湄公河流域缺資料地區水資源量評估方法探討
——以老撾南烏河和柬埔寨洞里薩湖為例
2022-07-01 13:31:14陳璽,李妍清,徐長江,金君良,趙樹辰
人民長江 2022年6期
關鍵詞:模型
陳 璽,李 妍 清,徐 長 江,金 君 良,趙 樹 辰
(1.長江水利委員會 水文局,湖北 武漢 430010; 2.河海大學 水文水資源與水利工程科學國家重點實驗室,江蘇 南京 210024; 3.南京水利科學研究院 水文水資源與水利工程科學國家重點實驗室/水利部應對氣候變化研究中心,江蘇 南京 210029; 4.長江勘測規劃設計研究有限責任公司,湖北 武漢 430010)
0 引 言
瀾滄江-湄公河是世界第六長河,全長約4 900 km,流域總面積81萬km2,多年平均徑流量740億m3。河流發源于中國青海省唐古拉山脈崗果日峰的扎曲,流至昌都后稱為瀾滄江,在云南省南臘河口出境后稱為湄公河。湄公河干流河谷較寬,彎道較多,經老撾到柬埔寨金邊與洞里薩湖交匯后進入越南,于越南胡志明市附近的湄公河三角洲注入南中國海。瀾湄流域水系發育、湖泊眾多,但水文監測站網布設相對滯后導致水資源監測能力不足,采用常規技術手段進行準確的水資源評價異常困難,特別是在“汛期成湖、枯期成河”的流域。針對如何通過科學的技術手段準確地評估水資源量的問題展開了分析,分析認為,基于合作協商機制來進行合理開發或優化分配水資源,為經濟社會發展提供精準決策,是解決瀾湄流域地區復雜歷史背景下水事糾紛的關鍵[1]。
流域水文模型是描述降雨、產流、匯流等水文循環各個環節動力過程的科學工具。自國際水文科學協會IAHS于2003年提出PUB計劃(Prediction in Ungauged Basins)以來[2],伴隨著“3S”技術的發展,水文模擬技術趨向于將水文模型與數字高程模型相結合,同地理信息系統與遙感集成,所揭示的水文物理過程越來越接近客觀世界[3],能客觀地反映氣候和下墊面因子的空間分布對流域降雨徑流形成的影響[4],先后涌現出了比如MIKE SHE[5]、TOPMODEL[6]、TOPKAPI[7]、SWAT[8]和 VIC(Variable Infiltration Capacity)[9]等能夠描述地形、土壤、植被以及氣候條件等要素空間異質性的分布式水文模型,這些模型的建立,為無資料地區水資源量的評估提供了科學可靠的技術工具和實踐示范[10-13]。
陳璽等[13]基于VIC模型,對老撾南烏河流域進行過徑流模擬,并在模型模擬成果的基礎上,對分區水資源量展開了初步評估和合理性分析。徐長江等[14]基于VIC模型開展過柬埔寨洞里薩湖流域在資料短缺情況下的水文參數移植和模型適用性探討。然而,采用分布式模型進行水資源評估時,如何考慮部分地區水面面積較大且隨季節的變化,甚至會出現“汛期成湖、枯期成河”等特征,是一個值得關注和深入探討的問題。在瀾湄水資源合作的背景下,本文選擇老撾南烏河流域和柬埔寨洞里薩湖流域2個典型研究區開展研究,其中,湖泊流域考慮了汛期水域面積變動問題,建立了流域分布式水文模型,用以探討河湖2種典型特征流域的水資源量評估方法,以便為不同下墊面條件下無資料或缺資料地區的水資源量評估,提供較為科學的方法。
1 研究區概況及研究方法
1.1 研究區概況
南烏河為湄公河左岸一級支流,位于老撾北部熱帶雨林山區,干流全長448 km,流域面積為2.61萬 km2,南北向長度200~295 km,東西向寬度125~150 km,海拔高度為280~2 263 m。洞里薩湖是湄公河流域最大的淡水湖,位于柬埔寨西部,通過洞里薩河與湄公河相連,是湄公河的天然蓄水池。洞里薩湖水量季節變化大:雨季,湄公河漲水時,水注入洞里薩湖,湖面面積可達10 000 km2,水深可達到10~18 m;旱季,湄公河水消退后,水從洞里薩河流入湄公河,湖面面積縮減至2 500 km2,水深為2~8 m。
依據 SL/T 238-1999《水資源評價導則》開展區域水資源評價時,首先應選擇資料質量較好、觀測系列較長的水文站作為選用站進行單站徑流系列分析;然后,對分區水資源量進行評價,以反映水資源量的時空分布特征。選用的代表站資料系列一般應超過30 a,包含完整的豐水、平水、枯水年份,否則需要進行插補延長資料系列年限。南烏河流域1個資料系列和洞里薩湖流域4個資料系列均不足20 a,且站點空間分布不均,無法反映水資源量的空間變化特征;加上流域內沒有可以用來插補延長的參證站,因而無法進行資料系列插補延長。
綜上,本文建立了分布式水文模型,輸入30 a以上的降水等氣象驅動資料,利用南烏河流域1個站點和洞里薩湖流域4個站點的水文資料進行模型率定和驗證,通過參數移植來模擬水資源量的空間特征。南烏河和洞里薩湖2處典型流域地理位置如圖1所示,站點選用資料系列如表1所列。
1.2 研究方法
(1) VIC模型建模。VIC模型是1994年由美國華盛頓大學和普林斯頓大學聯合開發的開源大尺度水文模型[13],主要由蒸散發計算、產流和匯流等基礎模塊,以及融雪、水庫調度、農業灌溉、地下水地表水耦合等附加模塊組成。近年來,Wi等[15]研發出了一套VIC-Automated Setup Toolkit,可以將其植入MATLAB進行可視化編程操作,這就為VIC模型愛好者提供了更加便捷的應用方式。
模型輸入包括地形、土壤、植被、氣候驅動4個部分。本文考慮到了研究流域面積和模型輸入數據的空間分辨率,構建了基于0.25°×0.25°網格的模型框架,模型輸入均按照0.25°×0.25° 網格進行準備。
地形:通過SRTM數字地形數據集提取研究流域的DEM,將DEM離散成與網格分辨率相同的數字地形單元,計算網格流向。
土壤:南烏河流域土壤表層主要為黏壤土,土壤深層為黏壤土;洞里薩湖區域以壤土和黏土為主。
植被:南烏河流域以常綠闊葉林為主,有少量落葉闊葉林和耕地零星分布;洞里薩湖流域以草地和耕地覆蓋為主。
氣候驅動:對于無資料地區,氣象輸入多采用當前國際上主流的再分析資料[16-18]。本文采用來自美國NASA 的融合了多源衛星數據和地面實測數據的AgMERRA數據集(1980~2010年)中的降水、氣溫、風速、濕度等氣象要素。對于該氣象數據集在研究區域的適用性,在以往研究中進行了闡述[13-14]。

表1 南烏河和洞里薩湖率定水文模型選用站點資料系列Tab.1 The hydrological series for model calibration in the study area
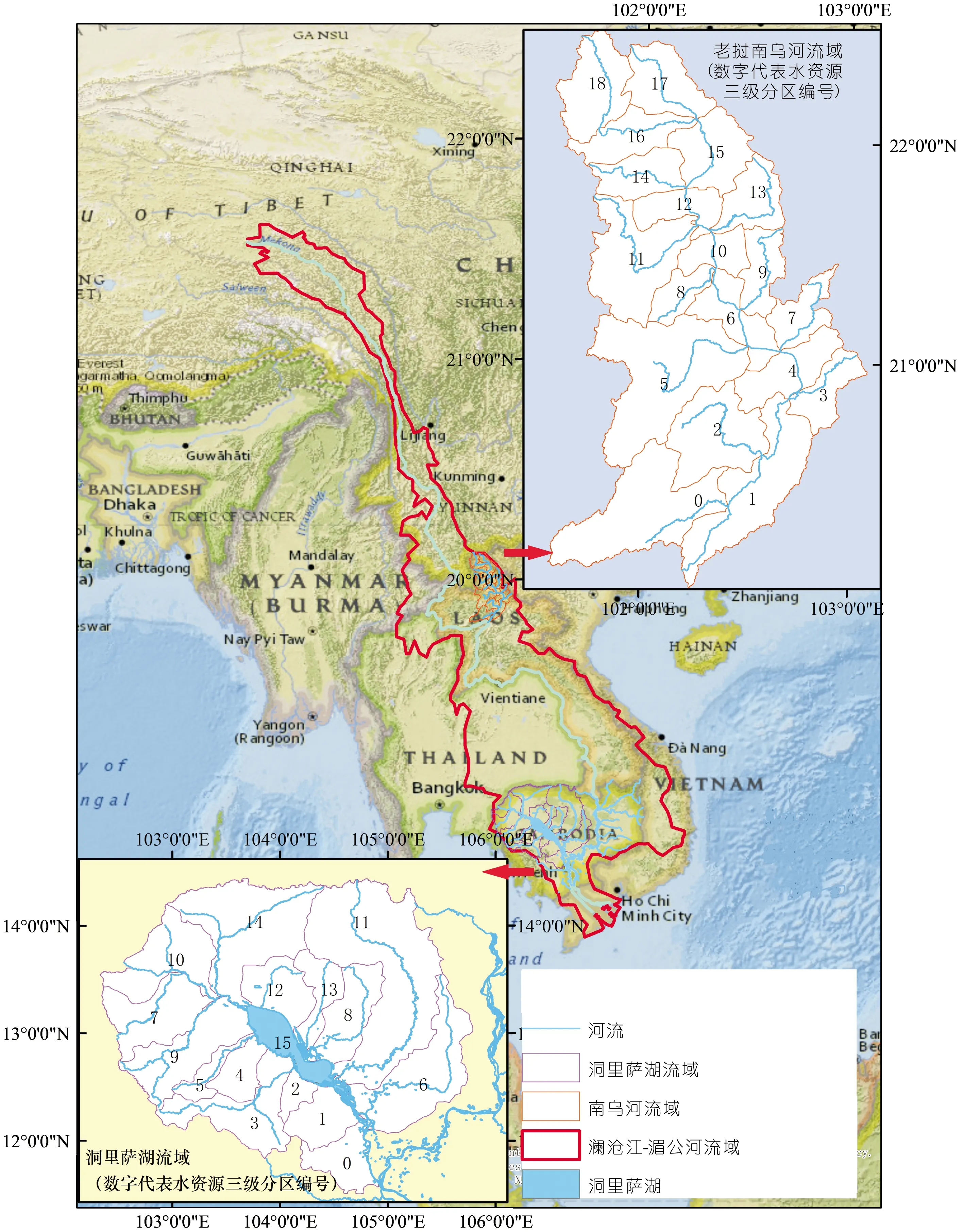
圖1 瀾滄江-湄公河流域及典型研究區地理位置Fig.1 The location of the study area and Lancang-Mekong River Basin
(2) 參數率定。VIC模型中有6 個與產匯流相關的參數難以直接給出,需要采用實測水文資料進行率定,這些參數分別是:入滲能力形狀參數B,底層土壤1 d 內產生基流的最大值Dsmax、基流非線性增長發生時占Dsmax的比例Ds、基流非線性增長發生時底層土壤含水量與最大土壤含水量的比值Ws、第2層土壤厚度d2和第3層土壤厚度d3[14,19]。本文在有水文站控制的區域采用實測水文資料對VIC模型進行水文參數率定,率定完成后的水文參數可以用于有水文站控制區域的水資源量的評估。采用確定性系數ENS和平均相對誤差RE來反映模擬過程的吻合度和水量平衡,這2個指標均在0~1之間變化,ENS越接近1,RE越接近0,說明模擬效果越好。
其中:
(1)
(2)

對沒有水文站控制的區域需要進行參數移植,在此基礎上,確定水文參數后再進行水資源量評估。為構建參數規律化移用方案采用的流域特征指標體系,根據實測系列、遙感數據或同化資料,首先通過主成分分析方法確定影響參數敏感性的主要因子,然后采用多元線性回歸的方法,構建參數與遴選的氣候要素之間的定量關系,參數移植方法和步驟已在徐長江等[14]的研究中進行了闡述,本文不再贅述。將有實測水文資料的控制區域劃分為2個部分:一部分用于水文參數,并與流域氣候因子和下墊面因子建立參數移用公式;另一部分則用于驗證參數移用公式的合理性,最終得到全流域水文參數。
(3) 水域面積動態分析。洞里薩湖周邊是廣闊的平原地區,汛期隨著降水和入湖徑流的增大,湖區周邊陸面面積會轉化為水面面積。湖區最大水面面積取16 000 km2,以此將湖區周邊水資源分區面積分為2個部分處理,其中一部分為常年陸面面積;另一部分為水陸變動面積。考慮水面面積的動態變化進而估算洞里薩湖流域的水資源量,首先需要根據湖區水位資料以及湖區水位面積(容積)曲線查算逐日(月)的湖區面積。對于洞里薩湖的水位面積(容積)關系,采用湄公河委員會和柬埔寨水利氣象部常用的數據集,如圖2所示,數據來源于芬蘭環境研究所。

圖2 洞里薩湖流域水位面積(容積)關系曲線Fig.2 Water level-area(volume)relation curve of Tonle Sap Lake Basin
通過分別計算變動面積中各年分月的水陸產流面積,進而計算相應的產流量。計算時,水面徑流系數按1.0考慮,最終計算出各水資源分區的水資源量日(月)系列,包括各個水資源分區內的水面面積、水面產水量、陸面面積、陸面產水量以及總的水資源量。
將洞里薩湖區面積以3 000 km2作為基準值,針對其周邊的某一個三級區i,變動的水面面積和陸面面積分別為
當S總水面>3 000時,
(3)
(4)
洞里薩湖三級區的水面面積為
(5)
當S總水面<3000時,
(6)
(7)
洞里薩湖三級區的水面面積為
(8)
式中:fi,fract為第i個三級區內變動的水面面積占所有湖面擴大的水面面積的比例,以最大湖面面積(16 000 km2)時占用周邊各三級區面積的百分比為參考。
2 模型模擬
2.1 參數率定
采用南烏河流域和洞里薩湖流域共計5個水文站實測的水文資料,對本次建立的分布式水文模型進行率定和驗證,結果如圖3所示。在率定期,南烏河流域M.Ngoy水文站日、月尺度流量過程模擬的確定性系數分別達到了0.84和0.92;在驗證期,該確定性系數則分別達到了0.68和0.80。洞里薩湖流域Prasat Keo水文站日尺度流量過程模擬的確定性系數,在率定期和驗證期均低于0.60,月尺度流量過程模擬的確定性系數在率定期和驗證期分別為0.65和0.62;其余3個水文站的日、月尺度流量過程模擬的確定性系數在率定期和驗證期分別為0.70~0.83和0.66~0.82。另外,南烏河流域和洞里薩湖流域5個水文站的日尺度流量過程模擬的平均相對誤差在10%以內。上述結果說明,本次構建的VIC模型在2個典型流域日、月尺度的流量過程模擬中效果良好,可以將其用于河流、湖泊2種典型流域的水資源量的評估工作。
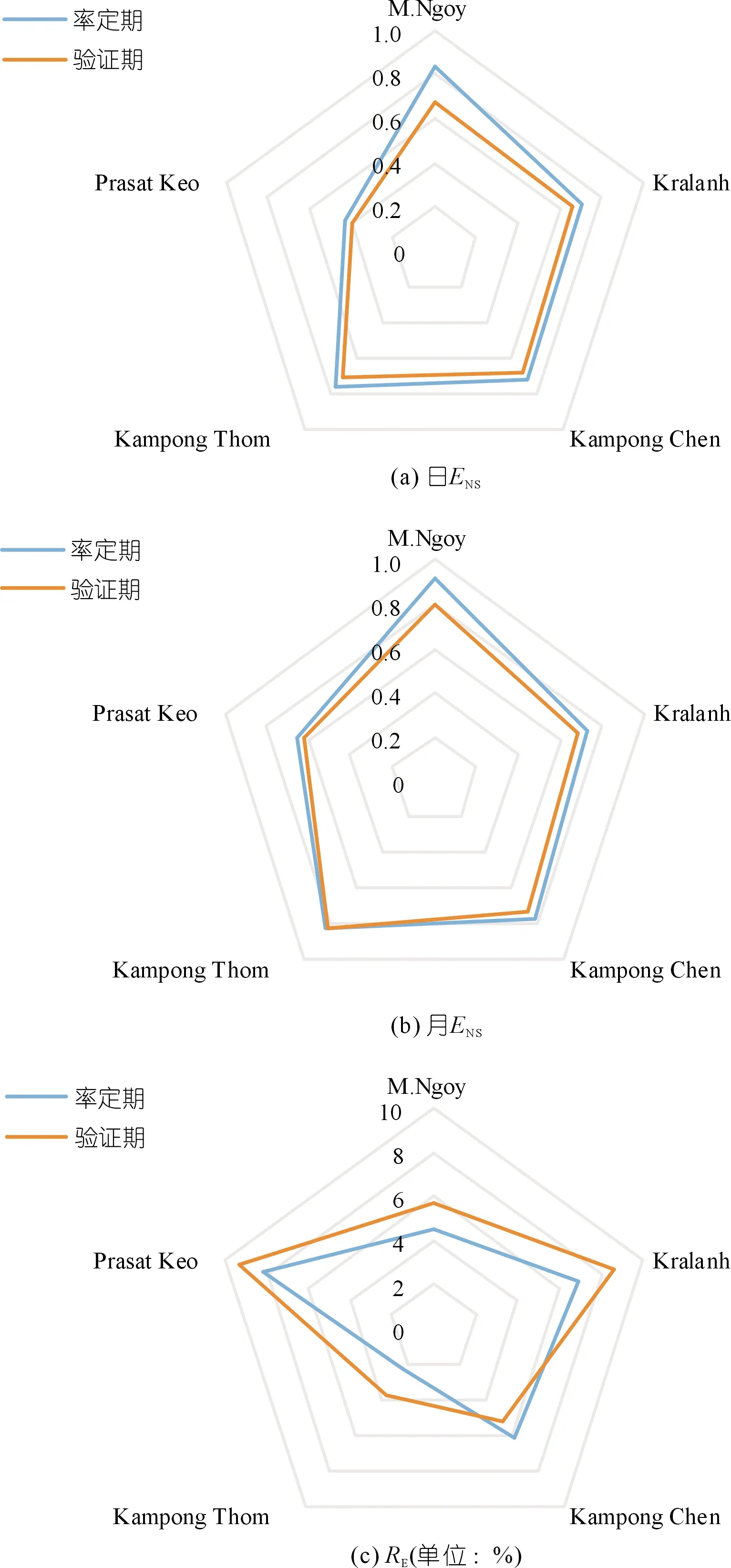
圖3 VIC模型在南烏河和洞里薩湖流域模擬效果Fig.3 The simulation effect of VIC model in the study area
2.2 模擬結果
本文利用AgMERRA再分析氣象數據集驅動VIC 模型,模擬得出了南烏河流域和洞里薩湖流域三級區1980~2010年的水資源量系列數據。各水資源三級區1980~2010年的多年平均徑流量如圖4所示。圖4中,水資源三級區名稱從左到右依次對應圖1中的水資源三級區序號。南烏河流域19個水資源三級分區在1980~2010年的多年平均水資源量總計為164.33億m3,多年平均徑流深為666 mm。對于洞里薩湖流域,在進行降水產流模擬分析時,湖區中心區(圖1中序號15)的基準水面面積為3 000 km2,當汛期來臨、降水量增加時,湖區中心區周邊的水資源三級分區(圖1中序號0~14)將會有一部分陸面面積轉換為水面面積,各水資源三級區產流量分為陸面產流量和水面產流量2個部分計算,兩者相加即為各區的水資源總量。洞里薩湖流域除了湖區中心區以外,其余的水資源三級分區(序號0~14)1980~2010年的多年平均水資源量總計為460億m3,其中,陸面多年平均產水量為400億m3,水面多年平均產水量為60億m3。
南烏河流域和洞里薩湖流域的水資源量均主要依賴于降水補給。南烏河流域徑流深由上游向下游遞減,洞里薩湖流域水資源量西南地區較為豐沛,而北部地區水資源量相對較為稀少,2個典型研究區的徑流深空間分布總體上與降水空間分布一致。
由于本文旨在對河流流域和湖泊流域缺資料地區水資源量的評估方法開展探討,因此,限于篇幅,不再對流域水資源量的時空分布以及徑流深、徑流系數等特征開展分析。

注:水資源三級區名稱從左到右依次對應圖1中水資源三級區序號0~18(南烏河),0~14(洞里薩湖)。圖4 南烏河流域和洞里薩湖流域三級區水資源量評估結果Fig.4 The water resources assessment results in the study area
3 結論與展望
3.1 結 論
本文基于以往的研究成果,探討了借助于分布式水文模型對河流和湖泊2種典型的缺乏實測水文資料流域的水資源量進行評估的方法,可以得出以下結論。
(1) 本研究中,無論是南烏河流域還是洞里薩湖流域,在依據SL/T 238-1999《水資源評價導則》和SL/T 278-2020《水利水電工程水文計算規范》進行水資源量評價時,流域內水文站個數不足、空間分布不均,實測水文資料系列長度不足而且也不具備插補延長的條件,屬于缺資料地區,對于這種條件,應借助于水文模型來開展水資源評價。
(2) 由于陸面和水面產流系數不同,本研究采用了流域分布式水文模型在典型河流流域和湖泊流域進行水文模擬,重在說明在湖泊流域進行水文模擬時,應考慮到湖泊流域水域面積隨著降水的年內變化而出現的動態變化。
(3) 考慮河湖典型流域不同特征進行建模,南烏河流域和洞里薩湖流域5個水文站日尺度流量過程模擬的平均相對誤差在10%以內,說明該分布式水文模型在河湖典型流域日、月尺度的流量過程模擬效果良好,可以將其用于進一步的水資源量模擬,以反映流域水資源量的時空分布狀況。
(4) 南烏河流域和洞里薩湖流域水資源量均主要依賴于降水補給,模型模擬得出的水資源量系列長度和空間分辨率,取決于模型輸入的降水系列和空間分辨率,徑流深的空間分布是降水與下墊面水文產匯流參數綜合作用的結果,總體上與降水空間分布基本一致。
3.2 展 望
一般來說,對用于水文模型率定和驗證的實測流量系列需要開展一致性分析,如果分析結果不滿足一致性條件,則需要進行流量系列還原計算。作為本文選用的模擬分析的典型流域,由于其經濟社會發展相對落后,水資源開發利用水平較低,可以暫不考慮對其進行還原計算。但在將其用于其他流域的分析時,如果在控制性水文站上游用水量較大或者建設有水庫、引調水工程等水利工程設施,則應根據水文站控制以上流域的一、二、三產用水量以及水利工程對水文站實測徑流系列來開展還原計算。
另外,運用分布式水文模型模擬得出的水資源空間分布分辨率,取決于模型網格大小的設置。模型網格設置一般會考慮到氣象驅動和植被、土壤等下墊面數據的空間分辨率,各網格的水資源量系列長度與模型輸入的降水系列長度一致,分區水資源量是流域分區邊界內的網格產流量的疊加。模型輸入的氣象驅動,多選用國際研究機構認可的再分析數據資料,不同數據集的系列長度一般在30~50 a之間,系列長度能夠滿足水資源評價的要求;而且需要經過研究區地面氣象站實測數據的驗證,如果差異較大則需要對數據進行矯正。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
