基于概率模擬攻擊的深度魯棒圖像水印算法
2022-07-23 15:51:46溫霞,袁超
現代計算機 2022年10期
溫 霞,袁 超
(四川大學網絡空間安全學院,成都 610207)
0 引言
數字水印作為版權保護的一種重要手段,在很多應用場景下發揮著非常重要的作用。其任務是在不引入太多感知差異的情況下,將盡可能多的水印信息嵌入到載體圖像中。由于得到的含水印圖像要在網絡中傳輸,可能會受到各種各樣的外部攻擊,所以便要求即使在含水印圖像存在一定失真的情況下,水印算法也能夠準確地將嵌入的水印信息提取出來。傳統的圖像水印算法主要是通過手工設計的方法來選擇嵌入信息的位置,根據嵌入域的不同,可分為空域水印算法和變換域水印算法。空域水印算法是在像素域中進行的,典型的空域水印算法有最低有效位算法(LSB)和Patchwork算法。變換域水印算法將載體圖像從空域轉換到變換域上,通過修改變換域系數來嵌入水印信息,典型的變換域水印算法有基于離散小波變換(DWT)、離散余弦變換(DCT)以及基于多變換域的水印算法。但是這兩種算法都需要人為設計嵌入和提取方式,過程比較復雜,且這些算法嵌入水印信息的容量都較低。
近年來,隨著深度學習技術在各個領域的成功應用,一些基于深度學習的水印算法也相繼出現,并且取得了很好的效果。2017年,Kandi等首次提出基于深度學習的非盲水印算法。2018年,Zhu等提出了一個名為HiDDeN的編解碼框架,可用于數字水印和隱寫術,其利用對抗訓練來提高水印系統的性能。2019年,Zhang等提出了一種高容量圖像信息隱藏技術SteganoGAN,能夠達到更高的嵌入容量的同時也能避免隱寫分析器的檢測。2020年,Zhang等提出了通用深度隱藏(UDH)框架,這種通用框架可以用于隱寫、水印以及LFM,其編碼器的輸入只與秘密信息有關,并取得了很好的性能。與傳統水印相比,基于深度學習的水印算法能通過具有擬合能力的神經網絡自動地學習水印的嵌入和提取。此外,基于深度學習的水印算法能取得較高的容量和不可感知性。但目前,大多數基于深度學習的水印算法在魯棒性上仍有較大提升空間。
為了解決這個問題,本文提出了一種基于概率模擬攻擊的深度魯棒圖像水印算法。該算法主要包括四部分,分別是生成器、判別器、解碼器和模擬攻擊層。生成器負責生成含水印圖像,判別器負責與生成器進行對抗訓練來提高含水印圖像的視覺質量,解碼器負責從含水印圖像中提取水印信息,而模擬攻擊層則負責模擬噪聲和幾何攻擊來提高水印魯棒性。為了模擬常見的外部攻擊并使其在訓練過程中可進行梯度的反向傳播,本文設計了不同的可微模擬攻擊加入訓練,并根據訓練過程中含水印圖像對攻擊的抵抗性能來動態調整不同模擬攻擊出現的概率,從而讓含水印圖像能逐漸對不同的外部攻擊時獲得較強的魯棒性。
1 本文方法
1.1 整體框架
圖1給出了本文提出算法的整體框架。如圖1所示,整個框架由生成器、解碼器、判別器、模擬攻擊層組成。將水印信息重塑(reshape)到和載體圖像I 相同的大小,然后與載體圖像I 一起送入生成器,將生成器的輸出結果與原載體圖像相加之后就得到了含水印圖像I 。為了保證含水印圖像I 的魯棒性,本文設計了一個模擬攻擊層來模擬含水印圖像在網絡中傳輸時可能遇到的攻擊。含水印圖像經過模擬攻擊層后得到噪聲圖像I ,再將I 送入解碼器來提取水印信息,將提取到的水印信息記為’。同時,為了保證噪聲圖像I 也有比較好的視覺質量,本文將載體圖像與噪聲圖像送入判別器C進行判別,通過生成器和判別器的相互博弈,使載體圖像與噪聲圖像無限接近。
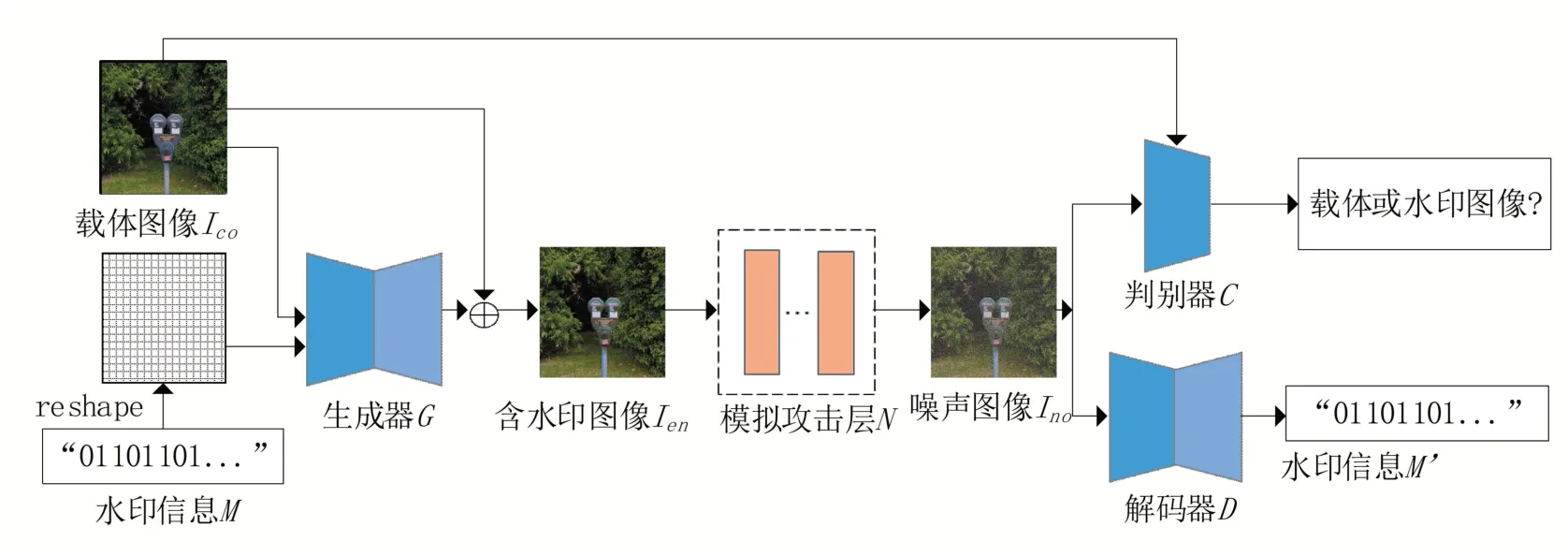
圖1 本文提出算法的總體框架
1.2 模擬攻擊層
在本文的算法中,將含水印圖像I 可能受到的各種攻擊模擬為網絡層并加入整體框架中,以便本文的水印模型能進行端到端的訓練。通過在循環訓練中保持模擬攻擊就可以促使本文的算法學習更為魯棒的水印模型,這樣就可以抵抗含水印圖像在通信信道傳輸時可能受到的真實攻擊。如果使用特定的攻擊,那訓練得到的網絡模型能生成對特定攻擊更為魯棒的含水印圖像,但對其他攻擊的抵抗性能很差。所以為了能使本文的水印模型可以同時抵抗更多種類的攻擊,本文設計了一個同時具有多個模擬攻擊的網絡,在迭代訓練時,網絡模型將按照一定的概率選擇具體使用哪種攻擊。圖2給出了這種同時具有多個模擬攻擊的混合攻擊層示意圖。
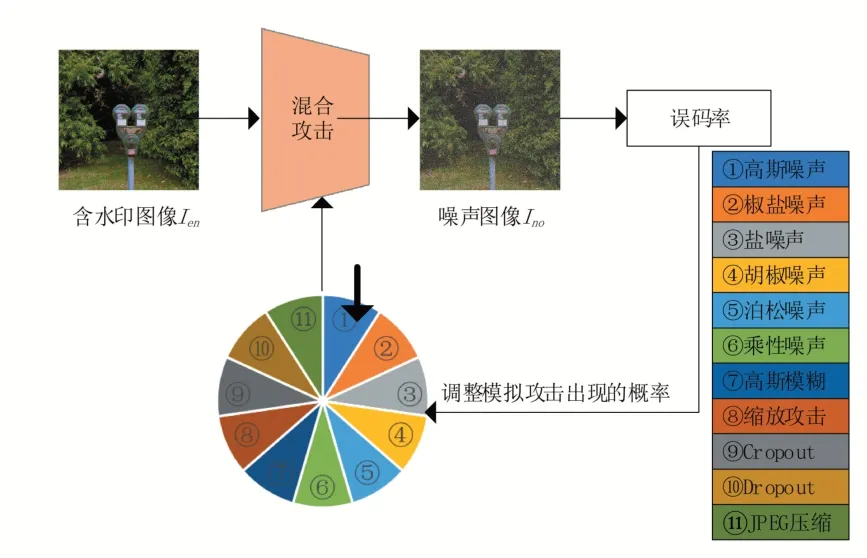
圖2 按概率進行模擬攻擊的混合攻擊層(第一個epoch)
如圖2所示,本文所用到的攻擊包括11種不同強度的攻擊:高斯噪聲(標準差=3),椒鹽噪聲(比例=10%),鹽噪聲(比例=10%),胡椒噪聲(比例=10%),泊松噪聲,乘性噪聲(標準差=0.1),高斯模糊(高斯核寬度=3),縮放攻擊(比例=50%),Cropout(比例=30%),Dropout(比例=30%)以及JPEG壓縮(品質因子=50)。JPEG是一種常見的圖像有損壓縮標準,由于其中包含不可微分的量化步驟,所以本文需要通過模擬JPEG壓縮,將其用于深度水印模型中來獲得關于實際JPEG壓縮的魯棒性。本文使用Zhu等提出的JPEGMask,通過舍棄高頻系數,保留一定數量的低頻系數產生對實際JPEG壓縮魯棒的模型。使用模擬攻擊層對含水印圖像進行攻擊的具體步驟如下:
(1)當進行第一個epoch時,對于其中的每次迭代,按相等的概率來隨機選擇一種攻擊進行訓練。
(2)第一個epoch訓練完成后,在驗證集上計算含水印圖像在每種攻擊下提取水印信息的誤碼率()。
(3)根據每種攻擊的BER值來動態調整選擇每種攻擊的概率,之后再進行下一個epoch。
1.3 損失函數
生成器的目的是將水印信息嵌入到載體圖像中的同時使得到的含水印圖像保持良好的視覺質量,所以其損失由圖像間像素值的均方誤差(MSE)來表征。本文使用L 來表示其損失,如公式(2)所示:
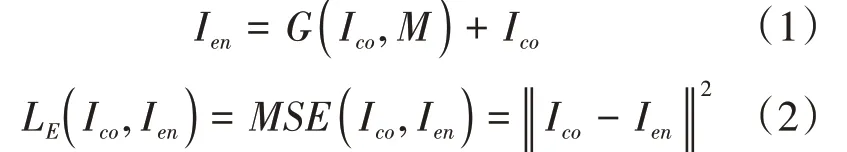
其中,I 為載體圖像,I 為含水印圖像。對于對抗訓練來說,生成器的目的是生成使判別器難以分辨的含水印圖像。本文用1表示真實圖像標簽,0表示生成圖像標簽。生成器期望噪聲圖像I 能夠被判別器判別為真實的載體圖像,也就是說希望判別器的輸出接近1。用L 來表示其損失,如公式(4)所示:
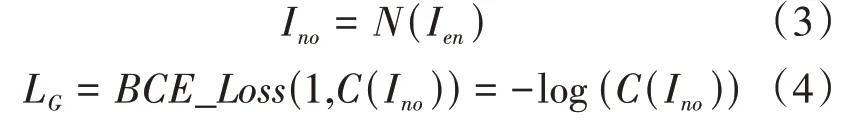
其中,I 是含水印圖像被模擬攻擊層攻擊后得到的噪聲圖像。對于解碼器來說,解碼的水印信息應該與編碼的水印信息相同,所以其損失由原始水印信息和解碼水印信息之間的交叉熵計算得到。該損失用L 表示,如公式(5)所示:
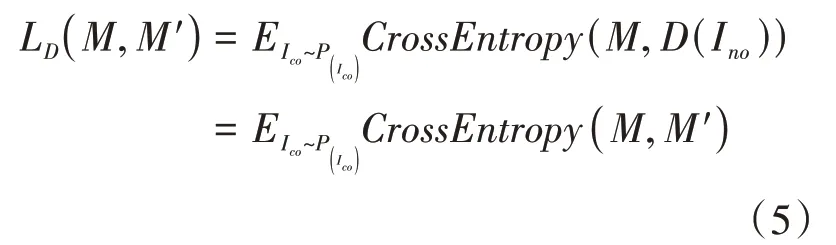
對于生成器和解碼器來說,本文通過最小化損失來訓練,如公式(6)所示:
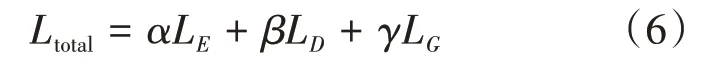
本文使用二值交叉熵(BCE)來計算判別器的損失。我們期望判別器能將載體圖像I 判別為真實圖像,即判別器的輸出接近1;將噪聲圖像I 判別為生成的虛假圖像,即判別器的輸出接近0。本文用L 表示其損失函數,如公式(7)所示:
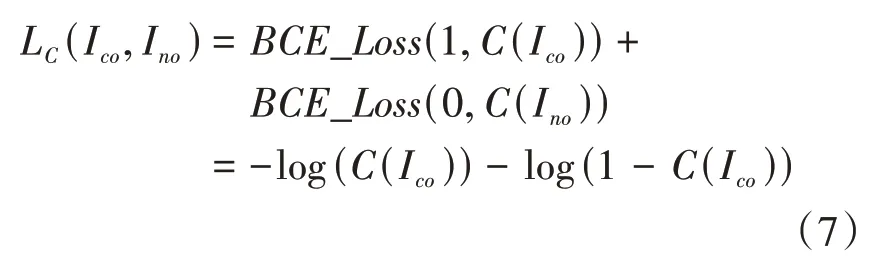
2 實驗結果
2.1 實驗設置
本文的實驗數據集采用MS COCO數據集,將RGB圖像的大小調整為256×256,使用隨機選擇的12000張圖片,其中8000張作為訓練集,2000張作為驗證集,2000張作為測試集。使用=256×256比特表示水印消息的大小。本文提出的框架由Pytorch實現,初始學習率設置為1e-4,學習率衰減使用指數衰減,批大小設置為16,本文使用Adam來優化本文的模型,總共訓練100個epoch。經過多次嘗試,本文將損失函數的、和分別設置為1.0、0.02和0.002,這樣可以很好地兼顧含水印圖像的視覺質量以及提取水印信息的準確率。
2.2 評價指標
對于不可感知性,本文使用載體圖像和含水印圖像之間的峰值信噪比(PSNR)和結構相似性(SSIM)來衡量。對于魯棒性,可以用提取的水印信息的準確性來衡量,提取的水印信息與原始水印信息越接近,則表明該水印算法的魯棒性越好。本文使用BER來評價提取的水印準確性,如公式(8)所示:
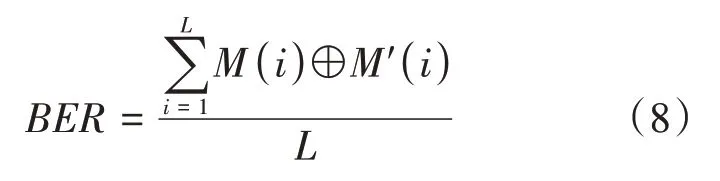
其中,()和()分別表示原始水印信息和提取的水印信息,符號⊕表示異或操作,表示水印信息的總比特數。準確地表示了水印信息嵌入前后比特不同的概率,的值越接近于0,提取出的水印信息錯誤率越小,說明水印魯棒性越強。
2.3 不可感知性評估
本節對模型生成的含水印圖像的不可感知性進行了評估。圖3顯示了本文模型的定性結果,可以看到載體圖像和含水印圖像之間沒有明顯的差異,也不太容易在圖像的平坦區域產生小的偽影。出于可視化的目的,將原始載體圖像和含水印圖像之間的殘差放大10倍,從放大后的殘差圖可以看出,本文模型生成的含水印圖像的失真較小。

圖3 本文模型不可感知性的定性結果
為了定量地評估含水印圖像的不可感知性,本文計算了載體圖像和含水印圖像之間的和。具體結果如表1所示。從表1可以看出,本文方法的值超過了35 dB,值也達到0.966,表明本文的方法具有良好的不可感知性。

表1 SteganoGAN、UDH以及本文模型的不可感知性對比
2.4 對比實驗
為了證明本文方法的優勢,本文與兩個基于深度學習的圖像水印算法SteganoGAN和UDH進行比較,其中SteganoGAN算法選取其中表現最好的模型Dense。為了公平比較,本文使用MS COCO數據集中相同的8000張圖片進行訓練,2000張圖片進行測試,并且將測試條件與隱藏條件相匹配,即在256×256 RGB彩色圖像中嵌入=256×256位隨機水印。圖4給出了這三種算法得到的含水印圖像I 以及被噪聲攻擊后得到的噪聲圖像I 的可視化結果。

圖4 三種模型生成的含水印圖像受到不同攻擊后的視覺質量
如圖4所示,SteganoGAN生成的含水印圖像被高斯噪聲和乘性噪聲攻擊之后產生了明顯的噪點。而UDH生成的含水印圖像I 本身就存在明顯的噪點,并且其被高斯噪聲和乘性噪聲攻擊之后的噪點增加了。但是本文模型生成的含水印圖像在平坦區域沒有明顯的噪點和偽影,并且被高斯噪聲和乘性噪聲攻擊之后也沒有明顯的噪點。也就是說,本文的模型生成的含水印圖像以及被攻擊后得到的噪聲圖像的視覺質量優于其他兩個模型。表1給出了定量的比較結果,從表1可以看到,本文模型的值和與SteganoGAN相當,都優于UDH。在魯棒性的定量比較上,如表2所示,本文的模型在沒有噪聲攻擊時的誤碼率略高于其他兩個模型,但對于大部分的攻擊,尤其是高斯模糊和縮放攻擊,其誤碼率都低于其他兩個模型。這表明本文的模型在保證良好的不可感知性的前提下,能夠抵抗更多種類的攻擊,并且在絕大部分外部攻擊下,模型的魯棒性都強于其他兩個模型。但實際上,從表2可知,三個模型都不能很好地抵抗Cropout和JPEG壓縮攻擊。
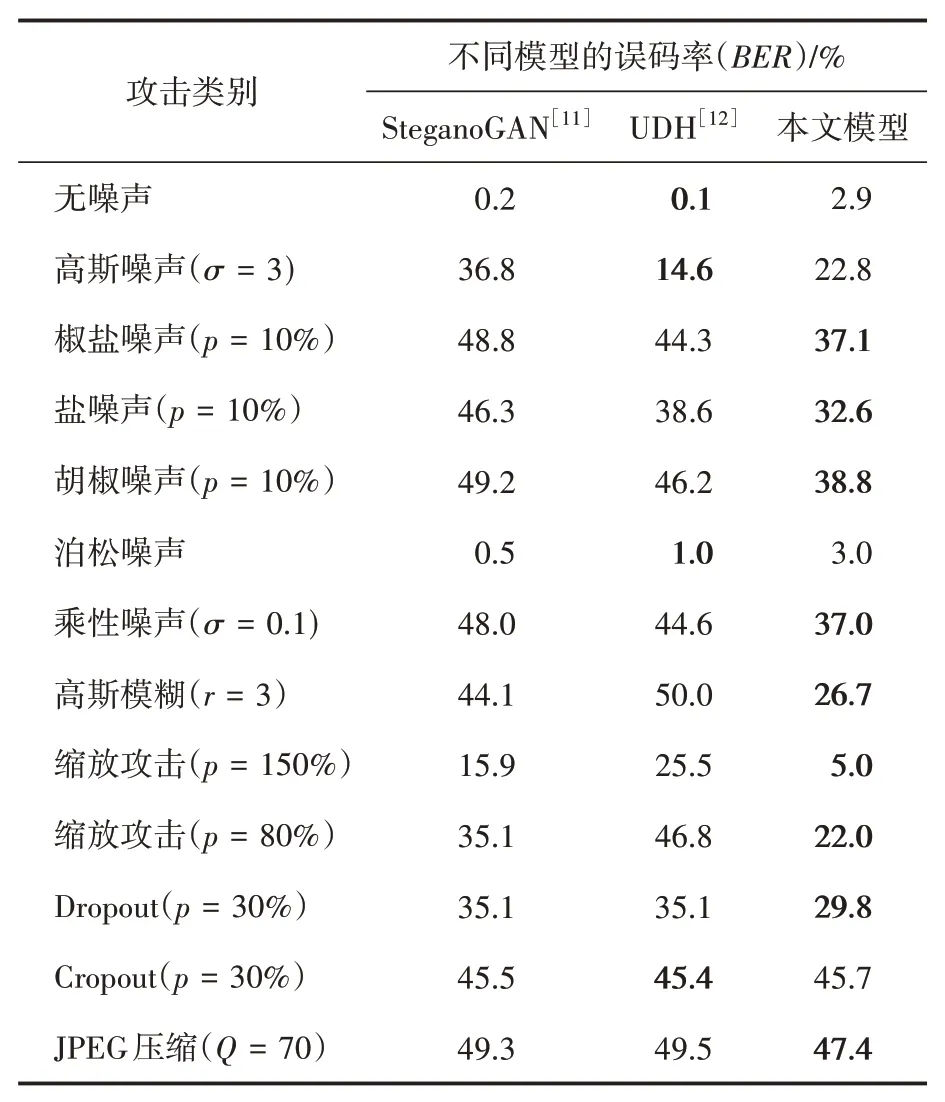
表2 SteganoGAN、UDH以及本文模型的不可感知性對比
2.5 消融實驗
為了探究本文框架中的模擬攻擊層對最終水印嵌入效果的貢獻,本文進行模擬攻擊層的消融實驗,其中模擬攻擊層中有一個noise_pro字典用于控制選擇每種攻擊的概率。本文在MS COCO訓練數據集上訓練了兩個額外的模型:
模型①:沒有模擬攻擊層的基本框架;
模型②:基本框架加上模擬攻擊層,但noise_pro中的概率不變;
完整模型:基本框架加上模擬攻擊層,noise_pro中的概率動態變化。
實驗結果如表3所示,從模型①、②的實驗結果可以看出,加入模擬攻擊層使得模型對外部攻擊的魯棒性明顯增強,而noise_pro中概率的動態變化會促使模型對多種攻擊同時產生較強的魯棒性。
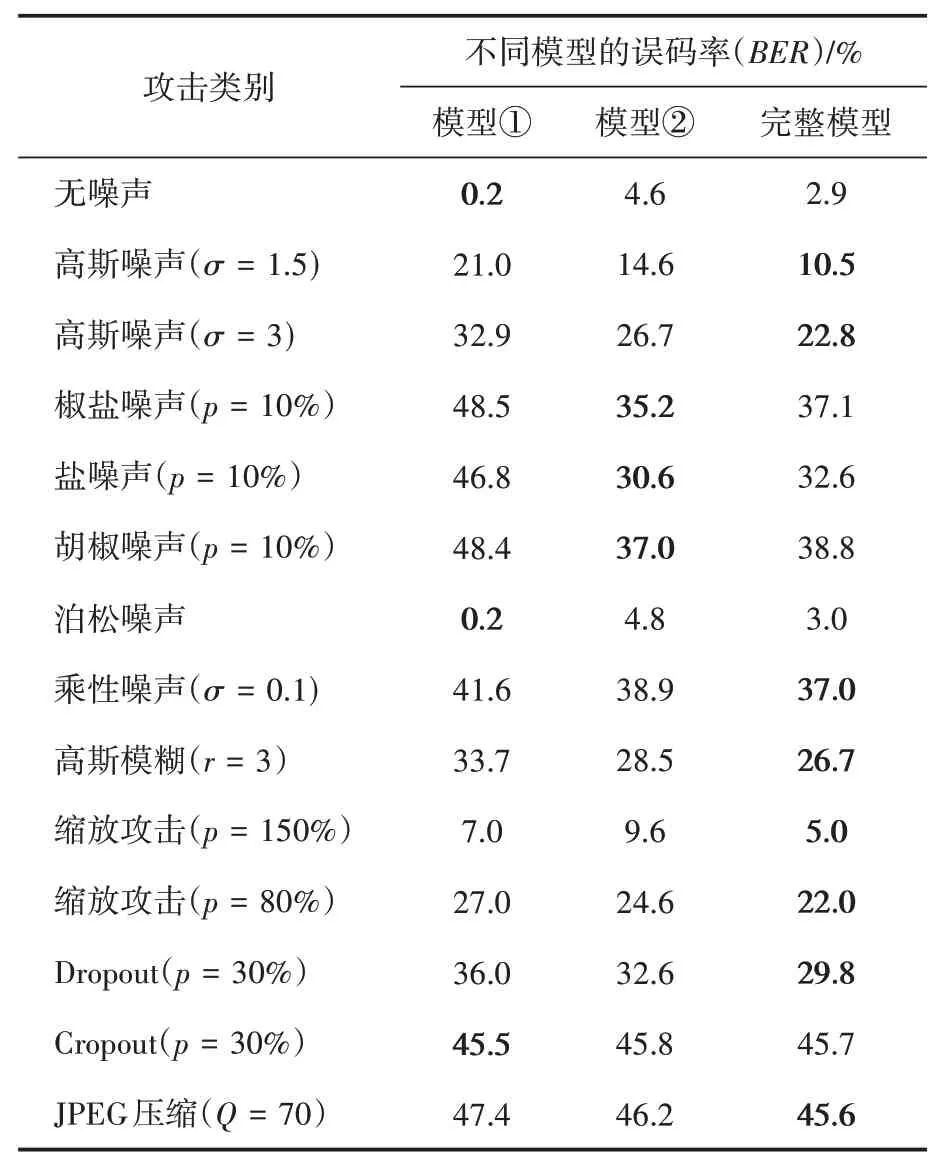
表3 本文模型消融實驗結果
3 結語
本文提出了一種基于概率模擬攻擊的端到端的深度魯棒圖像水印算法,該算法通過模擬攻擊使得含水印圖像逐漸產生對噪聲和幾何攻擊的魯棒性,并通過誤碼率來動態調整模擬攻擊出現的概率,使得模型能同時對多種攻擊產生魯棒性。本文的算法可以有效地將水印信息嵌入到載體圖像中,通過實驗評估,本文的水印模型在保證含水印圖像不可感知性的同時,能對多種攻擊產生較強的魯棒性。將來的研究將圍繞如何更好地模擬JPEG壓縮以及進一步增強抗Cropout和JPEG壓縮的魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
