基于改進型集成學習的風電功率預測研究
2022-06-22 03:01:18李思瑩陳海寶
可再生能源 2022年6期
李思瑩,陳海寶
(滁州學院 計算機與信息工程學院,安徽 滁州 239000)
0 引言
風電固有的間歇性和波動性,給電網的安全帶來了風險。準確的風電功率預測可以增強預見性,在提高電網安全的基礎上又提升了能源使用的經濟性[1]。近年來,很多學者將風電功率預測研究重點放在了機器學習方法上,機器學習方法在非線性建模方面擁有巨大的優勢。Vapnik所研究的SVM理論在20世紀90年代引起了廣泛重視,并被逐漸完善。SVM能在有限樣本下找到最優的分類,避免了可能出現的過學習、欠學習和陷入局部最小的問題。文獻[2]以SVM為核心,用SVM實現風電功率預測,表明了SVM方法的有效性。文獻[3]基于支持向量機和改進的蜻蜓算法進行短期風電功率預測,取得了較理想的預測精度,且泛化性能好,突出了SVM在風電應用中的優越性。但上述基于SVM的機器學習法,僅建立了單一的預測模型,這種模型大多不能完整地展現數據的各項特征,往往會“顧此失彼”。更加合理的方法是,集中優勢模型,采用組合模型的方法完成預測,進一步提高模型精度。
作為模型結合的方法之一,集成學習一直被廣大學者所研究和改進[4]。集成學習模型相較于單一模型有著更好的數據處理和泛化能力,可以將各子模型的學習成果進行整合,從而提升模型整體的預測精度。文獻[5]提出了基于支持向量機集成的SDAE在線風電系統動態安全評估,仿真結果表明了該方法的有效性和準確性。文獻[6]提出了一種改進集成學習算法的SVM風速預測方法,該方法預測精度高,運行速度較快,更進一步地實現了風速預測。基于集成學習和SVM思想的模型應用于風電功率預測中,有利于增強電網穩定性,因此有著重要的研究意義。
本文將機器學習與集成學習相結合,提出了一種基于集成學習思想的風電功率預測方法。首先采用模糊C均值(Fuzzy C-Means,FCM)聚類法進行工況辨識,再采用SVM建立子學習器模型。在主學習器模型的基礎上,提出了一種改進的SVM主學習器模型,將樣本到聚類中心的距離加入主學習器模型中,更加符合工程的實際情況,且進一步提高了預測精度。
1 方法
1.1 SVM算法



1.2 集成學習模型

2 基于SVM和集成學習的風電功率預測
2.1 數據準備
本文基于大連某風電場的實際運行數據進行預測。選取2015年10月的數據共6 480組,采樣間隔為2 min。首先利用拉依達準則對6 480組數據進行去除異常點的預處理,剩下5 831組數據;再對5 831組數據進行建模,將前3 500組數據作為子學習器的訓練樣本,中間2 000組數據作為主學習器的訓練樣本,后331組數據作為測試樣本。圖1為原始風電功率序列,圖2為拉依達準則處理后的風電功率序列。

圖1 原始風電功率序列Fig.1 Original wind power sequence
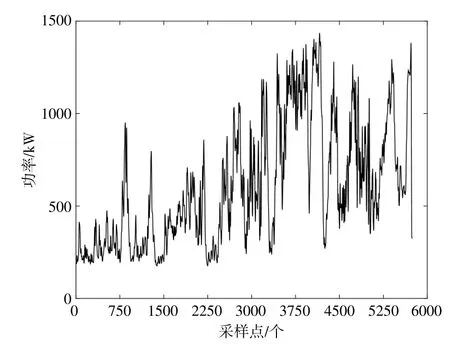
圖2 數據處理后的風電功率序列Fig.2 Wind power sequence after data processing
2.2 基于FCM聚類法的工況辨識
由于本文采用的實驗數據中未包含啟動時間段,故只研究風能追逐區、恒轉速發電區、恒功率發電區3種工況。本文采用FCM聚類法解決風電機組工況之間的模糊性問題。利用FCM聚類法將數據聚類成3類,聚類后各工況的樣本如圖3所示。

圖3 FCM聚類后各工況內的樣本Fig.3 Samples in each working condition after FCM clustering
從圖3可以看出,這3類工況的區別主要為功率高低的不同。
2.3 子學習器的生成
在各工況區間內,采用SVM算法建立子學習器。將用于主學習器訓練的數據(2 000組)分別輸入到各個子學習器中,完成各子學習器模型的測試。各個子學習器的測試結果如圖4所示。

圖4 各子學習器的測試結果Fig.4 Test results of each sub-learner
為了更加直觀地表示出各個子學習器的預測值和真實值的誤差,計算測試數據的均方根誤差和平均相對誤差,結果如表1所示。

表1 各子學習器測試誤差Table 1 Test error of each sub-learner
由表1可知,各個誤差值均較小,在允許的范圍內。良好的各子學習器預測精度也為集成后總體預測奠定了基礎。
2.4 主學習器的生成
將3個子學習器的預測結果作為主學習器的訓練樣本進行主學習器的訓練。在建立主學習器模型時,采用加權平均集成法和SVM集成法兩種不同的結合策略。
(1)加權平均集成法
加權平均作為直觀簡單、運算量小的一種普遍方法,被很多研究所使用。本文所采用的加權平均法基于輸入子學習器的樣本個數,對每一個子學習器的預測結果計算權重,將各子學習器的結果進行加權。預測結果如圖5所示。

圖5 加權平均法的預測結果Fig.5 Forecast results of the weighted average method
通過圖5可以看出,加權平均法的預測走勢大致正確,但是精準度上有待提高。這是由于加權平均法中權重的確定是從訓練數據中計算所得,而在實際建模中,隨機性強的集成器容易導致過擬合。因此在波動性較強的風電功率預測中,加權平均法不是最合適的結合策略。
(2)SVM集成法
在風電功率預測工程中,因為訓練數據較大,需要預測精度值較高,所以子學習器和主學習器均使用支持向量機進行建模,可以更好地提升預測精度,誤差縮小到允許的范圍。集成SVM的流程如圖6所示。

圖6 集成SVM流程示意圖Fig.6 Schematic diagram of the integrated method SVM process
基于SVM主學習器模型的預測結果如圖7所示。通過圖7可以看出,機器學習的方法相比加權平均法,最終的預測精度更高,擬合程度更強,這是因為主學習器采用了機器學習的方法完成了進一步學習。因此,支持向量機作為主學習器可以很好地應用于工程中。

圖7 學習法的預測結果Fig.7 The prediction result of the learning
最后,分析比較主學習器加權平均集成預測法和SVM集成預測法的均方根誤差、平均相對誤差,判斷各方法的精度,誤差值如表2所示。

表2 兩種預測模型的評價指標Table 2 Evaluation indicators of the two prediction models
通過表2可以看出:集成方法預測誤差較低,這是因為集成方法兼顧了幾種模型的特點,彌補了單一模型“顧此失彼”的局限性;由于SVM集成法基于機器學習方法完成了二次訓練,所以均方根誤差值和平均相對誤差值都小于加權平均集成法,實際驗證結果與理論預測結果相吻合。
3 基于改進的SVM和集成學習的風電功率預測
在基于SVM建立子學習器模型時,由于使用聚類算法,聚類中心可在一定程度上表征子學習器所覆蓋的運行工況。但此時將子學習器輸出的數據輸入到主學習器中,未考慮樣本與聚類中心的貼近程度,即忽略了工況對結果的影響。因此在建立主學習器模型時,考慮樣本到聚類中心的距離是必要的,從而完成對SVM主學習器的改進。圖8和圖9分別為主學習器訓練樣本與測試樣本到聚類中心的距離。從圖8、圖9可以看出,在3個子學習器中,工況不同,樣本到聚類中心的距離也不同。所以在建立主學習器模型時將工況因素考慮進去是非常必要的。在實驗中,將2 000組樣本到3個聚類中心的距離分別記為d1,d2,d3,則主學習器的輸入值為3個子學習器的輸出值和d1,d2,d3。在主學習器的輸入中加入工況信號,能夠使其在訓練參數時計及運行工況的因素,從理論上能進一步提高集成模型的精度,并且更加符合工程的實際要求。

圖8 主學習器訓練樣本與各聚類中心的距離Fig.8 The distance between the main learner test sample and each cluster center

圖9 主學習器測試樣本與各聚類中心的距離Fig.9 The distance between the main learner training sample and each cluster center
基于改進的主學習器風電功率預測具體步驟如下:
①利用拉依達準則對輸入數據進行預處理;
②基于FCM完成工況劃分,將子學習器的訓練數據劃分成3個子類,對每一個子類進行SVM子學習器建模,完成3個子學習器的建模;
③將主學習器的訓練數據分別輸入到3個子學習器中,然后將3個子學習器的輸出值作為主學習器的一部分輸入,主學習器的訓練數據和3個聚類中心的歐式距離作為主學習器的另一部分輸入。將以上變量輸入到主學習器中進行風電功率的預測。
改進的主學習器建模流程如圖10所示。

圖10 改進的主學習器模型流程圖Fig.10 Flow chart of the improved master learner model
建立主學習器模型后,將350組測試數據輸入到各子學習器中,各子學習器的輸出和樣本到聚類中心的距離作為主學習器的輸入,訓練主學習器。圖11為基于改進主學習器模型的預測結果。
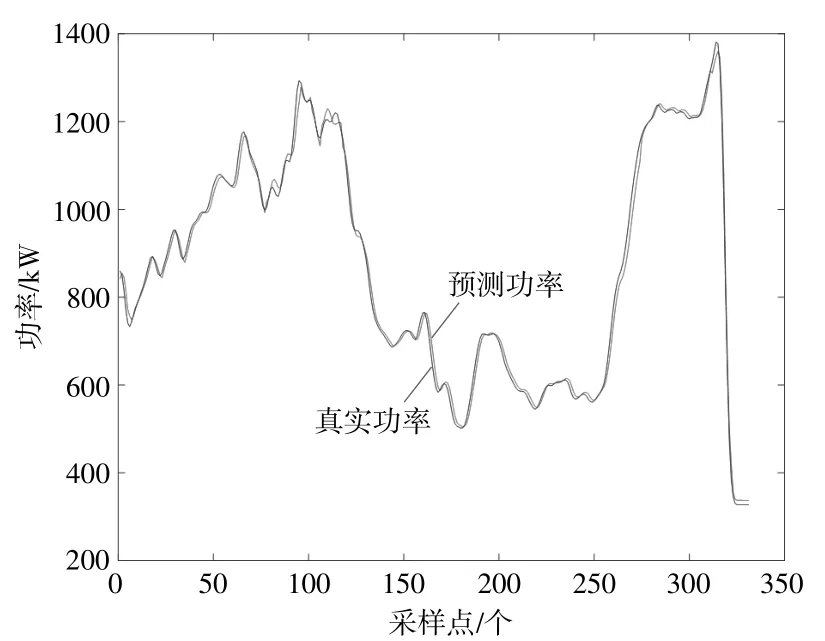
圖11 改進主學習器的預測結果Fig.11 Prediction result of the improved master learner
為了體現該方法的有效性,分別計算加權平均法集成模型、SVM集成模型和SVM優化集成模型的均方根誤差、平均相對誤差。3種模型的預測誤差如表3所示。

表3 不同集成方法的預測誤差Table 3 Forecast errors of different integrated methods
通過表3可以看出,SVM優化集成的組合模型相比于其它模型,由于將主學習器訓練數據到每一個聚類中心的距離作為輸入,考慮到了樣本對于不同工況的貢獻程度,使得均方根誤差和平均相對誤差減小,大幅度提高了模型精度。由此可見,本文提出的方法提高了預測精度,適合應用在波動性較強的風電功率預測中。
4 結論
針對單一的SVM算法學習能力不足、無法有效利用大數據資源提高精度,本文將集成學習應用在風電功率預測中。該方法可在不同工況下同時建立各工況的子學習器,提高了模型精度。基于集成學習的思想,采用FCM完成了風電機組實際SCADA歷史數據的工況辨識,建立了各工況的SVM子學習器模型。在建立主學習器模型時,提出一種改進的主學習器模型,將樣本到聚類中心的距離加入到主學習器模型中,考慮了運行工況對主學習器的影響。通過實驗對比可知,本文提出的風電功率預測方法預測精度高,滿足工程實際要求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
