基于互信息最大化的多視圖協作學習算法在智能崗位推薦上的應用
2022-05-30 00:18:02戈弋張磊
電腦知識與技術 2022年16期
戈弋 張磊


摘要:為了解決在線求職平臺中大量求職數據和企業招聘數據之間的精準匹配問題,文章設計了一種基于互信息最大化的多視角協作學習算法,以特定的預測分析和分值計算模型為基礎,提前對人崗的基礎信息做基礎訓練,對冷信息做預測模型,對熱數據做取向加權計算,以解決就業信息中人崗匹配精準度和速度性能的相悖性問題,并將算法成果應用到公共服務云平臺的智能崗位推薦工作場景中。
關鍵詞:互信息最大化;人崗匹配
中圖分類號:TP311? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)16-0074-03
1概述
隨著社會經濟和計算機技術的不斷發展,運用數字技術實現線上求職的平臺越來越受到求職者的青睞。大量的求職數據和企業發布的招聘數據的不斷增長,使得如何為求職者進行職位匹配成為求職平臺亟須解決的一項重要任務。如何將企業的招聘需求能夠自動匹配到合適的簡歷,通常的做法是將該任務轉換為監督文本匹配問題。在用戶提交的簡歷中能夠被標注出的信息監測點和個人數據充分且完備時,監督文本匹配的學習算法是能夠實現相應的人崗匹配功能。然而,由于很多的招聘求職平臺對求職人提交的簡歷或者個人信息未做嚴格的審核和監測,導致求職人員提交的信息和招聘人員與平臺的交互信息繁雜,導致數據的不準確和信息缺失(即噪聲數據),影響了求職匹配算法在人崗匹配方面所能夠發揮的性能。
許多研究人員都對解決上述問題提出了各自的解決思路,本文從不同的角度設計了基于多視點協作學習算法的多維預測分數計算方法,在求職平臺的簡歷匹配功能模塊中發揮了重要作用。本文提出的多維預測分數計算方法中,將計算模型分為兩大類:一類是根據文本數據集構建的匹配模型,另一類是根據關系數據集構建的匹配模型,這兩部分捕獲并增強了兩種不同觀點的語義兼容性。為了解決稀疏和噪聲數據帶來的影響,本研究提出了兩種不同的方法來組合這兩個組件,其目的是在原始數據集的基礎上提高人崗匹配算法的精準度。
2 國內外研究現狀
許多國內的研究人員在求職平臺的智能工作推薦領域進行了必要的研究。在崗位推薦中,Zhang等人[1]集中研究了基于客戶端的協同篩選和基于項目的協同過濾計算的某些場景。戴衛東等[2]根據BP網絡構建了求職崗位匹配評估模型,并進行了二次實驗驗證,檢驗了BP網絡中功能完備的自聯想、自變異和自學習能力,實驗成功地評估了大型企業招聘和技術人員求職的職業匹配。最近,一些大型互聯網招聘組織提出的工作參考管理部門對招聘調查給出了另一種觀點。例如,在L公司的大型求職推薦系統中,Zhang等人[3]提出了一個綜合直接混合模型(GLMix),這是一個在客戶或風險企業層面更為復雜的模型,在該框架中,就業申請量將增加20%~40%。徐等人[4]提出了一個基于職業變動網絡的能力圈揭示模型,以幫助企業識別足夠的符合本企業需求的求職人員,為求職者提供求職崗位建議,并追蹤合適的職位。Yu等人[5]從不同的在線社交軟件中收集與業務相關的信息,通過跨組織的網絡發現跳槽人員與企業之間的關系,并展示人才的流動與國家和企業政策制度之間的關系趨勢。Wang等人[6]利用具有職業特征因素的信息預測員工流動。考慮到應聘者的語義特征,張毅等人[7]改進了職業搜索數據的內外語義處理,針對求職者提出了一種更精確的語義匹配的創新算法。利用自然語言處理創新,Doc2vec策略被用來完全挖掘長文本中包含的語義數據,以實現求職人員和招聘崗位之間的數據精確匹配。
國外研究人員同樣對崗位推薦和人崗匹配保持著極高的研究興趣。專家們目前更傾向于使用定量的方法處理招聘情況調查,因為企業在招聘時需要求職者的大量信息[5]。也許主要的問題是專注于能力和工作原則之間的匹配水平,通常被稱為人員與工作匹配[8]。Malinowski等人[9]利用求職人員和職位的文件數據,在工作匹配的早期檢查中,構建了一個互惠工作建議框架,以追蹤求職人員和職位之間的合理匹配。根據提議框架的思想,Lee等人根據基本的工作傾向和興趣提出了一個任務候選工作建議框架[10]。Huang[11]通過將語義數據從卷積層中提取出來,做出了最后的求職崗位預測。為了預測匹配情況,Wang[12]建議將個人職位匹配問題作為一項分類任務,并將簡歷作為分類任務中的重要信息來源。他們提出了一種學習聯合表示的策略,該策略利用兩個卷積神經網絡(CNN)對簡歷和職位數據進行自由編碼,并計算出余弦可比性作為匹配分數。Yan[13]利用互聯網日志,通過記憶網絡將求職人員和招聘人員的人才需求整合到他們的研究中。He[14]最近提出了一個卷積神經網絡,用于協同過濾、學習比較、推薦求職人員和招聘平臺的植入向量后的推薦結果。事實上,智能工作推薦已經從多個角度得到了廣泛探索,包括以工作為導向的能力評估、求職者匹配和工作建議,目前已經成為企業招聘平臺的一項基本功能。
3 互信息最大化多視角協作學習算法的計算過程
3.1 問題定義
假設有一組崗位:[Γ={j1,j2,…,jn}],一組簡歷[R={r1,r2,…,rm}],其中[n]代表的是求職平臺上發布的招聘崗位總數,[m]代表的是求職平臺上求職人提交的簡歷總數,招聘崗位需求和求職簡歷中求職人的技能都以文本數據的形式展現。本文還設定一個觀察(訓練)匹配集[Y={
3.2 算法設計
本節介紹崗位匹配的設計策略。從一個角度來看,求職人員的文本檔案中描述了其求職傾向和個人簡歷。首先設計了一個文本匹配模型,該模型運用漸進式的文本編碼器,獲取個人簡歷和招聘信息中的文本語義。然后,以招聘信息和個人簡歷為基礎,構建“崗位—簡歷”關系圖,找出他們之間的潛在相關性。將人崗匹配任務轉化為崗位與簡歷之間的關聯性預測,利用“崗位—簡歷”神經網絡關系圖建立一個基于關系的匹配模型。如前所述,這兩種模式各有優勢,本文進一步將它們協調成一個多視角的協同學習網絡。
對于基于文本的匹配策略,尋找合適的方法處理招聘信息和簡歷信息,通過語義分析找出兩類信息之間的相似關聯關系,構建匹配模型。實現這種基于文本匹配策略的關鍵是如何構建應聘者獲取到的工作和當初其投遞的簡歷文件之間聯系的方法。
1)基于Bert的句子編碼器
本文模型的主體層是一個由標準BERT模型執行的句子編碼器,它是一個多層雙向轉換器。給定一個招聘需求或者個人求職簡歷的一段文本語句,文本語句的開頭會嵌入一個獨特的CLS印記。對于文本語句中的每個令牌,本文將兩種嵌入式標記視為輸入,其中令牌植入解決了每個令牌的含義,令牌的安裝位置表示的是每個令牌在消息排列中的位置。設定一個單獨的信息向量,在該信息向量中保存這兩種嵌入式標記,并由BERT編碼器對該信息向量進行處理,以習得的CLS符號描述為句子的描述。
2)分級變壓器編碼器
歸檔編碼器是根據BERT的句子編碼器創建的。給定一個招聘信息或個人求職簡歷,它將插入句子作為輸入信息,并生成整個檔案描述。通過采用分級式設計,編碼器可以顯示非常長的報告,并保持語義上的條件限制。文檔編碼器的更新方案如下:對于基于消息的匹配策略,跟蹤處理功能消息和恢復消息的適當方法,然后根據語義相似性構建匹配模型。
[h(l)r=LN(h(l-1)r+MHAtt(h(l-1)r))]? ? ? ? ? ? (1)
[h(l)j=LN(h(l-1)j+MHAtt(h(l-1)j))]? ? ? ? ? ? (2)
[h(l)r=LN(h(l-1)r+FFN(h(l)r))]? ? ? ? ? ? ? ? ? ?(3)
[h(l)j=LN(h(l-1)j+FFN(h(l)j))]? ? ? ? ? ? ? ? ? ?(4)
式中,[j]為工作文檔,[r]為簡歷文檔,[h(l)r]和[h(l)j]為第[i]層輸入簡歷和工作向量,[LN]為層歸一化運算,MHAtt為多頭注意運算。設[L]表示變壓器網絡的層數。最后的輸出層是sigmoid分類器,定義為:
[yj,r=σ(W1[h(L)j;h(L)r]+b1)]? ? ? ? ? ? ? ? ? ? (5)
公式(5)中[h(L)j]和[h(L)r]是分別表示在最后一層(即第L層)的工作文檔[j]和簡歷文檔[r],[W1]是一個參數矩陣轉換,表示連接崗位-簡歷文檔間的轉移系數, [b1]是一個偏移量,[yj,r∈(0,1)]表明工作文檔[j]和簡歷文檔[r]之間的匹配程度。
4 多維人崗匹配算法的算法設計
本文通過兩種整合策略,設計了一個多維人崗匹配算法。首先,共享學習到的信息或參數,以增強每個組件的原始表示。其次,對于平臺中存在的噪聲數據或者負樣本,如何減少它們對模型訓練的影響是需要重點關注的問題。在很多的機器學習算法中,為了減少噪聲影響,采用多樣本聯合訓練的方法,通過選擇更加接近于真實的訓練實例,讓這兩個部分能夠相互改進,提升算法質量。
由于在匹配過程中包含文本表示和關系表示兩類表示方法,為了在初始表示學習的過程中互相增強,在初始學習文本模塊的表示時會拼接關系圖上節點的表示。類似地,為了增強圖關系上節點的表示,會采用文本模塊學習到的表示作為關系圖訓練時的初始表示。
該算法的關鍵前提是真實樣本經常在多個模型視角下提供相對比較類似的預測,但噪聲樣本很難在所有模型被消除。在對原始數據進行機器學習的背景下,該算法的兩個組成部分可以被視為兩個相互印證的學習。一個學習者的樣本首先由另一個學習者進行檢查,被評為“良好質量”的樣本保留在機器學習的短語中。由于這兩種樣本學習方法對數據特征建模的立足點截然不同,他們可以互相補充,選擇“高質量”的培訓樣本,以提高整體性能。
5 多維人崗匹配算法的優勢分析
本文在國內主流的在線招聘平臺和合肥市現代職業教育集團公共信息服務云平臺上提供的真實數據來檢測模型的有效性。為了防止個人信息的泄露,所有的個人簡歷、招聘信息和企業與個人之間的溝通信息都做了脫敏處理。將原始數據集分為三類,以測試模型對不同領域的魯棒性。處理后的數據統計匯總如表1所示。
從表1可以看出:1)所有的信息指標的密度都非常少,其范圍在0.0142%和0.0431%之間;2)不同的分類與不同的信息質量有關。例如,銷售分類則是一個更為小眾卻又密度較高的信息數據集,而技術分類是一個龐大而密度極其稀疏的信息數據集。3)不可否認,對于每一種分類,不符合需求的數據樣本(即否定實例)的數量遠遠小于符合需求的數據樣本(即肯定實例)的數量。由于這種不均勻的信息數據集可能會誘發模型學習的偏差,因此需要經常使用調整信息分散度的策略來增加崗位與簡歷之間匹配的隨機性,增加隨機抽樣的可信度。本文認為有兩種數據匹配的模式是不符合需求的負面案例:1)企業在搜索者的登錄頁上點擊鏈接,在閱讀簡歷后在線聊天,但不發送最終的錄用通知(點擊錄用該求職者);2)企業在閱讀簡歷時沒有進一步的行為方式(下鉆式瀏覽)。如前所述,負面案例可能會是“誤導性噪聲數據”:盡管沒有合理的在線錄用的通知,但他們兩方可能已經通過線下構成了雇傭關系。為了將這些負面案例添加到準備信息中,本文需要研究模型從喧囂信息中獲得有用的雇傭信息的能力。通過相似性檢查這兩項指標,正面案例和負面案例的數量比例設置為1:1。需要注意的是,本文只是在準備階段使用這些負面案例,而對于確認集和測試集,本文使用具有明確承認或拒絕狀態的測試來保證本文評估的準確性和高質量。
5 結論
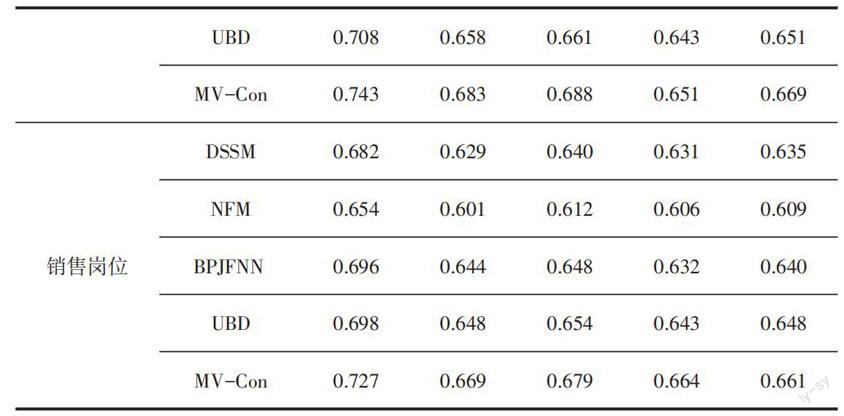
本文針對三個不同崗位的數據集,運用多種算法進行人崗匹配,比較不同算法之間的性能和優勢,經過實驗,得出如下結論。首先,NFM很難在實驗的任務上取得良好的效果。原因是該任務比傳統推薦場景數據更加稀疏;同時,DSSM在大多數情況下表現不佳,因為它無法捕獲文本信息中的時序信息;BPJFNN、PJFNN、APJFNN、JRMPM和DGMN之間的性能差異很小,并且針對不同指標或不同領域會有微小差別;此外,UBD是唯一訓練時解決噪聲問題的基線方法,與其他基線方法相比,該方法的效果有顯著提升,這也側面證實了該任務下處理噪聲數據的必要性。其次,本文提出的模型在不同數據集的所有指標上均獲得了最佳性能。與其他方法相比,模型中的協作學習機制能夠識別更多信息量豐富且更可靠的樣本來學習參數,也更容易削弱噪聲數據帶來的影響,因此優于其他方法。最后,對比篩選過濾和重加權這兩種策略,本文發現后者在大多數情況下更優異。可能因為重新加權策略采用了“軟”降噪的方法,該方法在處理噪聲數據時魯棒性更強。
參考文獻:
[1] Zhang Y Y,Yang C,Niu Z X.A research of job recommendation system based on collaborative filtering[C]//Hangzhou,China:2014 Seventh International Symposium on Computational Intelligence and Design.IEEE,2014:533-538.
[2] 戴衛東,蔣蓉,李鐵欣.基于BP神經網絡的科技人員人崗匹配測評模型[J].沈陽工業大學學報(社會科學版),2018,11(2):160-164.
[3] Zhang X X,Zhou Y T,Ma Y M,et al.Glmix: Generalized linear mixed models for largescale response prediction[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2016.
[4] Xu H,Yu Z W,Yang J Y,et al.Talent Circle Detection in Job Transition Networks[C].Knowledge Discovery and Data Mining,2016.
[5] ChengY,Xie Y S,Chen Z Z,et al.JobMiner:a real-time system for mining job-related patterns from social media[C]//Proceedingsof the 19th ACM SIGKDD international conference on knowledge discovery and data mining.Chicago Illinois USA.New York,NY,USA:ACM,2013.
[6] Wang J,Zhang Y,Posse C,et al.Is it time for a career switch?[C].World Wide Web,2013.
[7] 張毅,高元榮,黃宗財,等.結合深度語義特征的人崗精準匹配算法[J].貴州大學學報(自然科學版),2021,38(1):65-70.
[8] Sekiguchi T.Person-Organization Fit and Person-Job Fit in Employee Selection: A Review of the Literature[C].osaka keidaironshu,2004.
[9] Malinowski J,KeimT,Wendt O,et al.Matching people and jobs:abilateral recommendation approach[C]//Kauai,HI,USA:Proceedings of the 39th Annual Hawaii International Conference on System Sciences (HICSS'06).IEEE,2006:137c.
[10] Lee D H,Brusilovsky P.Fighting information overflow with personalized comprehensive information access:aproactive job recommender[C]//Athens,Greece:Third International Conference on Autonomic and Autonomous Systems (ICAS'07).IEEE,2007:21.
[11] Huang P S,He X D,Gao J F,et al.Learning deep structured semantic models for web search using clickthrough data[C].Information & Knowledge Management,2013.
[12] Wang J,Zhang Y,Posse C,et al.Is it time for a career switch?[C].World Wide Web,2013.
[13] Yan R,Le R,Song Y,et al.Interview choice reveals your preference on the market:to improve job-resume matching through profiling memories[C]//Anchorage AK USA:Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.NewYork,NY,USA:ACM,2019.
[14] He X, Deng K, Wang X, et al.Lightgcn: Simplifying and powering graph convolution network for recommendation[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval,2020:639-648.
【通聯編輯:唐一東】
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
外語學刊(2011年1期)2011-01-22 03:38:33
