改進MobileNetv3-YOLOv3交通標志牌檢測算法
2022-07-23 06:30:16劉宇宸劉明輝鄭秋萍
東北師大學報(自然科學版) 2022年2期
劉宇宸,石 剛,崔 青,劉明輝,鄭秋萍
(新疆大學信息科學與工程學院,新疆 烏魯木齊 830046)
0 引言
隨著現代科技的飛速發展,無人駕駛技術已經成為現實,其中交通標志檢測是無人駕駛和輔助駕駛的重要組成部分.然而交通標志識別容易受到天氣變化、遮擋、光照強度變化等影響,這給無人駕駛的應用帶來了很大的安全風險[1].因此,需要設計一種實時性強、精度高的方法來解決上述問題.
自2012年文獻[2]在Imagenet大規模視覺識別挑戰賽取得巨大的成功后,越來越多的深度學習模型被提出并應用于交通標志牌的識別.目前交通標志牌識別的主流算法主要以Faster R-CNN(Faster Region-CNN)[3]和YOLO(You Only Look Once)[4]兩大類為主,其中Faster R-CNN為雙階段模型,其檢測精度高,但是檢測速率略慢,YOLO為單階段模型,其檢測速率快,但是精度有所下降.
為了提高交通標志牌的檢測精度,文獻[5]首先提出改進的YOLOv2算法,但是其檢測準確度與精度都很低,隨后提出了多尺度融合的Cascaded R-CNN 算法,檢測準確度雖然有所上升,但其存在檢測速率慢的問題.為了更好契合實時性的特點,李旭東等[6]基于YOLOv3-Tiny提出了基于三尺度嵌套殘差結構的交通標志快速檢測算法,在CCTSDB上其檢測速度高達200 f/s,但是精度卻有所下降.陳昌川等[7]基于YOLOv3融合殘差網絡、下采樣并且舍棄通用池化層而改用卷積層等操作,提出了T-YOLO算法,在CCTSDB上檢測精度高達97.3%,但檢測速率每秒傳輸幀數(FPS)只有19.3,最新的算法YOLOv5s雖然檢測速度很快,但是檢測準確度與檢測精度卻很低.
綜上所述,為了減少算法的計算量,提高對目標的定位精度,本文提出了一種改進的MobileNetv3-YOLOv3算法,該算法與最新的算法比較,本文所提出的算法準確度和平均精度最好.
1 模型的構建
1.1 YOLOv3網絡
YOLOv3算法是對YOLOv2算法的改進,其借鑒殘差網絡(ResNet)[8]的思想,并增加了快捷鏈路(shortcut connections)、融合特征金字塔網絡(Feature Pyramid Network,FPN)[9],相比較之前的算法,YOLOv3在小目標的檢測上有了顯著的提升.
YOlOv3是端到端的網絡結構,以DarkNet-53為基礎網絡結構,由53層卷積而組成,從不同尺度來提取對應的特征,可以減少計算量并且降低低級特征在池化層中的丟失.YOLOv3算法處理流程如圖1所示.

圖1 YOLOv3算法處理流程
1.2 Focus模塊
聚焦(Focus)模塊的概念,最先應用于YOLOv5,聚焦(Focus)模塊的作用是在圖片進入骨干網絡(backbone)前,對圖片進行切片操作,將圖片的每一個像素值進行下采樣處理,經過一系列卷積操作后就可以得到沒有信息丟失的特征圖,可以有效地減少計算量加快處理速度.聚焦(Focus)模塊處理流程如圖2所示.
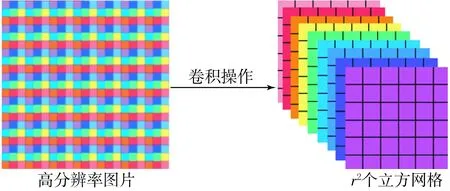
圖2 聚焦(Focus)模塊處理流程
1.3 SPPNet模塊
空間金字塔池化網絡(Spatial Pyramid Pooling Network,SPPNet)[10]模塊可以將任意分辨率的feature map轉換為與全連接層相同維度相匹配的特征向量,使得特征向量不再是單一尺度,其有效避免圖像因為縮放、剪裁等一系列操作而導致圖像失真的問題,SPPNet試圖通過增強圖像處理,將圖像像素映射到特征圖的感受野中心,增強感受野,提高處理結果的準確性.
圖片左上角映射公式為
x′=[x/S]+1.
(1)
圖片右下角映射公式為
x′=[x/S]-1.
(2)
SSPNet也解決了神經網絡中特征重復提取的問題,可以提高候選框的速度,從而大大降低了成本.SSPNet模塊處理流程如圖3所示.
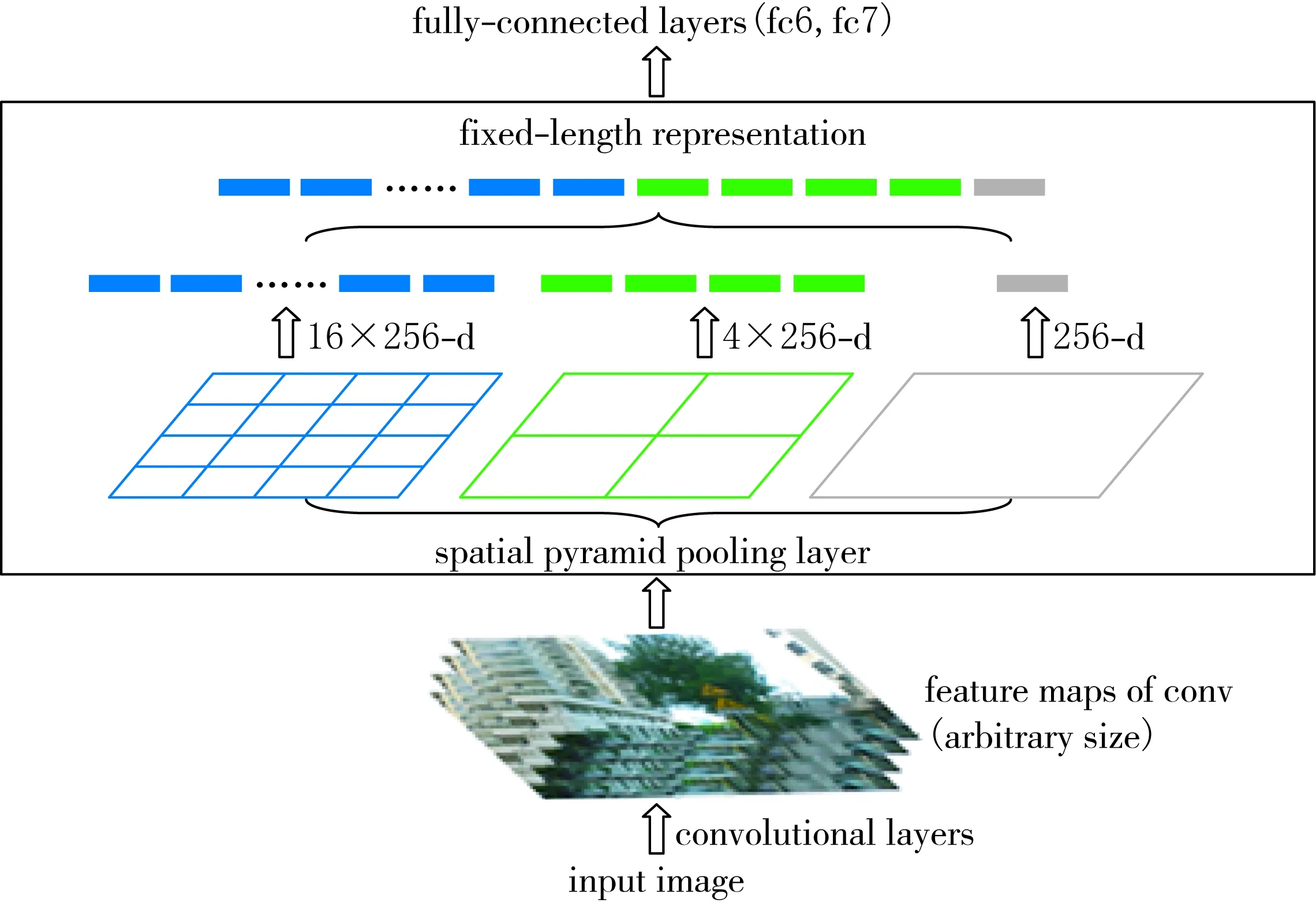
圖3 SSPNet模塊處理流程
1.4 CSPNet模塊
跨階段局部網絡(Cross Stage Partial Network,CSPNet)[11]結構在YOLO算法中最先應用于YOLOv4,CSPNet提出CSPNet是因為作者認為網絡優化中梯度重復導致算法推理速度慢,CSPNet起到的作用是將梯度變化全部集成到要處里的特征圖中,CSPNet常常用于與ResNet[12]模塊結合,這樣可以大大減少計算量,保證實驗結果的準確性.
2 改進MobileNetv3-YOLOv3網絡模型
2.1 MobileNetv3-YOLOv3
2.1.1 MobileNet模型
MobileNet系列因其檢測快速、精準度高而被廣泛應用于目標檢測,它已經成為輕量級網絡的代表.MobileNet使用的是深度可分離卷積,它相較于經典的CNN模型,其主要是將部分的全連接層來進行替換,以達到降低計算量的效果.深度可分離卷積和標準卷積結構如圖4所示.
深度可分離卷積的計算成本為
DK×DK×M×DF×DF.
(3)
逐點卷積的計算成本為
M×N×DF×DF.
(4)
深度可分離卷積與逐點卷積的計算成本為
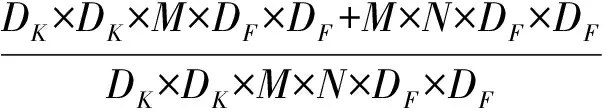
(5)
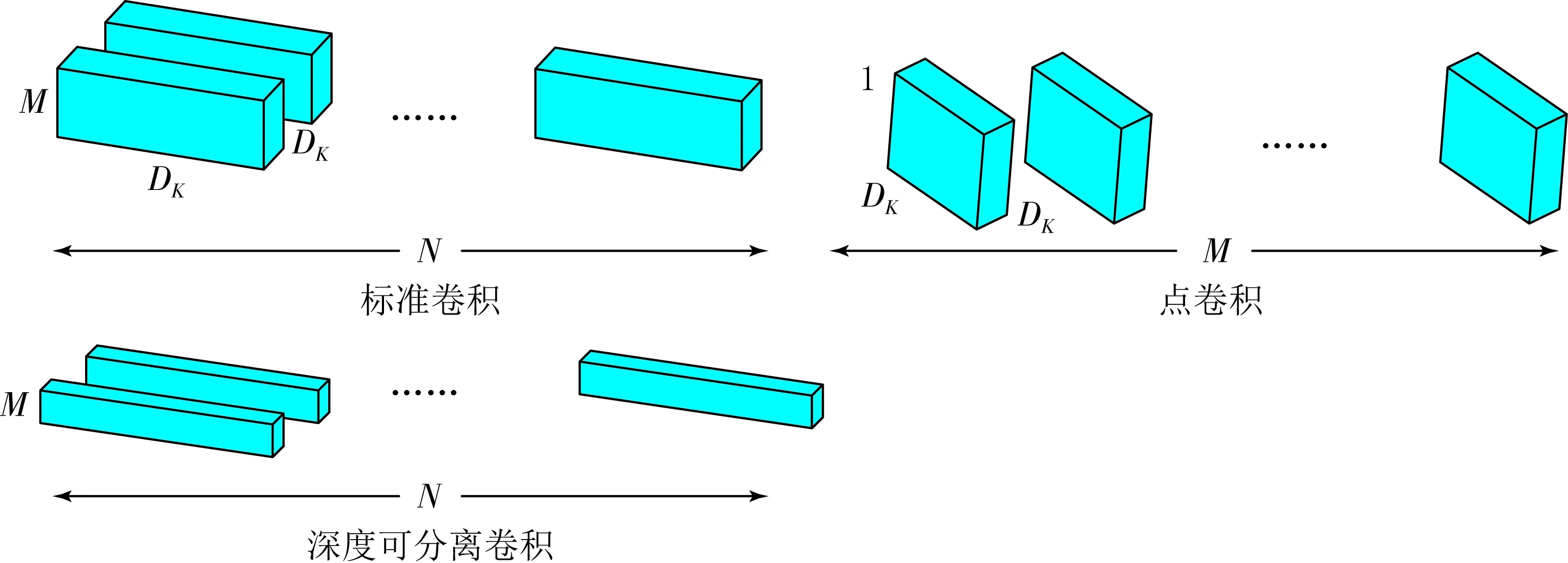
圖4 深度可分離卷積和標準卷積結構
2.1.2 MobileNetv3-YOLOv3模型
MobileNetv3-YOLOv3是將YOLOv3的骨干網絡DarkNet替換為MobileNetv3,利用了MobileNetv3的特性,保證模型為輕量型,其中MobileNetv3對多通道的3×3深度可分離卷積的卷積核進行操作,然后經過1×1的點卷積操作來完成特征圖的融合,這樣可以縮小模型的大小.MobileNetv1和MobileNetv2都具有32個濾波器的常規3×3卷積層,然而實驗表明,這是一個相對耗時的層,只要16個濾波器就足夠完成對224×224特征圖的濾波.雖然這樣并沒有節省很多參數,但確實降低了計算量,利用YOLOv3處理數據快的特性,可以加快模型的訓練速度,以達到實時處理數據的目的,MobileNetv3-YOLOv3算法流程如圖5所示.
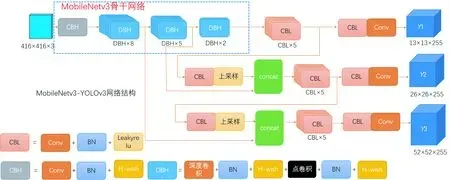
圖5 MobileNetv3-YOLOv3算法流程
2.1.3 MobileNetv3-YOLOv3模型的局限性
MobileNetv3-YOLOv3在YOLOv3的基礎上降低了計算量,但是仍然存在著一些缺點.實驗表明[9],深度可分離卷積在3×3的規模的時候,其計算量比標準卷積少了很多,使得模型的體積縮小,降低了計算量和成本,但其在大規模的特征處理中,仍然存在著特征提取不足的問題,在輸入一幀的情況下,多尺度特征圖在YOLOv3下定義為:
Fn=tn(Fn-1)=tn(tn-1(…t1(I)));
(6)
D=fn(dn(Fn),…,dn-k(Fn-k)),n>k>0.
(7)
其中:Fn表示第n層特征圖,t1(I)表示輸入圖像的第一層與特征圖之間的非線性關系,在經過一系列卷積操作后就會得到相對應n值的非線性函數的檢測結果.從以上的公式不難看出,輸入的n值不同,特征圖對應特征層的檢測結果也會發生改變,為了保證檢測結果的準確度,需要保證特征圖中每一層特征層包含的信息足夠多,MobileNetv3-YOLOv3雖然采用了深層卷積網絡,但是在特征提取的過程中,容易忽視淺層的一些特征信息,從而導致獲取到的小目標信息過少,最終檢測結果也會以顯示大目標為主要部分.從這點不難看出,MobileNetv3-YOLOv3對于小目標的檢測并不精準,而本文所要檢測的物體是交通標志牌,其屬于小目標檢測的范疇.
2.2 改進MobileNetv3-YOLOv3骨干網絡設計
MobileNetv3-YOLOv3雖然縮短了計算量,但也存在一些缺陷,對于小目標的檢測精度不高,由于分辨率低,小目標物體占用的像素低、攜帶的信息少、容易導致特征丟失,這是因為在進入MobileNetv3骨干網絡之前沒有對圖像進行預處理可能導致圖像特征的丟失,以及在處理過程中可能存在圖像失真的問題,所以本文為了解決這些問題引用了聚焦(Focus)模塊來進行圖片的預處理,用來防止圖像特征的丟失,以及引用空間金字塔池化網絡(Spatial Pyramid Pooling Network,SPPNet)防止圖像失真,引入這兩個模塊會增強了小目標檢測,但是也增加了計算量,所以最后引入跨階段局部網絡(Cross Stage Partial Network,CSPNet)消除在計算過程中產生的重復特征以及消除計算瓶頸,可以保證模型的準確率以及訓練速度,同時也能縮小模型的體積,本文算法CCTSDB數據集中與YOLOv3的比較,模型體積縮小了26%,其中YOLOv3訓練好的模型體積為123.3 MB,本文算法訓練好的模型體積為89.9 MB,改進的MobileNetv3-YOLOv3骨干網絡的結構如表1所示.
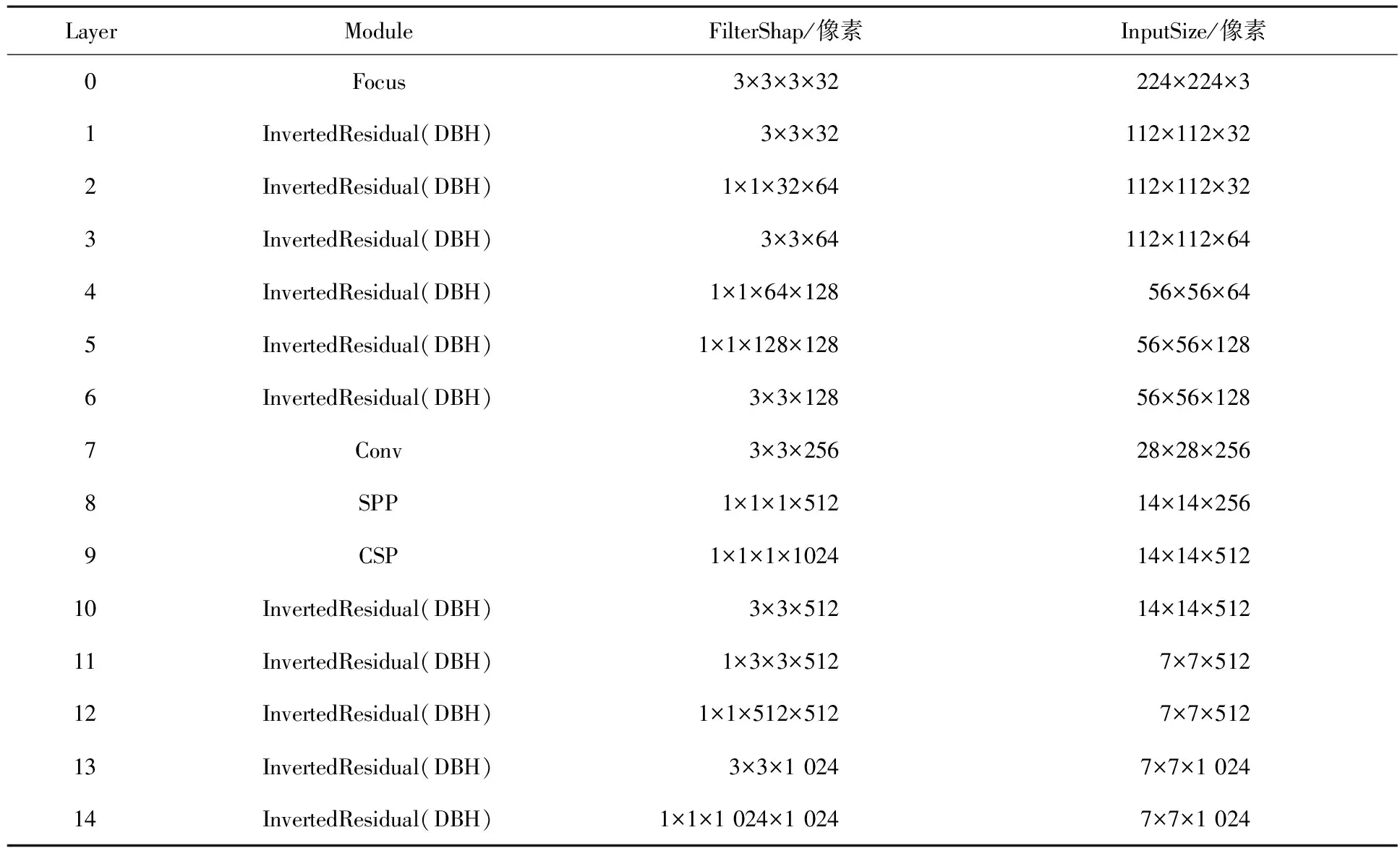
表1 改進MobileNetv3-YOLOv3骨干網絡結構
2.3 算法流程
改進的MobileNetv3-YOLOv3算法流程如圖6所示,該網絡可接受任意RGB色彩的圖像格式的輸入,然后經過聚焦(Focus)模塊的處理,對圖片進行切片操作,將圖片的每一個像素值進行下采樣處理,經過一系列卷積操作后得到沒有信息丟失的特征圖,然后將其經過深度可分離卷積的操作后,傳入空間金字池化網絡(Spatial Pyramid Pooling Network,SPPNet),可以使得特征圖轉換為與全連接層相同維度相匹配的特征向量,可以加強網絡層,更進一步確定特征圖信息的準確率,最后進入跨階段局部網絡(Cross Stage Partial Network,CSPNet)消除在計算過程中產生的重復特征以及消除計算瓶頸,達到模型的最優化.
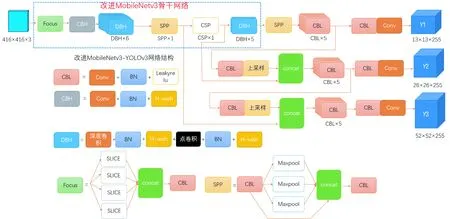
圖6 改進的MobileNetv3-YOLOv3算法流程
2.4 改進MobileNetv3-YOLOv3損失函數
改進的MobileNetv3-YOLOv3采用CIoU為損失函數.IoU表示交并比,是目標檢測的常用指標,用預測檢測框與真實檢測框進行比較,比較值越趨于1說明效果越好,越接近真實值,IoU計算公式為
(8)
IoU作為損失函數也會出現一些問題,如目標檢測框與正式檢測框沒有相交,那么IoU的值為0,不能反應兩者的重合度,同時loss的值也為0,沒有進行梯度回傳的問題,那么模型將無法進行訓練.GIoU的提出就是為了解決框值不重疊而導致無法進行梯度回傳的問題,GIoU的公式為
LGIoU=1-IoU(A,B)+|C-A∪B|/|C|.
(9)
其中:A表示預測框,B表示真實框,C是A和B的最小包圍框,但是GIoU存在著收斂速度慢的問題,因此,DIoU被提出,并且DIoU在IoU損失中增加了一個懲罰項,用來最小化兩個檢測框之間的距離,DIoU的公式為
LDIoU=1-IoU(A,B)+p2(Actr,Bctr)/c2.
(10)
其中:A表示預測框,B表示真實框,Actr表示預測檢測框中心的點坐標,Bctr表示真實檢測框中心的點坐標,p(·)表示歐式距離的計算公式.CIoU是DIoU的加強版,在DIoU的基礎上將長寬比引入進來.CIoU的損失值不在單一化,而是包含中心點的距離、長寬比以及重疊面積,其公式為:
LCIoU=1-IoU(A,B)+
p2(Actr,Bctr)/c2+αυ;
(11)
(12)
(13)
其中:A表示預測框,B表示真實框,Actr表示預測檢測框中心的點坐標,Bctr表示真實檢測框中心的點坐標,wgt和hgt表示真實檢測框的寬和高,w和h表示預測檢測框的寬和高.
3 實驗結果與分析
3.1 數據集介紹
本文所采用的數據集來自文獻[13](CSUST Chinese Traffic Sign Detection Benchmark,CCTSDB),是在2018年由文獻[5]制作完成,總共包含3大類:禁止、警告、指示,如圖7所示.為了保證結果的準確率,需要龐大的數據量的支持,該數據集有16 123張圖片,其中15 000張圖片作為訓練集,400張圖片作為測試集.

(a)禁止標志(紅色) (b)警告標志(黃色) (c)指示標志(藍色)
3.2 實驗配置
實驗是在Ubuntu18.04.4LTS系統下進行的,采用的是pytorch1.8.1深度學習框架,CUDA10.0,硬件配置為NVIDIA RTX 2080Ti顯卡,12 GB顯存.訓練時的參數配置:輸入為640×640像素比例的圖像,lr0為0.01,lrf為0.2,momentum為0.937,weight_decay為0.000 5,訓練批次為110,批量大小為12.
3.3 實驗評價指標
實驗使用多個指標來對算法進行評估,包括精確度(P),召回率(R),平均精度值(mAP)以及FPS,它們的計算過程如公式(14)—(17)所示,其中TP表示預測正確的正樣本的數量,FN表示預測失敗的正樣本的數量,p(rc)表示在召回率為rc的情況下的p值.
(14)
(15)
(16)
(17)
3.4 實驗結果
為了對本次提出的算法進行有效的驗證,本文在公開數據集CCTSDB上進行了消融對比實驗,其檢測結果如表2所示.表2列出了P,R,mAP 3種評價指標,在(CIoU取值為0.6)的情況下,對比baseline可以得出,本文所提出的算法P提升了8.6%,R值提升了0.5%,mAP值提升了3.3%.根據上述消融實驗的對比可以得出本文所提出的算法有了明確的提升,本文算法在CCTSDB數據集下的P,R,PR的曲線分別如圖8所示,測試集的測試效果如圖9所示,以YOLOv3與本文的算法對比為例,其中0表示警告類交通標志,1表示指示類交通標志,2表示禁止類交通標志,值越接近1效果越好.

表2 改進的MobileNetv3-YOLOv3在CCTSDB數據集上消融實驗結果
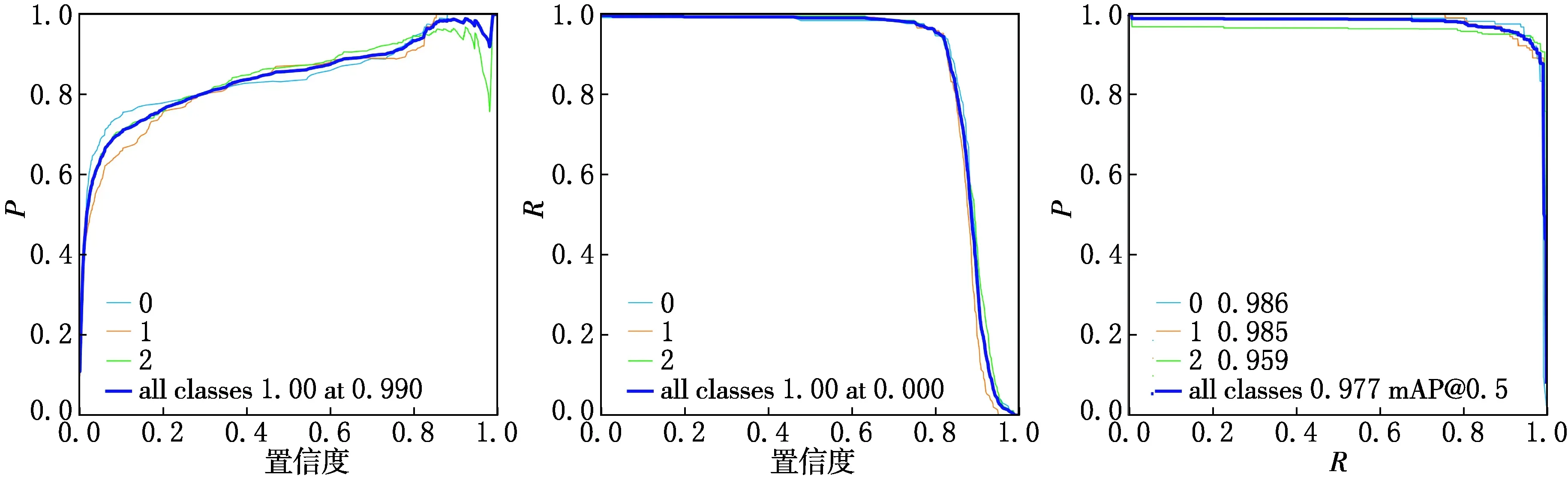
(a)P值曲線;(b)R值曲線;(c)PR值曲線

(a)YOLOv3算法1 (b)本文的算法1

(c)YOLOv3算法2 (d)本文的算法2
為了驗證本文所提出的算法的有效性,將本文的算法與最新文獻所提出的算法在CCTSDB公開數據集上進行了對比,對比結果如表3所示.從表3可以看出,YOLOv3以及T-YOLO均不是最優解,YOLOv3的準確度很低,而T-YOLO雖然準確度上升了,但是FPS卻下降到了極低的水平,根本無法滿足實時檢測的目的,改進的YOLOv3-Tiny雖然R得到最優的結果,但是最關鍵的指標mAP卻很低,無法滿足精準測量的目標,最新的算法YOLOv5s雖然FPS是最高的,但是P、R以及mAP均不如本文所提出的算法,綜上對比可知,本文的算法在交通標志牌檢測方面具有很好的效果.
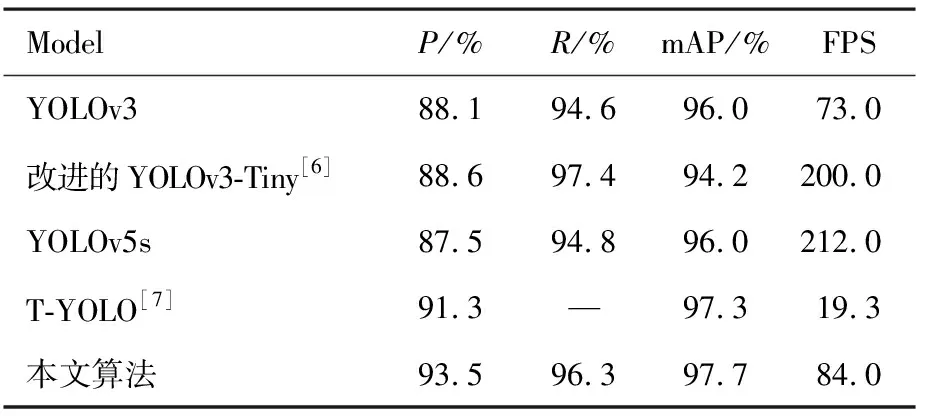
表3 不同算法在CCTSDB數據集中的表現
4 結束語
為了改進目前主流算法對交通標志牌檢測精度低、處理速度慢的問題,本文提出了改進的MobileNetv3-YOLOv3算法,引入SSPNet去除重復特征,可以提高候選框的速度,加快模型的推理速度,引入CSPNet消除計算瓶頸,節省了計算量,引入Focus層防止特征圖信息丟失,保證模型的準確度.從CCTSDB的對比實驗可以看出,本文的P以及mAP值均取得了最優的結果,與YOLOv3算法相比,本文的P、R、mAP值、FPS都得到了有效的提升,分別提升了6%,1.8%,1.8%以及15%,雖然FPS比YOLOv3以及T-YOLO高,但還不是最好的,未來還會在檢測速度方面進行提升以達到最優的效果.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
