基于高相關(guān)區(qū)域上最小角回歸的華南初夏暴雨日數(shù)預(yù)測(cè)
2022-07-01 23:37:12閆文杰劉圣軍劉新儒彭謙胡婭敏
數(shù)學(xué)理論與應(yīng)用 2022年2期
閆文杰 劉圣軍 劉新儒 彭謙 胡婭敏
(1. 中南大學(xué)數(shù)學(xué)與統(tǒng)計(jì)學(xué)院,長沙,410075?2. 中國人民大學(xué)統(tǒng)計(jì)學(xué)院,北京,100872?3. 廣東省氣候中心,廣州,510080)
1 引言
華南地區(qū)地處中國南部,屬熱帶、亞熱帶季風(fēng)氣候區(qū),具有非常顯著的季風(fēng)氣候特征,形成暴雨的天然條件位居我國前列[1],故暴雨發(fā)生較為頻繁,其中初夏為暴雨頻數(shù)最多的時(shí)段之一. 研究華南地區(qū)暴雨日數(shù)的時(shí)空分布特征,并選取合適模型進(jìn)行暴雨日數(shù)的預(yù)測(cè),在極端天氣時(shí)間預(yù)測(cè)方面具有重要的應(yīng)用價(jià)值.
對(duì)于暴雨日數(shù)預(yù)測(cè)問題,前人已進(jìn)行過許多相關(guān)研究. 在因子選取方面,簡茂球等[2]在2013 年利用相關(guān)系數(shù)法指出海南持續(xù)性暴雨天氣與熱帶大氣的準(zhǔn)雙周振蕩有關(guān),并將海溫納入分析范疇,發(fā)現(xiàn)2010 年在赤道中東太平洋發(fā)生的La Ni?a 現(xiàn)象有利于產(chǎn)生大氣準(zhǔn)雙周低頻振蕩. 在抽樣方法方面,為解決暴雨預(yù)測(cè)中類別不平衡問題,楊艷等[3]將減抽樣的思想應(yīng)用于AdaBoost 綜合學(xué)習(xí)算法[4]中. 實(shí)驗(yàn)結(jié)果表明,相對(duì)于傳統(tǒng)的AdaBoost 算法[5],該算法對(duì)銅川暴雨日數(shù)的預(yù)報(bào)準(zhǔn)確率顯著提高. 在預(yù)測(cè)方法方面,劉綠柳等[6]應(yīng)用一步法和兩步法兩種統(tǒng)計(jì)降尺度方法預(yù)測(cè)暴雨日數(shù),并提出了用標(biāo)準(zhǔn)差作為評(píng)估暴雨日數(shù)異常等級(jí)的評(píng)分標(biāo)準(zhǔn).文中交叉檢驗(yàn)的結(jié)果顯示這兩種方法對(duì)于月尺度降水與暴雨日數(shù)的預(yù)測(cè)都具有較好的效果.
除了以上傳統(tǒng)的方法, 近年來人工神經(jīng)網(wǎng)絡(luò)在氣象領(lǐng)域也得到了廣泛應(yīng)用. 葛彩蓮等[7]在2010 年應(yīng)用BP 神經(jīng)網(wǎng)絡(luò)對(duì)降雨量進(jìn)行預(yù)測(cè), 發(fā)現(xiàn)使用前5 年降雨量來預(yù)測(cè)后1 年的降雨量的效果與用氣象資料預(yù)測(cè)降雨量的效果相近,讓這種新預(yù)測(cè)模式應(yīng)用于降水預(yù)測(cè)成為可能. 黎玥君等[8]在2017 年基于BP 神經(jīng)網(wǎng)絡(luò)預(yù)測(cè)浙北夏季降水,發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)隱藏層節(jié)點(diǎn)數(shù)量為2 時(shí),擬合降水量的效果最佳. 關(guān)鵬洲等[9]在2017 年提出了基于梯度提升決策樹(GBDT)特征選擇的改進(jìn)AdaBoost 回歸模型、基于多個(gè)強(qiáng)回歸器組合的stacking 回歸模型,和Inception 卷積神經(jīng)網(wǎng)絡(luò)對(duì)數(shù)據(jù)集進(jìn)行分類和回歸,獲得了對(duì)短期降雨較好的預(yù)測(cè)效果.
前人的研究成果從數(shù)據(jù)處理到模型構(gòu)建,都為本文提供了寶貴的思路,但也存在亟待改善的地方. 大多數(shù)研究工作采用EOF 分解、獨(dú)立分量分析等傳統(tǒng)機(jī)器學(xué)習(xí)方法提取特征,選用常用的平均絕對(duì)誤差、相對(duì)偏差[8]、Ts 評(píng)分[3]等指標(biāo)進(jìn)行模型檢驗(yàn).然而,傳統(tǒng)方法算法簡單,更適合于線性關(guān)系建模,且常用檢驗(yàn)指標(biāo)不能全面有效地對(duì)結(jié)果進(jìn)行評(píng)估.為改善上述問題,本文引入新的特征提取方法與檢驗(yàn)方法.
2 研究方法
2.1 數(shù)據(jù)
降水?dāng)?shù)據(jù)來源于中國氣象局國家氣象信息中心和廣東省氣候中心數(shù)據(jù)庫. 本文選用1981 年至2018 年華南地區(qū)192 個(gè)站點(diǎn)的數(shù)據(jù). 選取的5 個(gè)環(huán)流要素場(chǎng)來自于NCEP/NCAR 再分析資料的月數(shù)據(jù),分別為: 高度場(chǎng)(hgt),經(jīng)向風(fēng)場(chǎng)(vwnd),緯向風(fēng)場(chǎng)(uwnd),比濕(shum),海平面氣壓(slp),其中水平分辨率為2.5°×2.5°?海溫?cái)?shù)據(jù)選用NOAA ERSST V3b 海表溫度(SST),水平分辨率為2.0°×2.0°?海冰數(shù)據(jù)來自NOAA 北半球逐月海冰資料?積雪逐月數(shù)據(jù)由Rutgers University Global Snow Lab 提供(包括北美洲、北半球、歐亞大陸積雪數(shù)據(jù)). 數(shù)據(jù)如表1所示.
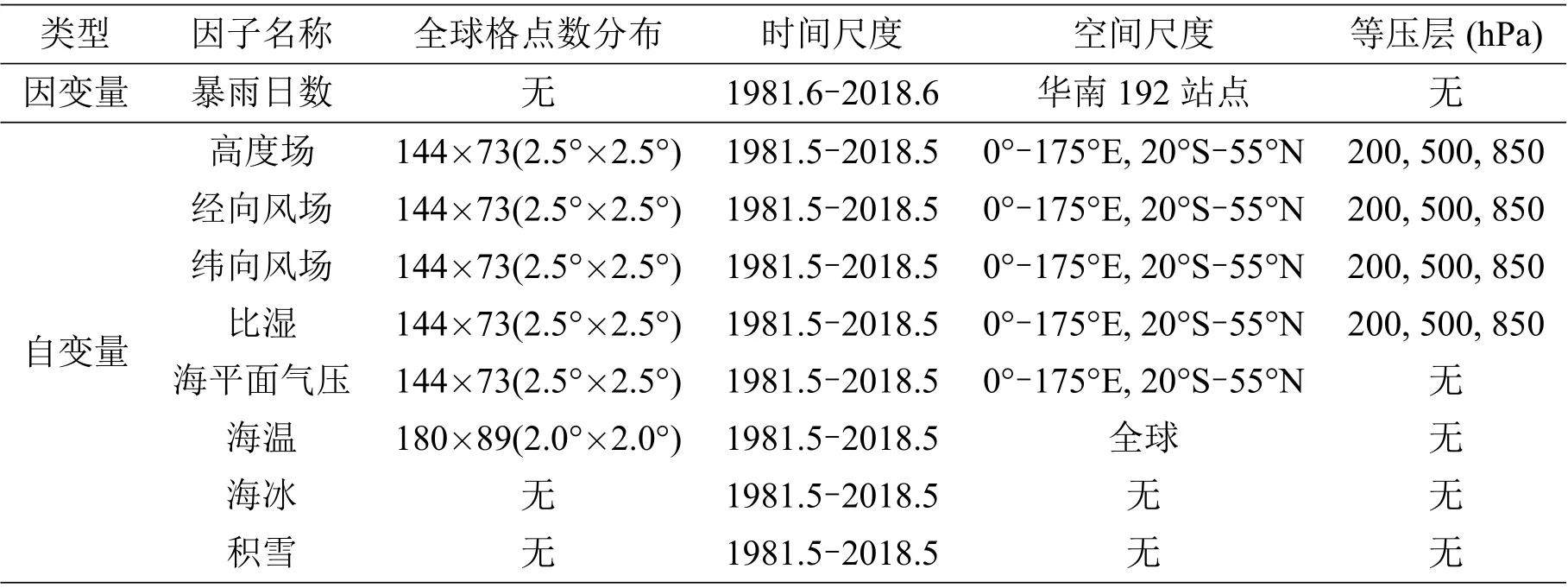
表1 詳細(xì)數(shù)據(jù)表格
根據(jù)廣東省氣候中心暴雨閾值標(biāo)準(zhǔn),24 小時(shí)單站降水量超過50mm 的日數(shù)定義為暴雨日數(shù).本文主要研究提前一個(gè)月的要素場(chǎng)對(duì)華南地區(qū)初夏暴雨日數(shù)的影響,因此選取當(dāng)年5 月的要素作為預(yù)報(bào)因子來預(yù)測(cè)華南地區(qū)初夏暴雨日數(shù).
對(duì)于部分預(yù)測(cè)因子,由于缺測(cè)或無法測(cè)量(如海溫?cái)?shù)據(jù)只能在海洋區(qū)域測(cè)出,陸地區(qū)域無法測(cè)量)等原因,會(huì)在某些格點(diǎn)或時(shí)間點(diǎn)出現(xiàn)異常數(shù)據(jù). 本文對(duì)異常值直接剔除. 為了消除預(yù)報(bào)因子之間的量綱影響,本文采用z score 方法對(duì)數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理:

其中,zij為對(duì)每個(gè)格點(diǎn)(第i行,第j列)數(shù)據(jù)求標(biāo)準(zhǔn)化后的值,xij為初始值, ˉxi為第i行數(shù)據(jù)的平均值,si為第i行數(shù)據(jù)的標(biāo)準(zhǔn)差.
2.2 統(tǒng)計(jì)降尺度方法框架
統(tǒng)計(jì)降尺度法是利用大氣環(huán)流的觀測(cè)資料建立大尺度氣候要素和區(qū)域氣候要素之間的統(tǒng)計(jì)關(guān)系,并把這種關(guān)系應(yīng)用于大氣環(huán)流模式中輸出大尺度氣候信息,進(jìn)而預(yù)測(cè)區(qū)域未來氣候變化的一種常用方法[10]. 其基本思路是建立大尺度預(yù)報(bào)因子和區(qū)域氣候預(yù)報(bào)量之間的統(tǒng)計(jì)關(guān)系函數(shù)[11]:

其中,y是區(qū)域氣候預(yù)報(bào)量(氣溫,降水等),x是大尺度預(yù)報(bào)因子,F(·)為建立的統(tǒng)計(jì)關(guān)系函數(shù),使用最廣泛的是轉(zhuǎn)換函數(shù). 統(tǒng)計(jì)降尺度基本流程如圖1所示: 在暴雨日數(shù)預(yù)報(bào)問題中,由于選取的預(yù)報(bào)因子較多,且環(huán)流預(yù)報(bào)因子為二維格點(diǎn)數(shù)據(jù),樣本數(shù)量有限,傳統(tǒng)機(jī)器學(xué)習(xí)模型會(huì)存在嚴(yán)重的過擬合現(xiàn)象. 緩解過擬合的方法主要有兩種[12]:
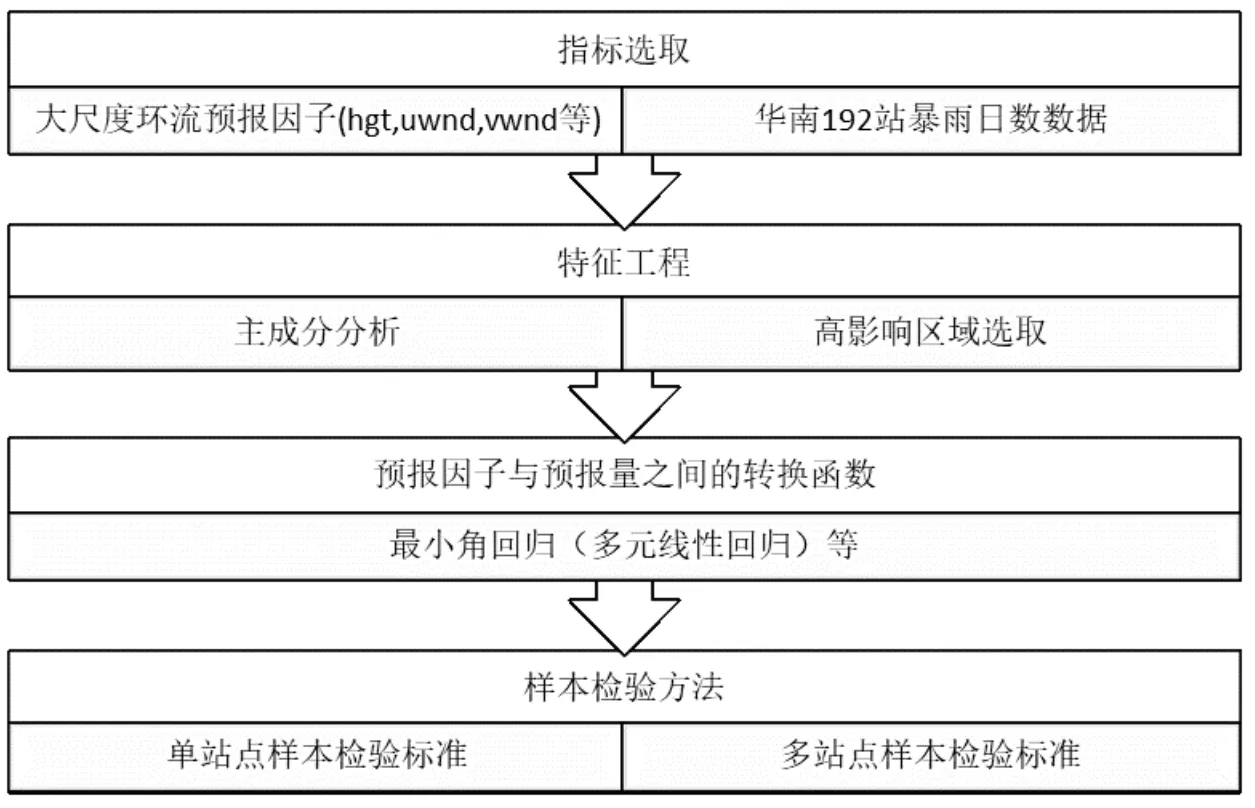
圖1 統(tǒng)計(jì)降尺度方法框架圖
(1)降低預(yù)報(bào)因子維度. 可通過篩選顯著相關(guān)因子和選取高相關(guān)區(qū)域格點(diǎn)數(shù)據(jù)并取區(qū)域平均值的方法來減少維度.
(2)將模型正則化,減少特征參數(shù)的數(shù)量級(jí).
本文采用高相關(guān)區(qū)域選取的方法來提取特征,使用最小角回歸的方法獲取預(yù)報(bào)因子與預(yù)報(bào)量之間的轉(zhuǎn)換函數(shù). 接下來分別詳細(xì)討論這兩個(gè)方法.
2.3 高相關(guān)區(qū)域提取方法
再分析資料數(shù)據(jù)是包含時(shí)間和空間信息的多維格點(diǎn)數(shù)據(jù). 預(yù)測(cè)過程中我們只關(guān)注與華南初夏暴雨有相關(guān)性的格點(diǎn)數(shù)據(jù),因此通常會(huì)將某個(gè)時(shí)間點(diǎn)的空間數(shù)據(jù)重組成一維數(shù)據(jù). 例如,由于本文中環(huán)流場(chǎng)的經(jīng)緯度范圍分別為0°–175°E,20°S–55°N,分辨率為2.5×2.5,某一時(shí)間點(diǎn)的200hPa 高度場(chǎng)數(shù)據(jù)經(jīng)度方向71 個(gè)數(shù)據(jù),緯度方向31 個(gè)數(shù)據(jù),進(jìn)行一維重組后,成為維度為2201 的一維向量.但由于相鄰格點(diǎn)數(shù)據(jù)相關(guān)性很高,必然導(dǎo)致模型產(chǎn)生嚴(yán)重的多重共線性及過擬合現(xiàn)象. 因此,我們需要對(duì)數(shù)據(jù)進(jìn)行預(yù)處理. 提取高相關(guān)區(qū)域是一種有效的數(shù)據(jù)降維方法. 本文使用預(yù)報(bào)因子各格點(diǎn)與單站點(diǎn)時(shí)間序列數(shù)據(jù)的線性相關(guān)系數(shù)來提取預(yù)報(bào)因子的高相關(guān)區(qū)域,其選取操作流程如圖2所示.

圖2 高相關(guān)區(qū)域選擇操作流程
以高度場(chǎng)數(shù)據(jù)與廣東佛岡站點(diǎn)的初夏暴雨日數(shù)的相關(guān)性分析為例,我們選擇時(shí)間范圍為1981年5 月至2018 年5 月,空間范圍為0°–175°E,20°S–55°N 的500hPa 高度場(chǎng)格點(diǎn)數(shù)據(jù)與廣東佛岡站點(diǎn)初夏暴雨日數(shù)進(jìn)行相關(guān)性分析,得到空間相關(guān)情況如圖3所示. 設(shè)定顯著性水平為0.05,可得高相關(guān)區(qū)域數(shù)為6,即有6 個(gè)區(qū)域的格點(diǎn)數(shù)據(jù)與因變量的相關(guān)系數(shù)較大. 由此可得,自變量的維數(shù)由原來的2201 維變成6 維.

圖3 500hPa 高度場(chǎng)與暴雨日數(shù)相關(guān)情況(以佛岡站點(diǎn)為例)
2.4 最小角回歸預(yù)測(cè)模型
在常用逐步回歸方法中,參數(shù)選擇可采用前向選擇算法和前向梯度算法. 然而,這兩種算法比較暴力,效率較低. Bradly Efron 在2004 年發(fā)表的文章中提出了一種新的算法——最小角回歸(LAR)算法[13]. 該算法保留了前向梯度算法的精確性,同時(shí)簡化了迭代的過程,步驟如下[13,14]:
Step 1: 設(shè)有n個(gè)經(jīng)過了標(biāo)準(zhǔn)化的自變量xk(k= 1,2,··· ,n),中心化的因變量y. 計(jì)算所有自變量與y的相關(guān)系數(shù)并排序,選出相關(guān)系數(shù)最大的一個(gè)自變量,不妨設(shè)為x1,滿足

其中r(x,y)表示x與y之間的相關(guān)系數(shù). 此時(shí)將x1加入逼近y的特征集合中.
Step 2: 在x1方向上用x1逼近y,選擇步長θ1,得到下列回歸方程

其中θ1表示回歸系數(shù), ˉy表示y在x1方向上的斜向投影,且

定義殘差

選取θ1使得存在一個(gè)未被選取的自變量,不妨設(shè)為x2,滿足

此時(shí),殘差yres位于x1和x2的角平分線上. 將x2加入逼近y的特征集合中.
Step 3: 在Step 2 得到的角平分線方向上前進(jìn)步長θ2,按上述方法更新殘差yres,使得存在另一個(gè)未被選取的自變量,不妨設(shè)為x3,滿足

Step 4: 循環(huán)上述步驟, 直到殘差‖yres‖2小于給定的值? 或者已經(jīng)遍歷了所有自變量xk(k=1,2,··· ,n),算法停止.
從幾何角度分析,每一步選擇的前進(jìn)路徑必須保證已選入模型的變量xk與殘差yres的角度最小(即“最小角”). 因此算法每一次都選擇原路徑與新變量夾角的角平分線方向作為新的前進(jìn)路徑方向.
最小角回歸算法是一個(gè)適用于高維數(shù)據(jù)的回歸算法. 該算法的最壞時(shí)間復(fù)雜度和最小二乘法類似,但計(jì)算速度卻能與前向選擇算法一樣快. 同時(shí),該方法可以產(chǎn)生分段線性結(jié)果的完整路徑,在模型的交叉驗(yàn)證中極為方便.
2.5 評(píng)價(jià)檢驗(yàn)
2.5.1 單站點(diǎn)預(yù)測(cè)結(jié)果檢驗(yàn)評(píng)估指標(biāo)
氣象學(xué)中有許多檢驗(yàn)評(píng)估指標(biāo),包括時(shí)間距平相關(guān)系數(shù)(TCC)、空間距平相關(guān)系數(shù)(ACC)、相對(duì)操作特征(ROC)等. 其中TCC原理簡單,運(yùn)用廣泛,且適用于本文研究問題的單站點(diǎn)輸出結(jié)果分析,因此可以作為主要的檢驗(yàn)指標(biāo). 符號(hào)一致率,也稱同號(hào)率(SS),能夠把握距平值的變化趨勢(shì)(升高或者降低). 訓(xùn)練集決定系數(shù)()可以檢驗(yàn)?zāi)P陀?xùn)練集的擬合情況.測(cè)試集決定系數(shù)()與訓(xùn)練集決定系數(shù)原理類似,可以檢驗(yàn)測(cè)試集的擬合情況,同時(shí)驗(yàn)證TCC指標(biāo)的合理性,但標(biāo)準(zhǔn)較為嚴(yán)苛.

時(shí)間距平相關(guān)系數(shù)的公式為其中,n1為模型測(cè)試集的樣本數(shù)量,TESTi為測(cè)試集中第i個(gè)測(cè)試數(shù)據(jù),OBSi為與測(cè)試數(shù)據(jù)對(duì)應(yīng)的第i個(gè)真實(shí)數(shù)據(jù),為測(cè)試集數(shù)據(jù)的平均值,為與測(cè)試集對(duì)應(yīng)的真實(shí)數(shù)據(jù)的平均值.TCC取值范圍是[?1,1],越接近1,說明預(yù)測(cè)效果越好.
同號(hào)率公式為
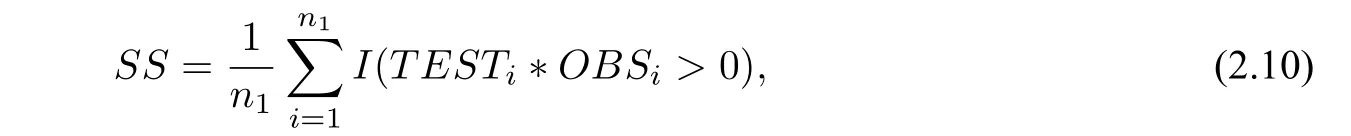
其中,I(·)表示示性函數(shù).
測(cè)試集決定系數(shù)為

訓(xùn)練集決定系數(shù)為

其中,n2為模型訓(xùn)練集的樣本數(shù)量,TRAINj為訓(xùn)練集中第j個(gè)測(cè)試數(shù)據(jù).
2.5.2 區(qū)域預(yù)測(cè)結(jié)果檢驗(yàn)評(píng)估指標(biāo)
趨勢(shì)異常綜合評(píng)分(Ps)是國內(nèi)氣象領(lǐng)域常用的評(píng)價(jià)標(biāo)準(zhǔn),它綜合考慮了同號(hào)率、擬合能力以及異常值(偏離平均值較多的觀測(cè)值)預(yù)報(bào)能力. 本文在保留Ps評(píng)分部分標(biāo)準(zhǔn)的同時(shí),針對(duì)華南地區(qū)暴雨日數(shù)預(yù)測(cè)問題,對(duì)評(píng)分標(biāo)準(zhǔn)進(jìn)行調(diào)整,將不連續(xù)的分段常數(shù)函數(shù)調(diào)整為連續(xù)函數(shù),得到調(diào)整Ps評(píng)分(APs).Ps評(píng)分標(biāo)準(zhǔn)基于距平百分率進(jìn)行操作,APs 評(píng)分沿用這種模式. 本小節(jié)涉及的變量均為對(duì)應(yīng)數(shù)據(jù)的距平百分率.
設(shè)共有m個(gè)站點(diǎn), 每個(gè)站點(diǎn)都有n個(gè)測(cè)試樣本, 即n年的月平均暴雨日數(shù)數(shù)據(jù). 當(dāng)OBS(i,k)*TEST(i,k)< 0, 即第i年第k個(gè)站點(diǎn)的觀測(cè)值與對(duì)應(yīng)預(yù)測(cè)值符號(hào)相反時(shí), 定義第i年,第k個(gè)站點(diǎn)的得分為零

當(dāng)OBS(i,k)*TEST(i,k)≥0,即第i年第k個(gè)站點(diǎn)的觀測(cè)值與對(duì)應(yīng)預(yù)測(cè)值符號(hào)相同時(shí)(包含其中某項(xiàng)為0 的情況),定義第i年,第k個(gè)站點(diǎn)的得分公式為
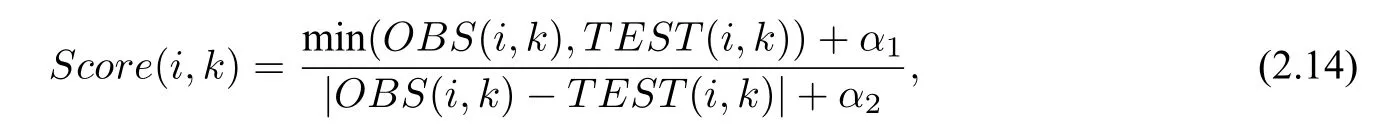
其中,α1,α2為經(jīng)驗(yàn)參數(shù),用于避免出現(xiàn)分子或分母為0 的情況(本文通過多次實(shí)驗(yàn)比較,將α1與α2均設(shè)為0.05). 上式分子部分用于對(duì)異常值的預(yù)報(bào)能力,分母部分衡量模型對(duì)觀測(cè)值的擬合程度.
與Ps評(píng)分準(zhǔn)則類似,構(gòu)造第i年所有站點(diǎn)的綜合APs評(píng)分
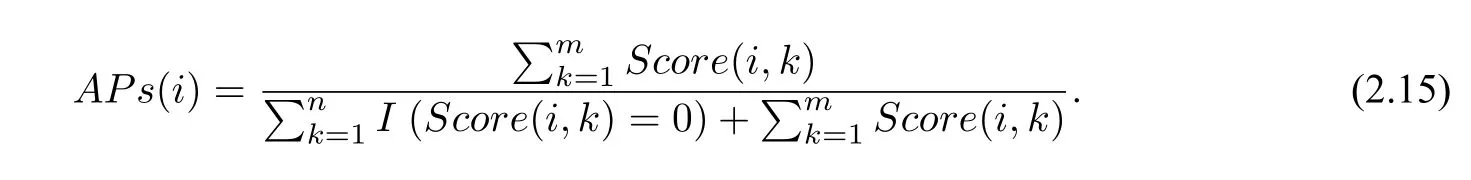
3 實(shí)驗(yàn)結(jié)果
在模型訓(xùn)練過程中,本文將數(shù)據(jù)按7:3 的比例分為訓(xùn)練集和測(cè)試集. 時(shí)間距平相關(guān)系數(shù),同號(hào)率和測(cè)試集決定系數(shù)用于評(píng)估測(cè)試集上的預(yù)測(cè)效果,訓(xùn)練集決定系數(shù)是訓(xùn)練集上的檢驗(yàn)標(biāo)準(zhǔn). 本小節(jié)涉及到的變量均為距平值.
3.1 單站點(diǎn)預(yù)測(cè)結(jié)果比較
本文分別基于主成分分析法和高相關(guān)區(qū)域選取法對(duì)數(shù)據(jù)降維和提取特征,并使用最小角回歸算法對(duì)站點(diǎn)暴雨日數(shù)進(jìn)行預(yù)測(cè).
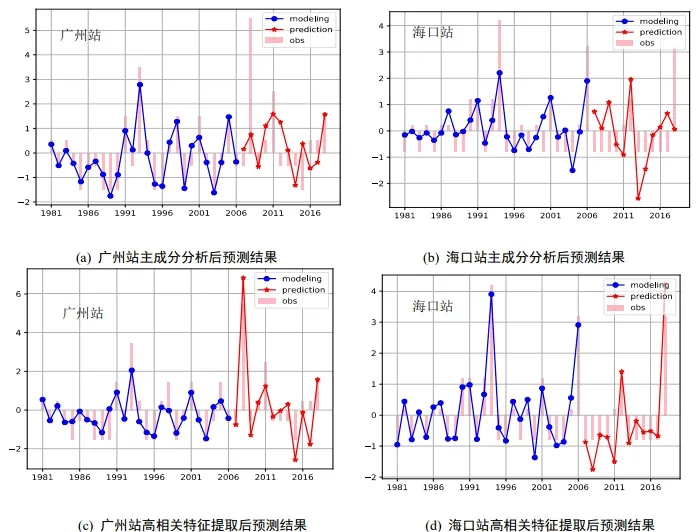
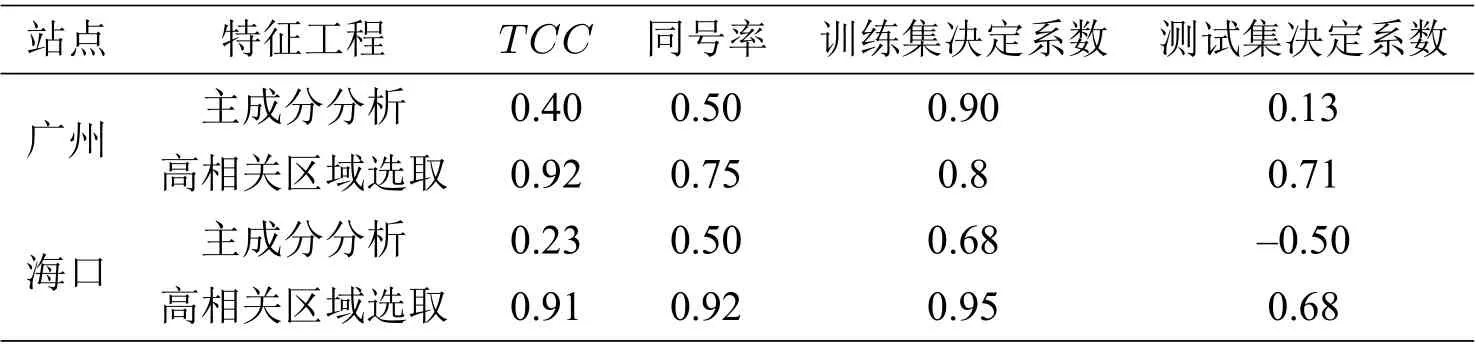
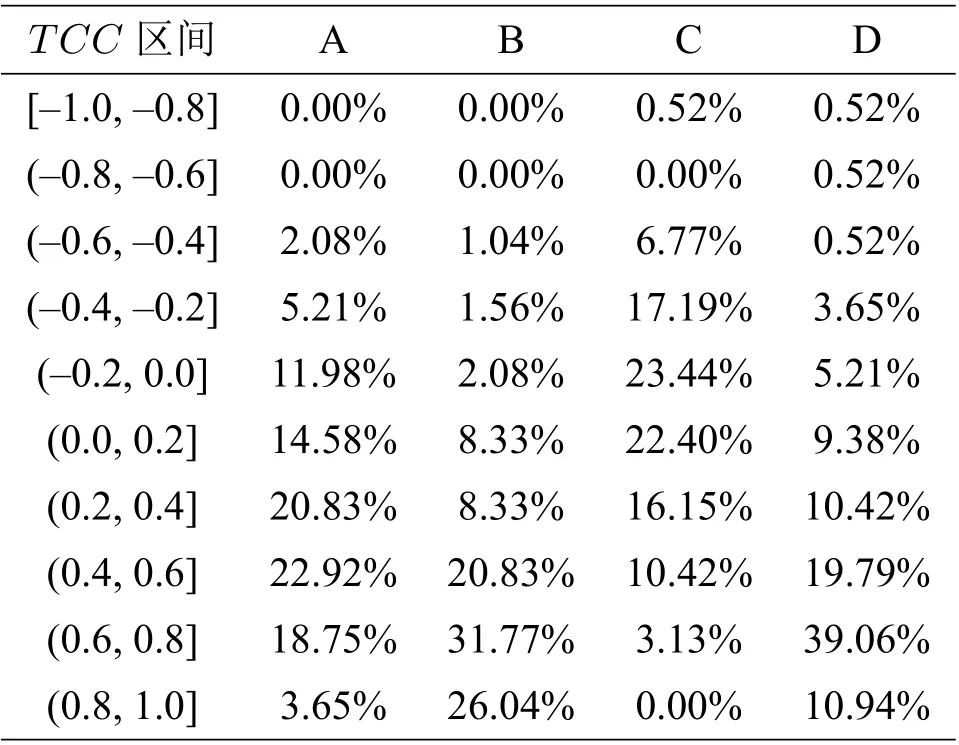
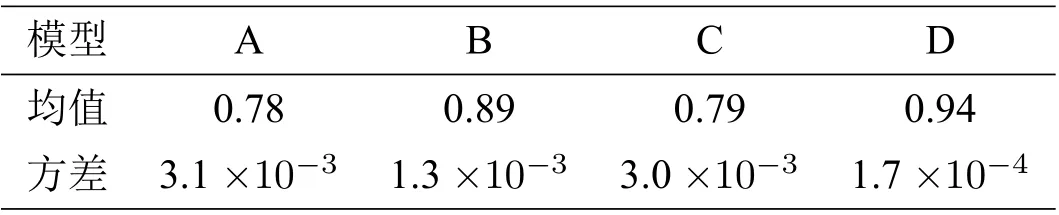
我們將提取高相關(guān)區(qū)域和主成分分析兩種提取特征的方法進(jìn)行對(duì)比分析. 主成分分析是一種使用最廣泛的數(shù)據(jù)降維算法,其基本思想是將n維特征映射到k(k< 對(duì)自變量進(jìn)行主成分分析,用協(xié)方差矩陣的特征值計(jì)算累計(jì)方差貢獻(xiàn)率,從而得到累計(jì)貢獻(xiàn)率與主成分?jǐn)?shù)量關(guān)系,如圖4所示.可以看出,累計(jì)貢獻(xiàn)率Ψm與主成分?jǐn)?shù)量m的函數(shù)關(guān)系為凹函數(shù),累計(jì)貢獻(xiàn)率的增長速度隨著主成分?jǐn)?shù)量逐步引入而降低. 當(dāng)引入第11 個(gè)主成分后,累計(jì)貢獻(xiàn)率高于0.7?當(dāng)引入第16 個(gè)主成分后,累計(jì)貢獻(xiàn)率高于0.8?當(dāng)引入第23 個(gè)主成分后,累計(jì)貢獻(xiàn)率高于0.9?累計(jì)貢獻(xiàn)率在主成分?jǐn)?shù)量為37 時(shí)達(dá)到最大值1. 本文選用23 個(gè)主成分,樣本貢獻(xiàn)率高于0.9. 圖4 累計(jì)樣本貢獻(xiàn)率與主成分?jǐn)?shù)量關(guān)系 對(duì)預(yù)報(bào)因子進(jìn)行高相關(guān)區(qū)域提取時(shí),根據(jù)最小角回歸算法特性,相關(guān)系數(shù)檢驗(yàn)的顯著性水平設(shè)為0.05,以增強(qiáng)自變量集的解釋能力. 我們使用1981 年至2006 年的數(shù)據(jù)進(jìn)行訓(xùn)練,將2007 年至2018 年的數(shù)據(jù)進(jìn)行測(cè)試,再與觀測(cè)值比對(duì). 設(shè)置殘差上限為2×10?16,非零參數(shù)數(shù)量設(shè)置為15. 實(shí)驗(yàn)結(jié)果如圖5所示. 圖5 最小角回歸預(yù)測(cè)初夏暴雨日數(shù)距平 用時(shí)間距平相關(guān)系數(shù)(TCC),同號(hào)率,訓(xùn)練集決定系數(shù)和測(cè)試集決定系數(shù),分別對(duì)基于兩種特征提取方法的最小角回歸算法結(jié)果進(jìn)行檢驗(yàn),并將得到的四個(gè)結(jié)果進(jìn)行對(duì)比分析,結(jié)果如表2所示,其中紅色的表示最好結(jié)果、藍(lán)色的表示次好結(jié)果. 由表2 的數(shù)據(jù)可得,對(duì)于兩個(gè)站點(diǎn)的模型輸出結(jié)果,除廣州站點(diǎn)的訓(xùn)練集決定系數(shù),使用主成 表2 廣州站點(diǎn)與海口站點(diǎn)初夏暴雨日數(shù)預(yù)測(cè)結(jié)果檢驗(yàn) 分分析的方法略優(yōu)于高相關(guān)區(qū)域提取的方法外,其他所有的檢驗(yàn)指標(biāo)都是高相關(guān)區(qū)域提取方法明顯占優(yōu). 這說明基于高相關(guān)區(qū)域提取的最小角回歸算法具有較高的預(yù)測(cè)精度. 本節(jié)從整個(gè)華南區(qū)域的角度對(duì)預(yù)測(cè)結(jié)果進(jìn)行分析. 為了更好地分析最小角回歸算法的預(yù)測(cè)效果,與分別采用基于主成分分析和高相關(guān)區(qū)域提取兩種特征選擇的多元線性回歸方法進(jìn)行對(duì)比. 為了方便表示,將兩種特征選擇方法下的兩種預(yù)測(cè)模型分別用代號(hào)A,B,C,D 進(jìn)行表示,具體對(duì)應(yīng)規(guī)則見表3. 表3 代號(hào)及對(duì)應(yīng)模型 選取氣象學(xué)中常用的檢驗(yàn)指標(biāo)TCC,分析比較A,B,C,D 四種模型在測(cè)試集上的得分. 將所有站點(diǎn)TCC得分分布情況列出如表4所示. 表中第一列表示TCC的劃分區(qū)間,第二至五列的數(shù)據(jù)表示TCC得分落在對(duì)應(yīng)區(qū)間的站點(diǎn)數(shù)占總站點(diǎn)數(shù)的百分比. 表4 四種模型下華南地區(qū)192 站點(diǎn)TCC 得分分布百分比 統(tǒng)計(jì)數(shù)據(jù)表明,模型A,C 的分布百分比隨著TCC的增加,呈現(xiàn)先增后減的分布趨勢(shì)?模型A中站點(diǎn)的TCC主要集中于區(qū)間[?0.2,0.8],模型C 中站點(diǎn)的TCC主要集中于區(qū)間[?0.2,0.6],說明基于主成分分析方法選擇特征的模型預(yù)測(cè)效果整體較差. 模型B,D 的站點(diǎn)百分比隨著TCC增加大致呈遞增趨勢(shì),兩種模型中站點(diǎn)的TCC均集中于效果最佳的[0.6,1]區(qū)間,且占比均為50%左右,不同的是模型B 在[0.8,1]區(qū)間的占比更高,而模型D 在[0.6,0.8]區(qū)間的占比更高. 這表明基于高相關(guān)區(qū)域提取方法的兩種預(yù)測(cè)模型在TCC上的表現(xiàn)接近. 上表從空間尺度上比較了模型的預(yù)測(cè)效果. 為了進(jìn)一步從時(shí)間尺度上比較分析,對(duì)四種模型2011 年到2018 年的測(cè)試集進(jìn)行APs評(píng)分,結(jié)果如圖6所示. 由圖6可知,整體而言模型B,D 處于更高的評(píng)分區(qū)間. 模型D 的APs評(píng)分均值最高為0.9359,所有年份均顯著地高于其他模型,且方差最小(1.7×10?4),測(cè)試集的預(yù)測(cè)結(jié)果能穩(wěn)定地位于較小的區(qū)間內(nèi),整體效果均顯著優(yōu)于其他模型. 模型B 預(yù)測(cè)效果次之,APs評(píng)分均值為0.8871,方差為1.3×10?3. 模型A,C 的測(cè)試集評(píng)分均值最低,方差最大,說明這兩種模型對(duì)華南站點(diǎn)初夏暴雨日數(shù)預(yù)測(cè)精度不足,且穩(wěn)定性較差. 四種模型的APs評(píng)分對(duì)應(yīng)均值與方差如表5所示. 表5 四種模型APs 評(píng)分對(duì)應(yīng)均值與方差 圖6 四種模型測(cè)試集APs 評(píng)分對(duì)比 本文旨在研究前期的大氣環(huán)流因子(高度場(chǎng)(hgt), 經(jīng)向風(fēng)場(chǎng)(vwnd), 緯向風(fēng)場(chǎng)(uwnd), 比濕(shum),海平面氣壓(slp))及海溫、海冰和積雪數(shù)據(jù)對(duì)華南地區(qū)初夏暴雨的影響,從而實(shí)現(xiàn)對(duì)華南地區(qū)初夏暴雨日數(shù)的預(yù)測(cè). 本文首先使用高相關(guān)區(qū)域提取的方法對(duì)數(shù)據(jù)降維,并與常用的主成分分析方法進(jìn)行比較. 然后用兩種方法選擇的特征分別構(gòu)建華南地區(qū)初夏暴雨日數(shù)的機(jī)器學(xué)習(xí)預(yù)測(cè)模型,并運(yùn)用以時(shí)間距平相關(guān)系數(shù)為主的單站點(diǎn)預(yù)測(cè)結(jié)果檢驗(yàn)標(biāo)準(zhǔn)和以APs評(píng)分為主的區(qū)域性檢驗(yàn)標(biāo)準(zhǔn)對(duì)混合構(gòu)建的四種模型進(jìn)行檢驗(yàn)分析,得到以下兩點(diǎn)結(jié)論. (1)在特征提取方面,從單站點(diǎn)預(yù)測(cè)結(jié)果分析,基于高相關(guān)區(qū)域提取方法的模型結(jié)果基本反映了真實(shí)距平值的變化,基于主成分分析方法的模型結(jié)果與真實(shí)情況偏差較大. 其他4 種評(píng)價(jià)指數(shù)也驗(yàn)證了基于高相關(guān)區(qū)域提取的最小角回歸預(yù)測(cè)模型的明顯優(yōu)勢(shì). 從區(qū)域預(yù)測(cè)結(jié)果分析可見,基于高相關(guān)區(qū)域提取的兩種模型的時(shí)間相關(guān)系數(shù)分布在區(qū)間[0.6,1],基于主成分分析方法的兩種模型的時(shí)間相關(guān)系數(shù)近似正態(tài)分布,主要位于區(qū)間[0.2,0.6]. 且高相關(guān)區(qū)域提取方法的兩種模型的APs評(píng)分主要在區(qū)間[0.88,0.96],而基于主成分分析方法的兩種模型的APs評(píng)分主要在區(qū)間[0.70,0.89]. (2)在預(yù)測(cè)模型方面,基于高相關(guān)區(qū)域提取方法的最小角回歸算法預(yù)測(cè)結(jié)果的時(shí)間相關(guān)系數(shù)分布在區(qū)間[0.6,0.8],而相應(yīng)的多元線性回歸模型的時(shí)間相關(guān)系數(shù)相對(duì)均勻地分布在區(qū)間[0.6,1],分布相差不明顯. 但高相關(guān)區(qū)域提取方法的最小角回歸算法的APs評(píng)分主要在區(qū)間[0.91,0.96]上,而對(duì)應(yīng)的多元線性回歸模型的APs評(píng)分主要在區(qū)間[0.81,0.93]. 綜上,基于高相關(guān)區(qū)域提取方法的最小角回歸算法能較好地預(yù)測(cè)華南初夏暴雨日數(shù).
3.2 區(qū)域的分析比較


4 結(jié)論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
