基于神經(jīng)元正則和資源釋放的增量學(xué)習(xí)
2022-07-08 01:50:06莫建文朱彥橋袁華林樂(lè)平黃晟洋
莫建文 朱彥橋 袁華 林樂(lè)平 黃晟洋
(桂林電子科技大學(xué) 信息與通信學(xué)院,廣西 桂林 541004)
快速適應(yīng)環(huán)境變化的能力是衡量深度學(xué)習(xí)模型性能的重要指標(biāo)之一,但一般的深度學(xué)習(xí)模型往往缺乏這樣的能力。當(dāng)它們不能一次性地訪問(wèn)所有訓(xùn)練數(shù)據(jù),而只能按順序處理分布在變化的連續(xù)數(shù)據(jù)時(shí),它們會(huì)在反向傳播過(guò)程中調(diào)整學(xué)習(xí)到的參數(shù)以適應(yīng)新的數(shù)據(jù),從而遺忘了先前學(xué)習(xí)到的知識(shí),這樣的現(xiàn)象可稱(chēng)為災(zāi)難性遺忘。克服災(zāi)難性遺忘是當(dāng)今人工智能領(lǐng)域的重點(diǎn)和難點(diǎn)之一[1]。目前,克服災(zāi)難性遺忘問(wèn)題的方法主要分為3類(lèi):基于樣本回放的方法、基于參數(shù)隔離的方法以及基于正則化的方法[2]。
基于樣本回放的方法通過(guò)保留從舊樣本集中抽取的原始樣本,將它們和新任務(wù)的樣本進(jìn)行聯(lián)合訓(xùn)練來(lái)達(dá)到記憶的目的,如Rebuff等[3]通過(guò)篩選出最接近類(lèi)均值的樣本并存儲(chǔ)。當(dāng)原始樣本無(wú)法隨時(shí)獲取時(shí),一個(gè)替代方案是利用生成模型合成與原始樣本相似的偽樣本[4-5]。
基于參數(shù)隔離的方法則是將模型參數(shù)劃分為不同的子集,每個(gè)子集都對(duì)應(yīng)特定的數(shù)據(jù)集,在訓(xùn)練過(guò)程中只對(duì)當(dāng)前任務(wù)的數(shù)據(jù)集所屬的參數(shù)集進(jìn)行訓(xùn)練。若模型容量沒(méi)有限制,則可以在原始架構(gòu)基礎(chǔ)上為新任務(wù)增加新的網(wǎng)絡(luò)分支[6-7]。當(dāng)無(wú)法對(duì)模型進(jìn)行擴(kuò)展時(shí),則可以在學(xué)習(xí)新任務(wù)時(shí)使用二進(jìn)制掩碼隔離那些用于識(shí)別舊圖像樣本的參數(shù)[8-9]。
基于正則化的方法不需要保存原始樣本。它通過(guò)在損失函數(shù)中添加額外的正則項(xiàng)來(lái)控制參數(shù)的調(diào)整幅度,避免與舊樣本關(guān)聯(lián)較大的參數(shù)被過(guò)度優(yōu)化。這方面最早的工作為Kirkpatrick等[10]提出的EWC。之后的SI[11]、MAS[12]、Rwalk[13]等也沿用了EWC的思想,主要區(qū)別在于衡量參數(shù)重要性的方式。貝葉斯增量學(xué)習(xí)是該類(lèi)方法的另一種應(yīng)用場(chǎng)景,它的基本框架從傳統(tǒng)神經(jīng)網(wǎng)絡(luò)變?yōu)樨惾~斯神經(jīng)網(wǎng)絡(luò),在這樣的框架下,網(wǎng)絡(luò)權(quán)值不再是定值,而是由均值和方差定義的概率分布。Blundell等[14]詳細(xì)闡述了如何將貝葉斯推理應(yīng)用于神經(jīng)網(wǎng)絡(luò),而后很多工作在此基礎(chǔ)上將貝葉斯推理推廣到增量式場(chǎng)景。Ebrahimi等[15]提出了以權(quán)值的不確定性為重要性判別標(biāo)準(zhǔn)的持續(xù)學(xué)習(xí)算法UCB;Li等[16]為每個(gè)任務(wù)訓(xùn)練一個(gè)獨(dú)立模型,通過(guò)整合各模型的相似部分并保留各自的不同部分來(lái)合成一個(gè)能記憶所有知識(shí)的通用模型。
上述方法在增量學(xué)習(xí)領(lǐng)域都取得了很好的效果,但也存在一些可改進(jìn)的地方。首先,基于正則化的方法[10-13,15]和基于參數(shù)隔離的方法[7]大多是對(duì)單個(gè)權(quán)值的重要性進(jìn)行判別并執(zhí)行正則或隔離操作,而基于單個(gè)權(quán)值的操作會(huì)出現(xiàn)重要性不同的權(quán)值共享同一神經(jīng)元的現(xiàn)象,這種現(xiàn)象會(huì)使得舊任務(wù)中樣本重要性較低的權(quán)值在訓(xùn)練新樣本時(shí)發(fā)生改變,進(jìn)而導(dǎo)致神經(jīng)元從舊樣本中學(xué)習(xí)到的重要特征也發(fā)生改變,從而造成遺忘;相反,當(dāng)將正則操作提升到節(jié)點(diǎn)層面后,模型對(duì)數(shù)據(jù)變化的敏感度會(huì)顯著降低,在新任務(wù)的訓(xùn)練中可以通過(guò)開(kāi)發(fā)重要性較低的神經(jīng)元來(lái)減少對(duì)舊任務(wù)的干擾,從而緩解遺忘問(wèn)題。其次,以上方法并沒(méi)能進(jìn)一步發(fā)掘模型的學(xué)習(xí)能力,因?yàn)樵谌萘坑邢薜哪P椭校瑑?yōu)先訓(xùn)練的樣本總是能獲得更多的資源,但這些資源由于已經(jīng)被施加了較強(qiáng)的正則化或被顯式地隔離,它們對(duì)于新任務(wù)來(lái)說(shuō)是難以訓(xùn)練的,所以隨著可訓(xùn)練資源的減少,未來(lái)任務(wù)的性能會(huì)因此而大幅度下降。
針對(duì)以上問(wèn)題,本文提出了一種基于神經(jīng)元正則和資源釋放機(jī)制的貝葉斯增量學(xué)習(xí)算法NR-RRM。首先,NR-RRM算法將權(quán)值的標(biāo)準(zhǔn)差以節(jié)點(diǎn)為單位進(jìn)行統(tǒng)一,然后將這個(gè)統(tǒng)一的標(biāo)準(zhǔn)差作為同一節(jié)點(diǎn)下所有權(quán)值進(jìn)行調(diào)整時(shí)的正則強(qiáng)度因子,在不引入額外操作的前提下完成對(duì)整個(gè)節(jié)點(diǎn)的約束。另外,為了更充分地發(fā)掘模型的持續(xù)學(xué)習(xí)能力,引入一個(gè)資源釋放機(jī)制,通過(guò)有選擇地釋放部分節(jié)點(diǎn)來(lái)為未來(lái)任務(wù)提供更大的學(xué)習(xí)空間。
1 基于變分貝葉斯推理的增量學(xué)習(xí)
1.1 貝葉斯神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)
首先以深度貝葉斯全連接神經(jīng)網(wǎng)絡(luò)為例對(duì)本文涉及到的變量進(jìn)行概述,如圖1所示,L為神經(jīng)網(wǎng)絡(luò)層數(shù),Il為第l(l∈{1,2,…,L})層的神經(jīng)元數(shù),i∈{1,2,…,Il}表示第l層的第i個(gè)神經(jīng)元,如果是卷積神經(jīng)網(wǎng)絡(luò),則表示第i個(gè)卷積核,z為網(wǎng)絡(luò)權(quán)值矩陣的集合,zl?z為第l層權(quán)值的集合,zl,(i,j)∈zl為第l層第i個(gè)神經(jīng)元的第j個(gè)權(quán)值。由于在貝葉斯神經(jīng)網(wǎng)絡(luò)中權(quán)值z(mì)都是以概率分布的形式存在,故θ=(μ,σ)定義為權(quán)值概率分布的參數(shù)(均值μ、標(biāo)準(zhǔn)差σ)集合。
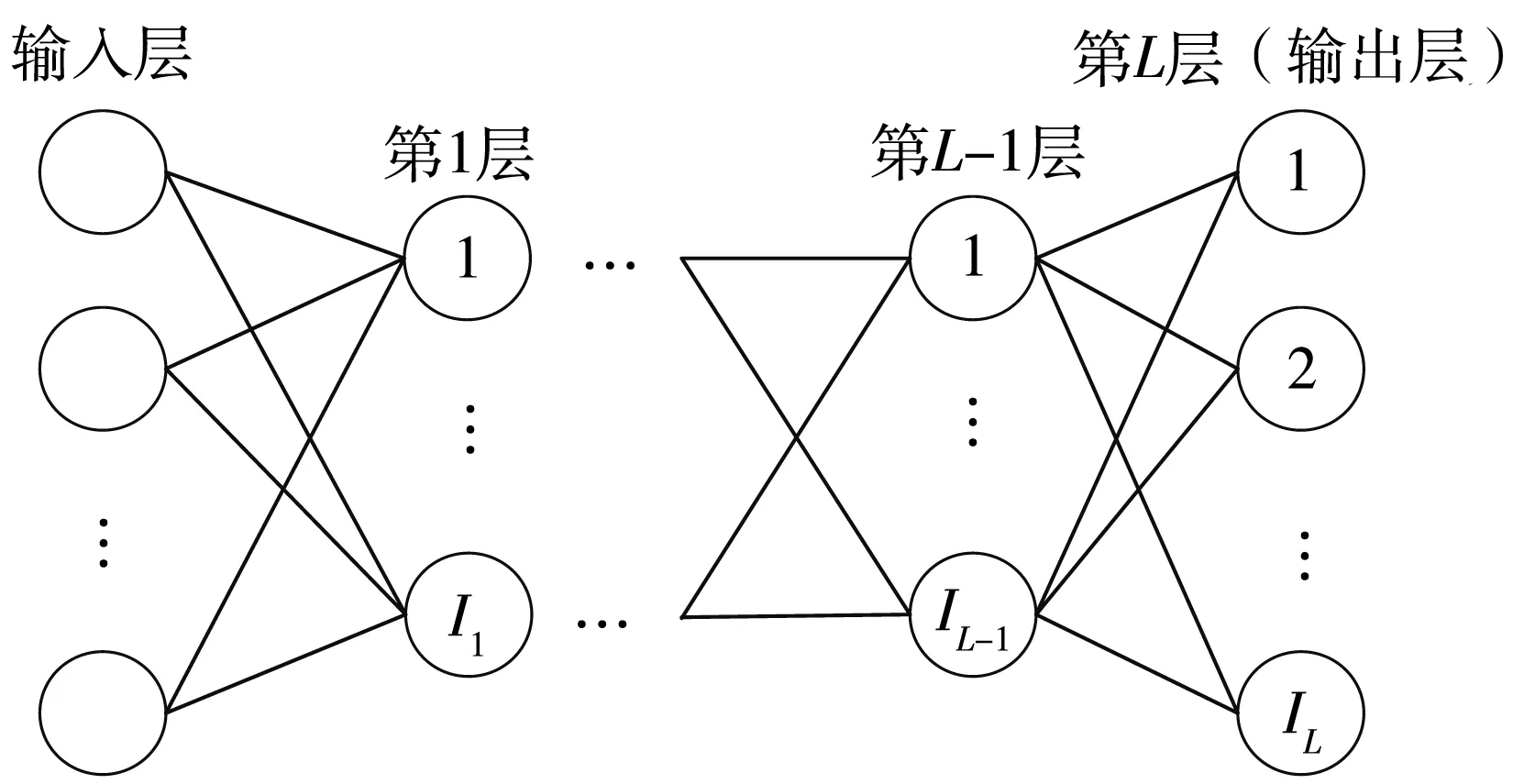
圖1 貝葉斯神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 Structure of Bayesian neural network
1.2 增量式場(chǎng)景下的變分貝葉斯推理
貝葉斯推理過(guò)程需要一個(gè)完整的概率模型,其中包括數(shù)據(jù)集D(X,Y)及其先驗(yàn)P(D)、數(shù)據(jù)的似然P(D|z)和模型的先驗(yàn)P(z),然后根據(jù)貝葉斯公式求出模型的后驗(yàn)分布:
(1)
但在增量式場(chǎng)景下,數(shù)據(jù)變?yōu)榘错樞蜉斎刖W(wǎng)絡(luò):D(X,Y)={(x1,y1),(x2,y2),…,(xk,yk)},網(wǎng)絡(luò)也只能按順序觀測(cè)相應(yīng)數(shù)據(jù),且對(duì)于已經(jīng)觀測(cè)過(guò)的數(shù)據(jù)無(wú)法再次訪問(wèn),在這樣的場(chǎng)景下,貝葉斯公式表示為
(2)
式中,Dk-1和Dk分別表示模型已經(jīng)觀測(cè)到的先前任務(wù)的舊數(shù)據(jù)和即將要觀測(cè)的當(dāng)前任務(wù)的新數(shù)據(jù),P(Dk|z)、P(z|Dk)和P(z|Dk-1)分別表示新數(shù)據(jù)的似然、模型訓(xùn)練新任務(wù)后形成的后驗(yàn)分布以及模型只觀測(cè)到舊數(shù)據(jù)時(shí)的后驗(yàn)分布。
由于在現(xiàn)實(shí)中,直接計(jì)算后驗(yàn)分布非常困難,因此,精確高效地近似后驗(yàn)分布是貝葉斯推理的關(guān)鍵。Blundell等[14]使用變分近似的方法來(lái)優(yōu)化一個(gè)貝葉斯神經(jīng)網(wǎng)絡(luò),與標(biāo)準(zhǔn)變分貝葉斯推理類(lèi)似,增量式的變分貝葉斯推理,其核心在于為當(dāng)前模型構(gòu)建一個(gè)基于參數(shù)簇θ=(μ,σ)的高斯分布:
(3)
然后通過(guò)最小化Qk(z|θ)與P(z|Dk)的KL散度求出一個(gè)近似P(z|Dk)的分布:
dKL[Qk(z|θ)‖P(z|Dk)]=
(4)
式中,logaP(Dk)是一個(gè)與參數(shù)無(wú)關(guān)的常數(shù)(a>1),若保持logaP(Dk)不變,則可以將最小化KL散度的問(wèn)題轉(zhuǎn)化為求解最佳變分參數(shù)的優(yōu)化問(wèn)題:
Ez~Qk(z|θ)[logaP(Dk|z)]
(5)
式中:Fdata(θ)=Ez~Qk(z|θ)[logaP(Dk|z)],是當(dāng)前數(shù)據(jù)的對(duì)數(shù)似然;在Freg(θ)=dKL[Qk(z|θ)‖P(z|Dk-1)]中舊任務(wù)的后驗(yàn)P(z|Dk-1)取代了P(z)作為新任務(wù)的先驗(yàn)。
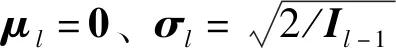
(6)
KL散度的計(jì)算是變分推理的關(guān)鍵,UCB[15]采用了將Fdata(θ)和Freg(θ)一起進(jìn)行蒙特卡洛采樣后得到的近似形式,但這里采用文獻(xiàn)[19]的方法,將KL散度項(xiàng)轉(zhuǎn)化為均值與方差的形式,由于貝葉斯推理通常可以假設(shè)所有變量之間相互獨(dú)立,因此可以將KL散度項(xiàng)分解為多個(gè)一元高斯函數(shù)后再進(jìn)行解析計(jì)算:
dKL[Q(z|θk)‖P(z|Dk-1)]=F(μk)+F(σk)=
(7)

1.3 基于神經(jīng)元的集體正則化
式(7)的正則化操作仍然停留在權(quán)值層面,為了實(shí)現(xiàn)將正則化操作提升到神經(jīng)元層面的目標(biāo),這里采用對(duì)每個(gè)神經(jīng)元的權(quán)值進(jìn)行統(tǒng)一限制的方法。
以第l層為例,在重參數(shù)化階段將標(biāo)準(zhǔn)差矩陣σl中的元素以節(jié)點(diǎn)為單位分為I組,并將每組元素都限制為一個(gè)相同的值:
(8)
然后用這I個(gè)值構(gòu)成一個(gè)新向量:
(9)
根據(jù)式(9)將F(μk)改寫(xiě)為
(10)
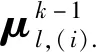
1.4 資源釋放機(jī)制
前面的操作雖然能有效緩解災(zāi)難性遺忘,但卻對(duì)未來(lái)任務(wù)非常不利,因?yàn)槟P拖拗屏舜蟛糠仲Y源的更新,所以留給后續(xù)任務(wù)的可訓(xùn)練資源會(huì)急劇減少。為了讓資源得到更合理的分配,本文在前面操作的基礎(chǔ)上引入一個(gè)資源釋放機(jī)制(RRM)。
1.4.1 權(quán)值篩選
資源釋放機(jī)制首先涉及到一個(gè)權(quán)值篩選的過(guò)程。同樣以第l層為例,在訓(xùn)練之前,首先將第l層中的權(quán)值根據(jù)方差的大小進(jìn)行排序:
(11)
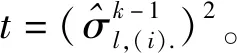
然后將I組權(quán)值中方差大于該閾值的i組視為重要性較低的權(quán)值,釋放它們對(duì)舊任務(wù)性能造成的影響較小,而對(duì)于其余I-i組權(quán)值,則認(rèn)為其重要性相對(duì)較高,不進(jìn)行釋放。
唯一的例外是第一個(gè)任務(wù),如1.2節(jié)所述,由于已經(jīng)將第一個(gè)任務(wù)的先驗(yàn)指定為固定的高斯分布,所以對(duì)于第l層中的權(quán)值,它們的先驗(yàn)方差都相等,無(wú)法比較大小,故在訓(xùn)練第一個(gè)任務(wù)時(shí),根據(jù)比例r隨機(jī)選擇rI組權(quán)值進(jìn)行釋放,其余未被選擇到的權(quán)值按照常規(guī)步驟進(jìn)行訓(xùn)練。
1.4.2 釋放操作
根據(jù)前面計(jì)算出的閾值t,引入資源釋放機(jī)制,用數(shù)學(xué)公式表述如下:
(12)
(13)
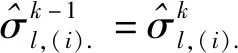
1.5 損失函數(shù)及算法描述
至此,經(jīng)過(guò)改進(jìn)后的損失函數(shù)為
(14)
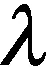
基于神經(jīng)元正則化和資源釋放的貝葉斯增量學(xué)習(xí)算法的描述如下:
{輸入:數(shù)據(jù)訓(xùn)練集D(X,Y)={(x1,y1),…,(xk,yk)}
初始化:將先驗(yàn)指定為均值為0、方差為2/Il-1的高斯分布
fork=1,2,…,Kdo
ifk=1 then
根據(jù)r隨機(jī)選擇rI組權(quán)值,令η>1;
其余(1-r)I組權(quán)值,令η=1;
根據(jù)式(12)優(yōu)化模型;
else
根據(jù)r確定釋放閾值t;
η>1;
else
η=1;
根據(jù)式(12)優(yōu)化模型;
end for}
2 仿真實(shí)驗(yàn)及結(jié)果分析
本文使用3個(gè)公開(kāi)的數(shù)據(jù)集MNIST、Fashion-MNIST和CIFAR10進(jìn)行實(shí)驗(yàn),并從多個(gè)角度來(lái)驗(yàn)證算法的效果。
MNIST數(shù)據(jù)集由手寫(xiě)數(shù)字組成,共有10個(gè)類(lèi)別,包括6萬(wàn)個(gè)訓(xùn)練樣本和1萬(wàn)個(gè)測(cè)試樣本,每幅圖像尺寸為28×28。在多任務(wù)設(shè)置中,通常按照Kirkpatrick等[10]提出的處理方法,以固定的排列方式將圖像的像素重新排列,形成多個(gè)分布不同的數(shù)據(jù)集,經(jīng)過(guò)改動(dòng)后的數(shù)據(jù)集稱(chēng)為Perturbation-MNIST。
Fashion-MNIST數(shù)據(jù)集由10類(lèi)標(biāo)記服裝圖像組成,每幅圖像尺寸為28×28。相較于MNIST數(shù)據(jù)集,F(xiàn)ashion-MNIST數(shù)據(jù)集更貼近真實(shí)場(chǎng)景,更能反映模型的分類(lèi)性能。在多任務(wù)設(shè)置中,可以以相同的方式對(duì)像素進(jìn)行重排列,形成數(shù)據(jù)集Perturbation-Fashion。
CIFAR10數(shù)據(jù)集由10類(lèi)彩色圖像組成,每幅圖像尺寸為32×32,每個(gè)類(lèi)別各有6萬(wàn)幅圖像,其中5萬(wàn)幅為訓(xùn)練圖像,1萬(wàn)幅為測(cè)試圖像。
2.1 消融分析
為分析神經(jīng)元正則化和資源釋放機(jī)制對(duì)模型性能的影響,使用Perturbation-MNIST與Perturbation-Fashion數(shù)據(jù)集,在如圖1所示的3層全連接神經(jīng)網(wǎng)絡(luò)上進(jìn)行實(shí)驗(yàn),以確定模型中每個(gè)部分的貢獻(xiàn)。對(duì)于Perturbation-MNIST數(shù)據(jù)集,每層節(jié)點(diǎn)數(shù)設(shè)為256,對(duì)于較難訓(xùn)練的Perturbation-Fashion數(shù)據(jù)集,節(jié)點(diǎn)數(shù)增加到400,并將WR(不對(duì)權(quán)值的標(biāo)準(zhǔn)差進(jìn)行分組統(tǒng)一,直接根據(jù)單個(gè)權(quán)值的重要性進(jìn)行正則的方法)作為參考。實(shí)驗(yàn)結(jié)果如表1所示。從表中可知,在3種模型中,WR在兩個(gè)數(shù)據(jù)集上的分類(lèi)精度均最低,當(dāng)對(duì)權(quán)值的正則化強(qiáng)度進(jìn)行統(tǒng)一后,分類(lèi)精度有了較明顯的提升,達(dá)到了89.67%和78.70%,最后加入資源釋放機(jī)制后,分類(lèi)精度進(jìn)一步提升,達(dá)到94.75%和82.11%。這表明,在模型容量固定的環(huán)境下,以神經(jīng)元為單位執(zhí)行正則化的模型能獲得比對(duì)單個(gè)權(quán)值進(jìn)行正則化的模型更好的分類(lèi)精度,而資源共享機(jī)制則進(jìn)一步提高了模型的持續(xù)學(xué)習(xí)能力。
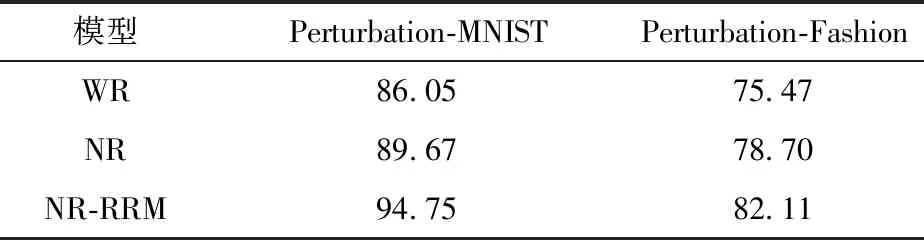
表1 3種模型的消融分析結(jié)果Table 1 Ablation analysis results of three models
2.2 資源釋放機(jī)制有效性分析
以Perturbation-MNIST數(shù)據(jù)集為例,圖2展示了單個(gè)任務(wù)的分類(lèi)精度隨著訓(xùn)練任務(wù)量的增加所發(fā)生的變化情況。由圖中可知,引入RRM后,模型在前3個(gè)任務(wù)上的分類(lèi)精度略低于不增加RRM的模型,但在后續(xù)幾個(gè)任務(wù)上的分類(lèi)精度明顯高于后者。這是因?yàn)椴灰隦RM時(shí),模型為了記憶舊任務(wù)的信息而限制了權(quán)值的調(diào)整,所以前幾個(gè)任務(wù)都保持著較高的分類(lèi)精度,但隨著訓(xùn)練任務(wù)量的增加,網(wǎng)絡(luò)中的可訓(xùn)練資源逐漸減少,導(dǎo)致后續(xù)任務(wù)的分類(lèi)精度急劇下降。加入RRM后,后續(xù)任務(wù)因?yàn)楂@得了更多可訓(xùn)練資源而使得分類(lèi)精度大大提高,而且通過(guò)合理調(diào)節(jié)釋放比例和釋放強(qiáng)度,又能使舊任務(wù)的分類(lèi)精度不會(huì)受到太大的影響。
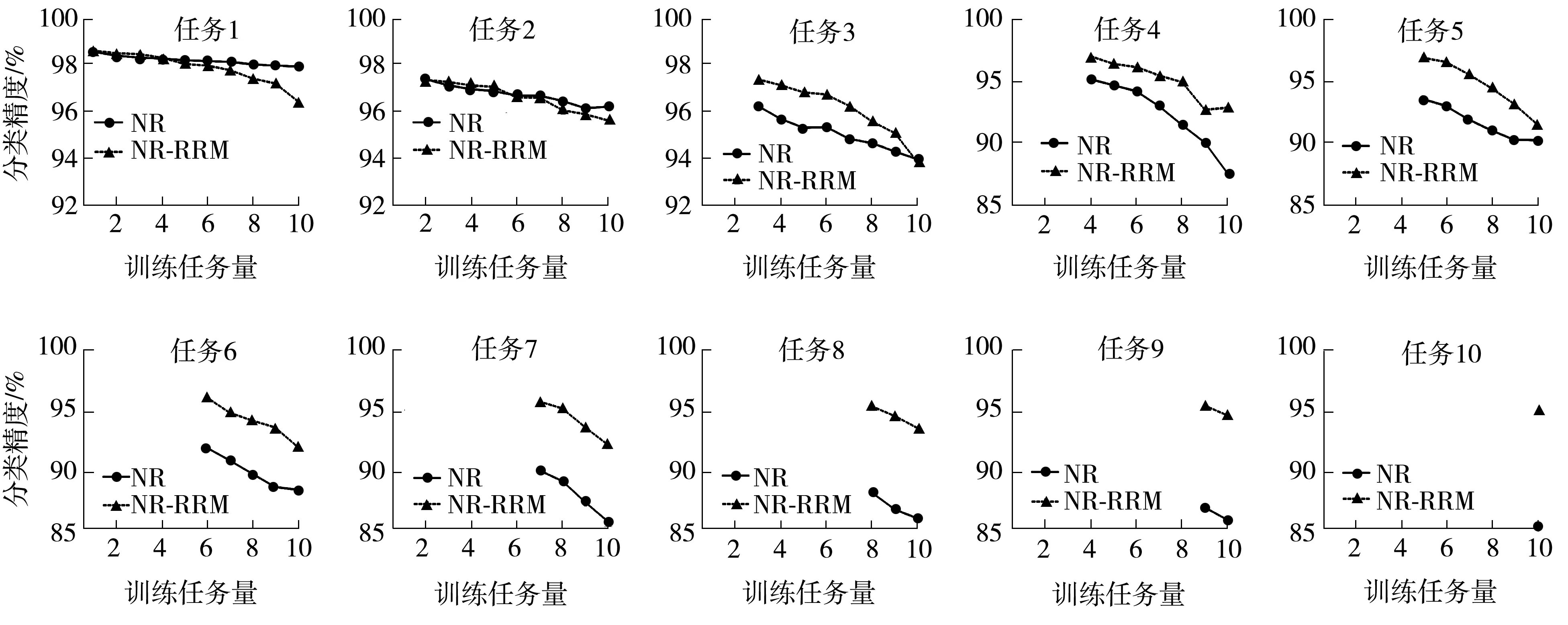
圖2 單個(gè)任務(wù)的分類(lèi)精度變化情況Fig.2 Variation of classification accuracy for a single task
2.3 參數(shù)變化分析
為了理解模型的運(yùn)行過(guò)程,本文對(duì)模型參數(shù)的變化進(jìn)行分析。
首先將一層中的每組權(quán)值的標(biāo)準(zhǔn)差在每次訓(xùn)練后的取值以散點(diǎn)圖的形式展示,如圖3所示。從圖中可知:當(dāng)不加入資源釋放機(jī)制時(shí),標(biāo)準(zhǔn)差的取值呈單調(diào)減小趨勢(shì),這是因?yàn)槟P偷挠?xùn)練過(guò)程也是一個(gè)降低標(biāo)準(zhǔn)差令權(quán)值的取值趨于穩(wěn)定的過(guò)程;當(dāng)加入資源釋放機(jī)制后,標(biāo)準(zhǔn)差的取值分布不再呈嚴(yán)格的單調(diào)趨勢(shì),這是因?yàn)橛胁糠謽?biāo)準(zhǔn)差的取值會(huì)因?yàn)獒尫艡C(jī)制的作用而提高。
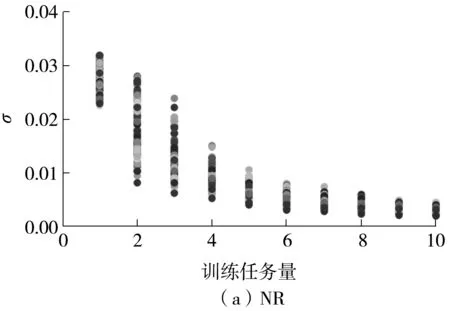
圖3 兩個(gè)模型權(quán)值的標(biāo)準(zhǔn)差分布Fig.3 Standard deviation distribution of the weights of two models
選取一組具有代表性的權(quán)值,分別在基于神經(jīng)元正則(NR)和加入RRM的模型(NR-RRM)中進(jìn)行訓(xùn)練后,該組權(quán)值標(biāo)準(zhǔn)差的變化如圖4所示,在各個(gè)訓(xùn)練階段該組權(quán)值的均值變化量Δμl,(i).的范數(shù)‖Δμl,(i).‖2如圖5所示,因?yàn)橄蛄康姆稊?shù)在一定程度上反映了向量中的元素大小,所以‖Δμl,(i).‖2可以反映出權(quán)值的變化幅度。
由圖4(b)可以觀察到,加入RRM后,權(quán)值的標(biāo)準(zhǔn)差在前幾個(gè)階段可能會(huì)有所提高,但在之后的某些階段,這些權(quán)值的標(biāo)準(zhǔn)差會(huì)有較大幅度的下降,同時(shí),對(duì)應(yīng)階段的均值變化量也會(huì)比其他階段更大(見(jiàn)圖5(b)加粗部分),這說(shuō)明權(quán)值可以為了更好地適應(yīng)新任務(wù)而進(jìn)行較大幅度的調(diào)整。相反,如果模型沒(méi)有引入RRM(見(jiàn)圖4(a)),那么在訓(xùn)練的前期階段權(quán)值的標(biāo)準(zhǔn)差便會(huì)下降至接近于0,之后標(biāo)準(zhǔn)差的變化也都比較平穩(wěn),而均值的變化幅度也一直保持在較小的狀態(tài),這說(shuō)明權(quán)值一旦被施加了很強(qiáng)的正則化,便很難進(jìn)行調(diào)整以適應(yīng)新的樣本。
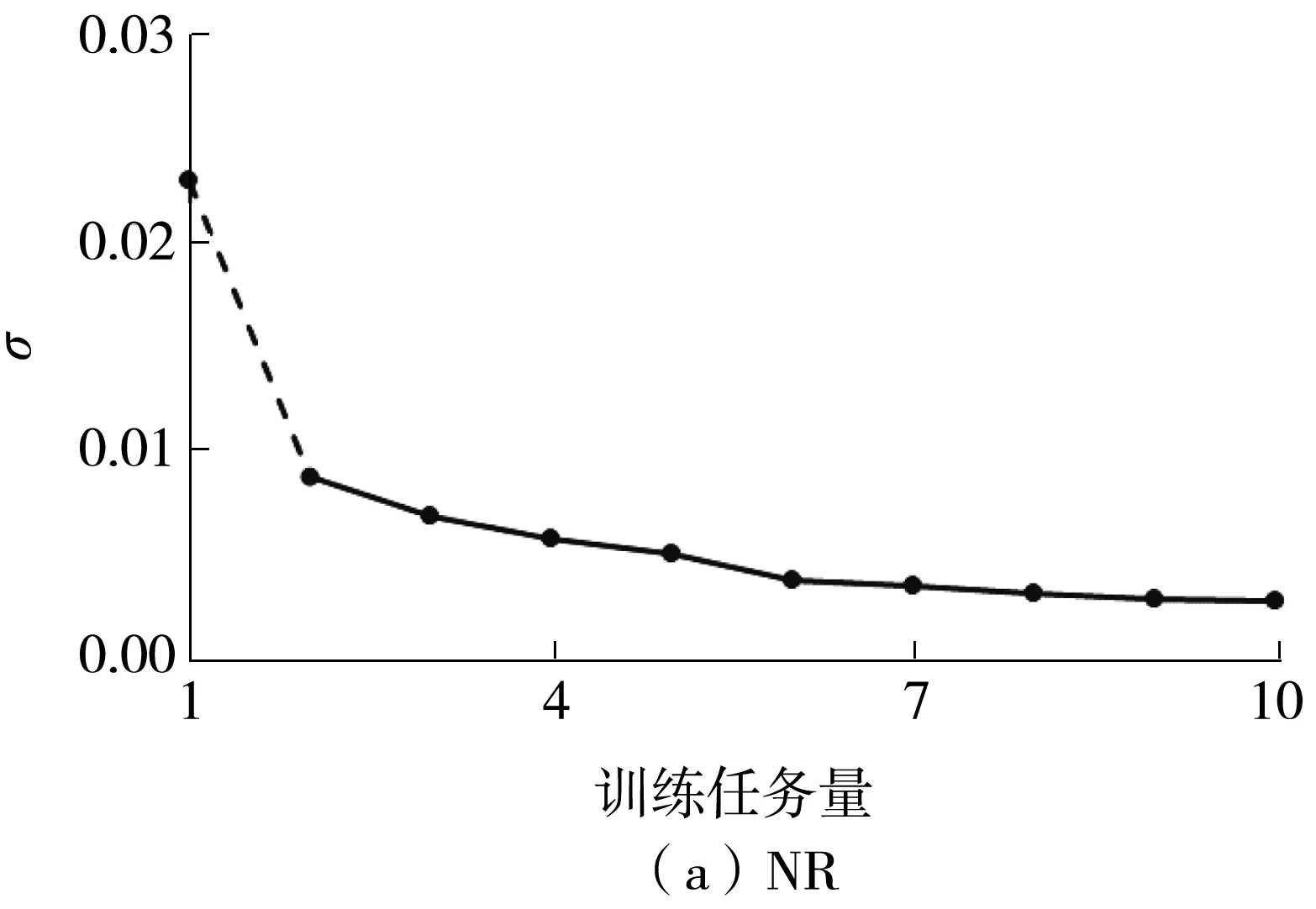
圖4 單組權(quán)值的標(biāo)準(zhǔn)差變化趨勢(shì)Fig.4 Trend of standard deviation of single group weights
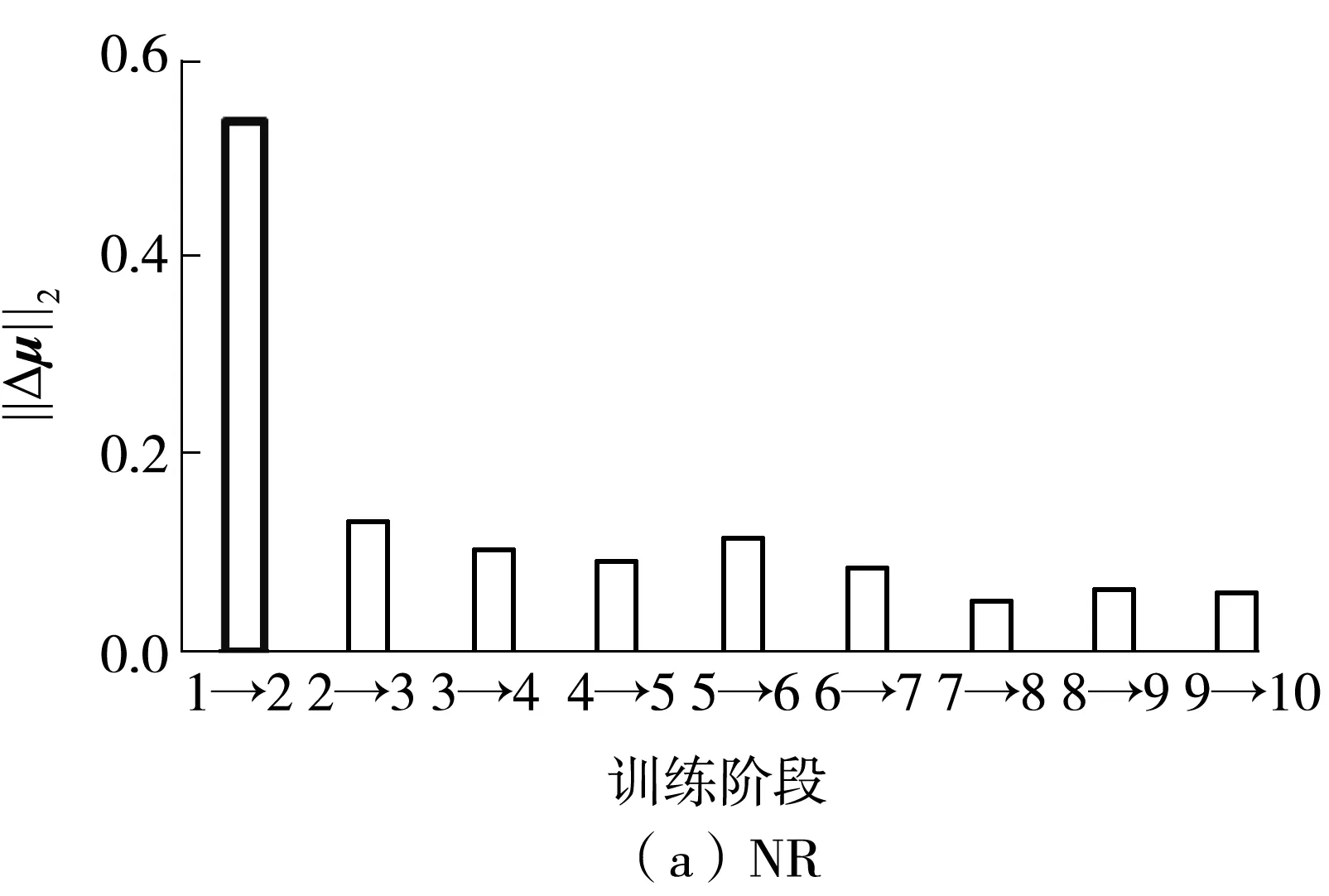
圖5 兩個(gè)模型權(quán)值的均值變化趨勢(shì)Fig.5 Trends of the mean weights of two models
2.4 超參數(shù)配置分析
2.4.1 不同強(qiáng)度因子和選擇比例對(duì)模型性能的影響
分別選取3種釋放強(qiáng)度(η=2,3,4)和4種篩選比例(r=50%,70%,80%,100%),也將2.2節(jié)中提及的僅將正則化提升至神經(jīng)元層面卻不引入釋放機(jī)制(即η=1,r=100%)的方法與其他參數(shù)配置結(jié)果進(jìn)行了比較,結(jié)果如表2所示。從表中可知:①僅將正則化提升至神經(jīng)元層面卻不引入釋放機(jī)制(即η=1,r=100%)的方法,在兩個(gè)數(shù)據(jù)集上獲得的分類(lèi)精度均比大部分的配置要低,這進(jìn)一步說(shuō)明,釋放操作的引入對(duì)模型性能有著積極的影響。②對(duì)于任何一個(gè)釋放強(qiáng)度,令r=100%都很難使模型的分類(lèi)精度達(dá)到最優(yōu),例如在Perturbation-MNIST數(shù)據(jù)集上,當(dāng)η等于2或3時(shí),模型的分類(lèi)精度都隨著釋放比例的增大而提高,但在r=100%時(shí)出現(xiàn)下降;而在Perturbation-Fashion上,當(dāng)η等于2或3且r=100%時(shí)的分類(lèi)精度是最低的。這是因?yàn)橘Y源釋放雖然對(duì)未來(lái)任務(wù)的學(xué)習(xí)有幫助,但不加選擇地進(jìn)行釋放可能會(huì)使舊任務(wù)丟失重要性極高的資源,從而降低舊任務(wù)的分類(lèi)精度,并不能令模型的性能有實(shí)質(zhì)性提高。
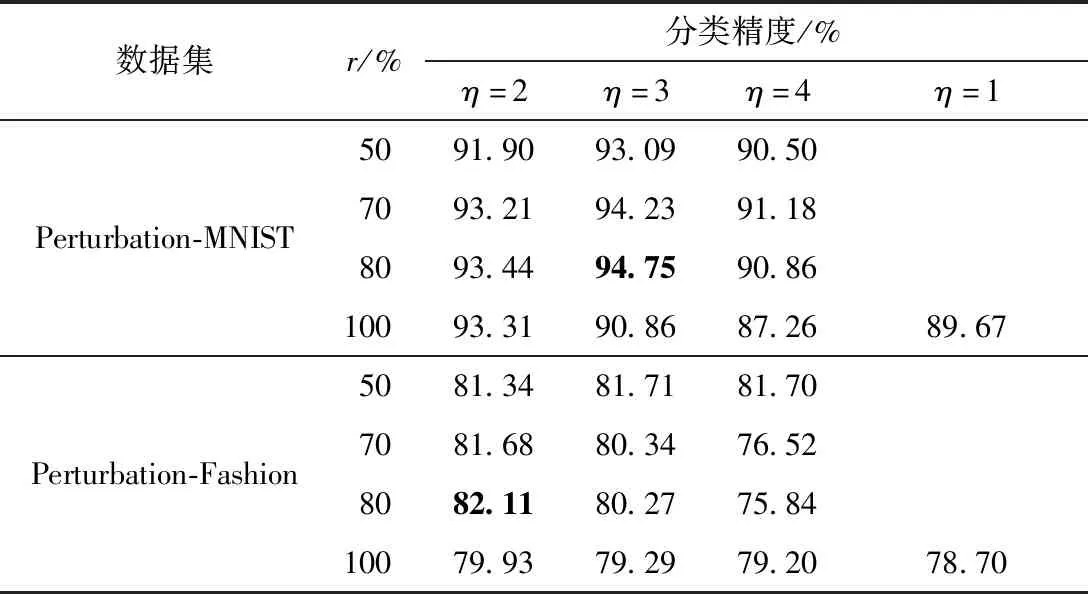
表2 NR-RRM模型在不同配置下的分類(lèi)精度Table 2 Classification accuracy of NR-RRM model under different combinations
2.4.2 平衡系數(shù)配置對(duì)模型性能的影響
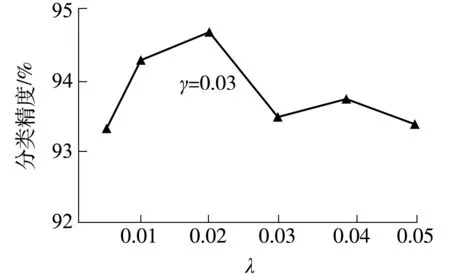
圖6 、γ對(duì)NR-RRM模型分類(lèi)精度的影響Fig.6 Effects of and γ on the classification accuracy of NR-RRM model
2.5 不同方法的性能對(duì)比
2.5.1 多任務(wù)測(cè)試
將NR-RRM與目前最常使用的幾種增量學(xué)習(xí)方法進(jìn)行性能比較。實(shí)驗(yàn)采用與2.2節(jié)相同的3層全連接神經(jīng)網(wǎng)絡(luò),但對(duì)網(wǎng)絡(luò)的規(guī)模進(jìn)行了不同設(shè)置,在不同網(wǎng)絡(luò)規(guī)模下幾種方法對(duì)Perturbation-MNIST和Perturbation-Fashion數(shù)據(jù)集的分類(lèi)精度如圖7所示。從圖中可以看到,不管是在Perturbation-MNIST還是在Perturbation-Fashion數(shù)據(jù)集上,NR-RRM在不同網(wǎng)絡(luò)規(guī)模下都能獲得最高的分類(lèi)精度。
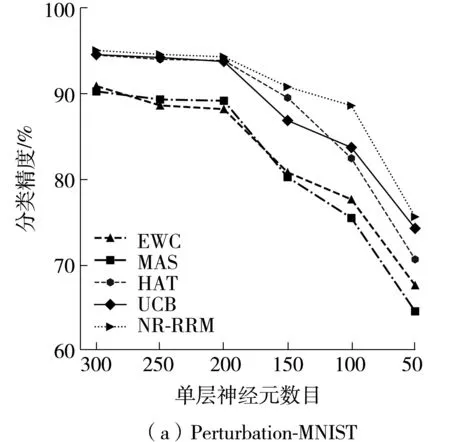
圖7 多任務(wù)場(chǎng)景下幾種方法的分類(lèi)精度比較Fig.7 Comparison of classification accuracy among several methods in multi-task scenarios
2.5.2 類(lèi)增量測(cè)試
為了測(cè)試NR-RRM在類(lèi)增量場(chǎng)景下的性能,分別將3個(gè)數(shù)據(jù)集內(nèi)的樣本按類(lèi)別劃分為5個(gè)獨(dú)立的子集,每個(gè)子集包含兩個(gè)不同的類(lèi)別,然后將這5個(gè)子集按順序輸入網(wǎng)絡(luò)進(jìn)行二分類(lèi)測(cè)試,其中Split-MNIST和Split-Fashion數(shù)據(jù)集繼續(xù)沿用多任務(wù)測(cè)試時(shí)的網(wǎng)絡(luò)結(jié)構(gòu),而Split-CIFAR10數(shù)據(jù)集則分別使用5種網(wǎng)絡(luò)(記為Net1、Net2、Net3、Net4和Net5)進(jìn)行訓(xùn)練,這5種網(wǎng)絡(luò)的結(jié)構(gòu)均為3個(gè)卷積層加1個(gè)全連接層,每層的卷積核或神經(jīng)元數(shù)目從Net1至Net5依次減少。實(shí)驗(yàn)結(jié)果如圖8所示,與其他方法相比,NR-RRM在幾種網(wǎng)絡(luò)結(jié)構(gòu)中都保持著最高的分類(lèi)精度,說(shuō)明NR-RRM同樣適用于類(lèi)增量場(chǎng)景。
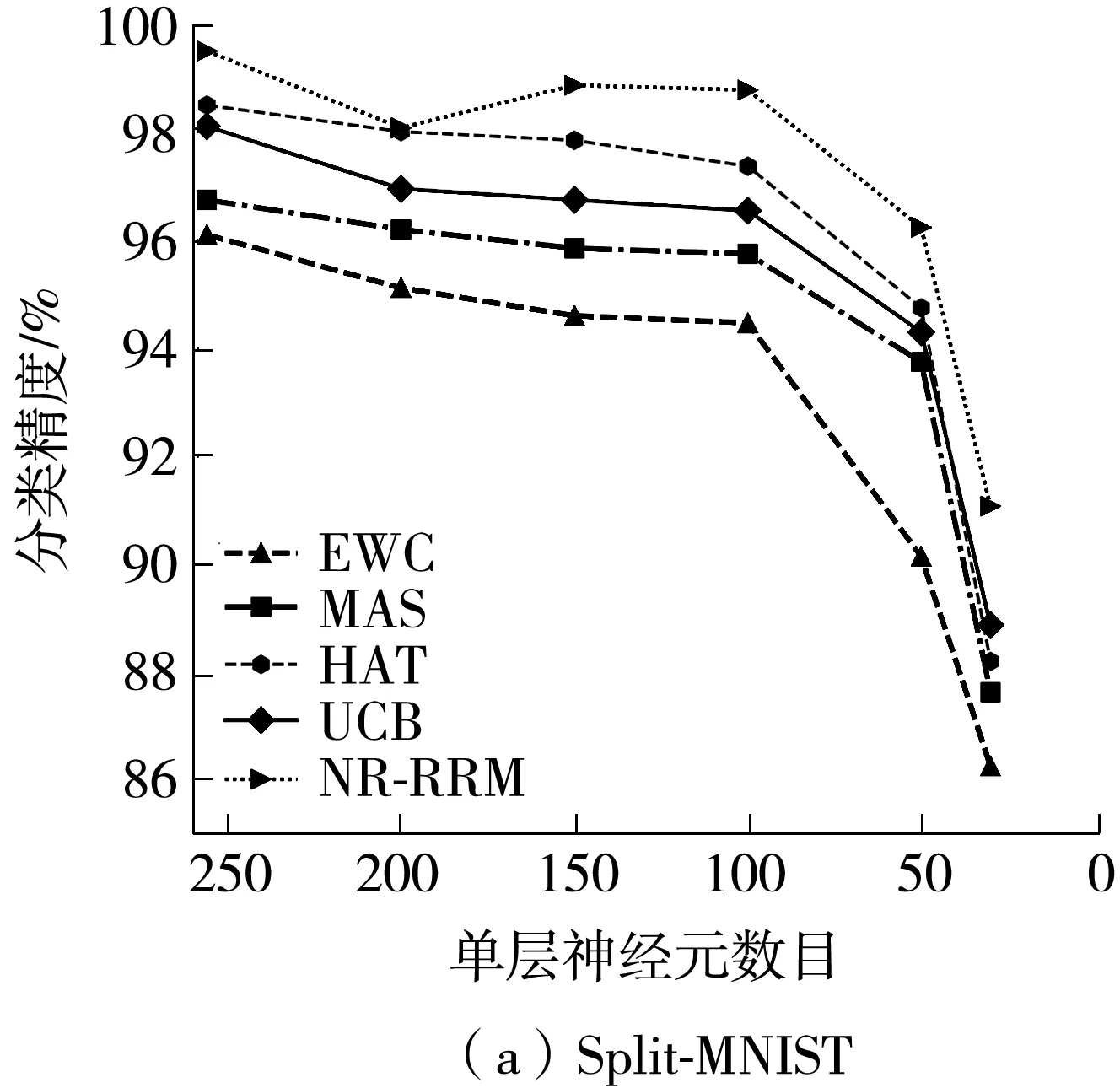
圖8 類(lèi)增量場(chǎng)景下幾種方法的分類(lèi)精度比較Fig.8 Comparison of classification accuracy among several methods in class incremental scenarios
2.5.3 網(wǎng)絡(luò)規(guī)模適用范圍分析
從圖7和圖8可知,NR-RRM所適用的網(wǎng)絡(luò)規(guī)模的范圍比其他增量學(xué)習(xí)方法更大。例如,對(duì)于多任務(wù)場(chǎng)景,在資源充足時(shí),HAT方法[8]在兩個(gè)數(shù)據(jù)集上的分類(lèi)精度與NR-RRM差別不大,但當(dāng)節(jié)點(diǎn)數(shù)分別減少到150和200時(shí),其分類(lèi)精度在兩個(gè)數(shù)據(jù)集上都出現(xiàn)了較明顯的下降,而NR-RRM只在節(jié)點(diǎn)數(shù)縮減到50和100時(shí),其分類(lèi)精度才會(huì)出現(xiàn)明顯的下降。
同樣的現(xiàn)象也出現(xiàn)在類(lèi)增量場(chǎng)景中,在Split-MNIST和Split-Fashion數(shù)據(jù)集上,需要將每層節(jié)點(diǎn)數(shù)分別減少到30和50,在Split-CIFAR10數(shù)據(jù)集上需要使用Net5訓(xùn)練,NR-RRM的分類(lèi)性能才會(huì)出現(xiàn)明顯的下降,而這一現(xiàn)象其他方法均會(huì)提前出現(xiàn)。而且當(dāng)NR-RRM的分類(lèi)性能出現(xiàn)明顯下滑時(shí),其分類(lèi)性能仍然能保持優(yōu)于其他方法。
3 結(jié)論
針對(duì)深度學(xué)習(xí)系統(tǒng)在增量式場(chǎng)景下進(jìn)行圖像分類(lèi)時(shí)容易產(chǎn)生災(zāi)難性遺忘的問(wèn)題,本文提出了一種基于神經(jīng)元正則和資源釋放的增量學(xué)習(xí)算法NR-RRM,該算法在處理連續(xù)任務(wù)時(shí)不需要額外計(jì)算神經(jīng)元的信息量,而是將權(quán)值的方差以神經(jīng)元為單位進(jìn)行分組統(tǒng)一,然后將方差的倒數(shù)作為重要性對(duì)每組權(quán)值施加相應(yīng)的正則化,并以適當(dāng)?shù)谋壤土Χ冉档筒糠謾?quán)值的重要性,使模型能更好地適應(yīng)新任務(wù)的資源釋放。實(shí)驗(yàn)結(jié)果表明,資源釋放機(jī)制能明顯提升模型的分類(lèi)精度,同時(shí)能使舊任務(wù)保持較小的性能損失。特別是在網(wǎng)絡(luò)資源較少的環(huán)境下,與目前較常用的方法相比,本文方法的分類(lèi)性能能維持在一個(gè)相對(duì)較高的水平。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
