基于改進YOLO v5的夜間溫室番茄果實快速識別
2022-06-21 08:21:26張亦博龔健林趙昱權(quán)吳若丁
農(nóng)業(yè)機械學(xué)報 2022年5期
何 斌 張亦博 龔健林 付 國 趙昱權(quán) 吳若丁
(1.西北農(nóng)林科技大學(xué)水利與建筑工程學(xué)院, 陜西楊凌 712100;2.西北農(nóng)林科技大學(xué)旱區(qū)農(nóng)業(yè)水土工程教育部重點實驗室, 陜西楊凌 712100)
0 引言
我國既是番茄出口大國又是消費大國,在日光溫室內(nèi)對番茄進行實時監(jiān)控并利用采摘機器人不僅降低人工成本,同時又能提高效率,節(jié)省時間,對于番茄培育具有重要意義[1-2]。但目前夜間環(huán)境下光線復(fù)雜,果實與葉片重疊在昏暗光線下進一步對采摘機器人與監(jiān)控設(shè)備的識別造成了困難。
日光溫室內(nèi)番茄果實的傳統(tǒng)識別方法主要依靠顏色空間的差異與形狀對圖像進行分割,隨著計算機技術(shù)與機器視覺技術(shù)的發(fā)展,深度學(xué)習(xí)也應(yīng)用到了番茄果實的識別方法中[3-11]。綜上所述,圖像分割等處理方法對于番茄識別的精度較低,卷積神經(jīng)網(wǎng)絡(luò)(CNN)等方法實時性較差,基于深度學(xué)習(xí)的識別算法雖提高了實時性與精度,但面對夜間復(fù)雜環(huán)境下的各種影響因素考慮不全,難以滿足實際要求。
隨著以卷積神經(jīng)網(wǎng)絡(luò)為代表的深度學(xué)習(xí)不斷地發(fā)展,目標檢測已經(jīng)廣泛地運用到了各個領(lǐng)域。目標檢測算法可以分為兩類,第一類是基于region proposal(候選區(qū)域)的R-CNN[12]系列算法,如:R-CNN、Fast R-CNN[13]、Faster R-CNN[14]等。該類算法通過兩個步驟進行計算:選取候選框;對候選框進行分類或者回歸。此類方法魯棒性高,識別錯誤率低,但運算時間長,占用磁盤空間大,對圖像信息進行重復(fù)計算,不適合進行實時檢測。第二類是如YOLO[15]、SSD[16]等網(wǎng)絡(luò)模型的one-stage算法[17]。該類算法是采用不同的尺寸對圖像進行遍歷抽樣,然后利用CNN提取特征后直接進行回歸[18]。該類方法識別速度快,實時性強,但由于網(wǎng)絡(luò)模型簡單,識別率低于第一類方法。SSD神經(jīng)網(wǎng)絡(luò)運行速度略低于YOLO,檢測精度略低于Faster R-CNN,但魯棒性較差,需要人工設(shè)置各種參數(shù)閾值,且先驗框無法通過學(xué)習(xí)獲得,需要手工設(shè)置,對于小目標存在低級特征卷積層數(shù)少,特征提取不充分的問題。YOLO系列網(wǎng)絡(luò)以YOLO v5為代表,由于平衡了速度快的特點,喪失了部分精度,因為沒有進行區(qū)域采樣,所以在小范圍的信息上表現(xiàn)較差,具有識別物體位置精準性差、召回率低等問題。研究表明[19],由于第二類目標檢測方法實時性強,有利于提高采摘機器人及監(jiān)測設(shè)備的工作效率,適用于復(fù)雜環(huán)境下實時的目標檢測。
本文基于改進YOLO v5目標檢測算法,根據(jù)夜間日光溫室下復(fù)雜環(huán)境情況,采用YOLO v5快速精確的檢測結(jié)構(gòu),融合多尺度信息模型,通過數(shù)據(jù)增強等方法提高檢測精度,構(gòu)建一種可在移動設(shè)備下實現(xiàn)夜間復(fù)雜環(huán)境的番茄本體特征識別的網(wǎng)絡(luò)模型。并通過與其他算法的對比,驗證本網(wǎng)絡(luò)模型的實時性與準確性,以期為采摘機器人與實時檢測設(shè)備系統(tǒng)設(shè)計提供參考。
1 番茄圖像數(shù)據(jù)采集
番茄圖像數(shù)據(jù)采集自西北農(nóng)林科技大學(xué)園藝場節(jié)能型日光溫室,番茄植株采用吊蔓式栽培方法。圖像采集設(shè)備為佳能EOS-750D型相機,采用CMOS傳感器,APS畫幅(22.3 mm×14.9 mm),采集番茄果實、葉片、花卉、稈莖4類RGB圖像共2 000幅用于數(shù)據(jù)訓(xùn)練及測試,RGB圖像分辨率為4 000像素×6 000像素。由于模擬日光溫室內(nèi)夜間環(huán)境下采摘機器人夜間視覺系統(tǒng),采集過程中在圖像采集設(shè)備一側(cè)設(shè)置對角光源[20],如圖1所示。為了避免由于樣本數(shù)據(jù)多樣性不足導(dǎo)致的過擬合現(xiàn)象,考慮夜間環(huán)境下暗光區(qū)域以及陰影區(qū)域,圖像數(shù)據(jù)分為正常采樣與暗光采樣兩種情況,如圖2所示。圖像樣本中對紅色成熟番茄果實與綠色未成熟果實兩種情況進行區(qū)分,同時也對不同果實數(shù)量、不同枝葉遮擋程度進行區(qū)分以增加樣本多樣性。圖3為夜間環(huán)境下番茄果實圖像。

圖1 夜間照明設(shè)備圖Fig.1 Night lighting diagram

圖3 夜間環(huán)境下番茄果實Fig.3 Effects of night environment on tomato fruit
為了保證數(shù)據(jù)參數(shù)的準確性,在數(shù)據(jù)訓(xùn)練前需要人工標注數(shù)據(jù),標注時將番茄各器官的最小外接矩形作為真實框,以此減少框內(nèi)背景上的無用像素。本研究的數(shù)據(jù)訓(xùn)練基于pytorch框架,使用線性增強技術(shù)降低出現(xiàn)樣本不均勻的概率,即在不改變原有數(shù)據(jù)特征的情況下對原有數(shù)據(jù)進行圖像處理,無需增加原始數(shù)據(jù)量,采用的數(shù)據(jù)增強手段主要有:①翻轉(zhuǎn)。對圖像進行90°翻轉(zhuǎn)、水平翻轉(zhuǎn)以及隨機(0°~180°)旋轉(zhuǎn),模擬檢測過程中圖像抓取的隨機性。②縮放。按照一定比例縮放圖像尺寸,模擬檢測過程中受距離影響的圖像尺寸不同。③顏色抖動。改變圖像的飽和度與亮度,模擬夜間環(huán)境下不同亮度差異。④添加噪聲。對數(shù)據(jù)圖像添加椒鹽噪聲和高斯噪聲,模擬拍攝過程中的噪聲,同時降低高頻特征防止出現(xiàn)過擬合現(xiàn)象。通過數(shù)據(jù)增強技術(shù)后得到新的數(shù)據(jù)樣本量,共計9 042幅。其中70%用于數(shù)據(jù)集訓(xùn)練,15%用于數(shù)據(jù)集驗證,15%用于數(shù)據(jù)集測試。
2 基于YOLO v5的番茄識別網(wǎng)絡(luò)
2.1 YOLO v5網(wǎng)絡(luò)模型
YOLO v5是一種單階段目標檢測算法,該算法在YOLO v4的基礎(chǔ)上添加了新的改進思路,使其速度與精度都得到極大的提升。YOLO v5網(wǎng)絡(luò)模型主要分為輸入端、Backbone基準網(wǎng)絡(luò)、Neck網(wǎng)絡(luò)、Head輸出端4部分。輸入端:包含一個圖像預(yù)處理階段,將輸入圖像縮放到網(wǎng)絡(luò)的輸入尺寸,并進行歸一化等操作,操作方法為Mosaic數(shù)據(jù)增強操作、自適應(yīng)錨框計算與自適應(yīng)圖像縮放方法。基準網(wǎng)絡(luò):通常是一些性能優(yōu)異的分類器的網(wǎng)絡(luò),該模塊用來提取一些通用的特征表示。YOLO v5同時使用了CSPDarknet53結(jié)構(gòu)與Focus結(jié)構(gòu)作為基準網(wǎng)絡(luò)。Neck網(wǎng)絡(luò):使用SPP模塊、FPN+PAN模塊位于基準網(wǎng)絡(luò)和頭網(wǎng)絡(luò)的中間位置,利用此兩個模塊進一步提升特征的多樣性及魯棒性。Head輸出端:用來完成目標檢測結(jié)果的輸出,包含一個分類分支和一個回歸分支,利用GIOU_Loss來代替Smooth L1 Loss函數(shù),增加了相交尺度的衡量,從而進一步提升算法的檢測精度。
2.2 多尺度特征提取
YOLO v5算法中使用Focus與CSPDarknet53特征提取網(wǎng)絡(luò)獲取多尺度圖像特征,相比前期版本進一步消除網(wǎng)格敏感性,提高對于遮擋物體特征信息的拾取,優(yōu)化小目標特征信息差異,提高識別精度。該算法首先以640像素×640像素的圖像為輸入進行切片操作,先變成320×320×12的特征圖,切片過程如圖4所示。
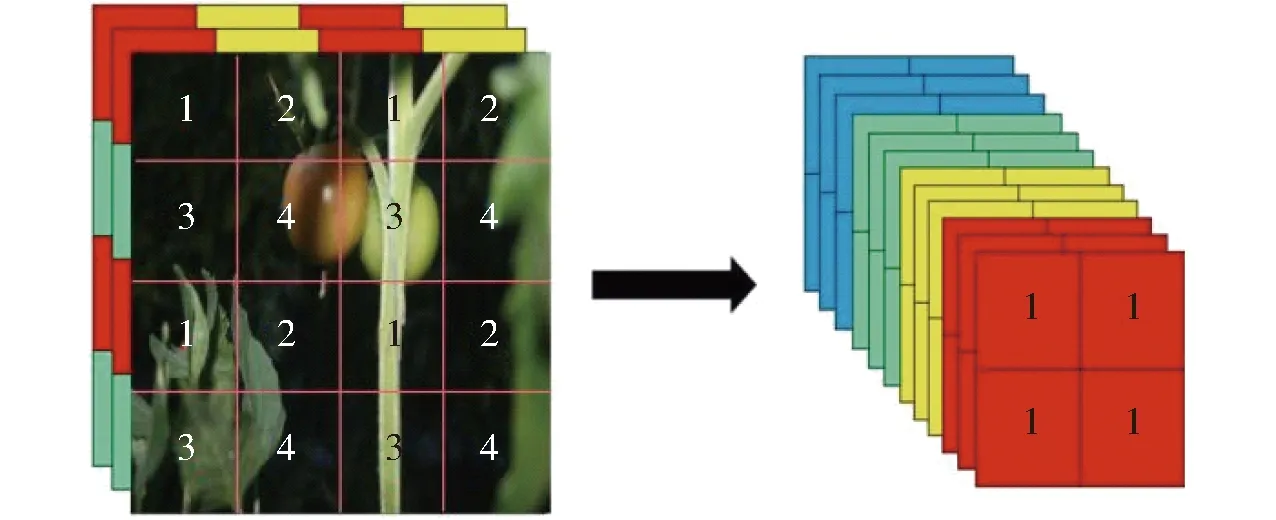
圖4 切片操作演示圖Fig.4 Slice operation demo
再經(jīng)過一次卷積操作,最終變成320×320×32的特征圖,該操作通過增加計算量來保證圖像特征信息不會丟失,將侯選框?qū)扺、侯選框高H的信息集中到通道上,使得特征提取得更加的充分。然后再分別進行32、16、8倍下采樣,獲得不同層次的特征圖,然后通過上采樣和張量拼接,將不同層次的特征圖融合轉(zhuǎn)化為維度相同的特征圖,如圖5所示。
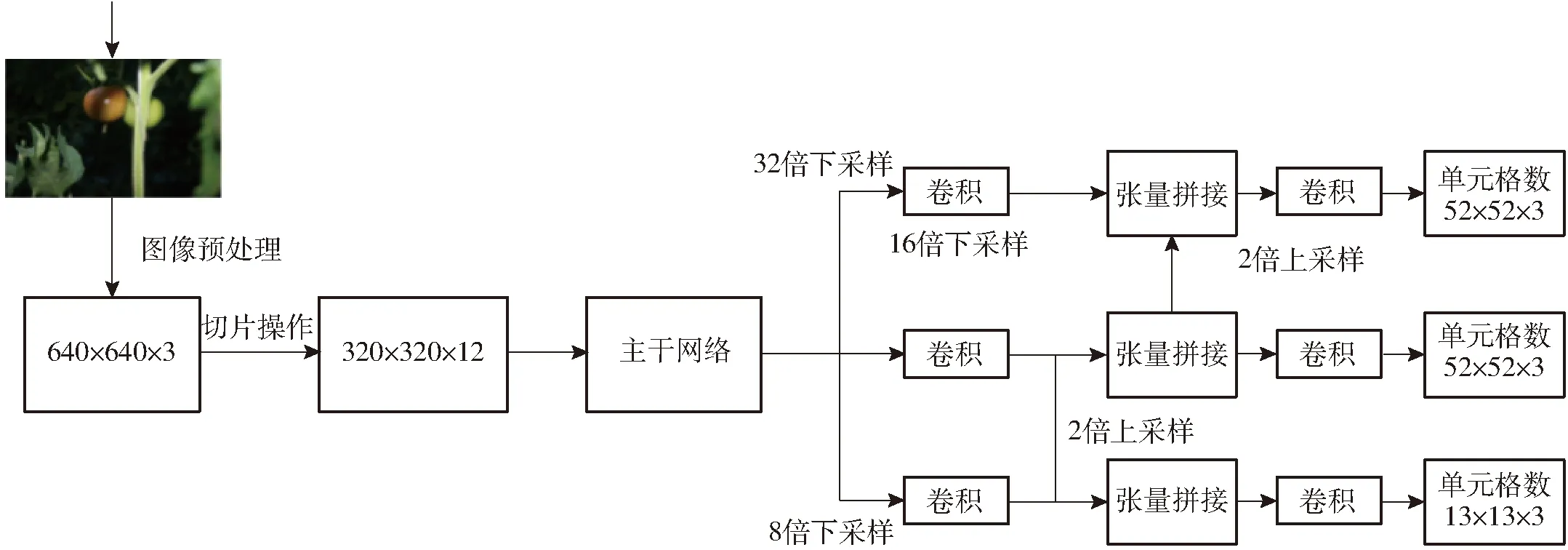
圖5 Darknet53特征流程圖Fig.5 Darknet53 feature flowchart
其解決了其他大型卷積神經(jīng)網(wǎng)絡(luò)框架Backbone中網(wǎng)絡(luò)優(yōu)化的梯度信息重復(fù)問題,將梯度的變化從頭到尾地集成到特征圖中,因此減少了模型的參數(shù)量和每秒浮點運算次數(shù)(FLOPS),既保證了推理速度和準確率,又減小了模型尺寸。鑒于本文檢測紅、綠兩種果實的不同目標,Darknet53特征提取最終分別輸出13像素×13像素、26像素×26像素、52像素×52像素3種尺度的特征圖,分別作為遠近景尺度視場內(nèi)各目標回歸檢測的依據(jù)。
2.3 自適應(yīng)錨定框
在YOLO v5中根據(jù)目標樣本邊框標注信息,采用K-means聚類算法預(yù)先設(shè)置先驗框進行回歸預(yù)測,并根據(jù)特征圖層次進行分配,但K-means聚類算法可能收斂至局部最小值,無法給出最優(yōu)解,對預(yù)測框造成誤差。因此對YOLO v5中錨定框計算方式進行改進。在原始COCO數(shù)據(jù)集中,針對不同特征大小的檢測框尺寸如表1所示。通過對原始檢測框的檢測效果分析表明,檢測框數(shù)據(jù)不協(xié)調(diào),候選檢測框長寬比達1∶8,不利于訓(xùn)練效果,影響真實框預(yù)測結(jié)果[21]。因此通過anchor計算函數(shù)進行機器學(xué)習(xí),迭代出每個步驟下的最優(yōu)檢測框尺寸,能夠有效抓取小目標特征值,減小真實檢測框偏離程度,并提高被遮擋物體的識別精度。重新計算檢測框尺寸,設(shè)置聚類數(shù)為9,anchor與bbox比值為8,迭代次數(shù)為1 000次,通過YOLO v5自動學(xué)習(xí)確定錨定框的最優(yōu)尺寸。

表1 原始數(shù)據(jù)集檢測框尺寸分配Tab.1 Size allocation of original data set detection frame
表2為數(shù)據(jù)集中縮放至一定水平的最佳錨定框尺寸,并用該尺寸替換原始COCO數(shù)據(jù)集中錨定框尺寸。

表2 改進后檢測框尺寸分配Tab.2 Improved size allocation of detection frame
2.4 損失函數(shù)改進
YOLO v5采用GIOU_Loss做Bounding box(目標位置)的損失函數(shù),使用二進制交叉熵和 Logits 損失函數(shù)計算類概率和目標得分的損失,計算公式為
(1)
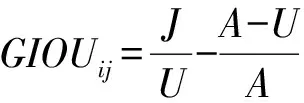
(2)
U=ii+ωihi-J
(3)
式中Losscoord——目標位置損失函數(shù)

J——邊框交集面積
U——邊框并集面積
A——邊框最小外接矩形面積
ωi、hi——預(yù)測框高與寬
S——真實框與預(yù)測框最小外接矩形面積
β——真實框與預(yù)測框并集區(qū)域面積
當預(yù)測框和真實框重合時,GIOU最大取1,反之,隨著二者距離的增大GIOU趨近于-1,即預(yù)測框與真實框距離越遠時損失值越大。但當預(yù)測框與真實框出現(xiàn)包含關(guān)系或出現(xiàn)寬和高對齊的情況時,差集為0,則損失函數(shù)不可導(dǎo),無法收斂,容易對遮擋情況下物體進行漏檢。因此本文采用考慮到預(yù)測框中心點歐氏距離和重疊率參數(shù)(CIOU)的損失函數(shù)作為預(yù)測框偏差的偏差指標[22],如圖6所示。圖中(ωgt,hgt)、(ω,h)分別表示預(yù)測框和真實框的高與寬,b、bgt分別表示預(yù)測框和真實框的中心點,ρ表示兩個中心點間的歐氏距離,c表示最小外接矩形框?qū)蔷€距離。則有
(4)
式中α——權(quán)重函數(shù)
ν——真實框與預(yù)測框矩形對角線傾斜角的差方
則目標函數(shù)改進為
(5)
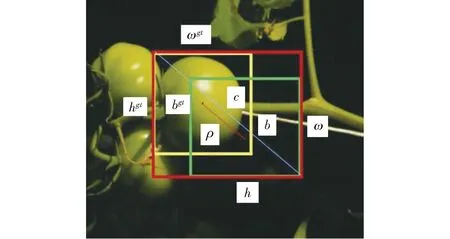
圖6 損失函數(shù)CIOU邊框圖Fig.6 Loss function CIOU border chart
該目標函數(shù)增加了中心點距離度量,可以直接最小化兩個目標框的距離,收斂速度大于GIOU損失函數(shù),且考慮到差異化情形,避免了真實框與預(yù)測框包含關(guān)系時的不收斂情況,能夠有效提高物體在遮擋情況下的識別率,優(yōu)化了邊框之間的相互關(guān)系。
3 網(wǎng)絡(luò)模型訓(xùn)練
3.1 算法運行環(huán)境與參數(shù)設(shè)置
檢測網(wǎng)絡(luò)算法在深度學(xué)習(xí)框架中運行,硬件環(huán)境為Intel i5-9560處理器,16GB DDR4 2 400 MHz運行內(nèi)存,顯卡為GeForce GTX 1050Ti。軟件環(huán)境為Windows 10操作系統(tǒng)下pytorch 1.8.1深度學(xué)習(xí)框架和CUDA 11.1并行計算構(gòu)架。
COCO和VOC數(shù)據(jù)集上的訓(xùn)練結(jié)果初始化YOLO v5的網(wǎng)絡(luò)參數(shù),參數(shù)訓(xùn)練采用SGD優(yōu)化算法,參數(shù)設(shè)置如下:圖像輸入尺寸為640像素×640像素,Batchsize為32;最大迭代次數(shù)為700;動量因子為0.9;權(quán)重衰減系數(shù)為0.000 5。采用余弦退火策略動態(tài)調(diào)整學(xué)習(xí)率,余弦退火超參數(shù)為0.1,初始學(xué)習(xí)率為0.001,采用CIOU Loss作為損失函數(shù)。
為了驗證本試驗方法的有效性,將改進YOLO v5、YOLO v5與CNN在數(shù)據(jù)集上進行試驗對比。
3.2 訓(xùn)練過程與結(jié)果
采用YOLO v5s檢測模塊,100次迭代周期中損失函數(shù)如圖7所示,前20次迭代周期中損失函數(shù)值明顯減小,后經(jīng)歷80次迭代損失函數(shù)值逐漸穩(wěn)定至0.03處小幅波動,則認為該檢測網(wǎng)絡(luò)模型穩(wěn)定收斂。經(jīng)過非極大值抑制(NMS)處理后得到的預(yù)測框分類中,將置信度大于閾值0.5的預(yù)測框定義為正樣本,反之為負樣本。
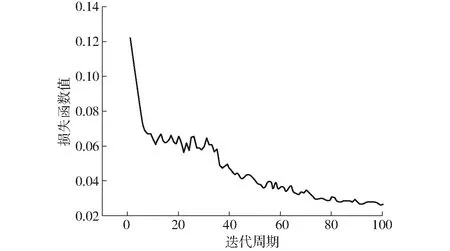
圖7 損失函數(shù)曲線Fig.7 Loss function curve
選用檢測網(wǎng)絡(luò)性能的指標包括平均精度MAP、綠色果與紅色果檢測精度APG與APR、準確率P、檢測時間t、召回率R及交并比(IOU)。主要衡量指標為平均精度MAP與檢測時間t,反映了檢測網(wǎng)絡(luò)的準確性與速度,準確率P為被預(yù)測為正的樣本中實際為正的樣本概率,召回率R為實際為正的樣本中被預(yù)測為正樣本的概率,交并比IOU為預(yù)測框與真實框的重合程度。為了對比改進后網(wǎng)絡(luò)模型的檢測效果,將改進YOLO v5、YOLO v5與CNN網(wǎng)絡(luò)模型進行比較。CNN網(wǎng)絡(luò)模型選擇Faster R-CNN網(wǎng)絡(luò)模型,對于任意尺寸的圖像,首先縮放至固定尺寸M×N,然后將圖像送入網(wǎng)絡(luò),池化層中包含了13個conv層+13個relu層+4個pooling層;RPN網(wǎng)絡(luò)首先經(jīng)過3×3卷積,再分別生成positive anchors和對應(yīng)bounding box regression偏移量,然后計算出proposal,而ROI Pooling層則利用proposals從feature maps中提取proposals feature送入后續(xù)全連接和softmax網(wǎng)絡(luò)做classification。Faster R-CNN網(wǎng)絡(luò)模型訓(xùn)練包含5個步驟:①在已經(jīng)訓(xùn)練好的model上,訓(xùn)練RPN網(wǎng)絡(luò)。②利用步驟①中訓(xùn)練的RPN網(wǎng)絡(luò),收集proposals。③訓(xùn)練Faster R-CNN網(wǎng)絡(luò)與RPN網(wǎng)絡(luò)。④再次利用步驟③中訓(xùn)練好的RPN網(wǎng)絡(luò),收集proposals。⑤第2次訓(xùn)練Faster R-CNN網(wǎng)絡(luò),得到結(jié)果。
在訓(xùn)練過程中,對各類圖像占比分兩組進行統(tǒng)計。其中第1組根據(jù)果實遮擋率進行劃分,果實遮擋率小于等于50%的圖像共6 473幅,占比69%;果實遮擋率大于50%的圖像共2 929幅,占比31%。第2組根據(jù)單果、多果進行劃分,單果圖像共4 012幅,占比43%;多果圖像共5 390幅,占比57%。訓(xùn)練集、驗證集、測試集檢測指標結(jié)果如表3所示。為還原真實場景中葉片對果實遮擋的情況,根據(jù)葉片對果實的遮擋率進行劃分,遮擋率計算方式為葉片遮擋果實部分的面積與果實總面積的比值。當遮擋率小于等于50%時,可認為葉片對果實的遮擋無影響,當遮擋率大于50%時認為葉片的遮擋對識別精度造成了影響,需要額外進行說明。
3種檢測結(jié)果如表4所示。由表4可知,YOLO v5的MAP為93.4%,改進YOLO v5模型MAP為96.7%,提高了3.3個百分點,檢測單幅圖像時間均為10 ms,可以看出改進YOLO v5模型魯棒性優(yōu)于YOLO v5。改進YOLO v5模型綠色果檢測精度和紅色果檢測精度分別較YOLO v5高0.5、1.0個百分點,可以看出改進YOLO v5模型因更換了損失函數(shù),對于遮擋番茄果實預(yù)測率提高,因此模型的平均精度有所提高。同時改進YOLO v5模型的交并比IOU比YOLO v5模型提高了1.8個百分點,由此可以看出,使用計算函數(shù)anchor重新計算檢測框尺寸并替換原有檢測框尺寸能夠有效提高交并比,提高檢測模型的魯棒性。

表3 訓(xùn)練集、驗證集、測試集檢測指標Tab.3 Test index results of training set, verification set and test set
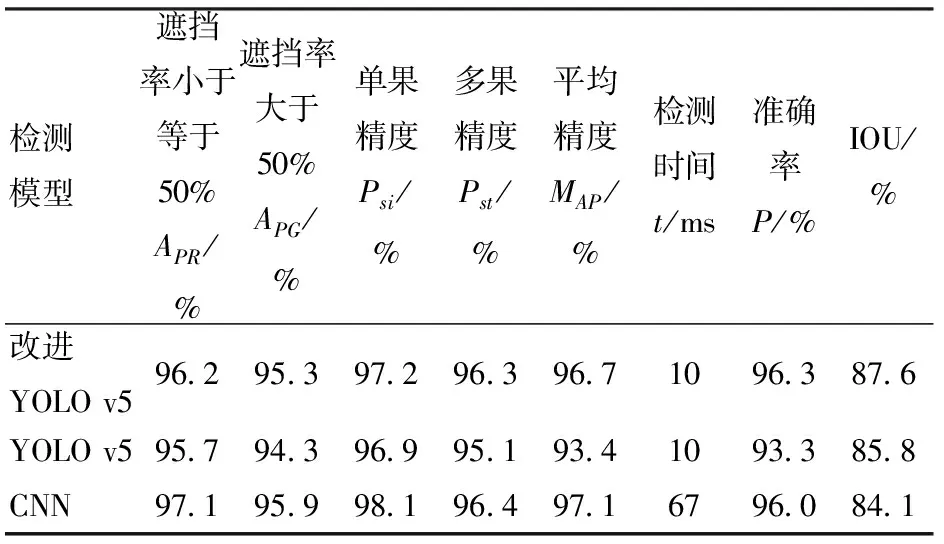
表4 3種模型各項檢測指標Tab.4 Results of all test indexes of three models
另外,雖改進YOLO v5模型的平均精度略低于CNN網(wǎng)絡(luò)模型,但改進YOLO v5的準確率與召回率均略高于CNN模型,果實遮擋率小于等于50%、果實遮擋率大于50%的差值與單果多果檢測精度的差值均小于CNN模型,且檢測時間為CNN模型的6.7倍,說明在保持準確率的情況下,改進YOLO v5模型的魯棒性與實時性均高于CNN網(wǎng)絡(luò)模型。又因為CNN模型的檢測框利用滑動檢測方式,因此交并比較改進YOLO v5低了3.5個百分點,說明改進YOLO v5對提取不同番茄果實特征信息與區(qū)分背景與目標信息的能力更為突出。
4 試驗
4.1 材料與方法
為驗證模型可靠性,2021年6月1日北京時間20:30于西北農(nóng)林科技大學(xué)北校區(qū)園藝場番茄日光溫室內(nèi)進行現(xiàn)場試驗,隨機挑選250個區(qū)域進行數(shù)據(jù)采集,利用改進YOLO v5模型與YOLO v5模型編譯的手機端應(yīng)用進行番茄檢測試驗。
試驗方法如下:①將兩種網(wǎng)絡(luò)模型的數(shù)據(jù)文件進行安卓端部署,生成手機檢測APP。②在日光溫室內(nèi)隨機挑選區(qū)域進行數(shù)據(jù)采集,為滿足隨機性,圖像數(shù)據(jù)包含遠近、遮擋等不同形態(tài)。③對采集數(shù)據(jù)進行人工識別,對不同顏色番茄果實,遮擋與未遮擋等特殊情況進行分類。④利用兩種網(wǎng)絡(luò)模型的手機應(yīng)用對采集的圖像數(shù)據(jù)進行識別,并與人工識別結(jié)果進行比對,分析模型精度。
4.2 YOLO v5安卓端部署
將YOLO v5模型訓(xùn)練后的Best.pt格式權(quán)重文件進行半精簡轉(zhuǎn)換為onnx格式文件,再將onnx文件使用騰訊NCNN平臺編譯為bin與param格式文件。利用Netron可視化工具對編譯后的文件進行修改,去除原模型文件中的切片操作。最后使用Android Studio工具將修改后的模型文件寫入Android系統(tǒng)生成應(yīng)用軟件。試驗采用手機型號為Oneplus 8t,系統(tǒng)版本為Android 11.0。
4.3 結(jié)果分析

圖8 2種模型手機應(yīng)用的夜間果實檢測效果Fig.8 Night fruit detection effects of two mobile phone models
為驗證實際檢測效果,使用改進YOLO v5與YOLO v5兩種模型訓(xùn)練后生成的手機應(yīng)用進行現(xiàn)場檢測,如圖8所示。并對檢測結(jié)果進行統(tǒng)計。以人工識別的番茄果實結(jié)果為參考,分別對兩種模型的檢測結(jié)果進行對比與分析評價。2個模型分別對番茄紅果、綠果的識別數(shù)量、識別總數(shù)量與人工識別數(shù)量的比值作為兩個模型番茄紅果、綠果的檢測精度。統(tǒng)計結(jié)果如表5所示。

表5 2種模型各項檢測指標
由表5可知,改進YOLO v5模型的番茄紅果與綠果的識別精度較YOLO v5模型分別提高了1.4、1.8個百分點,總識別精度提高了1.6個百分點,對于遮擋情況下或多果重疊情況下改進YOLO v5模型識別率優(yōu)于YOLO v5模型。為了驗證復(fù)雜環(huán)境下的模型檢測效果,對番茄綠果、紅果的單果、多果以及遮擋、未遮擋進行統(tǒng)計區(qū)分。選取各種情況下樣本數(shù)量50幅進行驗證,成功識別數(shù)量與樣本總量比值為識別率,結(jié)果如表6所示。由表6可以看出,在遮擋率不超過50%的情況下,番茄紅果與綠果的單果識別率均可達100%。由于番茄綠果在夜間環(huán)境下顏色容易與葉片、稈莖等混淆,多果在重疊情況下邊界條件區(qū)分較為困難,因此番茄綠果識別率及多果識別率略低于番茄紅果。
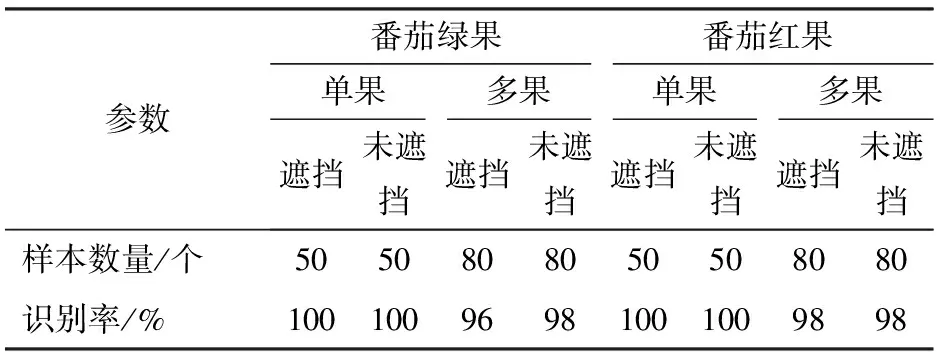
表6 復(fù)雜環(huán)境下番茄果實檢測結(jié)果Tab.6 Detection results of tomato fruit in complex environment
5 結(jié)論
(1)提出了基于改進YOLO v5的識別網(wǎng)絡(luò)模型對夜間環(huán)境下的番茄果實識別,使用計算函數(shù)anchor迭代出最優(yōu)檢測框代替原有方法,并修改原始數(shù)據(jù)中的目標檢測損失函數(shù),建立了夜間環(huán)境下番茄果實識別模型。改進YOLO v5的識別網(wǎng)絡(luò)模型識別精度得到改善,MAP為96.7%,較YOLO v5的MAP(93.4%)提高了3.3個百分點。
(2)為驗證模型的實際應(yīng)用性,利用改進YOLO v5模型訓(xùn)練后的權(quán)重文件制作手機端應(yīng)用軟件進行現(xiàn)場檢測。試驗表明,改進YOLO v5模型檢測精度較YOLO v5模型得到改善,針對夜間環(huán)境下綠色果實、紅色果實及總果實精度分別為96.2%、97.6%和96.8%。
(3)改進YOLO v5模型對于多果重疊、遮擋等復(fù)雜情況下的番茄果實識別有顯著的提升。在多果的遮擋情況下番茄綠果、紅果識別精度分別達96%、98%,相比于YOLO v5網(wǎng)絡(luò)模型魯棒性更優(yōu)。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
