基于寬度學習的注塑產品質量預測方法
2022-05-31 06:19:40林江豪吳宗澤李嘉俊謝勝利
電子與信息學報 2022年5期
林江豪 吳宗澤 李嘉俊 謝勝利③
①(廣東工業大學自動化學院 廣州 510006)
②(廣東外語外貿大學語言工程與計算實驗室 廣州 510006)
③(廣東工業大學粵港澳離散制造智能化聯合實驗室 廣州 510006)
1 引言
塑料制品具有質量輕、絕緣和耐腐蝕等優點,已廣泛應用于航空航天、高鐵、通信、新能源、物流和日常生活等多個領域。注塑產品的質量容易受注塑機工藝參數設定、模具狀態等諸多因素的影響。產品質量預測可應用于實際注塑工業場景中的缺陷自動發現,及時停止缺陷產品生產,降低生產損失,因此要求模型結構簡單、計算效率高,以滿足快速的系統響應,實現產品缺陷的實時預警。同時,要求模型具有穩健性,確保缺陷預警的真實性,降低系統漏報、錯報造成的生產損失。
常見的注塑產品質量缺陷有產品縮水、變形等多種。在現有的注塑產品質量預測研究中,主要選擇如寬度、厚度和質量作為模型的預測目標,采用回歸預測的方法來解決。傳統的基于機器學習的方法主要有支持向量機(Support Vector Machines,SVM)[1]、最近鄰算法(K-Nearest Neighbor,KNN)[2]、人工神經網絡(Artificial Neural Network, ANN)[2–5]、輕量梯度提升機(Light Gradient Boosting Machine, LightGBM)[6,7]等。近年來以神經網絡方法為主,Ogorodnyk等人[2]提出了采用多層感知機(MultiLayer Perceptron, MLP)來實現產品寬度和厚度的預測方法。文獻[3,4]采用反向傳播(Back Propagation, BP)網絡來進行質量參數的建模。文獻[5]結合徑向基函數(Radial Basis Function,RBF)神經網絡模型和多島遺傳算法(Multi-Island Genetic Algorithm MIGA)對注塑過程的最優參數尋找進行建模。文獻[6,7]對LightGBM算法優化過程進行改進,實現更精準的注塑成型產品質量預測模型。傳統機器學習的模型比較簡潔,滿足了實時計算的需求。然而,實際生產過程中,容易出現訓練數據以外的離群點,屬于典型的零樣本或者小樣本的問題,傳統機器學習方法難以解決,表現出模型泛化能力不足的缺陷,而對離群點的預測是產品質量檢測的核心。
隨著基于深度學習的計算視覺技術發展,利用電荷耦合器件(Charged Coupled Device, CCD)圖像傳感器采集產品外觀的多角度圖像,基于深度神經網絡模型構建缺陷分類器是可行的,主要以卷積神經網絡(Convolutional Neural Networks, CNN)[8,9]或CNN與如門控循環單元(Gated Recurrent Unit, GRU)[10]的其他深度神經網絡結合作為產品缺陷圖像的特征提取器,進而訓練分類器來進行注塑產品缺陷類別的自動分類。基于深度學習的方法雖然保證了準確率,但數據采集困難、特征提取復雜、不能針對生產場景靈活轉變,并且大規模的參數學習,學習的時間成本非常高,屬于典型的數據饑餓模型,需要大量的標注數據來進行模型訓練才能獲得穩定而有效的模型,然而在實際工業應用中獲得大規模的缺陷標注數據顯然是不現實的。
綜合以上,現有基于機器學習和深度學習的注塑產品質量預測方法推動了注塑行業智能化和自動化,但模型仍存在泛化能力不足、靈活性不夠、訓練成本高等缺陷。文獻[11]提出的寬度學習系統是基于隨機向量函數鏈接網絡的平行網絡(Random Vector Functional Link Neural Networks,RVFLNN),已被證明具有通用的逼近能力[12]。文獻[13]提出了采用最小p-Norm的方法優化參數矩陣W,在擬合sinc函數實驗發現,在數據中的噪聲分布不確定情況下,調節p值可以保持模型良好的魯棒性。寬度學習具有結構簡單、訓練速度快、泛化性能好等優勢。因此,本文以注塑產品質量的3維尺寸作為預測目標,提出一種基于寬度學習方法的注塑產品質量預測模型,主要創新工作可概括為以下3個方面:
(1)提出一種基于BLS的注塑產品尺寸預測方法,通過引入p范數提升寬度學習系統(Broad Learning System, BLS)模型應對異常數據和小樣本數據的能力,提升模型的魯棒性。
(2)介紹了一種基于相關系數矩陣的特征選擇方法。對高頻傳感器數據、spc數據、注塑機臺參數、產品質量數據進行預處理,利用相關系數進行特征篩選,并計算衍化特征,最后獲得預測模型的輸入特征。
(3)在注塑成型工藝品尺寸預測數據中進行實驗,實驗結果表明,本文所提方法確實能提高注塑產品尺寸預測的準確性。在實際的注塑產品缺陷自動發現中,能更好地預測小樣本異常尺寸。
本文其余部分組織如下:首先,在第2節主要介紹特征篩選的方法和結果。然后,在第3節提出基于最小p范數的寬度學習在注塑產品尺寸預測中的建模方法。接著,在第4節中對實驗結果進行分析。最后第5節對全文工作進行總結。
2 特征選擇
2.1 數據來源
本文使用第4屆工業大數據競賽題目《注塑成型工藝的虛擬量測和調機優化》中任務A-虛擬量測的數據1)https://www.industrial-bigdata.com/Home,數據集提供了每個批次產品的生產過程數據,以及工藝參數的調機記錄,并給出了每個模次生產的注塑產品的尺寸測量信息。數據的簡單描述如下:
(1)傳感器高頻數據(data sensor):該數據來自于模溫機及模具傳感器采集的數據,單個模次時長為40~43 s,采樣頻率根據階段有20 Hz和50 Hz兩種,含有24個溫度、壓力等傳感器數據,是連續的數據。
(2)成型機狀態數據(data spc):該數據來自成型機機臺,均為表征成型過程中的一些狀態數據,數據維度為86維。每個模次記錄1次數據,數據是離散的。
(3)機臺工藝設定參數(data_set):注塑成型的81種工藝設定參數,這部分數據是在注塑機參數調整的時候產生,只在參數變化時記錄,屬于離散數據。
(4)產品測量尺寸(size data):每個模次產品的3維尺寸,記為size1, size2和size3。size1∈[299.85,300.15],size2∈[199.925,200.075] 和size3∈[199.925,200.075]分別是size1, size2和size3的合格范圍。數據統計顯示,異常數據占比非常低,高于上限的異常尺寸產品數量占比分別為2.73%, 11.86%和5.78%;低于下限的異常產品數量分別占比為0%, 2.01%和0.44%,屬于典型的不平衡小樣本數據,符合實際生產環境中數據的采集特點,模型計算結果更接近實際場景。
2.2 特征選擇方法
為了對特征數據降維,采用基于斯皮爾曼(spearman)相關性系數矩陣的特征篩選方法2)https://github.com/chuangwang1991/VirtualMeasurement molding,如圖1所示。對采集到的不同特征數據進行處理,包括數據清理、合并和衍化特征計算。具體處理的過程:首先刪除data_sensor中存在空值和單一值的維度,計算每個模次中data_spc中傳感器采集數據的平均值作為整個周期的值,作為模型的基礎特征。將得到的基礎特征分別與每個目標尺寸進行斯皮爾曼相關性系數分析得到相關矩陣,并利用訓練集和測試集的數據分布差異,選擇合適的基礎特征。接著,刪除data_set中的空值和單一值的維度,并計算衍化特征。隨后,計算每個調機段中各個size的衍化特征。最后,將提取到的各類特征鏈接起來,作為總的特征提取結果。
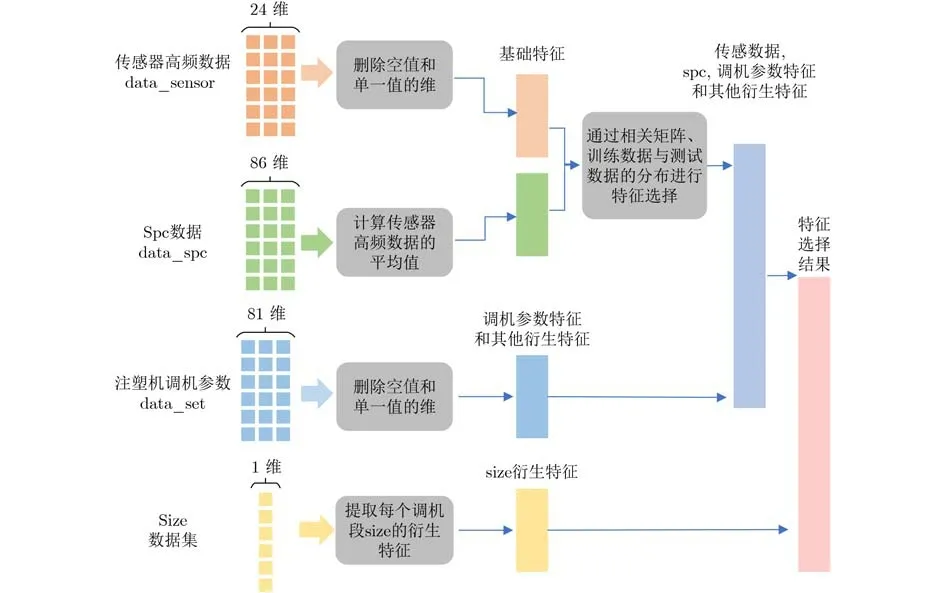
圖1 特征提取過程
經過特征提取后,獲得size1, size2, size3對應的模型特征如表1所示,其中“√”表示使用了該特征,“×”表示未使用該特征,最終的特征維數分別是21, 22和21,主要特征內容為時間、壓力、溫度和速度這4類參數。
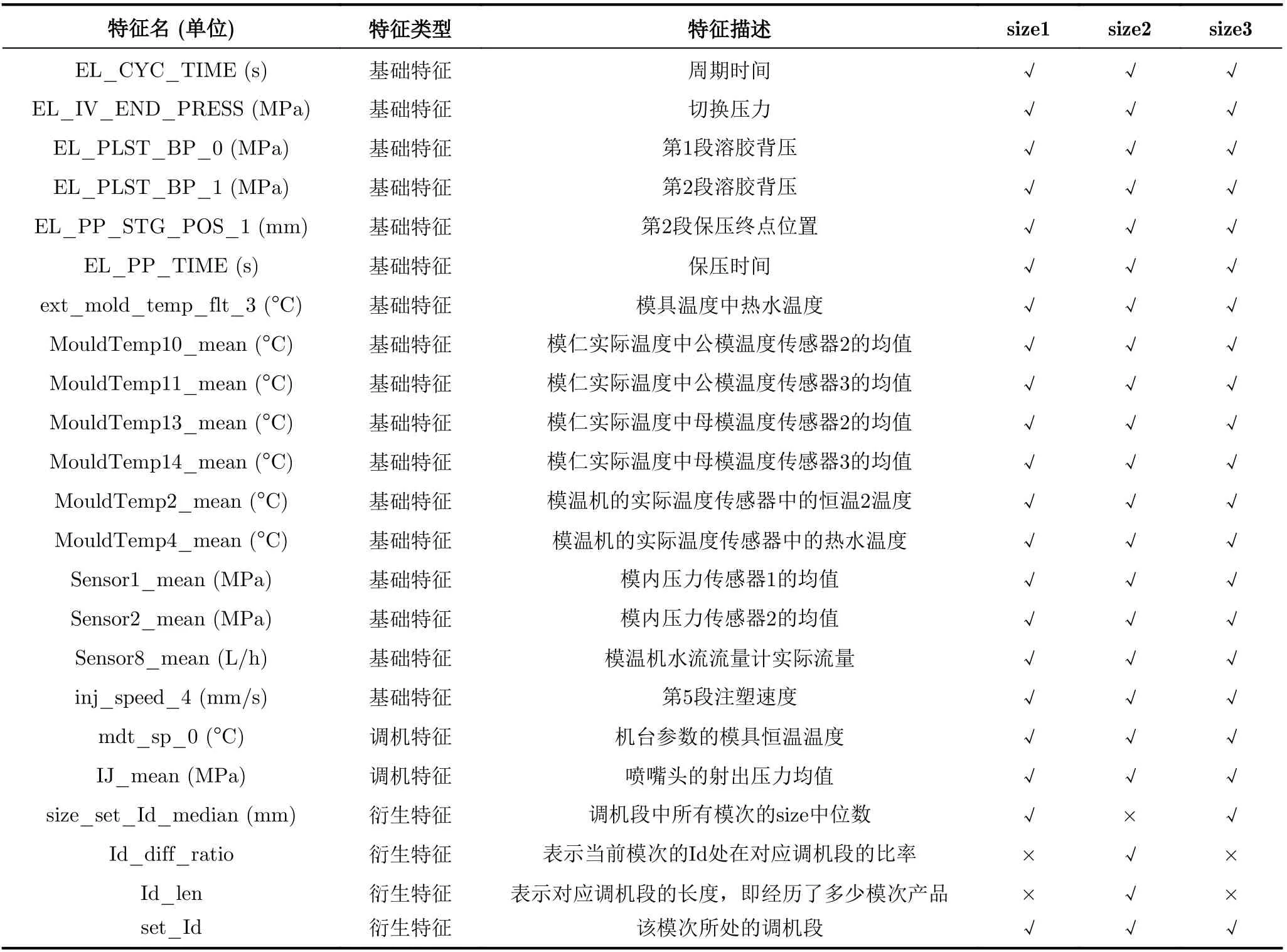
表1 特征選擇結果
3 基于最小p-范數寬度學習的注塑產品尺寸預測模型
3.1 基于BLS的注塑產品尺寸預測方法
注塑成型產品尺寸預測任務屬于回歸預測任務,對傳感器高頻數據、spc數據、機臺工藝設定參數等數據進行特征提取,得到特征矩陣X,X經過BLS的特征層線性映射后,再通過增強層的非線性轉換,最后將特征層和增強層的輸出共同輸入到輸出層,得到BLS的預測結果。如圖2所示,BLS簡化了隨機向量函數連接網絡 (Random Vector Functional-Link Neural Network, RVFLNN)的網絡結構,將增強節點和特征節點并列到同一層,主要優勢有:(1)增加隱藏層節點的數量,真正實現將網絡向寬度方向擴展;(2)輸入數據經過特征映射和增強映射兩次變換,增強了網絡的特征提取能力。
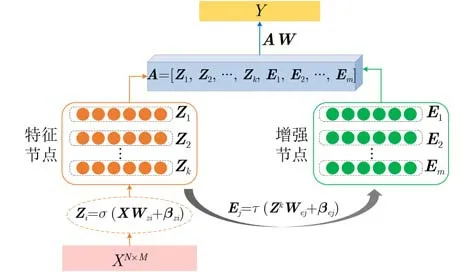
圖2 寬度學習網絡結構


3.2 基于最小p范數寬度學習的注塑成型工藝尺寸預測方法


表2 基于BLS的產品尺寸預測模型訓練


4 實驗結果與分析
4.1 基線模型
(1)支持向量機(SVM)[7]:能解決高維特征的回歸問題;僅依靠支持向量來決定超平面,無需依賴全部數據;有多種核函數可以選擇,從而可以更靈活地解決各種非線性的回歸問題;在注塑成型質量預測的小樣本數據中,具有更強的泛化能力。
(2) K近鄰(KNN)[6]:通過找出一個樣本的k個最近鄰居,將這些鄰居的某些屬性的平均值賦給該樣本,就可以得到該樣本對應屬性的值,模型比較簡單,無需估計參數,重新訓練代價低。
(3) 多層感知機(MLP)[6]:MLP是3層及以上的前饋神經網絡,層與層之間是全連接,利用激活函數來對節點信息進行非線性激活,隱藏層的神經元數量是可設置的,可采用誤差逆傳播方法來進行優化。
4.2 評價標準
選用均方誤差(Mean Squared Error, MSE)作為模型的評價標準,如式(16)所示,MSE是將所有預測結果與實際結果之間誤差平方后求平均所得,常用于評估回歸模型的性能。

表3 基于pN-BLS的產品尺寸預測模型訓練
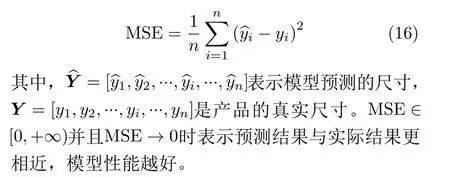
4.3 參數選擇
4.3.1 SVM
對比了linear,rbf,poly和sigmoid 4種不同核函數在數據集上的表現,發現核函數poly在size1,size2, size3 3個尺寸的回歸預測中,均可取得最小的MSE值。因此該文最終選擇poly作為SVM的核函數,并設置核函數的度為3。
4.3.2 KNN
針對KNN模型,為了選擇合適的最近鄰數(nneighbors),通過設置n-neighbors從3~99,步進為2,實驗結果發現n-neighbors對size1,size2,size3預測的MSE具有相同的趨勢,隨著n-neighbors逐步增加,MSE的值逐步變小,并趨向于穩定。相比而言,size1對n-neighbors更敏感,n-neighbors對size3的影響最小,根據實驗記過,最終設置nneighbors=99。
4.3.3 MLP
設計包含輸入層、隱藏層(N1) 、隱藏層(N2)、輸出層共4層結構的MLP神經網絡,采用tanh激活函數,設置alpha=1e-6。對隱藏層的最優節點數,采用網格搜索法來確定,設置每一個隱藏層的神經元數3~101,步進為2。實驗結果發現N1<10時,對size1,size2和size3的預測影響都比較大,說明了第1個隱藏層神經元數需要盡量大一些,能更充分地學習輸入層的信息。通過搜索,最終確定預測size1,size2和size3的最優N1和N2組合分別為(71,5),(83, 21),(43, 55)。
4.3.4 BLS
采用網格搜索法確定最優(q,k,r)組合,特征層的特征組數q和特征節點數k的搜索范圍都是[2:1:1 1],增強層的節點數搜索范圍設置為[3:2:101],設置正則化參數λ=2?30。實驗結果表明,size2對 (q,k,r)的變化更為敏感,相比而言,size1和size3在r>20時,更為穩定。通過實驗獲得(q,k,r)對size1,size2和size3的最優組合分別是(8,10, 97),(10, 10, 95)和(9, 8, 93)。
4.4 實驗結果
選擇SVM, KNN, MLP, BLS和pN-BLS中p-norm值分別為0.1, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0時,模型的最優預測結果,如表4為size1, size2,size3對應的預測MSE值。從實驗結果可以看出,相比SVM, KNN, MLP的預測結果,BLS和pN-BLS性能都有大幅度的提升,這說明了寬度學習方法可以有效地應用于注塑產品的質量預測。

表4 預測結果
對size1的預測,普通的BLS在q=8, k=10,r=97時取得最優的結果MSE=0.000548。在加入p進一步約束異常值的影響后,pN-BLS比BLS的效果普遍要好,當p=1.5, q=10, k=5, r=93時,最小的MSE=0.000187,相比BLS有較大幅度的性能提升。對size2的預測,當p=1.5, q=6, k=10,r=69時,pN-BLS預測的MSE=0.008483,取得最優效果;在q=10, k=10, r=95時的BLS預測的MSE=0.010706,比pN-BLS略差。對size3的預測,取p=1.5, q=10, k=2, r=89時pN-BLS的MSE=0.000178,而q=9, k=8, r=93時BLS預測結果的MSE=0.000385。綜合以上,p=1.5時,pNBLS總能達到一個很小的MSE。本文提出方法的優勢主要包括3個方面:(1)特征節點和增強節點能有效提取輸入數據的特征。(2)BLS能有效通過嶺回歸求解違逆矩陣,防止回歸模型過擬合。(3)p=范數的引入可有效提升BLS對抗復雜噪聲的干擾能力,提高模型的穩定性。
4.5 預測時間的對比
理論上,只要設計合理的訓練目標函數,模型的訓練時間足夠長,模型都可以達到收斂效果。現有的研究為了體現算法的計算優勢,更多關注模型在訓練時間訓練上的優勢,而不是預測時間。然而,在注塑產品缺陷檢測應用中,預測時間代表了模型的響應速度,預測時間越短表示響應越及時,對工人及時發現缺陷產品,及時調整機器參數,降低生產損失有重要的價值。因此,本文更關注的是預測時間,選擇每種模型中的最優參數,對比了不同模型在預測數據集上的時間表現,結果如表5所示,與其他傳統學習方法相比,寬度學習方法在響應速度上有顯著的優勢,特別是pN-BLS (p = 1.5)預測速度具有明顯的優勢。主要原因是寬度學習的結構優勢,通過矩陣計算的方法,能快速并行計算的大批量的輸入數據并得到預測結果,也說明了寬度學習的方法在注塑產品缺陷檢測中的應用具有響應速度快的優勢。
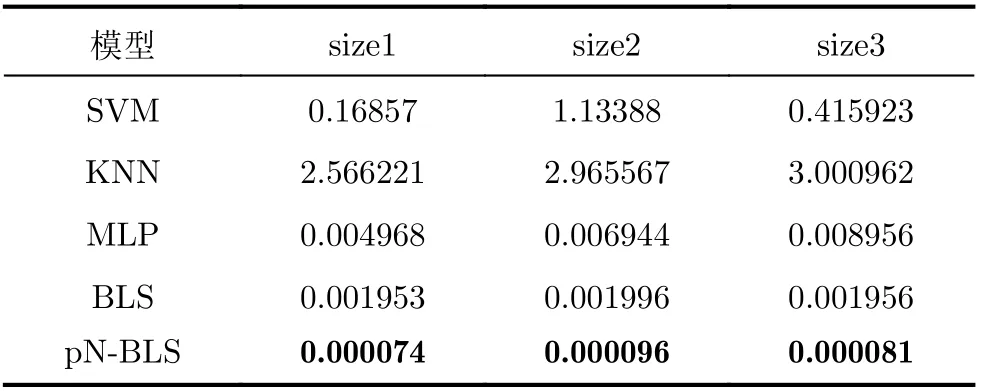
表5 預測時間(s)
4.6 注塑產品缺陷發現應用
為了對比不同方法在實際的產品缺陷發現應用中的效果,本文設置SVM, KNN, MLP, BLS和pN-BLS的最優參數,預測結果如圖3所示。
圖3中,綠色的線表示真實的尺寸數據,藍色的線表示預測結果。兩條紅色虛線之間的屬于正常尺寸的注塑產品,兩條紅色以外的點表示尺寸不合格。紅色的“●”是真實數據中的不合格尺寸,黑色的“●”點表示預測到的不合格尺寸。綠色的“●”和藍色的“●”分別表示實際的合格尺寸和預測的合格尺寸。從中可以觀察到,BLS和pNBLS都與真實尺寸的曲線更接近,對于異常值的發現更精準。觀察發現不同模型對高于上限的不合格尺寸預測比較準確,對低于下限的尺寸預測要差一些。分析數據發現,大部分的不合格尺寸都是超過上限,如3個尺寸數據中,只有size2存在少量的低于下限尺寸的不合格樣本。這種訓練數據嚴重不平衡的現象,導致模型容易產生過擬合,影響了預測的準確性。圖3中pN-BLS能更準確預測出部分低于下限的不合格尺寸,說明在引入p范數后,pN-BLS能有效降低異常值對模型的影響,這對實際注塑產品缺陷檢測應用是非常有價值的。
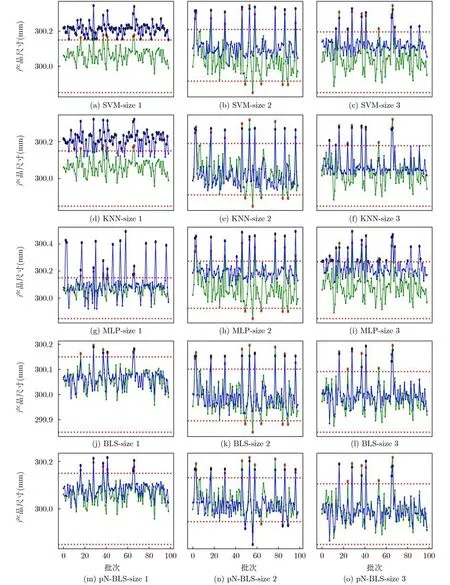
圖3 注塑產品異常尺寸預測結果
5 結論
注塑產品缺陷自動檢測一直以來都是注塑工業智能化發展的關注點。本文提出基于最小p范數寬度學習方法的注塑產品尺寸預測方法。首先,對采集到傳感器高頻數據、成型機狀態數據、機臺工藝設定參數和產品的3維尺寸進行數據預處理,并計算了衍生特征,采用了相關系數矩陣進行特征篩選,獲得3個尺寸對應的最優特征,實現對采集數據的特征選擇與降維。接著,采用pN-BLS模型對注塑產品的3維尺寸分別進行回歸預測,這種方法的輸入特征與預測的目標尺寸之間是強相關的關系。最后,以SVM, KNN, MLP為基線模型,在第4屆工業大數據創新競賽-賽題二注塑成型工藝的虛擬量測數據中,評估了不同模型參數對尺寸預測的影響,選擇最優效果的參數,進行模型的對比驗證,包括預測的MSE和預測時間。具體的結果可總結如下:
(1)訓練數據集和測試數據集均是8300組。在訓練數據中訓練并評估獲得每種方法的最優參數后,對比不同方法預測MSE發現,BLS和pNBLS比SVM, KNN, MLP都有明顯的優勢。pN-BLS對size1, size2和size3的預測MSE分別是0.000187(p=1.5, q=10,k=5,r=93),0.008483 (p=1.5, q=6,k=10, r=69)和0.000178 (p=1.5, q =10, k=2,r=89),與其他方法相比均有顯著的優勢。說明了寬度學習方法可以有效應用到注塑產品尺寸回歸預測中,p范數引入能優化BLS在回歸預測任務中的應用,能約束異常數據對BLS的影響。同時,在模型預測響應方面,pN-BLS的響應速度最快。
(2)本研究還對比了不同方法在注塑產品質量自動檢測方面的應用。結果發現,BLS和pNBLS的預測曲線與實際的尺寸曲線要比其他方法要更接近。但是相比BLS而言,pN-BLS能更好應對不平衡的訓練數據的影響,對少樣本的不合格尺寸的預測效果比BLS要好,也說明了引入p范數可提升模型的魯棒性,這對注塑產品質量異常檢測很有價值。
(3)通過特征篩選,最終選擇17個基礎特征,2個調機參數特征和4個衍生參數,其中8個不同位置溫度傳感器特征,6個不同壓力傳感器的特征。從特征選擇結果來看,影響注塑成型產品質量最關鍵的參數是溫度和壓力。在注塑產品缺陷自動檢測實際應用中,在其他注塑機上安裝傳感器采集數據時,可重點采集溫度和壓力參數,減少其他不必要的傳感器,降低采集成本和數據處理成本。當注塑機出現產品缺陷時,也應該首先考慮溫度和壓力的設置問題,這對快速發現和解決生產問題是非常有價值的。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
Coco薇(2015年1期)2015-08-13 02:23:50
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
河南科技(2014年23期)2014-02-27 14:19:15
玩具(2009年10期)2009-11-04 02:33:14
個人電腦(2009年9期)2009-09-14 03:18:46
