快遞末端自提網點選址及快遞柜配置優化
2022-05-30 14:06:48胡貴彥盧長永
物流技術 2022年5期
關鍵詞:模型
胡貴彥,王 華,盧長永
(北京物資學院,北京 101149)
0 引言
近年來,我國快遞業務量在日益增長的同時帶來了一些配送難題。一方面,快遞量大、配送對象分散導致投遞耗時長、配送成本高等,使得配送面對的壓力越來越大;另一方面,受新冠疫情影響,“無接觸式配送”悄然興起,對快遞終端配送提出了新的要求。
快遞柜自提方式作為無接觸式配送的主要方式之一,很大程度上緩解了“最后一公里”配送難題,但快遞柜自提方式依然存在快遞柜數量配置供需不協調、自提網點選址不合理等問題。在快遞柜布局配置方面,Wilson指出聚集效應在快遞行業突出,應統一規劃快遞柜配置布局。譚如詩,等以南京城區菜鳥驛站為例,提出自提空間布局與居民社會屬性、出行等行為密切相關。在自提點選址方面,張晶蓉,等綜合運用層次分析法和重心法,采用定性和定量相結合的方法對鄭州大學快遞服務中心選址問題進行研究。Deutsch,等根據客戶收入和設施運營成本,以利潤最大化為目標構建模型。張海軍,等以北京城市副中心為研究區域,建立整數規劃模型,優化郵政速遞自提網點。Morganti,等發現顧客與自提點的距離效用對自提點建立有較大影響。蔣森楚提出快遞企業網點布局優化要從實際情況出發,保證與市場的匹配性。張秋燕分析亞馬遜自提柜運營經驗,總結出自提柜在選址方面應靠近用戶、布置合理、靠近中央配送站等。
綜上所述,關于自提網點選址問題,國內外學者針對不同應用情況提出了不同選址模型,且普遍認為服務半徑和人口密度是主要考慮因素,但提出的方法復雜度較高,缺乏一定的普遍適用性;另外以往通常是單一研究自提網點選址或快遞柜配置,缺少綜合性。本文以服務半徑和人口密度為主要考慮因素,為優化自提網點選址與快遞柜配置,提出一種操作簡單實用、科學強的方法,有助于緩解“最后一公里”配送問題。
1 快遞末端自提網點現狀及問題
我國快遞末端自提網點主要有快遞公司獨立建設自提點、依托其他商業實體營業場所建立自提點、專業第三方收貨服務自提點、快遞柜自提點四類。
其中快遞柜自提點能夠使用戶隨時收取快件,隱私保護性較強,也可為廣告商提供廣告宣傳,因此快遞柜得以迅速發展。2015-2020年全國智能快遞柜數量由6.4萬組升至76.9萬組,6年時間達到了原來的12倍。這種方式雖然存在對體積較大的快件無法投放、建立之初成本較高等局限,但快遞柜自提相對于其他方式還是可以大幅提高投遞效率、提高顧客滿意度,智能快遞柜自提點的發展將是不可逆轉的趨勢。本研究將主要對快遞柜自提點進行分析。
快遞末端自提點分布目前整體基本符合“服務跟隨需求”原則,但還是不能很好地滿足顧客需求。一方面,由于快遞柜廠家繁多、市場混亂,選址標準不一,從而導致快遞柜分布不均;另一方面,各品牌快遞柜隨意建設,覆蓋范圍較小,數量配置不科學,導致快遞柜供需不平衡。
快遞柜自提相較其它配送方式有不可替代的優勢,但對其自身發展存在的快遞柜自提點分布不均和快遞柜數量設置不合理等問題需要加以解決。
2 模型構建
為解決上述問題,利用集合覆蓋法對目標區域快遞柜自提點的需求點進行處理,確定初步選址方案,并提出各自提點快遞柜設置數量,然后利用層次分析法分析篩選出較優方案。
2.1 模型假設
選址模型構建是從某區域的所有服務設施備選點中選擇若干個作為中心節點,然后用盡可能少的中心節點覆蓋所有的需求點,形成一個網狀射線狀結構。該模型構建要求從已經確定的備選點中選擇需要的中心節點,屬于離散型選址模型。
為便于建立模型和方便模型求解,本節做如下假設:
假設1:每天快遞量穩定且不考慮大型網購季節,并以日為單位進行研究;
假設2:顧客對取件方式沒有偏好,接受快遞柜自提方式;
假設3:建立的各個快遞末端自提網點容量不小于快遞量;
假設4:為便于計算,將研究區域按照實際小區劃分,建立單獨坐標系;
假設5:擬選擇選址都有建設條件。
2.2 確定初步選址方案
利用集合覆蓋法求備選方案,其目標是用盡可能少的服務設施點覆蓋所有需求點。需求點指顧客取件地址,本文以顧客取件地址所處的每幢樓為一個需求點;候選點指自提點放置的位置。因快遞自提點與顧客取件地址所屬樓房相近,所以將候選點位置與需求點位置近似看做一個點,即在本文研究中需求點也是候選點。
目標函數:

約束條件:

式(1)中,u為快遞末端自提網點選址變量,表示有個快遞自提網點;式(2)表示每一個需求點都可以被覆蓋;式(3)表示自提網點覆蓋的需求點在其服務半徑內;式(4)表示第i需求點是否被j個自提網點覆蓋;式(5)表示在候選點j是否建立快遞自提網點。
2.3 確定最終優化方案
利用層次分析法分析初步備選方案,選擇出最終較優的方案。
(1)建立層次分析模型。層次分析模型的目標層為快遞柜選址最優方案。根據對快遞末端自提網點現狀的研究,確定準則層為建設成本、客戶滿意度、物流效益、行走距離4個重要的因素。然后分析得到最終的甲方案、乙方案、丙方案。
(2)構造判斷矩陣。用1~9 標度法(參見表1)進行兩兩對比,確定各因素之間的相對重要性并賦值。
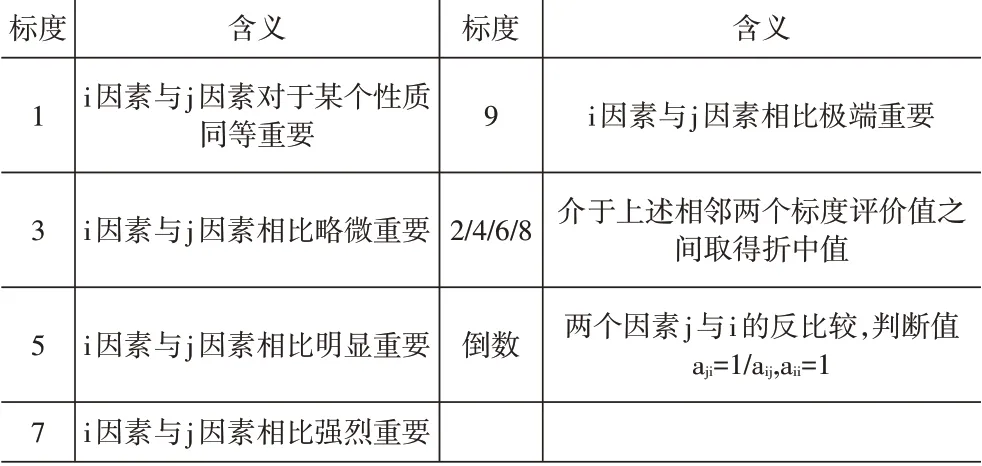
表1 重要性標度表
然后,構造出各層次中所有判斷矩陣B:
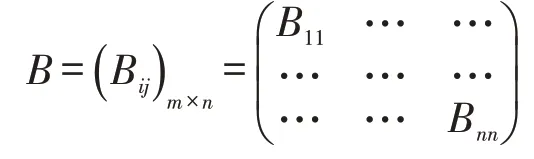
其中B>0;B=1/B;B=1。
(3)確定各層權重。利用準則對判斷矩陣中各因素進行權重計算。判斷矩陣B對應的最大特征值特征向量,經過歸一化處理,最后得到關于上一層次各因素相對重要性的排序權重。
(4)層次單排序及一致性檢驗。為避免其他因素對判斷矩陣的影響,對判斷矩陣進行一致性檢驗。當矩陣符合邏輯要求時,進行下一步分析。當0 時,表示有完全一致性;當接近0 時,有滿意一致性;越大,不一致性越嚴重。由于隨著矩陣階數增大,保持一致性難度加大,因此引入平均隨機一致性指標。當隨機一致性比率小于0.10時,即認為判斷矩陣具有滿意的一致性,否則需要調整判斷矩陣。

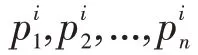
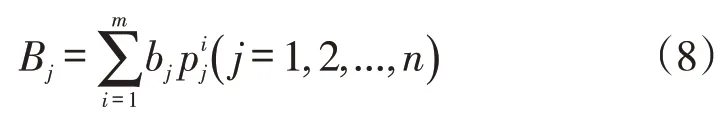
通過上述計算得到各個因素重要性排序值,通過對各個方案的權值進行排序,從而做出最后的決策。
3 實證分析
北京城市副中心第五組團地區中的金融街園中園、新建村二期、北京物資學院三個區域分別代表工業園類、小區類、學校類需求點,在需求類別、需求量等方面具有一定代表性。將上述構建的快遞末端快遞柜模型運用到實例中,以點代面進行分析。
3.1 數據收集及整理
從360地圖中獲取北京城市副中心第五組團地區數據進行統計分析并矢量化,將便利店、現存自提網點等作為快遞末端備選網點。為后期方便數據分析,將居民區、高校等主要人口密集度高的地點作為需求點,建立各小區獨立坐標系,得到需求點坐標。以金融街園中園、新建村二期、北京物資學院為例,編號首字母為A的區域是新建村二期共22個需求點,B為金融街園中園共40個需求點,C為北京物資學院共33個需求點(部分信息見表2)。
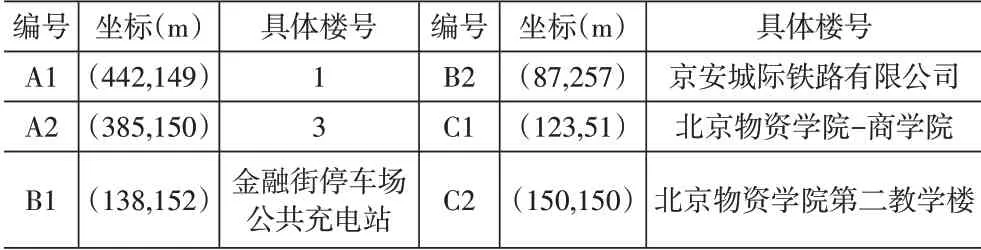
表2 部分小區需求點坐標示例圖
經實地調研統計,目標區域每日快件自提量約為12 000 件,其中金融街園中園的最大快遞量2 453,最小量867,平均量1 864。新建村二期最大快遞量4 796,最小量1 370,平均量3 000。北京物資學院最大快遞量3 516,最小量1 259,平均量2 336。三個區域快遞量總計約為7 200,約占總區域的60%。
3.2 快遞末端自提網點選址
3.2.1 確定初步備選方案。第五組團主要分為人口密度較高和人口密度較低兩類地區,高校和住宅區屬于人口密度較高地區,工業園屬于人口密度較低地區。據調查人走路速度約40-50m/min,為研究計算方便,將步速統一為45m/min。因此本論文設定3 個研究方案,分別是方案甲,快遞柜的服務半徑R為315m,步行7min;方案乙服務半徑R 為225m,步行5min;方案丙服務半徑R 為135m,步行3min。下面將對以上三種方案情況進行研究。
(1)建立集合覆蓋模型。以金融街園中園為例,方案丙的服務半徑R為135m,展示具體的計算過程。
目標函數:

約束條件:
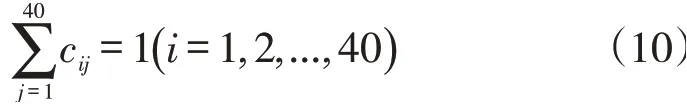

上述式子中,40表示有40個需求點或40個快遞末端自提網點備選點;a表示需求點i的橫坐標;b表示需求點i的縱坐標;x表示快遞備選點j的橫坐標;y表示快遞備選點j的縱坐標;135表示快遞末端自提網點選址的服務半徑。
(2)利用Excel 對數據進行初步處理。本文運用excel軟件根據集合覆蓋模型運用距離公式對各個建筑坐標進行數據初步處理。計算得到初步備選方案(見表3)。
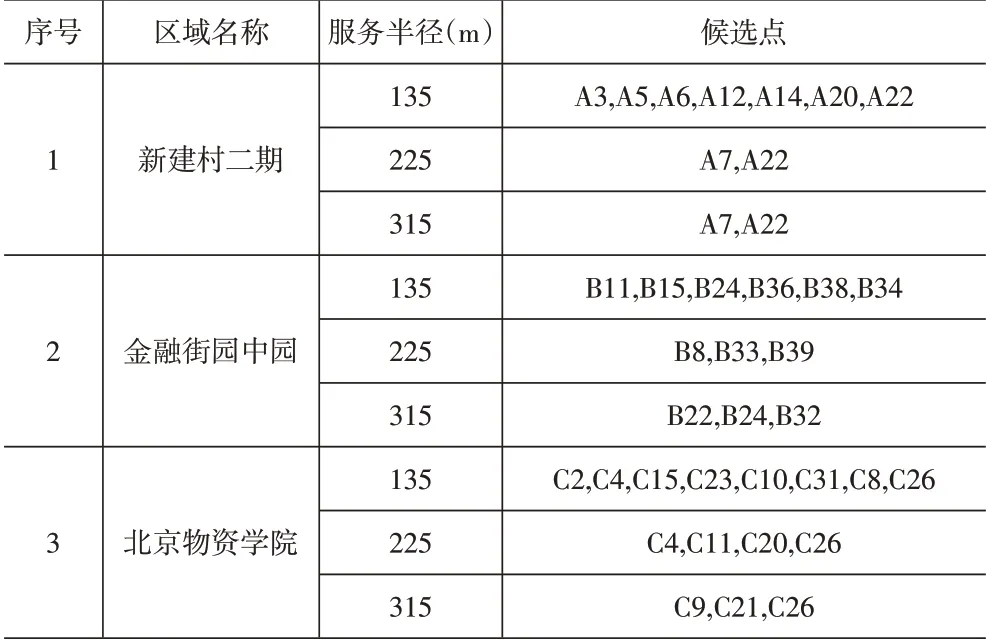
表3 初步備選方案
(3)python優化過程及結果。根據上面的備選方案,使用python軟件利用貪婪算法對上述結果進行優化,不斷趨近整體最優解,進而獲得比較科學的結果。計算得到優化后的方案見表4。
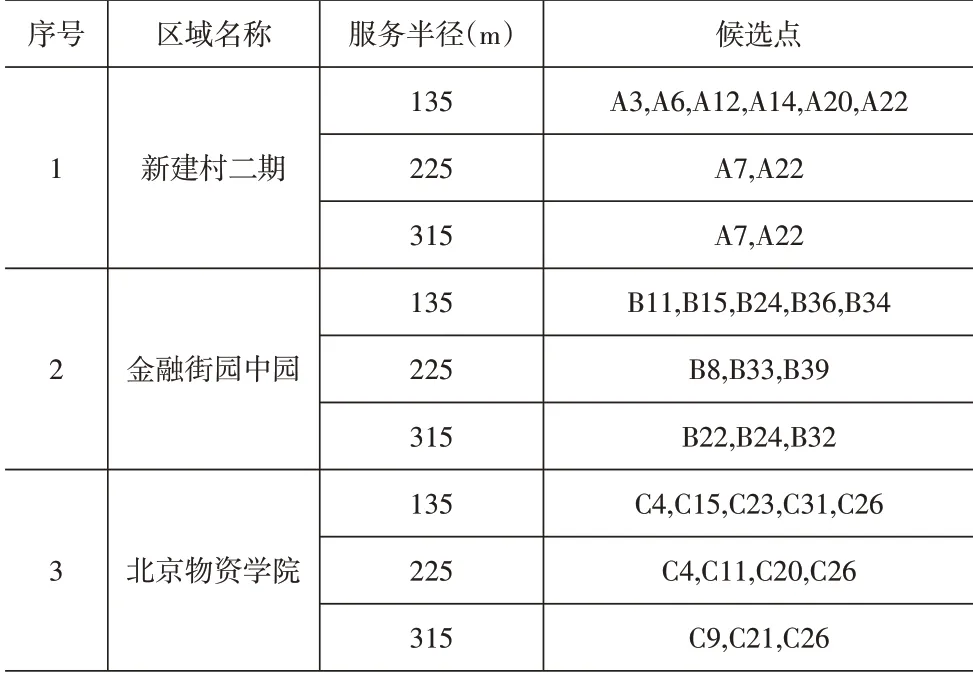
表4 優化后方案
(4)初步備選方案結果。根據改變快遞柜的服務半徑獲得不同的備選方案,方案甲金融街園中園候選點(B22,B24,B32),北京物資學院候選點(C9,C21,C26),新建村二期候選點(A7,A22),建議各區域每個候選點快遞柜庫存容量分別為平均622 件/d、946 件/d、1 500 件/d;方案乙金融街園中園候選點(B8,B33,B39),北京物資學院候選點(C4,C11,C20,C26),新建村二期候選點(A7,A22),建議各區域每個候選點快遞柜庫存容量分別為平均622件/d、709件/d、1 500件/d;方案丙金融街園中園候選點(B11,B15,B24,B36,B34),北京物資學院候選點(C4,C15,C23,C31,C26),新建村二期候選點(A3,A6,A12,A14,A20,A22),建議各區域每個候選點快遞柜庫存容量分別為平均373件/d、473件/d、500件/d。
3.2.2 確定最終優化方案。根據實際情況以及層次結構模型得出人口密度為主要考慮因素,本文將從人口密度高和人口密度低的兩類情況進行分別研究。
(1)人口密度較低區域。在人口密度低的地區,目標判斷矩陣為E。
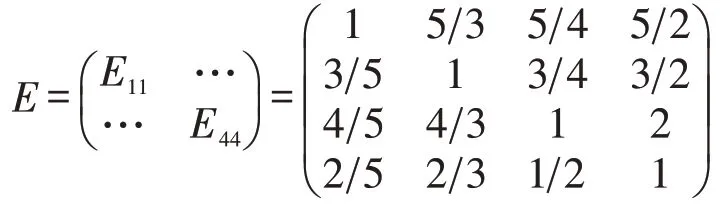
由此可得到選址方案的總排序表(見表5)。
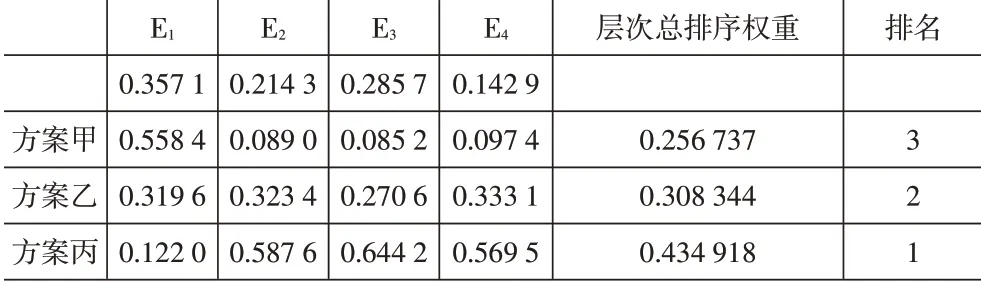
表5 總排序表(人口密度低)
方案甲、乙、丙的權重分別為0.256 737、0.308 344、0.434 918。三個備選方案的排序為甲<乙<丙。方案丙為最優選址方案。
(2)人口密度較高區域。在人口密度高的地區,目標判斷矩陣為E。
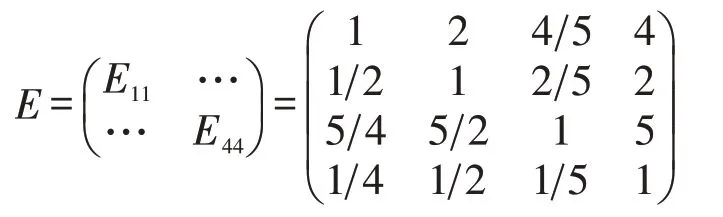
可得到選址方案的總排序表(見表6)。
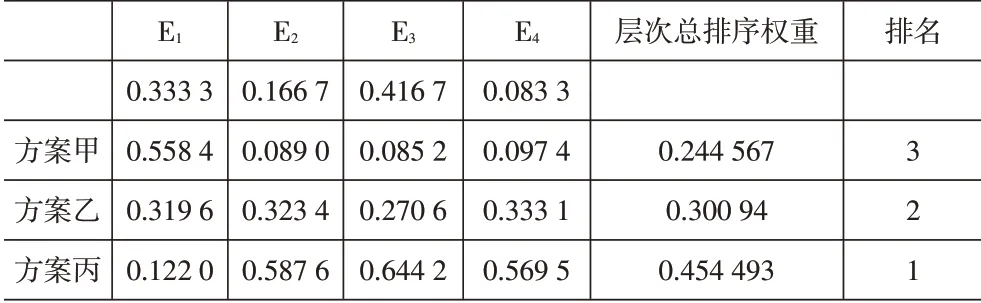
表6 總排序表(人口密度高)
方案甲、乙、丙的權重分別為0.244 567、0.300 94、0.454 493。三個備選方案的排序為甲<乙<丙。方案丙為最優選址方案。
綜合上述針對人口密度高和人口密度低的不同地區,一致認為方案丙最優。方案丙金融街園中園候選點(B11,B15,B24,B36,B34)北京物資學院候選點(C4,C15,C23,C31,C26)新建村二期候選點(A3,A6,A12,A14,A20,A22),建議各區域每個候選點快遞柜庫存容量分別為平均373件/d、473件/d、500件/d,即各區域快遞柜總庫存容量分別為平均1 865件/d,2 365件/d,3 000件/d。因此無論是人口密度高還是人口密度低的地區,自提網點布局服務半徑在合理范圍內較小是比較好的選擇。另外,根據快遞柜布局設置規劃快遞柜組數有利于提高快遞柜利用率。
4 結語
近年來快遞柜自提已成為“無接觸式配送”與解決快遞末端瓶頸問題的主要方式之一,但在自提點分布和快遞柜容量設置上仍存在一些問題。本文以點代面,以金融街園中園、新建村二期、北京物資學院分別代表北京城市副中心第五組團工業園類、小區類、學校類需求點,利用集合覆蓋模型與層次分析法構建快遞末端快遞柜自提網點選址模型。根據快遞量數據,優化各個自提點快遞柜容量設置。希望可以對北京等其它地區快遞末端自提網點選址、快遞柜容量設置提供一定的借鑒。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
