基于視覺注意力機制的人群密度估計方法
2022-06-24 10:02:30朱利華朱玲玲
計算機應用與軟件 2022年4期
關鍵詞:特征
朱利華 朱玲玲
1(常州信息職業技術學院軟件與大數據學院 江蘇 常州213164) 2(南通大學信息科學技術學院 江蘇 南通 226200)
0 引 言
人群密度估計是關注在一定時間和空間內的人群密度分布情況,在現實生活中人群密度分析存在許多方面的應用,如公共安全、交通監控和城市規劃等[1]。在人群密度估計中采用的計算方法也能夠應用于其他領域,如顯微圖像中的細胞計數、交通控制中的車輛計算等方面。目前,人群計數仍然面臨嚴重遮擋、透視失真、光照變化、人群分布不均勻及尺度不一等諸多方面的挑戰問題[2-3]。
大多數人群密度估計方法均是先從圖像中提取底層特征,然后采取不同的技術方法將這些特征映射到密度圖中。現有的人群計數方法大致可以分為三類[4],分別為基于檢測的方法[5]、基于回歸的方法[6]及基于密度估計的方法[7]。與基于檢測和回歸的方法相比,基于密度估計的方法能夠提供更多的人群分布空間信息,因此大多數人群計數方法采用密度估計方法。最初的人群計數工作主要采用手工特征,隨著卷積神經網絡的發展,由于其豐富的自動特征,在人群計數任務中取得了顯著的進展。人群計數面臨許多挑戰,如遮擋、場景內和場景間的尺度變化及密度不均勻。Xu等[8]提出了一種基于條件生成對抗框架的人群計數方法,利用生成器和鑒別器之間的博弈,實現了人群圖像到密度圖的高質量轉換。Wan等[9]提出了一種殘差回歸人群密度估計模型,通過在殘差網絡模型中引入樣本間的相關信息學習更多的內在特征,進而有效地利用不同場景的語義信息來提高人群密度估計精度。由于上述方法對不同尺度的特征圖進行,在一定程度上造成數據冗余,增加計算量。
近年來,注意力模型在各種計算機視覺任務中取得了巨大成功[10]。注意力機制不是從整個圖像中提取特征,而是根據模型需求有選擇地關注某些有用的視覺信息而忽略其他部分,實質上是一種加權共享的思想。Zhang等[11]利用局部和全局自注意力兩個模塊有效地捕獲像素的長距離和短距離依賴,然后采用關系模塊進行融合,解決密度圖中像素間的相互依賴關系,該方法主要采用自注意力機制和關系模塊來增強群組計數的特征表示。Liu等[12]提出一種注意力嵌入可變形卷積網絡,首先利用注意感知網絡檢測圖像中人群的擁擠程度,然后通過多尺度可變形網絡生成高質量的密度圖,該方法主要利用空間注意力機制,對特征圖中的重要區域進行檢測。Gao等[13]提出了一種基于空間和通道注意力的再聚集網絡,利用空間注意力和通道注意力來估計密度圖,但其未能很好地關聯兩種注意力獲取的特征信息,對目標區域的分辨能力不強。
針對人群圖像中尺度變化大及現有密度估計方法存在泛化性能差的問題,提出了一種基于視覺注意力機制的人群密度估計方法,通過在各個VGG-16層級采用空間注意力和通道注意力機制,達到選擇性地增強網絡不同層的功能,提高多尺度級聯的有效性。同時,本文設計了一個弱監督學習框架,使人群密度估計模型可以適應不同的場景和數據集。
1 視覺注意力機制
視覺注意力機制是人類視覺所特有的大腦信號處理機制。人類視覺通過快速掃描全局圖像,獲得需要重點關注的目標區域,然后對該區域投入更多注意力資源,以獲取更多所需要關注目標的細節信息,抑制其他無用信息。視覺注意機制極大地提高了信息處理的效率與準確性。
視覺注意力機制其實是從大量信息中有選擇性地篩選出少量重要信息,并且聚焦這些重要信息,忽略大多不重要的信息,提高運算效率,如圖1所示。

圖1 視覺注意力機制示意圖
信息源S中的元素是由一系列的數據對構成,目標元素為Q,通過計算Q和信息源中每個元素ki的相似性,得到ki對應的權重系數Vi。然后對Vi進行加權求和,得到最終的視覺注意值Att。視覺注意力機制本質思想就是對S中元素的權值系數Vi進行加權求和,其數學公式可被定義為:
(1)

2 方法設計
2.1 人群密度估計模型
由于同一圖像內不同空間位置處的人群頭部尺度可能會存在較大變化,因此本文在使用VGG16網絡中不同卷積層的特征映射來捕獲多尺度信息,同時將空間注意力模塊(SAM)和全局注意力模塊(GAM)引入到密度估計網絡中來提高計數性能。本文方法具體的模塊如圖2所示,基本網絡由VGG16網絡的卷積層(conv1-conv5)組成。conv3層特征由SAM進行增強,conv4層和conv5層的特征由GAM進行信道增強。conv3層的增強特征映射由3個卷積層組成的卷積模塊A進行轉發,均使用ReLU激活函數,轉發卷積模塊A定義為:Conv2d(256,64,1)、Conv2d(64,64,3)、Conv2d(64,24,1)。conv4層和conv5側的增強特征通過由3個卷積層組成的卷積模塊B和上采樣層轉發,從而保證將特征映射縮放到與conv3特征映射相同的尺度。卷積模塊A定義為:Conv2d(512,64,1)、Conv2d(64,64,3)、Conv2d(64,24,1)。最后,利用這些融合模塊將經過增強后的特征連接起來,生成最終的密度圖。融合模塊的卷積層定義為:Conv2d(72,64,1)、Conv2d(64,64,3)、Conv2d(64,1,1)。本文采用預測密度圖和真實密度圖之間的歐氏距離最小化來訓練網絡,數學公式定義如下:
(2)
式中:N是訓練樣本數;Xi表示第i個輸入圖像;Fd(Xi,Θ)是估計密度;Di是第i個真實值密度。Di通過將以每人的位置xg為中心的二維高斯核求和來計算:
(3)
式中:σ是二維高斯核的尺度參數;S是人群所處位置的所有點的集合。網絡生成的密度圖是輸入圖像分辨率的1/4,密度圖的總和提供了輸入圖像中人群數量的估計。

圖2 本文方法流程
2.1.1空間注意力模塊
空間注意的目標是在特征圖中選擇注意區域,然后用于動態增強特征響應。與現有工作中采用自我監督方式學習空間注意力相比,本文使用前景背景分割方式來進行監督學習。由于空間注意力模塊的關注目標是與前景區域存在關聯的相關區域,因此將前景背景信息注入網絡,采用標簽的方式來監督學習模塊,從而迫使網絡關注前景中的相關區域。由于這些標簽很容易獲得,因此不需要額外的注釋工作。

通過這種注意機制,能夠將分割意識引入低級別特征圖。如圖3所示,通過抑制不相關區域和增強前景區域,將分割信息用于網絡來豐富特征圖。然后將激勵的特征圖轉發到融合模塊(FM),在融合塊中,它們與來自其他層的特征融合以生成最終的密度圖。
通過預測分割映射和對應的真實值之間的交叉熵誤差最小化來學習SAM的權重。通常,分割任務需要逐像素注釋。本文對現有的真實密度圖注釋進行閾值處理以真實值分割映射,然后將其用于訓練空間注意模塊。在注釋時,包含頭部區域的像素標記為1(前景),否則標記為0(背景)。因此,本文方法不需要任何額外的標記。盡管這些注釋是有噪聲的,但使用分割信息會產生相當大的收益。
2.1.2全局注意力模塊
與參與低層特征圖中的相關空間位置的空間注意力模塊相比,全局注意力模塊則被設計為關注信道維度中的特征圖。全局注意力模塊使用來自中樞網絡的特征映射并學習計算沿著信道維度的注意力。計算的注意力可以捕獲特征圖中的重要通道,從而有助于抑制來自不必要通道的信息,該模塊從空間維度方面來看是在全局范圍內運行。由于通道可以捕獲物體的不同部分或者不同類別物體的存在情況,因此通道注意力是增強物體和圖像注釋之間相關性的有效方式。
基于上述考慮,本文給出了一組全局關注力模塊,這些模塊采用較高卷積層的特征圖作為輸入,并生成通道注意映射,然后用于激勵通道維度特征圖。在數學上,給定特征映射輸入X∈RW×H×C,首先,GAM利用式(4)執行空間池化操作生成池化特征Y∈R1×1×C。
(4)

2.2 弱監督學習
現有方法提高跨數據集性能的解決方案通過以完全監督或半監督的方式進行微調。與這些方法相比,本文提出了一種弱監督的方法來訓練新數據集上的計數網絡。這樣的設置將簡化培訓過程,不需要點式注釋。群體計數是一個回歸問題,執行弱監督的群組計數是將人群計數轉化為人群密度分類任務,即不計算圖像中的人數,而是將圖像重新劃分為六類標簽,即標簽集合C={零密度,極低密度,低密度,中等密度,高密度,極高密度}。本文利用標簽將計數問題轉化為弱監督學習的分類任務。
圖4給出了用于適應新目標場景或者數據集所提出的弱監督方法。與使用預先訓練的CNN語義分割類似,將弱監督方法引入計數網絡時需要利用源數據集進行預先訓練。因此,在計數網絡融合模塊之前增加一個類激活映射模塊(CAMM),該模塊由以下4個卷積層組成:Conv2d(72,64,3)、Conv2d(64,64,3)、Conv2d(64,32,3)和Conv2d(32,6,3)。

圖4 弱監督學習示意圖
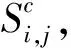
一般來說,聚合函數可以分為全局平均池化(GAP)和全局最大池化(GMP)兩類。對于GAP,分數映射中的所有像素都被賦予相同的權重,但是不屬于圖像的類標簽也會被賦值;對于GMP則通過向得分貢獻最大的像素分配權重來解決這個問題,但是訓練緩慢。因此,本文選擇對最大函數進行平滑和凸近似作為聚合函數:
(5)
式中:sc表示c類的聚合分數;r是控制平滑度的超參數;w、h表示分數映射的寬度和高度。然后將Soft-max函數應用于聚合的類分數,使用標準二元交叉熵損失函數訓練CAMM模塊。在訓練期間,密度估計網絡的參數保持固定。上述過程獲得的類分數映射可以表示圖像中屬于特定密度水平的區域或像素,而這些類分數映射可以用于目標集偽真實密度圖的近似:
(6)

將真實值密度圖應用于監控目標數據集上的密度估計網絡。在微調過程中,VGG-16網絡的權重是固定的,只更新后面卷積層的權重,從而確保了所得到的估計密度圖更清晰。盡管網絡是使用圖像級標簽訓練的,但是該網絡也學會了為目標集生成密度圖。因此,在測試過程中,目標集的測試圖像通過網絡轉發來估計密度圖。
3 實 驗
本文使用Adam優化器進行端到端地網絡訓練,學習率為0.000 05,單個NVIDIA GPU Titan Xp的動量為0.9。預留訓練集10%的圖像用于測試。為了防止網絡過擬合,在訓練集上進行了數據增加操作:從每個訓練圖像中的不同區域中裁剪出9個尺寸為224×224的圖像塊,然后采用對裁剪圖像進行隨機翻轉、添加隨機噪聲等方式來形成最終訓練數據集。
3.1 評價標準
為了測試本文算法的性能表現,采用平均絕對誤差(MAE)和平均平方誤差(MSE)進行評估,兩個評價標準的定義如下:
(7)
(8)

3.2 數據集
采用Shanghai Tech[2]數據集、UCF_CC_50數據集[14]及UCF-QNRF[7]數據集來測試本文算法的性能,同時與現在一些最新算法進行對比。實驗過程中,對UCF_CC_50數據集采用5次交叉驗證,Shanghai Tech和UCF-QNRF數據集使用標準訓練和測試分割方式進行測試。
UCF_CC_50是一個極具挑戰性的數據集,該數據集包含50個不同場景的注釋圖像,圖像具有不同的分辨率、寬高比和透視扭曲,而且該數據集的圖像中的人數從94到4 543不等。Shanghai Tech數據集包含1 198幅標記圖像,數據集分為part A和part B兩部分,part B部分的圖片相較于part A部分的圖像人群分布更為稀疏。part_A部分482幅圖像中300幅用于訓練,182幅用于測試;part_A部分716幅圖像中400幅用于訓練,316個用于測試。UCF-QNR是一個比較新的數據集,包含1 535個高質量圖像,總共125萬個注釋,訓練和測試集分別由1 201和334幅圖像組成。
3.3 實驗結果分析
首先給出了在不同數據集中測試的視覺效果,如圖5-圖7所示。一般來說,采用的三個數據集具有不同的特點:Shanghai Tech A的場景是擁擠和嘈雜的,Shanghai Tech B的樣本噪音很大,但并不擁擠;UCF-CC 50數據集由非常擁擠的場景組成,這些場景幾乎沒有任何背景噪聲;UCF-QNRF數據集則具有人群分布不均,閉塞阻擋較多的場景。從測試密度圖中可以看出,本文算法不僅在人群密集中等場景的Shanghai Tech數據集上有效,而且在人群密度較大場景的UCF_CC_50數據集上及人群密度較小但尺度變化很大的場景UCF-QNRF數據集上依然表現良好,從而充分說明提出算法的適用性。而且本文算法中采用的空間注意力和全局通道注意力模塊在細粒度特征提取方面的表現更好,能夠生成高質量的人群密度圖,有效降低計數誤差并提高基準數據集的準確性。

圖5 ShanghaiTech數據集的預測和真實密度圖對比

圖6 UCF_CC_50數據集的預測和真實密度圖對比

圖7 UCF-QNRF數據集的預測和真實密度圖對比
為了進一步驗證算法的有效性,對提出的方法進行了定量評估,并將其測試結果與深度尺度凈化網絡模型(DSPNet)[2]、自適應密度圖生成器模型(ADMG)[7]、群體注意卷積神經網絡模型(CAT-CNN)[10]、注意力嵌入可變形卷積網絡模型(ADCrowdNet)[12]、混合空間-通道注意力回歸網絡模型(SCAR)和尺度保留網絡模型(SPN)等先進人群計數方法進行對比。
表1給出了不同算法在Shanghai Tech數據集A和B部分的實驗結果。可以看出,與其他幾種算法相比,本文算法在四個結果中有三個達到了最好的性能,在Shanghai Tech B的MSE測試指標上比SPN模型稍低,這表示本文算法的穩健性在Shanghai Tech B數據集中表現稍弱。

表1 不同算法在Shanghai Tech數據集的測試結果
表2給出了不同算法在UCF_CC_50數據集的實驗結果。可以看出,本文算法在MAE和MSE指標上取得較好的結果,只在MAE稍低于SPN模型,取得次優值。

表2 不同算法在UCF_CC_50數據集的測試結果
表3給出了不同算法在UCF-QNRF數據集的實驗結果。通過對比每個數據集上不同算法的測試結果,發現在該數據集上,提出的模型在MAE和MSE方面明顯優于其他方法。

表3 不同算法在UCF-QNRF數據集的測試結果
4 結 語
為了解決人群圖像尺度變化劇烈及現有密度估計網絡泛化性能差的問題,本文提出一種基于視覺注意力機制的人群密度估計方法。該方法在VGG16網絡的conv3層特征引入空間注意機制動態增強特征圖中的關注區域,在conv4、conv5層引入全局注意機制進行信道維度中的特征圖增強,從而提高多尺度級聯的有效性。而且,為了提高本文方法在不同場景和數據集的適應性,設計了一個弱監督學習來擴展提出的密度估計網絡。實驗結果表明,提出的方法在不同尺度、不同場景下的人群密度圖像都有很好性能表現,相對于現有的人群密度估計算法也具有極大的優勢。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
