大數據技術在中藥材資源優化配置中的應用
2022-07-23 05:02:28郭春麗吳國華顧若濤林嘉穎陳鵬程
亞太傳統醫藥 2022年6期
關鍵詞:藥品
郭春麗,吳國華,顧若濤,林嘉穎,陳鵬程
(1.廣東財貿職業學院 信息技術學院,廣東 廣州 510445;2.廣東財貿職業學院 現代教育技術與實訓中心,廣東 廣州 510445;3.廣東財貿職業學院 總務處,廣東 廣州 510445)
中醫藥作為我國獨特的醫療資源、潛力巨大的經濟資源、具有原創優勢的科技資源、優秀的文化資源和重要的生態資源,對社會經濟的發展有重要的作用[1]。在抗擊新型冠狀病毒肺炎疫情中,中醫藥再一次向世人證實了其顯著的療效。而中藥材作為中醫藥事業傳承和發展的重要物質基礎[2],它的規范存儲、養護、運輸是促進中藥材產業健康發展的重要保障。
2015年1月,商務部印發了《關于加快推進中藥材現代物流體系建設指導意見》,指出到2020年基本建成中藥材主要產銷區為流通節點的物流基礎設施和流通網絡,配套建設規模化倉庫設施,實現中藥材物流的跨區域、規模化、集約化經營[3]。截至2019年底,11家中藥材物流實驗基地完成現場認證,67個基地正在建設中,規劃中的藥材倉儲量272萬噸[4]。物流示范基地主要是實現產區藥材的收儲[5],很少考慮到從產區到銷區的成本。而中藥材的下游企業中藥廠,作為中藥材的主要銷區,它們所處的位置影響著中藥材資源配置的高效。因此,如何結合中藥材的主要產銷區,優化資源的配置是具有現實意義的難題。
本文通過梳理“藥廠-中成藥-中藥材”三者的關系,運用大數據技術從大量中藥配方入手,挖掘出現次數最多的單個或組合中藥材,再通過以核心藥材為原材料的藥品,統計出藥廠,從而計算出使用頻率高的中藥材在全國的主銷區,最后結合主要產銷區,為優化資源的配置提供一種精準的方法。
1 大數據技術介紹
大數據技術是指對海量、異構、復雜的數據通過采集、存儲、清洗、分析與挖掘、展現等方式進行加工和支撐,從而發現有用的或有意思的規律和 結論,實現數據的增值。
一般處理流程有五個環節,主要介紹如下:①數據采集:常見的采集方式有網絡爬蟲、傳感器、日志記錄等;②數據存儲:一般有關系型數據庫、Excel、分布式數據庫,可根據數據量的大小進行選擇,方便數據的讀寫;③數據清洗:對缺失、錯誤、重復、異常等 “臟”數據進行處理,提高數據集的質量;④數據分析:常用的分析方法有聚類、分類、關聯規則等,運用算法對數據進行挖掘和分析;⑤數據展現:對分析的結果用圖表的形式進行展現,更清楚地呈現分析的結論。
2 中藥材資源優化配置的框架
目前,中藥材流通節點通過收集當地區域內分散農戶手中的中藥材,進行集中儲存規范入庫、按需配送以及配套安全監控,實現中藥材資源的配置。
2.1 邏輯框架
本文以中藥廠作為中藥材的主要銷區,整體配置業務如圖1所示。

圖1 中藥材資源配置業務邏輯
可以看出,流通節點作為基礎倉儲場所,既可以存儲,也可以根據賣方需求進行發貨。這樣極大程度保證資源的合理配置和中藥材的質量安全。中藥廠在國家藥監局公開備案,具備GMP生產資質后,從中藥材種植者或中間商采購中藥材,進一步加工生產中成藥,再以渠道或代理的方式進行銷售。現在信息發達,網上都可以檢索每家中藥廠生產的中成藥種類,每種中成藥的成分信息,即以哪些中藥材作為原材料。
2.2 技術框架
根據配置業務邏輯,采用大數據技術進行優化,技術框架如圖2所示。

圖2 技術框架
2.2.1 數據采集 數據采集是基礎,中藥材、中成藥、中藥廠信息在網上都能檢索,通過技術手段可以收集起來。
2.2.2 數據存儲 主要看數據量的大小,這里由于數據量最多上百萬條,選擇關系型數據Mysql存儲。
2.2.3 數據清洗 處理“臟”數據,包括重復值、缺失值、錯誤值、異常值,比如數據中混雜的有西藥,屬于異常值,需要對其進行刪除操作。
2.2.4 數據分析 通過分析中成藥的成分信息,統計出現頻數多的中藥材,再計算使用核心藥材的中成藥,然后檢索生產這些中成藥的藥廠,從而根據藥廠所在的區域得出主銷區。最后結合主要產銷區,給出資源配置優化的方案。
2.2.5 數據呈現 對分析的結果進行呈現,再分析其結果的正確性。
3 實驗分析
3.1 實驗過程
3.1.1 數據采集 采集中藥材、中成藥、藥廠的信息,分別見表1、表2、表3。其中藥廠包括生產中藥和西藥的藥廠,藥廠生產的藥品見表4。

表1 中藥材主要信息

表2 藥廠主要信息

表3 藥品主要信息

表4 藥廠生產的藥品
最終,共收集了1 759條中藥材標準信息、10 679條藥品信息(含少量西藥)以及8 289家藥廠信息,存儲到Mysql數據庫中。
3.1.2 數據清洗 由于中藥材名稱是有限且統一的,藥品的成分是0個或多個中藥材的配伍,這是一個典型的多模式串識別問題,本文采用Aho-Corasick算法進行數據清洗,具體步驟如圖3所示。

圖3 清洗步驟
需要注意的是,中藥材名稱有一些是包含關系,比如茯苓、土茯苓,但它們屬于不同的中藥材,清洗時要避免將土茯苓識別成為土茯苓和茯苓兩味藥材以造成數據的二次“污染”。
對重復、缺失的數據,以及不含中藥材的藥品數據進行刪除處理后,共有7 038條中成藥數據,成分信息里中藥材之間用逗號進行分隔。表5列出部分清洗前后的數據。

表5 清洗前后的數據(部分)
3.1.3 數據挖掘 選用關聯規則的模式增長算法即FP-growth算法來計算核心藥材,并發現核心藥材之間的隱含關系與規律。
首先,計算藥品中每味中藥材出現的頻次,即頻繁項集為1的藥材,結果見表6。這里支持度取0.07,大于支持度的單項集時核心藥材。

表6 單項集(部分)
可以看出甘草、當歸、茯苓、川芎、黃芪、黃芩等是使用頻數高的中藥材。甘草作為“中藥之王”,具有補氣功效等作用[6],當歸具有補血活血等作用[7],茯苓具有利水滲濕、健脾寧心的作用[8],黃芪素有“東北小人參”之稱,是補中益氣要藥[9]。核心藥材與在感冒類、脾胃類清熱類、肺炎類、增強免疫等細分領域的研究結果是一致的[10-13]。
其次,查詢使用核心藥材的中成藥,也就是檢索出成分含有核心藥材的中成藥,藥名是唯一的。
然后,統計生產這些中成藥的藥廠,再根據藥廠位置歸屬到所在省份/自治區/直轄市。由于本文采集的中藥廠分布在全國31個省/自治區/直轄市,每個區域對中藥材種類使用數量的情況如圖4。

注:顏色越深代表使用的中藥材類型數量越多,圖中可明顯看出內蒙古、吉林、河北、黑龍江、江西四個省/自治區的藥廠是中藥材的主要銷區。圖4 使用的核心藥材類型數量、分布地圖
最后,挖掘核心藥材之間的關聯關系。中成藥一般都是多味中藥材配伍,挖掘出關聯關系強的潛在中藥材組合。頻繁項集為2,最小支持度和置信度分別為0.05、31%,結果見表7,頻繁項集為3時,最小支持度和置信度分別為0.025、45%,結果見表8。

表7 最大頻繁項集為2時的關聯關系
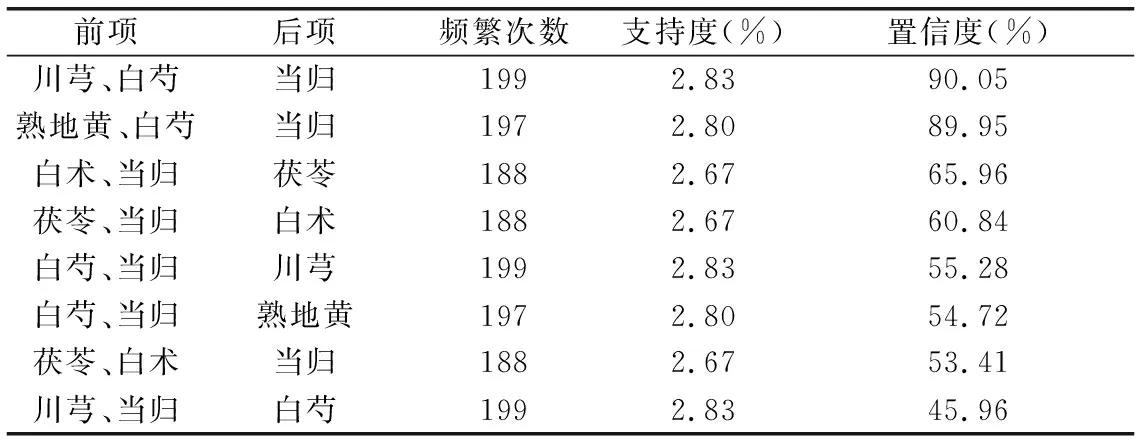
表8 最大頻繁項集為3時的關聯關系
3.2 結果分析
從表7結果可知,核心藥材間的關聯關系能夠同時滿足最小支持度和置信度的要求,表明核心藥材間存在強關聯規則。藥品成分中有川芎、白芍、當歸三味中藥材,則以上藥材同時出現的頻率為2.83%;另外,挖掘結果顯示含有川芎、白芍的所有中成藥中有90.05%的概率會出現當歸,出現桔梗的藥品中有62.8%的概率出現甘草,陳皮的藥品中有45.92%的概率出現甘草,白芍的藥品中有41.89%的概率出現甘草。這種強關聯關系既表明藥材間存在配伍的規律,也為流通節點對中藥材的資源配置提供了一種優化方法,即在配置桔梗、陳皮、白芍、茯苓的區域,可同時配置甘草,同理,在配置川芎、白術、黃芪的區域,可考慮同時配置當歸。
另外,從圖4可以看出,使用的核心藥材類型數量多的地區集中在華北、華東、華中、西南和西北地區,而青藏、新疆、江蘇、海南等地區相對少一些。這與中藥材的道地產區氣候、土壤等自然環境有很大關系。康傳志等[14]研究得出不同區域分布的道地藥材,如表9。

表9 不同區域分布的常見中藥材
將上表中藥材的道地產區與本文分析的核心藥材主要銷區結合起來,江西屬于白芍、白術、茯苓、丹參等核心藥材的中心產區,也是藥材使用類型最多的一個區域,所以在選擇大規模倉儲、物流中心節點時,可考慮在江西地區作為中藥材的綜合地區。而內蒙古中部地區是生產甘草的道地產區,也是甘草的主要使用地區,則此區域的流程節點以甘草為主,同樣,河北地區可以以黃芪、黃芩為主。
主產地與主銷區的結合,既可以發揮道地產區的優勢,保證中藥材的質量,也可以科學地將道地產區藥材倉儲到離銷售區域最近的位置,縮短銷售的時間、物流、經濟等成本,為中藥材資源的優化配置提供高效的途徑。
4 結語
本文運用大數據技術,采集中成藥、中藥材、藥廠等信息,利用Aho-Corasick算法對中成藥的成分信息進行清洗,再用FP-growth算法挖掘核心藥材之間的關聯關系,統計出核心藥材的主銷區。結合核心藥材的道地產區和主銷區,為中藥材的資源配置提供了一種優化的方法。
在研究過程中,核心藥材的類型數量是主要考慮因素,下一步工作可以加入藥廠對中藥材的使用量這一因素。因為藥廠有自己的主打藥品,成分中的前幾個中藥材一般是藥品的主要原材料,這樣預估使用量可以為優化方案提供更全面的依據。
猜你喜歡
中國合理用藥探索(2022年1期)2022-11-26 00:22:32
世界最新醫學信息文摘(2021年12期)2021-06-09 08:36:56
小學生優秀作文(低年級)(2018年6期)2018-05-19 01:54:28
消費導刊(2017年20期)2018-01-03 06:27:16
中國衛生(2016年6期)2016-11-23 01:09:08
中國衛生(2016年5期)2016-11-12 13:25:28
中國藥物應用與監測(2015年5期)2015-12-11 03:15:54
中國衛生(2015年9期)2015-11-10 03:11:14
中國衛生(2015年5期)2015-11-08 12:09:48
中國衛生(2015年4期)2015-11-08 11:15:58
