計算機視覺視域下物體抓取識別算法研究
2022-06-08 02:42:44王海寬
晉城職業(yè)技術(shù)學(xué)院學(xué)報 2022年3期
關(guān)鍵詞:模型
王海寬
(晉城職業(yè)技術(shù)學(xué)院,山西 晉城 048026)
目前在深度學(xué)習(xí)的計算機視覺之下,在對圖像進行識別的時候往往采取檢測、對比和分類的方式展開。在檢測的時候,一方面要保證物體上具有十分清晰的標簽,另一方面,要求采取合適的方式將物體具體位置標注清楚,以簡單的操作來避免在后期處理期間出現(xiàn)大量人力資源和物力資源消耗。就某些實際場景而言,例如在自動駕駛環(huán)境下,需要對過往的行人和行駛的車輛作出檢測,明確目標所在位置。基于計算機視覺領(lǐng)域任務(wù)不同,在解釋弱監(jiān)督學(xué)習(xí)時也有所不同,基本上分為以下兩種:第一種是對于圖像中所出現(xiàn)的物體進行標明;第二種是模型在學(xué)習(xí)的過程當(dāng)中,僅僅是將物體存在的相關(guān)信息提供給設(shè)備,而不必將物體真實出現(xiàn)的位置提供給設(shè)備。詳細地說,便是識別算法僅僅需要將目標視域下的物體數(shù)量和類別作出感應(yīng)即可。基于此種數(shù)據(jù)集所獲得的模型可以順利地推斷出全新的數(shù)據(jù)信息,直接將目標的數(shù)量和種類計算得出。
一、計算機視覺視域下識別物體
(一)構(gòu)建識別物體網(wǎng)絡(luò)結(jié)構(gòu)模型
當(dāng)神經(jīng)網(wǎng)絡(luò)加深時,則表明神經(jīng)網(wǎng)絡(luò)在表示具有復(fù)雜性的特征時,會表現(xiàn)出更好的能力。但是,若只是將網(wǎng)絡(luò)的深度采取加深處理,也會在一定程度上導(dǎo)致在反向傳播的算法之中發(fā)生梯度傳播的異常現(xiàn)象,最終得到的結(jié)果是訓(xùn)練的神經(jīng)網(wǎng)絡(luò)失去效果。若是想要解決這種問題,那么靈活性地運用BatchNormalization方法或者是權(quán)重初始化的方法便是最好的解決方案。但是,即使是有了這兩種方法,若是持續(xù)加深網(wǎng)絡(luò)深度,模型訓(xùn)練結(jié)果的準確性也不會再次被提升,甚至準確率出現(xiàn)不同程度的下降,這種現(xiàn)象為訓(xùn)練準確率下降。根據(jù)退化結(jié)果顯示,想要對深層模型展開合理化的訓(xùn)練,面臨較大的困難。于是ResNet為解決出現(xiàn)的深度學(xué)習(xí)模型退化的問題,提出了殘差學(xué)習(xí)法。
將輸入的數(shù)據(jù)假設(shè)為x,普遍情況下神經(jīng)網(wǎng)絡(luò)在學(xué)習(xí)映射H(x)的過程中,需要借助于幾個不同的堆疊層。ResNet學(xué)習(xí)的內(nèi)容是神經(jīng)網(wǎng)絡(luò)模型映射與輸出時所產(chǎn)生的殘差,即:

將公式1.1變換形式,得到的結(jié)果如下所示:

盡管在計算的環(huán)節(jié)之中,這兩種方法表示的內(nèi)容呈等價形式,但是通過實際的試驗結(jié)果得知,在訓(xùn)練的時候,運用殘差學(xué)習(xí)更加容易。ResNet的殘差學(xué)習(xí)法在研究的時候,通過使用幾個不同的堆疊殘差模塊表示出來,可以把殘差結(jié)果的形式轉(zhuǎn)化成為以下方式:
y=F(x,{Wi})+x (公式1.3)
在公式1.3當(dāng)中,F(xiàn)(x,{Wi})所表示的含義主要是需要進行學(xué)習(xí)的殘差映射。
通過圖1可以得知,殘差映射的結(jié)構(gòu)總共有兩層,可以對其表示如下:
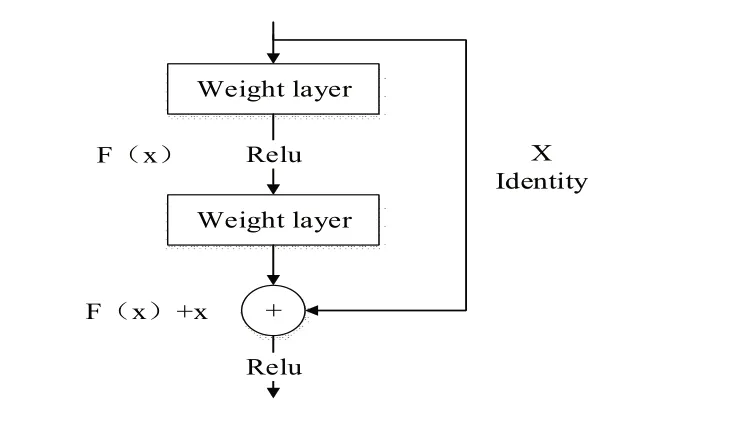
圖1 學(xué)習(xí)殘差結(jié)構(gòu)圖

公式1.4中,a所表示的含義為Relu激活函數(shù)。在圖1.1之中,總共劃分成為兩層,在實現(xiàn)ResNet殘差學(xué)習(xí)的時候,大量的選擇運用了兩層殘差結(jié)構(gòu)或者是三層殘差結(jié)構(gòu),但是在實際ResNet殘差學(xué)習(xí)過程中,卻沒有對數(shù)量的限制問題。若是僅僅有一層的時候,那么殘差結(jié)構(gòu)將會類比為一個線性層,所以在分析環(huán)節(jié),已經(jīng)不再有必要可用單層殘差結(jié)構(gòu)。
F(x)+x在ResNet殘差學(xué)習(xí)實現(xiàn),需要通過連接shortcut元素和相加逐元素,將其相加以后,獲得的結(jié)果將會在下一個Relu激活函數(shù)中被使用。從本質(zhì)上而言,shortcut連接所實現(xiàn)的功能是恒等映射(Indentity Map)在模型當(dāng)中輸入的x值。倘若是情況相對比較計算,那么獲得的殘差F(x)結(jié)果將會為零,從而導(dǎo)致整個殘差模塊只能夠完成一次恒等映射。這種現(xiàn)象是受神經(jīng)網(wǎng)絡(luò)直接決定的。假如x與F(x)所處的維度存在差異,那么在促使兩個數(shù)值的維度相同的時候,可以借助于公式1.5:

但是通過ResNet殘差學(xué)習(xí)的試驗結(jié)果可以得到,在解決退化的問題中,運用恒等映射具有積極作用,同時還相對比較簡單,在計算的時候,復(fù)雜度低且計算量不高。ResNet殘差學(xué)習(xí)結(jié)構(gòu)能夠為深度學(xué)習(xí)模型退化的問題提供解決方案。ResNet殘差學(xué)習(xí)模型在ImageNet數(shù)據(jù)集之上,最深能夠達到152層,并且擁有相對較高的準確率。
(二)損失函數(shù)分析
損失函數(shù)(Loss Function)衡量模型所表現(xiàn)出的含義為選擇樣本X標簽y和預(yù)測值Y之間的差異化程度,其中X的取值為{x1,x2,……,xn},y的取值為{y1,y2,……,yn},Y的取值為{Y1,Y2,……,Yn},損失函數(shù)模型差異程度的結(jié)果記作L(Y,y)。經(jīng)過計算得知,損失函數(shù)所獲得的結(jié)果為非負數(shù),函數(shù)結(jié)果的幅值和預(yù)測的準確度兩者之間呈現(xiàn)出負相關(guān)關(guān)系。在分析損失函數(shù)的時候,最為常用的類型基本上可以分為以下幾種。
第一,0-1損失函數(shù)(0-1 Loss Function),其表現(xiàn)形式如下所示:

第二,平方損失函數(shù)(Quadratic Loss Function),其表現(xiàn)形式如下所示:

第三,絕對損失函數(shù)(Absolute Loss Function),其表現(xiàn)形式如下所示:

第四,對數(shù)損失函數(shù)(Logarithmic Loss Function),其表現(xiàn)形式如下所示:

以計算機視覺所特定的任務(wù)作為出發(fā)點,在實施任務(wù)的時候要以特定編碼方式作為依據(jù),進而能夠快速且準確地得到損失函數(shù)的標簽y。
在機器的學(xué)習(xí)環(huán)節(jié),一般情況下在實現(xiàn)某個特定任務(wù)的時候,需要對單個模型展開優(yōu)化和設(shè)計,比如想要實現(xiàn)圖像分類任務(wù),可以通過CNN設(shè)計實現(xiàn)目標。大多數(shù)情況下,為了切實保障設(shè)計與學(xué)習(xí)環(huán)節(jié)獲得良好的效果,提升結(jié)果的準確度。另外,在對預(yù)測結(jié)果實施優(yōu)化期間,還可選擇應(yīng)用集成學(xué)習(xí)(Ensemble Leaning)的策略,從而實現(xiàn)優(yōu)化的目標。在保證其他任務(wù)環(huán)節(jié)處理妥帖的時候,使用遷移學(xué)習(xí)法(Transfer Leaning)快速獲取模型。利用多任務(wù)識別(Multi-Task Leaning)對不同任務(wù)共性和相似展開識別的能力,完成對不同的任務(wù)進行學(xué)習(xí)的目的,完成訓(xùn)練的模型具備處理多種任務(wù)的能力。
在深度學(xué)習(xí)的領(lǐng)域當(dāng)中,多任務(wù)學(xué)習(xí)需要以相關(guān)指標作為依據(jù),劃分成兩個層面。第一種是隱含層的硬件參數(shù)共享(Hard Parameters Sharing),第二種是隱含層的軟件參數(shù)共享(Soft Parameters Sharing)。神經(jīng)網(wǎng)絡(luò)中,硬參數(shù)共享是使用較為頻繁的方法,這種方法的使用能夠?qū)崿F(xiàn)對不同操作任務(wù)實施共享權(quán)重的目的,在任務(wù)之中完成對于不同輸出層的添加工作。[1]在軟參數(shù)共享當(dāng)中,所有的任務(wù)都具有獨特的參數(shù)和模型,但是在實際的運用環(huán)節(jié),會因為部分措施的使用發(fā)現(xiàn)參數(shù)之間存在的相似性。
構(gòu)建的模型,其主要目標是將圖像之中所出現(xiàn)目標的不同種類、種類的不同數(shù)量展開快速識別。就識別目標種類的時候,是分類標簽的過程,識別目標數(shù)量,則是屬于回歸性質(zhì)的問題。[2]
(三)實現(xiàn)平臺分析
訓(xùn)練和推斷深度神經(jīng)網(wǎng)絡(luò)的時候,CPU所具備的計算結(jié)構(gòu)是多核且并行的,流處理器的數(shù)量在普遍情況下能夠達到數(shù)千個,在深度學(xué)習(xí)的環(huán)節(jié)之中,可以實現(xiàn)矩陣計算的優(yōu)化目標,表現(xiàn)出良好的可行性。[3]
二、計算機視覺視域下識別物體行為
(一)數(shù)據(jù)集分析
行為識別模型在構(gòu)建的時候,其訓(xùn)練集則是運用了開源的MERL Shopping Dataset,并且構(gòu)建完成的模型可以在便利店中進行使用,通過觀察獲得模型的良好表現(xiàn)結(jié)果。[4]
MERL Shopping Dataset的組成是106段大約有兩分鐘時間長度的視頻,三部分分別為訓(xùn)練集部分、驗證集部分、測試集部分。利用MERL Shopping Dataset嚴格劃分了數(shù)據(jù)集,為后期的對比效果獲取提供便利。另外對訓(xùn)練完好的模型投放進入真實的環(huán)境下展開實驗,MERL Shopping Dataset能夠?qū)υ诒憷甑恼鎸嵀h(huán)境中展開購物活動的試驗人員,參與到試驗活動的相關(guān)人員,在每做出一個動作的時候,形成細粒度(Fine-Grained),試驗人員會在識別的范圍之內(nèi)作出五種不同的動作,數(shù)據(jù)集便通過使用對起始幀和結(jié)束幀展開標準的方式,對識別單位之內(nèi)的人員所表現(xiàn)出來的動作基本類別作出相應(yīng)的分析與識別。在本文的分析過程中,需要標注好試驗活動參與人員的每個動作,將他們的活動行為間隔定義為episode。
(二)物體運行行為信息
就識別物體運動的行為而言,將運動信息提取完成具有至關(guān)重要的作用,在組織識別任務(wù)期間,光流法是最為有效的措施之一。這種方法基本原理是光流在運動期間,運動目標外表保持穩(wěn)定。[5-6]FlowNet是自文獻資料查閱中,最早通過使用網(wǎng)絡(luò)端對端得到光流算法的,但是其實現(xiàn)的效果和具有的優(yōu)勢,仍舊沒有達到傳統(tǒng)算法效果和優(yōu)勢。深化研究FlowNet研究,效果獲得了顯著提升,但是其仍舊只能在小位移的物體運動活動中具有合理性。就本次研究所使用的數(shù)據(jù)集而言,后期研究得到的FlowNet所得到的效果如圖2所示:

圖2 FlowNet光流運動信息
(三)構(gòu)建識別物體行為網(wǎng)絡(luò)結(jié)構(gòu)模型
識別物體行為的模型構(gòu)建是基于雙流神經(jīng)網(wǎng)絡(luò),VGG-16卷積層部分被運用在時序流和空域流兩個部分的基礎(chǔ)網(wǎng)絡(luò)工作之中。在訓(xùn)練的時候,是將空域流和時間流分離的,但是可全部運用交叉熵損失函數(shù)完成數(shù)據(jù)分析。在測試時序流和空域流期間,兩者的網(wǎng)絡(luò)運行狀態(tài)處于并行狀態(tài),利用Softmax實現(xiàn)五維向量輸出,得到的結(jié)果表示六個不同類別的置信度。本文在探究中所選擇的方式是遲融合,相加時序流和空域流兩部分網(wǎng)絡(luò)所輸出的五維向量,最終所得到的預(yù)測結(jié)果是兩部分相加結(jié)果的最大值。
在對測試結(jié)果展開統(tǒng)計的時候,將所有的episode劃分成多個segment,所有的segment構(gòu)成全部是呈連續(xù)狀態(tài)的6幀圖像,倘若最后的episode幀數(shù)不能夠被6整除的時候,那么處于最后一段的segment將會從前面部分的segment當(dāng)中取出幾幀具有重疊現(xiàn)象的圖像,以此來湊滿6幀。本文在探究活動中通過使用投票的方式對構(gòu)建的模型準確率情況展開評估,利用某段episode當(dāng)中的所有segment作為投票的依據(jù),并獲得最終的結(jié)果。
在識別物體行為的時候,其基本模型框架如圖3所示。
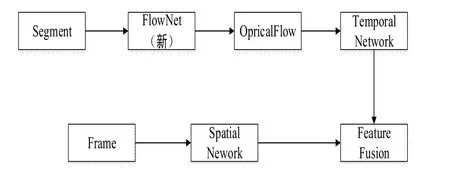
圖3 識別物體行為的模型框架圖
識別物體行為的模型在應(yīng)用以后,獲得的結(jié)果如表1所示:

表1 識別物體行為的模型實驗結(jié)果表
三、結(jié)語
對于物體的識別是人工智能發(fā)展的結(jié)果之一,在識別物體的領(lǐng)域中,相對而言具有新穎性和創(chuàng)新性。在識別物體時運用物體識別技術(shù),可以借助于運用弱監(jiān)督學(xué)習(xí)的方法展開學(xué)習(xí)訓(xùn)練,提升物體識別系統(tǒng)在識別物品種類和數(shù)量時的精確性,進而有效地將視頻數(shù)據(jù)作出分類,達到識別物體的目的。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
