深度半監(jiān)督學(xué)習(xí)中偽標(biāo)簽方法綜述
2022-06-17 07:10:34劉雅芬鄭藝峰江鈴燚李國和張文杰
計(jì)算機(jī)與生活 2022年6期
劉雅芬,鄭藝峰+,江鈴燚,李國和,張文杰
1.閩南師范大學(xué) 計(jì)算機(jī)學(xué)院,福建 漳州 363000
2.數(shù)據(jù)科學(xué)與智能應(yīng)用福建省高校重點(diǎn)實(shí)驗(yàn)室,福建 漳州 363000
3.中國石油大學(xué)(北京)信息科學(xué)與工程學(xué)院,北京 102249
隨著智能技術(shù)的發(fā)展,深度學(xué)習(xí)已得到學(xué)術(shù)界和工業(yè)界的廣泛關(guān)注,尤其在計(jì)算機(jī)視覺、圖像處理、自然語言處理和語音識別等領(lǐng)域。例如百度的無人駕駛、阿里的用戶行為分析等。
深度學(xué)習(xí)以數(shù)據(jù)為驅(qū)動,其優(yōu)異的性能離不開大量標(biāo)簽數(shù)據(jù)。然而,在現(xiàn)實(shí)生活中,標(biāo)簽數(shù)據(jù)獲取代價(jià)高昂。例如:在醫(yī)療任務(wù)中,標(biāo)簽均由領(lǐng)域?qū)<曳治龅贸觥O啾扔跇?biāo)簽數(shù)據(jù),無標(biāo)簽數(shù)據(jù)獲取相對容易,半監(jiān)督學(xué)習(xí)則將二者相結(jié)合用以訓(xùn)練模型。研究表明將少量有標(biāo)簽數(shù)據(jù)和大量無標(biāo)簽數(shù)據(jù)相結(jié)合有助于提高學(xué)習(xí)任務(wù)的準(zhǔn)確率。基于上述思想,研究人員將半監(jiān)督學(xué)習(xí)引入到深度學(xué)習(xí),提出深度半監(jiān)督學(xué)習(xí)。根據(jù)所采用半監(jiān)督損失函數(shù)和模型設(shè)計(jì)方式,深度半監(jiān)督學(xué)習(xí)方法可分為:生成式方法、一致性正則化方法、基于圖的方法、混合方法和偽標(biāo)簽方法。
(1)生成式方法:生成式方法學(xué)習(xí)數(shù)據(jù)的隱式特征,假設(shè)所有數(shù)據(jù)均來自同一潛在模型,以更好地將無標(biāo)簽數(shù)據(jù)與學(xué)習(xí)目標(biāo)關(guān)聯(lián)建模,并采用最大期望進(jìn)行求解。在標(biāo)簽數(shù)據(jù)極少時(shí),相比其他方法,能獲得較好的性能。其關(guān)鍵在于與真實(shí)分布吻合程度。
(2)一致性正則化方法:將無標(biāo)簽數(shù)據(jù)用以模型強(qiáng)化,即將一個(gè)實(shí)際的擾動應(yīng)用于一個(gè)無標(biāo)簽的數(shù)據(jù),亦不會使預(yù)測結(jié)果出現(xiàn)明顯變化。對于具有不同標(biāo)簽的數(shù)據(jù),在聚類假設(shè)中屬于低密度區(qū)域分離,因此,數(shù)據(jù)在擾動后標(biāo)簽發(fā)生變化的可能性微乎其微。由此可見,可將一致性正則化項(xiàng)作用于損失函數(shù),以指定假設(shè)的先驗(yàn)約束。
(3)基于圖的方法:在數(shù)據(jù)集上構(gòu)建圖,圖中每個(gè)節(jié)點(diǎn)表示一個(gè)訓(xùn)練數(shù)據(jù),每個(gè)邊緣表示節(jié)點(diǎn)對相似性。可分為圖正則化和圖嵌入兩種。圖正則化使用Laplacian 正則化,假設(shè)具有強(qiáng)連接邊緣的節(jié)點(diǎn)可能共享相同的標(biāo)簽,例如標(biāo)簽傳播(label propagation)、高斯隨機(jī)場(Gaussian random fields)和局部全局一致性(local and global consistency)。圖嵌入則是將節(jié)點(diǎn)編碼為向量,用于度量節(jié)點(diǎn)之間的相似性。
(4)混合方法:融合偽標(biāo)簽、偽一致性正則化和熵最小化的思想用以提高模型性能。此外還引入一種混合物學(xué)習(xí)原理,即一種簡單的、數(shù)據(jù)不可知的數(shù)據(jù)增強(qiáng)方法,一個(gè)配對的數(shù)據(jù)及其各自標(biāo)簽的凸組合。
大部分深度半監(jiān)督學(xué)習(xí)方法不足之處在于過分依賴特定區(qū)域的數(shù)據(jù)增強(qiáng),然而在大多數(shù)應(yīng)用場景下,數(shù)據(jù)增強(qiáng)并不容易生成,而其中偽標(biāo)簽方法卻不受數(shù)據(jù)增強(qiáng)的約束。現(xiàn)階段為無標(biāo)簽數(shù)據(jù)標(biāo)注偽標(biāo)簽的方法則大多先利用標(biāo)簽數(shù)據(jù)訓(xùn)練模型,而后將偽標(biāo)簽數(shù)據(jù)與標(biāo)簽數(shù)據(jù)相結(jié)合擴(kuò)大數(shù)據(jù)集,共同訓(xùn)練模型。可見,偽標(biāo)簽方法的性能主要依賴于所選擇的模型。偽標(biāo)簽方法可分成自訓(xùn)練和多視角訓(xùn)練兩大部分,自訓(xùn)練通過獲得無標(biāo)簽數(shù)據(jù)的偽標(biāo)簽從而得到更多訓(xùn)練數(shù)據(jù)。多視角訓(xùn)練是通過訓(xùn)練多個(gè)模型,利用模型間的“分歧”給無標(biāo)簽數(shù)據(jù)打上偽標(biāo)簽。而Zhu 于2002 年提出的標(biāo)簽傳播算法,無需依賴于任何的分類模型,將圖和偽標(biāo)簽相結(jié)合,利用樣本間的關(guān)系建立圖模型,通過相似度給無標(biāo)簽節(jié)點(diǎn)標(biāo)記標(biāo)簽。其具備易于實(shí)現(xiàn)且復(fù)雜度較低的特點(diǎn),已被廣泛應(yīng)用于虛擬社區(qū)挖掘等領(lǐng)域。
在本文中,首先,對深度半監(jiān)督學(xué)習(xí)進(jìn)行分析;其次,從自訓(xùn)練和多視角訓(xùn)練兩方面對偽標(biāo)簽方法進(jìn)行詳細(xì)的剖析;然后,著重闡述利用相似性且無需預(yù)訓(xùn)練的基于圖和偽標(biāo)簽的標(biāo)簽傳播方法,并討論其優(yōu)勢所在;接著,對已有的偽標(biāo)簽方法進(jìn)行實(shí)驗(yàn)分析的比對;最后,從無標(biāo)簽數(shù)據(jù)在實(shí)際應(yīng)用中是否適用于所有模型、真實(shí)數(shù)據(jù)集帶有噪聲數(shù)據(jù)、數(shù)據(jù)采樣的合理性以及偽標(biāo)簽方法和其他方法結(jié)合的情況總結(jié)偽標(biāo)簽方法所面臨的問題和未來研究方向。
1 深度半監(jiān)督學(xué)習(xí)
深度學(xué)習(xí)以數(shù)據(jù)為驅(qū)動,而獲取大量的標(biāo)簽數(shù)據(jù)代價(jià)昂貴。深度半監(jiān)督學(xué)習(xí)可通過少量標(biāo)簽數(shù)據(jù)和大量無標(biāo)簽數(shù)據(jù)構(gòu)建模型,其無標(biāo)簽信息能提供更多關(guān)于數(shù)據(jù)分布的信息,從而更好地估計(jì)不同類別的決策邊,有助于提高模型的性能。
近年來,隨著智能信息技術(shù)的推廣,機(jī)器學(xué)習(xí)方法得到廣泛的研究,其主要分為:監(jiān)督學(xué)習(xí)(supervised learning)、無監(jiān)督學(xué)習(xí)(unsupervised learning)和半監(jiān)督學(xué)習(xí)(semi-supervised learning)。
半監(jiān)督學(xué)習(xí)介于監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)二者之間,其基本思想是利用無標(biāo)簽數(shù)據(jù)提高模型的泛化能力,以減少對外界交互的過分依賴,從而訓(xùn)練更好的模型。三者之間對比如圖1 所示。從圖中可以看出,在半監(jiān)督學(xué)習(xí)中,同時(shí)提供標(biāo)簽數(shù)據(jù)集D={(,),(,),…,(x,y)} 和無標(biāo)簽數(shù)據(jù)集D={x,x,…,x},且無標(biāo)簽數(shù)據(jù)數(shù)量遠(yuǎn)遠(yuǎn)多于標(biāo)簽數(shù)據(jù),即?。更具體地說,半監(jiān)督學(xué)習(xí)的目標(biāo)是利用無標(biāo)簽數(shù)據(jù)集D輔助生成預(yù)測函數(shù)f,比僅使用標(biāo)簽數(shù)據(jù)集D所獲得的函數(shù)更準(zhǔn)確。
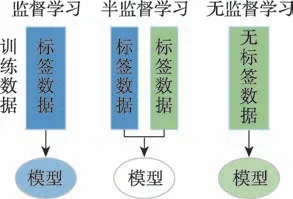
圖1 監(jiān)督學(xué)習(xí)、半監(jiān)督學(xué)習(xí)、無監(jiān)督學(xué)習(xí)結(jié)構(gòu)對比Fig.1 Structure comparison of supervised learning,semi-supervised learning and unsupervised learning
隨著智能應(yīng)用的普及,數(shù)據(jù)量急劇增加,數(shù)據(jù)標(biāo)注標(biāo)簽信息代價(jià)昂貴。例如:在進(jìn)行醫(yī)學(xué)影像分析時(shí),雖可獲得大量的醫(yī)院影像,但對影像中的病灶進(jìn)行標(biāo)注則需要由醫(yī)學(xué)專家才能進(jìn)行標(biāo)注。同樣,在進(jìn)行商品推薦時(shí),僅有少部分的用戶愿意協(xié)助對商品進(jìn)行標(biāo)注。由此可見,半監(jiān)督學(xué)習(xí)具有較高的應(yīng)用價(jià)值。
如何有效利用無標(biāo)簽數(shù)據(jù)成為亟需解決的問題。無標(biāo)簽數(shù)據(jù)因其與標(biāo)簽數(shù)據(jù)從相同的數(shù)據(jù)源獨(dú)立分布采樣而來,雖未包含標(biāo)簽信息,但其分布的信息有助于模型的構(gòu)建。本文給出一個(gè)直觀的示例,如圖2所示,圖中包含一個(gè)正方形類和一個(gè)三角形類,待判別樣本恰好位于兩者之間,則在進(jìn)行樣本類別判斷時(shí)僅能依靠隨機(jī)猜測。倘若能觀察到圖中的無標(biāo)簽數(shù)據(jù)分布狀況,則可將此待判別樣本歸為正方形類。由此可見,無標(biāo)簽數(shù)據(jù)可提供關(guān)于數(shù)據(jù)分布結(jié)構(gòu)的額外信息,有助于更好地估計(jì)不同類別之間的決策邊界。
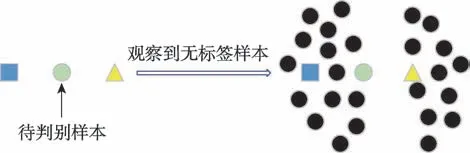
圖2 無標(biāo)簽數(shù)據(jù)效用示例(黑點(diǎn)為無標(biāo)簽數(shù)據(jù))Fig.2 Unlabeled data utility example(black dots indicate unlabeled data)
最早將無標(biāo)簽數(shù)據(jù)應(yīng)用到半監(jiān)督學(xué)習(xí)中的方法是Self-training 方法,該方法使用有標(biāo)簽數(shù)據(jù)構(gòu)建模型,進(jìn)而對無標(biāo)簽數(shù)據(jù)進(jìn)行預(yù)測,從中篩選出預(yù)測置信度高的樣本加入標(biāo)簽數(shù)據(jù)集中,不斷更新模型,直至收斂。然而要有效利用無標(biāo)簽數(shù)據(jù),則必須對無標(biāo)簽樣本所揭示的數(shù)據(jù)分布信息與類別標(biāo)簽之間的關(guān)系進(jìn)行假設(shè)。目前,可分為聚類假設(shè)(cluster assumption)、平滑假設(shè)(smoothing assumption)和流行假設(shè)(manifold assumption)。
(1)聚類假設(shè):當(dāng)兩個(gè)數(shù)據(jù)屬于同一簇時(shí),則擁有相同的類標(biāo)簽,即當(dāng)數(shù)據(jù)和位于同一簇時(shí),和的預(yù)測結(jié)果應(yīng)一致。聚類假設(shè)亦稱為低密度分離假設(shè),即決策邊界應(yīng)位于低密度區(qū)域。
(2)平滑假設(shè):指位于稠密數(shù)據(jù)區(qū)域的兩個(gè)距離相近的數(shù)據(jù)具有相同的標(biāo)簽,即對于稠密區(qū)域中的兩個(gè)數(shù)據(jù),如果其存在邊連接,則具有相同的標(biāo)簽信息,反之亦然。這個(gè)假設(shè)在分類任務(wù)中很有幫助,但對回歸任務(wù)沒有多大的幫助。
(3)流行假設(shè):將高維數(shù)據(jù)嵌入到低維流形中,如兩個(gè)數(shù)據(jù)在低維流形中同屬于一個(gè)局部鄰域,則其應(yīng)具有相似的類信息,其著重于模型的局部特性。在該假設(shè)下,無標(biāo)簽數(shù)據(jù)就能使數(shù)據(jù)空間更加密集,有助于分析局部區(qū)域特征信息,從而使決策函數(shù)較好地?cái)M合數(shù)據(jù)。
綜上所述,上述三類假設(shè)雖然實(shí)現(xiàn)的方式不同,但其本質(zhì)都是考慮樣本的相似性。
近年來,深度學(xué)習(xí)在實(shí)際應(yīng)用中取得優(yōu)異的表現(xiàn),但其以數(shù)據(jù)為驅(qū)動,需要大量標(biāo)簽樣本用以訓(xùn)練模型。然而,在現(xiàn)實(shí)生活中,對樣本進(jìn)行標(biāo)注代價(jià)高昂。為此,研究人員將半監(jiān)督學(xué)習(xí)引入到深度學(xué)習(xí)中,提出深度半監(jiān)督學(xué)習(xí)。
在早期的方法中標(biāo)簽數(shù)據(jù)和無標(biāo)簽數(shù)據(jù)分開使用,先利用無標(biāo)簽數(shù)據(jù)進(jìn)行初始化,再利用標(biāo)簽數(shù)據(jù)對模型進(jìn)行調(diào)整,其本質(zhì)上仍是監(jiān)督學(xué)習(xí)的模式。在半監(jiān)督模式下,神經(jīng)網(wǎng)絡(luò)則應(yīng)同時(shí)訓(xùn)練有標(biāo)簽和無標(biāo)簽樣本,其損失函數(shù)的范式定義如下:

其中,表示為監(jiān)督損失,表示為無監(jiān)督損失,()為權(quán)重。不同的深度半監(jiān)督方法區(qū)別在于所采用的的不同。
2 偽標(biāo)簽
現(xiàn)階段,以一致性正規(guī)化方法為主的深度半監(jiān)督學(xué)習(xí)由于過分依賴特定區(qū)域的數(shù)據(jù)增強(qiáng),不易實(shí)現(xiàn)。為此Lee 提出偽標(biāo)簽方法,標(biāo)簽數(shù)據(jù)和無標(biāo)簽數(shù)據(jù)同時(shí)參與模型的訓(xùn)練。對于無標(biāo)簽數(shù)據(jù),在每次權(quán)重更新時(shí),為每個(gè)無標(biāo)簽數(shù)據(jù)賦予具有最大預(yù)測概率的標(biāo)簽,再將標(biāo)注后的無標(biāo)簽數(shù)據(jù)放入標(biāo)簽數(shù)據(jù)集用以模型訓(xùn)練。本章將從自訓(xùn)練和多視角訓(xùn)練兩方面對偽標(biāo)簽方法進(jìn)行詳細(xì)的剖析。
2.1 自訓(xùn)練
自訓(xùn)練是基于最可信預(yù)測以此標(biāo)記無標(biāo)簽數(shù)據(jù),根據(jù)模型自身生成偽標(biāo)簽,可分為熵最小化方法、代理標(biāo)簽方法、噪聲學(xué)生模型方法、自半監(jiān)督方法和元偽標(biāo)簽方法。首先,使用少量的標(biāo)簽數(shù)據(jù)D來訓(xùn)練預(yù)測模型f,再使用f為無標(biāo)簽數(shù)據(jù)x∈D分配偽標(biāo)簽。如果模型預(yù)測概率高于預(yù)定的閾值,則將數(shù)據(jù)(,argmax f())添加到標(biāo)簽數(shù)據(jù)集中,繼續(xù)訓(xùn)練模型,為D-{x}中的數(shù)據(jù)標(biāo)記偽標(biāo)簽,重復(fù)上述過程,直至模型無法產(chǎn)生最可信預(yù)測或所有的無標(biāo)簽數(shù)據(jù)都標(biāo)注偽標(biāo)簽。在實(shí)際訓(xùn)練過程中,可采用相對置信度決定為哪些無標(biāo)簽數(shù)據(jù)標(biāo)記偽標(biāo)簽,即在每次訓(xùn)練后對前個(gè)高置信度預(yù)測的無標(biāo)簽樣本進(jìn)行標(biāo)記,并添加至標(biāo)簽數(shù)據(jù)集D中。Yalniz 等人將自訓(xùn)練方法用以訓(xùn)練ResNet-50 模型,先在帶有偽標(biāo)簽的無標(biāo)簽圖像上進(jìn)行訓(xùn)練,再對標(biāo)簽圖像進(jìn)行微調(diào),實(shí)驗(yàn)結(jié)果表明自訓(xùn)練方法進(jìn)一步提高訓(xùn)練模型的魯棒性。
熵最小化方法(entropy minimization)是一種熵正則化的方法,其通過鼓勵(lì)模型對無標(biāo)簽數(shù)據(jù)進(jìn)行低熵預(yù)測,再將其應(yīng)用到監(jiān)督學(xué)習(xí)中以實(shí)現(xiàn)半監(jiān)督學(xué)習(xí)。理論分析表明熵最小化有助于阻止決策邊界通過高密度的數(shù)據(jù)點(diǎn)區(qū)域,如無法阻止則將對無標(biāo)簽的數(shù)據(jù)產(chǎn)生低置信度的預(yù)測。
給定圖像數(shù)據(jù)∈,令()表示特定神經(jīng)輸出函數(shù),將所有概率分布P的熵(P)最小化,上述方法僅精確神經(jīng)網(wǎng)絡(luò)的預(yù)測,無法單獨(dú)使用。如果將其作為損失,則會導(dǎo)致預(yù)測退化。Grandvalet 和Bengio 考慮從標(biāo)簽和無標(biāo)簽的數(shù)據(jù)中學(xué)習(xí)決策規(guī)則,并使熵最小化方法規(guī)范化。熵最小化方法可作用于任何特定的或限制最低熵規(guī)范的模型。當(dāng)生成模型被錯(cuò)誤指定時(shí),熵最小化方法更有助于實(shí)現(xiàn)最低熵規(guī)范化。最新研究表明,熵最小化方法本身并不能產(chǎn)生有競爭力的結(jié)果,但當(dāng)與不同的方法結(jié)合時(shí),可以產(chǎn)生最先進(jìn)的結(jié)果。
代理標(biāo)簽是一種估計(jì)無標(biāo)簽數(shù)據(jù)為偽標(biāo)簽的最簡單方法,目標(biāo)是生成代理標(biāo)簽用以增強(qiáng)學(xué)習(xí)。代理標(biāo)簽同時(shí)將標(biāo)簽數(shù)據(jù)和無標(biāo)簽數(shù)據(jù)以監(jiān)督方式進(jìn)行訓(xùn)練,如圖3 所示。
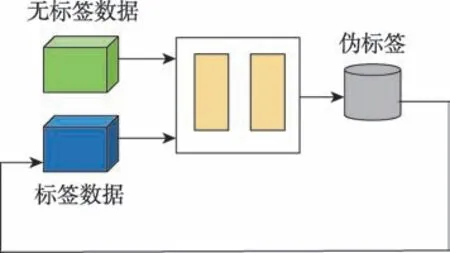
圖3 代理標(biāo)簽?zāi)P虵ig.3 Proxy-label model
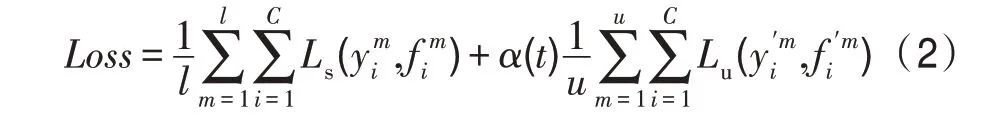
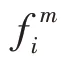
Shi 等試圖確定其最優(yōu)標(biāo)簽和最優(yōu)模型參數(shù),并通過迭代訓(xùn)練最小化損失函數(shù)。Iscen 等人將代理標(biāo)簽方法用于標(biāo)簽傳播,在標(biāo)簽數(shù)據(jù)和偽標(biāo)簽數(shù)據(jù)上交替訓(xùn)練網(wǎng)絡(luò)模型,同時(shí)引入兩個(gè)不確定性參數(shù),即每一個(gè)樣本基于輸出概率的熵(用以克服對預(yù)測的不平等置信度問題)和基于每個(gè)類得分的類種群(用以處理類的不平衡問題)。Arazo 等人則認(rèn)為由于存在確認(rèn)偏差,從而導(dǎo)致單純的偽標(biāo)簽會過度擬合于不正確的偽標(biāo)簽。同時(shí)證明采用混合方式并設(shè)置每批的最少標(biāo)簽樣本數(shù)量有助于減少上述偏差。
噪聲學(xué)生模型(noisy student)方法受知識蒸餾思想啟發(fā),基于“教師-學(xué)生”框架,如圖4 所示。其具體過程:首先采用教師EfficientNet模型對標(biāo)簽數(shù)據(jù)進(jìn)行訓(xùn)練,為無標(biāo)簽數(shù)據(jù)生成偽標(biāo)簽,加入標(biāo)簽數(shù)據(jù)集;再采用規(guī)模更大的EfficientNet 模型作為學(xué)生模型,在新數(shù)據(jù)集上進(jìn)行訓(xùn)練。同時(shí),可在學(xué)生模型訓(xùn)練階段加入Dropout 和Stochastic Depth 等模型噪聲。經(jīng)多次迭代,獲更具有魯棒性的學(xué)生模型,此時(shí)學(xué)生模型可作為教師模型,重新標(biāo)注無標(biāo)簽數(shù)據(jù)。
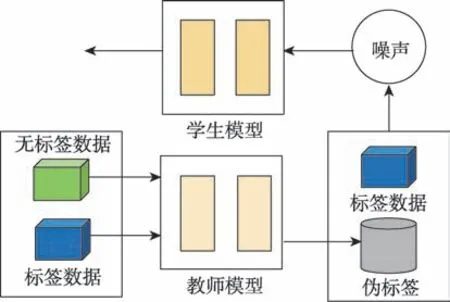
圖4 噪聲學(xué)生模型Fig.4 Noisy student model
Liu 等人將噪聲學(xué)生模型法用于探索藥物代謝作用,可進(jìn)一步加速藥物發(fā)現(xiàn)過程,從而降低成本。Kumar 等人也采用噪聲學(xué)生模型方法進(jìn)行面部表情的識別,模型隔離面部的不同區(qū)域,并使用多級注意機(jī)制獨(dú)立進(jìn)行處理。其結(jié)果表明,與其他單一模型相比,該方法更加有助于提升模型的性能。
自半監(jiān)督學(xué)習(xí)(self-supervised semi-supervised learning)將自監(jiān)督學(xué)習(xí)技術(shù)用以解決半監(jiān)督圖像分類的問題。在自半監(jiān)督學(xué)習(xí)方法中,有四個(gè)旋轉(zhuǎn)度{0°,90°,180°,270°},用以旋轉(zhuǎn)輸入圖像,其旋轉(zhuǎn)損失為旋轉(zhuǎn)圖像預(yù)測輸出的交叉熵?fù)p失。對于無標(biāo)簽數(shù)據(jù),預(yù)測其不同的旋轉(zhuǎn)角度打上偽標(biāo)簽,后與標(biāo)簽數(shù)據(jù)共同訓(xùn)練模型,如圖5 所示。
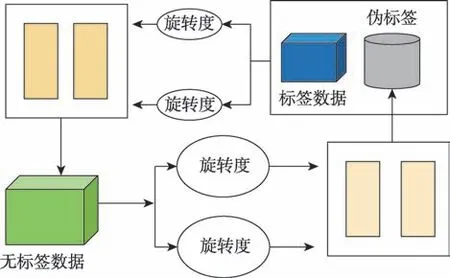
圖5 自半監(jiān)督學(xué)習(xí)模型Fig.5 Self-supervised semi-supervised learning model
Beyer 等人將損失分成有監(jiān)督損失和無監(jiān)督損失兩部分,其中監(jiān)督損失為交叉熵?fù)p失,而無監(jiān)督損失是基于自監(jiān)督技術(shù)的旋轉(zhuǎn)和樣本預(yù)測的損失。同時(shí),提出兩種半監(jiān)督圖像分類方法,有助于解決圖像分類的半監(jiān)督問題。
在半監(jiān)督學(xué)習(xí)過程中,偽標(biāo)簽通常是由教師模型生成,不能有效適應(yīng)網(wǎng)絡(luò)訓(xùn)練的學(xué)習(xí)狀態(tài)。為此,Pham 等人提出元偽標(biāo)簽(meta pseudo labels)方法,采用“學(xué)生-教師”框架,如圖6 所示。在該框架中,教師模型使用元學(xué)習(xí)方法生成代理標(biāo)簽,并鼓勵(lì)教師模型以改進(jìn)學(xué)生模型學(xué)習(xí)的方式從而調(diào)整訓(xùn)練的目標(biāo)分布,再通過評估學(xué)生模型用以更新教師模型。雖然允許教師模型調(diào)整和適應(yīng)學(xué)生的學(xué)習(xí)狀態(tài),但不足以訓(xùn)練教師模型。為了克服上述問題,在教師模型中,還需使用驗(yàn)證集對標(biāo)簽數(shù)據(jù)進(jìn)行訓(xùn)練。
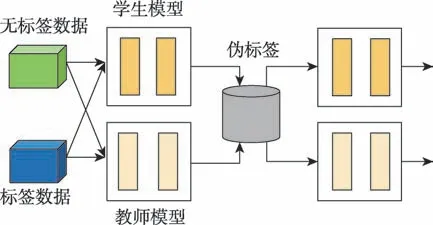
圖6 元偽標(biāo)簽?zāi)P虵ig.6 Meta pseudo labels model
Pham 等在CIFAR-10、SVHN 和ImageNet 實(shí)驗(yàn)更進(jìn)一步證明MPL方法的有效性。此外,在CIFAR10和ImageNet上附加額外的無標(biāo)簽數(shù)據(jù),并使用Efficient-Net 進(jìn)行訓(xùn)練。實(shí)驗(yàn)結(jié)果表明,采用元偽標(biāo)簽方法在CIFAR-10 上獲得88.6%的準(zhǔn)確率,在ImageNet 上獲得86.9%的top-1 準(zhǔn)確率。
自訓(xùn)練具備簡單性和通用性,可廣泛應(yīng)用于各個(gè)領(lǐng)域。例如,圖像分類、語義分割和目標(biāo)對象檢測等任務(wù)。但其不足之處在于,無法糾正其自身錯(cuò)誤(即任何錯(cuò)誤的分類都會被迅速放大)。而多視角訓(xùn)練在理想情況下,不同的視角可相互補(bǔ)充、相互協(xié)作,進(jìn)而提高彼此的性能。
2.2 多視角訓(xùn)練
多視角訓(xùn)練亦稱為基于分歧的模型訓(xùn)練,根據(jù)不同數(shù)據(jù)視角訓(xùn)練的模型生成偽標(biāo)簽,可分為協(xié)同訓(xùn)練方法和三體訓(xùn)練方法。與自訓(xùn)練不同之處在于,其數(shù)據(jù)存在多個(gè)視角,例如圖像的顏色信息和紋理信息。多視角訓(xùn)練的基本思想是同時(shí)訓(xùn)練多個(gè)學(xué)習(xí)模型,分別用以標(biāo)記無標(biāo)簽的樣本。
協(xié)同訓(xùn)練方法(co-training)是指在兩個(gè)視角上訓(xùn)練不同的分類模型,即在標(biāo)簽數(shù)據(jù)上分別訓(xùn)練兩個(gè)預(yù)測函數(shù)f和f,如圖7所示。在每次迭代過程中,將f標(biāo)記的無標(biāo)簽數(shù)據(jù)添加到f中,彼此交換,重復(fù)此過程,直至無標(biāo)簽數(shù)據(jù)耗盡或滿足最大迭代次數(shù)。
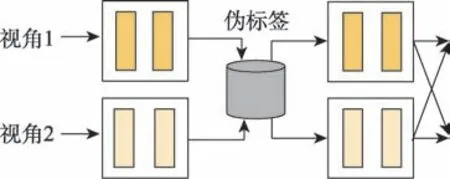
圖7 協(xié)同訓(xùn)練模型Fig.7 Co-training model
具體過程描述如下:令()和()表示兩個(gè)不同的數(shù)據(jù)視圖,使得=(,)。假設(shè)為在上訓(xùn)練的分類模型,表示在上訓(xùn)練的分類模型,在目標(biāo)函數(shù)中,協(xié)同訓(xùn)練方法假設(shè)定義如下:
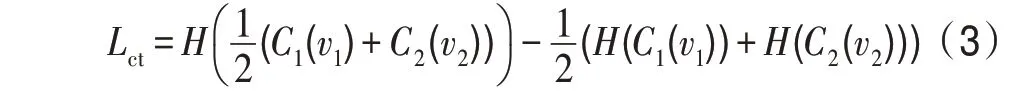
其中,(·)表示熵。
在標(biāo)簽數(shù)據(jù)集上,標(biāo)準(zhǔn)的交叉熵?fù)p失可定義為:
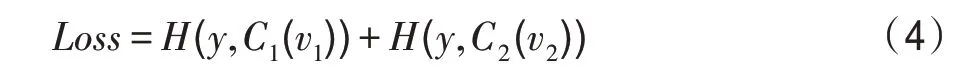
其中,(,)表示和之間的交叉熵。
對于協(xié)同訓(xùn)練模型,關(guān)鍵在于其兩種視角是不同且互補(bǔ)的,但損失函數(shù)和L僅確保模型對于數(shù)據(jù)集上的預(yù)測趨于一致。為了解決此問題,可在協(xié)同訓(xùn)練模型強(qiáng)制引入視角差異約束。
Tran 等人提出協(xié)同訓(xùn)練半監(jiān)督回歸和自適應(yīng)算法,利用不同的視角增加輸入數(shù)據(jù)量,并結(jié)合互相關(guān)等技術(shù)用于基于可見光的指紋技術(shù)定位。實(shí)驗(yàn)結(jié)果表明,隨著輸入數(shù)據(jù)量的增加,模型的定位精度隨著增高。Díaz 等人提出一種使用深度神經(jīng)網(wǎng)絡(luò)的視覺對象識別的聯(lián)合訓(xùn)練模型,通過添加多層自我監(jiān)督神經(jīng)網(wǎng)絡(luò)作為視圖的中間輸入,視圖會因其輸出的交叉熵正則化而呈現(xiàn)多樣化。該模型綜合考慮輸出的差異性,將協(xié)同訓(xùn)練和自我監(jiān)督學(xué)習(xí)相結(jié)合,可稱為差分自我監(jiān)督共同訓(xùn)練(different self-supervised co-training)。結(jié)果表明,該方法雖然簡單,但有助于提高模型的精度。
三體訓(xùn)練(tri-training)試圖克服多個(gè)視角存在的數(shù)據(jù)缺乏問題,從三個(gè)不同的訓(xùn)練集(均通過自助抽樣法得到)中訓(xùn)練三個(gè)分類模型,有助于減少自我訓(xùn)練中產(chǎn)生的預(yù)測偏差,如圖8 所示。其基本思想:首先利用標(biāo)簽數(shù)據(jù)集訓(xùn)練三個(gè)預(yù)測函數(shù)f、f和f。令表示無標(biāo)簽數(shù)據(jù),若其在f和f上預(yù)測結(jié)果一致,則認(rèn)為偽標(biāo)簽自信且穩(wěn)定。此時(shí),將標(biāo)記好的添加到f的標(biāo)簽數(shù)據(jù)集中,再對其進(jìn)行微調(diào)。如果無數(shù)據(jù)點(diǎn)再被添加到任何模型的訓(xùn)練集中,則訓(xùn)練停止。在整個(gè)增強(qiáng)過程中,三個(gè)模型會變得越來越相似。因此,需分別在訓(xùn)練集上進(jìn)行微調(diào),以確保模型多樣性。根據(jù)所采用的框架不同,三體訓(xùn)練可分為多任務(wù)三體訓(xùn)練(multi-task tri-training)和交叉視圖訓(xùn)練(cross-view training)。
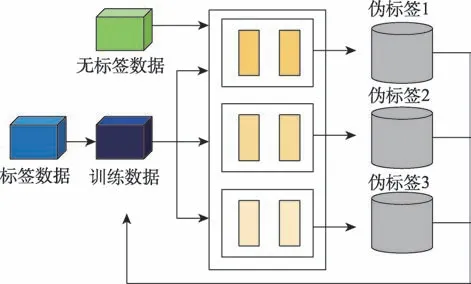
圖8 三體訓(xùn)練模型Fig.8 Tri-training model
(1)多任務(wù)三體訓(xùn)練:使用神經(jīng)網(wǎng)絡(luò)的三體訓(xùn)練代價(jià)昂貴,需要對三個(gè)模型中的所有無標(biāo)簽進(jìn)行預(yù)測。為了緩解上述問題,Ruder 和Plank將遷移學(xué)習(xí)思想引入半監(jiān)督學(xué)習(xí)中,提出多任務(wù)三體訓(xùn)練方法,三個(gè)模型與特定于模型的分類層共享相同的特征提取器,將模型與一個(gè)額外的正交約束聯(lián)合訓(xùn)練,從而進(jìn)一步減少時(shí)間和空間復(fù)雜度。多任務(wù)三體訓(xùn)練不再單獨(dú)訓(xùn)練模型,而是采用共享參數(shù),并用多任務(wù)學(xué)習(xí)機(jī)制進(jìn)行聯(lián)合訓(xùn)練。需要注意的是,由于模型作用相同,其屬于偽多任務(wù)學(xué)習(xí)。
(2)交叉視圖訓(xùn)練:Clark 等人結(jié)合多視角學(xué)習(xí)和一致性訓(xùn)練,提出交叉視圖訓(xùn)練,對于不同的輸入視圖能獲得一致的預(yù)測輸出。其基本思想是采用共享編碼器,再添加輔助預(yù)測模塊,將編碼器表示轉(zhuǎn)換為預(yù)測輸出。可將上述模塊分為輔助學(xué)生模塊和初級教師模塊,二者具有一致的預(yù)測。學(xué)生預(yù)測模塊可以從教師模塊的預(yù)測中學(xué)習(xí),既提高編碼器產(chǎn)生表示的質(zhì)量,也有助于改進(jìn)使用相同共享表示的完整模型。
在車輛識別中,不同視點(diǎn)下車輛的視覺外觀會發(fā)生顯著變化。為此,Yang 等人提出弱監(jiān)督交叉視圖學(xué)習(xí)模塊,用于車輛的重識別,僅通過基于車輛入侵檢測系統(tǒng)最小化交叉視角特征距離,而不使用任何視角標(biāo)注來學(xué)習(xí)一致的特征表示。該模型在VeRi-776、VehicleID、VRIC 和VRAI 數(shù)據(jù)集上均獲得顯著的性能改進(jìn)。
3 標(biāo)簽傳播
基于偽標(biāo)簽的深度半監(jiān)督學(xué)習(xí)方法均需使用標(biāo)簽數(shù)據(jù)訓(xùn)練模型,繼而標(biāo)注無標(biāo)簽數(shù)據(jù),其算法復(fù)雜度較高。而將偽標(biāo)簽方法與基于圖的方法相結(jié)合可解決訓(xùn)練模型復(fù)雜度高和數(shù)據(jù)分布形狀局限的問題。本章主要介紹標(biāo)簽傳播方法,即為二者相結(jié)合的深度半監(jiān)督學(xué)習(xí)方法,其滿足聚類假設(shè)和流行假設(shè),即同一簇和同一流行中的數(shù)據(jù)可能共享相同的標(biāo)簽,利用簇的結(jié)構(gòu)和節(jié)點(diǎn)間的相似性,將標(biāo)簽數(shù)據(jù)標(biāo)簽傳播給無標(biāo)簽數(shù)據(jù),具有運(yùn)算簡單和復(fù)雜度小的特點(diǎn)。
3.1 基于圖的半監(jiān)督學(xué)習(xí)
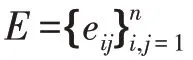
周志華認(rèn)為基于圖形的半監(jiān)督學(xué)習(xí)概念清晰,且易通過對所涉矩陣運(yùn)算的分析來闡述其性質(zhì)。其不足之處在于存儲開銷成本較大。此外,在圖構(gòu)建過程僅依賴于訓(xùn)練樣本集,對于新數(shù)據(jù)樣本,難以判斷其在圖中的位置。Yi 等人建立了一種自適應(yīng)的基于圖的標(biāo)簽傳播模型,解決了非負(fù)矩陣分解不能充分利用標(biāo)簽信息的弱點(diǎn),采用局部約束來反映數(shù)據(jù)的局部結(jié)構(gòu),迭代優(yōu)化算法求解目標(biāo)函數(shù)。實(shí)驗(yàn)結(jié)果表明,該框架具有優(yōu)異的性能。
3.2 基于圖和偽標(biāo)簽的標(biāo)簽傳播
標(biāo)簽傳播主要假設(shè)是流行假設(shè),即屬于同一流形中的數(shù)據(jù)樣本很可能共享相同的語義標(biāo)簽。為此,標(biāo)簽傳播根據(jù)數(shù)據(jù)流形結(jié)構(gòu)和中間節(jié)點(diǎn)相似性,將標(biāo)簽數(shù)據(jù)的標(biāo)簽傳播給無標(biāo)簽數(shù)據(jù)。
首先,根據(jù)給定數(shù)據(jù)構(gòu)建圖,若假設(shè)圖為完全圖,則節(jié)點(diǎn)x和x邊的權(quán)重可表示為:

其中,是超參數(shù)。
標(biāo)簽傳播算法通過相鄰節(jié)點(diǎn)之間傳播標(biāo)簽,若節(jié)點(diǎn)間的權(quán)重越大,則表示其相似程度越高,標(biāo)簽越容易傳播。為此,概率轉(zhuǎn)移矩陣可定義為:
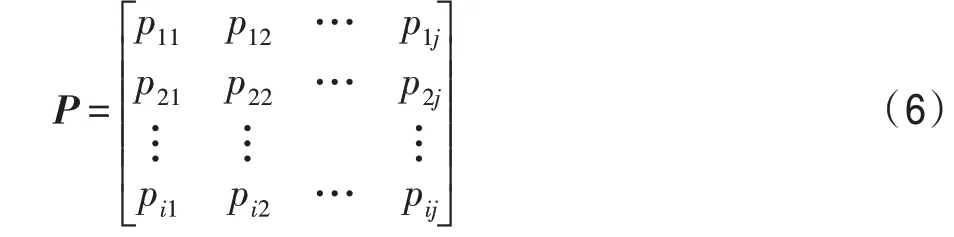
其中,p表示從節(jié)點(diǎn)x轉(zhuǎn)移到節(jié)點(diǎn)x的概率。
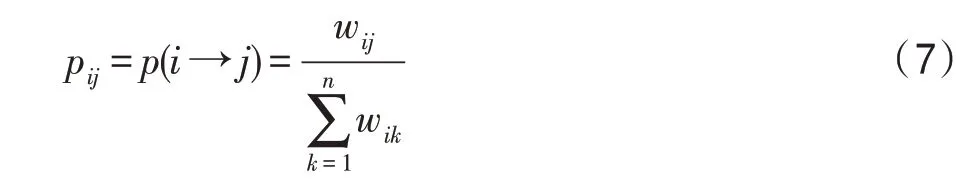
假設(shè)數(shù)據(jù)集中有個(gè)類和個(gè)標(biāo)簽樣本,則定義一個(gè)×的標(biāo)簽數(shù)據(jù)矩陣F:

其第行表示第個(gè)樣本的標(biāo)簽指示向量,即若第個(gè)樣本的類別為Y,則第個(gè)元素為1,其他為0。
為了便于說明,將上述標(biāo)簽數(shù)據(jù)矩陣表示為F=[,,…,f]。
同樣對于個(gè)無標(biāo)簽樣本定義一個(gè)×無標(biāo)簽數(shù)據(jù)矩陣F:
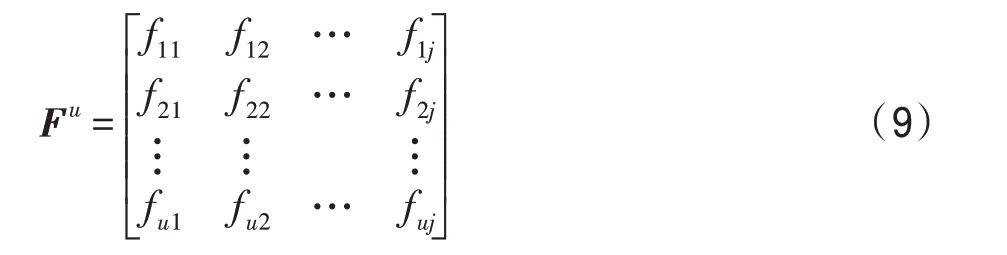
值得注意,其數(shù)值初始可進(jìn)行[0,1]之間隨機(jī)初始化。為了便于說明,將上述無標(biāo)簽數(shù)據(jù)矩陣表示為F=[f,f,…,f]。
將F和F合并得到標(biāo)簽向量矩陣=[F:F]。
標(biāo)簽傳播算法的具體過程如下:
(1)執(zhí)行傳播=;
(2)重置中前行標(biāo)簽樣本的標(biāo)簽F=F;
(3)重復(fù)步驟(1)、(2)直至收斂。
上述過程中,步驟(1)表示將矩陣和矩陣相乘,即對于每個(gè)節(jié)點(diǎn)按傳播概率將其周圍節(jié)點(diǎn)傳播的標(biāo)注值按權(quán)重相加,并更新自身的概率分布。兩個(gè)節(jié)點(diǎn)越相似(在歐式空間中距離越近),則對方的偽標(biāo)簽會越容易受影響。對于步驟(2),由于標(biāo)簽數(shù)據(jù)的標(biāo)簽是事先確定的,在每次傳播后,需要回歸其初始標(biāo)簽。隨著標(biāo)簽數(shù)據(jù)不斷將其標(biāo)簽傳播出去,最后的類邊界會穿越高密度區(qū)域,而停留在低密度的間隔中。
在每次迭代過程中,需對=[F:F]進(jìn)行計(jì)算,由于F已知,且需要重新恢復(fù)初始值,F是最終結(jié)果,于是可將矩陣表示如下:

F計(jì)算方式可表示為:

重復(fù)此步驟直至收斂。
近年來,社交媒體已廣泛應(yīng)用于各個(gè)領(lǐng)域,影響最大化(influence maximization,IM)已成為社會網(wǎng)絡(luò)分析研究的熱點(diǎn)問題之一。Kumar 等人提出一種基于節(jié)點(diǎn)播種、標(biāo)簽傳播和社團(tuán)檢測的影響最大化算法,其使用擴(kuò)展h 指數(shù)中心性檢測種子節(jié)點(diǎn),再使用標(biāo)簽傳播技術(shù)檢測群落。經(jīng)典的標(biāo)簽傳播方法不足之處在于無法有效地聯(lián)合節(jié)點(diǎn)屬性和標(biāo)簽,且在大規(guī)模圖上收斂速度較慢。為解決上述問題,Xie 等提出一種基于圖結(jié)構(gòu)數(shù)據(jù)的可伸縮半監(jiān)督節(jié)點(diǎn)分類方法(簡稱為GraphHop),其使用適當(dāng)?shù)某跏紭?biāo)簽嵌入向量。模型主要包括:標(biāo)簽聚合和標(biāo)簽更新。在標(biāo)簽聚合過程中,每個(gè)節(jié)點(diǎn)將前一次迭代得到的相鄰節(jié)點(diǎn)的標(biāo)簽向量進(jìn)行聚合;在標(biāo)簽更新過程中,利用鄰域信息,根據(jù)節(jié)點(diǎn)本身的標(biāo)簽和其所得到的聚合標(biāo)簽信息,為每個(gè)節(jié)點(diǎn)預(yù)測新的標(biāo)簽向量。實(shí)驗(yàn)結(jié)果表明,GraphHop 在各種規(guī)模的圖表中均能取得較好的結(jié)果。王俊斌對標(biāo)簽傳播算法進(jìn)行擴(kuò)展,提出基于成對約束的標(biāo)簽傳播算法,將先驗(yàn)信息保存到成對關(guān)系矩陣中,并采用成對關(guān)系與聚類結(jié)果之間的差異來代替劃分矩陣之間的差異。同時(shí),通過構(gòu)建一種新的最優(yōu)化模型,將標(biāo)簽傳播算法的最優(yōu)化問題轉(zhuǎn)化為譜聚類問題,并通過特征值分解方法進(jìn)行求解。
4 實(shí)驗(yàn)分析
本章將介紹各類半監(jiān)督偽標(biāo)簽方法所采用的數(shù)據(jù)集,同時(shí)對各種偽標(biāo)簽方法進(jìn)行實(shí)驗(yàn)分析對比。
4.1 實(shí)驗(yàn)數(shù)據(jù)集介紹
在實(shí)驗(yàn)分析過程中,本文主要采用UCI(University of California,Irvine)數(shù)據(jù)集和圖像數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)比對。UCI 數(shù)據(jù)集主要包括Iris、Cmc(contraceptive method choice)和Iono(Ionosphere),數(shù)據(jù)集信息如表1 所示。在實(shí)驗(yàn)過程中,為了保證實(shí)驗(yàn)結(jié)果的有效性,需對每個(gè)數(shù)據(jù)集進(jìn)行歸一化處理,并劃分訓(xùn)練集和驗(yàn)證集。在進(jìn)行半監(jiān)督訓(xùn)練時(shí),標(biāo)簽數(shù)據(jù)占訓(xùn)練集的10%,采取分層抽樣的方式對每個(gè)類別進(jìn)行采樣。
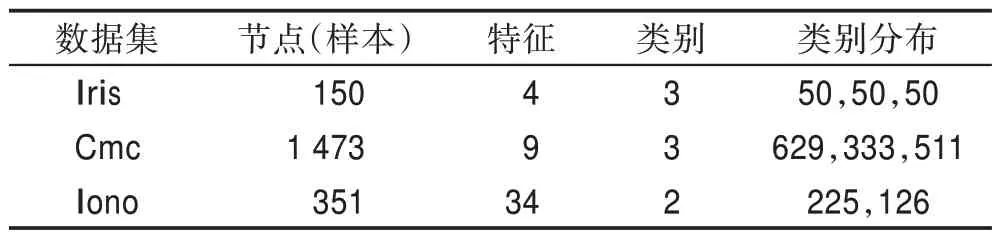
表1 實(shí)驗(yàn)中使用的UCI數(shù)據(jù)集Table 1 UCI datasets used in experiment
圖像數(shù)據(jù)集主要包括ILSVRC-2012(多用于自訓(xùn)練)、CIFAR-10(多用于多視角訓(xùn)練)和CIFAR-100(多用于多視角訓(xùn)練)。
ILSVRC-2012 是ImageNet 的子集,包含1 000 個(gè)圖像類別,其中訓(xùn)練集包含120 萬張圖像,驗(yàn)證集和測試集共包含15 萬張圖像。由于類別的數(shù)量較多,通常會將精確度設(shè)置為Top-1 和Top-5。Top-1 準(zhǔn)確度是指一個(gè)預(yù)測與一個(gè)真實(shí)標(biāo)簽相比較的經(jīng)典準(zhǔn)確度,而Top-5 準(zhǔn)確性則是檢查一個(gè)基本真實(shí)標(biāo)簽是否在一組最多5 個(gè)預(yù)測中。本文實(shí)驗(yàn)過程中所給出的結(jié)果為僅使用10%的標(biāo)簽進(jìn)行訓(xùn)練的Top-1 準(zhǔn)確度。
CIFAR-10 和CIFAR-100 是大小為32×32 的彩色自然圖像大型數(shù)據(jù)集,其中CIFAR-10 包含10 個(gè)類別,CIFAR-100 包含100 個(gè)類別。均使用5 萬張圖像用于訓(xùn)練,1 萬張圖像用于測試。本文實(shí)驗(yàn)過程中,對于CIFAR-10,使用從訓(xùn)練集中隨機(jī)選擇的4 000 張圖像作為標(biāo)簽數(shù)據(jù),其余的圖像作為無標(biāo)簽數(shù)據(jù);對于CIFAR-100,則是隨機(jī)挑選10 000 張圖像作為標(biāo)簽數(shù)據(jù),其余的圖像作為無標(biāo)簽數(shù)據(jù)。
4.2 實(shí)驗(yàn)結(jié)果分析
為了對已有的偽標(biāo)簽方法進(jìn)行分析,本文分別在圖像數(shù)據(jù)集和UCI數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),具體結(jié)果分別如表2 和表3 所示。其中圖像數(shù)據(jù)集CIARF-10 和CIFAR-100 還未在自訓(xùn)練模型實(shí)驗(yàn)中大規(guī)模投入使用。因此,為保證實(shí)驗(yàn)的公平性,自訓(xùn)練模型仍然以ILSVRC-2012 為主。
表2 主要描述圖像數(shù)據(jù)集中不同方法的實(shí)驗(yàn)結(jié)果,其中自半監(jiān)督模型在不同數(shù)據(jù)集上均取得最高的準(zhǔn)確率。自半監(jiān)督模型為混合模型,將自監(jiān)督旋轉(zhuǎn)預(yù)測、VAT(virtual adversarial training)、交叉熵?fù)p失和fine-tuning 結(jié)合到一個(gè)具有多個(gè)訓(xùn)練步驟的單一模型中。此外,其將損失函數(shù)分為有監(jiān)督和無監(jiān)督的部分,其監(jiān)督損失為交叉熵?fù)p失,而無監(jiān)督損失則采用旋轉(zhuǎn)和范例的自監(jiān)督技術(shù)。由此可見,基于偽標(biāo)簽半監(jiān)督學(xué)習(xí)方法仍然有著很大的進(jìn)步空間。此外,從實(shí)驗(yàn)結(jié)果不難發(fā)現(xiàn),隨著數(shù)據(jù)樣本的類別增多,模型的不確定程度逐漸增大,精確率隨之下降。在相同的數(shù)據(jù)集上,三體訓(xùn)練方法效果也都優(yōu)于協(xié)同訓(xùn)練方法,因三體訓(xùn)練方法同時(shí)使用半監(jiān)督學(xué)習(xí)和集成學(xué)習(xí)機(jī)制,進(jìn)一步提升學(xué)習(xí)性能。綜上所述,隨著基于偽標(biāo)簽半監(jiān)督學(xué)習(xí)方法的發(fā)展,模型的識別準(zhǔn)確率逐漸提高。而隨著所使用的架構(gòu)復(fù)雜程度增加,可以預(yù)測模型精度亦會隨著時(shí)間的推移而提高。
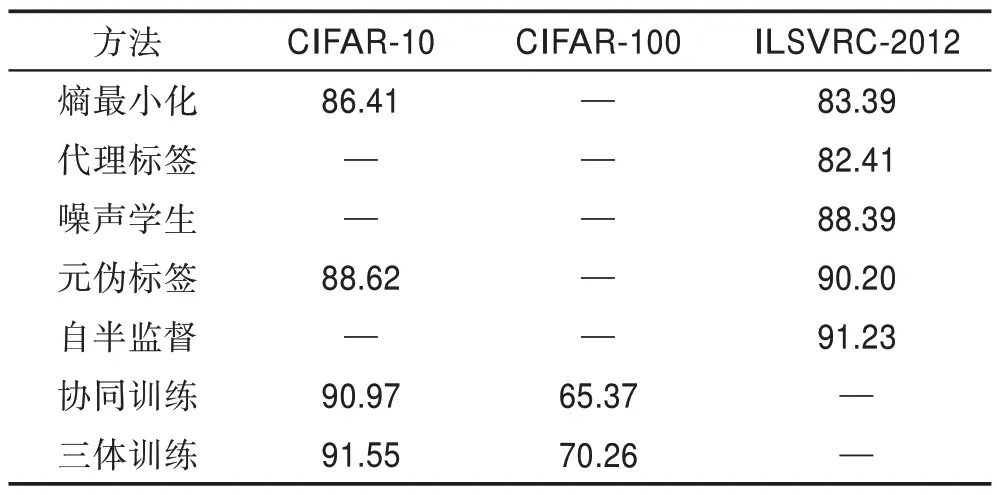
表2 偽標(biāo)簽方法在不同圖像數(shù)據(jù)集上實(shí)驗(yàn)結(jié)果Table 2 Experimental results of pseudo-labeling method on different image datasets %
表3 主要描述在3 個(gè)不同的UCI 數(shù)據(jù)集中,協(xié)同訓(xùn)練、三體訓(xùn)練和標(biāo)簽傳播方法在kNN(nearest neighborhood)上的實(shí)驗(yàn)效果(=10)。為了更好地挑揀出結(jié)果的差異,采用十折交叉驗(yàn)證方式。從結(jié)果可以看出,標(biāo)簽傳播方法優(yōu)于前兩者。模型的訓(xùn)練與數(shù)據(jù)的分布情況直接有關(guān),標(biāo)簽傳播主要假設(shè)是流行假設(shè)(即屬于同一流形中的數(shù)據(jù)樣本很可能共享相同的語義標(biāo)簽),可獲得更好的實(shí)驗(yàn)結(jié)果。協(xié)同訓(xùn)練要求數(shù)據(jù)能夠從不同的角度提取出兩份不同的數(shù)據(jù),即使用同一份數(shù)據(jù)構(gòu)造出兩個(gè)分類器,然而現(xiàn)實(shí)的數(shù)據(jù)大多缺乏多個(gè)視角。而三體訓(xùn)練能有效解決協(xié)同訓(xùn)練缺乏視角的問題,相比協(xié)同訓(xùn)練,其在UCI 數(shù)據(jù)集和圖像數(shù)據(jù)集上均表現(xiàn)出更好的性能。但需要注意的是,基于圖的標(biāo)簽傳播無法有效地聯(lián)合節(jié)點(diǎn)屬性并且具有很強(qiáng)的隨機(jī)性從而導(dǎo)致結(jié)果不穩(wěn)定。在后續(xù)的工作中,可對此進(jìn)行研究。
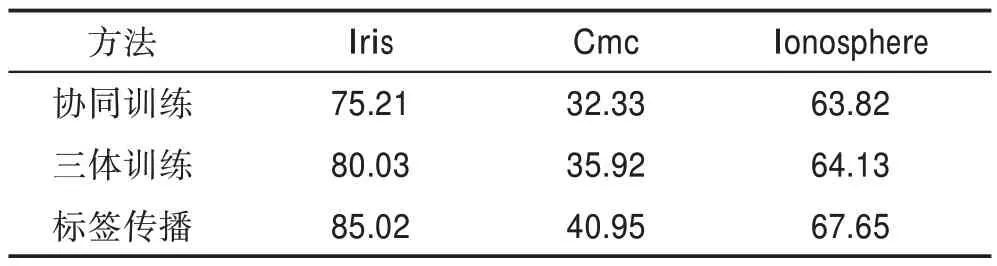
表3 偽標(biāo)簽方法在不同UCI數(shù)據(jù)集上實(shí)驗(yàn)結(jié)果Table 3 Experimental results of pseudo-labeling method on different UCI datasets %
5 問題與挑戰(zhàn)
盡管基于偽標(biāo)簽的深度半監(jiān)督學(xué)習(xí)已取得有效的進(jìn)展,但仍存在有待研究的開放研究問題。
(1)無標(biāo)簽數(shù)據(jù)效用性:在半監(jiān)督學(xué)習(xí)中,人們普遍認(rèn)為無標(biāo)簽數(shù)據(jù)可以提高學(xué)習(xí)性能,特別是在標(biāo)簽數(shù)據(jù)稀缺的情況下。值得注意的是,無標(biāo)簽數(shù)據(jù)可以提高學(xué)習(xí)性能是在適當(dāng)?shù)募僭O(shè)或條件下,一些研究表明,使用無標(biāo)簽的數(shù)據(jù)可能導(dǎo)致性能退化。現(xiàn)有的基于偽標(biāo)簽的深度半監(jiān)督方法主要使用無標(biāo)簽數(shù)據(jù)來生成約束,然后與標(biāo)簽數(shù)據(jù)共同更新模型。一般情況下,使用權(quán)衡因子用于平衡監(jiān)督和無監(jiān)督的損失,即所有無標(biāo)簽數(shù)據(jù)等權(quán)。然而,并非所有的無標(biāo)簽數(shù)據(jù)在實(shí)際應(yīng)用中都同樣適用于該模型。此時(shí),需考慮無標(biāo)簽數(shù)據(jù)的權(quán)重問題。
(2)噪聲數(shù)據(jù):本文所提到的標(biāo)簽數(shù)據(jù)均認(rèn)為是準(zhǔn)確的,從而可以學(xué)習(xí)標(biāo)準(zhǔn)的交叉熵?fù)p失函數(shù)。然而現(xiàn)實(shí)生活中得到的標(biāo)簽數(shù)據(jù)可能帶有噪聲,在訓(xùn)練時(shí)只能訓(xùn)練帶有噪聲的數(shù)據(jù)集。在基于圖的半監(jiān)督學(xué)習(xí)中,為增強(qiáng)數(shù)據(jù)預(yù)測的一致性,引入一種由稀疏編碼實(shí)現(xiàn)的L范數(shù)形式的Laplacian 正則化。從記憶效應(yīng)的角度提出了一種協(xié)同訓(xùn)練和平均教師相結(jié)合的學(xué)習(xí)范式。還可對數(shù)據(jù)進(jìn)行預(yù)處理,降低噪聲數(shù)據(jù)帶來的損失。
(3)合理性:在標(biāo)簽傳播方法中,目前大多采用有放回的取樣方式,使得樣本在下次采樣時(shí)仍然有可能被抽取到,這面臨的問題是有時(shí)取到的樣本集不能代表整體,從而降低其合理性,通過計(jì)算可得約有36.8%的樣本未出現(xiàn)在采集數(shù)據(jù)集中。在之后的工作中,可對群優(yōu)化進(jìn)行研究,群優(yōu)化的核心價(jià)值在于研究和探索“個(gè)體與總體之間的沖突和求得一致結(jié)果的條件”,進(jìn)而提升數(shù)據(jù)采樣的合理性。
(4)方法的結(jié)合:在調(diào)查過程中發(fā)現(xiàn),一些平常的方法與偽標(biāo)簽方法結(jié)合在一起會顯示出超乎預(yù)期的效果,第3 章有相應(yīng)的介紹。然而,目前只有少數(shù)方法與偽標(biāo)簽方法相結(jié)合,而合理的組合策略有助于進(jìn)一步提高模型的性能,因此,不同思想的相結(jié)合的融合策略是一個(gè)值得探索的未來研究領(lǐng)域。
6 結(jié)束語
本文首先介紹深度半監(jiān)督學(xué)習(xí),可根據(jù)半監(jiān)督損失函數(shù)和模型中最顯著的特征,將其分為生成式方法、一致性正則化方法、基于圖的方法、偽標(biāo)簽方法和混合方法。本文以偽標(biāo)簽方法作為切入點(diǎn)展開詳細(xì)的敘述,該方法旨在標(biāo)簽數(shù)據(jù)上訓(xùn)練模型,用以預(yù)測無標(biāo)簽數(shù)據(jù)的類別(即偽標(biāo)簽),再將新生成的偽標(biāo)簽數(shù)據(jù)擴(kuò)充訓(xùn)練數(shù)據(jù)。針對偽標(biāo)簽方法需預(yù)訓(xùn)練模型這一問題展開討論,引入基于圖的標(biāo)簽傳播方法,即無需經(jīng)過預(yù)訓(xùn)練模型就可得到偽標(biāo)簽。此外,本文進(jìn)一步闡述標(biāo)簽傳播方法的基本思想,其利用數(shù)據(jù)的分布及其內(nèi)在關(guān)系(即樣本間的相似關(guān)系),用以標(biāo)記無標(biāo)簽數(shù)據(jù)。最后,本文對偽標(biāo)簽學(xué)習(xí)研究過程中所存在的問題進(jìn)行總結(jié),并提出未來的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
人大建設(shè)(2020年4期)2020-09-21 03:39:12
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
人大建設(shè)(2017年2期)2017-07-21 10:59:25
人大建設(shè)(2017年9期)2017-02-03 02:53:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
