基于GitHub數據的安全性需求用戶故事生成
2022-06-23 11:00:16張曉妘鄭麗偉
計算機工程與設計 2022年6期
關鍵詞:用戶
張曉妘,鄭麗偉
(北京信息科技大學 計算機學院,北京 100101)
0 引 言
在開發大型軟件項目的過程中,軟件需求通常頻繁變更并且該過程通常貫穿整個軟件開發周期,開發者需要經過長時間的反復發現和認識才能逐步明確軟件需求。因此,軟件開發者也開始逐漸將一部分的注意力從軟件開發編程階段轉移到了軟件需求設計階段以減少軟件產品的迭代次數。軟件需求按照軟件功能性可以分為功能性需求和非功能性需求兩類[1]。相較于功能性需求,軟件的非功能性需求往往具有較大的隱含性和不確定性,難以準確獲取。
近年來,針對軟件需求的表示、抽取、挖掘等工作取得顯著成果,但也存在用戶需求數據較難獲取,數據種類較單一,挖掘結果易受領域局限等問題。針對這些問題,我們認為通過機器學習方法從GitHub等軟件開發類社交平臺的海量數據中發現潛在的軟件非功能需求是一種可行的思路。本文以軟件非功能性需求中較為重要的安全性需求作為切入點,以GitHub中龐大的Issues討論數據作為挖掘對象,利用自然語言處理中的實體識別技術對句子中的連接實體進行識別并在此背景下設計出了一種用戶故事生成方法——CreUS用戶故事生成方法,旨在將抽取到的用戶安全需求以用戶故事這種結構化的方法表示出來。所生成的用戶故事集,不僅可用于支持Issues所在項目的開發迭代,還可以作為領域知識,在同領域類似項目的需求發現中起到重要的參考和輔助作用。
1 研究背景
1.1 需求工程
在計算機剛剛發展起來的階段,人們對于軟件項目的開發大多關注在如何更好進行代碼編寫上。隨著編程技術發展的日趨成熟,人們開始將更多的焦點轉移到了需求分析上。一開始,軟件需求分析階段僅僅只是作為軟件開發生命周期中的第一階段,隨著軟件項目規模不斷擴大,其復雜性也相應增加,需要被滿足的功能愈來愈多。伴隨著諸多問題的產生,人們意識到如果只是把需求分析階段作為一個開發過程中的階段是不夠的,也許在軟件開發整個生命周期中都會伴隨著需求的增加與改進。在80年代中期,需求工程(requirement engineering,RE)作為軟件工程的一個子領域被提出,這也意味著軟件需求工程開始作為一個獨立的研究方向出現。
1.2 安全性需求探索
研究者對安全性需求的探索從未中斷,甚至在需求工程和安全的交叉領域提出了安全需求工程的概念。安全需求工程旨在通過一系列框架方法來重新解決軟件安全需求相關問題。例如Guarín等[2]對容易遭到攻擊的財產去進行危險分析從而從風險角度來獲取安全需求,把網絡應用程序作為研究目標,通過提出一種在敏捷環境下的安全需求審查辦法來幫助開發人員更好探測軟件安全需求缺陷。上述工作在安全需求問題領域做出了不可否認的貢獻,但是在需求發現方面仍然無法避免因系統復雜性和各類環境因素帶來的需求頻繁變更等問題。Mavin等[3]針對安全問題提出了一種框架用于處理安全需求工程問題,通過從安全需求的問題本體領域角度出發,提出了一種3層的認知方法,從而細化安全需求。Singh等[4]則是針對安全性需求,將其從根本類別上劃分出來,認為其既不屬于功能性需求,也不屬于非功能性需求,為了將其更好地界定出來,利用公開的SecReq數據集,對22種監督機器學習分類算法和兩種深度學習方法在分類安全需求方面的性能進行了實證,結果表明,在無監督算法中,長短期記憶(LSTM)網絡的準確率最高(84%),在有監督算法中,增強集成(boost Ensemble)的準確率最高(80%)。Villamizar等[5]將網絡應用程序作為研究目標,提出一種在敏捷開發環境下的安全需求審查辦法,該方法將用戶故事和安全規范相結合,對安全性需求進行審查,結果表明針對新手開發人員具有較好的效果。
1.3 軟件需求挖掘與抽取
從海量的網絡數據中挖掘出有價值的知識和信息是進行用戶需求抽取的有效途徑,目前已經有很多研究人員針對社交數據進行了需求挖掘,比如Martns等利用Twitter上的官方賬號(如Netflix、Spotify)去收集用戶反饋[6];Hassan等[7]通過對谷歌用戶商店中開發者和用戶的對話追蹤產品信息,查找產品缺陷從而對用戶提供支持;在需求抽取方面,Raharjana等[8]針對網絡新聞提出了一種概念模型提取用戶故事,但是該方法機制不靈活,存在一定的局限性,作者也提到對于未來可能會借助機器學習的方法對其進行完善,提高抽取效果;胡田媛等[9]針對應用商店中的APP評論進行挖掘與抽取,采用基于人工標注的少量初始評論種子持續構建候選評論模式庫,通過使用循環挖掘的方式進行匹配,動態擴大挖掘體現不同使用反饋類型的 APP 軟件用戶評論的范圍;Cui等[10]提出基于評論的需求挖掘方法RERM,通過使用本體和條件隨機場模型對相關特征進行提取,對軟件存在的相關問題進行分類,如改進意見和產品缺陷等;Panichella等[11]對用戶評論使用一種自然語言解析器進行特征抽取,通過對句子的相關語法進行分析確定用戶反饋或者產品問題。
通過以上的分析研究,我們發現還很少有人將用戶故事作為需求的表達載體,同時大多數學者的研究思路都是針對句子的語法結構對內容進行抽取,在此基礎上,我們針對句子中的連接詞對用戶需求進行抽取,并以用戶故事模板作為需求表達形式。
2 整體框架
規范的用戶需求不僅便于項目的迭代演進,還能在一定程度上便于領域內不同項目間的需求重用。本文主要工作包括以下內容:
(1)篩選安全性需求相關數據;所獲取到的Issues原數據并不是所有的都可以進行需求提取,因此需要從中篩選出符合需要的數據;
(2)提出一種通過對句子中的連接實體進行實體識別進而對Issues語句中的需求進行抽取的方法,主要針對3類句內連接實體來完成安全需求的抽取;
(3)基于需求抽取給出一種用戶故事生成方法——CreUS。該方法根據語句中的連接實體和連接實體的位置制定生成用戶故事的策略和規則,進而生成用戶故事;
(4)基于針對特定實際項目的案例分析,對所生成的用戶故事實用價值進行評價。
系統整體研究框架如圖1所示。

圖1 CreUS系統整體框架
3 數據篩選
3.1 數據來源
從廣義角度來看,需求工程是一個逐步明確目的的過程,通過確定利益相關者(stakeholders)的需求并將這些需求以一種便于分析、溝通和后續實現的形式記錄下來。其中利益相關者包括很多角色并且范圍較為廣泛,主要包括付費客戶、用戶和開發人員[12]。GitHub作為一個面向開發者的技術社區,迄今為止已經為超過5000萬的用戶提供了一個可供分享,可以共同協作完成軟件開發的平臺。開發者在上面不僅可以托管開發項目,提交代碼,進行代碼評審,同時還可以交流相關開發經驗,以便開發者們之間互相之間進行學習。在GitHub的開發項目的功能板塊中有一個Issues版塊,該板塊的主要目的是為平臺上的開發者提供一個交流平臺,開發者們在這上面可以對相關代碼功能提出改進建議或者對項目運行之后的結果給予相關反饋。Issues是GitHub為各類平臺使用者提供的一種交流工具,通常被用來追蹤各種用戶想法、任務、bug、完善用戶功能等。
另外,當用戶發布Issues對軟件功能進行反饋的時候,對于某些評論可能會帶有身份標簽;標簽主要包含兩種,分別是Author標簽和Member標簽,其中Author標簽代表發布這條Issues的作者;Member標簽代表參與構造這個軟件項目的成員;此外,還有其它參與到此條Issues中的評論者,此時,他們的反饋沒有身份標簽顯示;3種情況分別如圖2~圖4所示。

圖2 Issues的提出者-Author標簽

圖3 項目中的程序開發成員-Member標簽

圖4 其余參與到Issues中的評論人員-無標簽
明確此類標簽之后,在數據爬取階段可以根據身份標簽篩選相關數據。
3.2 數據獲取及篩選
利用GitHub 官方API工具,從217個項目中一共爬取了25 490條Issues。考慮到主要目的在于挖掘用戶的潛在需求,因此根據上面提到的GitHub Issues概念中的身份標簽,本次數據爬取過程中過濾掉了帶有
將獲取到的Issues數據進行分類從而得到符合研究要求的數據。本次實驗數據需要滿足“需求”和“安全”兩個方面,基于這兩點考慮,決定將這里的工作內容分成兩部分:①找出Issues語句中和需求相關的語句;②建立安全性需求初始特征詞表,從①得到的數據結果中按照安全性特征詞表進行篩選,可以大概率認為該條語句描述和安全性需求有關;通過以上兩個步驟最后得到的數據可以認為基本滿足所期望的數據要求,數據分類具體工作內容如下:
(1)篩選出Issues中的需求描述語句
參考文獻[13]中作者提出的一種界定需求(dema-rcating requirements)問題的新方法,基于該方法,本文對對篩選出的Issues語句中包含的需求描述加以識別。數據特征化完成后,本文分別選用邏輯回歸(logistic regression,LR)方法、支持向量機方法(support vector machine,SVM)、和決策樹(decision tree,DT)方法進行訓練分類模型并進行效果比較。3種方法的評估采用準確率A(Accuracy)、精確率P(Precision)和召回率R(Recall)。選用五折交叉驗證的方式對實驗結果取平均值,得到的結果見表1,SVM的方法要優于其余兩種方法,因為在本問題上傳統機器學習方法均表現較好,所以未對深度學習等新興方法進行比較。

表1 3種模型分類結果比較
(2)進行安全性需求篩選
在步驟(1)篩選出需求相關數據見表2,然后通過建立安全性關鍵詞屬性篩選出安全相關需求,經過這兩個步驟之后,可以認為最后得到的數據為基本滿足需要的目標數據,即與安全需求相關的Issues語句,其結果見表3。

表2 需求數據分類結果

表3 安全需求數據分類結果
所建立的關鍵詞表用來表示安全性需求分類的初始特征詞,表中描述詞匯主要整理、提取來自相關文獻[1],其結果見表4。

表4 安全性需求相關詞匯描述
3.3 數據預處理
對于上述步驟操作得到的數據需要對數據內容進行預處理操作,使用正則表達式去除句子中無用的鏈接和代碼。考慮到Issues的語言表達形式為英文形式,其中可能包含一些詞形變換,因此需要對一些詞語進行詞形還原,這樣才能保證不會影響后續操作。例如,短語詞組“would like to”在有些句子中用戶可能會將其口語化表達為“I’d like to”,這種情況不利于研究后續對數據進行標注,因此需要將其還原為“I would like to”。
4 句內連接實體識別
在敏捷環境下,用戶故事作為表達用戶需求的重要方法,對于軟件項目的開發有著巨大的影響。用戶故事作為敏捷開發中一種有效的需求表示形式在實際開發中廣泛應用。生成的用戶故事集,不僅可用于支持Issues所在項目的開發迭代,還可以作為領域知識,在同領域類似項目的需求發現中起到重要的參考和輔助作用。Issues數據往往較為雜亂,如果能夠將其規范化,將會大大提高它的可用性。因此,需要按照用戶故事模板對用戶故事進行提取。提取格式按照用戶故事英文模板格式: As a
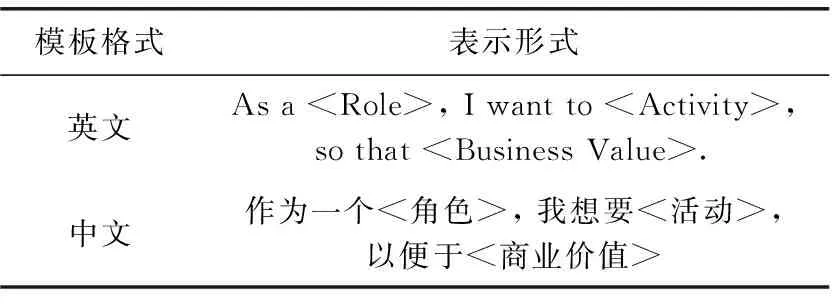
表5 用戶故事模板
用戶發表的Issues通常具有不同的表達形式,為了保證抽取工作的準確性,需要根據不用的句子特征對用戶故事進行提取。提取用戶故事只需要關注3個方面,分別是角色、行為和收益(原因),鑒于在爬取過程中已經對角色標簽進行了篩選,所以用戶故事角色可全部統一為“User”,接下來的任務就是如何對用戶行為和行為原因進行抽取。
想要準確的分離一句話中的用戶行為和行為原因,必須抓住其中起關鍵作用的句內連接實體然后對其進行分割。考慮到之前已經在此方向上對軟件需求實體方面進行研究,并且取得了較好的效果,為了提高對于句內連接實體的識別效率,考慮使用了自然語言處理領域中對于實體識別的研究方法,在之前的基礎上將其遷移到本次句內連接實體識別。
在本課題組前期相關工作中,使用Bi-LSTM+CRF實體識別方法對面向軟件開發社交網絡的軟件功能需求實體進行識別。本文實驗中直接采用上述方法對句內連接實體進行識別,該方法的性能比較以及實驗數據分析參見文獻[14]。
為了方便,在這里定義了一個新的概念——句內連接實體。句內連接實體是指通常句子內部會存在一些典型的連接詞或短語。該類詞語或者短語的上下文前后會對用戶行為和行為原因進行描述,并將這些連接詞或短語稱作句內連接實體。值得注意的是,本文提到的句內連接實體的概念不同于英語語法中的連詞的概念,連接實體還會包括一些連接短語表達。例如在下面的Issues語句中:
Itwould be nice tohave a short security summary in each crate documentation which would include known insecurities,applicability,etc.
其中,“would be nice to”不屬于英語語法中的連詞范疇,但是通過對“would be nice to”這類短語的識別可以切分該短語后面的句子作為用戶行為,完成用戶故事提取。因此該短語是句內連接實體;
句內連接實體包含的短語或者連接詞的種類眾多,在此,針對軟件需求領域,定義句內連接實體的范圍主要包括以下3種:表因果關系的連接實體;表意愿關系的連接實體;表建議關系的連接實體。主要集中在這3類連接實體的原因在于,根據用戶故事模板,可以推測出這3類連接實體的句子中包含其三要素中的一個或幾個,因此可以作為出發點來進行用戶故事生成。
5 CreUS用戶故事生成方法
用戶故事是在軟件開發過程中的一種需求描述形式,多用于在敏捷開發環境下。用戶故事的詳細定義請參見文獻[15]。
用戶故事通常按表5所示模板描述。例如:“作為一名[學生],我想要[輕松地完成密碼修改任務],以便于[我可以及時保證我的個人隱私]。”
本文針對不同Issues安全性需求語句特點制定相應的用戶故事元素提取規則;同時在用戶故事表示中使用“下劃線”來表示用戶行為,例如用戶行為;使用雙下劃線來表示行為收益,例如行為收益。
針對用戶故事的抽取本文提出了CreUS算法,該算法主要是面向蘊含潛在的用戶需求的Issues語句,通過上一小節的步驟對語句中的連接實體進行識別之后,還要根據不同語句類別和實體類型制定相應的規則進行抽取。該算法主要是從兩個方面進行考慮,分別是句子類型和連接實體兩個層面,基于這兩個角度,制定了如下規則:
(1)如果句子中含有句內連接實體,則:
規則1:對表因果關系的句內連接實體,將連接實體的前綴作為用戶行為,后綴作為行為原因,例如so that,because,in order that等;
規則2:對表意愿關系的句內連接實體,將句內連接實體的前綴作為行為原因,后綴作為用戶行為,例如would like to,want to,hope to等。
規則3:對表建議關系的句內連接實體,將句內連接實體前綴作為行為原因,后綴作為用戶行為,例如would be great to,be nice to,suggest that等。
(2)經過了上一步對于句內連接實體的判斷,還要針對Issues需求語句不同的表達形式,將二者結合起來并給出如下規則:
規則1:句中無標點符號,單獨短語成句,帶有祈使的語氣,在這種情況下,可將全部文本內容作為用戶行為原因,并且在用戶行為上使用“Action”進行補全,舉例如下:
原Issues語句:

insecure firebase architecture.
提取用戶故事:

As a user,I want Action, so that insecure firebase architecture.
規則2:對于含有句內連接實體的簡單句,首先識別句子中的連接實體并確定其所屬種類,然后按照(1)中對應的規則進行抽取,舉例如下:
原Issues語句:

finish session and login work so that the session is in the db and that the login is secure.
提取用戶故事:

As a user,I want to finish session and login work, so that the session is in the db and that the login is secure.
規則3:往往用戶的反饋不僅僅是一句,而是由多個語句構成的集合。對于含有多個語句的段落,如果其中只有一個句內連接實體的話根據該句內連接實體所處的位置和所在的句子進行分割,同樣在對句子進行分割的時候遵循(1)中的規則。例如:
原Issues語句:

the current 20 character limit on passwords is too short for secure passphrases. would be great to support lon-ger passwords eg: 128+ characters especially considering unicode chars take up more than one character in the pass-word manager.
對于該句,其中只包含一個句內連接實體。找到句內連接實體would be great to所在的位置,對前后文進行劃分;按照句內連接實體屬性規則,生成的用戶故事如下:
提取用戶故事:

As a user, I want to support longer passwords eg: 128+ characters especially considering unicode chars take up more than one character in the password manager so that the current 20 character limit on passwords is too short for se-cure passphrases.
規則4:在同一段落文本中,句內連接實體可能不止出現了一次,一段文本中可能含有兩個或者兩個以上句內連接實體,對于這種情況,按照句內連接實體的位置將句子分割,之后重復規則3。對于一段文本中含有多個句內連接實體的句子就表明用戶可能有多個需求,因此這樣的話就需要找出句中所有句內連接實體并對潛在的用戶需求進行拆解,從而保證需求提取的完整性,示例如下:
原Issues語句:

句子1:hashed key is the password hash from user specified plaintext password using crypto_pwhash. it is a hash value but used as a key, so it must be protected by safebox as same as other keys.(第一個連詞結尾處對段落進行分割)句子2:although the current password hash has drop to clear it, but it is allocated on stack which is weaker than the secured heap and potential to be persistent. so it should be u-sing same safebox as a normal key to enhance security.
重復步驟規則3,對已獲得到的句子進行用戶故事提取,如下:
提取用戶故事:

As a user, I want protected by safebox as same as other keys, so that hashed key is the password hash from us-er specified plaintext password using crypto_pwhash. it is a hash value but used as a key.

As a user,I want to use same safebox as a normal key to enhance security, so that although the current pass-word hash has drop to clear it, but it is allocated on stack which is weaker than the secured heap and potential to be persistent.
基于Issues安全性需求描述文本的用戶故事生成算法如下:
算法1:CreUS用戶故事生成算法
Input: 處理后的Issues語句
Output: Issues語句對應的用戶故事
Variable: SenEntityNum /*Issues語句中所含連接實體的數目*/
JustSinglePhrase /*句中無標點符號,單獨短語成句*/
SenNum /*輸入Issues語句中完整句子數目*/
SenIsSimple /*輸入Issues語句為簡單句*/
BeforeJoinEntity /*連接實體前文內容*/
AfterJoinEntity /*連接實體后文內容*/
RolePart /*用戶故事模板中用戶角色,統一為:User*/
ActionPart /*用戶故事模板中用戶行為部分*/
ReasonPart /*用戶故事模板中行為原因部分*/
Function:/*所用到的函數*/
Check() /*如果連接實體前后文為空則進行關鍵詞補全處理*/
(1) If(BeforeJoinEntity.content == null)
(2) Then “Action”→UserStory.ActionPart
(3) Return
(4) If(AfterJoinEntity.content == null)
(5) Then “Reason”→UserStory.reasonPart
(6) Return
MakeUserStory()/*創建用戶故事函數*/
JudgeEntityType(): /*判斷連接實體類型*/
(1)If(JudgeEntityType==1)/*如果是表示因果關系的實體*/
(2)ThenIssues. BeforeJoinEntity → UserStory.Action-Part;
(3) Issues. AfterJoinEntity →UserStory.Reason-Part
(4)MakeUserStory(RolePart+ActionPart+ReasonPart)
(5)ElseIf(JudgeEntityType==2‖JudgeEntityType==3)
/*如果實體是表示意愿關系或者表示建議關系的連接實體*/
(6)ThenIssues. AfterJoinEntity → UserStory.Action-Part;
(7) Issues. BeforeJoinEntity →UserStory.Reason-Part
(8)MakeUserStory(RolePart+ActionPart+ReasonPart)
CutSenByEntity() /*根據連接實體位置分割句子*/
Main()/*主函數*/
Begin:
(1)If(Issues.JustSinglePhrase == True)
(2)ThenIssues.WholeContent →UserStory.Reason-Part
(3) “Action”→UserStory.ActionPart
(4)MakeUserStory(RolePart+ActionPart+ReasonPart)
(5)ElseIf(Issues.SenEntityNum == 1 && SenNum ==1)
(6)Check();
(7)JudgeEntityType(Issues.entity)
(8)ElseIf(Issues.SenEntityNum == 1 && SenNum >1)
(9)Check()
(10)JudgeEntityType(Issues.entity)
(11)ElseIf(Issues.SenEntityNum >1 && SenNum >1)
(12)CutSenByEntity()/*通過實體對段落句子進行分割*/
(13)Repeat(Step(5)~Step(10))
(14)ElseCatchException()
(15)Return
End
本算法時間復雜度為O(n)。復雜度較低的原因主要是前期數據篩選和實體識別承擔了較大工作量。
6 案例分析
本文從GitHub抓取的Issues數據中篩選出425條安全相關Issues,通過上文提供的算法,從這些Issues語句中抽取到157條用戶故事。其中,不含語義錯誤的用戶故事共有52條。在GitHub中選取若干真實項目案例,通過計算用戶故事覆蓋率分析抽取到的用戶故事在實際項目中的實用性。
為了進行用戶故事實用價值判定,使用人工的方式對52條用戶故事進行分類,所采用的分類標準是文獻[16]里面Donald Firesmith所提出的12種安全性需求,即:①鑒別需求;②驗證需求;③授權需求;④免疫性需求;⑤完整性需求;⑥入侵檢測需求;⑦不可否認需求;⑧秘密需求;⑨安全審計需求;⑩可存活性需求;物理保護需求;系統維修安全性需求。按照這12類標簽對用戶故事進行分類,分類情況見表6。

表6 用戶故事按照安全需求標準進行分類
在GitHub上選取15個實際開發項目,其項目列表見表7;所選取的項目均為比較完整且權威的項目,每個項目都有比較完善的功能說明,根據這些功能說明可以列出原項目安全需求列表,形成具體功能點;依據功能點在所生成的用戶故事集中篩選出可能相關的用戶故事。進一步與原項目的安全需求進行比對,如果某個用戶故事覆蓋了項目中的有效功能點,則說明該用戶故事有效。通過人工統計的方法,計算用戶故事覆蓋率p,如式(1)所示;其中n(s)表示覆蓋實際項目用戶故事的條數,n(c)表示原項目中實際的安全需求用戶故事條數,在這里選用實際項目的目的是希望通過實際項目的角度出發來測試用戶故事的價值,這樣也會更加有說服力

(1)
生成用戶故事的主要目的主要有兩個,一個是以規范的形式幫助利益相關者完善某些需求,即覆蓋已有功能;另一個是幫助利益相關者發現新的需求并對其形成輔助作用,即增加新的功能。
上述步驟以表8中的項目paascloud-master為例簡要說明如下:
(1)根據項目介紹預測用戶故事
根據主頁信息中的簡短介紹從用戶故事列表中推薦相關的用戶故事,最終人工推薦用戶故事32條,并且按照Donald Firesmith在文獻[16]中所提到的分類辦法進行分類,具體序號見表8;考慮到抽取到的安全需求用戶故事條數較多,因此在本文里不詳細列出,作者已將用戶故事進行整理并且上傳到GitHub[17]。
(2)收集實際項目安全需求用戶故事并分類
人工方法進行安全需求用戶故事收集,具體需求見表8,在實際項目中,一共生成13條用戶故事,并對其進行分類,這樣便于更好推薦用戶故事。

表8 項目列表
(3)進行用戶故事價值比對并計算覆蓋率
最后得到實際用戶故事覆蓋條數為11條,用戶故事覆蓋率84.6%。
類似的對15個項目的用戶故事實用價值進行分析,結果詳見表8;可以看出,采用該方法所得到的平均用戶故事覆蓋率為85.71%,說明本次生成的用戶故事具有一定的實用價值,對實際項目開發能夠起到一定的輔助作用。
7 結束語
在敏捷開發環境下,相對于被集中撰寫的功能性需求,軟件的非功能需求描述通常較為分散和隱含。我們認為開發類社交媒體上針對特定軟件項目的討論中往往蘊含著許多潛在的系統功能需求和非功能需求。因此本文針對GitHub中的Issues模塊數據嘗試進行安全性需求挖掘,從而獲得有價值的信息為開發人員提供輔助工作。本文主要貢獻包括:①給出一種以3類連接實體識別為基礎從句子中抽取出用戶行為和行為原因的方法;②給出一種CreUS用戶故事生成算法,針對不同類型的Issues語句和句內連接實體類型設計規則進行用戶故事生成。生成的用戶故事集不僅可用于輔助Issues所在項目的開發迭代,還可以作為領域知識,在同領域類似項目的需求發現中起到重要的參考和輔助作用。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
