基于DenseNet與注意力機制的遙感影像云檢測算法
2022-06-22 06:47:56劉廣進王光輝畢衛華劉慧杰楊化超
自然資源遙感 2022年2期
劉廣進, 王光輝, 畢衛華, 劉慧杰, 楊化超
(1.中國礦業大學環境與測繪學院,徐州 221116; 2.自然資源部國土衛星遙感應用中心,北京 100048; 3.皖北煤電集團有限責任公司,宿州 234002)
0 引言
遙感衛星的出現使得我們獲取地表影像數據的能力大大提高,憑借其全天時、大范圍、時效性,使得遙感技術廣泛應用于農業生產、地質防災、氣象預報、軍事預警、地理國情等領域。但是遙感影像的獲取過程中云的存在是常見現象,由于云的遮擋,使得地面信息無法被衛星獲取到,給后續的影像分析解譯帶來了困難[1-2]。所以,遙感影像云檢測是首要而且必要的一環,云檢測的精度與速度對分析解譯有直接影響。
云檢測的方法大致可以分為3種: 手工勾繪方法、基于波段閾值及紋理信息的檢測方法與基于深度學習的檢測方法[3]。其中第一種方法為最傳統的方法,效率較低,本文不再贅述。第二種方法中基于波段閾值的方法需要人為監督,調整參數才可以達到較優的檢測結果,基于紋理的檢測算法需要后續對錯誤分類進行剔除。基于深度學習的云檢測過程中不需要人工干預,實現了端到端的檢測。基于波段閾值的云檢測方法最早是Zhu等[4]提出FMask算法,通過設定波段閾值來實現Landsat衛星影像的云檢測。在基于紋理的云檢測方法中,Otsu算法[5]和K-means聚類法[6]等都是基于鄰域的相似性進行檢測,對噪聲比較敏感,魯棒性較差。康一飛等[7]利用高斯混合模型自適應獲取影像的灰度閾值,從而分離ZY-3影像的前景與背景,實現云的檢測,但對地表上較亮的地物的誤判比較嚴重; 仇一帆等[8]使用CFMask算法檢測Landsat8影像的云及云陰影,然后用其結果代替人工勾繪的云標簽參與深度學習訓練,再用訓練出來的模型檢測新圖像的云及云陰影,結果發現其檢測結果比原始標簽精度更高; 栗旭升等[9]利用灰度共生矩陣提取圖像的紋理特征,使用紋理特征與光譜特征結合,再使用支持向量機的方法對高分一號衛星影像進行云檢測; 徐啟恒等[10]使用超像素分割方法與卷積神經網絡相結合,采用半監督的方式與傳統的Otsu算法相比,云檢測精度有較大的提高; 劉云峰等[11]將雙重注意機制模型與全卷積神經網絡模型相對比,發現雙注意力機制模型用于云檢測更為準確; 張家強等[12]對Unet網絡結構進行改進,編碼器與殘差結構相結合,提高了模型的泛化能力,比傳統的Unet模型檢測精度更優; 張永宏等[13]提出解碼器不僅在Unet模型的編碼器中引入殘差模塊,而且將密集連接模塊融入解碼器中,可以很好地檢測出薄云大量的碎云; 康超萌[14]采用自適應超像素分割算法與支持向量機相結合的方法進行云檢測,可以很好地檢測出薄云,但在數據量大的情況下,效率較低; 張晨等[15]針對云與云陰影的誤檢現象,使用ResNet作為編碼器與解碼器,跳躍連接部分引入雙重注意力機制,編碼器與解碼器之間使用改進的空洞金字塔池化模塊以提取圖像的多尺度特征,有效提高了云檢測的精度。
隨著深度學習算法的不斷進步,越來越多的遙感問題都可以通過深度學習的方法得到有效解決。基于上述研究,本文提出一種融入注意力機制的密集連接網絡,以解決深度學習算法檢測小塊云朵效果差的問題。首先,借鑒D-LinkNet網絡[16]的編碼器解碼器思想,使用DenseNet[17]作為編碼器與解碼器以訓練到更深層的網絡結構,能夠提取更多特征; 然后,中間層引入自注意力機制GCNet-Block[18]可以更好地提取上下文信息,引入雙注意力模塊[19]增加有用信息的特征級別,降低無用信息的特征級別,使網絡能夠注意到有用的特征; 最后,經過級聯的空洞卷積結構,使網絡在不改變特征圖分辨率的前提下,增大感受野,更加有利于捕獲影像的全局信息,將編碼器階段得到的特征圖與解碼器階段上采樣得到的特征圖進行跳躍拼接,實現了對編碼器階段得到的特征的復用。
1 融入注意力機制的密集連接網絡
1.1 DenseNet結構
DenseNet網絡是2017年由Huang等[20]提出,DenseNet借鑒了He等[21]提出ResNet的跳躍連接以減輕梯度消散現象,從而訓練到更深層網絡的思想,直接將任意2層進行跳躍連接,以求最大化減輕梯度消散問題,從而訓練到更深的網絡。ResNet網絡模型的公式為:
xl=H(xl-1)+xl-1
,
(1)
式中:xl-1為第l-1層輸出的特征圖;H為對特征圖進行卷積、批歸一化、激勵等操作;xl為第l層輸出的特征圖。
ResNet模型結構如圖1所示。

圖1 ResNet-Block結構
而DenseNet不同的是其互相連接所有的層,具體來說就是每個層都會接受其前面所有層作為其額外的輸入,密集連接模塊(densely connected block)結構如圖2所示,其公式為:
xl=H(x0,x1,...,xl-1)
,
(2)
式中[x0,x1…,xl-1]表示前l-1層的輸出的特征圖的拼接。

圖2 密集連接模塊
雖然通過跳躍拼接的方式保留了原始的特征,減輕了梯度傳播過程中消散現象,但隨著網絡層數越來越深,通道數也越來越大,參數量也越來越多,從而也難以訓練到更深的網絡。為此DenseNet還包含了一個重要的轉換模塊(transition block),如圖3所示,用在密集連接模塊之后,將得到的特征圖的通道數減小為原來的一半。但僅僅這樣還是會大大增加通道數,所以在密集連接模塊中每次拼接之前都加入一個瓶頸(bottleneck)結構,將其特征圖的通道數減小為增長率,這樣就可以大幅度減小通道數。則經過一個密集連接模塊之后的特征數就可以表示為:
C′=C+gn
,
(3)
式中:C′為經過密集連接模塊之后的通道數;C為經過密集連接模塊之前的通道數;g為通道數的增長率;n為層數量。

圖3 轉換模塊
通過密集連接模塊后經過轉換模塊(transition block)可將其通道數降為原始的一半,并進行下采樣減半尺寸大小,從而更加簡化了計算量,提升計算效率。
1.2 注意力機制
1.2.1 雙注意力機制
隨著計算機視覺的發展,各種注意力機制相繼被提出,從而使計算機關注有用信息,忽略不感興趣的信息。注意力機制分為通道注意力機制與位置注意力機制。
通道注意力機制最早提出的是SENet[22],通過壓縮激勵(squeeze-exciting)的方式對每個通道進行加權,實現對信息量大的通道重點關注,信息量少的通道關注力度更小。然而,雙注意力機制中的通道注意力模塊不像CBAM(convolutional block attention module)[23]中的通道注意力機制還需手工設計感知機,更加方便了應用。雙注意力機制的通道注意力模塊如圖4所示。

圖4 通道注意力模塊
通道注意力模塊的具體流程如下: 首先將特征圖A變形成C×N(其中N=H×W)大小,再轉置成N×C大小,與另一個只變形的特征圖矩陣相乘得到C×C大小的特征圖,再經過softmax層,得到不同通道的權值特征圖X,再與變形過后的A進行矩陣相乘得到C×N大小的特征圖,再變形成C×H×W大小的特征圖,最后與原始的A進行矩陣相加,得到通道加權后的特征圖Z。
位置注意力模塊的最早應用是CBAM中的空間注意力(spatial attention model,SAM)模塊,其首先將原始的特征圖分別對同一位置不同通道進行全局最大池化與全局平均池化,分別生成通道數為1的特征圖,然后將兩者拼接起來,繼而通過一個卷積核尺寸為7,填充尺寸為3的卷積將拼接起來的特征圖的通道數降為1,從而達到獲取其位置權重的目的。
而雙注意力機制中的位置注意力模塊則是使用通過自相關矩陣的變換得到位置權重,可以更注意全局特征。其模型結構如圖5所示。

圖5 位置注意力模塊
其結構與通道注意力模塊類似,區別是其進行矩陣相乘時得到的特征圖大小為(H×W,H×W),將所有通道信息進行了壓縮,然后進行softmax,得到各個位置的權值S。
1.2.2 全局上下文建模模塊
雙注意力機制可以融合通道注意力機制與位置注意力機制,雖然其加入了自相關矩陣大大改善了注意力陷入局部的問題,但充分利用全局的上下文信息是有必要的。所以在進行融合雙重注意力機制之前,先將全局的上下文信息提取出來。
為了解決此問題,最早提出的是NLNet(non-local net)[24],它利用自我注意機制建立遠程依賴,使網絡能夠更全面地理解圖像,從而不會使計算機局部感知圖像。對于每個查詢點,首先計算該點與所有點的點對關系,得到注意力圖,然后對所有點的特征進行加權求和,得到與查詢端相關的全局特征,最后將全局特征加入到每個查詢點的特征中,完成遠程依賴關系的建模(圖6)。
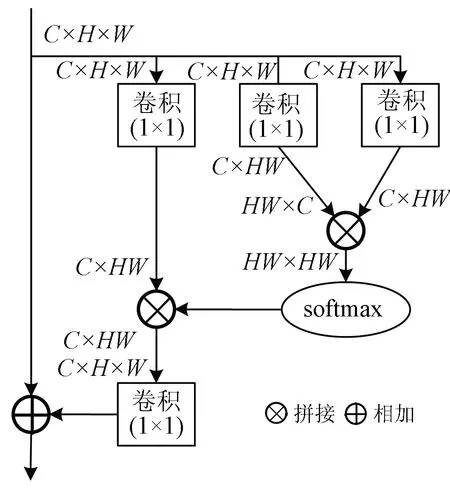
圖6 非局部神經網絡
但是由于NLNet內部有較多的矩陣變換運算,導致計算量大大增加,所以極大地限制了NLNet的使用,為此GCNet提出了簡化NLNet版本,即Simple-NLNet,并結合了SENet計算量少的優點,從而不僅有效地建立遠程依賴,又節省了網絡結構的計算量。GCNet的GC-Block模塊如圖7所示。

圖7 全局上下文建模模塊
對于GCNet其可以分為3個步驟: 首先是需要使用全局平均池化進行上下文建模(context modeling),原始大小為C×H×W一方面先將其變形成C×HW大小的特征圖,另一方面使用1×1卷積降低通道數為1,生成1×H×W大小的特征圖,再變形成HW×1×1大小的特征圖,經過softmax層后與C×HW大小的特征圖進行矩陣相乘,得到C×1×1大小的特征圖,至此每個通道的特征圖的大小都變為1×1,完成了上下文建模。第二步捕獲通道間的依賴,先將C×1×1大小的特征圖經過一個瓶頸結構,降低通道數,圖中r為通道數減少的倍數,從而減小了計算量,然后加入歸一化層提高泛化能力,使用ReLU函數進行激勵,得到非線性關系,最后還原通道數。第三步是將原始的特征圖與變換后的特征圖使用相加操作進行融合。
1.3 空洞卷積模塊
感受野表示單個像素點在上層卷積網絡特征圖中的區域范圍大小,感受野越大,則表示通過卷積得到一個像素點所使用的上層特征圖的像素個數越多,即所使用到的特征越多。感受野的大小決定了網絡能否獲取特征圖的全局信息。擴大感受野最簡單的方法就是增大卷積核的大小,但是卷積核大小的增大一定會使計算量增加,所以隨著Deeplab V1[25]提出的空洞卷積,即擴大卷積核并在卷積核中使用部分用0來填充,從而可以簡單方便地解決計算量增加的問題。如圖8所示,特征圖分為同等的6份,第一層為分別使用1,2,4,8,16大小空洞率進行空洞卷積,后面5層類似,最后將空洞卷積后的特征圖與最后一層的原始特征圖相加,從而可以增大感受野。
1.4 融合注意力機制的密集連接網絡
在上述研究的基礎上,本文提出融合注意力機制的密集連接網絡,具體模型結構如圖9所示。
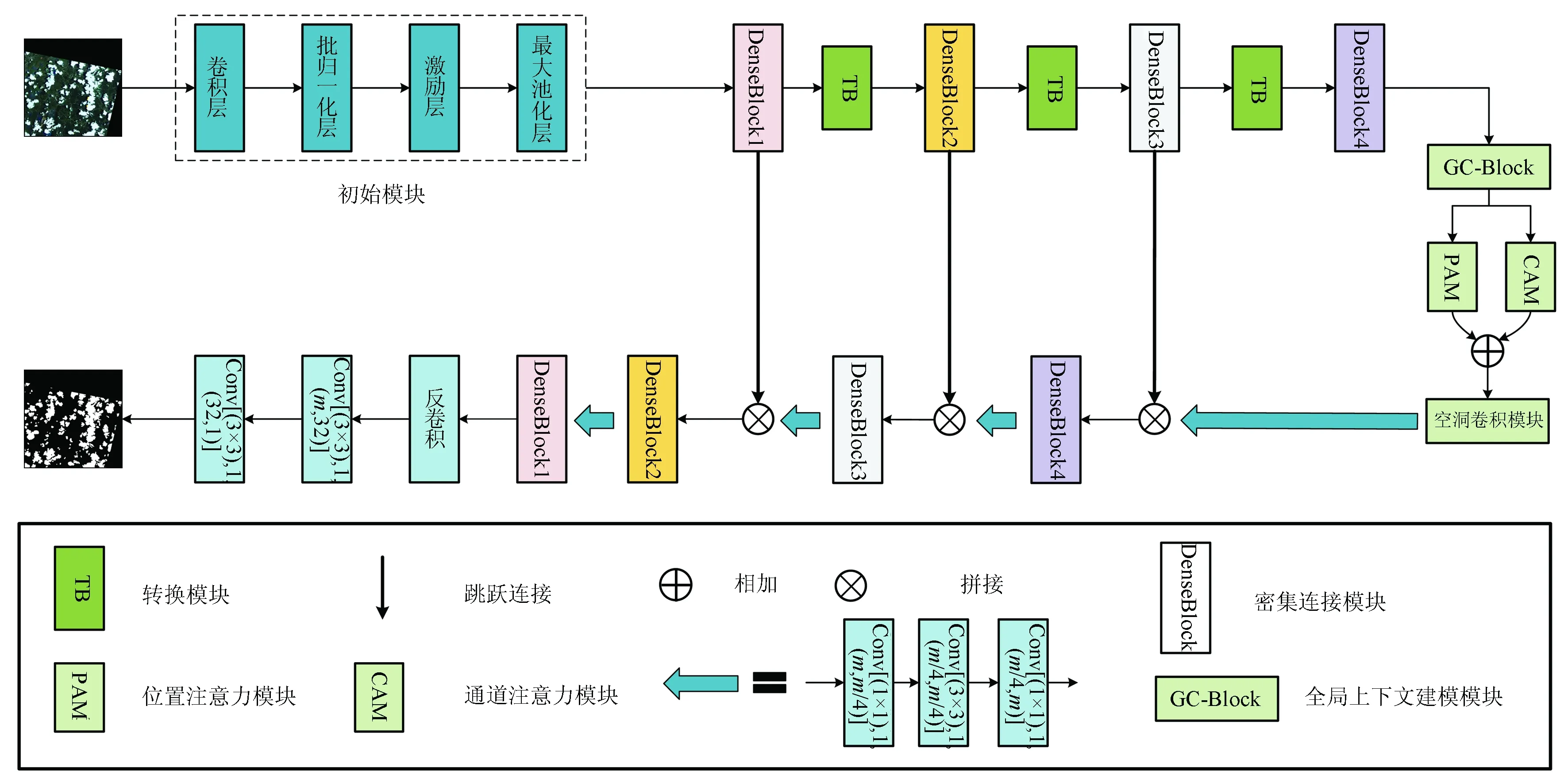
圖9 融入注意力機制的密集連接網絡
1)編碼器階段: 將裁剪好的3通道影像經過一個初始模塊,初始模塊由4個部分組成,第一部分為卷積核大小為7,填充大小為3的卷積層以不改變特征圖的大小,輸出通道數為64以減弱網絡對影像失真影響; 第二部分為批歸一化層,其作用加速模型收斂以及一定程度上緩解深層網絡的梯度彌散問題; 第三部分為激勵層,ReLU可以增加網絡的非線性,并使一部分神經元的輸出變為0,減少了參數之間的相互依賴,防止過擬合; 第四部分為最大池化層,最大池化層將原始特征圖的寬高尺寸減半,減少了參數量,并一定程度上增加了網絡的非線性關系。然后分別經過4個密集連接模塊與轉換模塊提取特征,密集連接模塊有效地減弱了梯度消散問題,轉換模塊有效地減少了參數量,使網絡不至于“參數爆炸”。其中4個密集連接模塊的層數量分別為6,8,12,16。
2)中間層: 首先通過GC-Block提取特征圖的上下文信息,雙注意力機制融合了位置注意力與通道注意力信息,使計算機更好地注意需要的特征,再將結果送入空洞卷積模塊中使其在不改變特征圖分辨率的前提下,增大感受野,進一步提取特征圖的全局特征。
3)解碼器階段: 解碼器部分首先上采樣使特征圖的通道數減小為剛通過編碼器階段DenseBlock3的特征圖的通道數,圖中m為當前層特征圖的通道數; 然后與其進行跳躍拼接,從而特征圖通道數變為原來的2倍,跳躍拼接可以實現特征復用,保留了更多的原始特征; 經過DenseBlock之后,通道數增加,再通過上采樣降低通道數,直到最后將特征圖變為通道數為1的二值圖。
2 實驗與分析
2.1 實驗數據準備與參數設置
本文的實驗均在ubantu16.04,CUDA 10.1,NVIDIA UNIX 64核的pytorch1.2.0深度學習框架下進行的。
本次實驗的數據來自自然資源部國土衛星遙感應用中心提供的國產衛星遙感影像,其中包括高分一號、高分二號、高分六號、資源衛星影像,由于我國中東部地區云量相對較小,所以大部分選取新疆、西藏及內蒙古等邊疆地區的遙感影像,小部分選取中東部地區的遙感影像,共596景,比例關系約為6∶4。標簽制作為手工勾繪云矢量,后使用自制python腳本將其轉化為二值圖標簽。原始標簽及其真值標簽部分數據如表1所示。

表1 原始影像及其真值標簽
訓練之前首先經過預處理,進行影像數據的擴充,方法有: 色彩抖動、水平翻轉、垂直翻轉、順序裁剪、旋轉等。首先進行順序裁剪,將原始的影像與標簽裁剪成512像素×512像素大小的影像共2 468張,再使用色彩抖動、平移、旋轉、尺度縮放、水平翻轉、垂直翻轉進行擴充數據集,共得到12 340張,按照8∶2的比例分為訓練集9 872張與測試集2 468張。預處理的目的是擴充數據量,對數據進行增廣,防止過擬合,提高模型的泛化能力。增強后的影像及其真值標簽見表2。

表2 增強之后的影像及真值標簽

(續表)
參數設置: batchsize為4,步長為20,使用的優化器為Adam,初始學習率為0.001,自動調整學習率,每次調整變為原來的1/2,直到損失值7次不再下降為止。
2.2 損失函數
由于這是針對二分類問題,所以使用BCELoss作為損失函數。BCELoss是二分類問題中優秀的損失函數,其公式為:
,
(4)
,
(5)
式中:GT為標簽影像(ground true);P為預測影像(predicet mask);B為批大小;W′為影像的寬度;H′為高度;gtij為標簽影像在i,j位置的像素值;pij為預測影像在i,j位置的像素值。
2.3 評價指標
這里選取的指標為交并比IoU、召回率recall以及精確率precision。其計算方式分別為:
,
(6)
,
(7)
,
(8)
式中:TP為真陽性,表示原本為云預測為云的數量;TN為真陰性,表示原本為非云預測為非云的數量;FP為假陽性,表示原本為非云錯誤預測為云的數量;FN為假陰性,表示原本為云錯誤預測為非云的數量。其中3個指標越高表示精度越高。
2.4 云檢測結果分析
由于影像不是多光譜影像,不能利用以熱紅外波段實施云檢測的FMask算法進行檢測,所以傳統方法分別使用Otsu閾值算法、Otsu多閾值算法及K-means聚類算法進行云檢測。深度學習算法分別使用SegNet,Unet,D-LinkNet50,未加注意力機制的本文方法(D-DenseNet)及本文方法(AD-DenseNet)對增強后的影像進行訓練。首先進行定量分析,其中在訓練集上的不同算法模型評價指標表現如表3所示,驗證集上的不同算法模型的評價指標表現如表4所示,從表3—4中可以看出,傳統算法的精度較深度學習算法的精度低,而在深度學習算法中,無論在訓練集上還是在驗證集上的召回率、交并比以及精確率都為本文方法精度最高。加上注意力機制后交并比增長約一個百分點,召回率與精確率也都有小幅度增長。

表3 訓練集上的不同算法模型評價結果

表4 驗證集上的不同算法模型評價結果
圖10為AD-DenseNet算法的損失值與交并比隨著訓練輪數epoch的變化,其中一個epoch表示全部數據訓練一次。一共訓練了120個epoch,訓練集與測試集上的交并比均高于0.91,并且最后都達到收斂。圖11為AD-DenseNet算法的精確率與召回率隨著epoch的變化曲線,可以發現最后均收斂,并且精確率都在0.95以上。不同算法云檢測結果如圖12所示。

圖10 AD-DenseNet算法損失值與交并比隨epoch的變化曲線

圖11 AD-DenseNet算法精確率與召回率隨epoch的變化曲線

(a) 原始云影像

(b) 真值標簽(c) Otsu閾值法(d) Otsu多閾值法

(e) K-means聚類法(f) SegNet(g) Unet

(h) D-LinkNet50(i) D-DenseNet(j) AD-DenseNet
首先使用傳統方法Ostu閾值法、Ostu多閾值法及K-means聚類法對原始影像進行云檢測,結果如圖12(c)—(e)所示,從中可以看到Otsu閾值法與K-means聚類法檢測效果明顯不佳,由于其對噪聲魯棒性較差,Otsu多閾值法可以較好地檢測出云的范圍,但是從圖12(d)中橙色橢圓虛線框中可以看到有明顯的錯檢現象。對于深度學習方法,分別使用SegNet,Unet,D-LinkNet50,D-DenseNet及AD-DenseNet進行預測測試集中的影像,首先,將原始影像進行順序切分為512像素×512像素大小的小影像,再使用訓練好的網絡模型進行預測,最后按照規則進行還原成原始影像大小。縱觀圖12的(f)—(j),其大體上沒什么差別,預測精度都較高,但對于小塊云朵的檢測卻不是如此。從圖12(a)中可以看到,原始影像在紅色框中有2片較小的云,由于其后方有明顯的云的陰影,所以判定其為云,真值標簽只勾繪出了一片云,SegNet,UNet,D-LinkNet及D-DenseNet均未預測出2片小塊云,但AD-DenseNet算法卻準確預測出其位置及形狀。圖12(a)中黃色框中,有一塊較小的薄云,放大之后可清晰看到其云陰影,其中SegNet,UNet和D-LinkNet均未預測出此小塊云,D-DenseNet與AD-DenseNet正確預測出其位置及形狀。
3 結論
本文針對傳統的深度學習算法不能很好地檢測出小塊云的問題,提出了一種融合注意力機制的密集連接網絡(attention DBlock densely connected networks,AD-DenseNet)。
1)首先從編碼器與解碼器結構出發,不再使用通用的ResNet-Block結構作為骨干網絡,使用DenseNet-Block作為編碼器與解碼器,從而可以訓練到更深層的網絡,提取到更多的影像特征。
2)中間層使用GC-Block提取全局特征,防止網絡陷入局部,引入雙注意力機制,使網絡更加注意有用信息,抑制無關信息。
3)中間層加入DBlock結構,使網絡在不改變分辨率的情況下增大感受野,以提取全局特征。
從實驗結果來看,交并比可以達到0.91以上,精確率可以達到0.95以上,本文方法可以很好地檢測出小塊云朵,較傳統方法有所提高。
但是對于雪的誤判還存在問題,這將是下一步需要研究的方向。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
