機場不正常事件實體檢測與識別方法研究
2022-08-03 02:42:40侯啟真袁天一王羅平
計算機測量與控制 2022年7期
侯啟真,袁天一,王羅平
(中國民航大學 電子信息與自動化學院,天津 300300)
0 引言
民航安全是民航業長久的主題[1],在美國的航空安全自愿報告系統(ASRS,aviation safety reporting system)獲得成功后,全世界眾多國家紛紛開始建立適合自身實際的航空安全自愿報告系統,我國創建了中國民用航空安全自愿報告系統[2]。該系統所收集的報告中含有報告人所見所聞的民航安全隱患故障,需要總結歸納引發故障的原因和控制故障發生的措施來防止重大事故的發生,從而保障民航系統安全運行。隨著時間積累,報告數量不斷增長,每份報告的非結構文本所含要素信息得不到充分分析,傳統的事件分析方法面對大量的文本很耗費人力也很依賴分析人員的專業能力。
為了充分利用這些事件報告,需要檢測并提取出文本中的事件本質要素,這些要素存在于非結構化的文本中,且這些要素正是影響著民航運行安全的風險要素,主要是人、機、環境的一些狀態信息。而命名實體識別正是能夠做到檢測和識別此類文本要素的關鍵技術,命名實體識別是一項序列標記任務,中文命名實體識別就是將每個文字或符號檢測為其對應的實體類別。隨著深度學習的興起,循環神經網絡(RNN,recurrent neural network)較適用于處理命名實體識別這樣的序列標注任務[3]。但是面對長文本序列,RNN的梯度消失與梯度爆炸的缺陷嚴重影響其序列標注效果。長短時記憶網(LSTM,long short-term memory)是一個特殊的循環神經網絡,網絡利用輸入門、遺忘門和輸出門來管理序列化數據[4-5],在命名實體識別任務上取得了較為優異的效果。在此基礎上有人提出雙向長短時記憶網絡(BiLSTM,Bi-directional long short-term memory)來提高模型效果,同時結合在命名實體識別任務上表現較好的機器學習模型——條件隨機場(CRF,condition random fields),可以使得該任務在通用領域數據集上達到更好的識別效果。近幾年也有人在此模型的基礎上引入自注意力機制,在一定程度上提升了模型識別能力。
機場不正常事件是航空安全自愿報告中描述事件與機場相關的文本報告,經過人工篩選,并進行預處理得到命名實體識別模型需求的非結構化文本形式。機場不正常事件命名實體識別技術的任務是從非結構化的機場不正常事件文本中將該領域文本特定的不同類別實體檢測識別出來,以達到對機場不正常事件關鍵要素提取和分類的目的,得到結構化文本作為開展機場不正常事件分析總結控制措施的基礎工作。然而由于機場不正常事件文本在表述方式、事件狀況、專業用語等文本特點上與通用領域不同,且通用領域主要以人名、地名、機構名等簡單實體為命名實體識別目標,所以通用領域常用的命名實體識別模型在本領域很難達到較好效果。
因此,針對以上問題,提出了更適合于機場不正常事件文本數據的命名實體識別模型BiLSTM_MSA_CRF(Bi-directional Long Short-Term Memory_Multi-Scale Self-Attention_ Condition Random Fields)模型。此外,為降低人工標注成本,根據模型自身特點,設計了樣本選擇策略,在降低人工標注數據量的同時更高效地提高了模型泛化能力。
1 機場不正常事件報告的構造特征
機場不正常事件報告文本從整個文本角度,文本長度偏長,每份報告300~700字。上下文具有很強的相關性,長距離相關性將影響著命名實體識別效果。由于上下文的相關性也幫助豐富文本中關鍵要素的語義信息,使其明顯區別于通用領域文本的結構,如“…27號跑道發生跑道入侵事件,并未造成…”中“入侵”與“跑道”共同組合成一個詞語“跑道入侵”有別于通用領域的常規用法,結合前文“27號跑道”這一地點詞可以確定此處詞語語義。
從單個實體角度,文中含有一定量的專業性用語,中英文縮寫及其中英文全稱,以及中文、字母、數字多種字符串組合在文本中交替出現,這些字符串可能表達航路、航班、扇區等信息(例如A326、SCS8997、ZSSSAR11),實體長度不等,實體間相互影響密切且交錯。所需檢測的實體種類也較多,多個實體種類之間比較相似,比如人的行為狀態和其他生物的行為狀態會有類似,需要結合語境進行區分。
2 數據標注規則
根據國際民航組織(ICAO)9859號文件[6],并結合機場不正常事件文本內容特點,充分考慮我國民航安全報告系統對故障防控的需求,設立了14個命名實體類別:時間、地點、方位、天氣元素/能見度、航空器、航空器狀態、航空器部件、航空器部件狀態、設施、設施狀態、人物類別、人類行為/狀態、其他生物(不包括人類)、其他生物的狀態。每個實體對應特定的編號,編號表如表1所示。

表1 命名實體類別編號
本文采用命名實體識別常用的BIO標注原則[7-8]對文本數據進行序列標注,即實體的開始標為B,實體的非開頭部分標為I,非實體標為O。由于每段文本較長,為方便人工標注,采用{"text":"S","label":{e1:[Ne1],…,ek:[Nek],…,e|E|:[Ne|E|]}}標注方式,這種標注方式相對傳統的BIO人工標注更簡單便捷。其中,S代表文本序列,ek∈E是命名實體類別,Nek代表在S這一文本序列中屬于ek這一實體類別的實體集合,人工標注完成的樣本如圖1所示。

圖1 人工標注樣本示例
數據處理程序中,將進行相應轉換處理,程序經過如圖2所示對人工標注數據進行相應處理,從而得到對應的BIO標注形式。

圖2 BIO標注處理程序
3 命名實體識別方法和過程
依據各個領域現有命名實體識別模型[9-10],并分析機場不正常事件報告的構造特征,提出的適用于檢測機場不正常事件要素信息的命名實體識別任務,主要分為4個部分:文本向量化,雙向長短時記憶網絡和多尺度注意力機制(MSA,multi-scale self-attention)提取上下文特征信息以獲取文本中每個字的實體類別預測分數,條件隨機場將獲取的最優預測序列解碼輸出最終識別結果,總體模型框架如圖3所示。
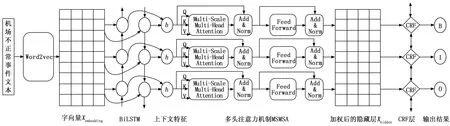
圖3 機場不正常事件命名實體識別的BiLSTM-MSA-CRF模型構架
3.1 字向量化
需要將輸入的句子中每個字表示成字向量,字向量的表示方式主要分為兩種:獨熱表示和稠密表示。由于獨熱表示無法表示字與字之間的相關關系,逐漸被新生的稠密表示方式取代,Word2vec[11]正是目前較經典的字向量稠密表示方法。Word2vec可以表示字與字之間的相關關系,從而含有一定的語法和語義特征表示 ,進而從輸入端提升命名實體識別模型的泛化能力。已知文本序列S={s1,s2,…,sm}有m個字,經過Word2vec處理后得到每個字si相對應的字向量表示形式xi,如式(1)所示:
xi=Ww2vvi
(1)
其中:Ww2v∈Rdx×|V|是由Word2vec訓練得到的向量矩陣,dx是字向量的維度,|V|是輸入字表的大小,vi是輸入字si的詞袋表示(獨熱形式)。由此得到一個向量序列x={x1,x2,…,xm},作為命名實體識別網絡的字向量輸入。
3.2 提取上下文信息
單向LSTM可隨著序列信息的提取保留前文“值得記憶”的特征信息,而模型最后檢測出的序列標簽是結合前文的信息預測得出的,也就做到了結合上文的語境信息來做命名實體識別任務。為解決RNN在長文本序列標注任務上的缺陷,每個LSTM均包含著輸入門、遺忘門和輸出門這3個“門”單元結構,以降低梯度消失等問題的出現率。LSTM單元結構如圖4所示。
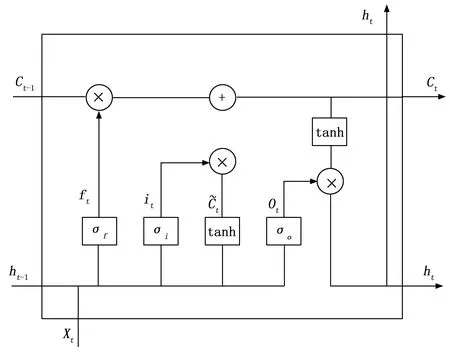
圖4 LSTM單元結構
式(2)描述了LSTM具體計算過程。
it=σ[Wi·(ht-1,xt)+bi]
ft=σ[Wf·(ht-1,xt)+bf]
ot=σ[Wo·(ht-1,xt)+bo]
ht=ot⊙tanh[ct]
(2)
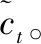
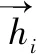
(3)
字向量經過BiLSTM提取一定的上下文特征,但并不足以準確檢測每個字的對應標簽。
3.3 結合層次結構的自注意力機制
盡管雙向長短時記憶網絡在一定程度上已經保留了上下文“重要”信息,已經可以做到較全面的處理,但是其依然沒有對這些“重要”信息分清主次,即從BiLSTM中得到每個字向量對應的上下文特征向量,但并沒有考慮到不同詞語間的不同程度關系,也沒有充分考慮到不同的詞語對模型識別結果會產生不同程度的影響,所以識別效果更待提升,需要使用自注意力機制來幫助分配權重以解決此問題。所以結合了自注意力機制的命名實體識別模型更能夠提取更加主要且與現有輸出關聯度更高的特征信息,避免過多提取次要關聯信息而造成語義偏差,在對輸入向量施加合適的權重系數后,模型識別結果會得到有效提升。
近年來,諸多領域為解決命名實體識別的這一問題引入了自注意力機制[14-16],盡管自注意力可以建模非常長的依賴關系,但深層的注意力往往過度集中在單個字上,且權重過于分散,并不能構成詞語間的依賴關系,導致對局部信息的使用不足,對短序列自注意力相對有效,但其難以表示長序列,隨著句子的長度增加自注意力的性能逐漸下降,從而導致信息表達不足,給模型完整地理解數據信息帶來困難,在語境中應更主要以詞與詞之間的影響來作為特征,這樣才更能提高模型識別效率。且基于自注意力機制的方法缺乏先驗假設,需要很大的樣本數據集才能訓練出一個泛化能力較好的模型。本研究數據量有限,無法滿足大樣本數據集的要求。多尺度結構可以幫助模型捕捉不同尺度的特征,實現多尺度的常用方法是采用層次結構,通過層次結構,模型可以捕獲較低層次的局部特征和較高層次的全局特征。多尺度多頭注意力[17]的各個頭具有可變尺度,頭部的大小限制了自注意力的工作范圍:大尺度包含更多上下文信息,小尺度更關注局部信息。
BiLSTM輸出向量為hi,對應的序列矩陣為H={h1,h2,…,hn},其中H∈Rn×D,n為句子長度,D是hi的向量維度,式(4)描述了多尺度注意力的計算過程。
Cij(A,ωj)={Ai-ωj-1/2,j,…,Ai+ωj-1/2,j}
Q=H·WQ,K=H·WK,V=H·WV
headj(H,ωj)=Concat[headj(H,ωj)1,…,headj(H,ωj)n]
MSMSA(H,Ω)=Concat[head1(H,ω1),…,
headj(H,ωj),…,headN′(H,ωN′)]WO
(4)
其中:WQ,WK,WV,WO是可學習的參數矩陣,ω是每個頭的尺度大小,ωj即為第j個頭的尺度,共有N’個頭,多尺度多頭自注意力的所有頭的尺度集合為Ω=[ω1,…,ωj,…,ωN′],C為給定位置提取上下文特征的函數。
多頭多尺度注意力機制,在不同層分配了不同尺度的“頭”,不同層中對應的尺度分配遵循式(5):
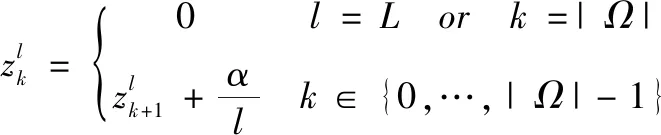
(5)
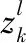
以上公式計算過程對于單個向量hi可以歸結為式(6):
(6)
對應注意力計算結構圖如圖5所示。
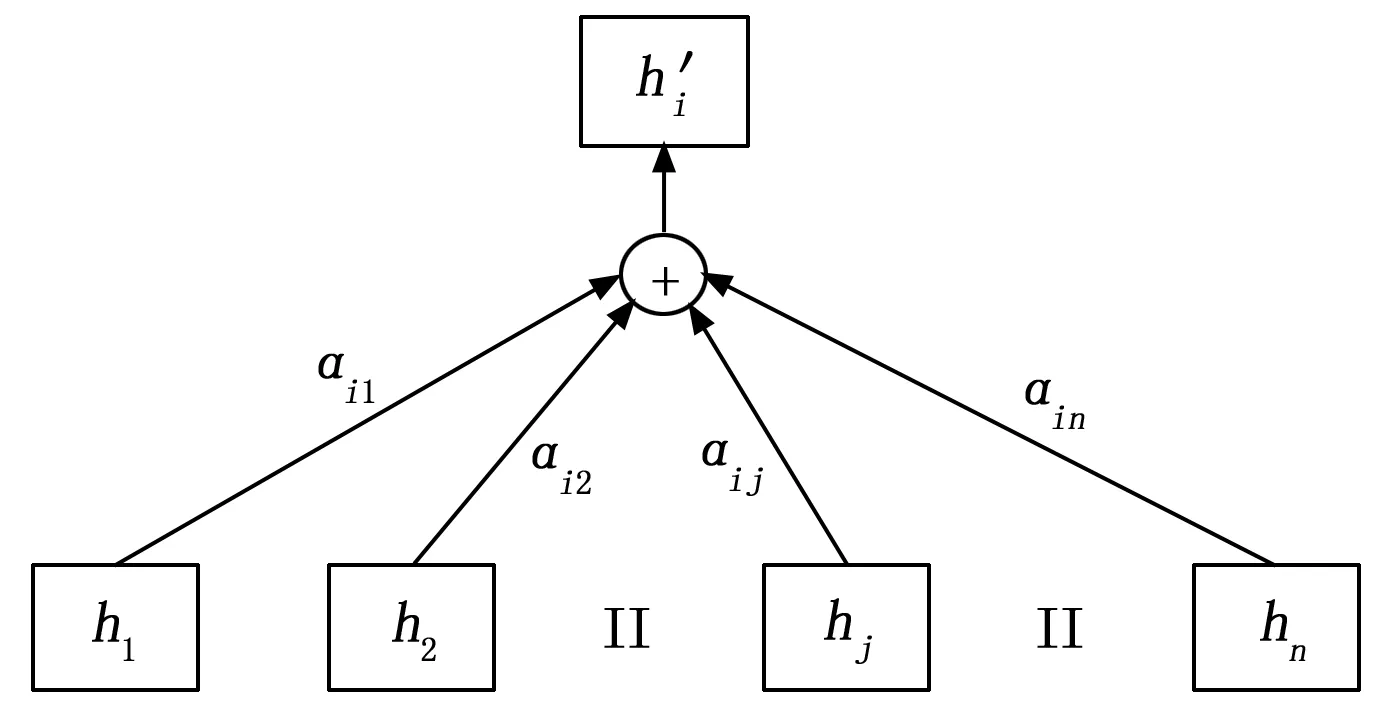
圖5 注意力加權計算過程
3.4 解碼輸出檢測結果
CRF[18]解碼過程中,將重新分配權重后的雙向LSTM概率矩陣輸出結果作為輸入,獲得預測序列標簽。CRF模型關注輸入序列各個相鄰字的前后依賴關系,進而計算最優預測標簽序列。借鑒王棟[19]等人使用CRF模型的思路,相關公式計算過程如下:
記句子序列為S={s1,s2,…,sm},其預測的標簽序列為Y={y1,y2,…,ym},則序列預測得分矩陣計算如式(7):
(7)
其中:T代表狀態轉移矩陣,Tyi-1,yi為yi-1標簽轉移到yi標簽的概率得分,Pi,yi是第i個字符被標記為標簽yi的概率得分。文本序列S計算產生標記序列Y的概率如式(8)所示:
(8)
在訓練過程的標記序列的似然函數如式(9)所示,通過極大似然估計的方法估計條件隨機場的模型參數。
(9)
使用CRF對序列進行預測時利用維特比(Viterbi)算法求解最可能的序列標簽,最終輸出如式(10)所示的最優序列Y*。
(10)
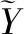
3.5 樣本選擇策略
由于模型所需標注訓練樣本數量較大,人工標注成本較高,且已有訓練數據中各個類別的實體數量不均衡,以至出現比較稀疏的實體類別,從而導致模型對這些稀疏實體識別不準確,為檢測出含有此類實體的高質量訓練樣本和提高人工標注效率,本文根據數據和模型本身特點,設計了基于不確定性的樣本選擇策略。該方法既能減低人工標注成本又能更高效地提高模型的泛化能力,基于不確定性的樣本選擇策略的核心思想是模型無法進行有效判斷的樣本[20-22]。結合現有命名實體識別模型,本文使用最優預測序列概率p(Y*|S)作為模型對未標注樣本的不確定性評判依據,最優預測序列概率p(Y*|S)越低,模型對樣本序列的標注越不確定,這類樣本與已有訓練數據相比含有稀疏實體較多,這類樣本越值得加入訓練集。基于不確定性的樣本選擇策略如式(11)。
D(Y*)={Y*|p(Y*|S)≤PD}
(11)
其中:D(Y*)是通過選擇后得到的需人工標注的樣本集,PD為模型最優預測序列概率閾值,當樣本S對應的最優預測序列Y*的概率未達到閾值時,則將該樣本加入需人工標注樣本集,等待人工進行標注。使用該樣本選擇策略后,構成了與模型訓練模塊構成了閉環主動學習框架,如圖6所示。
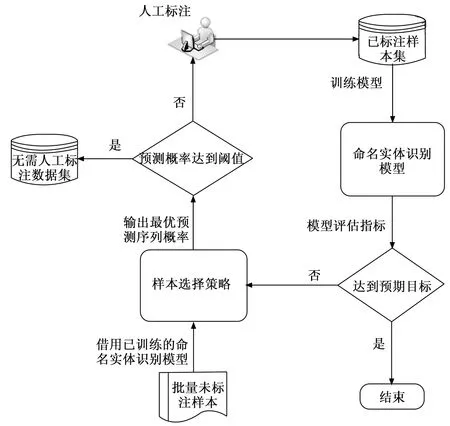
圖6 融合樣本選擇策略的命名實體識別框架
4 實驗結果與分析
4.1 實驗數據準備
使用的數據來自于ASRS和中國民用航空安全自愿報告系統中與機場相關的航空安全自愿報告,選取的報告包含了2010~2021年間機場航空安全自愿報告10 536條,所有文本去除無效字符并整理格式后組成本實驗機場不正常事件樣本數據,數據以中文形式呈現,每篇報告500字左右。隨機選取了7 000條樣本進行人工標注,標注形式如圖1所示,并隨機將其分為5 000條文本的訓練集和2 000條文本的測試集。剩余的未標注樣本作為樣本選擇策略的實驗數據。
4.2 實驗環境、參數設置和評價指標
實驗在Windows10(64位)系統中使用Python3.6作為編程語言,基于Pytorch框架對本文方法和對比實驗方法進行程序實現。所有實驗是在Intel Core i7-8700處理器、16 G內存、NVIDIA Quadro P2000 GPU硬件設備條件下進行的。表2是實驗中模型參數設置情況。
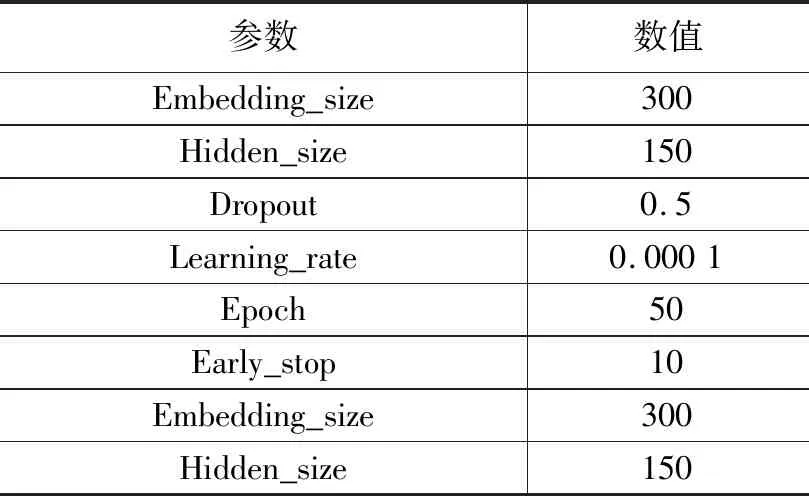
表2 模型參數設置
實驗采用精確率P、召回率R和F1值對命名實體識別結果進行評價。3個評價指標的計算如下:
(12)
以下實驗均通過計算不同模型在相同數據上的精確率P、召回率R和F1值進行對比。
4.3 實驗結果對比與分析
實驗一:加入多尺度注意力機制的命名實體識別模型在機場不正常事件文本數據上的識別效果需要對比通用領域的常用方法來驗證,以證明多尺度注意力機制能夠改善機場不正常事件文本命名實體識別效果。實驗使用3.1節所提及的訓練集和樣本集分別訓練BiLSTM_CRF模型、BiLSTM_self-attention_CRF模型以及本文提出的BiLSTM_MSA_CRF模型,為降低選取數據的偶然性,經過5次隨機分配得到的訓練數據和測試數據來分別訓練3個模型,最終將模型得出的評價指標取平均值,并填寫入表3中。
從表3可以看出,加入自注意力機制后,模型識別能力確有提升,但并不明顯,這正是因為自注意力機制對于文段較長且識別結果很依賴上下文語境的文本并沒有很好地發揮其捕捉上下文重要信息的作用,注意力過于分散在單個字上,沒有充分利用詞語級別的局部信息。而加入多尺度注意力機制后,識別效果有了明顯提升,說明多尺度注意力能夠改善自注意力的缺點,更適合機場不正常事件這種長文段的命名實體識別。
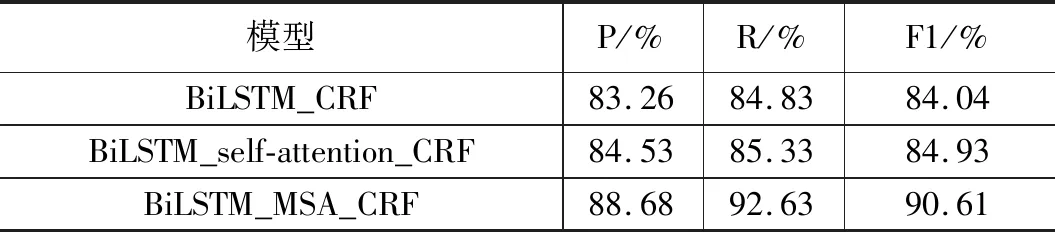
表3 固定樣本集條件下不同模型的對比實驗結果
為了降低人工標注成本且更高效地提升模型泛化能力,使用2.6節提出的樣本選擇策略進行對比實驗。如圖7所示,是閾值設為0.9時,提示需要標注的樣本示例。

圖7 樣本選擇策略下程序提示需要標注的樣本示例
實驗二:分別對比不同概率閾值PD對3種命名實體識別模型的影響,以尋找一個更合適的閾值。
實驗步驟為:將前一次實驗訓練后的3種模型保存分別命名為BiLSTM_CRF、BiLSTM_self-attention_CRF和BiLSTM_MSA_CRF,選取4種不同最優預測序列概率閾值PD(分別為0.8、0.85、0.9、0.95),并分為4個批次逐漸增加選取樣本,每個批次隨機選取500條未標注樣本,3種模型經樣本選擇策略后,挑選未達閾值的樣本進行人工標注,加入訓練集進行模型再訓練,將不同閾值各個批次訓練完成的模型區分開命名BiLSTM_CRFm(n),其中m=[0.8,0.85,0.9,0.95]為閾值,n=[1,2,3,4]為挑選樣本批次,如BiLSTM_CRF0.8(1)代表設定閾值為0.8隨機選取500條未標注樣本,篩選出需要人工標注的樣本加入訓練集中對BiLSTM_CRF再訓練而得到的模型;BiLSTM_MSA_CRF0.9(3)代表設定閾值為0.9在未標注樣本集里隨機選取500條未標注樣本篩選出需要人工標注的樣本累加到訓練集中對BiLSTM_MSA_CRF再訓練而得到的模型。對不同的樣本需要標注的內容有一定的差異性,為防止因這種“參差不齊”的現象而引起的偏差,在所有未標注樣本中隨機進行5次抽選2 000條文本,各進行5次實驗取平均值作為最終實驗結果。實驗結果如圖8~13所示,每組的橫坐標為使用樣本選擇策略選取備選樣本的批次,即500(2)意為第二批次隨機拿出500條未標注樣本進行樣本選擇,圖8,10,12縱坐標為每個批次篩選出需要人工標注的樣本數量,圖9,11,13縱坐標為對應批次訓練后模型的F1值。
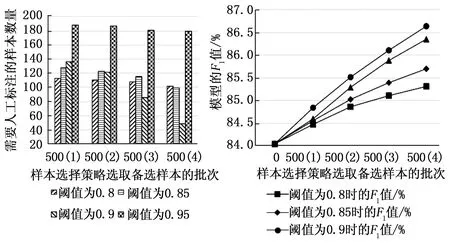
圖8 不同閾值條件下BiLSTM_CRF模型需人工標注樣本量對比 圖9 不同閾值條件下BiLSTM_CRF模型隨人工標記輪次F1值變化情況
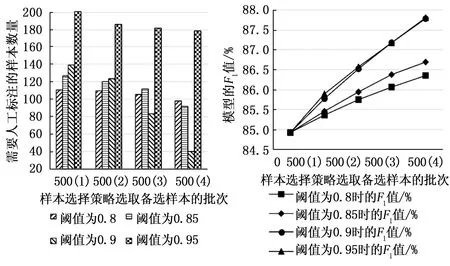
圖10 不同閾值條件下BiLSTM_self-attention_CRF模型需人工標注樣本量對比 圖11 不同閾值條件下BiLSTM_self-attention_CRF模型隨人工標記輪次F1值變化情況
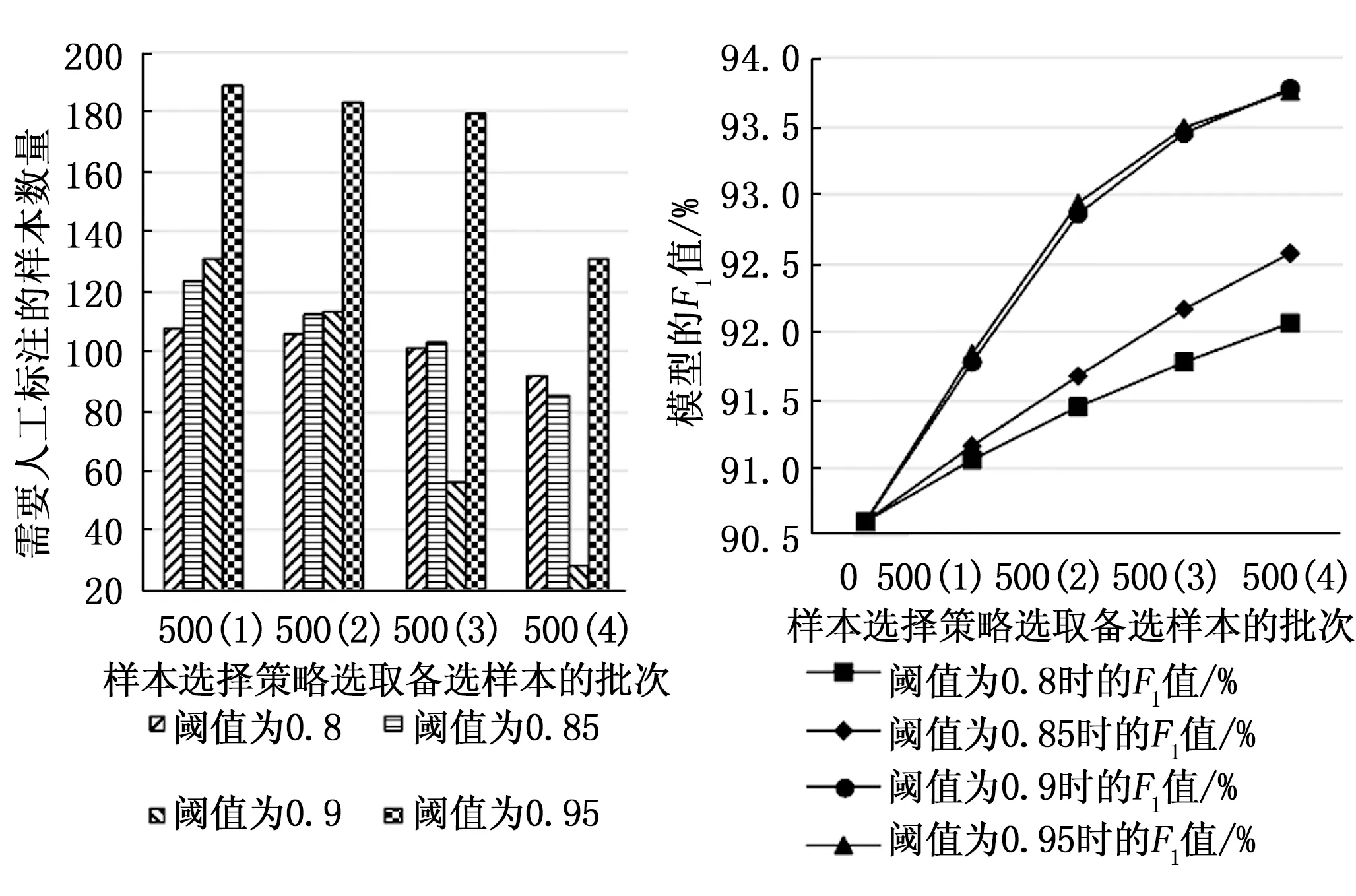
圖12 不同閾值條件下BiLSTM_MSA_CRF模型需人工標注樣本量對比 圖13 不同閾值條件下BiLSTM_MSA_CRF模型隨人工標記輪次F1值變化情況
由圖8~13以及表4可以看出,隨著樣本選擇策略的使用,3個模型的精確率P、召回率R和F1值均有提升,并且隨著閾值的提升(由0.8到0.85再到0.9)模型的精確率P、召回率R和F1值在以更高的增長速率提升,并且增長趨勢有提前趨于平穩的趨勢,這是因為各個模型對大部分能夠準確識別的未標注樣本的預測分數主要集中在0.9以上,預測分數在0.9之下的樣本正是模型不確定性較高的樣本,需要加入訓練集來提升模型的泛化能力。此外,隨著閾值的提升(由0.8到0.85再到0.9)模型所需標注樣本量也跟隨著篩選批次逐漸減少,閾值為0.9時現象尤為明顯。閾值為0.9和0.95時3個模型的評價指標上升趨勢均幾乎重合,模型所需標注樣本量卻有明顯差異,模型預測分數能達到0.95的樣本近乎少數,所以閾值設為0.95時3個模型需人工標記的樣本量明顯多于閾值設為0.9的情況,不過在閾值為0.95時,BiLSTM_MSA_CRF模型隨著樣本選擇策略批次所需人工標記的樣本量下降速度更明顯些,也從一定程度上說明該模型預測分數高于0.95的樣本數量要比另兩種模型多。所以4個閾值相比,閾值0.9更適合作為本文的文本數據和本文所使用的命名實體識別模型。

表4 不同閾值條件下3種模型評價指標變化對比
實驗三:為了更加凸顯樣本選擇策略的作用,在不使用樣本選擇策略的情況下,在上一個實驗的同一批500條樣本中隨機選出與該批樣本選擇策略選出的樣本數目相同的未標注樣本加入訓練集訓練相應模型,實驗結果如圖14所示。
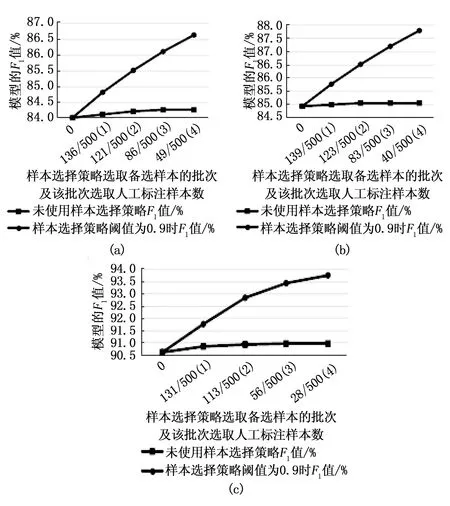
圖14 BiLSTM_CRF、BiLSTM_self-attention_CRF、BiLSTM_MSA_CRF使用和未使用樣本選擇策略實驗結果對比
從圖14可以看出,在未使用樣本選擇策略的情況下,人工標注與閾值為0.9的樣本選擇策略相同數量的樣本,模型識別能力的提升效果很不明顯,與使用了樣本選擇策略差異很大,所以樣本選擇策略明顯幫助我們在一批樣本中檢測出更能提升模型泛化能力的“有用”樣本,人工標注后加入訓練集,幫助模型“查漏補缺”。
5 結束語
經過上述3個實驗的對比,在機場不正常事件數據上,本文提出的BiLSTM_MSA_CRF模型達到更好的識別效果,明顯比BiLSTM_CRF、BiLSTM_self-attention_CRF提升了6個百分點的F1值。樣本選擇策略降低了人工標注成本,且幫助模型挑選了含有稀疏實體的樣本來供給人工標注后加入訓練數據,實驗得出的F1表明該方法明顯提升了模型識別效果。實驗證明本文提出的方法是解決海量機場不正常事件的關鍵要素檢測和識別的有效方法,可作為進一步分析大量機場不正常事件文本的基礎工作,協助民航相關人員及時總結事故規律和關系、制定控制事故的措施。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
