基于支持向量機模型的機場行李碼放策略
2022-08-10 08:12:00洪振宇
計算機應用與軟件 2022年7期
洪振宇 張 聰
(中國民航大學 天津 300300)
0 引 言
目前全球機場旅客運輸量超過7千萬的機場達到11家,其中,亞特蘭大國際機場和北京首都機場的旅客運輸量已經超過1億,平均每天運送行李超過20萬件,并且從近幾年的變化趨勢來看,旅客運輸量仍在持續(xù)增長,這對機場的高效、安全運營提出了挑戰(zhàn)。旅客行李轉運效率是衡量機場運行保障能力的關鍵指標。機場離港旅客行李轉運過程包括兩個階段,第一階段是在航站樓內從旅客值機到行李分揀口;第二階段是在飛行區(qū)將行李從分揀口運送至預定航班上。目前,行李處理的第一階段由自動化的行李處理系統(tǒng)完成,該系統(tǒng)技術比較成熟,已經實現了危險行李自動識別與分揀。而在行李轉運過程的第二階段,完全依靠人工,這也成為行李轉運效率和安全的瓶頸。采用機械手代替人工搬運行李是提高機場行李轉運效率的有效方法,而機械手的碼放策略又直接影響機場行李的轉運效率,所以對機械手的碼放策略的研究是非常必要的。
機場行李轉運要求機械手在無法提前預知行李尺寸的情況下,較短時間內根據行李車內布局給出行李的碼放位置,并使行李車得到較高的空間利用率。因此機場行李轉運問題不僅是三維裝箱問題,而且還是一個復雜的在線決策問題。三維裝箱問題按照貨物的尺寸不同分為單構型裝箱問題和異構型裝箱問題,按照使用容器的不同分為單箱裝箱和多箱裝箱問題,對于異構型貨物的裝箱問題在數學上屬于NP-hard[1]問題,很難得到精確解,目前對于NP-hard問題大多數學者采用的是啟發(fā)式算法,George等[2]提出采用基于“層”或“墻”的構造性啟發(fā)算法;Bischoff[3]在George的基礎上提出了基于“完全層”的啟發(fā)式算法,將二維裝箱問題應用到三維空間;Fanslau等[4]進一步擴展了“塊”的概念,提出復合塊的思想,設計了一種有效的啟發(fā)式算法;張德富等[5-6]提出一種混合模擬退火算法,隨后又提出了三維裝箱問題的組合啟發(fā)式算法;劉勝等[7]提出求解三維裝箱問題的啟發(fā)式正交二叉樹搜索算法,該算法裝箱效率已有顯著提高,但當箱子種類較少時,效果就會不理想。除此之外其他一些學者也取得了較好的研究成果[8-12]。
雖然啟發(fā)式算法在解決三維裝箱問題取得了顯著成果,卻不能解決碼放過程中的在線決策問題,為了解決這一問題我們引入支持向量機模型(Support Vector Machine,SVM),支持向量機是機器學習[14]重要算法之一,由Cortes等[13]于1995年提出,在解決樣本數量少、非線性及高維度的分類問題[14-15]時表現出許多特有的優(yōu)勢,將稀疏化理論[16]與最小二乘支持向量機模型(Least Squares Support Vector Machine, LSSVM)結合的多層訓練網絡近年來也得到了廣泛應用[17]。
為了同時解決機場行李轉運過程中存在的NP-hard問題和在線碼放問題,本文提出基于空間離散算法的機場行李碼放策略,通過行李車與行李空間離散化,將行李車連續(xù)空間的無數個可碼放位置轉化為空間單元節(jié)點個數種有限個可碼放位置,使系統(tǒng)的運算速度更快、效率更高。同時使用深度稀疏最小二乘支持向量機模型訓練,學習工人的碼放經驗,使算法在最短的時間內計算出行李最佳碼放位置,并且在碼放結束時可以得到接近人工碼放的空間利用率,滿足機場的需求。
1 碼放策略
在機場行李運輸的過程中,行李由分揀系統(tǒng)傳送帶依次有序運送至分揀口,由機械手完成碼放,行李按照先來先放的順序進行碼放,盡可能地實現使用行李車數量最少并且每個行李車的空間利用率達到最高,因此當一個行李進入碼放區(qū)域時需要機械手在較短時間內給出合理的碼放策略,決定行李碼放位置,而且機場行李尺寸大小不一,無法提前獲得,需要一個有效的評價方案用來評價該位置的優(yōu)劣,為了便于對碼放位置的評價,將行李車和行李空間離散化。
1.1 評價方法
公設行李車的長、寬、高分別為L、W、H;行李的長、寬、高分別為lj、wj、hj,(j表示第j種類型的行李),采用笛卡爾坐標系將行李車的左下角設為坐標原點,行李車的長度方向為x軸,寬度方向為y軸,高度方向為z軸,本文提出的空間離散算法的概念,將機場行李車和行李離散為由各單元組成的計算模型,離散后的單元與單元之間采用單元節(jié)點連接如圖1和圖2所示,單元節(jié)點可以記錄空間的狀態(tài)信息。

圖1 行李車三維空間離散示意圖

圖2 行李三維空間離散示意圖
考慮到三維裝箱問題的復雜性,我們將三維裝箱問題轉化為二維平面問題,將行李車和行李的z軸忽略,將其轉化為平面問題,如圖3和圖4所示。

圖3 行李車二維平面離散示意圖
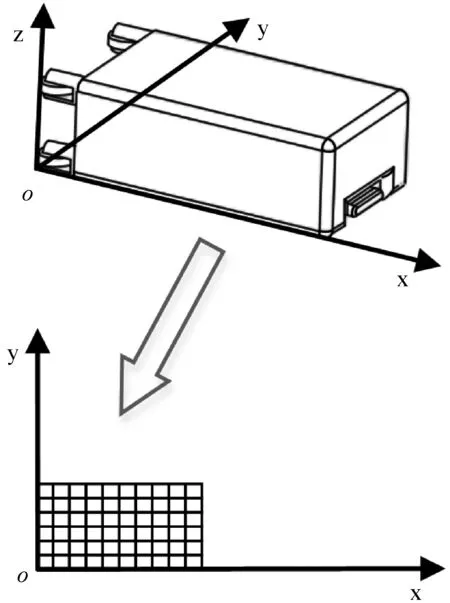
圖4 行李二維平面離散示意圖
在二維平面內,將行李車和行李空間離散化,沿長和寬方向等距劃分為大小相等的單元網格,網格的交點為單元節(jié)點,在行李進行碼放時,行李的單元網格必須與行李車的單元網格重合。行李可放位置由連續(xù)體內的無限種可能轉換為單元節(jié)點個數種可能,降低了問題的復雜程度,使計算過程更加簡單快速。
在行李進行碼放時需要對當前所有可能碼放的位置進行評價,根據評價的結果,選擇最佳位置,評價方案的好壞直接影響碼放結果和工作效率,因此針對行李碼放策略,需要根據實際情況進行分析,確定評價方案。
(1) 當一個行李放入行李車時,該行李在二維平面內與行李車的邊或者與其他行李之間接觸越多,其剩余空間可能被利用的機會就會越大,這樣的碼放是對最終的空間利用率有利的。
(2) 當一個行李擺放后,最終整體的高度會有怎樣的變化,顯然高度越低,最終的效果越好,當有兩個位置可選擇擺放時,應該優(yōu)先放置在比較低的位置上。
(3) 當一個行李擺放后,每一行的空的單元數量越多,對最終的空間利用率越不利。
(4) 行李車上擺放的行李個數越多則空間利用率越大。
以上是對評估局面需要考慮的參數的一般性描述,我們需要將其抽象為五個影響空間利用率結果的屬性:
(1) 底邊距:指行李在放置后,放置點距離行李車x軸垂直距離,用L表示。
(2) 行變換:對于離散后的行李車空間,在x軸方向上,從無行李放置區(qū)域到有行李放置區(qū)域是一種“變換”,從有行李放置區(qū)域到無行李放置區(qū)域也是一種“變換”,這個屬性是各行中“變換”次數之和,用字母R表示。
(3) 列變換:對于離散后的行李車空間,在y軸方向上,從無行李放置區(qū)域到有行李放置區(qū)域是一種“變換”,從有行李放置區(qū)域到無行李放置區(qū)域也是一種“變換”,這個屬性是各列中“變換”次數之和,用字母C表示。
(4) 空格:擺放后的空格數量之和用字母B表示,如圖5所示。

圖5 “空格”與“井”示意圖
(5) 井:在行李擺放后,兩個行李中間,未被行李填充的單元格個數的連加和,用字母W表示。
1.2 決策過程
在行李裝載過程中,需要根據實際情況考慮行李裝載過程中的約束條件,根據機場的實際調研,引入以下五種約束條件:
(1) 行李方向約束:在實際裝載的過程中,行李的方向約束一般分為三種,即任意方向旋轉、水平旋轉、不能旋轉。根據行李的設計特點,行李只能沿水平方向旋轉。
(2) 穩(wěn)定性約束:行李在裝載過程中必須得到行李車底部或者其他行李的完全支撐,不得懸空。
(3) 重心約束:在裝載完畢后,行李車的重心應該在行李車的幾何中心附近,有利于運輸過程的穩(wěn)定性。
(4) 行李最大碼放層數約束:考慮運輸過程中的穩(wěn)定性以及最下端行李的承載能力,要對行李允許的最大碼放層數限制,行李碼放高度不應該超出行李車圍欄的最高高度。
(5) 行李車最大載重、最大容積約束:行李車本身承載重量和最大容積的限制,已裝行李的總重量不得超過行李車的最大載重量,總體積不得超過行李車的容積。
在碼放過程中,在滿足約束條件的情況下,第一個行李的碼放通常按照“貼邊”“占角”的規(guī)則進行碼放,當第n個行李的位置確定后,第n+1個行李的可能碼放位置就會有多種選擇,在多個位置選擇中選擇最佳的一個位置作為行李的放置位置,這樣將碼放位置選擇問題轉換為二分類問題,即最佳碼放位置為一類,其他位置為一類。在機場的實際工作過程中,一個有經驗的裝載工人會根據多年的工作經驗合理選擇下一個行李的碼放位置,并且能得到較高空間利用率,因此在最佳位置選擇時,根據裝載工人的經驗選擇最佳位置,在不同布局的情況下每個可放位置的五個位置評價參數各不相同,而工人在選擇最佳位置后將其單獨作為最佳碼放位置的類別,這樣便將工人的經驗映射到位置評價參數的分類選擇中。例如:在圖6所示情況下,深顏色為已放行李區(qū)域,淺顏色為可放位置,計算所有可放位置的評估參數,并將評估參數記錄,如表1所示。根據裝載工人的經驗,選擇最佳位置H將其標記為1,其他位置標記為-1。將其作為機器學習分類數據集進行訓練,成功地將工人碼放經驗映射到行李參數中。

圖6 第n+1個行李可放位置示意圖
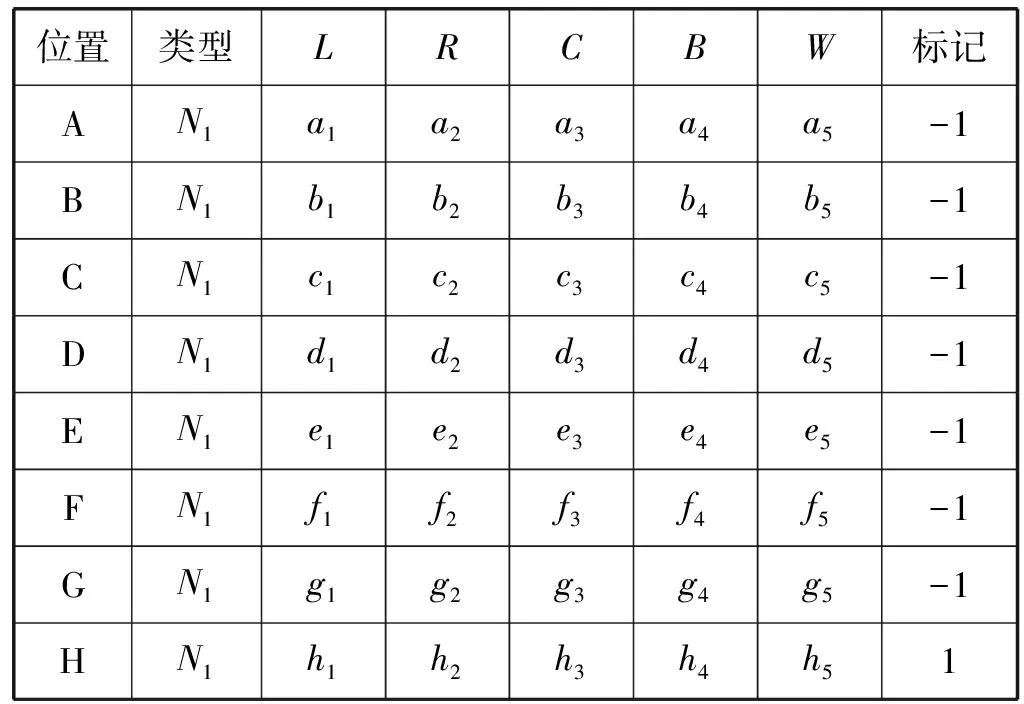
表1 不同碼放位置各參數取值
2 學習算法
在模型訓練過程中,根據裝載工人的經驗,對可放位置進行標記,將可放位置分為兩類,將選擇最佳位置作為機器學習的輸出,這樣行李位置的選擇問題轉化為二分類問題,針對二分類問題,支持向量機模型得到廣泛應用,并且可以得到較高的分類準確率。
2.1 支持向量機模型
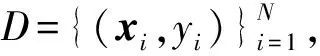
(1)
根據最小優(yōu)化原則可以求得優(yōu)化目標α,所以得到分類函數:
(2)
2.2 深度支持向量機模型
深度支持向量機(Deep Support Vector Machine, DSVM)由輸入層、中間層和輸出層組成,每層都是一個完整的支持向量機,其中間層的數量為l層,結構如圖7所示。訓練樣本通過上一層的訓練得到支持向量,并將每次訓練結果經過處理作為下一層訓練的輸入,從而構建一層新的訓練模型。

圖7 深度支持向量機模型
g(i)=ysviaiκ(xvi,x)+bi=1,2,…,Q
(3)
式中:svi為支持向量;ai為對應的拉格朗日因子;ysvi為支持向量對應的標簽;b為偏置。
在經過降維處理后可以得到的樣本可以表示為:
ysvQaQκ(svQ,xi)+b}
(4)
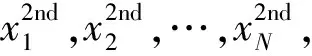
對于測試樣本集,也使用照降維公式逐層對其映射,其分類判別函數為:
(5)

2.3 深度稀疏最小二乘支持向量機
DSVM方法與傳統(tǒng)SVM方法比較,在對碼放行李參數訓練時,雖然能夠得到較高的準確率,但是隨著訓練層數的增加,訓練過程中計算的復雜程度和訓練時間也隨之增加。最小二乘法支持向量機模型可以將不等式約束轉換為等式約束,降低計算的復雜程度,但是在求解的過程中模型會對每個樣本進行訓練,缺少稀疏性,因此,提出深度稀疏最小二乘支持向量機模型來解決此問題。通過求解樣本數據高維特征空間近似最大線性無關向量組的方法對其進行稀疏化處理,在保證分類準確率的同時,增加了訓練樣本的稀疏性,提高了計算效率。
在對最小二乘支持向量機稀疏化的過程中主要包括兩個步驟。
(1) 尋找高維空間的一組近似線性無關向量,構造線性向量組,對位置參數樣本進行稀疏表示。
首先尋找碼放位置參數樣本的特征子集B={(xj,yj)}j∈s?D,m=|S|≤N,使所有的樣本可以表示成該特征子集在特征空間的線性組合:
(6)
所以可得:
(7)
因此,分類判別函數表示為:
(8)
通過選擇參數v來去除特征空間中的近似相關向量,同時也可以控制子集B與樣本的逼近程度,稀疏化的流程如圖8所示。
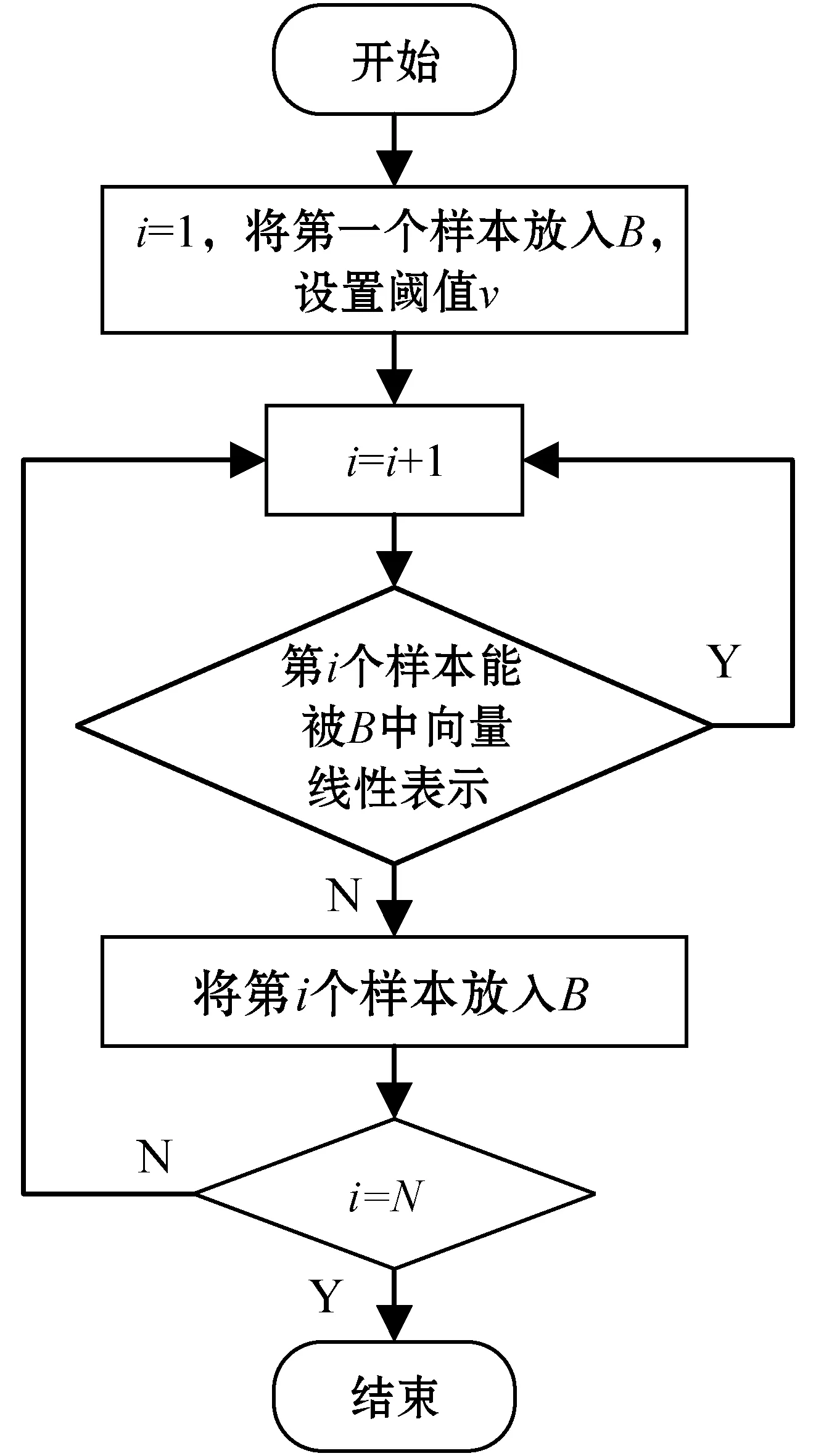
圖8 稀疏化流程
(2) 利用稀疏樣本求解最優(yōu)分類判別函數。將式(7)、式(8)代入最小二乘支持向量優(yōu)化目標函數中,可得:
(9)
式(9)是關于β和b的凸二次規(guī)劃問題,其中:β=[βS1,βS2,…,βSm];ym=[yS1,yS2,…,ySm]∈Rm;D(ym)為以ym元素為對角元素構成的對角矩陣;(Kmm)i,j∈S=κ(xi,xj)=Φ(xi)TΦ(xj);yN=[y1,y2,…,yN]∈RN;D(yN)為以yN為對角元素構成的對角矩陣;KNm=[km(x1),km(x2),…,km(xN)]T;km(xj)=[κ(xi,xS1),κ(xi,xS2),…,κ(xi,xSm)]T;1為元素全為1的單位列向量。最優(yōu)解可以通過以下條件求得:
(10)
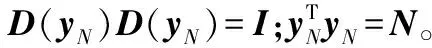
對其求解可得關于β和b的方程組:
(11)

2.4 算法實現
在算法實現過程中,只需將深度支持向量機中的每一層替換為SLSSVM即可,實現多層最小二乘支持向量機的疊加,訓練過程與DSVM相同,首先使用SLSSVM的輸入層對初始樣本進行訓練,然后使用降維公式對輸出層的結果進行處理,并將處理結果作為第二層的輸入進行訓練,而DSLSSVM利用SLSSVM的系數β與向量組B構造降維公式,這里降維公式可以表示為:
g(i)=ysvjβiκ(xj,x)+bj∈S
(12)
隨后逐層訓練,直至輸出結果。通過DSLSSVM深層結構對細膩碼放位置參數進行訓練,對其內在規(guī)律進行學習,既可以得到較高的識別準確率,又可以減少運算時間。
3 仿真實驗
3.1 實驗配置
本實驗使用計算機主要硬件配置如表2所示。

表2 計算機主要硬件配置
仿真實驗使用計算機運行的操作系統(tǒng)為Microsoft Windows 7,本實驗中的算法均使用Python語言進行編寫,在機器學習方面使用scikit-learn模塊來實現,使用pandas和numpy數據庫對數據進行處理。
3.2 訓練數據
根據國際航空運輸協會(International Air Transport Association,IATA)規(guī)定,隨身登機箱尺寸三邊之和不得超過115 cm,托運行李箱尺寸不得超過158 cm,所以20英寸及以下的行李箱可以隨身帶入機艙,28英寸及以下的行李箱可以進行托運,現假設行李的類型為4種,分別為22英寸(60 cm×35 cm×22 cm)、24英寸(65 cm×40 cm×26 cm)、26英寸(70 cm×45 cm×28 cm)和28英寸(75 cm×50 cm×32 cm);根據調研,目前機場采用的行李拖車大多數為三面護欄式行李拖車全車尺寸為300 cm×175 cm×100 cm。
在仿真實驗中,我們將仿真過程分為兩個階段,即訓練階段和工作階段。在訓練階段,數據集由計算機自動生成,首先系統(tǒng)會隨機生成要碼放行李類別,計算機根據當前行李車布局情況,沿x軸方向依次遍歷所有可放位置并計算每個位置評估參數數值,每個位置生成一組數據,有經驗的碼放工人根據多年工作經驗選擇最佳位置進行碼放,計算機將此位置進行標記,完成一個行李的碼放,重復以上過程直至整個行李車被裝滿,生成訓練數據集。
3.3 不同分類模型對比實驗
為了驗證本文使用的DSLSSVM分類模型優(yōu)于其他模型分類準確率,分別使用DSLSSVM、SVM、決策樹分類模型和樸素貝葉斯分類模型進行對比實驗。使用三組不同的行李碼放位置參數作為樣本進行實驗,每組實驗包括5 000組數據,分別使用不同算法進行實驗,實驗結果如表3所示。
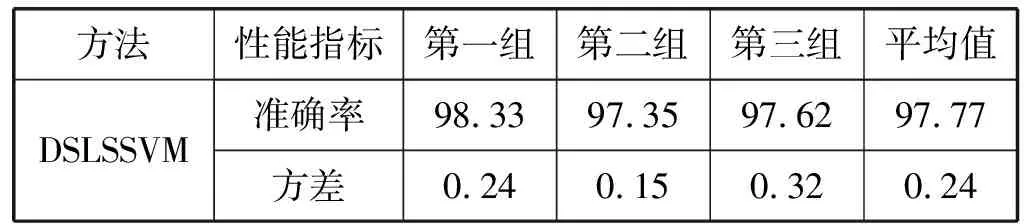
表3 準確率統(tǒng)計表(%)
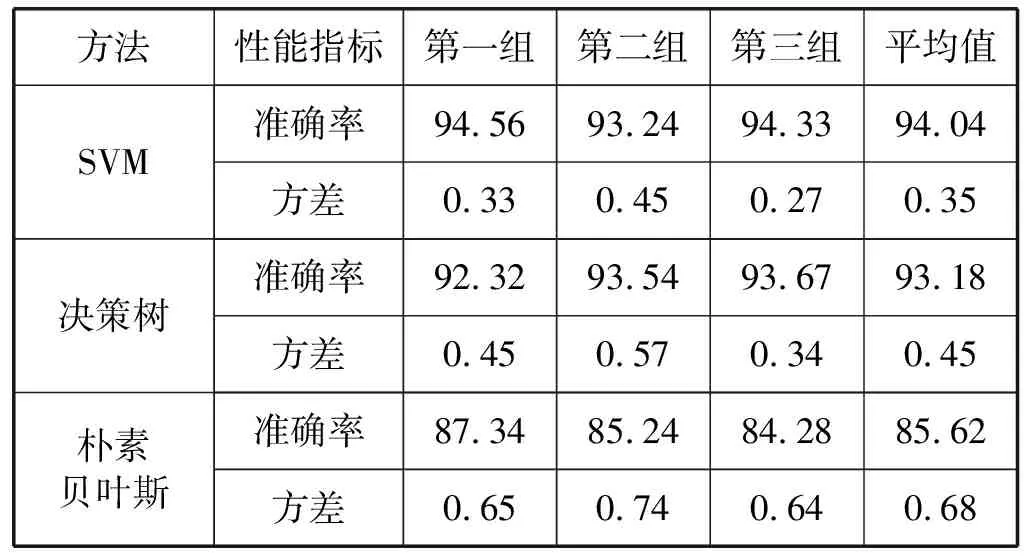
續(xù)表3
可以看出,在本文的分類實驗中, DSLSSVM分類準確率最高,達到97.77%以上,比SVM分類模型的分類精度高3.73百分點,比樸樹貝葉斯分類模型高12.15百分點,所以DSLSSVM分類算法模型適用于本文的空間離散算法,并且可以滿足精度要求。
3.4 利用率對比實驗
在確定了DSLSSVM分類模型的可行性后,將訓練數據集定為8 000組,使用10折交叉驗證法對DSLSSVM分類模型進行訓練,并將訓練好的模型保存。在利用率對比實驗中,使用訓練好的模型進行仿真實驗,圖9分別給出使用人工經驗碼放、基于機器學習的空間離散算法碼放、依次橫放、依次豎放和傳統(tǒng)的啟發(fā)式算法五種不同的碼放方法下得到的二維裝箱效果圖。

(a) 人工經驗碼放仿真圖
使用人工經驗進行碼放仿真時,通過Python語言進行編寫程序,使用計算機輸入設備鍵盤的方向鍵控制行李在行李車網格空間中的位置,模擬工人裝載的過程,通過工人日常積累的經驗根據行李的大小和行李車的布局情況調整行李碼放位置,將行李放在當前布局情況下最佳碼放位置,完成一次碼放。
傳統(tǒng)的啟發(fā)式算法在解決裝箱問題時大多采用“分層”和“分塊”的概念,本文在進行仿真實驗時根據文獻[18]提出的基于“塊”和“空間”的啟發(fā)式算法,對其算法進行復現,作為對照進行仿真實驗。
在實驗過程中,分別使用人工經驗碼放、基于空間離散算法的碼放策略、行李依次橫放、行李依次豎放和傳統(tǒng)啟發(fā)式算法的方式進行碼放實驗,每種碼放方式進行三組實驗,每組實驗各碼放十次,統(tǒng)計其利用率如表4所示。
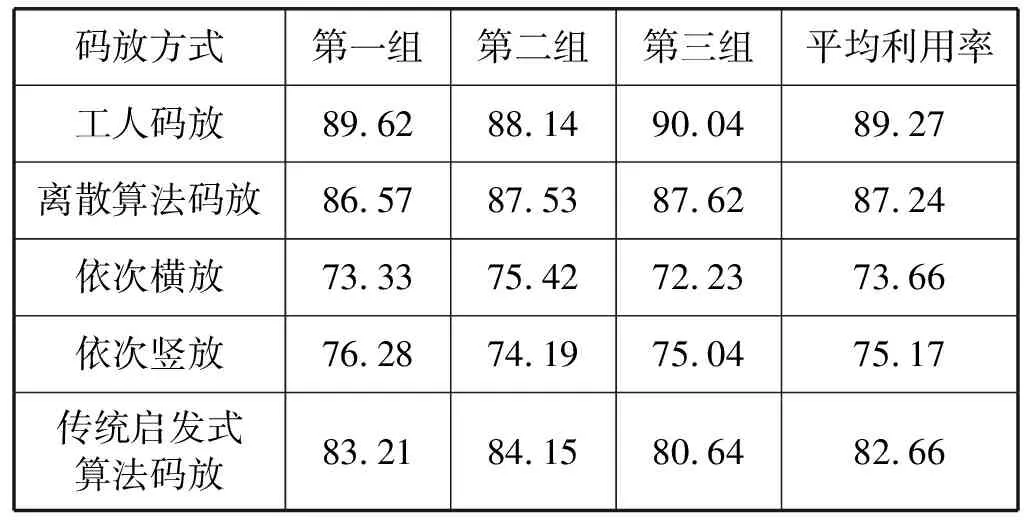
表4 利用率統(tǒng)計表(%)
通過與工人經驗碼放的對比實驗可以看出,本文提出的空間離散的概念可以有效地將工人經驗映射到評價參數中,同時證明了本文提出的基于深度稀疏最小二乘支持向量機分類模型可以實現對行李參數的準確分類,適用于空間離散算法。使用空間離散算法得到的空間利用率達到87.24%,接近有經驗的工人的碼放水平。與其他碼放方式進行對比可以看出,比傳統(tǒng)啟發(fā)式算法得到的仿真結果高4.58百分比,比行李依次豎放利用率提高了12.07百分比,比依次橫放利用率提高了13.58百分比。綜上所述,該算法可以代替機場工人實現行李的自動化裝載,并且可以達到與人工碼放行李較為接近的水平,與其他碼放方式相比可以得到較大的空間利用率,滿足機場高效運輸的基本要求。
3.5 運算時間對比實驗
在機場實際裝載的過程中,除了滿足空間利用率最大原則外還要考慮算法計算速度盡可能快,滿足在線碼放的要求。傳統(tǒng)的基于“塊”和“空間”的啟發(fā)式算法在進行碼放位置的選擇時,采用啟發(fā)式搜索的方法遍歷所有可能碼放的位置,同時還將剩余的空間進行選擇、劃分、合并,更是增加了可放位置的選擇,使得算法計算更加復雜,耗費大量時間。
使用本文提出的基于空間離散的機場行李碼放策略與基于“塊”和“空間”的啟發(fā)式算法的碼放方法在相同的情況下進行行李碼放作業(yè),統(tǒng)計兩種不同算法裝入行李個數如表5所示。
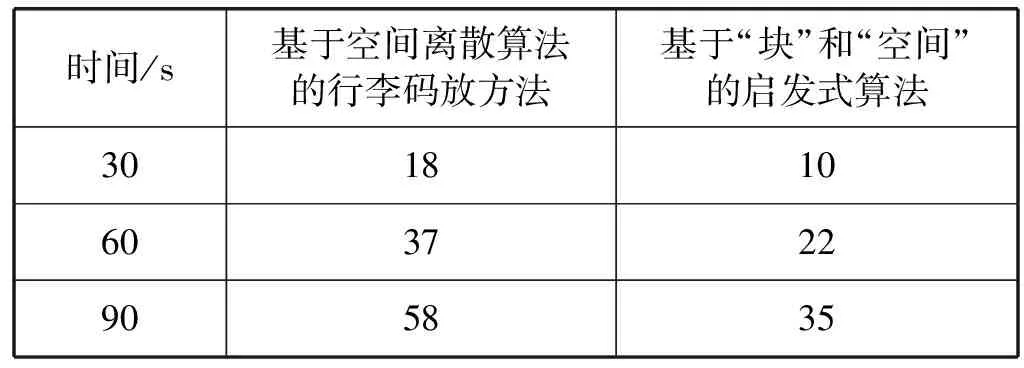
表5 相同時間下裝入行李個數統(tǒng)計表
可以看出,在本文提出的基于空間離散算法的機場行李碼放策略在相同時間碼放行李個數遠大于基于“塊”和“空間”的啟發(fā)式算法碼放的行李個數,并且對行李車的空間利用率較高,所以與傳統(tǒng)基于“塊”和“空間”的啟發(fā)式算法相比,本文算法更適合機場高速、高效率的要求。
4 結 語
為了解決機場行李在轉運過程中存在的裝箱問題,提出一種基于空間離散算法的機場行李碼放方法。通過分析機場行李碼放特點,定義行李碼放位置的評價參數,模擬有經驗工人的碼放過程,構建訓練樣本,使用DSLSSVM模型學習工人經驗,得到訓練模型。在實際工作中,系統(tǒng)根據行里車內不同局面給出不同的碼放方案,完成行李在線實時碼放。
仿真實驗結果表明,通過該方法碼放的行李在空間利用率和效率方面可以達到與人工碼放行李比較接近的水平,可以滿足機場行李運輸的要求。并且相比于基于“塊”和“空間”的傳統(tǒng)啟發(fā)式算法,該方法在實現過程中減少了算法計算時間,提高了機場行李裝載效率,具有較強的實用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
