模擬真實場景的場景流預測
2022-07-03 04:23:04梅海藝朱翔昱馬喜波
圖學學報 2022年3期
梅海藝,朱翔昱,雷 震,高 瑞,馬喜波
模擬真實場景的場景流預測
梅海藝1,2,3,朱翔昱2,3,雷 震2,3,高 瑞1,馬喜波2,3
(1. 山東大學控制科學與工程學院,山東 濟南 250061;2. 中國科學院自動化研究所,北京 100190;3. 中國科學院大學人工智能學院,北京 100049)
人工智能發展至今正逐漸進入認知時代,計算機對真實物理世界的認知與推理能力亟待提高。有關物體物理屬性與運動預測的現有工作多局限于簡單的物體和場景,因此嘗試拓展常識推理至仿真場景下物體場景流的預測。首先,為了彌補相關領域數據集的短缺,提出了一個基于仿真場景的數據集ModernCity,從常識推理的角度出發還原了現代都市的街邊景象,并提供了包括RGB圖像、深度圖、場景流數據和語義分割圖在內的多種標簽;此外,設計了一個物體描述子解碼模型(ODD),通過物體屬性輔助預測場景流。通過消融實驗證明,該模型可以在仿真的場景下通過物體的屬性準確地預測物體未來的運動趨勢,通過與其他SOTA模型的對比實驗驗證了該模型的性能及ModernCity數據集的可靠性。
常識推理;場景流;仿真場景;物體物理屬性;運動預測
現實世界被物理規律包圍著,每個物體都有其獨特的物理屬性,不同物體不停移動并相互交互組成了物理世界。人類擁有對世界的基本認知能力,通過學習和觀察可以估計出物體的一些屬性,并根據這些屬性預測出物體將來的運動趨勢,例如行人在過馬路時會通過觀察估計出馬路上車輛的體積、重量、位置、前進方向等,并判斷其未來的運動趨勢。隨著深度學習掀起的第三次人工智能浪潮[1],以神經網絡為核心的機器學習算法快速發展,大規模的數據讓越來越多的人工智能任務成為可能,也有不少研究者將精力投入到常識學習中;認知與推理是人工智能的一個重要研究領域,推理物理世界中的常識是其中重要的一環;在理解并認知物理世界后,機器可以對物體的運動進行預測,對異常狀況做出判斷,幫助機器人自主移動等,這也是邁向強人工智能所必須解決的問題。
本文從預測物體的運動速度出發,使用物體的屬性預測該物體下一時刻的三維速度,旨在探索人工智能理解物體的物理屬性并預測物體運動趨勢的可能性,并將其作為推理物理常識的基本問題。物體的屬性被抽象為一個特征向量,且被稱為物體描述子(object descriptor),物體的三維速度由場景流(scene flow)表示。本文將問題聚焦至在仿真場景下進行場景流預測,現有的研究工作多局限于簡單的物體與物理場景,例如在純色背景下預測簡單幾何體的運動趨勢,在設計時少有算法從常識推理的角度出發;本文向真實邁進,在仿真的場景下對復雜的物體進行場景流預測。為解決現有數據集在該領域的短缺,本文首先提出了一個基于仿真場景的數據集ModernCity,提供RGB圖像、深度圖、場景流和語義分割圖等標簽;該數據集的設計從常識推理出發,還原了現代都市的街邊景象,場景中的所有物體均遵循嚴格的物理規律。此外,還提出了物體描述子解碼模型(object descriptor decoder,ODD),負責提取場景中物體的屬性并通過神經網絡將這些屬性解碼為場景流;ODD模型生成的場景流提供給基準模型作為迭代初始值,填補缺失的局部和全局信息,生成更加準確的場景流預測結果。基準模型的設計參考了主流的光流估計模型。通過實驗證明ODD模型可以幫助基準模型對場景流進行預測,證明該模型可以在仿真的場景下通過物體的屬性準確地預測物體未來的運動趨勢。
1 相關研究
近年來,物理場景理解得到了研究人員的廣泛關注[2-29],隨著分類[30-38]、定位[39-41]、分割[42-43]等計算機視覺基礎任務研究的不斷完善,研究者們開始嘗試突破計算機視覺的傳統目標,其中一個任務是預測動態場景中物體的運動趨勢;該任務有2種解決方法:①基于像素的方法[13-17],直接從像素中進行特征提取,預測每個像素未來的情況,由于圖像中靜態背景的占比往往更大,即圖像中有很多冗余信息,這使得基于像素的算法往往缺乏泛化性;②基于物體屬性的方法[7-8],將圖像中的物體及其屬性進行分解,建立物體間的交互關系并進行預測,可以更好地挖掘有效信息,泛化能力更強。
常識學習領域也有一些工作旨在通過物體的屬性對物理場景進行理解[2-5],與從常識推理角度出發的常識學習方法不同的是,其算法是從物理規律出發進行設計的。文獻[2]使用卷積神經網絡(convolution neural network,CNN)學習物體的物理屬性,并利用這些屬性解決結果預測等任務;文獻[3]使用物體檢測算法生成物體區域,并使用CNN對區域內的物體進行特征提取,得到一個特征向量來表示該物體的物理狀態,然后將其放入物理引擎中預測未來的運動;文獻[4]設計了一種即插即用的模塊Slot Attention,旨在與其他神經網絡進行連接,生成以物體為中心的特征表示,并運用到預測任務上;類似的,文獻[5]提出了一個框架,可以提取潛在物體的屬性,并通過這些屬性對動力學進行預測。
上述工作均局限于簡單場景,即在單一的背景(通常是純色)下預測固定的簡單幾何體的運動,且少有算法在設計時從常識推理的角度出發。本文將場景擴展至仿真場景,將物體擴展至現實生活中的實際物體(如人類、動物、車輛等),物體的運動趨勢使用場景流表示,在此基礎上還提出了基于物體描述子的場景流預測模型(ODD模型),如圖1所示。該模型由2個階段組成:①使用ODD模型先對場景中的物體進行特征提取,得到物體描述子后將其解碼為場景流;②將ODD模型得到的場景流作為初始值代入基準模型中,預測得到場景流的預測結果。ODD模型使用反卷積神經網絡,對物體屬性進行解碼生成場景流;基準模型的設計參考了主流的光流估計模型[44-47]。
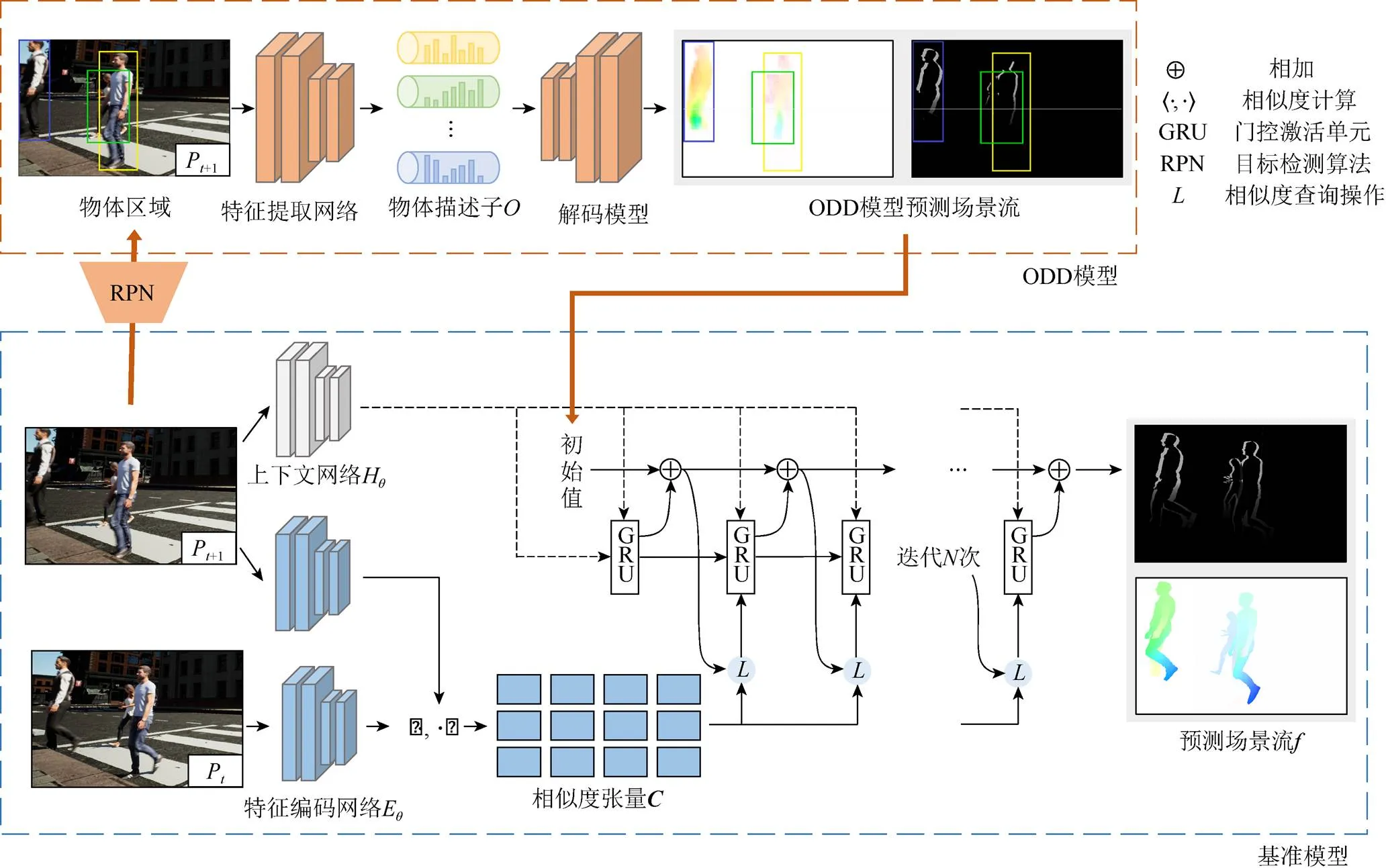
圖1 算法模型框架
2 場景流預測
在光源的照射下,連續運動的物體在成像平面上有一系列投影,根據運動物體的投影位移和時間差可以計算出該物體在投影平面上每個像素的二維運動速度,即光流(optical flow)。場景流(scene flow)是將物體的運動由二維拓展至三維,在平面二維速度的基礎上增加物體與投影平面間的垂直距離變化,即深度(depth)的變化。
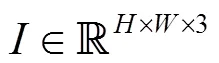
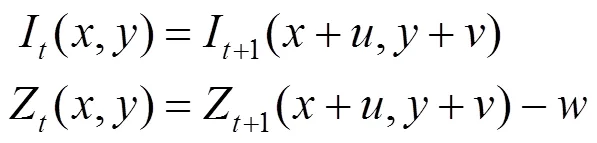
為方便計算,本文將軸的位移簡化為深度值在某一像素位置的變化,即該點所在像素位置的深度值變化,而非該點在軸方向的位移,簡化后為
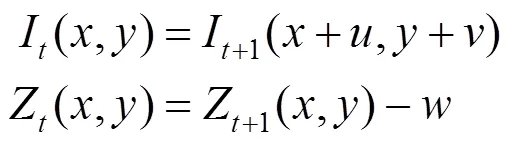
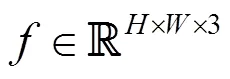
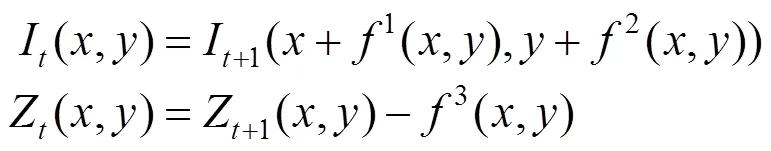
綜上,本文的任務場景流預測可以描述為:給定2張連續RGB-D圖像P,P+1,輸出P+1未來的場景流。
3 數據集
不同于傳統方法,深度學習方法需要大量包含真實標簽的數據作為基礎對模型進行訓練,而場景流、光流的真實標簽很難獲得,因為現實世界中正確的像素關聯無法輕易獲取。表1列舉了現有的數據集;現有的數據集缺少真實/仿真場景,且物體的運動未嚴格考慮物理規律;為彌補其不足,本文從常識推理和物理規律的角度出發,提出了新的數據集ModernCity,以推動向真實的物理場景推理邁進。
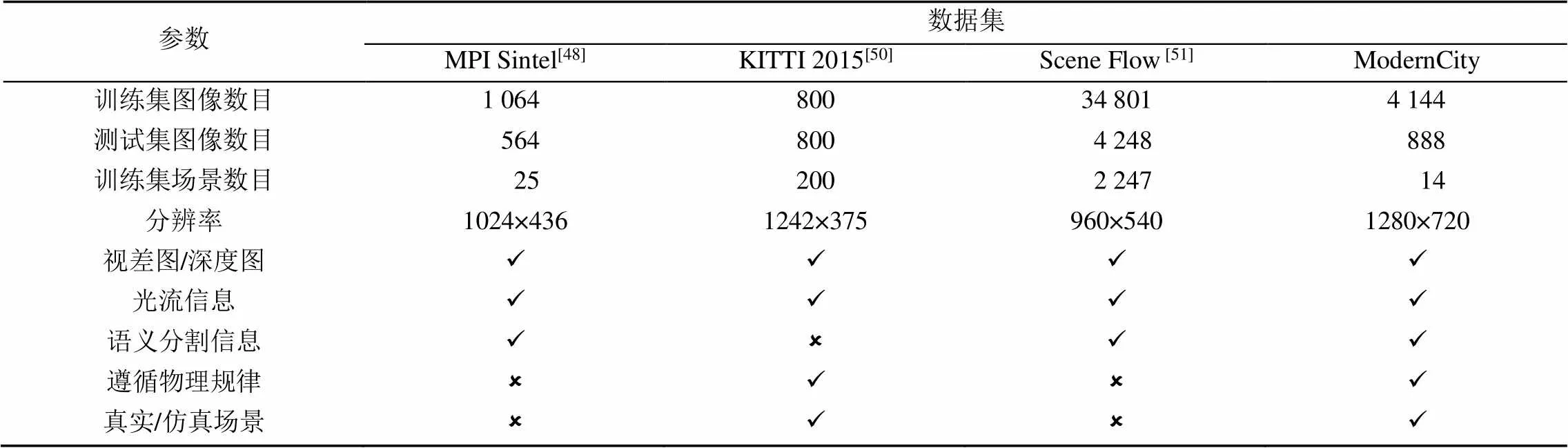
表1 現有的數據集與本文提出的ModernCity數據集之間的比較
注:ü表示數據集提供了此類型的標簽;?表示未提供
3.1 現有的數據集
(1) MPI Sintel數據集[48]源自開源的3D動畫電影,提供了光流的稠密真實標簽以及視差圖,訓練集中包含25個場景,1 064張圖像。作者花費了大量時間來驗證標簽的準確性,使其具有很高的可信度;但其數據量不大,不是真實場景,且物體的運動并未嚴格遵循物理規律。
(2) KITTI數據集在2012年被提出[49],并在2015年被擴展[50],其由立體相機在真實的道路場景拍攝組成,光流標簽和視差圖是由一個3D激光掃描儀結合汽車的運動數據得到的。然而激光僅能為場景中的靜態部分提供一定距離和高度的稀疏數據,運動的物體以及稠密的標簽是近似獲得的,且其數據量太小。
(3) Scene Flow數據集[51]是迄今最大的光流、場景流數據集,其使用Blender生成虛擬數據,提供真正的場景流標簽,包含FlyingThings3D,Monkaa和Driving 3個子數據集,訓練集中包括34 801對雙目圖像。大規模的數據讓深度學習估計光流成為可能,該數據集極大地推動了相關算法的發展;然而其未遵循物理規律,物理間的運動是隨機生成的。
3.2 ModernCity
如上節所述,現有的數據集在設計時均專注于光流/場景流估計,而常識推理方面未被顧及。Sintel數據集為卡通風格的圖像,與真實場景差別很大;KITTI數據集雖然取自于真實場景,但其稠密的場景流標簽是近似得到的,且數據量過小;Scene Flow數據集雖然規模龐大,但與真實場景相差甚遠,且不符合常識推理。
為解決常識推理在數據集方面的短缺,本文提出一個基于仿真場景的數據集ModernCity,使用Unreal Engine 4批量生成虛擬數據,該數據集包含有光流的稠密真實標簽、深度圖及語義分割信息,圖像分辨率1280×720,訓練集中包含14個場景,4 144張RGB-D圖像,其中一個實例如圖2所示。

圖2 ModernCity數據集的一個實例((a)RGB圖像;(b)稠密光流;(c)深度圖像;(d)語義信息)
場景的設計從常識推理出發,目標是還原現實生活中的場景。本文將范圍縮小至現代都市的街邊景象,包含有人物、寵物、車輛、飛機、鳥類以及雜物等;不同的物體有不同運動方式和運動軌跡,物體間存在物理關系,被碰撞時會遵循物理規律進行運動,例如雜物被拋擲時會沿拋物線做落體運動。上述的情況均是為常識推理服務。基于上述的規則,本文搭建了一個大型虛擬城市,如圖3所示。不同的場景取自虛擬城市的不同角落,并在視角上盡可能覆蓋了不同的高度與俯仰角,與現實世界城市中不同路段的監控攝像頭相似,如圖4所示。場景的布置和鏡頭的擺放等方面本文參考了Sintel數據集[48]。測試集與訓練集的視角間不存在重疊,并對不同場景中人物、物體的運動軌跡進行單獨設計,盡量擴大生成內容的差異性。

圖3 虛擬城市示意圖

圖4 不同場景的視角示意圖
此外,為保證數據的準確性,在數據和真實標簽生成參考了UnrealCV[52],光流、深度圖、語義信息的數值經過了嚴格的驗證。
4 物體描述子解碼模型ODD
認知與推理物理世界是一個復雜的過程,以人類認識世界的方式為參考,人們往往從物體的角度出發認知世界:①發現物體,并確定物體在世界中的位置;②分辨物體的種類,并推測其物理屬性,例如質量、密度、摩擦力等;③根據物體的屬性預測其未來一段時間內的狀態(運動軌跡、形態變化等)。本文以此為指導,設計了基于物體屬性的模型對場景流進行預測。
為了表示物體的屬性,本文將物體屬性抽象為特征向量并由神經網絡進行提取,這些特征向量被稱為物體描述子(object descriptor);此外本文提出了ODD模型(如圖1上半部分所示)對物體描述子進行解碼,為場景中的每個物體進行運動速度的預測。
4.1 物體描述子
每個物體都具有自己的屬性,如物體的質量、密度、摩擦力、位置、姿態、運動情況、物體的種類、是否有生命(決定了是否可以自主移動)等;為表示物體的屬性,本文將物體的屬性抽象為一個維的特征向量,稱為物體描述子,向量中的數值可以是具有實際物理意義的、顯式的,也可以是抽象的、隱式的。
物體描述子可以是人工標注的(對物體的屬性進行標簽標注),也可以是通過算法提取得到的特征向量。本文采用CNN作為特征提取算法對物體屬性進行提取。CNN具有很強的特征提取能力[53]:淺層卷積核負責提取低級的、具體的特征,例如物體的邊緣信息;中層的卷積核負責提取中級特征,例如物體的紋理信息;深層的卷積核負責提取高級的、抽象的特征,這些特征往往沒有具體的物理意義,但可以高度概括物體的屬性。神經網絡具有強大的學習能力,不同物體間所提取出的特征差異巨大,這些特征可以很好地表征物體的屬性,而且提取出的屬性通常比人工設計的屬性更加全面,這也是近年來深度學習迅猛發展的重要因素之一[54]。
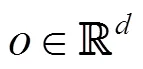
4.2 解碼模型
本文設計了一種基于物體描述子的解碼模型,主體使用反卷積層構建神經網絡,將維的物體描述子o解碼為場景流。由于物體描述子是一個特征向量,將其解碼為場景流的過程中需要不斷進行上采樣(upsampling)以推斷其空間信息,不斷豐富物體場景流的細節。反卷積(deconvolution)可以對輸入信號進行上采樣,其參數是由學習得到的,相比一些插值的方法(最近鄰插值等),反卷積可以根據不同物體的特征更好地推斷空間信息,生成更準確的場景流預測結果。
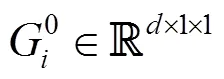
如圖5所示,解碼模型將物體描述子進行解碼,輸出該物體輪廓范圍內的速度信息。該模型可以根據物體的性質做出不同的預測,例如無生命的物體(紅色線框的箱子)傾向于靜止,而有自主意識的物體(藍色線框的人類和綠色線框的犬類)則傾向于運動。這說明該解碼模型能一定程度上理解每個物體的屬性,并根據前后2幀中屬性的變化推測下一幀中每個物體的運動速度。這與人們認知中人類對常識的理解近似,可以認為ODD模型有一定的常識推理能力。

圖5 解碼模型的預測結果
4.3 作為基準模型的初始值
解碼模型的輸入只有物體描述子,其缺乏圖像中的背景等全局信息,導致在單獨使用該模型時泛化能力較差,如圖6所示。預測的場景流中的物體輪廓大致正確,但存在明顯的鋸齒,邊緣細節較差,運動速度的方向與大小也預測得并不理想。
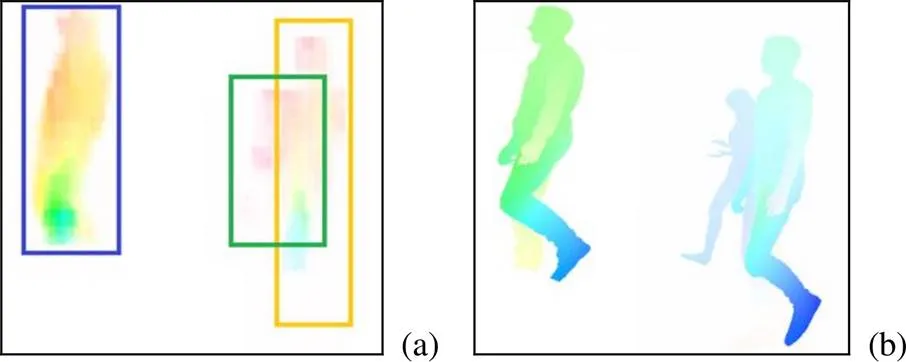
圖6 光流結果對比((a) ODD模型預測結果;(b)真實結果)
因此本文在使用ODD模型時,將其輸出作為基準模型的迭代初始值,如圖1所示。解碼模型負責根據物體屬性輸出的結果,作為初始值為基準模型提供一定的局部信息,在基準模型預測全局結果時可以向更加正確的方向進行迭代,且局部信息會在迭代中不斷增強,使得最終的預測結果在全局和局部都得到一定的改進。將基準模型和ODD模型進行結合后可以增強場景流的準確度,豐富預測結果的細節,例如人物的腿部、遠處的人物等。
4.4 損失函數
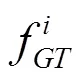
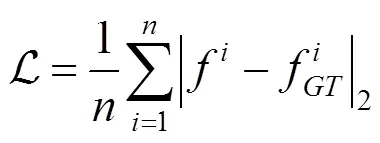
5 基準模型
鑒于場景流與光流之間的相似之處,本文從光流模型出發,對現有的光流估計模型進行修改,以作為場景流預測基準模型。經過多年的研究,光流估計逐漸由傳統迭代法轉變為深度學習方法,深度學習算法從最初的FlowNet[44],FlowNet2[45],發展為PWC-Net[46],再到如今的RAFT[47](recurrent all-pairs field transforms)。本文參考RAFT模型設計了預測場景流基準模型,該模型的基本結構如圖1下半部分所示,其由3個主要部分構成:①特征編碼網絡;②視覺相似度;③迭代更新。RAFT模型巧妙地將特征匹配與迭代更新進行了融合,兼顧了局部特征與全局特征。
5.1 特征編碼網絡
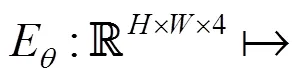
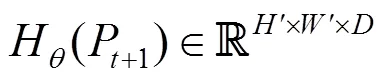
5.2 視覺相似度
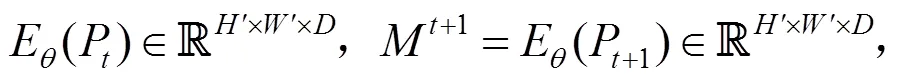
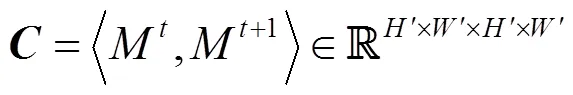
其中
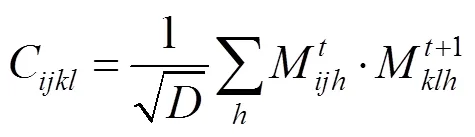
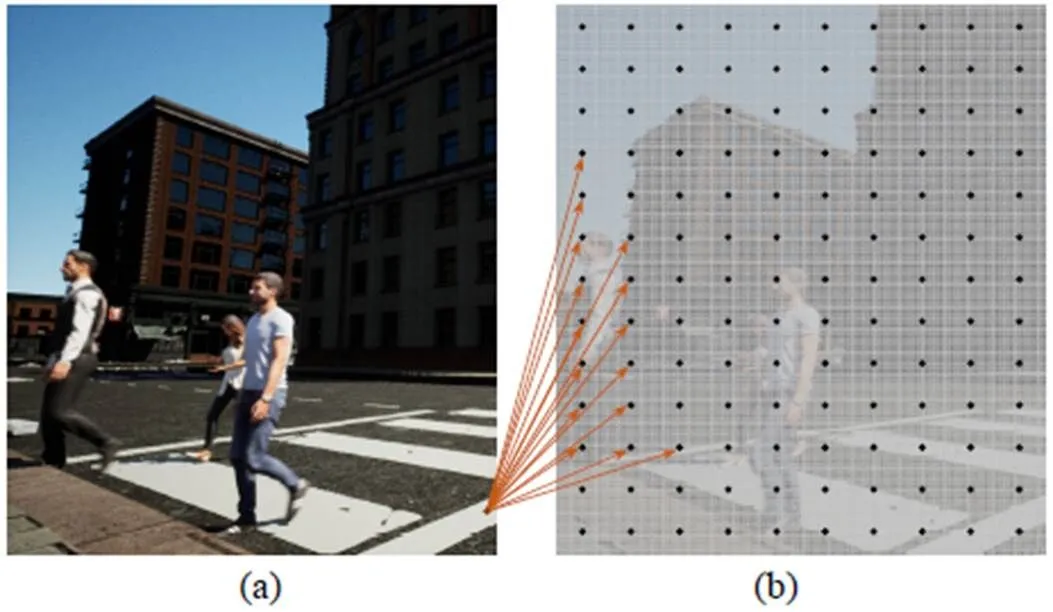
圖7 計算相似度張量C((a)特征圖M t;(b)特征圖M t+1)
基于相似度張量,定義一個相似度查詢操作,通過索引的方式提取相似度張量進而建立一個相似度特征圖。具體地,定義p=(,)為M中任意一點,p+1=(′,′)為M+1中的一點,通過p映射得到
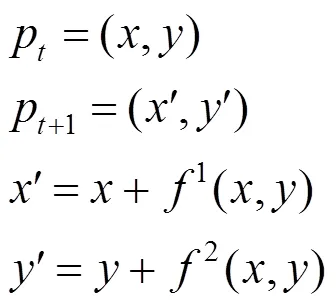
其中,1(,)和2(,)分別為點p的場景流在軸和軸方向的位移,在每個點p+1周圍定義一個領域點集,即
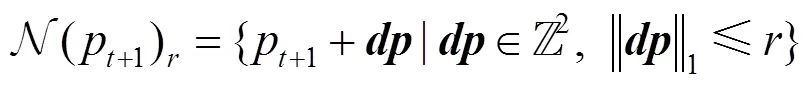
5.3 迭代更新
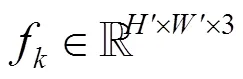
更新步驟的核心組成是一個基于GRU (gated recurrent unit)單元的門控激活單元[55],輸入為相似度特征圖、場景流f-1和上下文特征圖H(P+1),輸出為場景流的更新差值Δ。該算法旨在模擬優化算法,通過有界激活函數鼓勵其收斂至固定點,基于此目標對更新步驟進行訓練,使序列收斂到固定點f→f。計算過程為
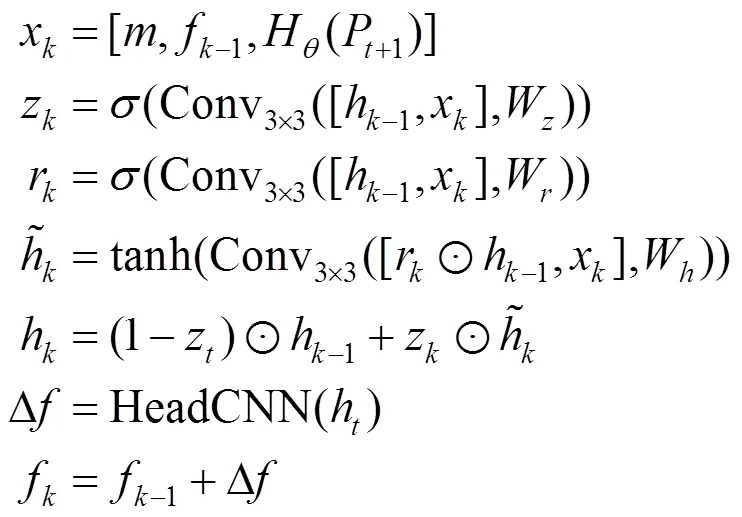
6 實驗與分析
為驗證本文提出的物體描述子解碼模型ODD的有效性,使用ModernCity數據集設計了若干組實驗。
6.1 評價指標
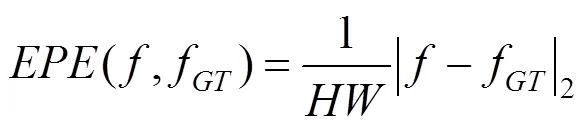
EPE的值越小,光流/場景流的準確度越高。
6.2 實現細節
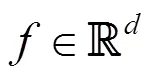
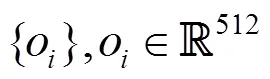
6.3 訓練細節
為了驗證ODD模型的有效性,在ModernCity數據集上進行訓練,實現工具為PyTorch[58],模型中所有的參數都是隨機初始化的。訓練時使用AdamW優化器[59],學習率為1×10-4,最大迭代次數為1 000 000次,批大小(batch size)為6,梯度裁剪至[-1,1]的范圍。此外在訓練RAFT模型時,對于每次迭代f-1+Δ,本文遵循文獻[60]建議,f-1反向傳播的梯度置零,僅將Δ的梯度進行回傳。
訓練策略上,本文采用了分步訓練的方式:①訓練基準模型:對基準模型進行單獨訓練,設基準模型中場景流的迭代初始值0=0;②聯合訓練:對ODD模型與基準模型中的GRU單元進行聯合訓練,對訓練后的基準模型中的特征編碼網絡E和上下文網絡H進行參數固定,此時基準模型中場景流的迭代初始值0由ODD模型提供。
6.4 消融實驗
為了驗證提出的ODD模型是否有效,以及物體描述子是否可以幫助常識學習,本文設計了表2的消融實驗。表中的第一行是單獨使用基準模型的情況,其中場景流的迭代初始值0= 0;第二行是使用ODD模型的輸出作為基準模型的迭代初始值。基準模型+ODD模型相比基準模型EPE指標提升5%,該結果從定量的角度出發,對模型的有效性上進行了證明。從圖8可知,基準模型+ODD模型明顯優于基準模型的預測結果,物體輪廓、局部細節與場景流的數值都更加準確。結合4.2節中分析ODD模型能一定程度地理解每個物體的屬性,并根據前后兩幀中屬性的變化推測出每個物體的運動速度。圖5和圖8從定性的角度出發,證明ODD模型有一定的常識推理能力。
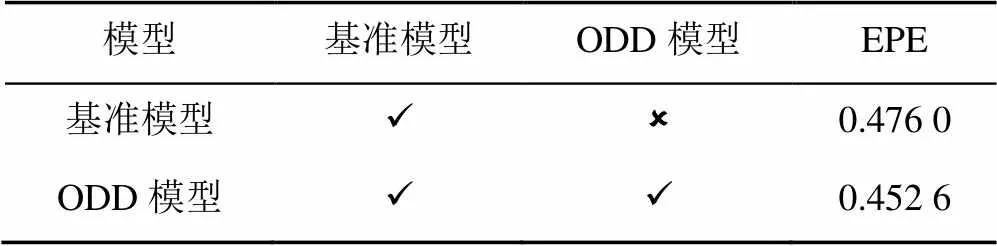
表2 消融實驗結果
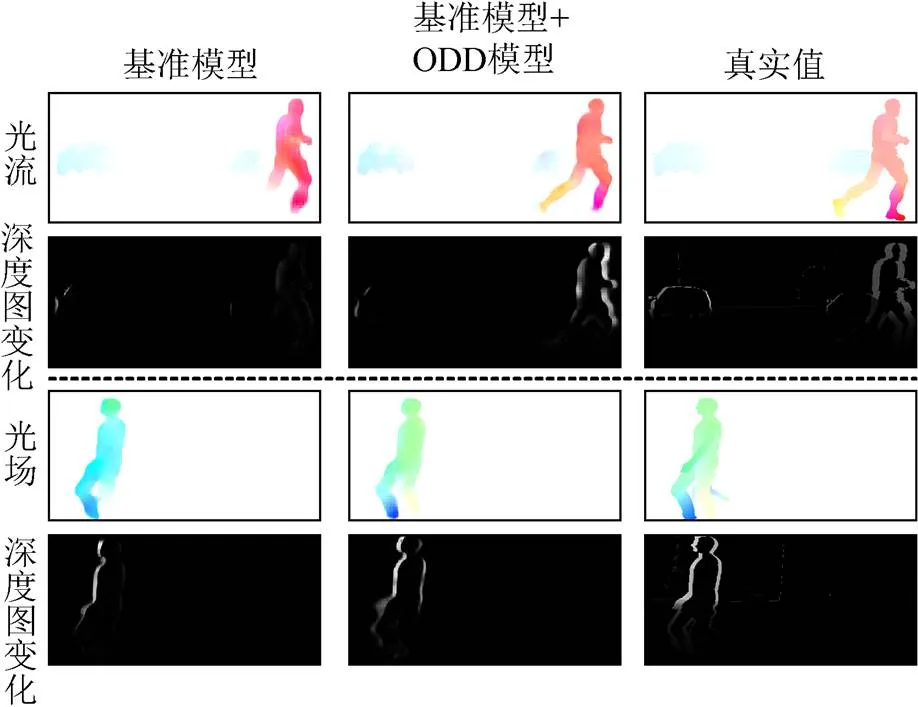
圖8 消融實驗對比圖
上述實驗表明ODD模型可以通過物體屬性幫助物體運動的預測,說明物體描述子可以一定程度上幫助常識推理,證明本文從人類認識世界的方式(從物體的角度認識世界)出發有一定的合理性。
6.5 對比實驗
為驗證本文所提出算法的性能及數據集的可靠性,表3在ModernCity場景流預測任務中使用不同的SOTA模型進行對比,結果表明本文提出的模型效果最好,可以從常識推理的角度出發,更準確地預測場景流。

表3 對比實驗結果
7 結 論
本文從使用物理屬性預測物體的三維運動速度出發,將之前相關工作擴展至仿真的情景,提出新的數據集ModernCity以彌補相關數據集的短缺;設計了ODD模型,并通過實驗結果證明ODD模型具有在仿真場景下通過物體屬性預測運動的能力,為常識學習向真實邁進做出了貢獻。
[1] 唐杰. 淺談人工智能的下一個十年[J]. 智能系統學報, 2020, 15(1): 187-192.
TANG J. On the next decade of artificial intelligence[J]. CAAI Transactions on Intelligent Systems, 2020, 15(1): 187-192 (in Chinese).
[2] WU J J, LIM J J, ZHANG H Y, et al. Physics 101: learning physical object properties from unlabeled videos[C]//The 27th British Machine Vision Conference. New York: BMVA Press, 2016: 1-12.
[3] WU J J, LU E, KOHLI P, et al. Learning to see physics via visual de-animation[C]//The 31th International Conference on Neural Information Processing Systems. New York: ACM Press, 2017: 153-164.
[4] LOCATELLO F, WEISSENBORN D, UNTERTHINER T, et al. Object-centric learning with slot attention[EB/OL]. [2021-07-03]. https://arxiv.org/abs/2006.15055.
[5] ZHENG D, LUO V, WU J J, et al. Unsupervised learning of latent physical properties using perception-prediction networks[EB/OL]. [2021-05-30]. https://arxiv.org/abs/1807. 09244.
[6] ZHANG R Q, WU J J, ZHANG C K, et al. A comparative evaluation of approximate probabilistic simulation and deep neural networks as accounts of human physical scene understanding[EB/OL]. [2021-08-01]. https://arxiv.org/abs/ 1605.01138.
[7] CHANG M B, ULLMAN T, TORRALBA A, et al. A compositional object-based approach to learning physical dynamics[EB/OL]. [2021-04-28]. https://arxiv.org/abs/1612. 00341.
[8] BATTAGLIA P W, PASCANU R, LAI M, et al. Interaction networks for learning about objects, relations and physics[C]// The 30th International Conference on Neural Information Processing Systems. New York: ACM Press, 2016: 4502-4510.
[9] GUPTA A, EFROS A A, HEBERT M. Blocks world revisited: image understanding using qualitative geometry and mechanics[C]//2010 European Conference on Computer Vision. Cham: Springer International Publishing, 2010: 482-496.
[10] SHAO T J, MONSZPART A, ZHENG Y Y, et al. Imagining the unseen[J]. ACM Transactions on Graphics, 2014, 33(6): 1-11.
[11] EHRHARDT S, MONSZPART A, MITRA N J, et al. Learning A physical long-term predictor[EB/OL]. [2021-06-14]. https:// arxiv.org/abs/1703.00247.
[12] PINTEA S L, VAN GEMERT J C, SMEULDERS A W M. Déjà Vu: motion prediction in static images[C]//The 13th European Conference on Computer Vision. Cham: Springer International Publishing, 2014: 172-187.
[13] LERER A, GROSS S, FERGUS R. Learning physical intuition of block towers by example[EB/OL]. [2021-05-07]. https:// arxiv.org/abs/1603.01312.
[14] PINTO L, GANDHI D, HAN Y F, et al. The curious robot: learning visual representations via physical interactions[C]// The 14th European Conference on Computer Vision. Amsterdam: Springer, 2016: 3-18.
[15] AGRAWAL P, NAIR A, ABBEEL P, et al. Learning to poke by poking: experiential learning of intuitive physics[EB/OL]. [2021-06-19]. https://arxiv.org/abs/1606.07419.
[16] FRAGKIADAKI K, AGRAWAL P, LEVINE S, et al. Learning visual predictive models of physics for playing billiards[EB/OL]. [2021-08-01]. https://arxiv.org/abs/1511. 07404.
[17] MOTTAGHI R, RASTEGARI M, GUPTA A, et al. “What happens if ···” learning to predict the effect of forces in images[C]//The 14th European Conference on Computer Vision. Cham: Springer International Publishing, 2016: 269-285.
[18] HAMRICK J B, BALLARD A J, PASCANU R, et al. Metacontrol for adaptive imagination-based optimization[EB/OL]. [2021-07-15]. https://arxiv.org/abs/1705.02670.
[19] JIA Z Y, GALLAGHER A C, SAXENA A, et al. 3D reasoning from blocks to stability[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(5): 905-918.
[20] MOTTAGHI R, BAGHERINEZHAD H, RASTEGARI M, et al. Newtonian image understanding: unfolding the dynamics of objects in static images[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 3521-3529.
[21] ZHENG B, ZHAO Y B, YU J, et al. Scene understanding by reasoning stability and safety[J]. International Journal of Computer Vision, 2015, 112(2): 221-238.
[22] BATTAGLIA P W, HAMRICK J B, TENENBAUM J B. Simulation as an engine of physical scene understanding[J]. Proceedings of the National Academy of Sciences of the United States of America, 2013, 110(45): 18327-18332.
[23] FINN C, GOODFELLOW I, LEVINE S. Unsupervised learning for physical interaction through video prediction[C]// The 30th International Conference on Neural Information Processing Systems. New York: ACM Press, 2016: 64-72.
[24] WALKER J, GUPTA A, HEBERT M. Dense optical flow prediction from a static image[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2443-2451.
[25] JI D H, WEI Z, DUNN E, et al. Dynamic visual sequence prediction with motion flow networks[C]//2018 IEEE Winter Conference on Applications of Computer Vision. New York: IEEE Press, 2018: 1038-1046.
[26] L?WE S, GREFF K, JONSCHKOWSKI R, et al. Learning object-centric video models by contrasting sets[EB/OL]. [2021-06-13]. https://arxiv.org/abs/2011.10287.
[27] LI Y Z, WU J J, TEDRAKE R, et al. Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids[EB/OL]. [2021-04-28]. https://arxiv.org/abs/1810. 01566.
[28] CHAABANE M, TRABELSI A, BLANCHARD N, et al. Looking ahead: anticipating pedestrians crossing with future frames prediction[C]//2020 IEEE Winter Conference on Applications of Computer Vision. New York: IEEE Press, 2020: 2286-2295.
[29] DING D, HILL F, SANTORO A, et al. Attention over Learned Object Embeddings Enables Complex Visual Reasoning[C]// Advances in Neural Information Processing Systems. New York: Curran Associates, Inc., 2021.
[30] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2009: 248-255.
[31] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[32] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. [2021-05-20]. https://arxiv.org/abs/1409.1556.
[33] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 770-778.
[34] SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 1-9.
[35] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 7132-7141.
[36] CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? A new model and the kinetics dataset[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 4724-4733.
[37] LIU X, YANG X D. Multi-stream with deep convolutional neural networks for human action recognition in videos[C]// The 25th International Conference on Neural Information Processing. Cham: Springer International Publishing, 2018: 251-262.
[38] WANG L M, XIONG Y J, WANG Z, et al. Temporal segment networks: towards good practices for deep action recognition[EB/OL]. [2021-06-10]. https://arxiv.org/abs/1608. 00859.
[39] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[40] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. [2021-07-19]. https://arxiv.org/abs/ 1804.02767.
[41] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[EB/OL]. [2021-07-15]. https://arxiv.org/ abs/1512.02325.
[42] HE K M, GKIOXARI G, DOLLáR P, et al. Mask R-CNN[C]// 2017 IEEE International Conference on Computer Vision. New York: IEEE Press, 2017: 2980-2988.
[43] RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation[C]// 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich: Springer, 2015: 234-241.
[44] DOSOVITSKIY A, FISCHER P, ILG E, et al. FlowNet: learning optical flow with convolutional networks[C]//2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 2758-2766.
[45] ILG E, MAYER N, SAIKIA T, et al. FlowNet 2.0: evolution of optical flow estimation with deep networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1647-1655.
[46] SUN D Q, YANG X D, LIU M Y, et al. PWC-net: CNNs for optical flow using pyramid, warping, and cost volume[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 8934-8943.
[47] TEED Z, DENG J. RAFT: recurrent all-pairs field transforms for optical flow[EB/OL]. [2021-08-19]. https://arxiv.org/abs/ 2003.12039.
[48] BUTLER D J, WULFF J, STANLEY G B, et al. A naturalistic open source movie for optical flow evaluation[C]//2012 European conference on Computer Vision. Heidelberg: Springer, 2012: 611-625.
[49] GEIGER A, LENZ P, STILLER C, et al. Vision meets robotics: The KITTI dataset[J]. The International Journal of Robotics Research, 2013, 32(11): 1231-1237.
[50] MENZE M, GEIGER A. Object scene flow for autonomous vehicles[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 3061-3070.
[51] MAYER N, ILG E, H?USSER P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 4040-4048.
[52] QIU W C, ZHONG F W, ZHANG Y, et al. UnrealCV: virtual worlds for computer vision[C]//The 25th ACM International Conference on Multimedia. New York: ACM Press, 2017: 1221-1224.
[53] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]//2014 European Conference on Computer Vision. Cham: Springer International Publishing, 2014: 818-833.
[54] O’MAHONY N, CAMPBELL S, CARVALHO A, et al. Deep learning vs. traditional computer vision[C]//2019 Computer Vision Conference. Cham: Springer International Publishing, 2019: 128-144.
[55] CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder–decoder for statistical machine translation[C]//The 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2014: 1724-1734.
[56] LIN T Y, DOLLáR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 936-944.
[57] CHEN X L, FANG H, LIN T Y, et al. Microsoft COCO captions: data collection and evaluation server[EB/OL]. [2021-06-09]. http://de.arxiv.org/pdf/1504.00325.
[58] PASZKE A, GROSS S, CHINTALA S, et al. Pytorch: an imperative style, high-performance deep learning library[EB/OL]. [2021-07-20]. https://arxiv.org/abs/1912.01703.
[59] LOSHCHILOV I, HUTTER F. Decoupled weight decay regulariza[2021-06-15]. https://arxiv.org/abs/1711.05101.
[60] HOFINGER M, BULò S R, PORZI L, et al. Improving optical flow on a pyramid level[M]//The 16th European Conference on Computer Vision. Cham: Springer International Publishing, 2020: 770-786.
Scene flow prediction with simulated real scenarios
MEI Hai-yi1,2,3, ZHU Xiang-yu2,3, LEI Zhen2,3, GAO Rui1, MA Xi-bo2,3
(1.School of Control Science and Engineering, Shandong University, Jinan Shandong 250061, China;2. Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China;3. School of Artificial Intelligence, University of Chinese Academy of Sciences, Beijing 100049, China)
Artificial intelligence is stepping into the age of cognition, the ability of cognizing and inferring the physical world for machines needs to be improved. Recent works about exploring the physical properties of objects and predicting the motion of objects are mostly constrained by simple objects and scenes. We attempted to predict the scene flow of objects in simulated scenarios to extend common sense cognizing. First, due to the lack of data in the related field, a dataset calledbased on simulated scenarios is proposed, which contains the street scene of modern cities designed from the perspective of cognizing common sense, and provides RGB images, depth maps, scene flow, and semantic segmentations. In addition, we design an object descriptor decoder (ODD) to predict the scene flow through the properties of the objects. The model we proposed is proved to have the ability to predict future motion accurately through the properties of objects in simulated scenarios by experiments. The comparison experiment with other SOTA models demonstrates the performance of the model and the reliability of the ModernCity dataset.
common sense cognizing; scene flow; simulated scenarios; properties of objects; motion prediction
TP 391
10.11996/JG.j.2095-302X.2022030404
A
2095-302X(2022)03-0404-10
2021-09-14;
2021-12-21
14 September,2021;
21 December,2021
國家重點研究計劃項目(2016YFA0100900,2016YFA0100902);NSFC-山東聯合基金項目(U1806202);國家自然科學基金項目(81871442,61876178,61806196,61976229,61872367);中國科學院青年創新促進會項目(Y201930)
National Key Research Programs of China (2016YFA0100900, 2016YFA0100902); Natural Science Foundation of China Under Grant (U1806202); Chinese National Natural Science Foundation Projects (81871442, 61876178, 61806196, 61976229, 61872367); Youth Innovation Promotion Association CAS (Y201930)
梅海藝(1997?),男,碩士研究生。主要研究方向為計算機視覺、計算機圖形學和深度學習等。E-mail:haiyimei@mail.sdu.edu.cn
MEI Hai-yi (1997?), master student. His main research interests cover computer vision, computer graphics and deep learning, etc. E-mail:haiyimei@mail.sdu.edu.cn
高 瑞(1975?),男,教授,博士。主要研究方向為混合動力系統、最優控制理論、分子生物學數學建模、系統生物學等。Email:gaorui@sdu.edu.cn
GAO Rui (1975?), professor, Ph.D. His main research interests cover hybrid power systems, optimal control theory, molecular biology mathematical modeling, systems biology, etc. E-mail:gaorui@sdu.edu.cn
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
井岡教育(2022年2期)2022-10-14 03:11:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
云南教育·中學教師(2020年9期)2020-11-16 00:27:58
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
中學生數理化·八年級物理人教版(2017年9期)2017-12-20 08:11:28
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
