適用于FPGA的輕量實時視頻人臉檢測
2022-07-01 08:16:28趙興博陶青川
現代計算機 2022年8期
趙興博,陶青川
(四川大學電子信息學院,成都 610065)
0 引言
隨著社會的發展,城市吸納了越來越多的外來就業人口,大量的人口流動和短期租住給社區公共安全的維護和保障帶來了新的挑戰。傳統的視頻監控系統僅負責將部署的探頭采集的圖像數據傳輸到監控中心進行集中保存,具體的監控排查以及異常情況告警則交由人工進行負責。隨著特大城市生活圈的逐步建立,人們生產生活的活動區域也隨之擴張,因此需要進行治安監控的時間與區域同步擴大,傳統的人工監控成本隨之水漲船高;同時,采用人工的方式不可避免地存在分析人員疏忽、怠惰的問題,從而影響事件發生時監控告警信號的及時性。因此,采用低成本平臺的自動化實時智能分析監控系統才是一種行之有效的解決辦法。
人臉檢測是智能視頻監控的關鍵技術之一。如今人臉檢測技術廣泛應用于人機交互領域,在面部情緒自動化分析、視頻實時人像跟蹤等視覺任務中發揮重要作用。傳統的人臉檢測技術使用依賴于先驗知識設計的特征描述算子,應用廣泛的有哈爾特征算子(haar-like feature)、梯度方向直方圖統計(histogram of oriented gradient,HOG)等;而后將所提取的特征使用分類算法歸類,諸如支持向量機(support vector machine,SVM)、迭代提升方法(boosting)等。傳統的機器學習方式不能自動設計適用于目標數據的特征提取算子,導致其泛化能力弱,實際使用效果較差;隨著人工智能的快速發展,深度學習技術作為成果之一,在視覺目標檢測方面同樣成績斐然。以人臉檢測子領域為例,采用深度學習技術的算法準確率和速度不斷提高,達到甚至超越人類水平。目前主流的檢測方法,主要分為two-stage(兩階段檢測)和one-stage(一階段檢測)兩類。以Faster RCNN為代表的兩階段檢測算法由于其先產生候選檢測框,再對候選框分類的運行邏輯導致計算開銷大、推理速度慢,難以部署于具有實時性要求的低算力設備上。一階段檢測算法則不需要產生候選框,直接將目標在輸入圖像位置上的求解過程轉化為預設檢測框中心位置的回歸問題從而求解,因此檢測速度一般比兩階段算法更快,代價是精度有所降低。這類算法常見的有SSD和YOLO系列。然而,面對監控視頻中存在的小分辨率、遮擋、背景干擾以及姿態變化等復雜人臉,現有算法的高準確率仍依賴于復雜模型和大量計算資源,在應用到現實場景的人臉檢測任務時受到限制,因此,實時輕量級復雜人臉檢測方法受到廣泛關注。
本文主要工作:設計一種適用于FPGA的輕量級目標檢測網絡,以YOLO 算法為基礎,采用RepVGG 方法進行改進,通過結構重參數化方式去除網絡分支結構,同時大幅減少計算量,使得目標檢測網絡能夠適應FPGA 設備低功耗、低算力、小內存空間的客觀條件。訓練過程中輔助聚類分析重新劃分數據集的方法,提高網絡空間信息的聚合能力,從而提高檢測精度。實驗表明,該方法在FPGA設備上運行時具有良好的檢測性能,可在保證精度的前提下滿足實時性要求。
1 YOLO檢測模型
目前被廣泛采用的YOLO 系列目標檢測網絡YOLOv4,相較于YOLO 系列之 前 模 型來說,在確保模型結構簡潔的前提下,在較小目標的識別效率上有極大提高,是此系列的集大成之作。YOLOv4 的模型及詳細結構如圖1 所示,可從整體上劃分為三大部分。
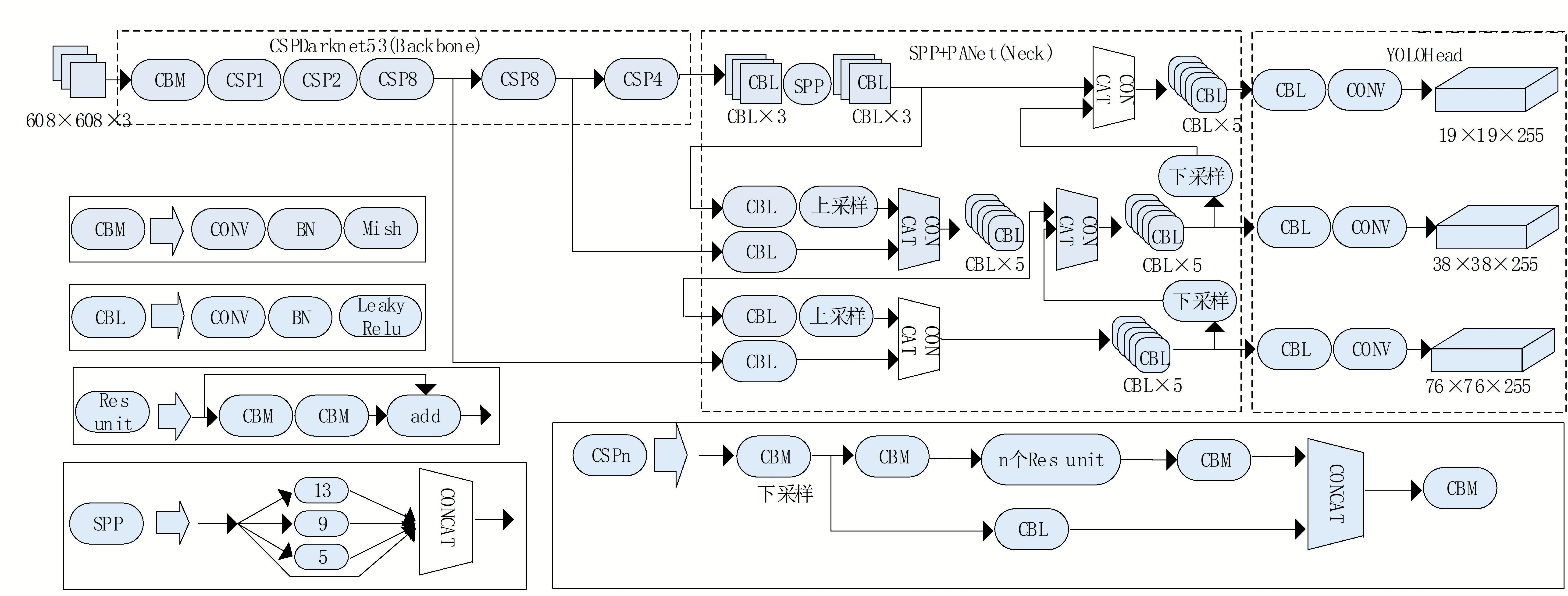
圖1 YOLOv4模型結構圖
首先是特征提取主干結構CSPDarknet53,主要進行圖像高級語義信息的提取,其由5 個CSP-n 模塊串聯而成。一個CSP-n 模塊則融入CSPNet的構造特點,首先堆疊一次步長為2的下采樣,隨后跟隨由個串聯殘差塊單元(res unint)輔助一條貫穿輸入、輸出的殘差邊分支形成多支結構并進行合并,以便在不增加網絡深度的前提下保證高效的特征提取能力;最終,整個特征提取主干依次輸出最后三個CSP-n 模塊的特征提取結果,即相較于輸入尺寸進行2倍、2倍和2倍下采樣得到3幅從大到小的提取特征圖。以輸入圖像尺寸為608 × 608 舉例,最終輸出的特征圖尺寸分別為76 × 76,38 × 38,19 × 19。
其次是SPP加PANet多尺度感受野特征融合結構。SPP模塊通過所設計的多分支不同尺寸最大池化后進行特征拼接,從而自底向上地增強了特征在尺度變換上的平滑性。隨后特征輸入到PANet特征融合模塊中進行處理,與SPP模塊相對應,此處實現了自上到下的下采樣特征拼接操作。SPP 與PANet互相配合,實現了不同尺度特征的相互融合,從而使不同尺度的特征互補。
最后一個結構為YOLOHead 檢測頭,對之前的網絡結構提取到的特征進行解析,從而得出最終的目標檢測框位置以及分類結果。
2 改進的YOLO目標檢測模型
YOLOv4作為一類通用目標檢測網絡,在設計之初便需要考慮不同尺寸、形態各異的各個類別目標物體的差異性,其所考慮的檢測目標從火車到棒球無所不包,需要極強的特征提取能力以保證提取出的特征足夠有代表性。因此,其網絡的復雜度較高,例如其特征提取主干CSPDarknet53,采用多分支結構CSP以及性能優異的網絡組件殘差塊單元,通過加深的網絡層數(總計53 層),并且輔以大通道數來提高模型性能,最大通道數已達1024,最終導致模型在部署時需要設備有極高的計算能力和較大內存,非常不利于工業場景(尤其是在算力受限的情況下)。針對視頻監控中的人臉檢測問題,由于目標非常明確,僅需要檢測人臉,不需要如此復雜的網絡,因此對其原本的特征提取網絡進行輕量化設計。需要針對實時人臉檢測這一任務特性做出以下改進。
(1)對網絡深度以及分支結構進行精簡。對比YOLO 系列使用過激活函數,目前主流的Mish 激活函數通過復雜的非線性映射進行計算,在低算力設備上會加重計算開銷,因此全部替換為擁有良好性能優化的ReLU 激活函數;同時對比了現有多種分支設計結構,最終選用由一組3 × 3 卷積、1 × 1 卷積以及恒等映射(identity)組成的RepVGG 式分支組合結構與ReLU 激活函數相結合的方式作為特征,提取主干結構的基本構成單元(REP_unit),并在原始結構上通過將單元重復次數減半來縮減通道深度。
(2)為進一步降低參數量和計算量,在訓練得到的模型基礎上采用結構重參數化的方法進行分支合并以及算子融合,從而降低計算量,進一步提升處理速度。
(3)同時針對人臉目標數據集中目標尺寸變化大,小模型訓練過程不容易收斂所導致精度大幅降低的問題,通過聚類方法對數據進行拆分訓練,提高網絡的準確率。
2.1 特征提取主干結構的改進
為構建專用硬件上計算速度高、內存小的高效模型,清華大學于2021年提出了RepVGG 式的主干設計思路:構建僅使用3 × 3卷積算子堆疊,并通過對3 × 3 卷積算子權值重新賦值派生出特殊的1 × 1 卷積分支以及恒等映射Identity 分支結合的結構。同時采用結構重參數化的方式解耦訓練時和推理時算法架構。訓練時參考ResNet 結構的分支組合思路,為每一個3 × 3 卷積添加并行的1 × 1 卷積分支和恒等映射Identity 分支,從而計算更多的特征信息,提高檢測精度。在推理時對模型做等價轉換,得到實際部署模型。由于三種卷積算子均由同一種算子派生,因此結構可轉化為無分支結構類VGG 的單路模型。此類設計的單路模型具有以下優點。
(1)單路模型并行度高,計算速度快。采用結構重參數化的方式合并分支結構,節省了內存占用。
(2)單路架構靈活性更好,容易改變各層的寬度(如剪枝)。
因此,為滿足檢測模型實時性和精度的需求,本文使用REPVGG的基本構成單元(REP_unit)對CSPDarknet53 的基本結構進行修改,并在原始結構上通過將單元重復次數減半來縮減通道深度;并針對性地將激活函數替換為具有良好硬件性能優化的ReLU 激活函數。重新設計的REP-YOLO 特征提取主干結構如圖2所示。具體細節在接下來的小節中詳細說明。

圖2 改進后的REP-YOLO 特征提取主干結構圖
2.2 結構重參數化
結構重參數化思想的核心是解耦訓練時和推理時架構,即訓練一個多分支模型;將多分支模型通過數學推理等價轉換為單路模型;最終得到部署單路模型。因此,可以同時利用多分支模型訓練時性能高的優勢以及單路模型推理時計算量小、方便模型高效部署的好處,達到獲取擁有復雜模型檢測能力的簡單模型的目的。
為實現這一思想,Ding 等人采用數學推導的方式,并經過實驗驗證了該思想的有效性。本文依照設計需求選取其中的BN(Batch Normalization)層與卷積層合并以及分支合并思想來實踐此方法。具體做法在以下兩小節進行闡述。
2.2.1 BN(batch normalization)層與卷積層合并
在深度學習網絡訓練過程中,為解決因網絡深度加深而導致梯度消失以及梯度爆炸的問題,通常選擇在卷積層處理后增加層。層通過歸一化操作使得數據滿足標準分布,從而控制梯度在合理范圍內加速網絡的收斂,并在一定程度上解決過擬合問題。整個層的計算過程數學表達見公式(1)。
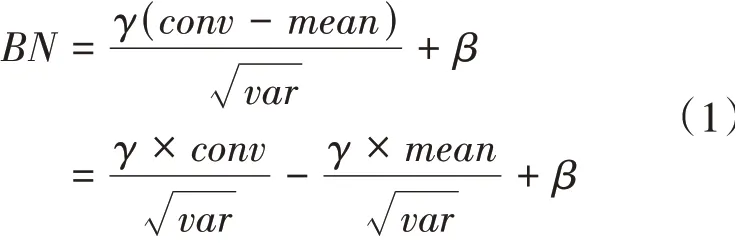
其中為層的輸入數據,也就是前一層卷積的輸出。首先求出輸入數據的均值與方差;接著使用求得的均值與方差對輸入數據進行偏移及縮放的歸一化操作,其中為縮放系數、為偏移因子。訓練過程中,,,會依照輸入的數據特征進行學習,在前向推理時固定為常數。
層在網絡前向推理時作為常數算子,會帶來額外的內存占用與計算量,因此會影響模型推理速度。考慮到本文網絡中大部分均為卷積層與層配合處理的結構,因此在部署前預先對層與卷積層進行合并,減少計算層間通信與中間存儲,從而提高實際部署模型前向推理的速度。卷積層對輸入特征圖的計算公式如公式(2)所示。

其中為卷積層權值,為偏移量。對公式(1)、(2)進行合并計算,可得出卷積層與BN 層的輸入輸出計算公式(3)。

由于卷積層與層的運算均不涉及非線性操作,因此依照矩陣操作的齊次性,合并過程同樣是線性運算,可將整體看作一個新的卷積操作,新卷積的權值與偏移如公式(4)所示,此變換不改變整體的映射關系。

2.2.2 分支合并
本文所使用的REP_unit基礎模塊結構在圖3中進行展示。圖中為原始網絡所使用的ResNet 結構,為訓練階段的REP_unit 基礎模塊,為推理階段的REP_unit基礎模塊。從可以看出,訓練時存在三路并行的3 × 3 卷積分支、1 × 1 卷積分支以及恒等映射Identity 分支。由于1 × 1卷積和恒等映射Identity分支是通過對3 × 3 卷積算子權值重新賦值派生出的結構,因此REP_unit中的1 × 1卷積是相當于一個除了卷積核中心位置權值存在,其他位置權值均為零的3 × 3 卷積,同樣的恒等映射Identity 分支操作,即輸入的每個特征元素直接對應到輸出的相應位置,相當于以單位矩陣為卷積權值的1 × 1卷積,因此也是一個特殊的3 × 3 卷積。根據卷積的可加性,將三個分支的3 × 3 卷積的加和操作等價為一個同樣對應位置是三個分支卷積對應位置加和的新3 × 3 卷積,即將網絡基礎模塊從訓練階段的多分支結構融合為推理階段的單路結構。

圖3 基礎模塊結構對比
2.3 通過聚類分析重新劃分訓練數據集
目前深度神經網絡的訓練數方法通常為隨機小批量數據加載訓練法,對于多尺度目標數據集,在數據集中隨機采樣分批訓練會導致大目標與小目標的混雜。由于網絡中模塊感受野參數固定,無法靈活地針對不同尺度的目標適應卷積參數,在訓練過程中往往造成所訓練的網絡輸出精度波動大,從而導致性能下降;而對于輕量級的深度神經網絡負面影響更嚴重。圖4 是本文采用的WIDER FACE 數據集目標分布圖,可見該數據集中目標尺度及長寬比存在分布不均衡的情況。
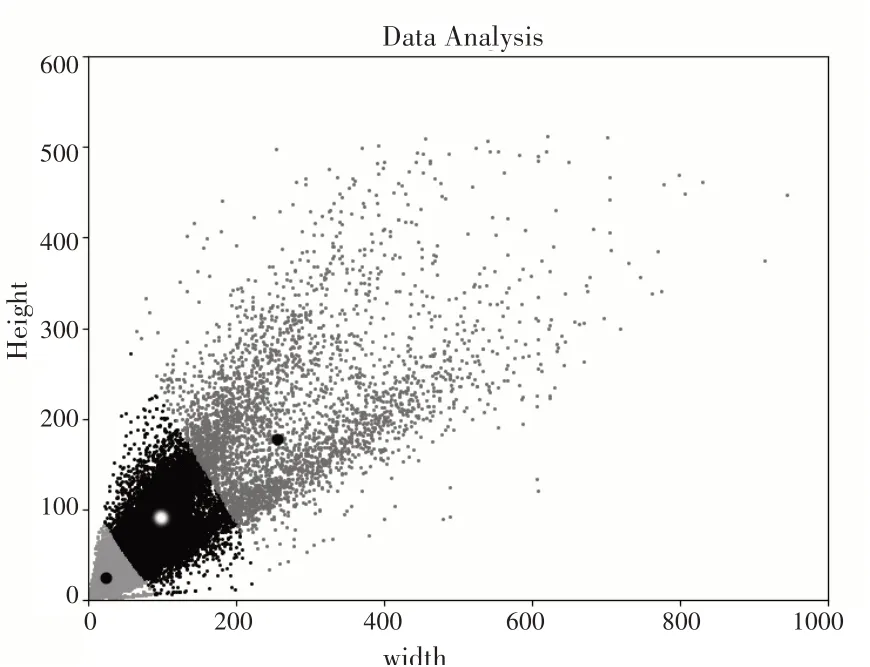
圖4 樣本分布示意圖
對目標檢測算法進行分析可知,目標所處圖像相對位置的變化并不會影響算法性能,而算法性能對目標框的長寬比以及尺寸的改變非常敏感。就YOLO 系列算法舉例,便是預選框長寬比的設置以及大中小三個檢測頭尺寸的檢測尺度與目標尺寸的適配。從這一角度出發,本文引入聚類算法以適應數據集尺度變化大的問題。
為進行聚類,本文采用數據集中標簽目標框的高、寬屬性信息作為聚類特征數據,選取歐氏距離函數作為聚類的相似性度量函數進行K-means聚類,如式(5)。

其中x,x代表數據集中不同的目標框,W,W與H,H為兩個目標框的寬與高。按照YOLO 的設計理念,將數據劃分為大中小三個聚簇。最終聚類結果如圖4所示,圖中兩個較大黑色標志點以及黑色區域的較大白色標志點表示聚類得出的三個聚簇中心,其余不同灰度顏色的標志點則分別代表三個聚簇中的目標點。
對于訓練過程,經驗可知大尺寸的輸入目標數據訓練網絡容易收斂,可獲得較高精度;而對于尺度較小的輸入數據,由于特征較小,在訓練初期模型很難收斂。對于單一目標種類的人臉檢測數據來說,即使尺寸存在差異,人臉的結構特征是相似的,因此對大尺度目標的學習也可對小尺度目標的識別提供幫助。在訓練過程中重新劃分訓練數據集進行分步訓練,先使用容易訓練的大尺度目標聚簇對整個模型網絡進行權值初始化;然后添加中尺度目標聚簇進行兩個尺度目標的混合識別推理;最終使用完整的數據集進行完整的多尺度目標識別訓練。
3 實驗過程與分析
3.1 實驗環境配置
本文的實驗環境包括訓練所用的通用GPU訓練平臺以及實際應用的FPGA平臺。通用GPU訓練平臺搭建在處理器型號為Intel Core i5-9400F,16 GB 內存,顯卡為NVIDIA GeForce GTX1080Ti,運行Ubuntu 20.04 系統的主機上,深度學習框架為Pytorch。
采用的FPGA 設備為U280 FPGA 加速計算模塊,其詳細參數見表1。

表1 U280參數表
3.2 模型評價方法
本次實驗選用以下幾個指標作為標準,以評價算法在FPGA類型的低算力設備上的運行情況:檢測精確率()、檢測速度以及模型參數量(Params)大小。
是目標檢測常用的性能指標,它表示檢測器的性能,計算過程如公式(6),表示預測正確的目標數占總的正類預測個數的比例。本文所有實驗中目標檢測交并比大于0.5 視為真目標。
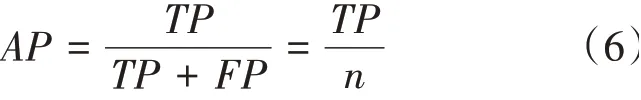
其中,為目標檢測網絡預測出的真目標數;為未能成功預測出的真目標數;+即總數為的預測目標中正類目標的總數目;檢測速度代表檢測器的檢測速度,其定義為對一張輸入圖像進行目標檢測算法所消耗的時間,單位為毫秒(ms)。通常模型參數量Params 越小,代表部署時的硬件壓力越小,越容易搭建于低算力設備中。
3.3 實驗結果以及分析
由于本文算法重點在于嵌入式設備上目標檢測算法的性能,因此選取YOLOv4、Tiny-YOLOv3、與REP-YOLO進行對比。
訓練的實驗參數設置如下:批大小設置為16,最大迭代步數設置為1000000,學習率為0.01,權重衰減設置為0.001,動量設置為0.9。
為確保模型在訓練中達到高準確率的同時在真實數據上擁有泛化性,先使用COCO數據集進行預訓練,得到主干結構的預訓練權值,再使用針對人臉目標監測的WIDER FACE 數據集進行訓練。具體的訓練過程如圖5所示。
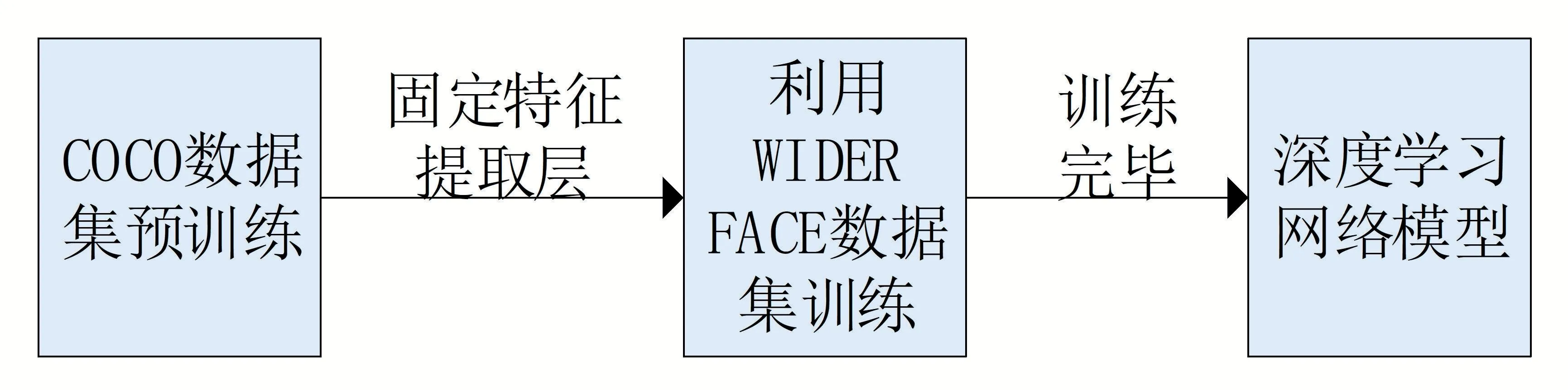
圖5 網絡訓練流程
為了對比模型實際應用場景的性能,將測試模型統一部署到FPGA 設備U280上進行測試。具體部署過程如圖6所示。
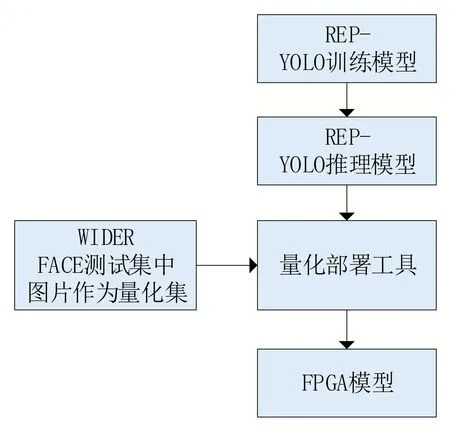
圖6 模型部署流程
為客觀評價本文所進行的各部分設計改進的具體效果,設置對基礎網絡進行不同部分修改的消融實驗,“√”表示使用相應手段進行修改,而“×”表示保持原樣,以COCO 數據集為基準輸入尺寸為608 ×608 在GPU 上進行測試,測試結果如表2所示。

表2 消融實驗
從消融實驗可以得出以下結論。從實驗1、2的測試準確率對比可以看出,實驗使用聚類分析劃分訓練集訓練的方法對于大模型來說,僅有1.3%的提升,效果不大;但從實驗3、4的測試準確率對比可以看出,對于小模型來說,使用重新劃分的數據集進行訓練可在原有基礎上提升14%,準確率從0.344 提升至0.392,因此此項技術對于小型目標檢測模型的訓練是有幫助的;同樣的,從實驗4、6 的模型參數量以及測試準確率對比可以看出,結構重參數化手段可在不改變網絡推理準確率的前提下,減少將近五分之一的參數量,從20.3 M 降至16.8 M,因此該方法可以減少模型對設備計算能力的需求,加快模型推理。
為了驗證所設計算法的實際效果,我們選取YOLOv4 以及同樣以輕量化為設計前提的YOLOv4-tiny 作為對比,測試三者使用WIDER FACE 數據集進行訓練并部署在FPGA 設備上測試人臉檢測的具體效果,結果如表3所示。

表3 WIDER FACE數據集人臉檢測結果對比
由表3 可以看出,本文算法的速度相對于YOLOv4 來說提升了2.2 倍,而即使是同樣輕量化設計的YOLOv4-tiny,速度依然有1.5 倍的提升;在檢測準確率方面,對于簡單目標與中等目標,本文算法檢測精度與YOLOv4-tiny 相差無幾,僅略遜于YOLOv4。在困難目標檢測方面,由于此類目標場景存在分辨率小、部分遮擋以及姿態變化等復雜難點,輕量化設計的特征提取主干結構能力稍有不足,但仍能成功檢測出將近八成目標。
為直觀展示改進算法在真實場景下的效果,我們從網上隨機選取若干圖片進行人臉檢測,檢測結果如圖7所示,可以看出在真實場景下算法有著良好的泛化性能。

圖7 算法效果展示
4 結語
針對目前算法依賴于大參數量以及高算力設備,在應用到現實場景的人臉檢測任務時受到限制的現狀,本文設計了一種基于YOLO 的識別改進算法。通過使用REPVGG 式結構結合結構重參數化方法對YOLO 目標檢測算法主干進行了精簡,并通過聚類分析劃分訓練集分批次訓練的方法來保證輕量化結構的準確性。實驗結果表明,該算法針對中大型人臉目標的檢測具有良好的可靠性,同時該算法模型在FPGA類型的低算力設備上能實時進行準確的目標檢測。在接下來的研究中,將結合模型的量化與剪枝算法對深度神經網絡參數量做進一步壓縮,以此確保精度的前提下達到更高的實時性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
