可重構結構下四叉樹編碼劃分并行設計與實現
2022-06-02 06:57:46李遠成
無線電工程 2022年6期
關鍵詞:模型
王 欣,蔣 林,曹 非,李遠成
(1.西安科技大學 電氣與控制工程學院,陜西 西安 710600;2.西安科技大學 計算機科學與技術學院,陜西 西安 710600)
0 引言
高效視頻編碼(High Efficiency Video Coding,HEVC)標準是新一代視頻編碼國際標準。與上一代標準H.264/AVC相比,在編碼結構上放棄了宏塊的概念[1],采用了對圖像進行四叉樹劃分的方式。這種四叉樹遞歸結構在將壓縮效率提升了1倍的同時,也極大地增加了編碼計算復雜度與編碼時間[2]。因此,降低四叉樹編碼過程中的計算復雜度與減少編碼時間是研究的問題之一[3]。
針對高效視頻編碼中編碼復雜度高的問題,一些研究通過算法的簡化,降低四叉樹編碼復雜度[4]。文獻[5]針對快速編碼單元(Coding Unit,CU)編碼過程中四叉樹遍歷計算出現的冗余信息,提出了一種靈活的復雜度分配機制,該分配機制將CU深度決策問題轉換為分類問題。但是,該方法存在計算量大和存儲成本高的問題。從視頻編碼算法的角度考慮[6],優化后的算法計算量仍然巨大,單從算法層面去進行優化[7-8],仍然無法滿足實時視頻編碼的需求。所以,在優化編碼算法的同時,采用FPGA進行并行加速也是提升編碼效率的一種更有效的方式。文獻[9-11]在優化編碼算法的同時進行了FPGA加速,縮短了編碼時間,但也占用了較大的硬件資源和專用的DSP。文獻[10]基于多核處理器實現了解碼器,雖然有效利用了多核的并行性,但其使用了多達64個處理單元,硬件成本較高。
針對高效視頻編碼中編碼復雜度高的問題,可以通過FPGA加速來提高編碼效率。利用硬件加速器來實現視頻編碼加速,執行計算密集型算法,以滿足視頻應用的性能要求,是當前的研究熱點。四叉樹編碼算法的數據以CU的形式參與運算,運算步驟相對獨立,計算過程中數據依賴性低,具有較高的并行性,適合可重構陣列處理器進行并行運算。四叉樹編碼的過程中會將圖像的數據最大劃分為樹形結構單元(Coding Tree Unit,CTU),且編碼過程可以劃分成不同的模塊,不同的CTU間便可以采用流水線作業思想進行加速作業。
綜上所述,基于可重構陣列處理器,提出了一種新的四叉樹CU劃分并行化設計方案,在不考慮功耗的情況下,重點研究設計方案在并行加速與硬件資源消耗等方面的性能,實現四叉樹CU在可重構陣列上的高效靈活部署。
1 四叉樹CU劃分算法及并行性分析
1.1 四叉樹CU劃分算法
HEVC編碼結構首先是將視頻劃分為圖像組(Group of Picture,GOP),CTU是HEVC里的基本處理單元。在每個CTU內部按照四叉樹的循環分層結構劃分為不同的CU,CU是HEVC總體框架的基本單元。一幅圖像劃分為CTU以及一個CTU劃分為CU的圖像,劃分結構示意圖如圖1所示。
CU的循環四叉樹分層結構如圖2所示。CU是否繼續劃分取決于分割標志位(Splitflag)。對于編碼單元CUd,假設其大小為2N×2N,深度為d。若它對應的Splitflag值為0,則CUd不再進行劃分;反之,CUd將會作為四叉樹劃分的根源被劃分為4個獨立的編碼單元CUd+1,編碼單元CUd+1的深度和大小變為d+1和N×N。HEVC標準中最大的編碼單元(Largest Coding Unit,LCU)為64×64。

圖1 圖像劃分結構示意Fig.1 Schematic diagram of image division structure
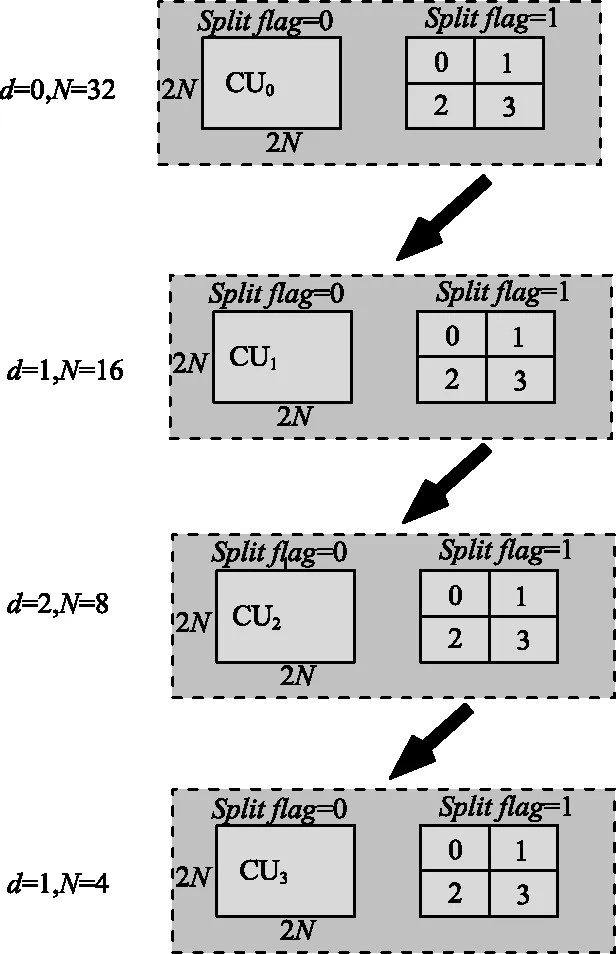
圖2 CU的循環四叉樹分層結構Fig.2 Cyclic quadtree hierarchical structure of coding unit
在HEVC測試模型參考軟件中會有很多種可能的分割方法,通過尋找率失真(Rate Distortion,RD)最小的方法作為最佳分割[12]。率失真的計算公式如下:
J=SATD(S,P)+λmodeRmode,
(1)
式中,SATD(S,P)為經過幀內預測后得到的殘差塊的SATD;λmode為拉格朗日因子;Rmode為編碼當前模式所需要的比特數。SATD是指將殘差信號進行哈達瑪變換后再求元素絕對值之和。
算法對每個CU均進行率失真的計算,計算方法如下:
JCUi=JCU0+JCU1+JCU2+JCU3,
(2)
式中,JCUi(i=0,1,2,3)表示當前CU的率失真;JCU0,JCU1,JCU2,JCU3表示分割后4個更小的CU的率失真。
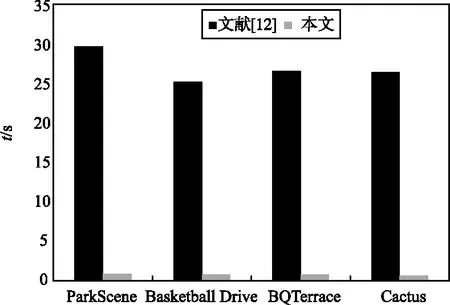
通過遞歸的方式獲取所有的CU的率失真,對每一深度進行分割后CU與分割前CU的率失真比較,選取率失真小的作為最優CU分割方法。若J分割前>J分割后,此時Splitflag值為1,CUd將會作為四叉樹劃分的根源被劃分為4個獨立的編碼單元CUd+1。若J分割前 HEVC這種靈活的單元表示方法可以使得在平緩區域編碼效率大大提高的同時提供數據并行處理的結構單元。 考慮到HEVC標準的特點,在四叉樹編碼劃分的過程中信息劃分為相互獨立的部分,每一部分交給不同的處理單元PE來處理。結合分布式共享存儲結構,從數據級并行的角度進行算法加速。數據并行實現示意圖如圖3所示。 圖3 并行實現示意Fig.3 Schematic diagram of data parallel implementation 在CTU進行四叉樹編碼劃分的內部,由于每個CTU的數據之間要進行比較判別運算,相鄰數據之間存在依賴關系,因此,可將CTU劃分成不同的塊,多塊CTU被分別送到不同的PE處理單元中并行進行判別運算處理,當每個PE處理結果出現判別結束的標志時,將這個PE的輸出結果基于CTU到CU間的循環嵌套分層結構再進行下一層次的判別運算。若所有進行多塊CTU的PE劃分到最后,則將多塊CTU的數據再整合進行判別,最終得到編碼劃分結果。在整個HEVC編碼過程中,可以分為不同的模塊,主要進行數據加載、率失真的計算與比較、不同深度的數據劃分和編碼劃分結果的輸出,各個功能的模塊組成串行的四級流水,而分別在各個模塊的內部,針對不同的子數據進行數據并行。這樣,在四叉樹CU的劃分過程中基于可重構陣列處理器混合功能并行和數據并行2種并行方式對編碼過程進行加速。 可重構陣列處理器(基于FPGA實現的BEE4平臺),能夠滿足四叉樹CU劃分的并行化設計需求[13]。可重構陣列處理器由主控器和可重構處理單元陣列組成。可重構陣列處理器的部分硬件結構如圖4所示,主要包括數據輸入存儲、陣列處理器、全局控制器、指令存儲器和數據輸出存儲器5部分。 圖4 可重構陣列處理器部分硬件結構Fig.4 Part of the hardware structure of the reconfigurable array processor 可重構陣列處理器結構中每16個處理單元(Process Element,PE)組成一個簇(Processing Element Group,PEG),采用4×4的矩陣結構。采用分布式共享存儲結構,這種結構是一種最直接且并行度很高的高速交換單元結構。在邏輯上整個片上存儲采用統一的編址方式,在物理上分布于各個PE,實現了存儲的并行訪問。具有“邏輯共享、物理分布”特性的分布式存儲結構,所表現出的并行化設計優勢,適合四叉樹編碼劃分算法這種數據密集型算法。 基于可重構陣列處理器硬件結構以及1.2節中四叉樹編碼劃分的并行性分析,從功能并行和數據并行2種并行方式對編碼過程進行加速及映射實現。 2.2.1 基于分布式存儲的并行映射實現——數據并行 四叉樹編碼劃分的16個PE并行映射圖如圖5所示。 步驟1:將要劃分的原始圖像幀數據存儲在數據輸入存儲DIM中。PE00與DIM相連,將外部存儲中原始的一幀圖像分為64 pixel×64 pixel的CTU數據通過PE進行數據下發,分別下發給00~33號這16個PE。 步驟2:每個PE并行對其數據進行判別運算,若PE中的數據判別結果Splitflag值為1,直接將PE的RAM中的16×16的CU塊數據分割成8×8的CU,此時輸出depth為3;若每個PE中判別結果Splitflag值為0,若PE00,PE01,PE10,PE11內數據判別Splitflag值均為0,則判別這4個PE的Splitflag值;若Splitflag值為1,此時輸出depth為2;與此同時,PE02,PE03,PE12,PE13;PE20,PE21,PE30,PE31;PE02,PE03,PE12,PE13均并行采取相同的操作。 步驟3:若PE00,PE01,PE10,PE11的輸出結果Splitflag值為0,且PE02,PE03,PE12,PE13的輸出結果Splitflag值為0;PE20,PE21,PE30,PE31的輸出結果Splitflag值為0;PE02,PE03,PE12,PE13的輸出結果Splitflag值為0,則判別這4部分的輸出的Splitflag值,若Splitflag值為1,則輸出depth為1;否則,輸出depth為0。 圖5 基于可重構陣列處理器的四叉樹編碼劃分映射Fig.5 Quadtree coding division mapping based on reconfigurable array processor 2.2.2 基于流水線加速并行——功能并行 在采用16個PE進行四叉樹編碼的過程中,可以將劃分過程分為數據加載、率失真的計算與比較、不同深度的數據劃分以及編碼劃分結果的輸出等不同的模塊。有的PE在算法的執行過程中會處于空閑狀態,為了最大化地減少編碼時間,使用如圖6所示的流水線方式實現CTU間并行加速,其中B1~Bm是指在四叉樹劃分過程中不同深度模塊的操作。 圖6中,將圖像的像素塊通過原始數據加載、Splitflag值計算、深度劃分和結果輸出這4個部分進行四叉樹編碼劃分。當第一個CTU數據加載完成后,第二個CTU開始原始數據加載。因此,采用此流水線方式能夠縮短編碼劃分的執行時間。采用16個PE進行四叉樹編碼劃分的方案采用流水線方式加速的設計方法,算法如下所示: if addparallel(“Quadtree”,1)finish∥激活四叉樹編碼劃分操作 The core 1exec Quadtree(image_orgin,image_code); endif addparallel(input,the_core)={ i=get_input_core_ID(input); if the coreiisfreedom∥確定處理單元是否空閑 return finish; else continue to wait;∥同步 endif} 其中,addparallel(“Quadtree”1)詢問處理單元是否處于freedom狀態,對于繁忙狀態則需要等待,進行線程同步;反之,直接進行運算處理。 圖6 四叉樹編碼劃分時空間流水線作業圖Fig.6 Spatial pipeline operation diagram of quadtree coding division 在編譯方式上,與通用編譯為單一目標處理器的匯編指令不同,可重構編譯通過軟硬件劃分,將劃分結果分別生成主控制器的控制碼以及配置陣列處理器上的配置信息。可重構陣列處理器的執行方式是通過主處理器將任務下發給可重構陣列處理器執行,采用主控制器選擇片上配置存儲器中的信息,將信息下發給處理簇PEG執行,每個簇再通過片上配置存儲器將存儲的可重構配置信息分配到PE中進行運算。 重構配置信息執行示意圖如圖7所示。首先,通過分析四叉樹CU的劃分算法與可重構陣列結構的關系得到四叉樹CU算法的配置信息。然后,將配置信息載入到片上配置存儲器,在可重構計算陣列執行時,載入PEG。最后,在并行執行的過程中,PEG00載入四叉樹編碼劃分配置信息后重復執行N次四叉樹編碼劃分,最后得到四叉樹編碼劃分的結果。 圖7 可重構配置信息執行示意Fig.7 Schematic diagram of reconfigurable configuration information execution 為了驗證四叉樹編碼并行化實現方案的可行性,在基于BEECube公司BEE4開發平臺搭建的可重構陣列處理器原型系統上進行驗證和測試[14]。首先,將算法代碼編譯為可重構陣列處理器匯編指令代碼;接著,用指令翻譯器將匯編代碼指令翻譯成二進制代碼;然后,使用Questasim10.1d進行功能仿真驗證,通過Xilinx公司的ISE14.7開發環境對設計進行綜合,并分析其性能;最后,在參考軟件HM中測試編碼性能,并將本文提出的四叉樹編碼劃分并行化方案在可重構陣列處理器測試平臺中進行FPGA硬件測試。 3.2.1 運行時間分析 實驗通過串行和并行2種實現方案對算法并行模塊運行時間做對比分析。算法的運行時間通過Qusetasim進行功能仿真得到。在depth_balloons測試序列中找到4種具有代表性的CTU劃分模型,如圖8所示。測試模型a不進行劃分,最大深度為0;測試模型b是一個深度為1的根節點劃分為最大深度3;測試模型c是一個深度為2的根節點劃分為最大深度3;測試模型d是全劃分為最大深度3。 在算法執行過程中,記錄4種測試模型從開始到結束的時間來計算運行時間。4種測試序列在不同實現方案下的運行時間對比如表1所示。 (a) 測試模型a (b) 測試模型b (c) 測試模型c (d) 測試模型d 表1 不同測試模型下不同方案運行時間對比 由表1可以看出,用于測試的4種測試模型a~d的數據量是逐步增加的,測試模型a~d體現并行性的程度是逐漸提高的。與單個PE串行相比,并行方案在4種測試模型下的平均加速比達到了9.64,在可重構陣列處理器上PE資源的使用比例,即在一個簇內的PE資源利用率提高了93.75%。 由統計的運行時間可以看出,并行加速比都隨著測試模型數據并行性的增加而增加。本文基于可重構陣列處理器所設計的并行方案在不同的測試模型中均可提高數據的并行性,減少編碼時間,特別是在數據量越大、數據劃分越復雜的情況下。因而針對四叉樹編碼這種數據密集型算法,并行方案能夠有效減少算法的運行時間。 文獻[15]提出了一種基于四叉樹模型的快速幀間編碼算法,同時考慮CU深度級別的邊緣信息,提出了一種快速CU劃分方案。根據提出的四叉樹模型和CU大小的相關性盡早確定可能的深度范圍,加快編碼過程。其實驗平臺為Inter? CoreTMi5 CPU,16 GB內存。本文基于可重構陣列處理器的結構特點進行算法的并行實現,減少編碼時間。采用本文所提出的并行化方案對PartScence,Basketballdrive,BQTerrace和Cactus測試序列進行編碼劃分,編碼時間對比如圖9所示。與文獻[15]相比,本文對測試序列Cactus進行四叉樹劃分的編碼時間減少最多,相比文獻[15]編碼時間總體提升約36倍。 圖9 編碼時間對比Fig.9 Coding time comparison chart 3.2.2 編碼性能對比分析 本文與3D-HEVC參考軟件(HM)中幾種測試序列在編碼過程中CU劃分結果分析統計并進行了對比,結果如圖10和11所示。 圖10 HM劃分結果Fig.10 HM division result 圖11 本文劃分結果Fig.11 Division results of test 從圖10和11中的數據對比可以得出,本文與HM測試模型相比編碼劃分結果的精準率為86%。 使用本文的方法作為編碼劃分的方法,選取了5組測試序列在BeeCube公司的BEE4搭建的可重構陣列處理器測試平臺中進行驗證測試。采用的峰值信噪比(Peak Signal to Noise Ratio,PSNR)和結構相似性(Structural Similariy Index Measurement,SSIM)是2種常用的圖像質量評價指標,對完整Ι幀的測試結果圖像進行分析,如表2所示,相比HM測試一個完整Ι幀的結果,平均PSNR值增加了2.425 1 dB,平均SSIM值為0.995 7。 表2 測試性能分析 3.2.3 硬件資源對比分析 為了更好地說明本文設計方案的優勢,將算法對應的硬件設計綜合情況與其他同類型文獻進行對比。實驗數據如表3所示,文獻[16]在Xilinx Virtex 6的開發平臺上設計基于HEVC的視頻編碼算法,硬件設計上采用全流水線方式工作,最大只能支持5條路徑并行,本文中支持最大16個PE并行。與本文相比,文獻[16]的LUT的資源與寄存器的資源消耗增加了很多;在實現了更高的并行度的情況下,本文方案硬件消耗相對較少,ISE硬件綜合資源消耗圖如圖12所示,LUT資源僅使用了31 730個,REG資源僅使用了9 664個。 圖12 硬件資源消耗Fig.12 Hardware resource consumption 文獻[17]在Xilinx Zynq ZC706上實現,編碼器以140 MHz的工作頻率實現編碼,工作頻率略高于本文。本文和文獻[17]在功能上都可以支持任意大小塊劃分。但相比于文獻[16],本文的硬件消耗(LUT資源+REG資源)減少62%,且沒有使用乘法器進行運算,使用加法器和移位操作代替乘法器進行運算,計算速度更快,無需使用DSP資源。 文獻[18]基于Virtex 7現場可編程門陣列設計硬件的混合并行和數據流級架構的HEVC編碼。在功能上可以支持任意大小塊劃分。相比于文獻[18],在工作頻率略高的情況下本文的硬件消耗也明顯減少。LUT資源僅占其使用量的28%,REG資源僅占其使用量的80%。 綜上所述,本文基于可重構陣列處理器的設計方案在較低的硬件消耗下實現了四叉樹編碼的并行化設計,并行加速比達到9.64,且在結構上具備靈活性。 表3 硬件結果對比 針對3D-HEVC標準中四叉樹編碼劃分存在的編碼復雜度高、數據量大、編碼時間長和資源消耗大的問題,基于可重構陣列處理器提出了一種新的四叉樹CU并行劃分方案,完成并行映射、功能仿真以及FPGA測試。該方案利用可重構陣列結構分布式共享存儲的特點,充分挖掘數據之間的并行性,實現計算資源PE的最大化利用,減少編碼劃分的時間。實驗結果表明,四叉樹CU劃分在更具備靈活性的同時,與單個處理單元PE串行相比,16個PE并行設計的加速比達到9.64,很大程度上減少了編碼時間。相比于文獻[12]編碼效率總體提升了約36倍。簇內PE的資源利用率提高了93.75%。與文獻[14]相比,在不使用DSP資源的情況下資源消耗降低了62%。與文獻[15]專用硬件對比,LUT資源消耗減少了78%,REG資源消耗減少了20%。總之,基于可重構陣列處理器的四叉樹編碼并行劃分方案,在不影響編碼質量的同時,提升了編碼效率,且硬件資源消耗也相對較少。1.2 四叉樹編碼劃分的并行性分析

2 基于可重構陣列處理器的四叉樹編碼劃分并行實現
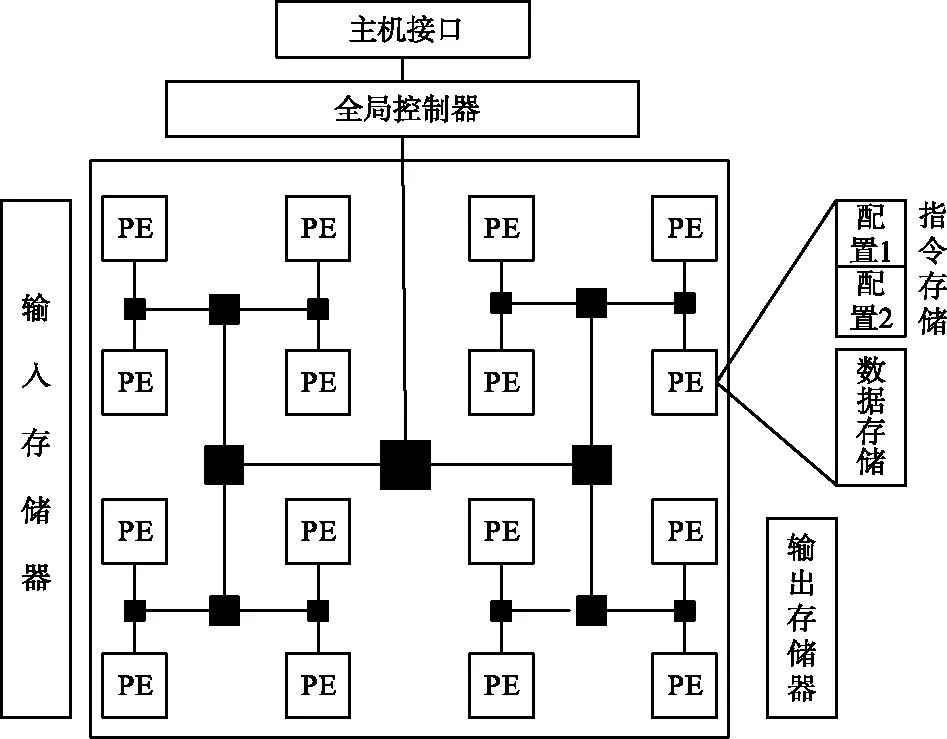
2.1 可重構陣列處理器硬件結構
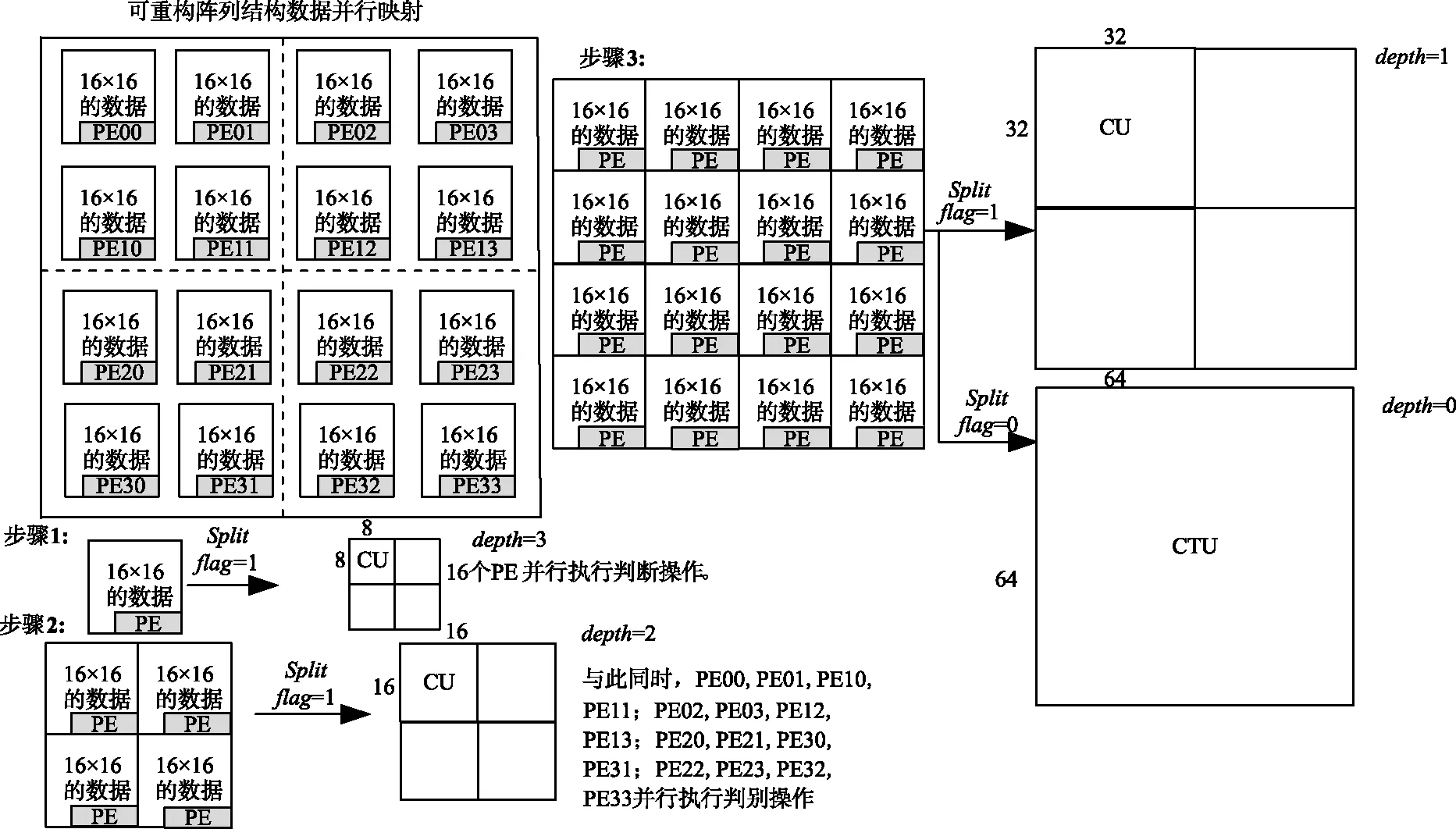
2.2 四叉樹編碼劃分并行實現
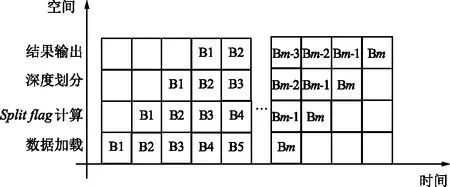
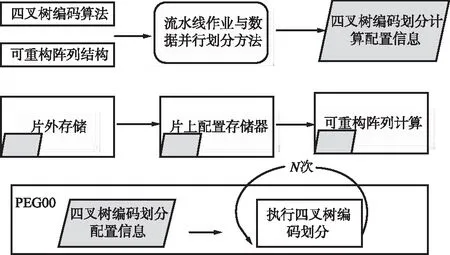
2.3 重構信息配置
3 實驗及結果分析
3.1 實驗平臺環境
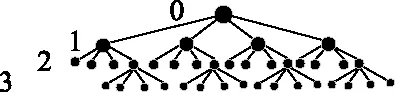
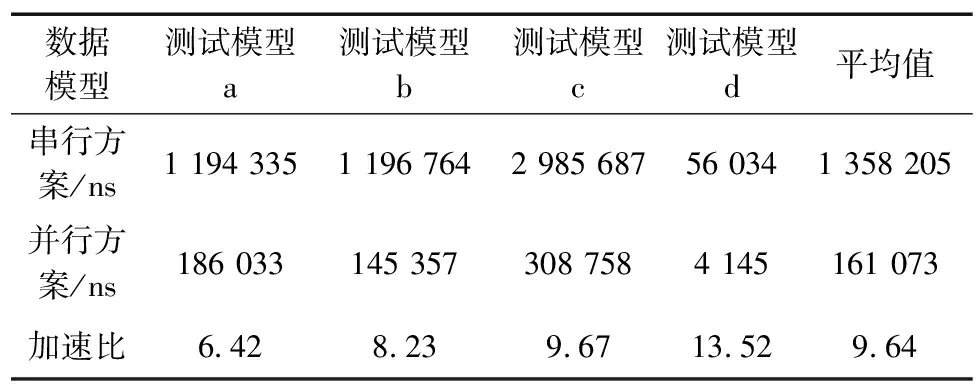
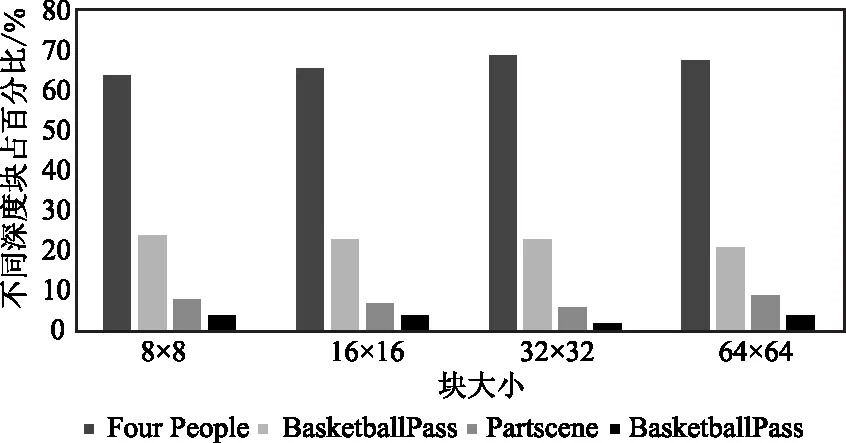
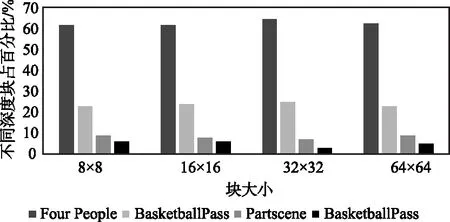
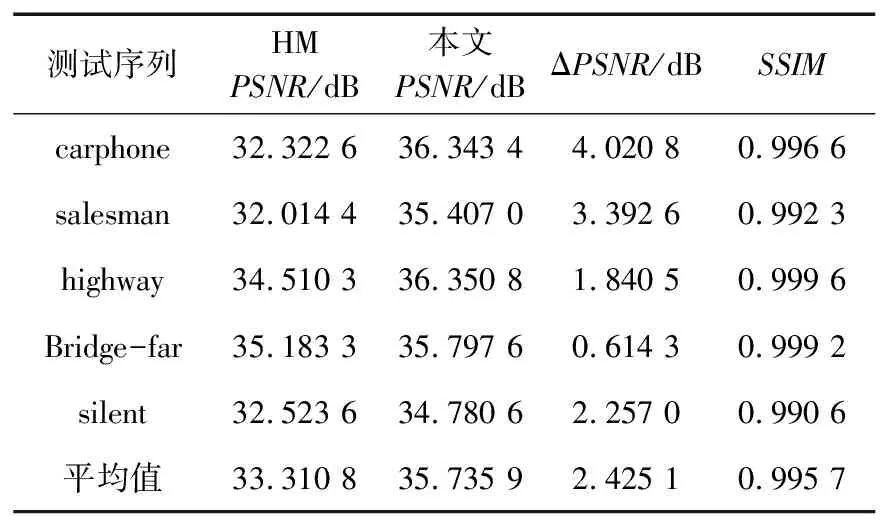
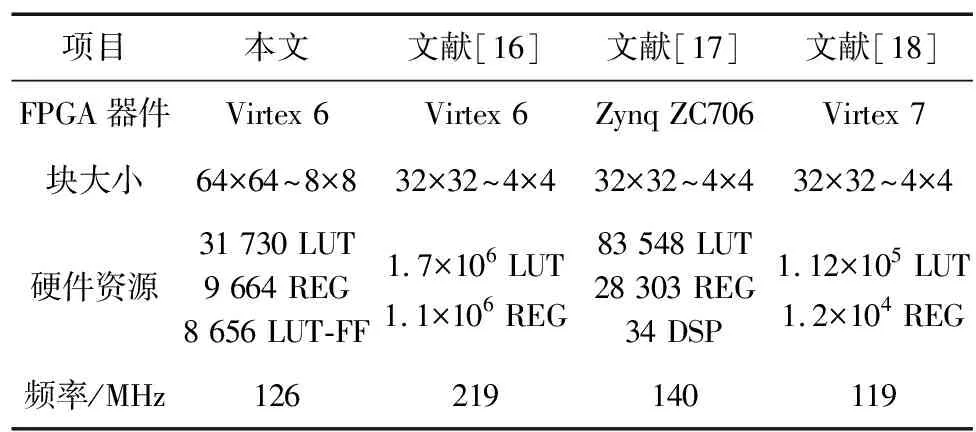
3.2 實驗結果




4 結束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
