影響花生秧近紅外光譜預測準確性因素的分析
2022-06-28 01:17:42李改英王春秀蔡阿敏廉紅霞張立陽高騰云
江西農業學報 2022年4期
李改英,王春秀,蔡阿敏,廉紅霞,張立陽,傅 彤,高騰云
(河南農業大學 動物科技學院,河南 鄭州 450046)
花生是我國種植面積最大的油料作物之一,花生秧是花生收獲后的副產品,其產量高,營養豐富,約占花生生物總量的50%,在我國平均年產量約2700萬t[1]。花生在河南省已經成為繼小麥、玉米之后的第三大農作物,2018年花生秧產量約600萬t[2]。花生秧的粗蛋白含量僅低于紫花苜蓿[1],是牛、羊等反芻動物的優質粗飼料資源。常規營養成分的含量是評價飼料營養價值的主要依據,目前對樣品營養成分含量的測定分析主要采用傳統的方法,但耗時費力,檢測誤差大,檢測費用較高,對樣品具有破壞性,不能夠實時快速進行檢測[3]。近紅外光譜(NIRS)技術利用有機物中含氫化學鍵(X-H)振動,以漫反射方式在近紅外區域獲得相應的吸收光譜,通過多元線性回歸分析、主成分分析、最小偏二乘法等現代化學計量方法建立反映物質光譜和待測成分含量之間關系的數學模型,實現對待測成分含量的快速計算。但是,近紅外技術在實際推廣應用中還存在一些缺點,如靈敏度低、模型精度要求高等[4];此外儀器類型、樣品的形態、試驗因素、光譜處理和分析方法等均會影響模型的精度,從而影響預測結果的準確性[5]。本研究采用濕化學方法和近紅外掃描技術檢測了花生秧樣品的營養成分含量,并從樣品數量、粉碎粒度、測定指標、計量方法及模型選擇等方面分析了影響花生秧近紅外光譜模型預測準確性的各種因素,旨在為后期建立和完善預測模型提供借鑒和參考。
1 材料與方法
1.1 試驗樣品
按照五點采樣法采集不同地區不同品種的花生秧樣品92份,去除花生秧上的雜質,并在65 ℃的烘箱中烘干48 h,然后將風干的樣品粉碎,制作成待測樣品。
1.2 測定方法
采用NIRS技術和濕化學方法分別對采集的花生秧樣品的主要營養成分含量進行測定,之后對其測定結果進行相應的分析。
1.3 NIRS掃描及模型的建立
采用美國Unity公司生產的Spectrastar 1400Xl-3型光譜分析儀,對花生秧樣品進行光譜掃描和信息采集。將通過濕化學方法測定的花生秧的營養成分含量數據以及通過近紅外光譜儀收集的樣品的光譜信息數據分別導入到建模軟件中,對光譜圖中的異常數據進行篩選和剔除,采用不同的預處理方法建立校正模型,應用最優預測模型對花生秧樣品的營養成分含量進行預測。
2 結果與分析
2.1 用濕化學方法測定花生秧樣品主要營養成分的含量
用濕化學方法測定的花生秧樣品中各營養成分的含量如表1所示,92個花生秧試驗樣品中的粗蛋白質、干物質、中性洗滌纖維、酸性洗滌纖維、粗脂肪、粗灰分、鈣、磷含量的變動范圍分別為5.11%~16.96%、88.58%~94.56%、39.23%~65.21%、28.99%~51.51%、0.215%~5.760%、2.535~21.660%、0.767%~2.179%、0.025%~0.174%。各營養成分含量波動大,覆蓋范圍廣,樣品數量多,因此具備代表性。
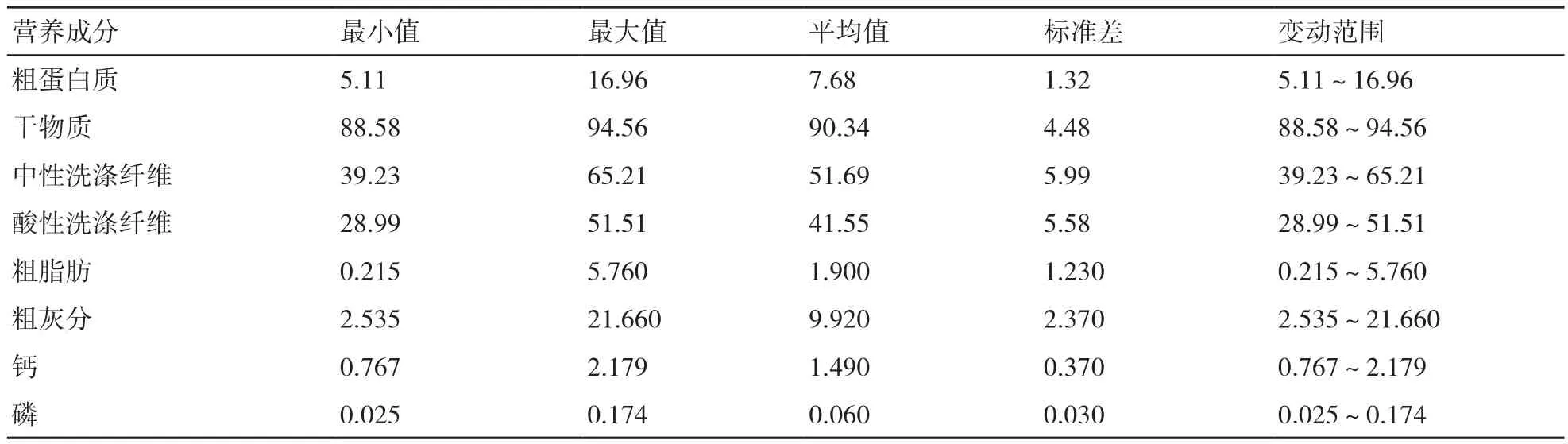
表1 用濕化學方法測定的花生秧樣品主要營養成分的含量 %
2.2 用NIRS技術掃描得到的預測值的離散度分析
標準差的大小受每個預測值的影響,當預測值的變異越大時,其標準差也越大。花生秧樣品各營養成分含量預測值的最小值、最大值、平均值、標準差以及變異系數見表2。變異系數表示測定結果的離散程度,也反映了NIRS技術掃描得到的預測值的變異程度。在各營養成分中,干物質和中性洗滌纖維含量預測值的變異系數較低,表明以均數為準的預測值的分散程度小;而粗脂肪、鈣、磷含量預測值的變異系數較大。
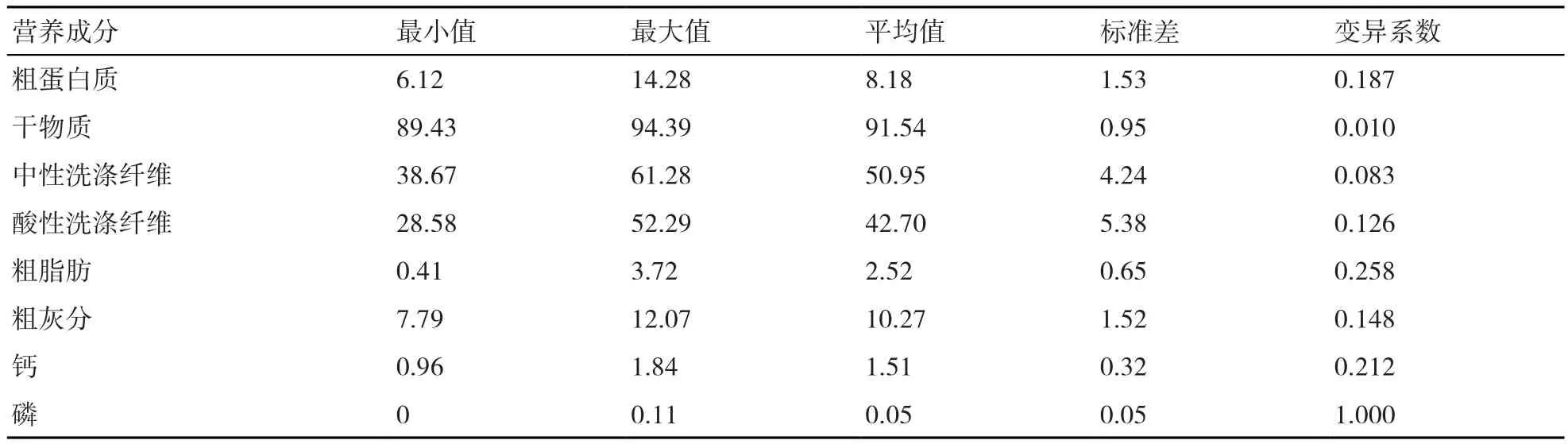
表2 用NIRS技術得到的花生秧樣品營養成分含量的預測值 %
2.3 樣品數量和測定指標對近紅外預測結果的影響
表3為花生秧不同樣本數量和不同測定指標的預測值與實測值之間的交叉驗證相關系數(RSQV)。由表3可知:隨著樣本數量的增加,不同測定指標的預測值與實測值間的RSQV值均增大,其中以粗蛋白質、 干物質、粗灰分、鈣最為明顯;在不同的測定指標中,粗蛋白質、干物質、中性洗滌纖維、酸性洗滌纖維的RSQV值較高,預測效果較好。可見,樣本數量影響NIRS技術預測的準確性,樣本數量越多,NIRS技術預測的準確性越高。同時在預測花生秧樣品的粗蛋白質、干物質、中性洗滌纖維、酸性洗滌纖維含量時準確性更高,更穩定,而對鈣、磷含量的預測效果不理想。
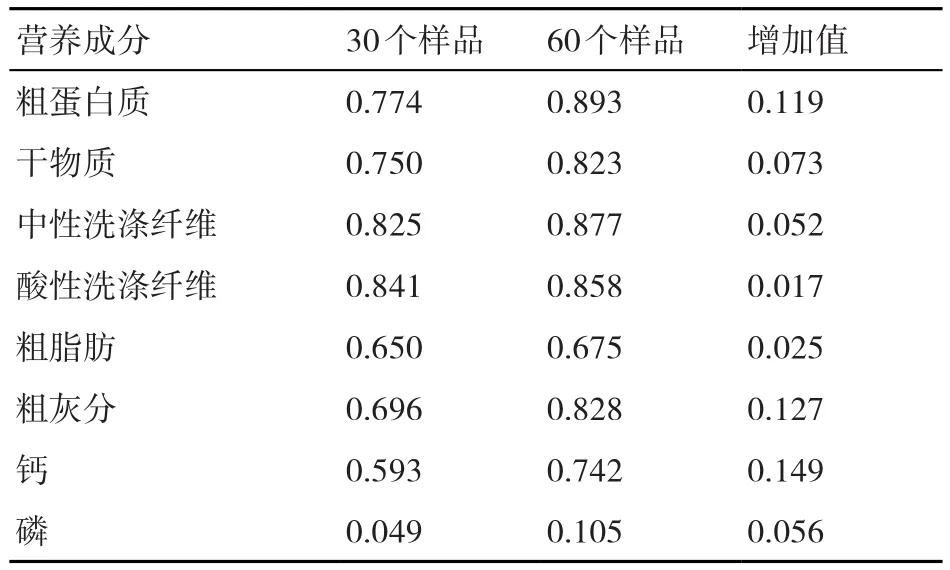
表3 花生秧不同樣本數量和測定指標的預測值與實測值之間的RSQV值
2.4 粒度對近紅外預測結果的影響
由表4可以看出:6目樣品集各指標(除粗蛋白質和中性洗滌纖維外)的RSQ和RSQV值均小于0.7,而SEC和SECV值總體均較大;18目樣品集各指標的RSQ和RSQV值總體上大于6目樣品集,而且SEC和SECV值總體上小于6目樣品集,說明18目樣品集的預測精度高于6目樣品集;40目樣品集各指標的RSQ和RSQV值總體上大于18目樣品集,而且SEC和SECV值總體上小于18目樣品集,說明40目樣品集的預測精度得到了進一步提高。因此,在建立花生秧樣品的近紅外快速檢測模型時,宜將樣品粉碎至40目。
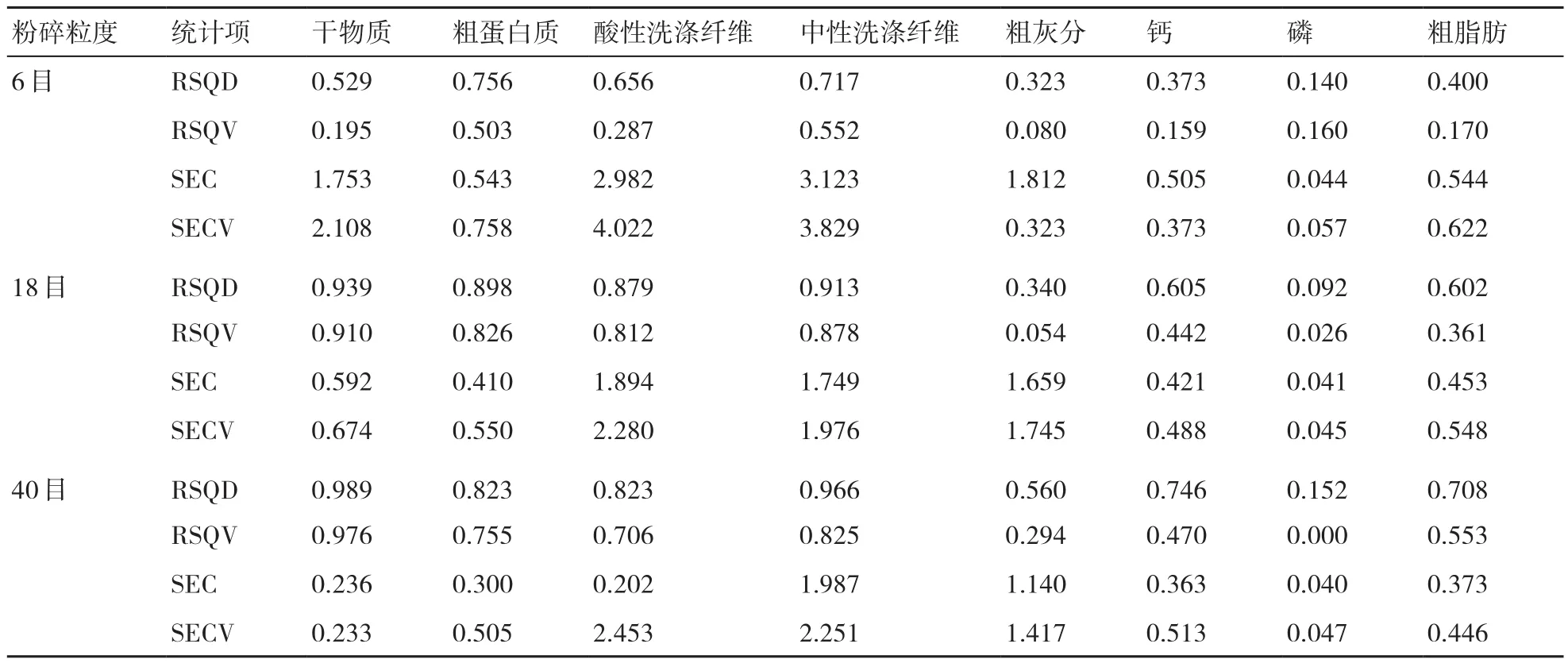
表4 不同粉碎粒度對花生秧各營養成分含量預測效果的影響
2.5 參數設置和計量方法對定標結果的影響
2.5.1 不同離群值對粗蛋白定標結果的影響 離群值也稱為逸出值,是指在樣本數據中與其他數據相比差異比較大、應當舍棄的一個或幾個數值。離群值的選擇會影響模型預測的準確性。表5為選擇不同離群值對粗蛋白定標結果的影響,由表5可知,隨著離群值的下降以及離群值數量的減少,群體數據增多,定標相關系數也逐漸增大,交叉驗證相關系數和定標誤差先增大后變小;當離群值達到5.0時交叉驗證誤差達到一個較低值;當離群值進一步增大而離群數量不變時,模型誤差增大。經綜合評判,建立預測模型時樣本的離群值不宜大于5.0。
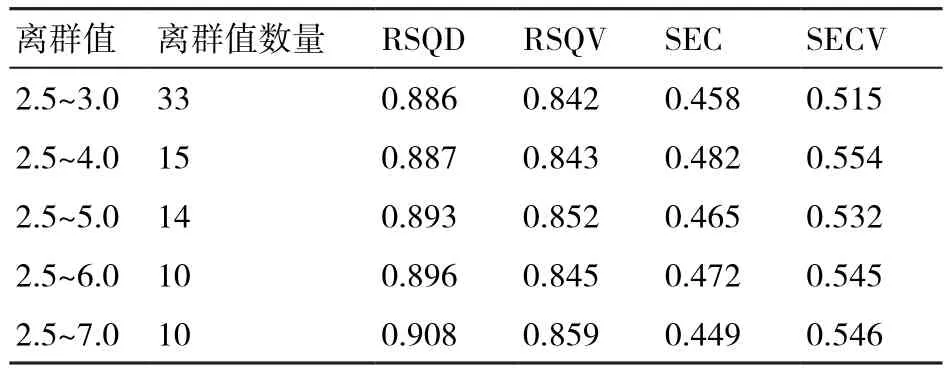
表5 離群值對粗蛋白定標結果的影響
2.5.2 不同計量方法對粗蛋白模型定標結果的影響 將離群值設置為2.5~5.0,分析了不同計量方法對粗蛋白定標結果的影響,結果如表6所示,采用標準正態(SNV)+一階導數(1st Derivative)計量方法的相關系數高,誤差小;采用SNV/Detrend相結合的計量方法時定標系數略有降低,但是誤差也隨之減少;相比于一階導數的計量方法,二階導數(2nd Derivative)處理模型的定標系數有所提高,誤差明顯減少。經初步判斷,在試驗設定的樣本數量條件下,粗蛋白定標模型采用SNV/Detrend+二階導數計量方法的效果較好。

表6 不同計量方法對粗蛋白定標結果的影響
2.5.3 模型選擇對花生秧各營養成分定標結果的影響 計量方法的選擇會影響花生秧各營養成分含量的預測效果,不同的測定指標需要選擇不同的處理方法。通過對數據庫的優化處理和模型的反復修正選擇,花生秧各測定指標模型的最佳計量方法和結果見表7。各指標的計量方法均選擇標準正態變換處理(SNV),其中粗灰分采用一階導數處理,鈣和磷分別采用一階導數去散射處理和二階導數處理后,定標結果得到了優化,但定標系數較低;酸性洗滌纖維、粗脂肪均采用二階導數去散射處理,定標效果最佳;粗蛋白質、干物質、中性洗滌纖維分別采用二階導數去散射、一階導數、一階導數去散射處理后,定標結果最佳,相關系數均在0.90以上,能夠達到準確預測的效果。

表7 不同化學計量方法對花生秧各營養成分定標結果的影響
3 討論
近紅外掃描受外部環境、儀器穩定性以及測定樣品本身等多重因素的影響。在操作中應保持樣品的一致性以及儀器的清潔,保證每次填裝都不受雜質的干擾;在建立近紅外預測模型之前,要對光譜圖進行預處理,以去除干擾信息,使建立的近紅外預測模型更加穩定[6]。此外,樣品本身的差異對預測效果也有影響,樣品集的代表性,花生秧的刈割時間、品種、來源地、部位和種植水平等,都會導致其營養成分含量的差異[7]。
3.1 樣品數量和測定指標對近紅外預測結果的影響
在建立定標模型的過程中,樣品集的數量和參比值含量范圍對模型預測的精確度起著關鍵作用[8]。樣品數量越多,其各個營養成分含量的分布范圍越大,NIRS技術預測的準確性越高。本試驗采集不同地區不同品種的花生秧,經過濕化學分析和初步預測分析,證明所采集的樣品具有代表性。本試驗發現:隨著花生秧樣品數量的增多,模型預測的準確性提高,其中60個樣品集的RSQV值大于30個樣品集的RSQV值;粗蛋白質、干物質、中性洗滌纖維、酸性洗滌纖維這4個指標的RSQV值較高,預測效果較好;而鈣、磷、粗脂肪含量低,預測效果不理想,這可能與物質的結構和含量有關,因為NIRS技術對含有R-H和X-H鍵的無機物和高含量成分的吸收較好,準確性高。田曠達等[9]采用近紅外光譜法結合最小二乘支持向量機測定了煙葉中鈣、鎂的含量,校正集的決定系數分別為0.9755和0.9961,證明該方法是可行的。一般來說近紅外預測的極限含量是0.1%[10]。在本試驗中,花生秧磷的平均含量只有0.06%,鈣和粗脂肪的含量也比較低,并且鈣、磷不含R-H鍵,這些是預測不準確的主要原因。
3.2 粒度對近紅外預測結果的影響
樣品粒度會影響光對樣品的穿透性和反射性,當粒度大時漫反射吸光度增加,造成光譜的重現性變差,影響準確性。楊丹等[11]的研究結果表明,茶樣的粒度越小,均勻性越強,穩定性和準確性越好。吳文輝等[12]研究了樣品粒度對附子近紅外(NIR)定量模型準確性的影響,發現粒度越大,誤差越大;而中粉和極細粉的測定值較為穩定。朱貞映[13]利用近紅外技術研究了整粒和粉碎顆粒(10、20、40、60和80目)對大豆建模的影響,結果表明:準確測定水分含量需要樣品粉碎過篩40目;準確測定粗脂肪和蛋白質含量需要粉碎過篩60目。本研究結果表明:隨著花生秧樣品粉碎目數的增加,各測定指標模型的相關系數逐漸增大,因此最佳粉碎粒度為40目。
3.3 參數設置和計量方法對定標結果的影響
選擇合適的計量方法和光譜預處理,能有效地降低噪聲,減少干擾,簡化運算,提高預測的準確性[14]。偏最小二乘法具有抗干擾能力強、易于回歸建模和識別系統的信息與噪聲等優點,是近紅外建模常用的方法[15]。該方法在吸光度與化學組分含量呈線性關系的條件下所得結果十分準確。但受光的散射和化學鍵締結等因素的影響,化學組分含量與紅外光譜還會呈現復雜的非線性關系。對于固體粉末樣品,多元散射校正和標準正態變換是有效的散射校正方法;此外,常用的方法還有平滑、求導、去趨勢和標準化等[16]。導數處理可以提高光譜的分辨率,減少基線漂移[17]。李朋成等[14]用偏最小二乘法建立了126個玉米樣本蛋白質、脂肪和纖維素的模型,結果顯示,模型的決定系數均大于0.95,定標集的均方誤差均小于0.14。陰佳鴻等[18]測試了不同含水量的燕麥種子,發現采用多元散射校正預處理方法所建立的近紅外定量模型效果最佳,對預測集和校正集樣本的鑒別率可以達到100%。本研究結果表明:花生秧粗蛋白模型的最佳離群值不宜大于5;粗蛋白定標模型的最佳計量方法是SNV/Detrend+二階導數預處理;通過SNV處理后,干物質用一階導數處理后預測的效果最佳,中性洗滌纖維通過去趨勢校正和一階導數處理后預測的效果較佳,粗蛋白質通過去趨勢校正和二階導數處理后預測的效果最佳,而鈣、磷、粗灰分的含量無法準確預測。可見,不同的測定指標需要采用不同的化學計量方法,合理的化學計量方法對提高NIRS預測花生秧各營養成分含量的準確性有重要作用。
4 結論
樣本數量、粉碎粒度和營養成分含量均會影響花生秧營養成分含量預測結果的準確性,樣本越大,含量越高時預測準確性越高;粗蛋白質、干物質、中性洗滌纖維、酸性洗滌纖維的含量高,因此預測的準確性更高、更穩定,而粗脂肪、鈣、磷的含量太低,不能準確預測;花生秧的最佳粒度為40目。參數設置和計量方法的選擇會影響預測的準確性,不同的預測指標需要采用不同的化學計量方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
