探尋潛在高效的攻擊方向。
SSIM(Structural Similarity)結構相似性是一種全參考的圖像質量評價指標,它分別從亮度、對比度和結構三方面度量圖像相似性。SSIM取值范圍為[0,1],值越大,表示圖像失真越小。因此,本文引入圖像的質量評價指標SSIM,計算式為:
(8)
式中:C1、C2是為了避免當分母為0時造成的不穩定問題引入的常數;μX、σX、μX*、σX*和σXX*分別是輸入圖像X的亮度均值、亮度標準差、對抗圖像X*的亮度均值和亮度標準差,以及它們的相關系數。
(9)
原輸入樣本是X,目標網絡輸出是Y,F是網絡在訓練期間學習的函數,η是針對特征所做的擾動,τ是最大擾動L0距離,Pth是過濾掉熱力圖里過小的像素值。利用算法1產生對抗樣本。
算法1對抗樣本生成
輸入:X,Y,F,τ,Pth。
1.X*←X;
3.S=GradCAM(F(X*),X*,Y);
4.η=FGSM(J(X*,Y));
5.S[S 7.δX←X*-X; 8.endwhile 9.returnX* 以Densenet161作為模型結構,ImageNet作為訓練集。實驗采集了來自ILSVRC2014、網絡圖像等數據集一共1萬幅圖片作為測試集,來驗證攻擊效果。 為了驗證本文方法的高效性,即驗證Grad-CAM熱力中心的攻擊效果是否優于非熱力中心。如圖3所示,通過隨機放置噪聲塊的位置,從而探究攻擊位置與熱力中心的關系。 圖3 噪聲塊與熱力中心的相對位置 通過實驗驗證,發現同樣大小的一塊噪聲疊加在原圖的攻擊效果與距離熱力中心的距離呈現圖4所示關系,其中:虛線以上表示攻擊不成功,虛線以下表示攻擊成功。噪聲塊距離熱力中心越近,則攻擊效果越好, 表現為模型對于錯誤預測的類別的置信度的絕對值越高,噪聲塊距離熱力中心越遠,則攻擊效果越差,表現為模型對于正確預測的類別的置信度的絕對值越高。因此,實驗驗證了本文方法的高效性和有效性,該方法能挖掘潛在高效的攻擊方向。 圖4 類別置信度與噪聲塊距離熱力中心距離的關系 本文方法和原始FGSM[29]方法以及DeepFool[6]的生成對抗樣本的實驗對比如圖5所示。從實驗結果可以看出,本文方法僅僅需要擾動極為少量的輸入便可以達到攻擊目的。 圖5 攻擊效果對比(第一列:Grad-CAM結果以及原輸入分類結果;第二列第三列:原始FGSM攻擊結果以及疊加的噪聲擾動;第四列第五列:DeepFool對抗結果以及疊加的噪聲擾動;第六列第七列:本文的方法以及疊加的噪聲擾動) 實驗表明本文方法僅僅需要擾動極為少量的元素便可以達到攻擊目的,表1給出了本文方法與FGSM以及目前典型的對抗樣本攻擊方法比較結果。可以看出,本文方法無論是在L0距離還是SSIM評價指標上均取得最佳效果。 表1 本文方法效果與經典方法對比 本文引入深度學習可解釋性的模型Grad-CAM,針對深度神經網絡(DNN)的結構并基于對DNN輸入和輸出之間映射的關系,結合FGSM方法,平均僅僅需要擾動3.821%的輸入便可達到攻擊目的。通過與目前已有的經典方法進行實驗結果對比,充分驗證了本文方法的高效性。本文結合了可解釋性領域的成果,將其成功應用在對抗樣本領域,實驗結果表明本文方法效果顯著,發掘了潛在的攻擊方向,能夠以更少的擾動成本達到攻擊目的。此外,本文方法具有良好的普適性,可以進一步推廣出更多的攻擊思路,具有良好的應用前景。
3 實驗與結果分析
3.1 實驗設置及數據集
3.2 驗證攻擊方向
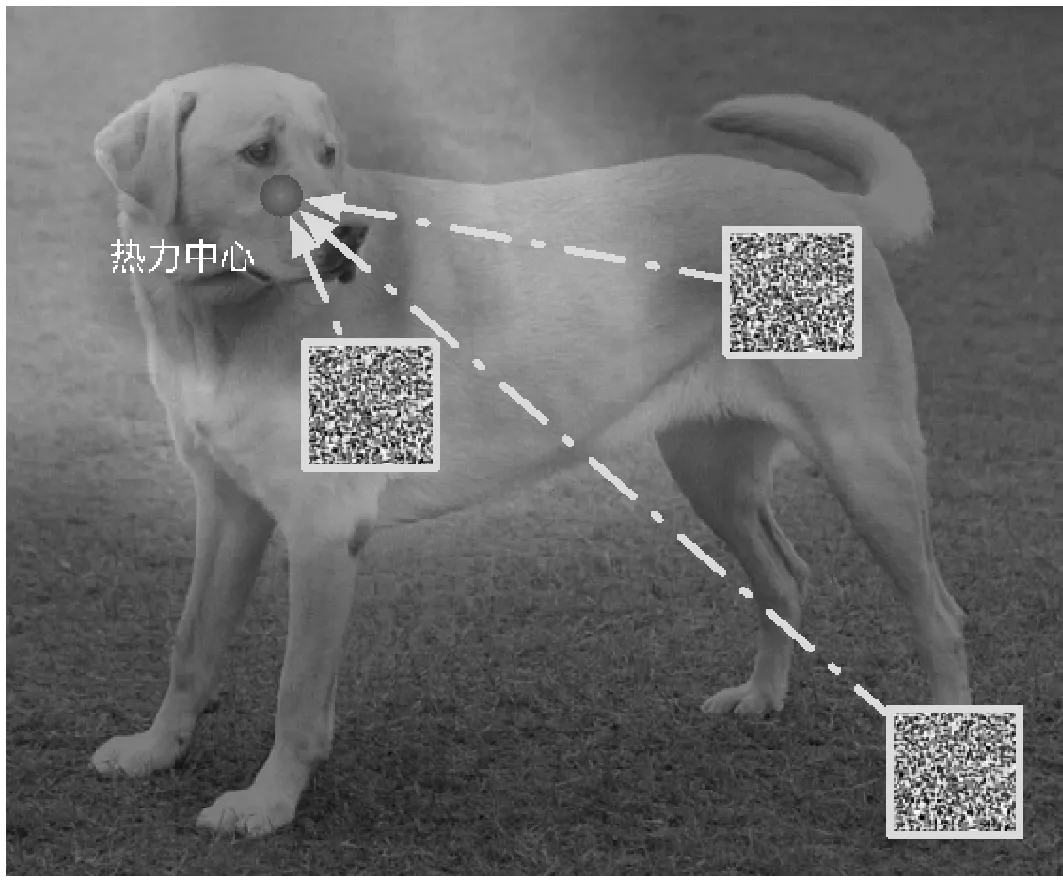

3.3 攻擊效果


4 結 語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
