基于深度學習的天網圖像質量評價研究
2022-08-03 08:59:56農忠海劉向榮
數字通信世界 2022年7期
農忠海,劉向榮
(廣西警察學院,廣西 南寧 530023)
0 引言
近幾年,公安機關開展天網工程建設,全國攝像頭數量已超過2 000萬個[1],視頻監控在公安偵查破案、治安防控、警務指揮、社會管理等公共安全領域發揮了重大作用。天網視頻監控系統對公共安全及時預防、現場處理和現場管控,應對突發事件起到非常重要的作用。
天網是大型社會視頻監控系統,監控點規模龐大、所處環境復雜,在視頻監控圖像的獲取、壓縮、傳輸等過程中難免會存在一些異常干擾因素,這些都會造成圖像質量的下降(降質、失真),從而導致其中包含的信息丟失,視頻監控圖像經常出現抖動、模糊、偏色、畫面凍結、黑屏與播放延時、亮度異常、視頻源丟失等異常現象。
往往因為一些天網攝像頭關鍵點圖像質量不好,直接影響了公共安全相關業務工作。面對海量前端攝像機,如何及時、準確地管理與掌握前端攝像機的視頻圖像質量,保障監控系統良好運行,及時處理故障,提高維護效率,進一步提高圖像聯網監控系統的建設與應用,促進治安防控體系的完善,已成為天網視頻監控系統真正發揮作用急需解決的問題,也是確保系統發揮良好社會效益的重要任務。
對天網視頻圖像質量監測,最初階段是采用人工檢查的主觀評價方法,隨著監控攝像機數量在逐年增加,該方法已經無法完成工作任務。現在普遍采用視頻質量輪巡系統的客觀評價方法,對大規模視頻圖像質量的檢測,在效率上有了很大的提高。視頻質量輪巡系統所采用的核心算法是基于傳統的無參考圖像質量評價方法,主要采用基于人工特征提取的方法,該方法解決了天網視頻圖像質量監測存在誤報率高、漏報率高、準確度不高等問題。本文主要研究應用深度學習算法提高天網視頻監控異常圖像發現的準確性。
1 圖像質量評價方法概述及存在問題
1.1 圖像質量評價方法概述
圖像質量評價有主觀、客觀兩種方法[2]。主觀圖像質量評價方法就是采用人工肉眼觀看的方式,由人對正常圖像和異常圖像進行評價的方法。在圖像數量少的情況下,可以采用主觀圖像質量評價方法,但是像天網這樣具有海量監控圖像的系統,該方法就難以完成任務。客觀圖像質量評價方法就是通過計算機程序根據一定的參數對圖像質量進行判定的方法,而使用全參考圖像進行判定的叫全參考客觀圖像質量評價方法,使用部分參考圖像進行判定的叫半參考客觀圖像質量評價方法,不使用參考圖像進行判定的叫無參考客觀圖像質量評價方法[3]。
全參考圖像質量評價需要將失真前圖像的所有信息和失真圖像進行對比,如均方根誤差(MSE)和峰值信噪比(PSNR)[4]。半參考圖像使用失真前圖像的部分信息作為參考,對失真后圖像質量進行評價。全參考和半參考的圖像質量評價方法多用于圖像傳輸和壓縮。
1.2 存在的問題
在實際應用中,如果要對圖像的清晰度衰減程度進行評價,圖像清晰度的衰減可能來自于傳輸和壓縮,此時可以通過和壓縮傳輸前的圖像進行比對來衡量其衰減程度。但更多的圖像質量問題是來自于聚焦錯誤或其他意外故障,這是我們主要關注的異常情況,此時圖像的來源即攝像機端的圖像已經失真,沒有無失真圖像可參考,所以要用無參考圖像質量評價方法。無參考圖像質量評價是一種無須原始圖像任何信息,直接對目標圖像進行質量評價的方法,是實際應用中最廣泛的評價方法。
目前的天網視頻質量輪巡系統基于傳統的無參考圖像質量評價方法,采用基于人工特征提取的方法,對圖像的模糊、曝光、偏色以及遮擋等指標進行判斷,在對于單一攝像機或者網上公開的圖像質量數據集如LIVE、TID2008/TID2013等進行判斷方面取得了較好的效果,但在實際應用中效果并不理想。基于傳統方法的圖像質量評價方法主要存在模型容量小,無法考慮攝像機的多樣性,以及在實際使用中場景的復雜性,對實際場景泛化能力差等缺點。
1.3 深度學習模型
深度學習是一種模擬人腦神經網絡的一種算法,在很多專門領域應用達到了像人腦一樣學習、歸納的效果,目前在圖像質量評價方面也有一些應用研究。比如,在計算視覺與模式識別領域頂級國際會議CVPR 2014上,Kang等人的論文“Convolutional Neural Networks for No-Reference Image Quality Assessment”[5]設計的卷積神經網絡(CNN),對圖像的一部分和整幅圖像都進行質量評價。
深度學習卷積神經網絡(CNN)的特征提取層參數是通過訓練數據學習得到的,避免了人工特征提取,通過同一特征圖的權值共享,大幅減少了網絡參數,同時也降低了圖像質量評價實現的復雜度。CNN具有良好的容錯能力、并行處理能力和自學習能力,在處理二維圖像問題上具有良好的魯棒性和運算效率。因此,應用深度學習,在天網視頻監控圖像質量評價方面將有比傳統方法更好的效果。
2 基于深度學習的天網圖像質量檢測研究
2.1 總體研究思路
本文研究使用深度學習卷積神經網絡(CNN)模型算法對視頻監控圖像進行質量檢測。首先人工對天網中存在的異常視頻監控圖像進行抓取;然后人工標定異常圖像為清晰、輕微模糊或嚴重模糊,并對應的異常圖像提取歷史記錄的清晰圖片;接著對輸入圖像進行裁剪和縮放預處理,處理后的數據在tensorflow serving進行數據訓練,以獲得有效的圖像質量評價模型。本文的圖像質量評價算法基于優化卷積神經網絡(CNN),進行天網視頻監控圖像質量評價方法有三種,分別是清晰度評價、曝光評價和偏色評價。
陳欣的“基于深度學習的無參考模糊圖像質量評價方法研究”[6],采用傳統CNN方法在圖像上取不同的塊分別計算清晰度值然后求平均,由于圖像空白區域和被虛化的部分都是模糊的,因此會將這兩種圖像評價為偏向模糊,實際上這兩種圖像都是正常的清晰圖像。針對天網視頻監控圖像的特點,本文提出取所有圖像塊的均值作為整張圖的評價值,將整張圖像采樣同時輸入網絡,考慮圖像不同區域清晰度的差異,尤其是對存在大面積空白和背景虛化的圖像。
通過tensorflow serving構建卷積神經網絡,以從監控平臺抓取的圖片作為訓練數據,訓練出可以評價圖像清晰度、曝光和偏色模型并測試效果,采用“理論模型→原型系統→實驗驗證→理論模型”的做法。
2.2 實驗過程
2.2.1 數據獲取
訓練卷積神經網絡所用的數據主要來自天網抓取的圖像數據,包括多種前端設備,從分辨率為1080 p圖像到CIF圖像,工作模式包括可見光和紅外,場景包括室內、室外、交通、卡口等多種場景共32 516張圖像,取出60%作為訓練集,分別取20%作為驗證集和測試集。
2.2.2 數據標定
由于抓取圖像的前端設備的種類非常多,且場景多,不同類型的前端成像效果不同,為了減少人工標定時的復雜度,我們將圖像清晰度分為清晰、輕微模糊、嚴重模糊三個等級。
一級:清晰圖片,指圖像內容邊緣清晰、細節紋理豐富,清晰度無明顯衰減。
二級:輕微模糊,指圖像的內容大致都能看清,邊緣不夠銳利,畫面中的紋理不明顯,清晰度有一定程度的衰減。產生該問題的主要原因是輕微的失焦。
三級:嚴重模糊,指圖像有明顯的模糊,導致部分內容已經無法分辨,紋理和邊緣基完全看不到。產生這種問題的主要原因是嚴重的失焦。
對于不同分辨率的圖像清晰度的比較,我們僅考慮實際分辨率下圖像內容是否清晰,即以達到圖像分辨率極限作為最清晰,所有圖像在標定時以原始分辨率查看。
2.2.3 數據預處理
由于采集的圖像大多是1080 p和720 p的高清圖像,1080 p單幀的輸入節點數為1920×1080×3,如果直接輸入原圖,則需要對整張圖像進行卷積,計算量非常大,會嚴重影響圖像質量評價系統的運行效率,所以要對輸入圖像進行裁剪和縮放。
對于清晰度評價算法則不能對圖像進行縮放,因為縮小圖像會導致圖像的高頻信息丟失,無法分辨圖像的清晰度,所以采用裁剪下的圖像塊作為輸入。在原圖像上等間距裁剪20個1×64的圖像塊,將20個1×64的圖像在垂直方向層疊,生成一個高20寬63的三通道圖像。
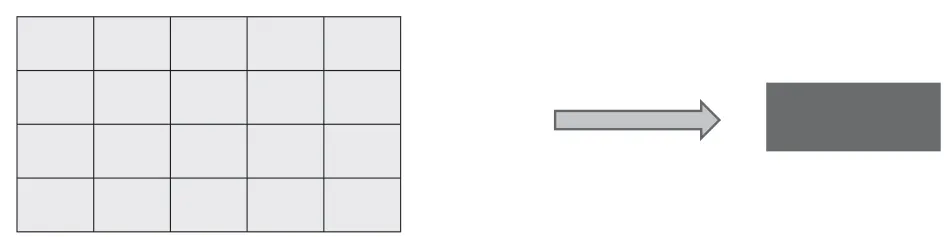
圖1 圖像塊裁取方式
這里假設圖像在垂直方向的分辨率和水平方向分辨率是相同的。在實際應用環境中,由于sensor和鏡頭像差,垂直方向和水平方向的分辨率是不同的,但相對于圖像清晰度出現異常情況和正常情況清晰度的差別,垂直和水平方向分辨率的差異可以忽略,為了減小計算量和內存占用,提高運行速度,從圖像中隨機裁剪1×64的圖像塊作為輸入。
實際圖像各部分的分辨率是不一致的,如果對所有選區的樣本進行標定,則工作量太大,難以實現,所以近似圖像每個部分分辨率一致。由于清晰度值是連續的,采用一個數值來表示每個圖像清晰度,將不同三個清晰度值分別映射到0、0.5和1。
對于曝光和偏色算法,將圖像統一縮放到96×96,然后隨機裁剪出64×64的圖像塊作為輸入,這樣既保留了圖像顏色和亮度信息,又能反映出圖像整體的亮度和顏色分布。分別用偏藍值和偏紅值來表示圖像偏色程度,用一個曝光數值來表示圖像曝光情況。
2.2.4 模型訓練
清晰度評價模型的輸入大小為1×64,基于CNN的分類網絡,將網絡結構在水平方向上做卷積和池化,在20個圖像塊分別經過相同參數的卷積和池化以及一個全連接層后,得到一個大小為[batch_size,20,36]的tensor,batch_size為一個batch的樣本圖像數目,20表示輸入中包含的20個圖像塊樣本,36為每個樣本最后的輸出節點數,最后將20個樣本中每個樣本的36個節點合并成一個720節點的向量,經過一個全連接層,輸出1個清晰度值。取所有圖像塊的均值作為整張圖的評價值,對整張圖像采樣同時輸入網絡考慮了圖像不同區域清晰度的差異,尤其是對存在大面積空白和背景虛化的圖像。傳統CNN方法在圖像上取不同的塊分別計算清晰度值然后求平均,由于圖像空白區域和被虛化的部分都是模糊的,因此會將這兩種圖像評價為偏向模糊,實際上這兩種圖像都是正常的清晰圖像。
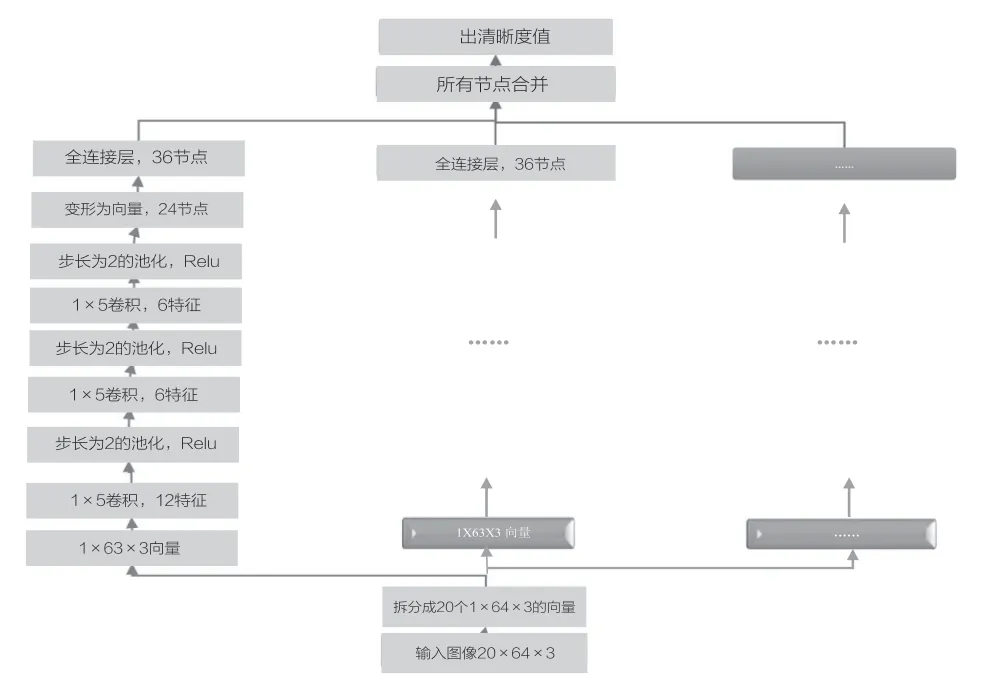
圖2 清晰度評價網絡
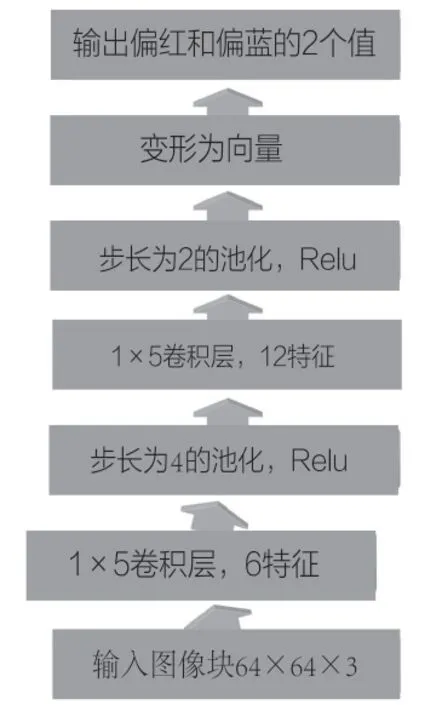
圖3 偏色評價網絡
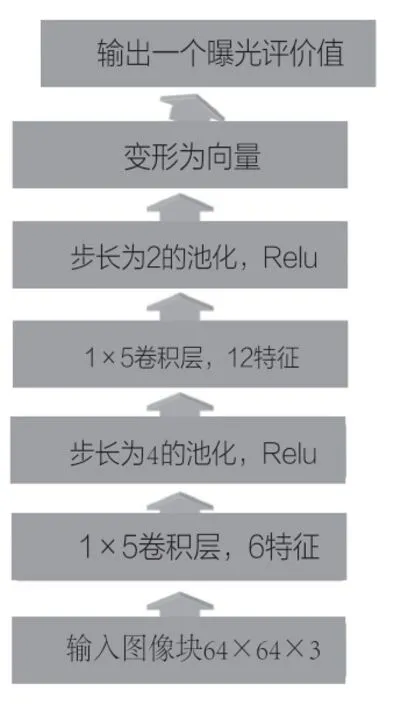
圖4 曝光評價網絡
曝光評價模型輸入為64×64×3,即先將圖像縮放到64×64大小,基于CNN回歸網絡,輸出一個值評價曝光程度。
偏色評價模型輸入為64×64×3,即先將圖像縮放到64×64大小,基于CNN回歸網絡,輸出兩個值評價偏色程度。
經過200個epoch的訓練,清晰度評價模型交叉熵收斂到0.4,曝光和偏色模型分別收斂到0.09和0.11。
2.3 應用效果與模型驗證
部署基于tensorflow serving,分為client端和server端,server端運行在有GPU的服務器上,可以實現同時對多路圖像進行分析。
在推斷時,在輸入圖像上取等間距的20個1×64的圖像塊作為輸入x[20],分別得到20個塊的分類結果y[20],統計y[20]中三個分類的個數,取個數最多的分類作為整張圖片的分類結果。

圖5 清晰圖像與切塊后的輸入

圖6 輕微模糊圖像與切塊后的輸入

圖7 嚴重模糊圖像與切塊后的輸入
采用皮爾遜線性相關系數PLCC(Pearson Linear Correlation Coefficient)對圖像評價方法進行評價,PLCC的數學表達式為
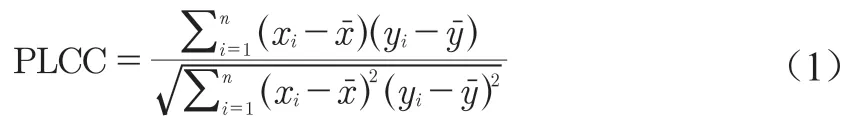
式中,n為圖像數量;為主觀圖像質量評價分值;為客觀圖像質量評價分值;分別表示兩組數據的均值。
應用上述方法在測試集數據上測試了清晰度分辨模型,PLCC達到了0.80。這個結果比已有的研究在LIVE或TID2008等公開數據集上得到的超過0.9的PLCC準確率要低得多。應該是天網實際場景圖像比公開數據集的情況復雜,因此準確率相對較低。
應用本圖像質量評價模型,通過對天網圖像質量輪巡系統上的1000臺設備進行了輪巡,檢測出存在圖像模糊問題的設備26臺,準確率0.81,召回率0.82,存在偏色問題的設備5臺,存在曝光問題的設備8臺。
3 結束語
基于深度學習的天網圖像質量輪巡系統,可以利用大數據的優勢,對實際應用中攝像機種類多且場景復雜的情況有較好的泛化能力,相對于傳統方法更適用于實際應用,提高了發現問題設備的準確率。在應用過程中還可以通過對異常圖像的采集,經過人工標定,加入訓練數據,后續只要更新模型模塊即可不斷提高圖像質量評價的準確率。得益于當前深度學習硬件加速技術的發展,基于深度學習的天網圖像質量輪巡系統可以有很高的運行速度,在短時間內對大量設備進行輪巡,可用于公安部門天網攝像頭輪巡,也可拓展延伸到交通部門、電力行業、大型建筑群、運營商監控等建設有大型視頻監控系統的領域。■
猜你喜歡
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中國生殖健康(2019年2期)2019-08-23 08:12:08
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
