基于AP-SVM混合分類的指紋定位算法優化*
2022-07-15 13:15:18毛永毅
傳感器與微系統 2022年7期
關鍵詞:分類
毛永毅, 呂 丹
(西安郵電大學 電子工程學院,陜西 西安 712000)
0 引 言
近年來,隨著人類生活方式和需求的不斷更新,室內已成為人們工作活動的主要場所,室內精確定位的需求也愈來愈強烈。當前主流的室內定位技術包括有:紅外線[1]、藍牙[2]、超寬帶(ultra wideband,UWB)[3]、射頻識別(radio frequency identification,RFID)[4]、無線保真技術(wireless fidelity,WiFi)[5]等。WiFi定位技術是一種在辦公室和家庭中使用的短間隔無線技術,使用2.4 GHz左右的頻段[6],具有傳輸速度快、傳播穩定等優勢,并且價格低廉,方便搭建,能夠在日常生活中廣泛使用,因此該項技術一直是室內定位技術研究中的熱點[7,8],眾多學者對其進行了深入研究,進一步促進了WiFi室內定位技術的發展。
文獻[9]提出一種基于指紋數據物理位置關系對指紋數據分級的方法,通過數據分級縮小數據匹配范圍提高匹配效率,同時提高定位精度。文獻[10]提出基于支持向量機(support vector machine,SVM)的混合相似度加權K最近鄰(mixed similarity weighted K nearest neighbor,MWKNN)算法,即SVM-MWKNN通過建立多相似度指標,可以有效提高數據利用率,減少定位誤差,定位精度提高達45 %。文獻[11]提出一種基于奇異值檢測和親和力傳播(affinity propagation,AP)聚類的無線局域網指紋定位算法,通過AP聚類粗檢測和基于加權K近鄰算法的細檢測評估得到用戶位置,完成定位。
本文提出了基于黃金分割法掃描AP聚類算法中的偏向參數P的范圍的方法—GAP-SVM混合分類算法。首先應用優化后的AP聚類算法即GP-AP聚類算法優化樣本數據集,得到具有代表性的高質量的數據作為SVM分類器的訓練集,然后結合SVM模型,提高分類精度,進而提高了WiFi位置指紋定位技術的準確度和穩定性。
1 AP-SVM相關
1.1 AP聚類算法
AP聚類算法是由Frey和Dueck提出的一種新的無監督學習方法[12]。AP聚類不需要預先指定聚類數,所有數據點在啟動時都視為機會均等的候選聚類中心點,通過節點之間的通信找到最合適的聚類中心和相應的聚類數,與此同時也會淘汰質量低的候選聚類中心。經過對數據信息進行綜合判斷,將非聚類中心點歸屬到相應的類別中進行聚類。AP聚類算法通過反復迭代不斷調整每個點的吸引度和歸屬度值,直到產生高質量的簇中心,并將其他的數據點分配到相應的簇。AP聚類算法使用S(i,k)來表示數據點Xk在類代表點中適合數據點Xi的程度,為每個數據點k設置偏移參數S(k,k)值,S(k,k)值越大,越有可能選擇對應的點k作為類代表點。AP聚類算法的初始假設是選擇所有數據點成為類代表點的可能性相同,即所有S(k,k)值與P值相同,同樣,P值的大小也會影響最終聚類的類數。這是AP聚類算法的一個重要參數。
AP聚類算法兩個重要的信息內容參數:吸引矩陣R=[R(i,k)]n×n和歸屬矩陣A=[A(i,k)]n×n。R(i,k)為數據對象Xk適合作為數據對象Xi的聚類中心的程度,A(i,k)描述了數據對象Xi選擇數據對象Xk作為其聚類中心的適合程度。AP聚類算法的迭代過程是交替更新兩個信息內容的過程,兩種信息內容代表不同的競爭目的。更新公式如下
R(i,k)←S(i,k)-maxk′s,t,k′≠k{A(i,k′)+s(i,k′)}
(1)
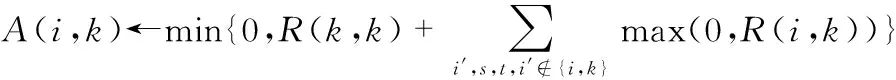
(2)
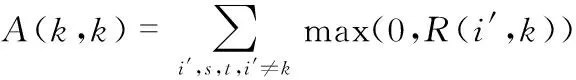
(3)
通過迭代,樣本點競爭得到具有代表性的點,即聚類中心。最后,可以確定集群中心的數量是否滿足要求,如果不是,再次調整P和集群的大小,直到集群的數量滿足要求。
1.2 SVM
SVM是一種有監督的分類識別方法[13]。在D維空間中輸入兩類數據,選取i個訓練樣本,(xi,yi),i=1,…,l,x∈Rn,y∈{+1,-1},利用SVM在空間中構造一個超平面wx+b=0來區分兩類數據(w表示超平面法向量,b表示超平面的偏置),使得超平面與兩類數據邊界的距離最遠。所有的訓練樣本都滿足以下條件
yi(wix+b)-1+ε≥0,εi≥0,i=1,…,l
(4)
非線性情況下,SVM的基本思想:通過一定的非線性函數將訓練樣本從原始輸入空間映射到高維特征空間,在高維特征空間中構造最優分類超平面,使訓練樣本在高維空間中按線性維函數進行分類。線性不可分的情況下,有一些樣本不能被最優分類面正確分類,因此,可以引入松弛變量ε來允許誤分類,εi≥0,i=1,…,l。在非線性可分的情況下,利用映射函數φ將輸入向量x映射到高維特征空間Z,在該空間找到一個最優的分類器。最大化SVM邊界等價于求解如下優化問題
(5)
約束條件為
yi[(w·xi)+b]-1+ε≥0,εi≥0,i=1,…,l
(6)
優化問題可以轉換為
(7)
約束條件為
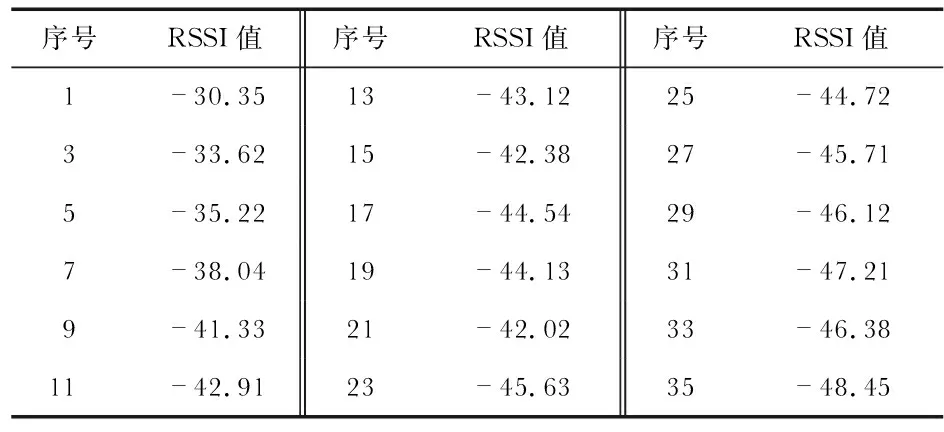
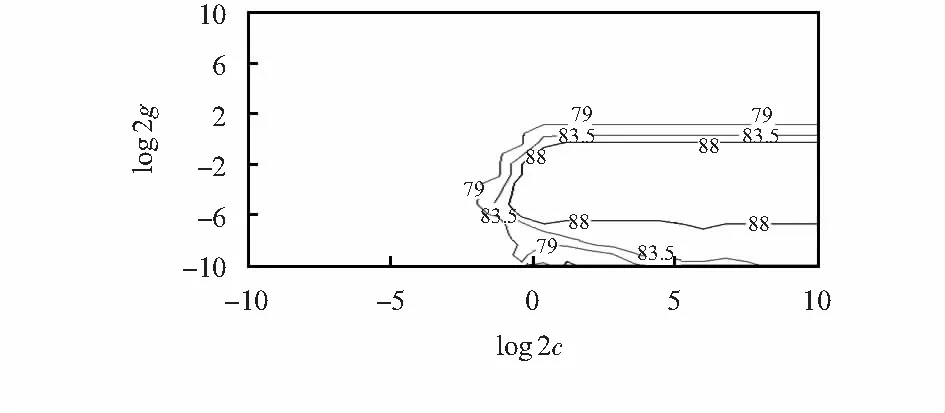
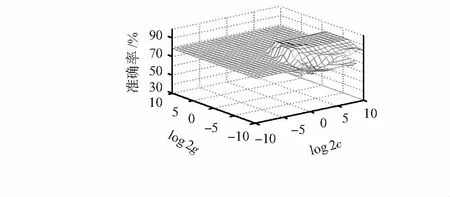
∑yiαi=0,0<αi (8) 該模型由兩部分組成,分別為AP聚類算法和SVM,基本思路:利用AP聚類算法對數據集進行初始聚類,并從聚類結果中選擇具有代表性的樣本訓練SVM分類器,然后將所有數據交給SVM分類器。因此,如何選擇合適的訓練樣本,將會直接影響SVM分類器的生成和最終的分類結果。 混合分類過程包括以下三個部分:1)AP聚類算法初始聚類:輸入采集到的數據后,AP聚類算法在開始時默認所有數據點均是聚類中心,根據N個數據點之間的相似度進行聚類;2)訓練樣本的選擇:AP聚類后,得到初始類,然后選擇類別中心及相似度較大的數據點作為訓練樣本;3)訓練SVM分類器。 AP聚類算法中,偏向參數P值直接影響聚類數目,P值增大,聚類數目增多。傳統的AP聚類算法中,P值選擇N個樣本點相似度的均值Pm。本文提出一種黃金分割法掃描AP聚類算法中的偏向參數P的范圍的方法—GAP,以期得到更好的聚類效果,產生更高質量的訓練樣本,再將GAP與SVM結合,形成GAP-SVM算法。 算法思路如下:第一次,確定偏向參數P的掃描范圍[PminPmax],在區間內取兩個點P1,P2,將[PminPmax]分為3段。P1=Pmin+0.382(Pmax-Pmin),P2=Pmin+0.618(Pmax-Pmin),通過計算對應的Silhouetter指標S1和S2,來決定去掉一部分區間,若S1 GAP的具體步驟如下: 1)取N個樣本點相似度的最小值和平均值,分別為Pmin和Pm,經驗證,偏向參數初值取Pm/2,可以得到不錯的聚類效果。因此,偏向參數P的范圍取[PminPmax],初值取Pm/2。變量參數說明如表1; 2)AP聚類算法進行一次循環,產生K個聚類; 3)判斷AP聚類算法是否收斂,(收斂條件是聚類數目K,滿足預先設定的連續不變次數),若收斂,則轉至步驟(5),否則,執行步驟(3); 4)計算P1,P2對應的Silhouette指標,分別為S1,S2,若S1 5)輸出最后一次迭代的聚類結果和P*及對應的S*,P*=(Pmin+Pmax)/2。 表1 變量參數說明 位置指紋庫定位是基于信號接收強度指示(RSSI)的定位方法,利用信號強度特征數據來推斷待定位點的物理位置坐標。定位過程包括兩個階段,分別是離線階段和在線階段。 離線階段:將定位區域進行合理均勻地劃分,并且合理選擇接入點(AP)的位置和數目,根據每個AP無線信號的覆蓋范圍和定位精度的需求,在劃分后的每個區域進行參考點設立,參考點的密度通常控制在2 m以內。在每個參考點位置處采集信號的RSS值等特征數據。將采集到的數據首先利用GP-AP聚類算法進行初始聚類,并從聚類結果中選擇高質量樣本訓練SVM分類器,對數據進行準確的分類,建立位置指紋數據庫(包括RSSI值及所在區域的物理位置坐標)。 在線階段:對待定位點進行信號采集,將實時獲取的RSSI與相對應的物理位置坐標作為測試集,輸入到GAP-SVM模型中,進而模型對指紋展開合理的分類,最后得到待定位點的物理位置坐標。定位模型如圖1所示。 圖1 定位模型 本文利用GAP-SVM分類與預測來實現室內定位,在實驗區域中采集數據并進行訓練,得到包含位置信息的指紋庫。在定位過程中,通過對待定位目標進行RSSI特征數據采集, 將獲得的數據信息與指紋信息庫展開匹配,從而完成目標位置的估計。 實驗環境如圖2所示。選擇已知位置坐標的8個AP進行安裝,采集數據過程中,在每個采樣點,使用移動設備來獲取AP的RSSI值,然后利用迭代法得到設備的坐標。在每個參考點處,采集各個AP在5 min內接收到的RSSI值,每5 s進行一次信號采集,一共采集了60次,該參考點指紋信息向量通過計算這60次RSSI值的平均值獲得。為了檢驗本文所提算法的定位效果,選取最近鄰(nearest neighbor,NN)算法,K最近鄰(K-nearest neighbor,KNN)算法,加權K最近鄰(weighted K-nearest neighbor,WKNN)算法[14,15]以及AP-SVM進行比對。 圖2 實驗環境 表2 采集到的部分RSSI值 dB SVM訓練模型中的兩個主要參數:懲罰參數C和核函數參數g[16],這兩個參數的取值,通常采用網格搜索的交叉驗證(cross validation,CV)方法進行參數尋優,最終選擇分類準確率最高的一組參數。但在實驗過程中,分類準確率最高的同時可能會存在多組匹配的參數,因為C太高會產生過學習現象,所以通常會選擇懲罰參數C最小的一組,同時,由于C值不同,也可能會有與C值所對應的不同的g值出現,此時一般選擇搜索到的第一組參數。 圖3、圖4分別為精選范圍內參數網格搜索法尋優的等高線圖與3D視圖,得到參數最優組合為0.758和0.027,訓練集的正確分類識別率最高近似達91.59 %。 圖3 參數尋優(等高線圖) 圖4 參數尋優(3D視圖) 圖5是利用CV法得到的實際—預測分類圖,確定了SVM模型中C和g,對測試集數據進行預測,最終將預測分類結果正確率提高到92.21 %,提升效果明顯。 圖5 測試集的實際分類和預測分類 圖6是在不同信號強度下,各個算法的定位準確率。隨著信號強度增強,GAP-SVM定位準確率提高明顯,較傳統的NN,KNN,WKNN,AP-SVM效果好,GAP-SVM與AP-SVM相比,定位準確率提高了46 %。 圖6 不同信號強度下各種算法的定位精度 本文基于黃金分割法的理論提出了新的算法GP來尋找AP聚類算法最優的P值,得到了更好的聚類結果,從而得到了更高質量的SVM的訓練集,再將GAP與SVM相結合,利用設計出的基于GAP-SVM模型的位置指紋定位整體系統架構,通過仿真實驗,驗證了新算法GAP-SVM相較于傳統算法AP-SVM具有更高的定位準確率。1.3 AP-SVM
2 GAP-SVM相關
2.1 GAP-SVM算法

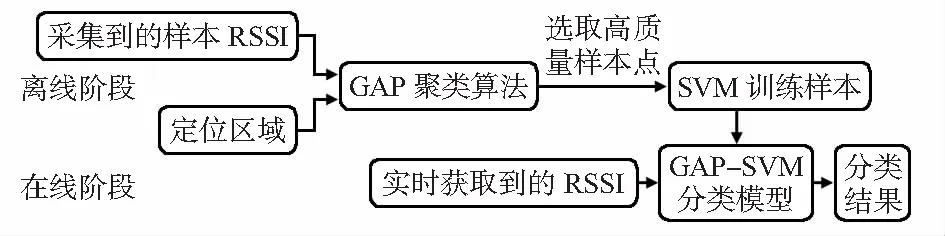
2.2 基于GAP-SVM位置匹配定位模型
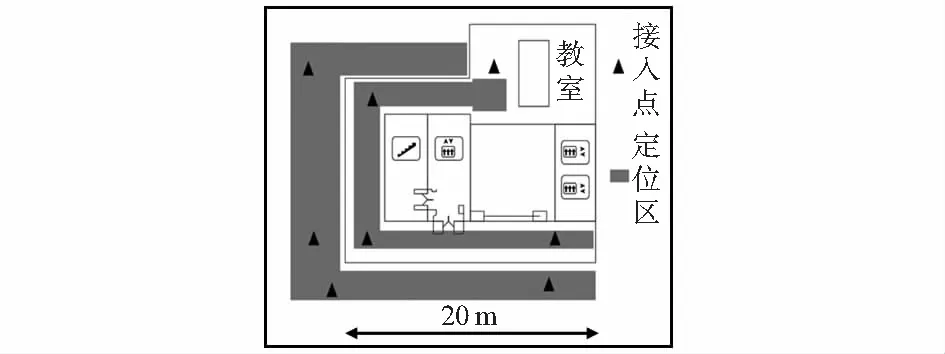
3 實驗結果與分析
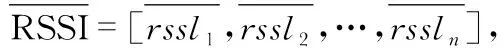
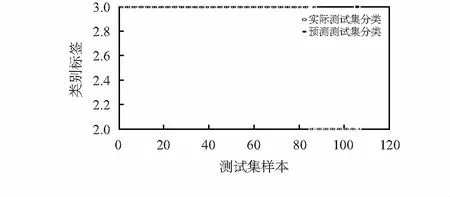
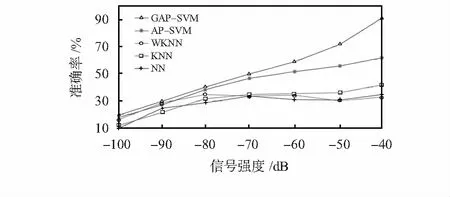
4 結 論
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56大眾健康(2021年6期)2021-06-08 19:30:06小聰仔(科普版)(2020年12期)2021-01-18 09:16:52東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10學生天地(2019年32期)2019-08-25 08:55:22中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56初中生世界·七年級(2017年9期)2017-10-13 22:27:46
