基于生成對(duì)抗網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)算法的研究
2022-07-26 09:31:20俞君杰
微型電腦應(yīng)用 2022年6期
俞君杰
(江蘇電力信息技術(shù)有限公司, 江蘇, 南京 210013)
0 引言
生成對(duì)抗網(wǎng)絡(luò)是最近提出的一類生成模型,其訓(xùn)練了生成器以優(yōu)化區(qū)分器同時(shí)學(xué)習(xí)的成本函數(shù)[1]。盡管學(xué)習(xí)成本函數(shù)的概念在生成建模領(lǐng)域相對(duì)較新,但長期以來,人們?nèi)匀徊捎脧?qiáng)化學(xué)習(xí)算法模型,導(dǎo)致存在學(xué)習(xí)效率低下,收斂速度慢等種種缺陷[2-3]。
因此,許多學(xué)者不斷研究其改進(jìn)和替換方法。文獻(xiàn)[4]公開了ASE學(xué)習(xí)算法,通過改進(jìn)樣本的采樣工序來提高目標(biāo)函數(shù)的精確度。該算法通過人工智能的方式提高了數(shù)據(jù)應(yīng)用和訓(xùn)練能力,但數(shù)據(jù)學(xué)習(xí)過程和應(yīng)用能力方法沒有提及,無法獲取數(shù)據(jù)訓(xùn)練或者計(jì)算的過程,工作效率滯后,也無法解決相關(guān)技術(shù)問題。文獻(xiàn)[5]應(yīng)用一種通過小計(jì)算獲取大效果的Q學(xué)習(xí)算法,應(yīng)用過程中,計(jì)算量比較小,該算法能夠輸出較佳的數(shù)據(jù)最優(yōu)解,對(duì)于解決復(fù)雜數(shù)據(jù)問題具有突出的技術(shù)效果,能夠通過隨機(jī)的方式實(shí)現(xiàn)數(shù)據(jù)的動(dòng)態(tài)變化,大大提高了數(shù)據(jù)應(yīng)用能力。該算法訓(xùn)練樣本的過程復(fù)雜,且對(duì)計(jì)算機(jī)系統(tǒng)性能要求過高,具有一定的局限性。本文借助生成對(duì)抗網(wǎng)絡(luò)的思想,給出用生成對(duì)抗網(wǎng)絡(luò)實(shí)現(xiàn)強(qiáng)化學(xué)習(xí)算法,下面將具體闡述該算法的結(jié)構(gòu)框架和相關(guān)理論內(nèi)容理論背景、基本思路、算法實(shí)現(xiàn)和實(shí)驗(yàn)分析。
1 相關(guān)理論
1.1 強(qiáng)化學(xué)習(xí)理論
在具體學(xué)習(xí)和應(yīng)用中,該研究構(gòu)建的馬爾科夫決策過程(MDP)能夠提高數(shù)學(xué)建模能力,尤其是在強(qiáng)化學(xué)習(xí)中,MDP應(yīng)用在完全可觀測的技術(shù)環(huán)境中具有一定現(xiàn)實(shí)意義,觀測到的狀態(tài)內(nèi)容完整地決定了決策需要的特征,幾乎所有的強(qiáng)化學(xué)習(xí)問題都可以轉(zhuǎn)化為MDP。一個(gè)MDP過程受幾個(gè)重要參數(shù)所影響,該重要數(shù)據(jù)參數(shù)因素中存在有限的數(shù)據(jù)信息狀態(tài)集s,有限的數(shù)據(jù)信息動(dòng)作集A,還能夠?qū)崿F(xiàn)使數(shù)據(jù)信息進(jìn)行轉(zhuǎn)移的狀態(tài)轉(zhuǎn)移概率P,實(shí)現(xiàn)數(shù)據(jù)信息回饋的回報(bào)函數(shù)R,將數(shù)據(jù)信息進(jìn)行折算的折扣因子γ。在MDP從狀態(tài)到動(dòng)作的映射過程為
Pss′=P(st+1=s′|st=s,at=a)
(1)
π(a|s)=P(at=a|st=s)
(2)
其中,t表示一個(gè)時(shí)間間隔,a表示目標(biāo)函數(shù)。根據(jù)MDP回報(bào)函數(shù)R能夠得出累計(jì)回報(bào)為
(3)
其中,G代表累加回報(bào)值,k代表回報(bào)函數(shù)R的自變量。由式(3)得出狀態(tài)處的期望回報(bào)值V為
(4)
由式(4)得出動(dòng)作處的期望回報(bào)值Q為
(5)
綜上式得出最有函數(shù)解的公式為
(6)
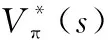
1.2 生成對(duì)抗網(wǎng)絡(luò)理論
在具體應(yīng)用過程中,將生成對(duì)抗網(wǎng)絡(luò)作為生成建模的一種方法,通過生成模型G和判別模型D兩種不同的方式實(shí)現(xiàn)數(shù)據(jù)信息評(píng)估與分析。實(shí)現(xiàn)數(shù)據(jù)信息生成對(duì)抗網(wǎng)絡(luò)的判別模型能夠?qū)?shù)據(jù)信息通過輸入分類數(shù)據(jù)信息,進(jìn)而將數(shù)據(jù)信息通過生成模型的方式進(jìn)行輸出,進(jìn)一步將能夠?qū)崿F(xiàn)的基礎(chǔ)數(shù)據(jù)樣本信息通過信息p(x)的形式實(shí)現(xiàn)輸出。為了提高數(shù)據(jù)信息的分類與輸出,通過生成模型完成。基于上述分析,該研究的生成對(duì)抗網(wǎng)絡(luò)模型結(jié)構(gòu)見圖1。
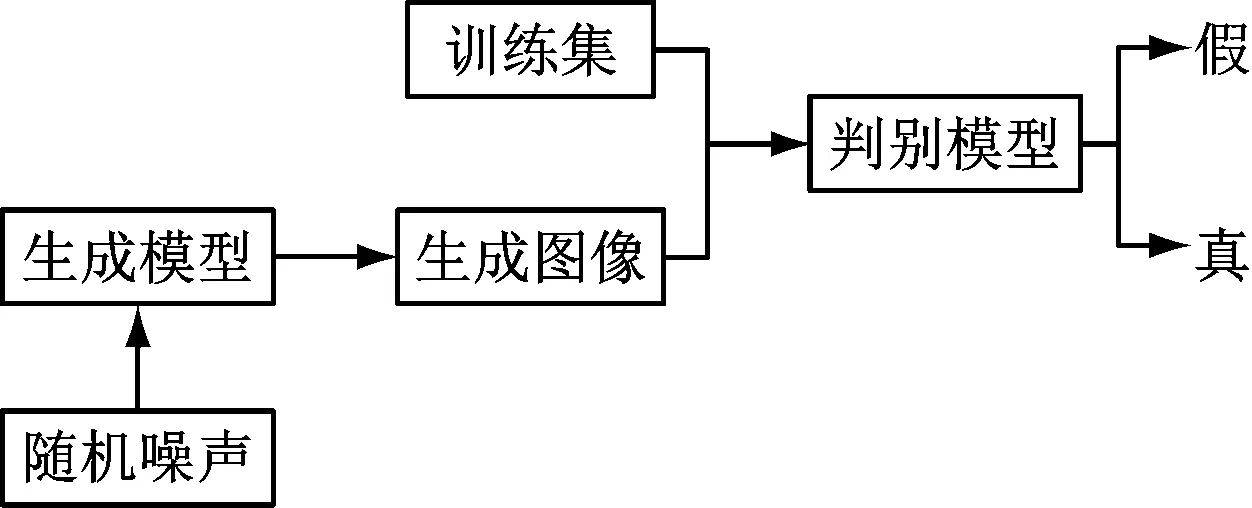
圖1 生成對(duì)抗網(wǎng)絡(luò)模型結(jié)構(gòu)圖
結(jié)合圖1對(duì)該研究的生成對(duì)抗網(wǎng)絡(luò)模型進(jìn)行以下介紹,在生成對(duì)抗網(wǎng)絡(luò)模型的過程中,通常將對(duì)抗過程劃分為極小、極大二元博弈問題。在一種形式上,輸出的生成模型具有出色噪音處理能力,在具體工作過程中能夠?qū)⑤敵龅脑肼曌鳛檩斎胄畔ⅲ⑤斎氲臄?shù)據(jù)信息轉(zhuǎn)化為樣本數(shù)據(jù)集合x~G,通過判別模型也能夠輸出數(shù)據(jù)信息,并將數(shù)據(jù)樣本數(shù)據(jù)信息集合記作為樣本x,然后將樣本數(shù)據(jù)集合x進(jìn)行數(shù)據(jù)輸入,其中輸出樣本數(shù)據(jù)信息通過分布式概率D(x)進(jìn)行計(jì)算。
通過判別模型輸出的數(shù)據(jù)信息損失能夠?qū)崿F(xiàn)正確的信息分類,并通過平均對(duì)數(shù)概率實(shí)現(xiàn)網(wǎng)絡(luò)數(shù)據(jù)信息損耗計(jì)算。在進(jìn)一步計(jì)算過程中,通過對(duì)比真實(shí)經(jīng)驗(yàn)樣本以及數(shù)據(jù)生成模型進(jìn)而實(shí)現(xiàn)均等混合數(shù)據(jù)信息的評(píng)估輸出:
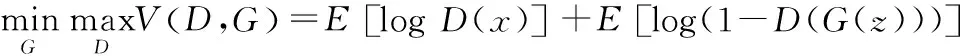
(7)
其中,生成模型的優(yōu)化方向是使D(x)增大,D(G(z))減小。將判別模型輸出的真實(shí)樣本通過大概率取樣,進(jìn)而能夠?qū)⑸赡P蜆颖靖怕手当M可能小;而判別模型與其理念相反。在明白兩個(gè)模型的優(yōu)化方向后,下面將闡述生成模型與判別模型的訓(xùn)練樣本過程。
首先,生成模型作為訓(xùn)練樣本的概率期望回報(bào)值V相關(guān)公式為
V=E[logD(x)]+E[log(1-D(x))]
(8)
對(duì)式(8)用積分的形式表示出來:
(9)
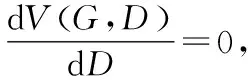
(10)
其中,Pdata表示整個(gè)對(duì)抗模型訓(xùn)練出數(shù)據(jù)樣本的概率,PG(x)表示生成模型G訓(xùn)練出數(shù)據(jù)樣本的概率。將式(10)帶入到式(9)中并進(jìn)行化簡計(jì)算得到:
V=-2log 2+2JSD(Pdata(x)|PG(x))
(11)
其中,JSD表示分布相似性的散度。通過式(11)的轉(zhuǎn)換得到生成模型G訓(xùn)練出來的樣本為
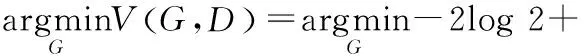
2JSD(Pdata(x)|PG(x))
(12)
通過式(12)可以得出,通過組合判別模型D與生成模型G,能夠進(jìn)而輸出生成的對(duì)抗網(wǎng)絡(luò)模型。這是因?yàn)榕袆e模型的優(yōu)先優(yōu)化更有利于目標(biāo)函數(shù)快速收斂,對(duì)訓(xùn)練樣本的速度影響更大,關(guān)于生成對(duì)抗網(wǎng)絡(luò)優(yōu)化過程如圖2所示。

(a) 初始過程
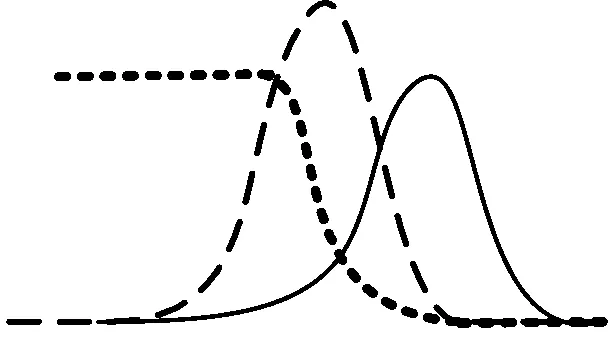
(b) 優(yōu)化判別模型
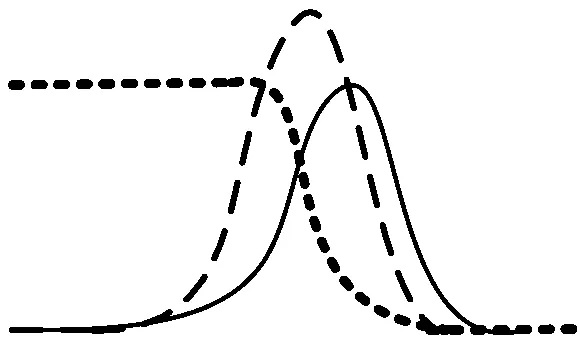
(c) 優(yōu)化生成模型
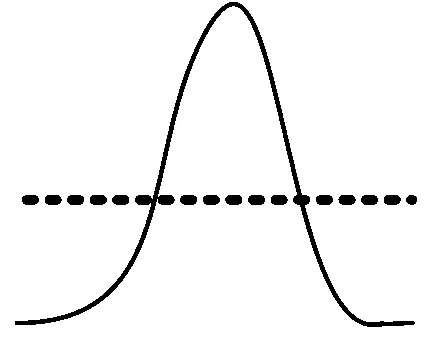
(d) 兩個(gè)模型收斂圖2 生成對(duì)抗網(wǎng)絡(luò)模型的優(yōu)化過程
1.3 基于生成對(duì)抗網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)算法
1.3.1 算法總體結(jié)構(gòu)框架
針對(duì)強(qiáng)化學(xué)習(xí)在訓(xùn)練樣本的開始階段,訓(xùn)練樣本學(xué)習(xí)效率低下,收斂速度滿足不了現(xiàn)有技術(shù)的需求,該研究將生成對(duì)抗網(wǎng)絡(luò)模型融入本研究技術(shù)中,通過構(gòu)建和設(shè)計(jì)強(qiáng)化學(xué)習(xí)算法提高該研究的計(jì)算能力,總體結(jié)構(gòu)框如圖3所示。

圖3 算法總體結(jié)構(gòu)框架示意圖
由圖3可知,在訓(xùn)練開始之前,根據(jù)強(qiáng)化學(xué)習(xí)的目標(biāo)策略進(jìn)行和歷史數(shù)據(jù)的真實(shí)經(jīng)驗(yàn)樣本聯(lián)合構(gòu)建真實(shí)經(jīng)驗(yàn)樣本集。在訓(xùn)練初始情況下,將生成對(duì)抗網(wǎng)絡(luò)算法模型的數(shù)學(xué)模型以及樣本數(shù)據(jù)模型作為試驗(yàn)樣本數(shù)據(jù)信息進(jìn)行訓(xùn)練、分析,以生成新的樣本,這種樣本數(shù)據(jù)信息并不是歷史數(shù)據(jù)所得出的真實(shí)經(jīng)驗(yàn),僅是理論上可行的數(shù)據(jù)樣本,可稱為虛擬樣本[6]。虛擬樣本不能直接并入真實(shí)經(jīng)驗(yàn)樣本集中,還需要通過智能體agent進(jìn)行一次訓(xùn)練,智能體類似于人腦一樣,既可以感知環(huán)境信息,也可以執(zhí)行最優(yōu)決策[7]。它會(huì)將好的虛擬樣本并入到真實(shí)樣本集當(dāng)中,提高訓(xùn)練樣本的質(zhì)量。大量的經(jīng)驗(yàn)樣本不斷更新狀態(tài)動(dòng)作,以達(dá)到全局最優(yōu)。同時(shí)引入關(guān)系修正單元,基于生成對(duì)抗網(wǎng)絡(luò)算法模型將經(jīng)驗(yàn)樣本一分為二,并算出兩者的相似性[8],在狀態(tài)空間大的情況下,能顯著提高強(qiáng)化學(xué)習(xí)的訓(xùn)練速度,并通過相對(duì)熵進(jìn)一步提高訓(xùn)練樣本的質(zhì)量。
在生成對(duì)抗網(wǎng)絡(luò)模型的基礎(chǔ)下定義強(qiáng)化學(xué)習(xí)計(jì)算,為了更好地進(jìn)行描述,需引入真實(shí)經(jīng)驗(yàn)樣本集C和獎(jiǎng)賞函數(shù)r的概念,表示為
C=[(s,a),(s′,r)]=[x1,x2]
(13)
在后續(xù)狀態(tài)函數(shù)s中,如何將該函數(shù)信息延續(xù)也是生成對(duì)抗網(wǎng)絡(luò)模型工作的關(guān)鍵,通常通過生成有限的狀態(tài)函數(shù)s′實(shí)現(xiàn)數(shù)據(jù)信息的分析與計(jì)算。在信息分析時(shí),通過將x1、x2兩者不同的數(shù)據(jù)信息產(chǎn)生數(shù)據(jù)關(guān)聯(lián)具有至關(guān)重要的作用,其關(guān)聯(lián)性通過以下公式描述:
I(x1,x2)=H(x2)-H(x2|x1)=P(x2)log2(P(x2))+
P(x2,x1)log2(P(x2|x1))=
(14)
式中,H表示熵,I表示x1、x2兩者之間的差異性。通過生成對(duì)抗網(wǎng)絡(luò)算法模型生成經(jīng)驗(yàn)樣本集G:
G=[(s,a),(s′,r)]=[G1,G2]
(15)
其中,G1、G2分別對(duì)應(yīng)x1、x2。由于后續(xù)狀態(tài)函數(shù)是延續(xù)上一個(gè)有限的狀態(tài)函數(shù),因此G1、G2兩者具有相似性,引入相對(duì)熵(KL)的概念,用其表示G1、G2兩者相似性:
(16)
式中,P數(shù)據(jù)信息對(duì)應(yīng)G1,Q數(shù)據(jù)信息對(duì)應(yīng)著G2。其中,p數(shù)據(jù)值對(duì)應(yīng)P函數(shù)值中數(shù)據(jù)信息,q值對(duì)應(yīng)Q數(shù)據(jù)信息中的函數(shù)值,i表示函數(shù)自變量。在狀態(tài)空間大的情況下,能顯著提高強(qiáng)化學(xué)習(xí)的訓(xùn)練速度,并且通過式(16)的延展推導(dǎo),還能滿足兩個(gè)關(guān)鍵要素:
(1) 倘若P=Q,則DKL=0。
以上關(guān)鍵要素用文字描述,則表示通過上述函數(shù)生成的數(shù)據(jù)狀態(tài)與后續(xù)數(shù)據(jù)信息生成的狀態(tài)相吻合,后續(xù)數(shù)據(jù)信息是通過函數(shù)生成的后續(xù)狀態(tài)與獎(jiǎng)賞函數(shù)進(jìn)行對(duì)比的工作進(jìn)行對(duì)比情況的比較。在這種數(shù)據(jù)信息的相對(duì)熵能夠以無限趨近的方式相似時(shí),則表示這種方式生成的數(shù)據(jù)信息或者通過對(duì)抗網(wǎng)絡(luò)算法模型進(jìn)行訓(xùn)練的樣本數(shù)據(jù)信息質(zhì)量比較高,根據(jù)式(7)演變得出:
(17)
其中,k為上述算法模型用到的權(quán)重參數(shù),W為上述算法模型中能夠?qū)崿F(xiàn)生成對(duì)抗網(wǎng)絡(luò)模型的目標(biāo)函數(shù)。當(dāng)相對(duì)熵比較無限地接近并與0趨近時(shí),能夠使對(duì)抗網(wǎng)絡(luò)算法模型輸出的目標(biāo)函數(shù)變得較小。
(2) 倘若PG=Pdata,則V(D,G)達(dá)到局部最優(yōu)。
以上關(guān)鍵要素用公式推導(dǎo),如果PG=Pdata,則根據(jù)式(10)得出D(x)=0.5,根據(jù)式(11)得出:
(18)
如果PG=Pdata,則P=Q,DKL=0,JSD=0,V(D,G)為最小值-2log2,取得局部最優(yōu)。
2 實(shí)驗(yàn)與分析
該研究構(gòu)建的實(shí)驗(yàn)內(nèi)容為一輛四輪小車處于兩面高中間底的山谷模型,其模型示意圖如圖4所示。
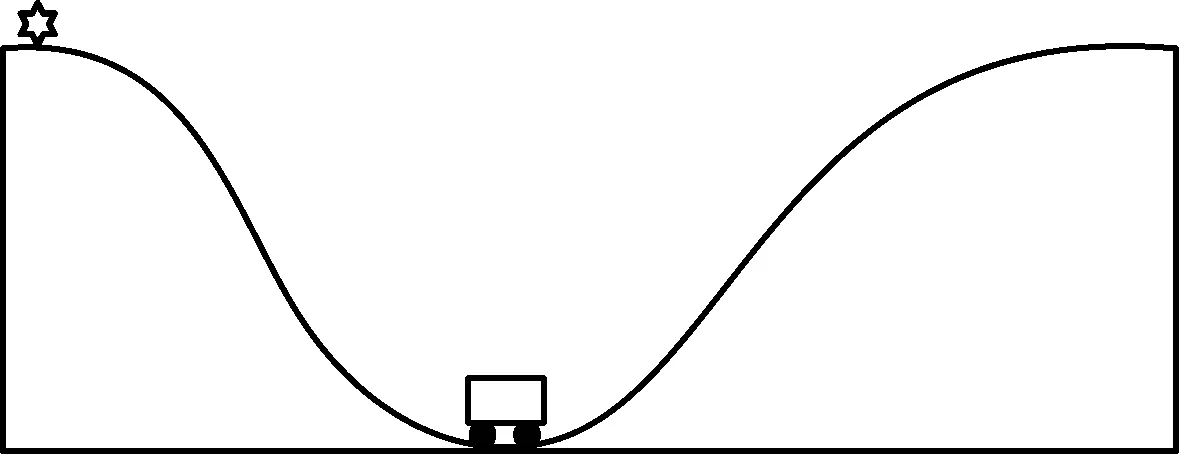
圖4 實(shí)驗(yàn)?zāi)P?/p>
該實(shí)驗(yàn)?zāi)P偷哪M內(nèi)容為在一個(gè)光滑曲面上給四輪小車一個(gè)加速度,使其到達(dá)五角形標(biāo)記的位置。但由于四輪小車初始加速度很小,四輪小車不能向左一次出發(fā)到達(dá)標(biāo)記位置,需經(jīng)過利用慣性,多次上下坡才能完成測試條件。在該實(shí)驗(yàn)?zāi)P椭校瑢?shí)驗(yàn)中設(shè)置重要參數(shù)折扣因子γ=0.99,學(xué)習(xí)率α=0.001,狀態(tài)s=[p,v],動(dòng)作a={+1,-1,0}。p表示四輪小車所處的水平位置,v表示四輪小車當(dāng)前位置的瞬時(shí)速度。+1表示四輪小車的初始加速度向左,-1表示四輪小車的初始加速度向右,0表示不給四輪小車初始加速度。
數(shù)據(jù)試驗(yàn)時(shí),通過強(qiáng)化學(xué)習(xí)算法的工具包OpenAI Gym進(jìn)行仿真,計(jì)算機(jī)操作系統(tǒng)為Windows 10,64位,計(jì)算機(jī)的開發(fā)工具為Visual Studio 2019,OpenCV 3.0,該研究采用文獻(xiàn)[5]中Q學(xué)習(xí)算法作為參照,采用基于生成對(duì)抗網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)(GRL)算法與Q學(xué)習(xí)算法在實(shí)驗(yàn)?zāi)P蜕线M(jìn)行訓(xùn)練,初始訓(xùn)練次數(shù)為5,兩種算法需獨(dú)立執(zhí)行10次,得出訓(xùn)練次數(shù)與算法執(zhí)行步數(shù)關(guān)系曲線如圖5所示。
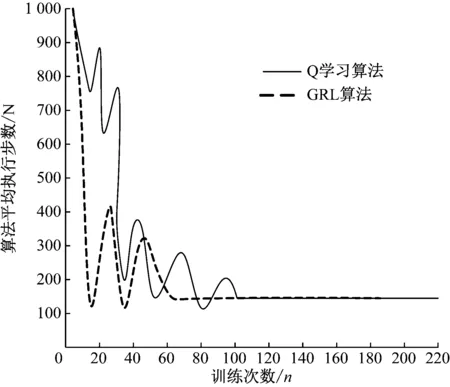
圖5 兩種算法性能對(duì)比圖
從圖5中可以看出,采用生成對(duì)抗網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)算法收斂所需的訓(xùn)練次數(shù)更少,這表明采用生成對(duì)抗網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)算法的系統(tǒng)性能更好,訓(xùn)練樣本的速度也更快。分析其原因在于采用生成對(duì)抗網(wǎng)絡(luò)將真實(shí)經(jīng)驗(yàn)樣本集C作為模板,生成新的虛擬樣本并入到樣本集C當(dāng)中,大量的經(jīng)驗(yàn)樣本不斷更新動(dòng)作a,因此訓(xùn)練樣本的速度快。
為了更好地表現(xiàn)出基于生成對(duì)抗網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)算法性能優(yōu)勢(shì),該研究采用在訓(xùn)練次數(shù)為1和10的情況下開始生成樣本,并且應(yīng)用網(wǎng)絡(luò)模型輸出的對(duì)抗網(wǎng)絡(luò)進(jìn)行強(qiáng)化計(jì)算后的結(jié)果需獨(dú)立執(zhí)行10次,得出訓(xùn)練次數(shù)與算法執(zhí)行步數(shù)關(guān)系曲線如圖6、圖7所示。
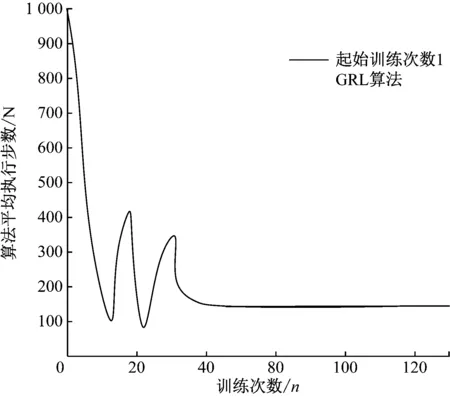
圖6 起始訓(xùn)練次數(shù)為1的GRL算法性能圖

圖7 起始訓(xùn)練次數(shù)為10的GRL算法性能圖
結(jié)合圖6與圖7中GRL算法的曲線圖綜合來看,其中起始訓(xùn)練次數(shù)為1的GRL算法收斂得最快,在訓(xùn)練次數(shù)為40左右就已收斂,而起始訓(xùn)練次數(shù)5和10的GRL算法分別在訓(xùn)練次數(shù)為60與80次的收斂。分析其原因在于采用生成對(duì)抗網(wǎng)絡(luò)將真實(shí)經(jīng)驗(yàn)樣本集C作為模板,生成新的虛擬樣本并入到樣本集C當(dāng)中,越早的加入生成新的虛擬樣本,更新動(dòng)作a的頻率也就越大,因此在起始訓(xùn)練樣本次數(shù)越低的情況下,用生成對(duì)抗網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)算法的系統(tǒng)性也就會(huì)更好,訓(xùn)練樣本的速度也更快。
3 總結(jié)
該研究利用生成對(duì)抗網(wǎng)絡(luò)模型與執(zhí)行最大熵強(qiáng)化學(xué)習(xí)算法之間的等效性,推導(dǎo)使用一種特殊形式的判別模型,該判別模型利用了生成模型的似然值,從而對(duì)目標(biāo)函數(shù)收斂進(jìn)行了無差別估計(jì)。上述方法的輸出結(jié)果表明,該研究方法的輸出性能比Q算法的輸出性能具有顯著的提升,該算法的收斂速度比較快。這種方案也存在其他方面的不足,這仍舊需要進(jìn)一步探究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中外會(huì)展(2014年4期)2014-11-27 07:46:46
中學(xué)數(shù)學(xué)雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
