基于隨機森林算法對ERA5太陽輻射產品的訂正
2022-06-22 07:04:04王雪潔施國萍周子欽甄洋
自然資源遙感 2022年2期
王雪潔, 施國萍, 周子欽, 甄洋
(1.南京信息工程大學長望學院,南京 210044; 2.南京信息工程大學地理科學學院,南京 210044)
0 引言
太陽能作為地球最主要的能量來源和基本動力,推動了地表的幾乎全部自然地理過程,使地理環境得以形成和有序發展[1]。也是氣候形成和演變過程中重要的外參數[2],是陸面過程的主要驅動因子。太陽輻射影響大氣圈、水圈、陸地圈層中的物質與能量交換,對太陽輻射研究可以促進對碳循環、水循環等的研究,對全球氣候變化也有重要意義。
隨著科技的進步,農業、電力和城市建設等行業對太陽輻射的研究提出了新的要求[3-5]。我國太陽輻射觀測臺站較少,且測站空間分布不均勻。而再分析數據,即經過對太陽輻射觀測資料(包括地面觀測、衛星,還有雷達、探空等)的質量控制,再同化入全球模式后得到的數據,有著時間序列長、空間分布廣的特點,可以極大彌補地面觀測數據的不足。但是,再分析數據受資料源、模式等影響,無法完全達到真實模擬大氣的程度,具有一定程度的偏差,建立訂正模型對于使用再分析數據來說顯得極為重要。目前已有相關研究利用地面站點地表輻射數據對再分析輻射數據進行了多尺度的驗證。研究表明太陽輻射與云量、氣溶膠、水汽等有關[6-7]。再分析資料與我國太陽輻射站點觀測資料相比,絕大部分高于臺站數據[8-10]。6種再分析地表輻射產品(NCEP-NCAR reanalysis, NCEP-DOE reanalysis, Climate Foreast System Reanalysis (CFSR) ,ECMWF Interim Reanalysis (ERA Interim),Modem-Era Retrospective Analysis for Research and Applications (MERRA) reanalysis,The Japanese 55-year reanalysis),全球月均偏差為11.25~49.80 W/m2,并且發現在中國范圍上,云量和氣溶膠的低估都可能導致再分析地表輻射的高估,夏秋季節明顯好于春冬季節[8-9]。
隨著機器學習的發展,越來越多的研究者開始使用機器學習進行不同地區的太陽輻射的預報偏差的訂正。大量的研究表明,機器學習模型效果較理論參數模型、經驗模型更加準確。陳昱文等[11]利用氣象站點的4個觀測要素,挖掘觀測數據的時序特征并結合氣溫預報結果訓練機器學習模型,對結果進行偏差訂正,發現集成學習方法在數值模式預報結果訂正中具有較大的應用潛力; 李凈等[12]利用ERA5(ECMWF Reanalysis 5)等產品,將人工神經網絡、支持向量機和隨機森林3種機器學習模擬黃土高原地區的太陽輻射并對3種方法進行比較; Benali等[13]將智能持久性、人工神經網絡和隨機森林這3種方法進行比較,預測了法國的太陽輻射,二者結果都表明隨機森林的模擬精度最高; Yu等[14]利用4種機器學習方法,包括梯度提升回歸樹、隨機森林、多元自適應回歸樣條和人工神經網絡對地面96個站點日、月尺度的太陽輻射進行模擬評估,驗證了訓練數據集基于隨機森林方法的太陽輻射估計值與地面測量值的相關性最好。隨機森林的訂正方法在海洋環境預報[15]、氣溫數值預報[16]、空氣質量[17]等方面都有應用且精度很高。Babar等[18]利用ERA5和云、反照率、輻射數據集(CLARA-A2)建立隨機森林回歸模型對挪威地區日平均全球水平輻照度(GHI)進行估計,發現隨機森林模型的估計值較原來的預報值更精確,能夠更好地估計。但是目前很少有研究對中國范圍內的ERA5的高精度太陽輻射數據進行空間訂正,沒有連續的空間分布訂正資料。
本文利用2013年全國93個輻射站的總輻射逐時觀測資料對ERA5同期再分析輻射資料進行了評估,并選擇相關氣象要素及地理要素作為隨機森林學習的輸入量,對全國93個站點上ERA5輻射量的值進行了訂正,進而對ERA5輻射產品進行空間分布上的訂正,得到訂正后的逐時輻射空間分布圖。利用ERA5輻射產品作為輸入變量進行隨機森林回歸,對中國范圍內的高空間分辨率格網數據進行逐時數值訂正,解決了太陽輻射站點不均的問題,為高精度太陽輻射量空間分布資料的獲取提供一種方法。
1 數據源與研究方法
1.1 數據源
①使用歐洲中心天氣預報中心(European Centre for Medium-Range Weather Forecasts,ECMWF)發布的第五代再分析數據集ERA5(ECMWF Reanalysis 5)中相關數據進行分析與訂正,主要包括太陽下行短波輻射(mean surface downward shot-wave radiation flux,MSDWSWRF)、地表反照率、水汽、總云量、臭氧、高云、低云、中云、冰云、水云產品,時間為2013年,時間分辨率為1 h,空間分辨率為0.25°×0.25°; ②中國93個輻射站點信息(經度、緯度和海拔),以及2013年逐時的太陽總輻射量。
1.2 研究方法
1.2.1 數據評估指標
采用絕對誤差(absolute error,AE)、平均絕對誤差(mean absolute error,MAE)、均方根誤差(root mean squared error,RMSE)和相關系數(R)來分別描述偏離程度、不確定性、準確性和相關性。表達式分別為:
AE=|x-y|
,
(1)
,
(2)
,
(3)
,
(4)
式中:x為估計值;y為觀測值;n為樣本數;i為樣本序號,i=1,2,…,n;Cov(·)為協方差函數;D(·)為方差函數。
本文主要運用MAE,RMSE和R進行逐時資料的再分析資料與實測值、逐時訂正值與實測值之間的誤差對比分析。AE用于比較ERA5再分析資料的模擬值和隨機森林回歸值與中國地面站點輻射量的月均實測值之間的差異。
1.2.2 隨機森林回歸
1)隨機森林算法。該算法是基于多棵決策樹的一種集成學習算法,且森林中的每一棵決策樹之間沒有關聯,模型的最終輸出由森林中的每一棵決策樹共同決定。隨機森林用于分類時,采用N個決策樹分類,將分類結果采用簡單投票法得到最終分類,提高分類準確率。選取與太陽輻射有關的因子,即時間、經緯度、地表反照率、海拔、天頂角余弦、總云量、臭氧、水汽、低云、中云、高云、冰云、水云作為輸入數據,輸出量為每小時輻射值。算法步驟為: ①用有抽樣放回的方法(bootstrap)從樣本集中選取n個樣本作為一個訓練集; ②用抽樣得到的樣本集生成一棵決策樹,在每一個決策樹節點不重復地選擇m個特征,使用基尼指數找到最佳的劃分特征; ③重復第二步N次之后生成N棵決策樹; ④用訓練得到的隨機森林對測試樣本進行預測,并采用票選法決定預測的結果。
2)特征重要性分析。基尼指數用作對隨機森林訓練樣本特征進行重要性分析,比較每個特征在隨機森林中的每棵樹所做的貢獻。基尼指數越小表示集合中被選中的樣本被分錯的概率越小,也就是說集合的純度越高,反之,集合越不純。設VIM為變量重要性評分,GI為基尼指數,假設有m個特征X1,X2,…,Xm,則GI的計算公式為:
,
(5)
式中:K為類別數;pmk為節點m中類別k所占的比例。在節點m上,特征Xi在節點m分支前后的基尼指數變化為:
VIMim=GIm-GIg-GIh
,
(6)
式中GIg和GIh為分支后新的基尼指數。特征Xi在第j棵決策樹的重要性為特征Xi在決策樹j中出現的節點m的基尼指數變化量的和,記為VIMij。若隨機森林模型中有N棵樹,特征Xi的變量重要性評分VIMi為出現的所有決策樹j中的VIMij的總和。最后,把所有求得的重要性評分做一個歸一化處理即可。
3)K折交叉驗證。該方法用于模型調優,可以減少過擬合的問題。為了進一步檢驗模型泛化能力,基于獨立樣本數據,因訓練集較大選擇5折交叉驗證以降低訓練成本。步驟為: 將數據分為5組,每次從訓練集中,抽取出5份中的一份數據作為驗證集,剩余4組作為測試集,重復5次。測試結果采用5組數據的測試誤差的平均值作為最后精度評價。原始數據集劃分成訓練集和測試集以后,其中測試集除了用作調整參數,也用來測量模型的好壞。K折交叉驗證對網格搜索(GridSearchCV)是很重要的,用來選擇模型的最優參數,本文將全部數據集按照7∶3劃分為訓練集和測試集進行5折交叉驗證。
1.3 隨機森林模型
1.3.1 模型參數取值
使用隨機森林模型進行學習時,參數對模型準確度意義重大。網格搜索算法(GridSearchCV)是一種通過遍歷給定的參數組合來優化模型表現的方法,再利用K折交叉驗證,得到最優模型。隨機森林算法參數眾多,最終優化模型參數取值如表1所示。

表1 模型參數取值
隨機森林模型參數優化的一般步驟是: 先保持其他參數為默認值,對待定參數設置范圍,然后不斷縮小范圍,最終確定參數值。子樹數量對模型的準確性影響最大,設置過低會導致模型不準確,設置過高會增加模型復雜度,所以首先確定子樹數量。設置范圍從[50,70]縮小為[50,57],最終確定子樹數量為56。其他參數仍然利用網格搜索方法,得到最終模型。
1.3.2 5折交叉驗證模型的精度
經過5折交叉驗證模型,結果如表2所示,決定系數平均值為0.855,說明建立的隨機森林模型的精度較高,模型模擬較優,穩定性良好。
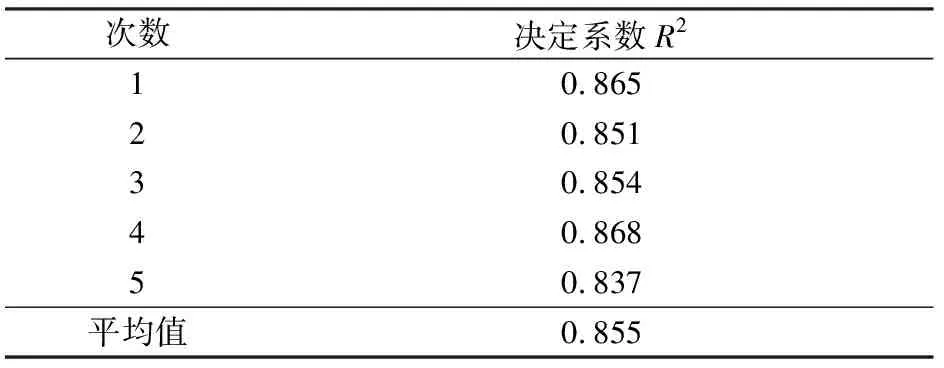
表2 5折交叉驗證模型結果
1.3.3 特征重要性分析
特征重要性可以看出每個輸入量對模型預報所做的貢獻,將時間、經緯度、地表反照率、海拔、天頂角、水汽、總云量、臭氧、高云、低云、中云、冰云、水云作為最終輸入量,輸出量為每小時輻射量。利用基尼指數作為評價指標來衡量特征重要性。由圖1可以看出,天頂角數據重要性最大,為0.325,高云重要性最小,為0.004。說明天頂角對地表太陽輻射量影響較大,高云對地表太陽輻射量影響很小。
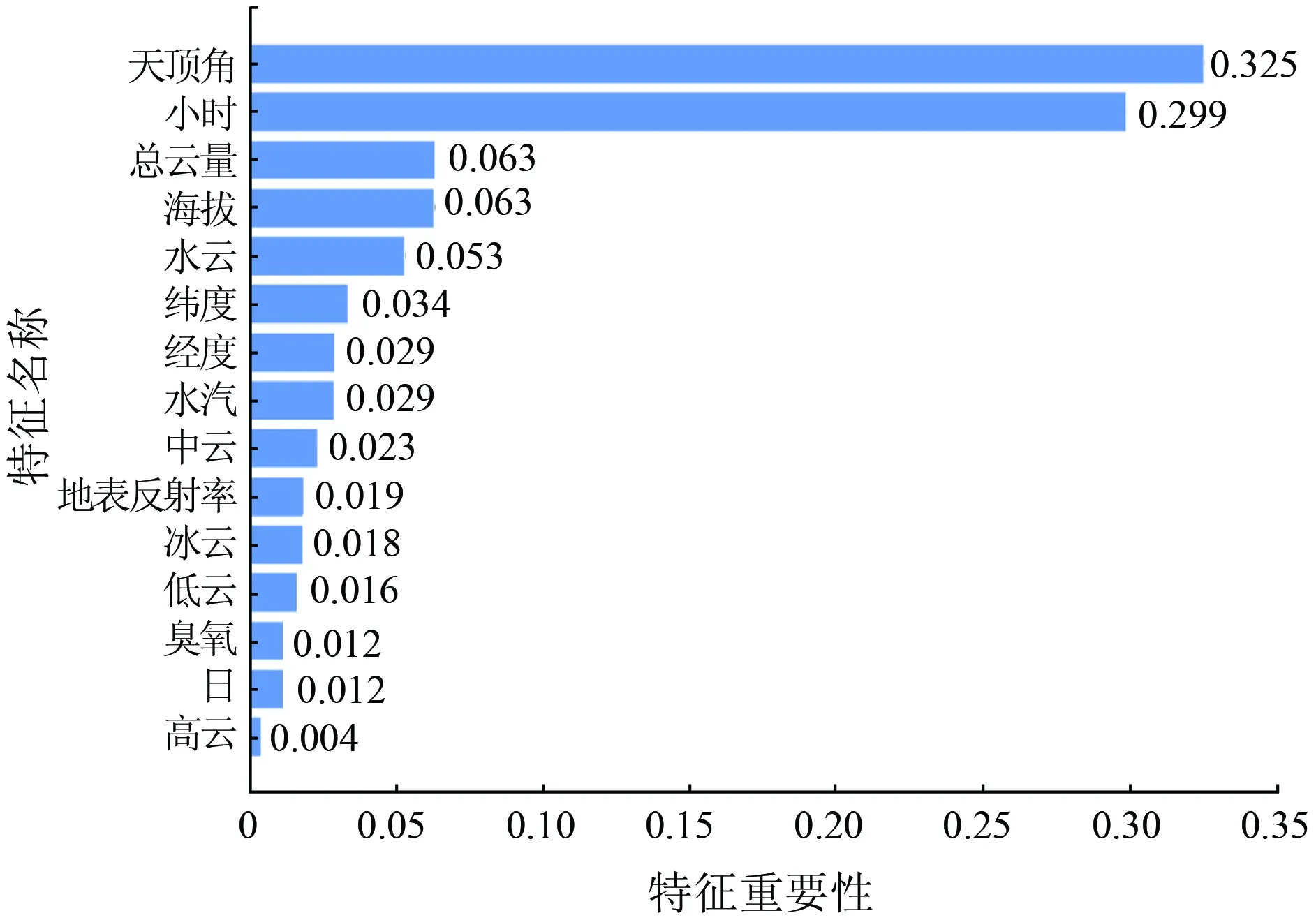
圖1 特征重要性比較
2 結果與分析
2.1 訂正前后的精度分析
圖2為1月、4月、7月、10月ECMWF再分析數據與地面站觀測數據小時地表輻射的訂正前((a)—(d))后((e)—(h))逐時輻射量散點分布對比圖。訂正前,MAE分別為112.22 W/m2,141.91 W/m2,140.08 W/m2和125.50 W/m2,RMSE分別為155.84 W/m2,201.50 W/m2,196.69 W/m2和175.27 W/m2,R分別為0.74,0.80,0.79,0.77。結果表明不同月份的小時輻射數據誤差不同且較大,1月和10月的離散程度小,相關程度也較小,4月和7月的離散程度大,相關程度也較大。訂正后,各月份的訂正值與站點值的離散程度減小,相關性明顯提高,MAE分別為47.99 W/m2,78.77 W/m2,96.44 W/m2和58.38 W/m2,RMSE分別為87.90 W/m2,133.53 W/m2,160.59 W/m2和102.29 W/m2,R分別為0.91,0.91,0.88和0.92; 1月、4月、7月、10月的各誤差指標變化幅度不同,MAE分別降低了57.24%,44.49%,31.15%和53.48%,RMSE分別降低了43.60%,33.73%,18.35%和41.64%,R分別提高了0.17,0.11,0.09和0.15,可見4個月中1月的ERA5地表太陽輻射值訂正效果最好。

(a) 1月訂正前 (b) 4月訂正前 (c) 7月訂正前 (d) 10月訂正前

(e) 1月訂正后 (f) 4月訂正后 (g) 7月訂正后 (h) 10月訂正后
2.2 月均輻射值變化
2013年ERA5再分析資料與中國氣象站點資料訂正前后的月均輻射變化如圖3所示。可以看出,訂正前ERA5太陽輻射量的值較站點值偏高,總體規律都是夏秋輻射量高、春冬輻射量低。訂正后的值接近站點實測值,誤差較小。
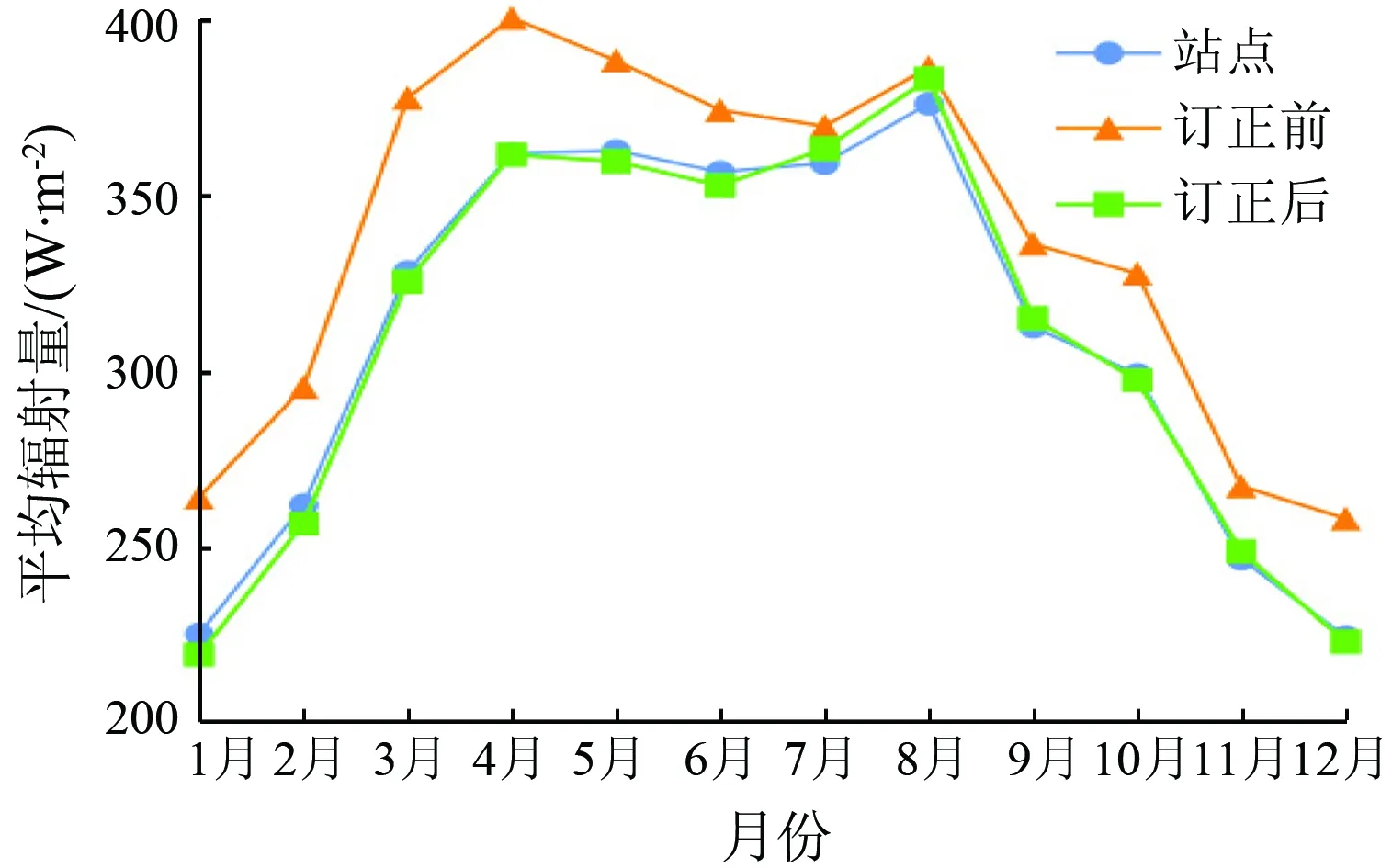
圖3 訂正前后月輻射均值
誤差指標比較如表3所示,訂正前的MAE,RMSE和R分別是27.60 W/m2,29.87 W/m2和0.97,訂正后三者值分別為3.34 W/m2,3.85 W/m2和1.00。MAE下降了87.90%,RMSE下降了87.11%,R提高了0.03。
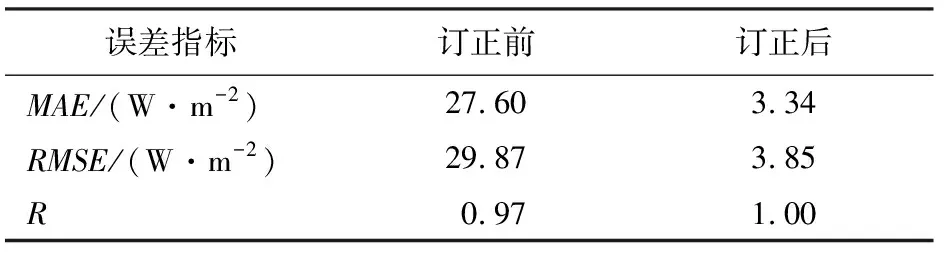
表3 3種誤差指標比較
2.3 訂正前后分月的誤差分布規律
圖4(a)為ERA5再分析資料與中國地面站點輻射量的月均值絕對誤差比較,圖4(b)—(d)為對每個月的小時數據求MAE,RMSE和R的分月誤差比較。得出的結果是,在訂正前,ERA5數據與地面站點的AE在10.28~49.53 W/m2之間,且夏秋季絕對誤差小,春冬季絕對誤差大;MAE在107.80~142.75 W/m2之間,RMSE在148.85~202.15 W/m2之間,R在0.74~0.80之間; 訂正后,AE在-5.91~7.08 W/m2之間,MAE在40.00~98.31 W/m2之間,RMSE在70.98~164.07 W/m2之間,R在0.87~0.94之間。此結果說明: 隨機森林模型對ERA5地表太陽輻射量的訂正效果較好;MAE和RMSE隨著時間的變化也有所規律,明顯看出夏秋季2種誤差指標較大,春冬季較小。

(a) AE (b) MAE (c) RMSE (d) R
2.4 簡單交叉驗證
為了進一步驗證隨機森林模型的穩定性,在中國范圍內采用均勻分布的方法選取6個站點(表4),分別為阿克蘇、剛察、長春、綿陽、建甌和北海,將其2013年所有樣本數據作為模型的驗證數據集,不參與訓練,其余站點的樣本數據作為訓練數據集,進行訓練,訂正結果的比較如表5所示。從表5中看出,對于本身離散程度大、相關性弱的站點數據,經過隨機森林的訂正后精度有明顯的提高,而本身離散程度小、相關性較高的站點數據,經過隨機森林訂正后能夠保持精度或者有小幅度的提高。說明隨機森林的模擬精度高,有較好的穩定性。
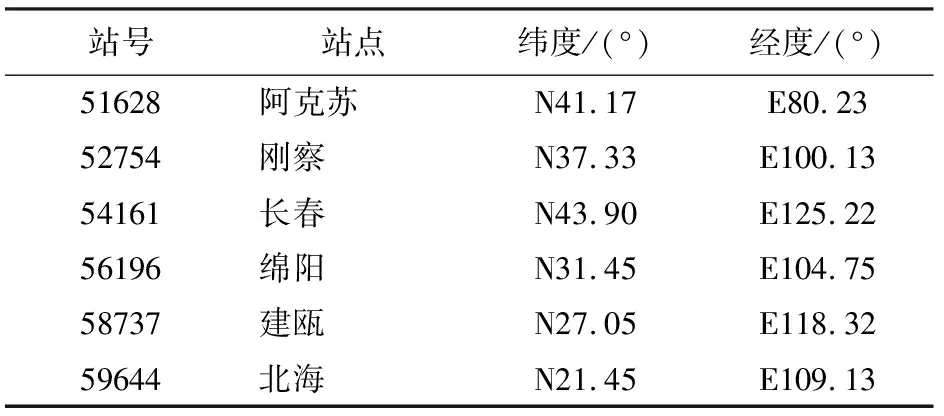
表4 6個站點的信息
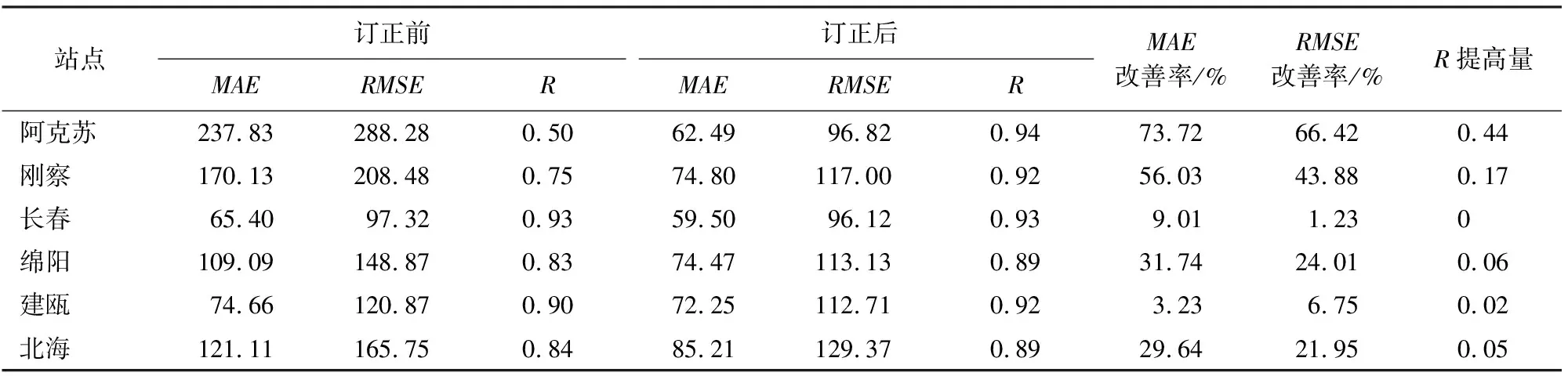
表5 6個站點前后訂正的誤差指標分析
2.5 訂正前后的空間分布變化
圖5為利用上述建立的隨機森林模型對1月、4月、7月、10月的北京時間15日13時ERA5總輻射進行訂正前后的空間分布圖。圖5(a)—(d)和(e)—(h)分別為訂正前后的空間分布結果。由圖5可見,太陽輻射量訂正前后的宏觀分布規律一致,訂正后ERA5太陽輻射量在局部地區有明顯的下降,對ERA5太陽輻射量偏高的情況有所改進,通過隨機森林訂正后的分布圖局部特征更加明顯,精度得到提高。
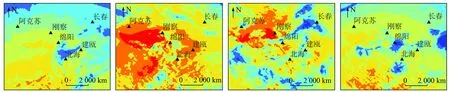
(a) 1月訂正前(b) 4月訂正前(c) 7月訂正前(d) 10月訂正前

圖5-1 訂正前后太陽輻射的空間分布

(e) 1月訂正后(f) 4月訂正后(g) 7月訂正后(h) 10月訂正后
圖5-2 訂正前后太陽輻射的空間分布
3 結論與討論
1)本文首先對2013年的再分析資料ERA5和地面觀測的太陽總輻射數據進行了對比。從總體上看,兩者有較大的差異,ERA5的地表太陽輻射量要高于地面觀測數據,這與前人研究一致; ERA5輻射量與站點值的AE夏秋季小,春冬季大; 1月和10月的離散程度小,相關程度也較小,4月和7月的離散程度大,相關程度也較大。訂正前,2013年MAE,RMSE和R的值分別是27.60 W/m2,29.87 W/m2和0.97,對小時數據分月比較,ERA5數據與地面站點的AE在10.28~49.53 W/m2之間,且夏秋季AE小,春冬季AE大;MAE在107.80~142.75 W/m2之間,RMSE在148.85~202.15 W/m2之間,R在0.74~0.80之間。
2)利用5折交叉驗證和網格搜索選擇模型參數,得到模型最優參數和交叉驗證的模型得分并評價模型的穩定性,從得分可以驗證模型的模擬較優,穩定性較好。將時間、經緯度、地表反照率、海拔、天頂角、水汽、云量、高云等作為輸入參數進行隨機森林訓練。從2013年總體上看,MAE下降了24.26 W/m2,RMSE下降了26.02 W/m2,R提高了0.03,說明隨機森林回歸模型取得了相對有效的訂正結果。對小時數據處理并分月比較,訂正后的AE在-5.91~7.08 W/m2之間,MAE在40.00~98.31 W/m2之間,RMSE在70.98~164.07 W/m2之間,R在0.87~0.94之間,訂正后的離散程度減小,相關性明顯提高。MAE和RMSE隨著時間的變化有所規律,明顯看出夏秋季2種誤差指標較大,春冬季較小。1月、4月、7月、10月的各誤差指標增長幅度不同,4個月中1月的ERA5地表太陽輻射量訂正效果最好。
3)利用簡單交叉驗證,進一步驗證隨機森林模型的穩定性。阿克蘇、剛察、長春、綿陽、建甌、北海站點的太陽輻射量訂正后的MAE,RMSE和R均有提高。結果表明對于本身離散程度大、相關性弱的站點數據,經過隨機森林的訂正后精度有明顯的提高,而本身離散程度小、相關性較高的站點數據,經過隨機森林訂正后能夠保持精度或者有小幅度的提高。說明隨機森林的模擬精度高,有較好的穩定性。
4)通過隨機森林的回歸,對ERA5進行了空間分布上的訂正,訂正前后的宏觀規律一致,訂正后ERA5太陽輻射量在局部地區有明顯的下降,精度得到提高。隨機森林模型對ERA5地表太陽輻射量能夠進行有效地訂正,在實現大樣本數據訓練時能夠保證速度,訓練的模型精度較高,實現較為方便快捷,能夠更好地進行太陽輻射產品的數據融合,得到的全國范圍的連續的太陽輻射數據能夠為農業、電力和城市建設等行業研究提供基礎數據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
