基于詞向量集成與數據增強的惡意評論分類模型
2022-07-25 02:12:06楊金靈
科學技術創新 2022年22期
楊金靈
(大連外國語大學,遼寧 大連 116044)
如今,隨著科技時代的到來,人們在發達的互聯網背景下往往傾向于利用方便的電子設備在網絡中發表各種各樣的言論和表達自身的情感。因此從眾多的意見中也產生了海量的數據。但是,其中不乏暗含著具有充滿威脅性的甚至報復性質的惡意評論。據調查,網絡安全研究員Jeremy Fuchs 在發表的一份報告中寫道,CheckPoint 公司旗下的電子郵件協作和安全公司的研究人員在12 月首次觀察到了大規模黑客利用谷歌文檔的評論功能進行攻擊的趨勢,并且到目前為止攻擊者通過利用谷歌基于云端的文字處理應用程序的功能,已經攻擊了30 個用戶的500 多個收件箱,來自100 多個不同的Gmail 賬戶。這類不良現象的頻繁發生聚集了越來越多的科學家和研究人員等業內人士的焦點。在處理這一問題的方法上,實則是一個文本分類的工作,因此利用經典的,前沿的技術手段對這些文本進行高效最優地分類成為了科研人員研究的熱點問題之一[1]。如在文獻[2]中陳等人提出了融合領域知識圖譜的方法,將跨境民族文化文本進行歸類處理。
本文采用來自維基百科談話頁面編輯的評論數據集設計了惡意評論的文本分類任務,即使研究者們的實驗模型已經達到了不錯的預測性能,但是在實驗配置與數據集等方面仍有待改進之處:
(1)將文本轉換成數值向量的詞向量中記錄了日常常見單詞文本的相似度,詞向量的選擇對于模型的分類性能有著巨大影響。而在某個語料庫單獨訓練的詞向量往往會對統計學的捕捉存有偏差,因而降低模型的分類性能。在惡意評論分類模型中只使用了一個在fastText上預訓練的300 維詞向量,因此在這一問題上增大了模型預測值不準確性的概率。
(2)現有的數據集中約有15 萬條評論,由于樣本數量有限,因此模型在樣本數據集中能會導致惡意分類錯誤的情況發生,從而危害模型的穩健性(robustness)。因此,從模型所能夠學到的內容與穩健性角度來看,現有的模型仍存在不足。
(3)在現有的研究中,集成詞向量與數據增強較少被人們使用,研究方法層面也有所欠缺。
所以針對以上問題,本文提出了一種集成詞向量與數據增強的惡意文本分類模型(ENSVEC-DA)。
1 實驗設置
1.1 實驗框架
本實驗的總體流程介紹如下:
首先,準備本實驗所需的兩種訓練集,分別為增強的訓練集與非增強的訓練集。
其次,先后選擇訓練集中的一種,通過預訓練的詞向量將里面的評論文本轉化為非集成的數值向量和集成的數值向量。
再次,通過是否增強訓練集與是否集成詞向量兩兩組合得到四組對比實驗,并使用相同的測試集使RNN 網絡依次預測四組實驗的惡意概率。
最后,計算出每組實驗中六組標簽所對應的Acc、AUC、Brier Score 評估指標,通過對比評估指標得出結論。實驗框架如圖1 所示。
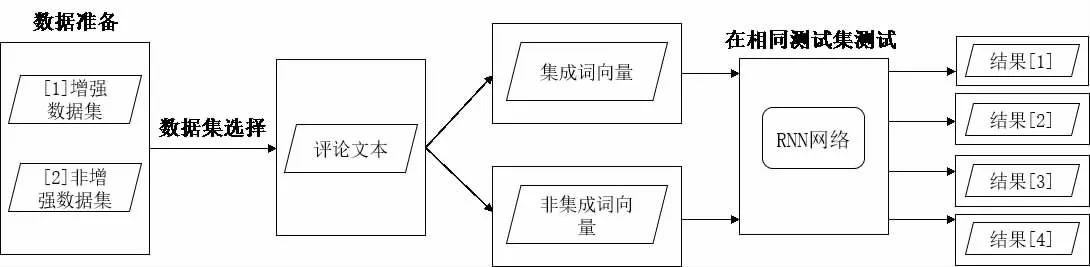
圖1 實驗框架圖
1.2 實驗數據集
本實驗的樣本數據集采用來自維基百科談話頁面編輯的評論數據集,來源可靠且相對權威。
此數據集包含訓練集與測試集,均含有6 個標簽,總評論條數分別為159571 條和153165 條,其中在測試集里除-1 標簽標注的無效評論外共有63979 條有效評論,統計的樣本數據集如表1、表2 所示。

表1 訓練集標簽

表2 測試集標簽
1.3 評估指標
為了更合理且準確地評估ENSVEC-DA 惡意文本分類模型的預測性能,本文選用了較為常用高效的準確率Acc(Accuracy)、AUC(Area Under Curve)和布里爾分數(Brier Score)三種評估指標。詳見表3。

表3 性能評估相關值表
準確率Acc(Accuracy)計算公式:
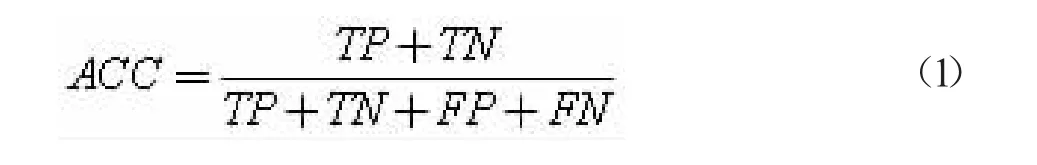
布里爾分數(Brier Score)計算公式:
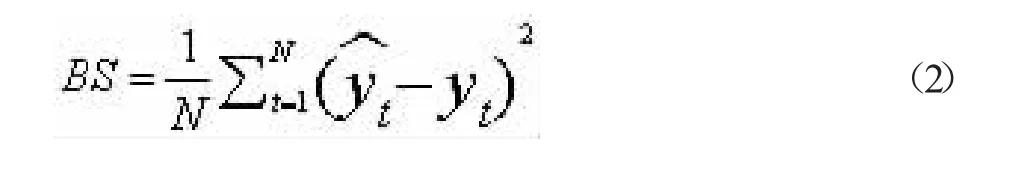
布里爾分數是衡量概率校準的一個參數[3],可以被認為是對一組概率預測的“校準”的量度。式(2)中:N 表示總共檢測的樣本數目,y^t是預測的概率值,yt是真實的概率值。
AUC 是ROC 曲線下方的面積大小[4],是對模型性能評估的一項重要指標。ROC 曲線[5]的橫坐標是假正例率(FPR),其計算公式為FPR=FP/(TN+FP),縱坐標是真正例率(TPR),計算公式為TPR=TP/(TP+FN)。
在本實驗中以是否集成詞向量,是否數據增強為變量,使變量兩兩組合得到四組對比實驗。通過分別計算四組實驗的評估指標最終判斷模型的預測性能提升與否。
2 實驗結果
2.1 詞向量集成技術對惡意評論分類性能的影響
為了驗證詞向量集成技術具有提升模型分類性能的優點,我們基于非數據增強的訓練集,對使用詞向量集成技術與非使用詞向量集成技術進行了對比實驗。表4、5、6 為實驗評估指標結果。
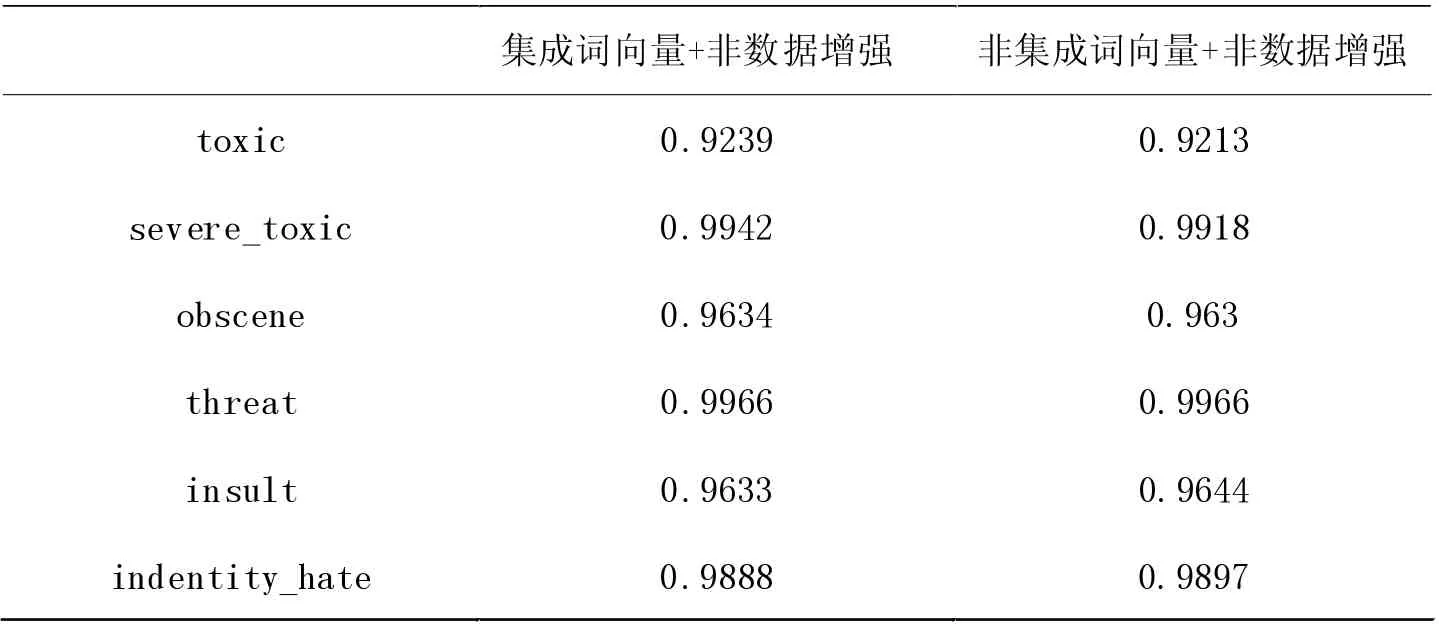
表4 Acc 評估指標
在指標值層面分析實驗的惡意預測概率可以看出,詞向量集成技術對模型分類性能的提升有所幫助。雖然在表5 所示的AUC 指標中,六種標簽所對應的AUC 數值在非集成詞向量方面表現更好,但是綜合對比Acc 和Brier Score 指標后我們發現,詞向量技術在某些惡意評論分類上有更優效果。根據表4 進一步分析,在toxic、server_toxic、obscene 這三種評論上集成詞向量比非集成詞向量的評估指標Acc 值分別高出0.0026、0.0024 和0.0004。并且由表6 中的Brier Score 值所示,在集成詞向量實驗中,server_toxic 的Brier Score 值比非集成詞向量實驗的值降低了0.0003。因此,結合表4 與表6 的結果,我們發現詞向量集成技術可以提升部分種類的惡意評論的分類性能。
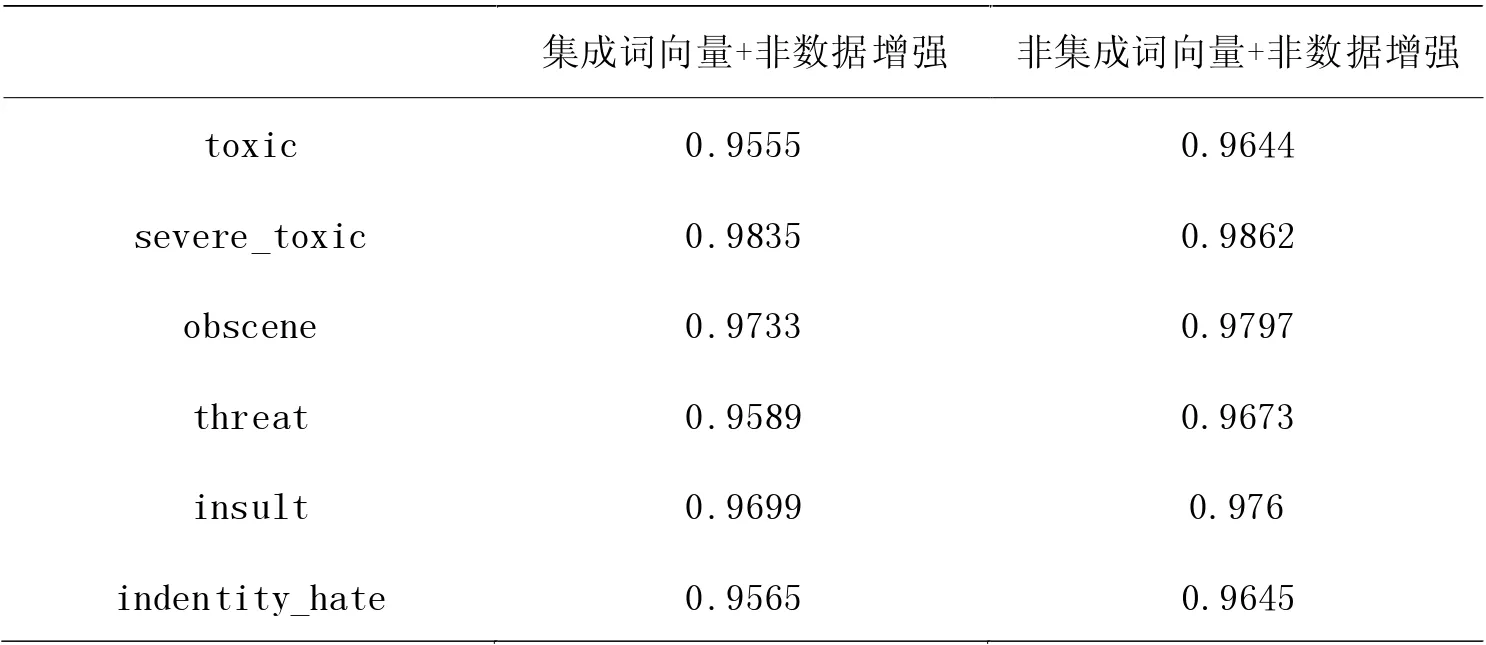
表5 AUC 評估指標
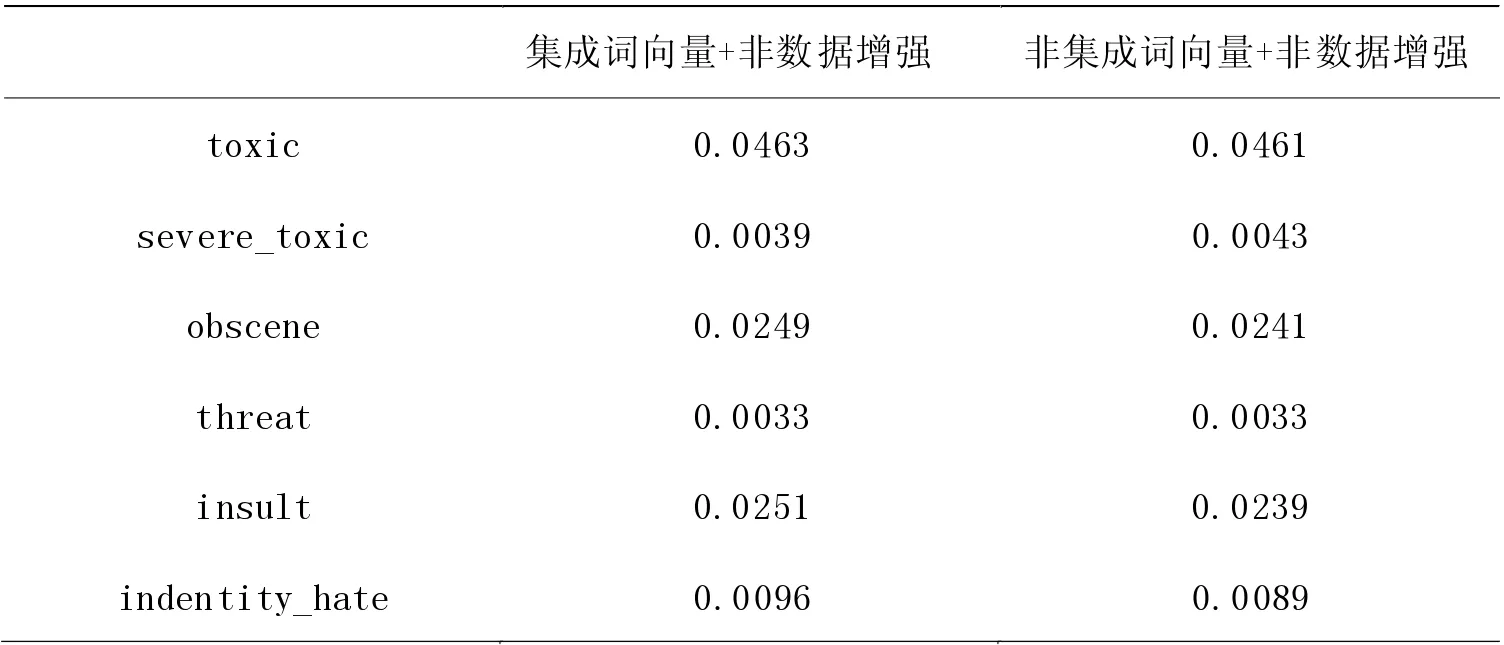
表6 Brier Score 評估指標
2.2 數據增強技術對惡意評論分類性能的影響
本組實驗使用與上組實驗相同的評估指標來分析數據增強技術對惡意評論分類性能的影響。根據實驗所得的惡意評論分值計算出的評估指標展示如圖7-9。
對比分析表7、8、9 中的數據,我們發現數據增強技術與詞向量集成技術所產生效果相似,兩者均提高了實驗模型對某種惡意評論的分類性能。根據表中數據可得出結果如下:

表7 Acc 評估指標
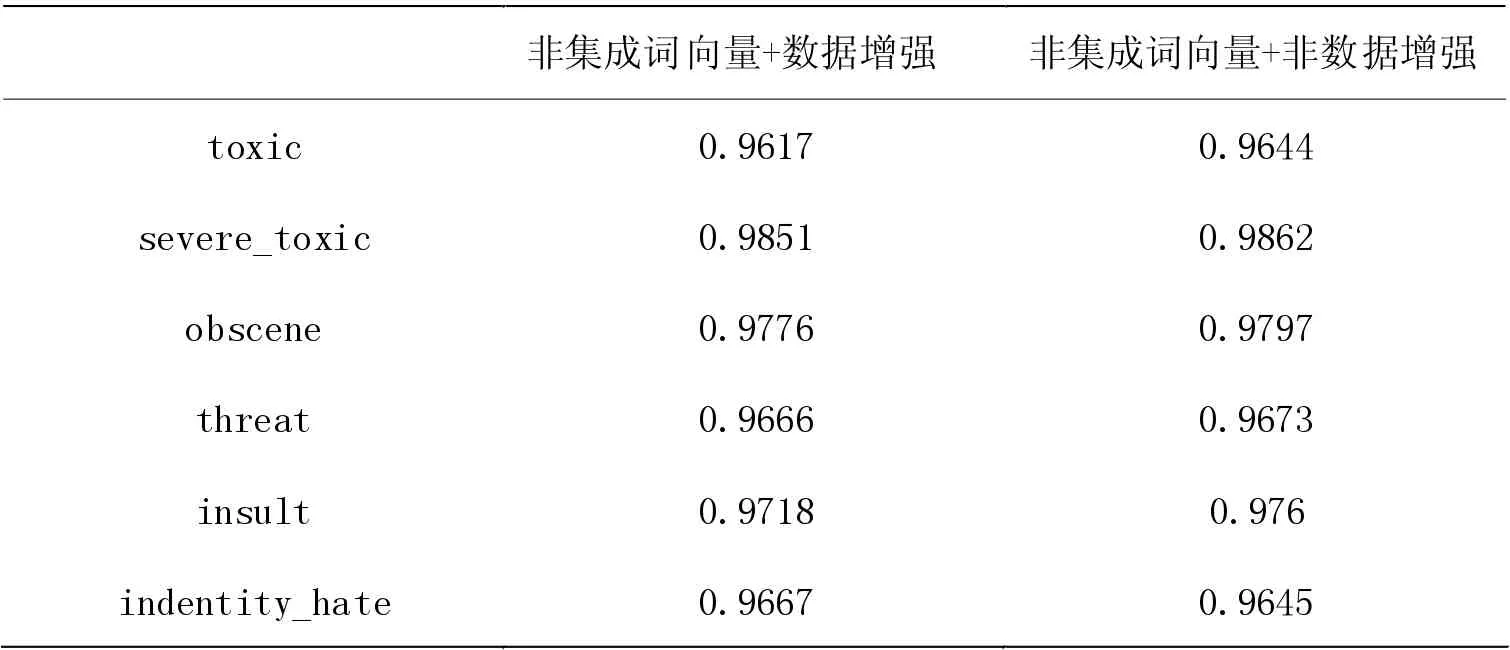
表8 AUC 評估指標

表9 Brier Score 評估指標
(1) 在server_toxic 和obscene種類上,數據增強實驗的Acc 值比非數據增強的Acc 值分別高出了0.0003 和0.0027。
(2)在AUC 值上,數據增強的indentity_hate 種類表現更好,且比非數據增強高出0.0022。
(3) 對比非數據增強實驗的Brier Score 值,在數據增強的實驗里,server_toxic 和obscene 種類所對應的數值分別降低了0.0001 和0.0004。
因此,可以肯定數據集成技術對惡意評論分類性能提升的積極影響。
2.3 ENSVEC-DA 惡意文本分類模型性能評估
為研究詞向量集成技術與數據增強技術的結合使用的ENSVEC-DA 惡意文本分類模型是否對分類性能產生有益影響,本文分別從ACC、AUC、Brier Score 三種評估指標分析了本模型在四組實驗中對六種惡意評論的預測分值,并通過繪制分組條形圖進行對比分析,如圖2、3、4 所示。
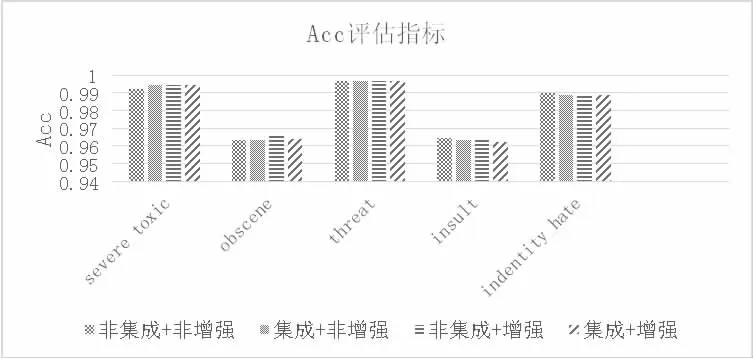
圖2 Acc 評估指標對比

圖3 AUC 評估指標對比

圖4 Brier Score 評估指標對比
從圖2 中我們可以發現,在server_toxic 種類上,Acc 值雖然在集成詞向量和數據增強方面略低,但是總體在直方圖展示上幾乎呈現上升趨勢,并且在toxic、obscene、indentity_hate 中,兩種技術的結合使用比其他某個組合實驗的Acc 值更高。由AUC 評估指標對比圖可見,結合詞向量集成技術和數據增強技術的AUC 值比集成詞向量和非數據增強實驗的AUC 值在indentity_hate 種類表現上更好,并且在圖4 Brier Score 分組條形圖中的server_toxic 種類上,使用兩種技術的評估值比非使用兩者的評估值高。
由此可見,詞向量集成技術和數據增強技術的結合使用使ENSVEC-DA 惡意文本分類模型的預測性能在部分種類的惡意評論上有所提升。
3 結論
通過分析惡意評論分類模型的實驗配置與樣本數據集,我們發現了原實驗中存在的使用詞向量單一,數據集信息有限的問題,這會降低分類模型在某種惡意評論的預測性能。因此,本文中提出了ENSVEC-DA 惡意文本分類模型,使用詞向量集成技術和數據增強技術來有效解決這一問題,通過控制是否集成詞向量和是否數據增強這兩個變量在同一測試集上做四組對比實驗。最終結果顯示,ENSVEC-DA 惡意文本分類模型在某種惡意評論分類性能上表現更好,這有效地改善了現有方法的不足之處。
綜上,在未來的研究工作中我們將繼續多角度優化并驗證ENSVEC-DA 惡意文本分類模型的分類性能,使該模型應用于更多領域中。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
