基于動態多最小支持度的用戶頻繁軌跡挖掘
2022-06-23 11:12:24嚴愛俐劉漫丹
計算機工程與設計 2022年6期
嚴愛俐,劉漫丹
(華東理工大學 信息科學與工程學院,上海 200237)
0 引 言
融合移動互聯網、大數據、云計算、物聯網等現代化信息技術,推動校園教學管理、教師教學模式、學生學習模式等方面的改革,為廣大師生提供了全面智能感知、個性化的服務[1,2]。隨著高校的信息化建設,會產生一些校園數據,例如一卡通消費數據、圖書館借閱數據等,通過對這些數據進行頻繁序列模式挖掘能夠發現很多隱藏的信息。
常用的序列模式挖掘算法有Apriori算法[3]、FP-Growth(frequent pattern growth)算法[4]、FreeSpan算法[5]及PrefixSpan算法[6]等。針對數據量大、分布范圍廣的數據集,本文選擇用PrefixSpan算法進行序列挖掘。但該算法在執行過程中,需要遞歸構造投影數據集,從而影響了算法的運行時間。目前,已有不少學者針對上述問題提出了改進。文獻[7]中通過支持度末尾判斷和后綴指針偽投影的方法進行改進,文獻[8]中提出基于后綴索引的PrefixSpan算法和基于投影數據庫的PrefixSpan改進算法,文獻[9]中借助已生成的序列模式投影提出AprioriAll-PrefixSpan改進算法,等等。針對PrefixSpan算法存在的缺陷,本文從閾值、運行效率和運行內存角度出發,分別提出相應的改進舉措。
1 相關定義及工作
本文采用PrefixSpan算法從獲取的校園數據中挖掘出用戶的頻繁軌跡模式,PrefixSpan算法是由JW Han等[6]提出的,算法的思想與Apriori算法類似。從長度為1的前綴開始挖掘序列模式,搜索對應的投影數據庫得到長度為1的前綴對應的頻繁序列,然后遞歸挖掘長度為2的前綴所對應的頻繁序列。以此類推,一直遞歸到不能挖掘到更長的前綴挖掘為止。
下面對PrefixSpan算法中涉及的相關概念抽象成具體的數學表達式,具體定義如下:
定義1 序列:假設存在序列數據集D={S1,S2,…,Sj,…,SN}, 其中序列Sj(1≤j≤N) 由m項構成,即Sj={ij,1,ij,2,…ij,k,…,ij,m}, (1≤k≤m),ij,k表示Sj中的第k項;令序列s={ij,k}, 則稱序列s是序列Sj的子序列,序列Sj為序列s的超序列;
定義2 支持度(Support):一個序列的支持度被定義為數據集中包含該序列的記錄數占數據集總序列數的比值。假設序列數據集D={S1,S2,…,SN}, 序列Sj={ij,1,ij,2,…ij,k,…,ij,m}, 則子序列s={ij,k} 的支持度即
(1)
定義3 最小支持度(Minimum Support):用戶定義衡量支持度的一個閾值,表示項在統計意義上的最低重要性,記作min_sup;
定義4 頻繁序列:假設數據集D中存在子序列s,滿足其支持度≥最小支持度,即sup(s)≥min_sup, 則子序列s稱為頻繁序列,若子序列s由n項組成,則子序列s又可稱為頻繁n-序列;
定義5 投影數據庫:假設有序列Sj={ij,1,ij,2,…ij,k,…,ij,m}, 其中子序列sj={ij,1,ij,2,…,ij,k}, (1≤k≤m), 則稱序列sj是序列Sj的序列前綴,序列Sj為序列sj的序列投影;子序列s′j={ij,k+1,ij,k+2,…,ij,m}, 稱其為序列Sj的序列后綴;由s′j(1≤j≤N) 組成的數據庫稱為投影數據庫。
本文是基于PrefixSpan算法的改進,下面將通過表1中的具體實例解釋PrefixSpan算法的整個運行過程,設定min_sup=0.5, 對應的最小支持度閾值次數為:min_sup*序列總數N=0.5*4=2次。

表1 序列數據集實例
首先對序列數據集第一次掃描,統計所有項出現的次數:{a}:4、{b}:4、{c}:4、g0gggggg:3、{e}:2、{f}:2、{g}:1。其中{g}出現次數不滿足最小支持度閾值次數,則頻繁1-序列集如下:{a}、{b}、{c}、g0gggggg、{e}、{f}。將這些頻繁1-序列作為前綴并找出對應的投影數據庫,見表2。

表2 頻繁1-序列前綴及對應投影數據庫
接著以前綴g0gggggg為例介紹整個挖掘過程,其它序列前綴挖掘方法類似。對序列{a}對應的投影數據庫進行統計:{a}:1、{b}:2、{c}:3、{e}:1、{f}:1、{_f}:1,其中滿足min_sup閾值次數的是{b}、{c},則頻繁2-序列為{db}、{dc}。以頻繁2-序列為前綴找出對應的投影數據庫,見表3。

表3 頻繁2-序列前綴及對應投影數據庫
同理對2-序列前綴的投影數據庫中各項進行統計,前綴{dc}中項{b}出現2次得到頻繁3-序列{dcb}對應的投影數據庫見表4。根據投影數據庫發現沒有滿足條件的項,因此無法產生頻繁4-序列,以g0gggggg為序列前綴挖掘的所有頻繁序列如下:g0gggggg、{db}、{dc}、{dcb}。

表4 頻繁3-序列前綴及對應投影數據庫
2 動態多最小支持度前綴投影挖掘算法(DMS-PrefixSpan)
由于PrefixSpan算法的基本思想是,根據確定的最小支持度min_sup從序列集合中挖掘出滿足條件的頻繁序列。因此min_sup的選擇就顯得極為重要,如果min_sup設置過高會導致一些重要的隱藏信息被丟失,反之設置過低則挖掘的結果中混入大量干擾信息。針對用戶的頻繁軌跡挖掘,其移動軌跡中通常會包含一些熱點地區,但這些地區在軌跡中的重要程度相對較低。例如在校園中大部分用戶會在特定時間出現在食堂、教室等地點,如果僅根據這些數據希望挖掘出各個用戶之間的社會關系,很大程度上會得到所有人的行為軌跡都是相似的。另外,同一個地點對不同用戶的重要性是不同的。例如在博物館工作的工作人員和去博物館游覽的游客,明顯能夠看出博物館在后者軌跡模式中重要性明顯超過前者,在這種情況下確定的工作人員和游客去博物館的最小支持度應該有所區別。
其次,用戶不同的需求促使用戶有不同的行為,隨著年齡、角色、生活環境的變化需求也在不斷發生變化。例如,校園網絡中的用戶在大二、大三選修的課程不同,因此其上課的教室、時間、同學也是不同的;選修的課程安排在上學期或者下學期,會對其某段時間的生活作息產生影響。因此通過分析用戶行為的轉變,試著分析其背后行為轉變的原因對學生管理和資源分配具有指導意義。
針對上文提到的單一最小支持度和行為模式變化問題,本文將從以下兩個方面:多最小支持度和動態頻繁序列挖掘進行討論。此外,由于使用數據集時間跨度很長且用戶數據量很多,因此算法改進還需要考慮到內存消耗問題。本文將引入動態多最小支持度的PrefixSpan改進算法稱為動態多最小支持度前綴投影挖掘算法,簡稱DMS-Prefix-Span算法。
2.1 序列壓縮和序列匹配
由于PrefixSpan算法挖掘的結果存在大量的冗余,為了減少挖掘結果的內存占用,提出序列壓縮和序列匹配兩個概念,將引入序列壓縮和序列匹配的PrefixSpan算法稱為最長頻繁項集挖掘算法,簡稱L-PrefixSpan算法。其中序列壓縮和序列匹配的概念如下:
假設從數據集D中存在頻繁n-序列,頻繁n-序列是從頻繁1-序列中衍生增長而來的,可以發現頻繁1~(n-1) 序列為頻繁n-序列的子序列,則只保留頻繁n-序列即可,這種操作稱為序列壓縮。
遍歷整個挖掘結果序列集合,若其中某序列為其它序列的子序列,則去除這條冗余的子序列,以保證結果中所有序列互相不為子序列或超序列的關系,這種操作稱為序列匹配。
根據圖1可以發現,挖掘的頻繁項如下: {a},{ab},{ac},{af},{abc},{abb},{acb},{abcf},{abbf}, 經過序列壓縮可得到如下的結果: {abcf},{abbf},{acb},{af}; 根據序列壓縮結果可以進一步發現:序列 {af} 為序列 {abcf} 和 {abbf} 的子序列,則經過序列匹配可得到最終的結果: {abcf},{abbf},{acb}。 以此類推,可以發現經過序列壓縮和序列匹配,挖掘的頻繁序列會大大減少,因此占用內存空間也會減少。

圖1 PrefixSpan算法挖掘結果示例
2.2 多最小支持度的計算
某無線網絡中所有用戶的軌跡序列集合為UR={R1,R2,…,Ru,…,RN}, 該無線網絡中采集的所有地點區域項集為L={l1,l2,…,li,…,lM}, 其中M為該無線網絡中地點區域總數。則地點區域li的地點熱度用群體地點分布頻率(frequency of locations in the group,FLG)表示,如式(2)所示
(2)
式中:N(li) 為統計的軌跡序列中含有地點區域li的序列出現次數,N為軌跡序列中所有軌跡序列總數。
假設無線網絡中的某用戶u其軌跡序列集合為Ru={ru,1,ru,2,…,ru,x,…,ru,Ku}, 其中Ku為該用戶軌跡序列總長度,元素ru,x為軌跡點記錄,ru,x=(tu,x,lu,x) 表示用戶u的第x個軌跡記錄的出現時間tu,x和出現地點lu,x。 用戶個人的地點偏好用個人地點分布頻率(frequency of locations in the personal tracks,FLP)表示,如式(3)所示
(3)
式中:K(lu,i) 為用戶u軌跡序列中含有地點區域li的序列出現次數。
綜合考慮地點熱度和個人地點概率分布,需要將FLG(li) 和FLP(lu,i) 分別根據其與最小支持度的變化規律進行非線性映射轉換。由于FLP(lu,i) 表示用戶u的地點偏好程度,計算得到的數值越大表明地點li對用戶越重要。選擇映射函數的時候要考慮到min_sup與用戶在地點出現的頻率成正比,所以選用的映射函數在 [0,1] 范圍內單調遞增的自然對數函數進行變換,具體函數如式(4)所示
f(x)=ln(x+1)
(4)
FLG(li) 表示地點熱度,數值越大則表明地點li的熱度越高。而min_sup與該地點在整個軌跡序列中出現的次數成反比,因此選擇映射函數在 [0,1] 范圍內為單調遞減的函數。由于指數函數和對數函數互為反函數,所以FLG(li) 的映射函數選用標準對數函數,具體如式(5)所示
(5)

SuperMap建庫的核心工作是對數據進行轉換處理,轉換處理的標準數據能直接應用于后續數據的處理,采用的建庫模式是從臨時庫到標準庫再到調查庫。
f(x)=exp(-πx2)
(6)
根據式(2)至式(6),可得用戶u在地點li的最小支持度,記為MIS(lu,i), 具體表達式如式(7)所示
MIS(lu,i)=ln(FLP(lu,i)+1)*exp(-π(FLG(li))2)
(7)
根據式(7),求得用戶u在該無線網絡中所有地點的多最小支持度閾值,記為MMS(L), 具體表達式如式(8)所示
MMS(L)={MIS(lu,1),MIS(lu,2),…,MIS(lu,i),…,MIS(lu,M)}
(8)
2.3 動態頻繁序列挖掘
一般情況下,對數據流頻繁項的挖掘都是基于某個時間段對數據的分析和研究[10]。主要有兩個原因:一是數據量過于龐大挖掘過程會消耗很多時間,二是不同時間段的數據重要程度不同。根據數據流中的不同時序范圍,可以把數據流模型劃分為如下3類:快照模型、界標模型和滑動窗口模型[11]。參考文獻[12]中提到,根據挖掘模式結果集合的精簡程度,可以分為全集模式挖掘方法和壓縮模式挖掘方法等;壓縮模式主要包括閉合模式、最大模式、top-k模式以及三者之間的組合模式。根據2.1節中提到的序列壓縮和序列匹配,本文中的挖掘模式為壓縮模式中的最大模式挖掘。
挖掘用戶頻繁軌跡的過程中,綜合考慮到數據量和時效性兩方面,選擇用滑動窗口模型,即窗口的起始時間和結束時間都是變化的。在整個過程中,存在用戶本身在不同時段對不同地點偏好程度不同的問題,因此用戶在不同時間段內不同地點的min_sup是不同的。文獻[13-15]中涉及上述問題,無論是采用滑動窗口模型還是衰減窗口模型,無論數據集是密集數據集或者稀疏數據集,均根據所有之前時間窗口的事務占比確定項的權重,但本文的權值是基于前一個時間窗口的事務占比,通過不斷循環該操作既沒有忽視之前的數據,同時也大大縮短了計算消耗的時間,其對于內存消耗、運行時間及實驗結果均有所改善。
用戶u的軌跡序列集合為Ru={ru,1,ru,2,…,ru,x,…,ru,Ku} 且ru,x=(tu,x,lu,x), 以周期T為窗口大小劃分用戶軌跡,假設用戶數據的起始時間為start、 結束時間為end, 則用戶的軌跡序列的滑動窗口劃分方式如下: 〈start,start+T,…,start+kT,…,end〉, 且有n個周期。
當Tk=[start+(k-1)T,start+kT], 1≤k≤n時,由式(7)可得用戶u在地點li的最小支持度,記為MIS(luTk,i), 則用戶u在n個周期內地點li的最小支持度MMS(lu,i) 如式(9)所示
MMS(lu,i)={MIS(luT1,i),MIS(luT2,i),…,MIS(luTn,i)}
(9)

(10)
(11)
根據Tk周期內用戶u的在地點li出現的概率為Pu,li, 在計算T(k+1)周期地點li的最小支持度時需要迭加權值計算,具體計算如式(12)所示
MIS(luT(k+1),i)=MIS(luT(k+1),i)×e-PuTk,li,k=2,3,…,n
(12)
根據式(12)可以計算出用戶u在T1~Tn周期地點li所有的最小支持度。
對M個地點重復上述步驟,得到用戶u在該無線網絡中所有地點的動態多最小支持度閾值,記為DMS(L), 具體表達式如式(13)所示
DMS(L)={MMS(lu,1),MMS(lu,2),…,MMS(lu,i),…,MMS(lu,M)}
(13)
2.4 DMS-PrefixSpan算法的實現步驟
具體挖掘步驟如下:
步驟1 首先對移動軌跡的序列數據集預處理,然后將數據集以T為周期劃分為n個區域稱為Tk(k=1,2,…,n), 令k=1;
步驟2 從Tk開始根據式(7)計算所有地點的多最小支持度閾值MMS(LTk);
步驟3 結合MMS(LTk) 根據式(12)計算所有地點的動態多最小支持度閾值DMS(LTk)={MIS(luTk,1),MIS(luTk,2),…,MIS(luTk,i),…,MIS(luTk,M)};
步驟4 對Tk區域內所有出現的地點進行計數,找出所有滿足閾值DMS(LTk) 的地點保存作為頻繁i-項集,令i=1;
步驟5 對于每個長度為i且滿足閾值MIS(luTk,i) 要求的前綴進行遞歸挖掘:①找出前綴對應的投影數據庫,如果投影數據庫為空,則遞歸返回;②統計投影數據庫中各個地點出現的次數,將滿足閾值MIS(luTk,i) 要求的地點與當前的前綴合并,得到新的前綴;若不存在滿足要求的地點,則遞歸返回;③令i=i+1, 保存合并后的前綴作為頻繁i-項集,并遞歸返回步驟5;
步驟6 遍歷頻繁軌跡模式集合,進行序列匹配,剔除挖掘的冗余頻繁序列;
步驟7 根據式(10)計算不同地點在用戶的軌跡中出現的概率,令k=k+1, 遞歸返回步驟2;
經過n次周期的計算,獲得用戶在不同周期內所有的頻繁序列集。
3 某高校用戶頻繁項挖掘
3.1 數據預處理
本仿真實驗的硬件環境為Intel(R) Core(TM) i7-2600 CPU @ 3.40 GHz,4 GB內存,軟件環境為Windows 8 64位操作系統,Matlab R2019b軟件和Pycharm開發環境。本文采用2019年09月至2019年12月某高校學生移動軌跡數據共包含6991個用戶,獲取的真實數據包含“手機的MAC地址、AP的MAC地址、rssi、時間、地點類別、樓宇、房間”,具體信息見表5。

表5 某高校無線網絡獲取部分信息
首先根據獲取的記錄數量,保留記錄數大于等于1000的用戶共有4673名。然后對原始數據中的異常數據進行處理:根據獲取的數據發現有些用戶在同一時刻獲取無線網絡登錄點是兩個不同的MAC地址,所以將用戶在5分鐘以內的數據進行合并,使用接收無限信號最強的MAC地址作為其確切的登錄點。
由于原始的PrefixSpan算法挖掘的結果不強調項之間的先后順序,為解決這一問題,本文將原始的地點項做出一些改進。表6為用戶u的部分移動軌跡數據,第2列時間是將原來的年月日表示方法轉變為數值表示,第4列為改進地點項集表示,例如改進后的地點項(21,22)是由在當前時間點出現的地點和下一個出現的地點組成。
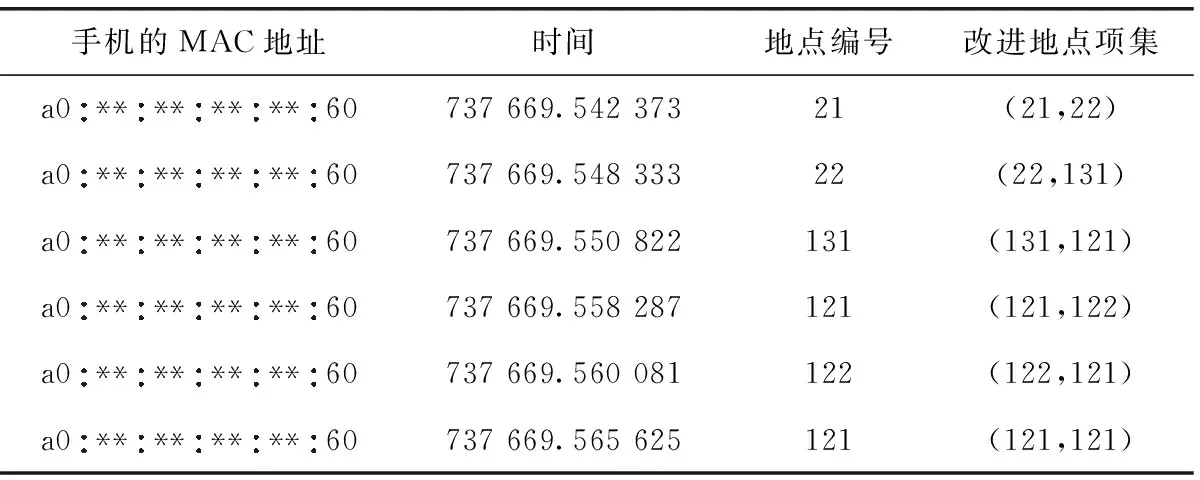
表6 用戶u部分移動軌跡數據
3.2 實驗結果及分析
本文從挖掘用戶的頻繁模式總數、平均頻繁軌跡模式個數和平均軌跡序列模式序列長度3個方面,對比分析基本算法和改進算法的運行時間、運行效率等。另外,還分析了序列壓縮和序列匹配對挖掘序列的個數影響,下面為具體實驗的比較分析結果。
(1)L-PrefixSpan算法序列壓縮與序列匹配效果對比
根據上文2.1節中提到的序列壓縮與序列匹配的概念,為驗證序列壓縮和序列匹配去除冗余軌跡的效果,將PrefixSpan算法和L-PrefixSpan算法挖掘頻繁序列的個數進行比較,具體的實驗結果見表7,圖2為不同最小支持度條件下PrefixSpan算法和L-PrefixSpan算法挖掘結果對比的柱形圖。

表7 PrefixSpan算法和L-PrefixSpan算法 挖掘頻繁軌跡數量對比
從圖2中可以觀察到,隨著最小支持度min_sup的增大,PrefixSpan算法和L-PrefixSpan算法挖掘結果數量也在隨之減小。以最小支持度min_sup=0.05為例,可以發現經過序列壓縮和序列匹配,L-PrefixSpan算法挖掘結果數量只占PrefixSpan算法的50%左右,換言之剔除的冗余率大概在50%左右,而其它的最小支持度結果比較的剔除冗余率也在50%左右。根據圖2和表7的結果驗證了序列壓縮和序列匹配的效果,表明序列壓縮和序列匹配對于剔除冗余率具有顯著的效果。

圖2 PrefixSpan算法和L-PrefixSpan算法挖掘結果對比
(2)多最小支持度結果分析
為驗證DMS-PrefixSpan算法的有效性,本文將L-PrefixSpan算法與DMS-PrefixSpan算法的挖掘結果進行比較。表8為DMS-PrefixSpan算法挖掘結果,表9為不同最小支持度下L-PrefixSpan算法挖掘結果。表中UserNum為存在頻繁軌跡挖掘結果的用戶數,PatternNum為挖掘的頻繁軌跡模式總數,AvgPatternNum為平均每個用戶頻繁軌跡模式數,AvgPatternNum/T為每個周期用戶的平均頻繁軌跡模式數,AvgPatternLen為平均每個頻繁軌跡模式的序列長度,AvgPatternLen/T為每個周期的平均序列長度。

表8 DMS-PrefixSpan算法挖掘結果

表9 L-PrefixSpan算法挖掘結果
根據表9可以發現:對于L-PrefixSpan算法,隨著最小支持度的增大,挖掘的UserNum值、PatternNum值、AvgPatternNum值、AvgPatternLen值都隨之減小;對比DMS-PrefixSpan算法的挖掘結果,所有的AvgPatternLen值均穩定在4左右,但DMS-PrefixSpan算法中的AvgPatternNum值大于L-PrefixSpan算法在不同最小支持度條件下的AvgPatternNum數值。表明改進后的DMS-PrefixSpan算法不僅能夠挖掘出用戶所有的頻繁項集,而且在保證挖掘結果的前提下也沒有影響算法的運行效率,算法的具體運行時間見表11。
(3)動態頻繁序列挖掘結果分析
根據表10的頻繁序列結果展示,可以發現:該用戶的行為軌跡在宿舍樓和教學樓之間徘徊(第一個數字“1”表示宿舍樓,“2”表示教學樓);最長的頻繁序列為 ((131,132), (132,131))和((132,131), (131,132)), 即用戶最長的頻繁序列為131→132→131或者132→131→132,符合數據集集中分布在宿舍樓的特點。用戶具體的頻繁序列移動軌跡如圖3所示,其中線段較粗的表示該用戶經常往返的路線,而線段較細的表示頻繁序列軌跡中相對頻率較低的。從圖3中能夠直觀看出,該用戶經常往返于宿舍與教學樓、教學樓之間和宿舍之間,表明該學生的行為模式較為單一。且該用戶經常往返于教學樓之間,表明該用戶的連續課程安排在不同的教學樓之間;學校可以根據用戶行為之間的時間差及行動速度,合理安排課間休息時間及課程時間、地點的安排等。

表10 DMS-PrefixSpan算法頻繁序列結果展示
(4)運行時間分析
表11為L-PrefixSpan算法和DMS-PrefixSpan算法運行時間對比,可以發現隨著支持度的增加,L-PrefixSpan算法的運行時間在隨之減少;而DMS-PrefixSpan算法的運行過程中,即使包含滑動窗口模型和多最小支持度模型,但是其運行時間介于min_sup=0.3和min_sup=0.4之間,表明改進后的DMS-PrefixSpan算法有較好的運行效率。

圖3 用戶的頻繁移動軌跡
根據實驗(1)~實驗(4)的實驗結果分析,實驗(1)中實驗結果驗證了序列壓縮和序列匹配的有效性,實驗(2)、實驗(4)分別從挖掘的用戶頻繁序列模式個數、平均序列長度及運行時間凸顯了改進算法的優勢。實驗(3)中涉及到用戶動態頻繁序列模式挖掘,可以將挖掘結果進一步用于研究用戶的異常行為及學校如何對課程進行合理安排。

表11 L-PrefixSpan和DMS-PrefixSpan算法運行時間比較
4 結束語
本文就傳統的頻繁項模式挖掘中的單一最小支持度存在的問題做出了改進,引入多最小支持度動態確定模型,在充分運用獲取數據的基礎上避免由于最小支持度的問題影響最終的挖掘結果。針對PrefixSpan算法中大量冗余的頻繁序列,利用序列壓縮和序列匹配極大減少了存儲空間。為查看用戶在一段時間的地點偏好,運用加權的方式使得挖掘結果綜合考慮過去和現在不同的行為習慣,并且也大大縮短了挖掘的運行時間。分析研究挖掘的一系列結果,可以了解用戶的行為習慣、地點偏好變化等情況。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
