醫(yī)學(xué)知識(shí)推理研究現(xiàn)狀與發(fā)展
2022-06-17 07:10:26董文波孫仕亮殷敏智
計(jì)算機(jī)與生活 2022年6期
關(guān)鍵詞:模型
董文波,孫仕亮+,殷敏智
1.華東師范大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,上海 200062
2.上海交通大學(xué)醫(yī)學(xué)院 附屬上海兒童醫(yī)學(xué)中心病理科,上海 200127
2012 年,谷歌首次推出了知識(shí)圖譜,并利用它來提高查詢結(jié)果的相關(guān)性和用戶的檢索體驗(yàn),為用戶提供了更加精確化和智能化的搜索服務(wù)。知識(shí)圖譜以網(wǎng)狀的結(jié)構(gòu)、三元組的知識(shí)組成形式來顯式表示現(xiàn)實(shí)世界中的知識(shí),更加簡(jiǎn)潔直觀,靈活豐富。目前,不同領(lǐng)域內(nèi)已經(jīng)創(chuàng)建了很多大型知識(shí)圖譜庫(knowledge bases,KB),如DBpedia、Freebase和Yago等。這些知識(shí)圖譜庫是由大量的事實(shí)以三元組(頭實(shí)體,關(guān)系,尾實(shí)體)形式構(gòu)成的。其中,頭實(shí)體和尾實(shí)體用圖譜中的節(jié)點(diǎn)表示,關(guān)系由圖譜中節(jié)點(diǎn)之間的連接邊表示。每一個(gè)三元組表達(dá)了現(xiàn)實(shí)物理世界中的一條知識(shí)或事實(shí)。最近幾年,伴隨人工智能的快步發(fā)展,知識(shí)圖譜逐漸成為了知識(shí)服務(wù)領(lǐng)域中一個(gè)新的研究熱點(diǎn),受到國(guó)內(nèi)外學(xué)者和工業(yè)界的聚焦與關(guān)注,已經(jīng)發(fā)展成為支撐眾多人工智能應(yīng)用的核心,比如智能化精準(zhǔn)搜索、自動(dòng)問答、推薦系統(tǒng)和決策支持等。
在醫(yī)學(xué)領(lǐng)域,得益于信息化技術(shù)的快速發(fā)展和醫(yī)療信息系統(tǒng)的普及,醫(yī)學(xué)數(shù)據(jù)庫中積淀了海量的醫(yī)學(xué)知識(shí)和臨床診斷數(shù)據(jù),如果能從這些數(shù)據(jù)中提煉出知識(shí),同時(shí)對(duì)其管理和合理利用,是推進(jìn)醫(yī)學(xué)智能化和自動(dòng)化的關(guān)鍵。同時(shí),也能夠?yàn)獒t(yī)學(xué)知識(shí)檢索、醫(yī)療輔助診斷以及醫(yī)學(xué)檔案的智能化管理提供基礎(chǔ)。知識(shí)圖譜能夠有效挖掘、組織和管理大規(guī)模數(shù)據(jù)中的知識(shí),提高知識(shí)信息服務(wù)質(zhì)量,從而也可以在醫(yī)學(xué)領(lǐng)域?yàn)獒t(yī)生和病人提供更智能化的服務(wù)。尤其近年來人工智能快步發(fā)展和智能醫(yī)療、精準(zhǔn)醫(yī)療和醫(yī)學(xué)輔助診斷的提出,知識(shí)圖譜在醫(yī)學(xué)領(lǐng)域逐漸引起重視,受到國(guó)內(nèi)外研究人員廣泛的關(guān)注。不斷有知識(shí)圖譜在醫(yī)學(xué)領(lǐng)域的相關(guān)成果和研究被提出。比如,牛津大學(xué)建立了稱為L(zhǎng)ynxKB 的知識(shí)圖譜,主要用以藥學(xué)相關(guān)的研究。日本東北大學(xué)提出一種知識(shí)圖譜來進(jìn)行面向個(gè)體化預(yù)防和醫(yī)療的基因組前瞻性隊(duì)列研究工作。中醫(yī)科學(xué)院通過自動(dòng)化技術(shù)構(gòu)建了一種中醫(yī)藥知識(shí)圖譜,用于幫助醫(yī)生進(jìn)行輔助診斷。吉林大學(xué)針對(duì)世界基因組流行病建立了一種基于知識(shí)圖譜的可視化分析方法等。在這些醫(yī)學(xué)知識(shí)圖譜中,節(jié)點(diǎn)以及節(jié)點(diǎn)間的連接邊分別囊括了不同的含義。通常,節(jié)點(diǎn)的含義包括:疾病、癥狀、藥物、輔助檢查、科室、手術(shù)和部位等。節(jié)點(diǎn)之間連接邊的含義包含:疾病類型、臨床表現(xiàn)、誘發(fā)病因、發(fā)病機(jī)理和機(jī)制、預(yù)防措施、藥理作用、鑒別方式和診斷方法等。當(dāng)前醫(yī)學(xué)知識(shí)圖譜的主要應(yīng)用涵蓋了醫(yī)學(xué)問答系統(tǒng)、臨床決策與支持系統(tǒng)、醫(yī)學(xué)輔助診斷和醫(yī)學(xué)語義精準(zhǔn)搜索等方面,這些研究和成果促進(jìn)了智能醫(yī)療和醫(yī)學(xué)智能自動(dòng)化的發(fā)展,存在著極其廣闊的應(yīng)用前景和社會(huì)價(jià)值。然而,雖然醫(yī)學(xué)知識(shí)圖譜取得了較好的應(yīng)用與發(fā)展,卻存在著一些缺陷,其中醫(yī)學(xué)知識(shí)圖譜由于構(gòu)建過程中的不完整性嚴(yán)重制約了其使用效能。如何自動(dòng)地從已有的醫(yī)學(xué)知識(shí)中發(fā)掘隱藏的醫(yī)學(xué)知識(shí)進(jìn)而補(bǔ)全醫(yī)學(xué)知識(shí)圖譜已成亟待解決的事項(xiàng)。
從海量數(shù)據(jù)中發(fā)掘出隱藏的知識(shí)依賴于推理技術(shù)的支持。推理是模擬人類思維的過程,旨在從一個(gè)或多個(gè)已有的經(jīng)驗(yàn)知識(shí)前提下推理出結(jié)論或者新的知識(shí)。學(xué)術(shù)界相繼給出了知識(shí)推理的基本概念。Nikolas認(rèn)為推理是一系列能力的集合,這種能力包括理解對(duì)象、應(yīng)用邏輯規(guī)則和根據(jù)已有知識(shí)校準(zhǔn)和核驗(yàn)體系結(jié)構(gòu)的能力。Tari將知識(shí)推理歸納為基于已知事實(shí)和現(xiàn)有邏輯規(guī)則推斷出新知識(shí)的機(jī)制。基于知識(shí)圖譜的醫(yī)學(xué)知識(shí)推理目的主要是從現(xiàn)有的知識(shí)圖譜數(shù)據(jù)中辨別出錯(cuò)誤的醫(yī)學(xué)知識(shí)數(shù)據(jù)并發(fā)掘推斷出新的知識(shí)。通過醫(yī)學(xué)知識(shí)推理,可以獲得醫(yī)學(xué)知識(shí)圖譜中現(xiàn)有實(shí)體對(duì)間新的關(guān)系,然后反饋給醫(yī)學(xué)知識(shí)圖譜,從而能夠擴(kuò)展和補(bǔ)全現(xiàn)有醫(yī)學(xué)知識(shí)圖譜,為醫(yī)學(xué)高級(jí)應(yīng)用提供完備的醫(yī)學(xué)知識(shí)支持。基于醫(yī)學(xué)知識(shí)圖譜廣泛的現(xiàn)實(shí)應(yīng)用和補(bǔ)全現(xiàn)有醫(yī)學(xué)知識(shí)圖譜不完整的缺陷需求,基于知識(shí)圖譜的醫(yī)學(xué)知識(shí)推理成為當(dāng)前知識(shí)圖譜和知識(shí)推理研究領(lǐng)域的熱門問題。醫(yī)療領(lǐng)域知識(shí)推理不僅可以補(bǔ)全醫(yī)學(xué)知識(shí)圖譜,還可以為醫(yī)療人員和病患者提供臨床知識(shí)及相關(guān)診療方案進(jìn)行輔助診斷,促進(jìn)并推動(dòng)了醫(yī)療診斷智能化的改革與進(jìn)程。
本文首先針對(duì)醫(yī)學(xué)知識(shí)圖譜的相關(guān)構(gòu)建技術(shù)和基于知識(shí)推理的醫(yī)學(xué)輔助診斷進(jìn)行了總結(jié)與歸納。其次重點(diǎn)回顧了醫(yī)學(xué)知識(shí)推理的研究現(xiàn)狀,并對(duì)其推理方法進(jìn)行了分類,即:基于邏輯規(guī)則的醫(yī)學(xué)推理、基于表示學(xué)習(xí)的醫(yī)學(xué)推理以及基于深度學(xué)習(xí)的醫(yī)學(xué)推理。最后,本文總結(jié)了醫(yī)學(xué)知識(shí)推理目前面對(duì)的一些挑戰(zhàn)和重要問題,并展望了其發(fā)展前景和研究趨勢(shì)。
1 醫(yī)學(xué)知識(shí)圖譜的構(gòu)建
本章首先結(jié)合標(biāo)準(zhǔn)知識(shí)圖譜的構(gòu)建流程,并從醫(yī)學(xué)知識(shí)的表示、醫(yī)學(xué)知識(shí)抽取、醫(yī)學(xué)知識(shí)融合和質(zhì)量評(píng)估這幾個(gè)方面結(jié)合知識(shí)推理來介紹醫(yī)學(xué)知識(shí)圖譜的構(gòu)建。首先,通過醫(yī)學(xué)知識(shí)抽取和表示從大量的非結(jié)構(gòu)化、半結(jié)構(gòu)化和結(jié)構(gòu)化的醫(yī)學(xué)數(shù)據(jù)和醫(yī)學(xué)知識(shí)中提取出實(shí)體、關(guān)系和屬性等基本要素,并以合理高效的三元組形式保存到醫(yī)學(xué)知識(shí)庫中。然后,通過醫(yī)學(xué)知識(shí)融合中的數(shù)據(jù)整合、實(shí)體對(duì)齊、知識(shí)消歧和知識(shí)加工分別對(duì)醫(yī)學(xué)知識(shí)庫的知識(shí)進(jìn)行清理和整合,消除冗余和偏差信息,確保知識(shí)的質(zhì)量,提升知識(shí)和數(shù)據(jù)內(nèi)部的邏輯性和層次性。通過知識(shí)推理,推斷出缺失或者隱藏的知識(shí),自動(dòng)把醫(yī)學(xué)知識(shí)圖譜中的舊知識(shí)進(jìn)行更正與更新,并為知識(shí)圖譜補(bǔ)充新的知識(shí)。質(zhì)量評(píng)估主要是通過人工或者定義規(guī)則丟棄構(gòu)建過程中置信度比較低的醫(yī)學(xué)知識(shí),來提高醫(yī)學(xué)知識(shí)圖譜的可信性和準(zhǔn)確率,從而確保醫(yī)學(xué)圖譜知識(shí)和數(shù)據(jù)的質(zhì)量。針對(duì)以上流程,圖1 描述了醫(yī)學(xué)知識(shí)圖譜構(gòu)建的框架和詳細(xì)過程。
1.1 醫(yī)學(xué)知識(shí)抽取
醫(yī)學(xué)知識(shí)抽取方式可以劃為人類專家抽取和以機(jī)器學(xué)習(xí)方法自動(dòng)的抽取。人類專家抽取是專家根據(jù)經(jīng)驗(yàn)制定相應(yīng)的規(guī)則從醫(yī)學(xué)信息中提取知識(shí)。基于機(jī)器學(xué)習(xí)方法的醫(yī)學(xué)知識(shí)抽取是利用機(jī)器學(xué)習(xí)方法和技術(shù),從原始醫(yī)學(xué)數(shù)據(jù)中自動(dòng)抽取出醫(yī)學(xué)知識(shí)。由于人類專家提取的代價(jià)較大,通過機(jī)器學(xué)習(xí)方法設(shè)計(jì)自動(dòng)提取技術(shù)是知識(shí)抽取當(dāng)前的重點(diǎn)研究方向。醫(yī)學(xué)知識(shí)抽取主要是從非結(jié)構(gòu)化、半結(jié)構(gòu)化和結(jié)構(gòu)化的海量醫(yī)學(xué)知識(shí)中提取出實(shí)體、關(guān)系和屬性等基本要素。
早期的醫(yī)學(xué)實(shí)體抽取方法基于醫(yī)學(xué)詞典和規(guī)則。該方法主要是通過醫(yī)學(xué)專家定義規(guī)則生成醫(yī)學(xué)詞典或使用現(xiàn)有醫(yī)學(xué)詞典從語料中抽取疾病名、藥物名、癥狀名等醫(yī)學(xué)實(shí)體。Wu 等通過CHV 和SNOMEDCT 兩個(gè)醫(yī)學(xué)詞典對(duì)醫(yī)療診所筆記中的醫(yī)學(xué)信息進(jìn)行識(shí)別,取得了較好的實(shí)驗(yàn)結(jié)果。Friedman 等通過自定義語義模式和語法來識(shí)別電子病歷中的醫(yī)學(xué)信息。Hanisch 等通過基于規(guī)則的方法和預(yù)處理的同義詞詞典用于識(shí)別生物醫(yī)學(xué)文本中可能出現(xiàn)的實(shí)體名,并將識(shí)別結(jié)果對(duì)齊至蛋白質(zhì)和基因數(shù)據(jù)庫。Savova 等提出了一種臨床文本分析和知識(shí)提取系統(tǒng),采用流水線結(jié)構(gòu)以及基于規(guī)則和機(jī)器學(xué)習(xí)的技術(shù)來從電子病歷和臨床記錄中提取信息。Yang 等提出一種基于字典的生物醫(yī)學(xué)實(shí)體名稱識(shí)別方法,并設(shè)計(jì)了醫(yī)學(xué)術(shù)語縮寫識(shí)別算法對(duì)生物醫(yī)學(xué)實(shí)體詞典進(jìn)行擴(kuò)充。然而,該類方法面臨以下挑戰(zhàn):(1)目前沒有一個(gè)完整的醫(yī)學(xué)詞典可以包括所有類型的醫(yī)學(xué)實(shí)體,因此簡(jiǎn)單的文本匹配算法不足以強(qiáng)大來對(duì)實(shí)體進(jìn)行識(shí)別;(2)相同的單詞或短語其意義往往根據(jù)上下文語境的改變而改變;(3)很多藥物和疾病實(shí)體擁有多個(gè)名稱。因此,該類方法雖然有較高的提取準(zhǔn)確度,卻依賴專家編寫的規(guī)則和醫(yī)學(xué)詞典,難以適應(yīng)數(shù)據(jù)不斷變化的現(xiàn)實(shí)情況。
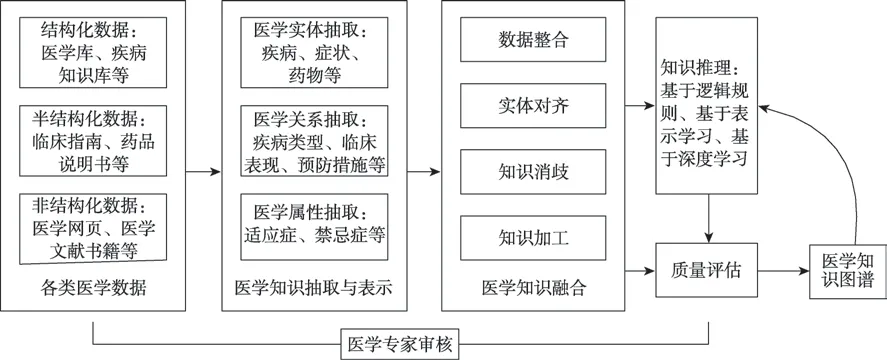
圖1 醫(yī)學(xué)知識(shí)圖譜的構(gòu)建流程Fig.1 Construction process of medical knowledge graph
隨之,研究者將機(jī)器學(xué)習(xí)算法應(yīng)用于醫(yī)學(xué)實(shí)體抽取中,利用醫(yī)學(xué)數(shù)據(jù)的特點(diǎn)對(duì)模型進(jìn)行訓(xùn)練,然后識(shí)別實(shí)體。與基于規(guī)則和詞典的方法不同,機(jī)器學(xué)習(xí)方法需要標(biāo)準(zhǔn)的標(biāo)注數(shù)據(jù)集以及合適的算法,然后利用樣本數(shù)據(jù)的統(tǒng)計(jì)特征和參數(shù)來構(gòu)建模型。目前使用到的機(jī)器學(xué)習(xí)算法有隱馬爾科夫模型(hidden Markov model,HMM)、支持向量機(jī)(support vector machine,SVM)和條件隨機(jī)場(chǎng)(conditional random field,CRF)等。Kazama 等使用支持向量機(jī)進(jìn)行生物醫(yī)學(xué)命名實(shí)體識(shí)別,同時(shí)為了提高訓(xùn)練效果,引入了詞緩存和無監(jiān)督訓(xùn)練等方法。實(shí)驗(yàn)結(jié)果表明了所提方法提取準(zhǔn)確率高于對(duì)比方法,并能應(yīng)用于大規(guī)模知識(shí)庫中。Zhou 等通過一系列特征訓(xùn)練隱馬爾科夫模型,包括詞的構(gòu)成特征、形態(tài)特征、文獻(xiàn)內(nèi)名稱別名等,其醫(yī)學(xué)知識(shí)的識(shí)別準(zhǔn)確率達(dá)到了66.5%。Tang等提出了一種結(jié)構(gòu)支持向量機(jī)算法來識(shí)別臨床記錄中的實(shí)體名,該算法結(jié)合了CRF 和SVM 的優(yōu)點(diǎn)以及單詞嵌入的有效表示,取得了高效的識(shí)別效果。然而,基于機(jī)器學(xué)習(xí)的方法需要高質(zhì)量的數(shù)據(jù)進(jìn)行訓(xùn)練,因而對(duì)人工標(biāo)注的專業(yè)性要求較高。
為了降低對(duì)數(shù)據(jù)標(biāo)注依賴,利用海量未標(biāo)注數(shù)據(jù)提升模型性能,深度學(xué)習(xí)近些年來也被廣泛應(yīng)用于實(shí)體抽取。Collobert 等提出一個(gè)深層神經(jīng)網(wǎng)絡(luò)模型,取得了超越傳統(tǒng)算法的識(shí)別效果。Wei 等基于CRF和雙向循環(huán)神經(jīng)網(wǎng)絡(luò)(recurrent neural network,RNN)生成特征,再使用SVM 進(jìn)行疾病命名實(shí)體識(shí)別。Jagannatha等實(shí)現(xiàn)了CRF、BiLSTM(bi-directional long short-term memory)和BiLSTM-CRF 三種模型以及一些改進(jìn)模型在英文電子病歷命名實(shí)體識(shí)別中的效果,實(shí)驗(yàn)結(jié)果表明基于LSTM 的模型比CRF 效果更好,并且BiLSTM 結(jié)合CRF 模型能夠進(jìn)一步提高評(píng)測(cè)結(jié)果的準(zhǔn)確率。深度學(xué)習(xí)方法的優(yōu)勢(shì)在于無需專家制定復(fù)雜的抽取特征,神經(jīng)網(wǎng)絡(luò)模型可以自動(dòng)學(xué)習(xí)到句子中隱含的語義表示。總結(jié)了不同的醫(yī)學(xué)實(shí)體抽取方法如表1 所示。
醫(yī)學(xué)關(guān)系抽取的目的是解決醫(yī)學(xué)實(shí)體間的語義鏈接問題。早期的關(guān)系抽取主要是通過人工構(gòu)造語義規(guī)則以及模板的方法識(shí)別實(shí)體關(guān)系。因?yàn)槿斯?gòu)造規(guī)則難以應(yīng)對(duì)大規(guī)模數(shù)據(jù)量,所以各種關(guān)系抽取模型被提出。這些模型的做法通常是在兩個(gè)實(shí)體間預(yù)定義好要抽取的關(guān)系類型,再將抽取任務(wù)轉(zhuǎn)換為分類問題來處理。Uzuner 等在句子層面抽取了六類醫(yī)療實(shí)體關(guān)系,使用實(shí)體順序和距離、鏈接語法和詞匯特征來訓(xùn)練六個(gè)SVM 分類器,實(shí)驗(yàn)結(jié)果證明了所提方法的有效性。Abacha 等使用人工模板和SVM 的混合模型,取得了較高的值。該研究還指出,在樣本數(shù)較少時(shí),模板匹配方法起主要作用。而樣本數(shù)較多時(shí),SVM 起主要作用。Ryan分析了電子病歷中實(shí)體關(guān)系的偏置特性,提出了一種節(jié)省標(biāo)注語料的半監(jiān)督關(guān)系識(shí)別方法,該方法采用SVM 作為分類器,對(duì)標(biāo)注的樣本先進(jìn)行預(yù)測(cè),把置信度低的樣本加入到訓(xùn)練集中。曹明宇等提出一種基于BiLSTM-CRF 的藥物實(shí)體與關(guān)系聯(lián)合抽取方法。具體的,將藥物實(shí)體及關(guān)系的聯(lián)合抽取轉(zhuǎn)化為端到端的序列標(biāo)注任務(wù),使用詞向量及字符向量作為輸入特征,應(yīng)用BiLSTM-CRF 模型進(jìn)行標(biāo)注。針對(duì)生物醫(yī)學(xué)文本中大量存在的重疊關(guān)系,他們改進(jìn)了原始的標(biāo)注模式,增加了M 標(biāo)簽來緩解重疊關(guān)系的問題,且增加了實(shí)體類別標(biāo)簽來更充分利用實(shí)體信息。此外還改進(jìn)了關(guān)系抽取規(guī)則,相比簡(jiǎn)單的最近匹配規(guī)則,所提的方法能夠顯著提升重疊關(guān)系的召回率。Seol 等提出利用CRF 模型識(shí)別與患者相關(guān)的臨床事件,利用SVM 模型提取事件之間的關(guān)系。
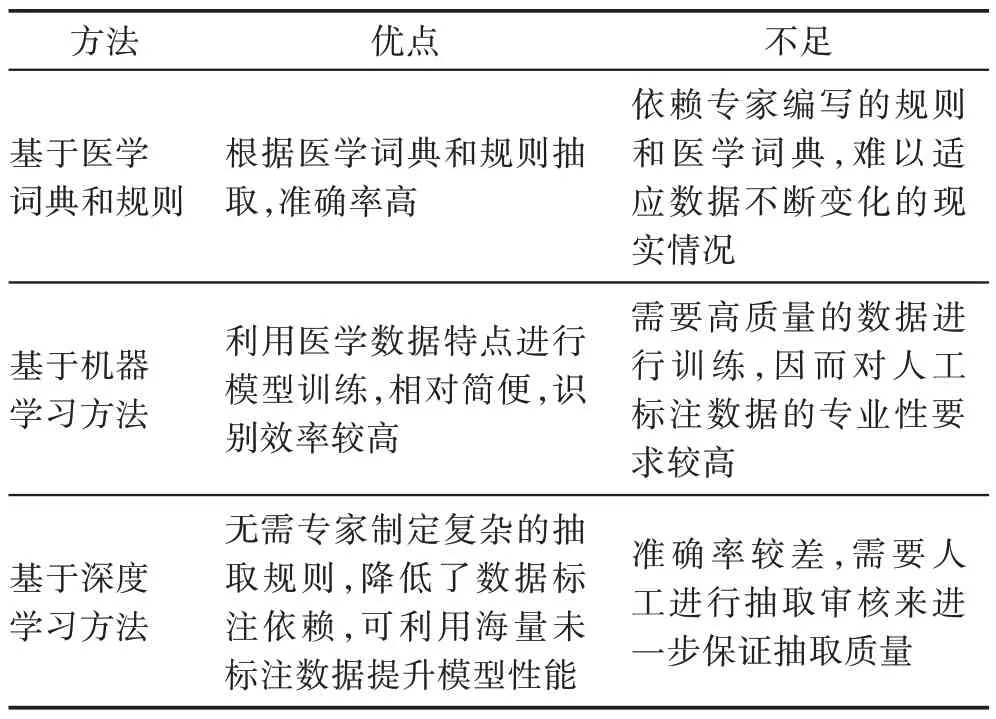
表1 醫(yī)學(xué)實(shí)體抽取方法Table 1 Medical entity extraction methods
屬性抽取是指對(duì)屬性和屬性值對(duì)的抽取。屬性的抽取是指為醫(yī)學(xué)實(shí)體構(gòu)造屬性列表,如藥品的屬性包括適應(yīng)癥、禁忌癥、規(guī)格、劑量等。屬性值的抽取是指為各實(shí)體附加具體的屬性值。目前的做法通常是將屬性抽取看成一種特殊的關(guān)系抽取,然后轉(zhuǎn)化為關(guān)系抽取問題。阮彤等考慮了知識(shí)源的可靠性以及不同信息在各知識(shí)源中出現(xiàn)的頻度等因素。在構(gòu)建中醫(yī)藥知識(shí)圖譜時(shí)對(duì)數(shù)據(jù)源的可信度進(jìn)行評(píng)分,結(jié)合數(shù)據(jù)在不同源中出現(xiàn)的次數(shù)對(duì)數(shù)據(jù)項(xiàng)進(jìn)行排序,并補(bǔ)充到相應(yīng)的屬性值字段中。
1.2 醫(yī)學(xué)知識(shí)表示
醫(yī)學(xué)知識(shí)表示主要是以符號(hào)化、形式化和模式化的語言來表示醫(yī)學(xué)知識(shí),提高計(jì)算機(jī)在醫(yī)學(xué)知識(shí)獲取、存儲(chǔ)和應(yīng)用上的效率。
目前構(gòu)建的醫(yī)學(xué)知識(shí)圖譜基本是以(頭實(shí)體,關(guān)系,尾實(shí)體)三元組的組織形式來表示醫(yī)學(xué)知識(shí)。這種知識(shí)表示方法相對(duì)聚焦和深入,表示能力既強(qiáng)又方便靈活,因而具有較大的發(fā)展?jié)摿Α4送猓摲N以三元組形式的知識(shí)表示還可以借助機(jī)器學(xué)習(xí)方法,將實(shí)體和關(guān)系分別轉(zhuǎn)化為計(jì)算機(jī)容易處理的低維稠密向量,提升了知識(shí)融合和知識(shí)推理的性能。
1.3 醫(yī)學(xué)知識(shí)融合
醫(yī)學(xué)知識(shí)融合主要是在概念規(guī)范下對(duì)醫(yī)學(xué)知識(shí)實(shí)行數(shù)據(jù)整合、實(shí)體對(duì)齊、知識(shí)消歧和加工的過程。目的是解決由于醫(yī)學(xué)知識(shí)來源不同引起醫(yī)學(xué)知識(shí)重復(fù)、醫(yī)學(xué)知識(shí)質(zhì)量參差不齊和醫(yī)學(xué)知識(shí)關(guān)聯(lián)不清晰等問題,消除多余和錯(cuò)誤的知識(shí)信息,提升醫(yī)學(xué)知識(shí)數(shù)據(jù)內(nèi)部的層次性和邏輯性。本文將醫(yī)學(xué)知識(shí)融合分為醫(yī)學(xué)實(shí)體對(duì)齊和醫(yī)學(xué)知識(shí)庫融合。
實(shí)體對(duì)齊用于消除異構(gòu)數(shù)據(jù)中的實(shí)體沖突,指向不一致問題,從而形成高質(zhì)量知識(shí)。于曉青等綜述了數(shù)據(jù)融合技術(shù)在醫(yī)學(xué)領(lǐng)域中的應(yīng)用,并根據(jù)不同的抽象層次將其分為數(shù)據(jù)級(jí)融合、特征級(jí)融合和決策級(jí)融合三類。翟霄等提出一種多模態(tài)結(jié)構(gòu)圖模型,利用圖結(jié)構(gòu)對(duì)多模態(tài)醫(yī)學(xué)數(shù)據(jù)進(jìn)行建模和表示。并基于此模型,提出一種并行的數(shù)據(jù)加載技術(shù),用于抽取出多模態(tài)醫(yī)學(xué)數(shù)據(jù)中分屬不同模態(tài)和模態(tài)間關(guān)系的數(shù)據(jù)并存儲(chǔ)到圖數(shù)據(jù)庫中。吳嘉敏利用基于命名實(shí)體屬性關(guān)系的相似性比較法,對(duì)“藥物”“靶標(biāo)”“基因”這幾個(gè)類別的數(shù)據(jù)進(jìn)行實(shí)體對(duì)齊。龐震等根據(jù)醫(yī)療領(lǐng)域的實(shí)際應(yīng)用需求,提出了一種多數(shù)據(jù)源融合的醫(yī)療知識(shí)圖譜構(gòu)建理論框架。張志劍通過計(jì)算詞向量間的空間距離表征詞間語義相似度,并設(shè)定相似度閾值來劃分醫(yī)學(xué)本體間的關(guān)系,以此實(shí)現(xiàn)實(shí)體對(duì)齊。
由于當(dāng)前大部分醫(yī)學(xué)知識(shí)圖譜都是針對(duì)某個(gè)科室或者某類疾病和藥物來構(gòu)建的,需要對(duì)不同的醫(yī)學(xué)知識(shí)庫進(jìn)行融合以獲得涵蓋范圍更為廣泛和完整的醫(yī)學(xué)知識(shí)圖譜。Dieng 等將醫(yī)學(xué)數(shù)據(jù)庫轉(zhuǎn)換為醫(yī)學(xué)本體,然后在人工控制下對(duì)本體進(jìn)行擴(kuò)展和補(bǔ)全,并設(shè)計(jì)了一種啟發(fā)式規(guī)則,自動(dòng)建立知識(shí)的概念層次來實(shí)現(xiàn)醫(yī)學(xué)知識(shí)庫的融合。Baorto 等進(jìn)行知識(shí)庫融合時(shí),先確定數(shù)據(jù)的醫(yī)學(xué)術(shù)語是否已經(jīng)存在,然后將新術(shù)語添加到醫(yī)學(xué)實(shí)體詞典中,同時(shí)建立了審計(jì)流程來保證引入醫(yī)學(xué)數(shù)據(jù)的一致性。
總結(jié)了醫(yī)學(xué)知識(shí)融合的方法如表2 所示。目前醫(yī)學(xué)知識(shí)圖譜的知識(shí)融合技術(shù)雖有一定的發(fā)展,然而,醫(yī)學(xué)知識(shí)融合的質(zhì)量還有待提升,融合過程需要大量人工干預(yù)。因此,高效的醫(yī)學(xué)知識(shí)融合算法值得進(jìn)一步研究。

表2 醫(yī)學(xué)知識(shí)融合Table 2 Medical knowledge fusion
1.4 醫(yī)學(xué)知識(shí)推理
醫(yī)學(xué)知識(shí)推理主要通過從現(xiàn)有的醫(yī)學(xué)知識(shí)數(shù)據(jù)中推斷出查詢結(jié)果,并能夠識(shí)別錯(cuò)誤推理出新的知識(shí)。
通過知識(shí)推理,可以發(fā)掘并推斷出缺失和隱藏的醫(yī)學(xué)知識(shí),自動(dòng)把醫(yī)學(xué)知識(shí)圖譜中的舊知識(shí)進(jìn)行更新,并為知識(shí)圖譜補(bǔ)充新的知識(shí)。在具體應(yīng)用中,醫(yī)學(xué)知識(shí)推理不僅可以補(bǔ)全醫(yī)學(xué)知識(shí)圖譜,還能夠?yàn)獒t(yī)療人員和患者提供臨床知識(shí)及相關(guān)診療方案進(jìn)行輔助診斷。將在下節(jié)對(duì)醫(yī)學(xué)知識(shí)推理進(jìn)行詳細(xì)的回顧與分析。
1.5 質(zhì)量評(píng)估
質(zhì)量評(píng)估則是確保圖譜知識(shí)數(shù)據(jù)好壞的重要過程。通過人工或者定義規(guī)則丟棄構(gòu)建過程中可信度比較低的知識(shí),來提高醫(yī)學(xué)知識(shí)圖譜的可信度和準(zhǔn)確度。
Clarke 等使用基于任務(wù)評(píng)估方法來分析基因本體。Bright 等使用本體設(shè)計(jì)原則和領(lǐng)域?qū)<覍彶橐庖娮鳛橹笜?biāo)來評(píng)估本體在抗生素決策支持系統(tǒng)中的效果。Cordon 等通過電子病歷、診斷案例和臨床事件等來構(gòu)造黃金標(biāo)準(zhǔn)用以評(píng)估和改進(jìn)傳染病本體。張志劍和昝紅英等在構(gòu)建醫(yī)學(xué)知識(shí)圖譜時(shí)使用精度、召回率和1 值來作為評(píng)價(jià)指標(biāo),其定義分別為=/(+),=/(+),1=2×/(+)。其中,、、分別表示準(zhǔn)確識(shí)別、錯(cuò)誤識(shí)別以及無法識(shí)別的實(shí)體的數(shù)量。在關(guān)系抽取任務(wù)中,采用準(zhǔn)確率ACC 作為評(píng)估標(biāo)準(zhǔn)。王菁薇等在構(gòu)建傷寒論醫(yī)學(xué)知識(shí)圖譜時(shí),針對(duì)實(shí)體抽取的結(jié)果,經(jīng)過兩位中醫(yī)學(xué)博士進(jìn)行人工校對(duì)與評(píng)估。
醫(yī)學(xué)知識(shí)圖譜構(gòu)建是其應(yīng)用的基礎(chǔ),而醫(yī)學(xué)知識(shí)推理是醫(yī)學(xué)知識(shí)圖譜構(gòu)建過程中非常重要卻充滿挑戰(zhàn)的任務(wù)。早期的醫(yī)學(xué)知識(shí)庫需要小范圍專家通過人工方式構(gòu)建,成本高昂,因此其構(gòu)建的醫(yī)學(xué)知識(shí)庫的規(guī)模較為有限。為了更好地構(gòu)建大型醫(yī)學(xué)知識(shí)圖譜,利用人工智能技術(shù)和自然語言處理的方法,從半結(jié)構(gòu)化和非結(jié)構(gòu)化的文檔中自動(dòng)抽取知識(shí),構(gòu)成知識(shí)庫。然而,數(shù)據(jù)來源有限和知識(shí)提取算法能力本身造成了其構(gòu)建的知識(shí)圖譜并不完整。隨著知識(shí)圖譜的增大,圖譜中仍然有很多實(shí)體之間沒有得到有效的關(guān)聯(lián)。同時(shí),知識(shí)圖譜中也有一些明顯的錯(cuò)誤和過時(shí)的信息,需要進(jìn)行更正和更新。無論是人工構(gòu)建還是自動(dòng)構(gòu)建的醫(yī)學(xué)知識(shí)圖譜,以上不完整性嚴(yán)重限制了本身的使用效能。因此,醫(yī)學(xué)知識(shí)推理技術(shù)無論是在醫(yī)學(xué)知識(shí)圖譜構(gòu)建過程中,還是自身應(yīng)用愈發(fā)重要。
1.6 醫(yī)學(xué)知識(shí)圖譜庫
Open PHACTS 是一個(gè)開放型的醫(yī)學(xué)知識(shí)訪問平臺(tái),它整合了不同來源的醫(yī)學(xué)數(shù)據(jù)。該平臺(tái)創(chuàng)建了約三十億余條的生物醫(yī)學(xué)語義數(shù)據(jù)三元組。中醫(yī)藥知識(shí)服務(wù)平臺(tái)則整合了中醫(yī)藥及其相關(guān)領(lǐng)域的醫(yī)學(xué)術(shù)語和資源,包括醫(yī)學(xué)本體、中藥材、藥劑藥方和疾病癥狀等相關(guān)知識(shí)庫。用戶可以通過該平臺(tái)進(jìn)行關(guān)于中醫(yī)藥醫(yī)學(xué)知識(shí)的檢索和問答。SNOMED-CT是目前國(guó)內(nèi)外比較全面的由多種語言的臨床醫(yī)學(xué)術(shù)語構(gòu)成的本體醫(yī)學(xué)知識(shí)庫,它包含了經(jīng)過科學(xué)驗(yàn)證的臨床資源,并對(duì)電子健康記錄中臨床醫(yī)學(xué)內(nèi)容進(jìn)行了一致性表示。最后,該知識(shí)庫包含了大約349 548個(gè)醫(yī)學(xué)相關(guān)概念。DisGeNET是一個(gè)關(guān)于基因、變異與疾病的醫(yī)學(xué)數(shù)據(jù)庫,囊括了大約10 萬條醫(yī)學(xué)關(guān)聯(lián)關(guān)系。這些關(guān)聯(lián)關(guān)系是由不同來源組成的,主要包括專家人工組織的數(shù)據(jù)庫、動(dòng)物實(shí)驗(yàn)結(jié)果、基因編碼序列推斷和相關(guān)科學(xué)文獻(xiàn)挖掘結(jié)果,并使用了標(biāo)準(zhǔn)名詞表映射以確保醫(yī)學(xué)內(nèi)容的一致性。DisGeNET已被普遍應(yīng)用于人類疾病的分子級(jí)基礎(chǔ)研究、疾病基因表現(xiàn)觀察、疾病并發(fā)癥治療、藥物療效和副作用調(diào)查等相關(guān)領(lǐng)域。
醫(yī)學(xué)知識(shí)圖譜和其他領(lǐng)域知識(shí)圖譜一個(gè)區(qū)別之處在于,醫(yī)學(xué)知識(shí)圖譜中的節(jié)點(diǎn)可能更多的是醫(yī)學(xué)相關(guān)概念。在一些醫(yī)學(xué)知識(shí)圖譜研究工作中,研究者一般將那些含有豐富語義鏈接關(guān)系的節(jié)點(diǎn)當(dāng)作實(shí)體,比如“冠心病”疾病。而那些相對(duì)比較抽象、語義模糊和鏈接較少的當(dāng)作醫(yī)學(xué)概念,比如“心血管疾病”。其次,醫(yī)學(xué)知識(shí)圖譜是更加針對(duì)性的,更具有專業(yè)性質(zhì)的領(lǐng)域知識(shí)圖譜,其醫(yī)學(xué)知識(shí)語義分析復(fù)雜性使得構(gòu)建更具挑戰(zhàn)性。再者,醫(yī)學(xué)實(shí)體名稱不規(guī)范和醫(yī)學(xué)規(guī)范命名不統(tǒng)一使得醫(yī)學(xué)名稱多樣性,而醫(yī)學(xué)又是關(guān)乎生命的科學(xué),因此醫(yī)學(xué)知識(shí)圖譜對(duì)知識(shí)精度的要求非常高,特別是應(yīng)用于臨床輔助決策過程中的醫(yī)學(xué)知識(shí),必須保證其準(zhǔn)確性。因此,在醫(yī)學(xué)知識(shí)圖譜的整個(gè)構(gòu)建過程中,需要有醫(yī)學(xué)專家全程審核醫(yī)學(xué)相關(guān)知識(shí)來保證知識(shí)的正確性。最后,也有研究者認(rèn)為醫(yī)學(xué)知識(shí)圖譜是一個(gè)概率知識(shí)圖譜,即圖譜中有一些關(guān)系可能具有一定的概率。其他知識(shí)圖譜多為事實(shí)類圖譜。例如,比爾蓋茨創(chuàng)建了微軟,在知識(shí)圖譜中被表示為三元組(比爾蓋茨,創(chuàng)建,微軟)。該三元組是一個(gè)事實(shí)三元組,它成立的概率為1。而在醫(yī)學(xué)知識(shí)圖譜中,雖然“糖尿病”會(huì)導(dǎo)致“多飲”“多尿”等癥狀,但這并不是對(duì)于所有患有糖尿病的病人都成立的,很多病人并沒有這些顯性癥狀。其次,在“藥物不良反應(yīng)”關(guān)系中,也會(huì)出現(xiàn)“常見”“罕見”和“非常罕見”等不同的概率。這些藥物的不良反應(yīng)概率不盡相同。
醫(yī)學(xué)知識(shí)圖譜應(yīng)用于實(shí)際問題中,主要面臨兩個(gè)難題。其一,缺乏涉及全科醫(yī)學(xué)知識(shí)的完整性醫(yī)學(xué)知識(shí)圖譜。目前的醫(yī)學(xué)知識(shí)圖譜主要是依據(jù)單個(gè)科室、某種疾病和治療藥物來構(gòu)建的,無法被廣泛應(yīng)用。其二,醫(yī)學(xué)知識(shí)推理的可靠性。基于醫(yī)學(xué)推理做出的診斷支持牽系到病人的身體健康和生命安全,因此對(duì)推理的正確性和可靠性有非常高的要求。目前,基于醫(yī)學(xué)知識(shí)推理給出的醫(yī)療診斷支持只能起到搜索和輔助診斷的作用。受限于醫(yī)學(xué)知識(shí)圖譜構(gòu)建的復(fù)雜性和現(xiàn)有醫(yī)學(xué)知識(shí)推理的能力,基于醫(yī)學(xué)知識(shí)圖譜的醫(yī)學(xué)知識(shí)推理仍需進(jìn)一步研究。
2 基于醫(yī)學(xué)知識(shí)推理的輔助診斷
基于醫(yī)學(xué)知識(shí)推理的輔助診斷應(yīng)用廣泛。美國(guó)斯坦福大學(xué)開發(fā)出一個(gè)MYCIN 系統(tǒng),用來輔助內(nèi)科醫(yī)生診療由細(xì)菌感染的血液性疾病。MYCIN 的主要功能是可以對(duì)疾病進(jìn)行辨別診斷,并根據(jù)患者體重不同給出使用抗生素計(jì)量差異性的建議。Rugers大學(xué)研發(fā)了一個(gè)名為CASNET 的系統(tǒng),主要用以輔助醫(yī)生進(jìn)行青光眼的診治。斯坦福大學(xué)研發(fā)出一款叫作PUFF 的肺功能檢測(cè)系統(tǒng),用以輔助醫(yī)生專家進(jìn)行肺功能測(cè)試。經(jīng)過各種臨床實(shí)例驗(yàn)證,其測(cè)試成功率可以達(dá)到93%。耶魯大學(xué)構(gòu)建了Senselab 知識(shí)圖譜,用以描述人類的腦結(jié)構(gòu)。它緩解了目前神經(jīng)科學(xué)所面對(duì)的大量數(shù)據(jù)難題,并從微觀到宏觀,基因到行為的多個(gè)層系上幫助研究人員理解人類大腦。目前,比較常見的醫(yī)學(xué)知識(shí)圖譜有NDF-RT、Sider、MEDI、LabeledIn等。這些醫(yī)學(xué)知識(shí)圖譜大多來自于MEDLINE 和OpenKG 等公開的醫(yī)學(xué)數(shù)據(jù)庫。此外,國(guó)外應(yīng)用比較廣泛的臨床知識(shí)庫有MorphoCol、NursingKB等,主要用以輔助醫(yī)生進(jìn)行醫(yī)療決策診斷和支持工作。
國(guó)內(nèi)學(xué)者和研究人員對(duì)中醫(yī)藥知識(shí)圖譜的創(chuàng)建流程和方法,以及基于醫(yī)學(xué)推理的輔助開藥進(jìn)行了探索和研究。張德政等開發(fā)出用以高血壓診斷的智能專家系統(tǒng),該系統(tǒng)利用人工神經(jīng)網(wǎng)絡(luò)技術(shù)來抽取知識(shí)并基于此進(jìn)行推理以輔助醫(yī)生進(jìn)行診治。還有學(xué)者成功研發(fā)出一款計(jì)算機(jī)輔助分析專家系統(tǒng),主要用以智能描繪心率和記錄宮縮圖像。該系統(tǒng)可以在對(duì)不同病人進(jìn)行診治的同時(shí)給出同樣或類似的診療建議,并可以對(duì)病人進(jìn)行診斷解釋。楊連初等研發(fā)出一款存儲(chǔ)了四百多種疾病類型的中醫(yī)診斷軟件。該軟件內(nèi)容充實(shí)詳細(xì),涉及面廣泛,得到了普遍的應(yīng)用。阮彤等創(chuàng)建了一種中醫(yī)藥知識(shí)圖譜。該中醫(yī)藥知識(shí)圖譜囊括了發(fā)病癥狀庫、疾病類型庫和中草藥庫中的相關(guān)醫(yī)學(xué)知識(shí),主要用以中醫(yī)藥問答和幫助醫(yī)生輔助開藥。
基于醫(yī)學(xué)知識(shí)推理的輔助診斷在工業(yè)界也備受矚目。北京康夫子科技有限公司利用知識(shí)圖譜相關(guān)構(gòu)建技術(shù),構(gòu)建了醫(yī)療大腦知識(shí)圖譜。主要讓計(jì)算機(jī)去閱讀醫(yī)療文獻(xiàn),構(gòu)建知識(shí)庫,并利用知識(shí)推理技術(shù),達(dá)到輔助醫(yī)生診斷的目的。百度創(chuàng)建了百度醫(yī)生APP,利用醫(yī)療知識(shí)圖譜和知識(shí)推理技術(shù),讓醫(yī)生和患者之間交流進(jìn)行輔助診斷,并提供醫(yī)療信息服務(wù)。IBM 開發(fā)的Watson,可為病人患者提供個(gè)性化、有優(yōu)先針對(duì)順序和循證醫(yī)學(xué)證據(jù)的治療方案。目前可支持乳腺癌、肺癌、胃癌和結(jié)腸癌等13 種常見癌癥,其提供的治療方案與世界頂級(jí)醫(yī)生專家符合度高達(dá)90%以上。開放醫(yī)療和健康聯(lián)盟(open medical and healthcare alliance,OMAHA)研究了醫(yī)學(xué)知識(shí)圖譜的相關(guān)構(gòu)建工作,目前已經(jīng)成功發(fā)布了Schema 知識(shí)圖譜模型。知識(shí)圖譜包括了藥品和適應(yīng)癥,用于臨床治療的相關(guān)檢查這兩種醫(yī)學(xué)知識(shí)數(shù)據(jù)。在醫(yī)學(xué)知識(shí)推理的輔助診斷過程中,他們也發(fā)現(xiàn)醫(yī)學(xué)知識(shí)圖譜獨(dú)特于其他知識(shí)圖譜的問題。比如:(1)醫(yī)學(xué)實(shí)體名稱多樣性。由于醫(yī)學(xué)知識(shí)數(shù)據(jù)來源不同,致使醫(yī)學(xué)實(shí)體名稱多樣性。然而,很多醫(yī)學(xué)實(shí)體實(shí)際上表示同一醫(yī)學(xué)知識(shí)。比如,獲得性免疫缺陷綜合征與艾滋病表示同一種醫(yī)學(xué)疾病。OMAHA 通過借鑒醫(yī)學(xué)知識(shí)定義較為清晰的七巧板醫(yī)學(xué)術(shù)語集來進(jìn)行醫(yī)學(xué)知識(shí)圖譜實(shí)體對(duì)齊,從而消除醫(yī)學(xué)實(shí)體名稱多樣性的問題。同時(shí),還可以完善醫(yī)學(xué)實(shí)體的定義,豐富醫(yī)學(xué)實(shí)體的表述方式。(2)醫(yī)學(xué)對(duì)知識(shí)質(zhì)量和推理精度要求更高。醫(yī)學(xué)涉及到人類的生命健康,因此對(duì)于醫(yī)學(xué)知識(shí)質(zhì)量和推理的精度提出了非常高的要求。尤其是應(yīng)用于醫(yī)療輔助診斷中的醫(yī)學(xué)知識(shí),必須已在實(shí)踐中得到了充分的驗(yàn)證。醫(yī)學(xué)知識(shí)推理的精度也必須得到較高的保障。研究人員應(yīng)該優(yōu)先選取臨床指南、醫(yī)學(xué)教材、藥品說明書等這些醫(yī)學(xué)知識(shí)質(zhì)量較高的知識(shí)來源用于醫(yī)學(xué)知識(shí)圖譜的構(gòu)建,同時(shí)通過自動(dòng)抽取加人工審查相結(jié)合的方式來保證醫(yī)學(xué)知識(shí)的精確度。
3 醫(yī)學(xué)知識(shí)推理
醫(yī)學(xué)知識(shí)推理不僅可以補(bǔ)全醫(yī)學(xué)知識(shí)圖譜,還能夠?yàn)獒t(yī)療人員和患者提供臨床知識(shí)及相關(guān)診療方案進(jìn)行輔助診斷。知識(shí)圖譜推理在醫(yī)生輔助診斷任務(wù)中得到了廣泛的研究和應(yīng)用,大大提高了醫(yī)生工作的效率,已成為近年來的研究熱點(diǎn)。
醫(yī)學(xué)知識(shí)推理也是基于通用的知識(shí)推理技術(shù),因此,本文首先將醫(yī)學(xué)知識(shí)推理分為三類,即:基于邏輯規(guī)則的醫(yī)學(xué)推理、基于表示學(xué)習(xí)的醫(yī)學(xué)推理以及基于深度學(xué)習(xí)的醫(yī)學(xué)推理。然后給出每種推理類別的定義以及一些典型做法,最后給出該類推理方法在醫(yī)學(xué)知識(shí)圖譜推理中的應(yīng)用。
3.1 基于邏輯規(guī)則的醫(yī)學(xué)推理
基于邏輯規(guī)則的醫(yī)學(xué)推理方法在早期得到了普遍的關(guān)注,產(chǎn)生了不同的推理方法,包含了謂詞邏輯推理方法、本體推理方法和隨機(jī)游走推理方法等。
一階謂詞邏輯將命題當(dāng)作基本的推理單元,其中命題包含了個(gè)體和預(yù)測(cè)。個(gè)體即是知識(shí)圖譜中的實(shí)體對(duì)象,可以單獨(dú)存在。它們可以是一個(gè)具體的事物或者一個(gè)抽象的概念。謂語被用來描述個(gè)體的屬性。Schoenmackers 等提出了一種一階歸納學(xué)習(xí)方法,是謂詞邏輯的一項(xiàng)主要工作。該方法主要通過搜索知識(shí)圖譜中的全部關(guān)系,并獲得每個(gè)關(guān)系的集合作為特征來推理和預(yù)測(cè)實(shí)體對(duì)應(yīng)的關(guān)系是否存在。Bienvenu 等提出一種框架來強(qiáng)化推理系統(tǒng),使之在不一致容忍語義下具有解釋能力。為了對(duì)大規(guī)模的不完整信息知識(shí)庫進(jìn)行推理,Wang 等提出了一種稱為ProPPR 的一階概率語言,在知識(shí)庫推理中允許相互遞歸(聯(lián)合學(xué)習(xí))來提高性能。Yang 等研究了概率一階邏輯規(guī)則的學(xué)習(xí)問題,主要用以知識(shí)庫的推理。這個(gè)問題較為困難,因?yàn)樗枰獙W(xué)習(xí)連續(xù)空間中的參數(shù)和離散空間中的結(jié)構(gòu)。因此構(gòu)建了一種基于神經(jīng)邏輯的程序架構(gòu),將一階邏輯規(guī)則的參數(shù)學(xué)習(xí)和結(jié)構(gòu)學(xué)習(xí)進(jìn)行聯(lián)合學(xué)習(xí)。在經(jīng)驗(yàn)數(shù)據(jù)中的實(shí)驗(yàn)驗(yàn)證了該框架在多個(gè)知識(shí)庫基準(zhǔn)數(shù)據(jù)集上的表現(xiàn)好于對(duì)比方法。Bousquet 等提出一種根據(jù)DAML(Darpa agent markup language)和OIL(ontology inference layer)描述邏輯來推理的實(shí)現(xiàn)方法,并用以改進(jìn)信號(hào)檢測(cè)用于藥物警戒系統(tǒng)。Chen 等采用基于規(guī)則的推理方法研發(fā)了糖尿病診斷系統(tǒng)用以輔助醫(yī)生并提供開藥建議。邊紅根據(jù)醫(yī)療數(shù)據(jù)建立了中醫(yī)胃病的相關(guān)知識(shí)圖譜,并基于此圖譜實(shí)現(xiàn)了一種專家輔助診斷系統(tǒng)。該系統(tǒng)可以通過把不同的醫(yī)學(xué)輸入信息轉(zhuǎn)變?yōu)橹眯沤Y(jié)構(gòu),然后根據(jù)產(chǎn)生式規(guī)則來表示這些內(nèi)容,接著進(jìn)行模糊推理,最后可以通過患者的體征表現(xiàn)和癥狀表現(xiàn)向患者提供快速而基本的診斷結(jié)果。袁勇等建立了一個(gè)呼吸道疾病專家系統(tǒng),主要針對(duì)呼吸道疾病進(jìn)行確診和排除,并對(duì)提出的診斷假設(shè)進(jìn)行判斷。該系統(tǒng)主要使用基于規(guī)則的方法進(jìn)行推理,同時(shí)還考慮了疾病和表現(xiàn)癥狀之間的不確定性。在相關(guān)實(shí)驗(yàn)上證明了所提方法有效性,能夠給出較高準(zhǔn)確性的診斷結(jié)果。羅率力受啟發(fā)于醫(yī)生在診斷過程中的思維分析,并根據(jù)醫(yī)學(xué)知識(shí)表達(dá)結(jié)構(gòu),提出了一種基于模糊框架的推理機(jī)制和模糊規(guī)則的推理機(jī)制。該機(jī)制運(yùn)用了正向推理和逆向推理,這兩種推理互相嵌套,克服了單一推理機(jī)制的不足,提高了醫(yī)學(xué)診斷的正確性。該推理機(jī)制還將推理過程分為多個(gè)步驟同步進(jìn)行,使得推理過程不至于過分冗長(zhǎng),滿足了不同用戶的個(gè)性化需求。Kumar等提出了一種基于實(shí)例推理和規(guī)則推理的混合方法,并開發(fā)出一種用以重癥監(jiān)護(hù)病房的臨床決策支持系統(tǒng),提高了病房的監(jiān)察與護(hù)理。
基于知識(shí)圖譜的醫(yī)學(xué)推理也能夠基于圖譜中本體進(jìn)行推理。本體是更抽象化和概念化的知識(shí)表示,基于本體的圖譜推理主要是發(fā)現(xiàn)本體定義里的邏輯錯(cuò)誤與矛盾,從而構(gòu)建更加準(zhǔn)確的本體。在對(duì)物理世界中的知識(shí)進(jìn)行建模時(shí),常常需要用本體來表示和推理。為了使用描述邏輯(description logics,DL)來處理這樣的本體,Markus 等使用有限的屬性值對(duì)集合(稱之為注釋)來豐富DL 概念和角色,并允許概念包含來表達(dá)對(duì)注釋的約束。Wei 等提出并實(shí)現(xiàn)了知識(shí)圖譜表示學(xué)習(xí)分布式推理系統(tǒng),該系統(tǒng)基于一個(gè)OWL(web ontology language)的知識(shí)圖譜。由于系統(tǒng)含有豐富的更具表達(dá)性的規(guī)則,推理能力也相對(duì)較強(qiáng)。同時(shí),還支持對(duì)冗余數(shù)據(jù)的優(yōu)化。實(shí)驗(yàn)結(jié)果表明,與其他推理系統(tǒng)相比,該系統(tǒng)能夠有效推導(dǎo)出本體中更多的隱含信息,也能夠很好地檢測(cè)知識(shí)圖譜中的不一致性。Martínez-Romero 等研發(fā)了一種基于本體的智能監(jiān)護(hù)治療系統(tǒng),用以急性心臟病危重病人的智能監(jiān)護(hù)。其中,專家知識(shí)由OWL 本體和一組規(guī)則來進(jìn)行表示。基于可以代表專家知識(shí)的本體和規(guī)則,推理機(jī)可以進(jìn)行相應(yīng)推理,從而能夠向醫(yī)生提供關(guān)于病人診療的建議。Shi 等根據(jù)本體的概念建立了語義健康知識(shí)圖譜,它是異構(gòu)醫(yī)學(xué)知識(shí)與醫(yī)學(xué)服務(wù)的語義集成,可以用于自動(dòng)化的臨床醫(yī)學(xué)輔助診斷和推理。Angel等研發(fā)了基于邏輯推理和本體驅(qū)動(dòng)的辨別輔助診斷系統(tǒng),并用于幫助醫(yī)生進(jìn)行輔助診斷。
一系列研究表明,將基于路徑的推理規(guī)則引入知識(shí)推理可以顯著提升推理的性能。路徑排序算法(path ranking algorithm,PRA)是一種在圖中根據(jù)路徑進(jìn)行推理的算法。為了學(xué)習(xí)知識(shí)庫中某個(gè)特定邊類型的推理模型,PRA 會(huì)找到經(jīng)常鏈接節(jié)點(diǎn)的邊類型序列,這些節(jié)點(diǎn)是該邊類型的實(shí)例預(yù)測(cè)。PRA根據(jù)路徑上的關(guān)系規(guī)則的特征作為L(zhǎng)ogistic 回歸模型的輸入來推理知識(shí)圖中實(shí)體對(duì)的缺失邊。PRA 的主要思想是用一條或者多條連接兩個(gè)實(shí)體之間的序列路徑來推理該對(duì)實(shí)體之間的具體的隱藏關(guān)系。在知識(shí)圖譜中,路徑主要是由連接兩個(gè)實(shí)體之間的實(shí)體和關(guān)系序列構(gòu)成。學(xué)習(xí)階段一般分為三個(gè)階段:序列路徑尋找、提取路徑特征和構(gòu)建分類器。PRA算法中常用的序列路徑尋找方法有隨機(jī)游走、深度優(yōu)先游走和廣度優(yōu)先游走。提取路徑特征一般是將不同路徑的二值特征提取并作為下一步分類器的輸入。分類器通常是構(gòu)造一個(gè)邏輯回歸二元分類器。侯秀萍等設(shè)計(jì)了基于動(dòng)態(tài)模糊邏輯和加權(quán)模糊邏輯相結(jié)合的計(jì)算機(jī)輔助醫(yī)學(xué)診斷系統(tǒng),通過實(shí)例證明了所提方法的有效性。朱呂行通過整合基因-疾病庫、基因-基因庫和疾病-疾病庫,構(gòu)建了一個(gè)異構(gòu)中醫(yī)知識(shí)圖譜。該知識(shí)圖譜含有疾病和基因兩種類型節(jié)點(diǎn),以及它們的三種相互關(guān)系。基于該知識(shí)圖譜,提出了一種深度游走算法使得可以在全局網(wǎng)絡(luò)上進(jìn)行搜索游走,然后根據(jù)游走的路徑獲得各個(gè)節(jié)點(diǎn)的嵌入表示向量。最后使用圖卷積神經(jīng)網(wǎng)絡(luò)提取向量的特征用于后續(xù)的預(yù)測(cè)診斷。他們實(shí)現(xiàn)了可以學(xué)習(xí)已知的疾病-基因關(guān)聯(lián)信息并為未知的疾病-基因關(guān)聯(lián)做出預(yù)測(cè)。王雁等提出一種專家醫(yī)生的知識(shí)結(jié)構(gòu)及診斷推理方式。醫(yī)生將臨床醫(yī)學(xué)數(shù)據(jù)以疾病腳本的方式進(jìn)行組織。伴隨臨床經(jīng)驗(yàn)的豐富與增加,專家醫(yī)生可以聚積充足的疾病腳本。在臨床診斷過程中,專家可以不需要對(duì)病人全部的病歷數(shù)據(jù)和病狀進(jìn)行詳細(xì)分析,而可以通過模式識(shí)別或樣例辨認(rèn)等機(jī)器學(xué)習(xí)方法自動(dòng)搜索與之相似的疾病腳本,從而可以對(duì)病人做出快速準(zhǔn)確的診斷。
3.2 基于表示學(xué)習(xí)的醫(yī)學(xué)推理
基于表示學(xué)習(xí)的醫(yī)學(xué)推理主要是學(xué)習(xí)三元組中實(shí)體和關(guān)系的低維嵌入表示,然后基于此向量化的知識(shí)表示進(jìn)行計(jì)算和知識(shí)圖譜推理。近些年來,不同學(xué)者相繼提出了一些基于表示學(xué)習(xí)的推理方法,比如距離平移模型和語義匹配模型。
距離平移模型是通過構(gòu)建三元組中實(shí)體和關(guān)系的平移操作來學(xué)習(xí)它們的向量化表示。Bordes 等提出了基于距離平移的TransE 模型,旨在將知識(shí)圖譜中構(gòu)成三元組的實(shí)體和關(guān)系使用低維的稠密實(shí)值向量來表示。TransE 將知識(shí)圖譜中實(shí)體和關(guān)系分別投影到一個(gè)連續(xù)的低維向量空間中,把關(guān)系解釋為頭實(shí)體和尾實(shí)體之間的平移操作,即+≈。然后通過計(jì)算式(1),數(shù)值越小,認(rèn)為構(gòu)成的三元組越合理。
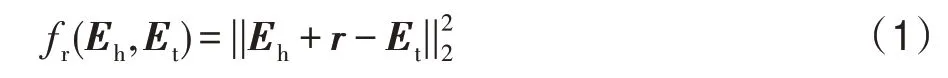

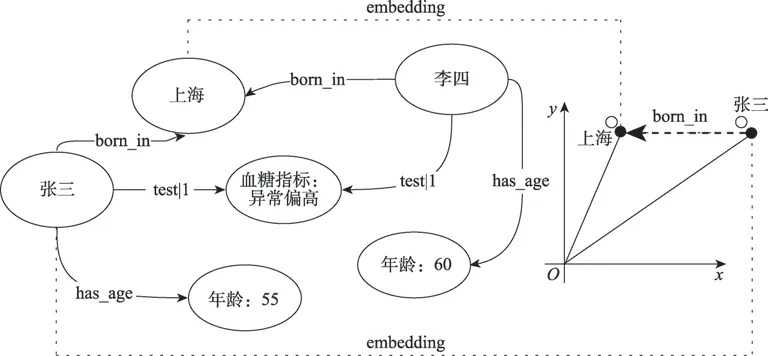
圖2 醫(yī)學(xué)知識(shí)圖譜嵌入表示學(xué)習(xí)示例Fig.2 Framework of medical knowledge graph embedding representation learning
為了解決多跳推理問題,各種基于路徑的知識(shí)表示學(xué)習(xí)模型被提出。Seo 等提出一種基于可靠路徑的表示學(xué)習(xí)方法,用以知識(shí)圖譜的表示學(xué)習(xí)。具體來說,他們提出一種可靠的知識(shí)圖路徑排序方法,避免了不可靠路徑的不必要計(jì)算,找到語義上有效的關(guān)系路徑。實(shí)驗(yàn)結(jié)果證明了所提方法有效性和高效性。劉嶠等提出了一種基于表示學(xué)習(xí)的語義感知關(guān)系推理算法,充分考慮了實(shí)體和關(guān)系在語義上的多樣性。通過加權(quán)的方式聯(lián)合實(shí)體向量的語義要素,實(shí)現(xiàn)不同實(shí)體對(duì)之間關(guān)系語義的表示與辨分。在知識(shí)圖譜中的推理任務(wù)驗(yàn)證了所提算法的有效性,實(shí)驗(yàn)結(jié)果表明了算法可以較好地區(qū)分實(shí)體對(duì)之間的復(fù)雜關(guān)系的語義,提升了知識(shí)圖譜中關(guān)系推理任務(wù)中的準(zhǔn)確率。鄭子強(qiáng)通過整理關(guān)于慢性腎臟病中醫(yī)醫(yī)案文獻(xiàn),構(gòu)建了慢性腎臟病知識(shí)圖譜。在醫(yī)學(xué)知識(shí)推理任務(wù)中,按照慢性腎臟病的診療過程,將之分解為知識(shí)圖譜多層實(shí)體間的鏈路預(yù)測(cè)任務(wù)。在慢性腎臟病知識(shí)圖譜表示學(xué)習(xí)的基礎(chǔ)上,通過多維卷積神經(jīng)網(wǎng)絡(luò)對(duì)知識(shí)圖譜中的實(shí)體和關(guān)系構(gòu)成的路徑向量進(jìn)行特征提取,然后輸入分類器中實(shí)現(xiàn)鏈路預(yù)測(cè)任務(wù)。實(shí)驗(yàn)結(jié)果驗(yàn)證了所提方法是有效的,在多個(gè)評(píng)估指標(biāo)下預(yù)測(cè)都超過了95%。
3.3 基于深度學(xué)習(xí)的醫(yī)學(xué)推理
深度學(xué)習(xí)的再度興起,使得深度神經(jīng)網(wǎng)絡(luò)被廣泛應(yīng)用于各種領(lǐng)域。神經(jīng)網(wǎng)絡(luò)由于其較強(qiáng)的特征捕捉與映射能力,基于深度學(xué)習(xí)的知識(shí)推理也是當(dāng)前一個(gè)研究熱點(diǎn)。目前在醫(yī)學(xué)推理中應(yīng)用比較廣泛的是基于循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)、卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)和圖神經(jīng)網(wǎng)絡(luò)(graph neural network,GNN)的知識(shí)推理方法。
循環(huán)神經(jīng)網(wǎng)絡(luò)的優(yōu)勢(shì)是可以有效處理序列數(shù)據(jù),并能夠有效編碼序列信息的上下文。然而,知識(shí)圖譜是由大量的知識(shí)三元組構(gòu)成的,這些知識(shí)三元組無法形成有效的序列信息。一個(gè)可行的解決方案是通過尋找知識(shí)圖譜中兩個(gè)實(shí)體之間的鏈接路徑,將路徑上的信息融合來構(gòu)建知識(shí)圖譜鏈路序列信息。然后,通過將鏈路序列輸入RNN 進(jìn)行路徑編碼,最終來獲得知識(shí)圖譜中頭實(shí)體與尾實(shí)體之間的路徑的語義相關(guān)向量進(jìn)行知識(shí)推理。然而,由實(shí)體和關(guān)系組成的路徑序列信息僅能夠提供有限的推理信息。同時(shí),從大量的鏈路序列中搜索對(duì)推理有用的路徑序列效率較低。Arvind 等提出了一種使用稱為path-RNN 的遞歸神經(jīng)網(wǎng)絡(luò)來組合路徑含義,該網(wǎng)絡(luò)對(duì)多跳關(guān)系的鏈接進(jìn)行推理。Path-RNN 使用PRA為每個(gè)關(guān)系類型找到不同的路徑,然后將路徑中二進(jìn)制關(guān)系的嵌入作為輸入向量。最后通過構(gòu)建關(guān)系分類器來將路徑特征向量推理為實(shí)體間具體的關(guān)系。
大多數(shù)方法集中在使用三元組本身的結(jié)構(gòu)信息來學(xué)習(xí)實(shí)體和關(guān)系的語義嵌入表示,然后基于此低維嵌入表示進(jìn)行推理。然而,實(shí)際上,在大多數(shù)知識(shí)圖譜中,實(shí)體的描述通常很簡(jiǎn)潔,現(xiàn)有的方法無法很好地利用這些描述。而這些多源異構(gòu)描述信息能夠加強(qiáng)知識(shí)圖譜中實(shí)體和關(guān)系的語義區(qū)分能力。卷積神經(jīng)網(wǎng)絡(luò)因?yàn)槠渥陨愍?dú)有的網(wǎng)絡(luò)架構(gòu),為這些額外的描述數(shù)據(jù)的特征提取提供了支持。Xie 等提出了一種基于實(shí)體描述信息的知識(shí)圖譜嵌入表示學(xué)習(xí)模型。具體來說,他們探索了連續(xù)詞袋和深度卷積神經(jīng)網(wǎng)絡(luò)兩種編碼方法來分別編碼實(shí)體描述的語義信息。然后進(jìn)一步使用三元組和描述語義信息的特征來學(xué)習(xí)知識(shí)圖譜三元組中實(shí)體和關(guān)系的向量化知識(shí)表示。實(shí)驗(yàn)表明,該方法在推理任務(wù)中取得了良好的效果,還可以減少數(shù)據(jù)稀疏性對(duì)推理模型性能的影響。Chen等提出了DIVA(discrete infer variational auto-encoder)的概率圖模型框架。他們認(rèn)為知識(shí)圖譜推理問題可以歸結(jié)為兩個(gè)步驟:鏈接路徑尋找和路徑推理。同時(shí)在優(yōu)化過程中通過提高了這兩步之間的交互以增加模型的魯棒性和減弱模型對(duì)噪聲的敏感性。DIVA 使用潛變量圖模型來建模知識(shí)推理問題,假設(shè)在知識(shí)圖譜中存在一個(gè)潛在變量,它承載了實(shí)體之間關(guān)系的等價(jià)語義。路徑尋找過程作為一個(gè)先驗(yàn)分布,主要用來搜索給定實(shí)體對(duì)之間的關(guān)系鏈接路徑。路徑推理過程作為一個(gè)似然分布,主要是將搜索到的路徑的潛在變量分類為多個(gè)關(guān)系類別。
近幾年來,利用圖神經(jīng)網(wǎng)絡(luò)和強(qiáng)化學(xué)習(xí)來求解路徑搜索問題也引起了廣泛關(guān)注。Xiong 等假設(shè)給定源實(shí)體和關(guān)系,可以通過路徑尋找另一個(gè)實(shí)體,這個(gè)過程可以定義為一個(gè)馬爾科夫決策過程。提出的Deep-Path 是首次在知識(shí)圖中使用強(qiáng)化學(xué)習(xí)方法進(jìn)行路徑尋找的模型,對(duì)后續(xù)的派生模型有著重要的啟示。在這項(xiàng)工作中,他們提出了一種新的可控多跳推理方法,將路徑尋找過程使用強(qiáng)化學(xué)習(xí)(reinforcement learning,RL)來搜索。代理agent 在路徑尋找的每一步中,通過對(duì)關(guān)系進(jìn)行采樣來擴(kuò)展其路徑,從而采取增量式路徑擴(kuò)充。為了更有效地刺激強(qiáng)化學(xué)習(xí)中的代理尋找關(guān)系路徑,他們使用策略梯度進(jìn)行訓(xùn)練并設(shè)計(jì)了一個(gè)新穎的獎(jiǎng)勵(lì)懲罰函數(shù),用來共同鼓勵(lì)路徑搜索過程中尋找到路徑的準(zhǔn)確性、多樣性和效率。實(shí)驗(yàn)結(jié)果表明該方法優(yōu)于路徑排序算法和基于距離嵌入模型的方法。然而,與傳統(tǒng)方法相比,Deep-Path 更側(cè)重于路徑的搜索,在推理過程中,只是簡(jiǎn)單地使用尋找到路徑的二值特征輸入到一個(gè)二元分類器中來預(yù)測(cè)一個(gè)預(yù)定義的關(guān)系是否存在。DAPath 模型增強(qiáng)了基于深度路徑的強(qiáng)化學(xué)習(xí)的運(yùn)用,并用之主要解決知識(shí)圖譜推理任務(wù)中的鏈接預(yù)測(cè)問題。進(jìn)一步的,M-WALK 通過使用RNN 記錄所有軌跡路徑,然后使用蒙特卡洛采樣和Q 學(xué)習(xí)算法迭代優(yōu)化策略來學(xué)習(xí)模型。Wang 等設(shè)計(jì)了一個(gè)基于生成對(duì)抗網(wǎng)絡(luò)(generative adversarial network,GAN)的強(qiáng)化學(xué)習(xí)模型,應(yīng)用于知識(shí)圖譜推理與補(bǔ)全的任務(wù)。他們將知識(shí)圖譜補(bǔ)全問題定義為馬爾科夫過程,并探索在狀態(tài)轉(zhuǎn)移過程和獎(jiǎng)勵(lì)過程中引入的規(guī)則,以更好地指導(dǎo)生成對(duì)抗網(wǎng)絡(luò)優(yōu)化下的行走路徑。同時(shí),使用長(zhǎng)短項(xiàng)記憶模型(long shortterm memory,LSTM)作為生成對(duì)抗網(wǎng)絡(luò)的生成器,不僅用來記錄歷史軌跡,而且可以生成新的子圖,然后使用GAN 訓(xùn)練策略網(wǎng)絡(luò)。此外,為了更好地生成新的子圖,采用圖神經(jīng)網(wǎng)絡(luò)將知識(shí)圖嵌入到低維向量中,并對(duì)各層的消息傳遞過程進(jìn)行參數(shù)化。
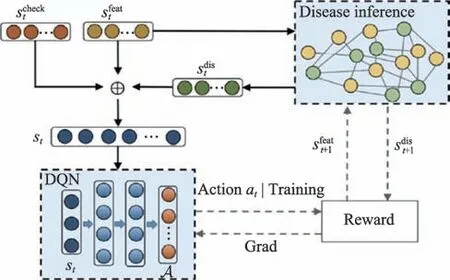
圖3 動(dòng)態(tài)交互式智能診斷模型框架圖Fig.3 Framework of dynamic interactive intelligent diagnosis model
受以上知識(shí)推理工作的啟發(fā),殷蘇娜通過對(duì)糖尿病臨床醫(yī)學(xué)數(shù)據(jù)進(jìn)行分析和整理,構(gòu)建了糖尿病知識(shí)圖譜。同時(shí),為了處理醫(yī)學(xué)臨床知識(shí)中的時(shí)序數(shù)據(jù),設(shè)計(jì)了基于長(zhǎng)短期記憶神經(jīng)網(wǎng)絡(luò)的序列增量學(xué)習(xí)模型。該模型利用長(zhǎng)短期記憶網(wǎng)絡(luò)可以聯(lián)系上下文的優(yōu)勢(shì),并提出一個(gè)序列增量學(xué)習(xí)層來強(qiáng)化學(xué)習(xí)特征。最后,以一種端到端的方法來解決知識(shí)圖譜中的鏈接預(yù)測(cè)推理任務(wù)。李蕓提出一個(gè)交互式智能輔助診斷模型用于提升醫(yī)生的診斷效率。該模型包括了疾病推理和檢查推薦兩大模塊,其智能診斷整體結(jié)構(gòu)如圖3 所示。首先,模型根據(jù)疾病與癥狀、病史等之間的關(guān)聯(lián)關(guān)系,構(gòu)建了疾病知識(shí)圖譜。模型推理模塊將醫(yī)學(xué)診斷過程看作馬爾科夫決策過程,設(shè)計(jì)了一個(gè)基于強(qiáng)化學(xué)習(xí)框架的檢查推薦策略網(wǎng)絡(luò),用于預(yù)測(cè)每步交互狀態(tài)中最優(yōu)的動(dòng)作,優(yōu)化診斷路徑。模型接收到用戶在系統(tǒng)中輸入的信息,然后推薦當(dāng)前狀態(tài)的動(dòng)作。如果推薦動(dòng)作為檢查項(xiàng)目,模型則會(huì)等待用戶進(jìn)一步輸入信息,繼續(xù)與用戶進(jìn)行交互。如果推薦動(dòng)作為診斷疾病結(jié)果,模型則結(jié)束當(dāng)前交互過程并給出醫(yī)學(xué)診斷結(jié)果。通過現(xiàn)實(shí)中的實(shí)際操作,驗(yàn)證了所提模型和系統(tǒng)在疾病輔助診斷上的靈活性和準(zhǔn)確性。Yang 等提出一種ART-Kohonen 神經(jīng)網(wǎng)絡(luò)和病歷推理相結(jié)合的智能診斷,提高了診斷的效率和準(zhǔn)確度。神經(jīng)張量網(wǎng)絡(luò)模型在Freebase 等知識(shí)圖譜本體庫上對(duì)缺失和隱藏關(guān)系的推理準(zhǔn)確率達(dá)到了90%。Karegowda 等在糖尿病知識(shí)圖譜中通過使用遺傳算法和反向傳播神經(jīng)網(wǎng)絡(luò)相結(jié)合的混合推理模型,將診斷正確率提高了7%左右。趙超提出基于馬爾科夫隨機(jī)場(chǎng)的醫(yī)學(xué)知識(shí)推理框架,針對(duì)疾病診斷、檢查推薦、治療方案推薦三大臨床決策問題,結(jié)合圖特征、邊特征、分布式表示的節(jié)點(diǎn)特征等構(gòu)建了六種勢(shì)函數(shù),設(shè)計(jì)了三種評(píng)價(jià)指標(biāo)對(duì)推理系統(tǒng)性能進(jìn)行評(píng)估。這三種評(píng)價(jià)指標(biāo)分別是平均@(mean@,@)、平均@(mean@,@) 以及平均準(zhǔn)確率(mean average precision,MAP)。其中,@是指前個(gè)返回結(jié)果的準(zhǔn)確率,@是前個(gè)返回結(jié)果中的正實(shí)例在全部正實(shí)例中所占的比重,MAP 為多個(gè)查詢的平均正確率的均值。羅計(jì)根通過整理中醫(yī)書籍《中醫(yī)證候鑒別診斷書》和《中醫(yī)證候辨證論治輯要》,提出了一種結(jié)合雙向長(zhǎng)短期記憶網(wǎng)絡(luò)和條件隨機(jī)場(chǎng)的中醫(yī)命名實(shí)體識(shí)別模型,然后構(gòu)建了中醫(yī)實(shí)體抽取語料庫。為了更好地展示中醫(yī)實(shí)體及實(shí)體間的關(guān)系,建立了模式層的結(jié)構(gòu)。然后,作者利用TF-IDF(term frequencyinverse document frequency)算法分別對(duì)證候-癥狀、證候-舌像、證候-脈象三類關(guān)系之間的貢獻(xiàn)權(quán)重進(jìn)行計(jì)算。最后將實(shí)體、關(guān)系和權(quán)重導(dǎo)入到數(shù)據(jù)庫中完成知識(shí)圖譜的構(gòu)建,如圖4 所示。在中醫(yī)知識(shí)圖譜推理過程,中醫(yī)領(lǐng)域里面大部分的實(shí)體之間沒有存在直接的關(guān)系。例如,當(dāng)要查詢治療血虛證的證方中是否含有當(dāng)歸這味中藥時(shí),知識(shí)圖譜中中藥類實(shí)體和證候類實(shí)體并沒有直接的關(guān)系,這兩者是根據(jù)方劑相連接的,如圖5 所示。此時(shí),需要通過實(shí)體血虛證找到治療它的方劑,再根據(jù)方劑找到組成中是否含有該中藥。因此,為了更好地對(duì)構(gòu)建的中醫(yī)知識(shí)圖譜進(jìn)行實(shí)際應(yīng)用,提出了一種基于路徑的推理算法。
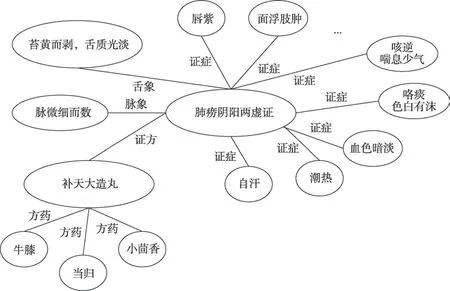
圖4 中醫(yī)領(lǐng)域構(gòu)建的知識(shí)圖譜Fig.4 Constructed knowledge graph in field of traditional Chinese medicine

圖5 知識(shí)圖譜中的間接關(guān)系Fig.5 Indirect relationship in knowledge graph
目前基于深度學(xué)習(xí)的知識(shí)圖譜推理在醫(yī)學(xué)領(lǐng)域的探索和工作研究處在初始階段,仍有很多可以進(jìn)步的空間。
3.4 小結(jié)與討論
本節(jié)對(duì)現(xiàn)有的醫(yī)學(xué)知識(shí)推理技術(shù)進(jìn)行了廣泛的綜述,并對(duì)其推理方法進(jìn)行了分類:基于邏輯規(guī)則的醫(yī)學(xué)推理、基于表示學(xué)習(xí)的醫(yī)學(xué)推理以及基于深度學(xué)習(xí)的醫(yī)學(xué)推理。這三種方法既有相似之處又有區(qū)別,在推理任務(wù)中是可以互相補(bǔ)充的。相似之處是這些方法都是對(duì)知識(shí)圖譜中的三元組進(jìn)行特征建模和參數(shù)學(xué)習(xí)。主要區(qū)別在于基于深度學(xué)習(xí)的知識(shí)推理模型將CNN、RNN 和GNN 集成到表示學(xué)習(xí)模型或邏輯規(guī)則模型中,通過深度學(xué)習(xí)模型對(duì)知識(shí)圖譜中的實(shí)體和實(shí)體間關(guān)系進(jìn)行學(xué)習(xí),然后通過實(shí)體之間的序列路徑建立預(yù)測(cè)模型進(jìn)行相關(guān)推理。表示學(xué)習(xí)模型主要是學(xué)習(xí)實(shí)體和關(guān)系的低維嵌入表示,并基于此語義表示進(jìn)行后續(xù)的醫(yī)學(xué)推理。其優(yōu)點(diǎn)是可以充分利用知識(shí)圖譜中的結(jié)構(gòu)信息,缺點(diǎn)是建模時(shí)不能引入先驗(yàn)知識(shí)來實(shí)現(xiàn)推理。邏輯規(guī)則模型的優(yōu)點(diǎn)是可以模擬人類的邏輯推理能力,并映入人類的先驗(yàn)知識(shí)來進(jìn)行輔助推理。缺點(diǎn)是它沒有解決對(duì)領(lǐng)域?qū)<业囊蕾囆裕?jì)算復(fù)雜度高,泛化能力比較差。在醫(yī)學(xué)知識(shí)圖譜領(lǐng)域,目前的醫(yī)學(xué)推理方法雖然促進(jìn)了醫(yī)學(xué)診斷自動(dòng)化和智能的進(jìn)程,但仍存在著學(xué)習(xí)能力不夠強(qiáng)、醫(yī)學(xué)知識(shí)和數(shù)據(jù)利用率較低等缺陷。為了解決上述問題,需要探索和研究高效的混合醫(yī)學(xué)推理模型。表3 羅列并對(duì)比了不同知識(shí)推理方法。

表3 醫(yī)學(xué)知識(shí)推理方法Table 3 Medical knowledge reasoning methods
4 挑戰(zhàn)及展望
醫(yī)學(xué)知識(shí)圖譜構(gòu)建和醫(yī)學(xué)推理技術(shù),將會(huì)成為知識(shí)圖譜和人工智能領(lǐng)域的熱點(diǎn)研究對(duì)象,其研究成果能夠推動(dòng)醫(yī)學(xué)自動(dòng)化和智能化進(jìn)程,促進(jìn)智能醫(yī)學(xué)應(yīng)用的研發(fā)。本章總結(jié)了醫(yī)學(xué)知識(shí)推理目前面對(duì)的一些挑戰(zhàn)和重要問題,并展望了其發(fā)展前景和研究趨勢(shì),希望能促進(jìn)這一快速發(fā)展領(lǐng)域的進(jìn)一步研究。
(1)現(xiàn)有的海量醫(yī)療數(shù)據(jù)在語言、功能、存儲(chǔ)等方面存在著比較大的差異。因此,知識(shí)復(fù)用、泛化能力和實(shí)體消歧等問題對(duì)醫(yī)學(xué)推理造成了極大的挑戰(zhàn)。深度學(xué)習(xí)的信息捕捉和特征映射能力已在其他人工智能領(lǐng)域得到了驗(yàn)證,而目前基于深度學(xué)習(xí)的知識(shí)圖譜推理在醫(yī)學(xué)領(lǐng)域的探索和工作研究處在初始階段,仍有很多可以進(jìn)步的空間。深度學(xué)習(xí)的表示學(xué)習(xí)能力和醫(yī)學(xué)知識(shí)推理的結(jié)合,將顯著提升推理學(xué)習(xí)的性能,并帶動(dòng)工業(yè)界和學(xué)術(shù)界的發(fā)展。
(2)現(xiàn)有的醫(yī)學(xué)知識(shí)推理方法通常需要很多高質(zhì)量的醫(yī)學(xué)知識(shí)和數(shù)據(jù)樣本進(jìn)行訓(xùn)練和學(xué)習(xí),然后才能完成有效的推理。而這需要消耗醫(yī)生專家和研究人員大量的時(shí)間和精力對(duì)醫(yī)學(xué)數(shù)據(jù)和樣本進(jìn)行標(biāo)注,成本和代價(jià)高昂。此外,訓(xùn)練所得到的模型的泛化能力通常也比較差。而人類常常可以根據(jù)少量樣本學(xué)習(xí),然后舉一反三即可完成推理。如何實(shí)現(xiàn)小樣本或者零樣本學(xué)習(xí)推理是一個(gè)挑戰(zhàn)。最近幾年,零樣本學(xué)習(xí)(zero-shot learning)和少樣本學(xué)習(xí)(fewshot learning)在計(jì)算機(jī)視覺及自然語言處理等領(lǐng)域引起了廣泛的關(guān)注。零樣本學(xué)習(xí)和少樣本學(xué)習(xí)可以從一個(gè)未遇到過的類別或者只有很少的樣本實(shí)例中學(xué)習(xí)。結(jié)合零樣本學(xué)習(xí)和少樣本學(xué)習(xí)的醫(yī)學(xué)知識(shí)推理可以避免高昂的數(shù)據(jù)獲取,提高推理泛化能力,值得進(jìn)一步研究。
(3)醫(yī)學(xué)知識(shí)推理的可視化可以讓醫(yī)生和患者更加直觀地了解到推理的詳細(xì)過程和依據(jù)結(jié)果。在醫(yī)療領(lǐng)域,由于醫(yī)生和患者的知識(shí)背景不同,如何提高醫(yī)生和患者之間的溝通效率是一件困難的事情。醫(yī)學(xué)推理可視化可以做到“換位思考”,即分別從醫(yī)生和病人的角度,展示出最佳的推理方案,讓病人能夠明白診斷的過程和依據(jù)結(jié)果,醫(yī)生則可以根據(jù)知識(shí)圖譜的動(dòng)態(tài)推理做出合理高效的醫(yī)療診斷,從而達(dá)到輔助診斷、智能診斷的目的,也可以帶給病患更友好的就診體驗(yàn)。
(4)傳統(tǒng)醫(yī)學(xué)知識(shí)推理的方法只考慮了圖譜中三元組本身的結(jié)構(gòu)信息,知識(shí)信息利用不全面,也在一定程度上造成了推理準(zhǔn)確度不高。如何更高效地利用知識(shí)圖譜的圖結(jié)構(gòu)信息和外部專家知識(shí)是進(jìn)一步提升推理性能的關(guān)鍵問題。不同模態(tài)、不同來源的醫(yī)學(xué)數(shù)據(jù),比如醫(yī)療文本、醫(yī)療影像等中蘊(yùn)含著豐富的、可以相互補(bǔ)充的醫(yī)學(xué)知識(shí)和信息。可以利用多模態(tài)和多源數(shù)據(jù)融合的方法進(jìn)行更加可靠的知識(shí)推理,從知識(shí)增強(qiáng)的角度進(jìn)一步提高知識(shí)推理的性能。同時(shí),知識(shí)圖譜中的關(guān)系預(yù)測(cè)路徑長(zhǎng)度會(huì)隨著知識(shí)圖譜的增大不斷增長(zhǎng),而現(xiàn)有的主要方法中預(yù)測(cè)長(zhǎng)路徑的能力有限。推理性能隨著路徑的長(zhǎng)度逐漸降低。然而,在大規(guī)模醫(yī)學(xué)知識(shí)圖譜中,實(shí)體之間的長(zhǎng)路徑推理不可避免。因此需要更高效的推理模型來描述更復(fù)雜的推理任務(wù)。
(5)醫(yī)學(xué)知識(shí)圖譜中醫(yī)學(xué)知識(shí)的有效性通常會(huì)受到空間以及時(shí)間等動(dòng)態(tài)因素的影響。如何更加合理地利用這些醫(yī)學(xué)知識(shí)的動(dòng)態(tài)約束信息進(jìn)行動(dòng)態(tài)推理也是醫(yī)學(xué)知識(shí)推理目前面臨的難題和一大挑戰(zhàn)。比如,疾病的誘發(fā)、緩解和治愈是一個(gè)逐漸發(fā)展演變的歷程,因此醫(yī)學(xué)知識(shí)推理需要結(jié)合病人在醫(yī)治過程中產(chǎn)生的歷史臨床數(shù)據(jù)進(jìn)行推理。但是,目前的推理模型還無法結(jié)合病人治療過程中動(dòng)態(tài)產(chǎn)生的臨床事實(shí)序列,因此不能夠總是給出正確的推理結(jié)果。設(shè)計(jì)能夠根據(jù)醫(yī)學(xué)知識(shí)的有效性進(jìn)行動(dòng)態(tài)推理的模型是必要的。
(6)患者自我診斷。如何解決醫(yī)生短缺這個(gè)醫(yī)療領(lǐng)域的難題是一個(gè)挑戰(zhàn)。培養(yǎng)一個(gè)經(jīng)驗(yàn)豐富的醫(yī)生需要較長(zhǎng)的時(shí)間。基于知識(shí)推理技術(shù)的智能問診在解決該難題方面有巨大的潛力。智能問診系統(tǒng)主要是患者與機(jī)器進(jìn)行交互,患者通過輸入自身基本信息,比如患病癥狀、既往病歷和過敏史等,系統(tǒng)可以通過知識(shí)推理技術(shù)進(jìn)行分析,然后形成原始的診斷結(jié)果,極大減短了問診的時(shí)間,提高了問診的效率。同時(shí),患者也可以通過人機(jī)交互來進(jìn)行智能查詢與診斷,比如誘發(fā)病因、用藥、治療方案等,最終可以生成診斷報(bào)告,從而進(jìn)行自我辨別診斷。
5 結(jié)束語
從大量的醫(yī)療數(shù)據(jù)中提取出醫(yī)學(xué)知識(shí),然后構(gòu)建醫(yī)學(xué)知識(shí)圖譜,對(duì)其進(jìn)行高效利用,是推進(jìn)醫(yī)學(xué)智能化和自動(dòng)化改革的關(guān)鍵,對(duì)智能醫(yī)療的實(shí)現(xiàn)有著重要意義。同時(shí),也能夠?yàn)獒t(yī)學(xué)知識(shí)檢索、醫(yī)學(xué)輔助診斷以及醫(yī)學(xué)檔案的智能化管理提供基礎(chǔ)。本文對(duì)構(gòu)建醫(yī)學(xué)知識(shí)圖譜的關(guān)鍵技術(shù)和醫(yī)學(xué)輔助診斷進(jìn)行了總結(jié)與歸納,并重點(diǎn)回顧了醫(yī)學(xué)知識(shí)推理研究現(xiàn)狀,對(duì)其推理方法進(jìn)行了分類。對(duì)于每一類別,分別介紹了代表性算法和最新研究進(jìn)展。最后,本文總結(jié)了醫(yī)學(xué)知識(shí)推理目前面對(duì)的一些挑戰(zhàn)和重要問題,并展望了其發(fā)展前景和研究趨勢(shì)。醫(yī)學(xué)知識(shí)推理仍有很多尚未完善和可創(chuàng)新的工作,需要更多的學(xué)者和研究人員共同推進(jìn)該領(lǐng)域的發(fā)展。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
