基于知識圖譜的通用學習路徑生成研究
2022-05-26 04:23:06白玉帥徐洪勝
綿陽師范學院學報 2022年5期
白玉帥,徐洪勝,魏 銘,唐 海
(湖北汽車工業學院電氣與信息工程學院,湖北十堰 442002)
0 引言
近年來,個性化在線學習系統的研究因疫情的影響而變得異常迫切,越來越多的學者和專家關注并投入到此領域的研究中.在線學習系統服務于在線學習者,滿足其個性的需求,緩解當前在線學習中存在的“信息過載”與“學習迷航”等問題.眾多專家學者從不同的角度對個性化在線教育進行分析與討論:劉芳等[1]重視學習者特征,并以此構建學習者模型進行學習資源推薦;李浩君等[2]從學習資源角度出發,利用優化算法,為在線學習者推薦最優學習資源與學習路徑;申云鳳等[3]分析并量化在線學習行為特征,引入多重智能型算法進行學習路徑的個性化推薦.學習路徑生成的研究已然成為在線學習系統的重要研究領域.
學習路徑的研究隨著在線學習系統的盛行而日益蓬勃.歐美國家對學習路徑開展研究的時間較早、成果也較為顯著:美國匹茲堡大學Peter Brusilovsky[4]依據奧蘇泊爾的有意義學習理論,采用模糊神經網絡方法判斷知識水平、動機等,實現學習路徑的定制.奧地利格拉茨大學的Nussbaume[5]采用知識空間理論和布魯姆目標分類法判斷學習者的知識水平,創建適應性學習路徑.國內對該領域的研究也取得了一定的進展:姜強等[6]利用序列模式挖掘算法,挖掘、分析并匹配計算學習者特征與學習對象,生成精準的個性化學習路徑.牟智佳等[7]對在線學習系統服務與數據處理技術間的關系進行論述,提出了基于學習特征模型的自適應學習路徑生成框架.
當前,多數的研究傾向于關注如何構建個性化的學習路徑以解決在線學習質量差、效率低等問題,但個性化路徑生成效果并不理想.本研究在構建學科知識圖譜的基礎上提出了一種通用與可行的學習路徑,為當前大多數在線學習群體提供“學習導航”的功能,提高學習質量、提升學習效率.
1 學習路徑研究現狀
1.1 學習路徑定義

圖1 基于學習行為活動的學習路徑Fig.1 Learning path based on learning behavior activities
關于學習路徑的概念界定,目前主流的定義分為兩種:其一,學習者在一定的學習方法指導下,根據其學習的目標、水平等,對所需完成的學習活動進行排序[8].即通過挖掘學習者學習活動時的行為日志數據,如瀏覽課件、交流提問和在線測試等,并結合學習者的學習風格對學習活動進行序列化,形成基于學習行為活動的學習路徑,其路徑結構如圖1.

圖2 基于知識單元的學習路徑Fig.2 Learning path based on knowledge unit
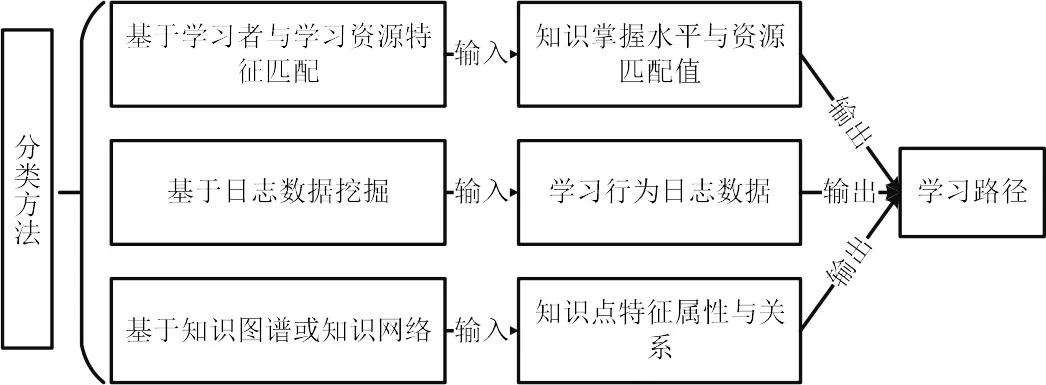
圖3 學習路徑自動生成方法分類Fig.3 Classification of automatic learning path generation methods
其二,將學習路徑抽象化,理解成學習節點的組織序列,由路徑節點和節點間的關系構成學習路徑[9],其中路徑節點是最基本的構成要素,是學習者完成學習目標所需要進行的最小學習單元.利用學習單元本身的屬性特征及其之間的關系,在不違背學習單元之間內在邏輯的前提下,對待學習單元進行序列化,形成基于知識單元的學習路徑,其路徑結構如圖2.
1.2 學習路徑自動生成方法分類
根據對學習路徑生成研究的核心思路與策略的不同特征將其分為三類[10],歸納成圖3.
1.2.1 基于學習者與學習資源特征匹配的方法 通過計算學習者掌握知識水平與學習資源間匹配程度,按照兩者匹配程度的高低對學習者進行學習資源的序列化推薦.例如,李浩君[11]引入在線學習資源相斥的排序規則,根據相斥度的大小實現在線學習資源序列化推薦服務.此類路徑生成方法強調的是個性化定制,但存在違背知識點之間內在邏輯及認知規律的風險.
1.2.2 基于日志數據挖掘的方法 利用學習者的學習行為日志數據,采用關聯規則挖掘算法,從海量的知識單元序列或在線學習者的學習測試記錄中獲取知識單元的關系并以此構建學習路徑.例如,申云鳳[3]利用網絡學習日志,結合學習風格與能力水平,量化學習行為特征,采用多重智能型算法實現了對個性化學習路徑的推薦.此類路徑生成方法充分考慮了群體學習者的智慧,但忽視了自組織學習路徑本身也可能存在錯誤,利用從群體經驗中總結出的學習路徑并不一定具備普適性.
1.2.3 基于知識圖譜或知識網絡的方法 根據知識圖譜本身包含的知識點屬性與知識點之間的關系作為算法的輸入,在確保學習路徑符合知識點之間內在邏輯的基礎上,結合自定義的網絡節點拓撲排序算法與優化算法構建成學習路徑.例如,淵明[12]設計出三層知識圖譜結構并結合學習者模型,對在線學習者推薦學習路徑.此類學習路徑生成方法從學科領域知識結構出發規劃學習路徑,保證了學習路徑生成結果的邏輯性與科學性,但目前而言對知識圖譜的設計、開發與維護的代價較高,需要投入大量的人工精力與資源.
以上三類學習路徑的生成方法各有優劣,總體而言,基于知識圖譜或知識網絡生成學習路徑的準確性較高,也更符合學習者的認知規律.但目前基于此類方法的相關研究缺乏對知識圖譜構建過程的討論,圖譜設計的質量也難以保證,故本研究將先從知識圖譜的設計與構建等角度展開分析與討論.
2 通用學習路徑自動生成方法
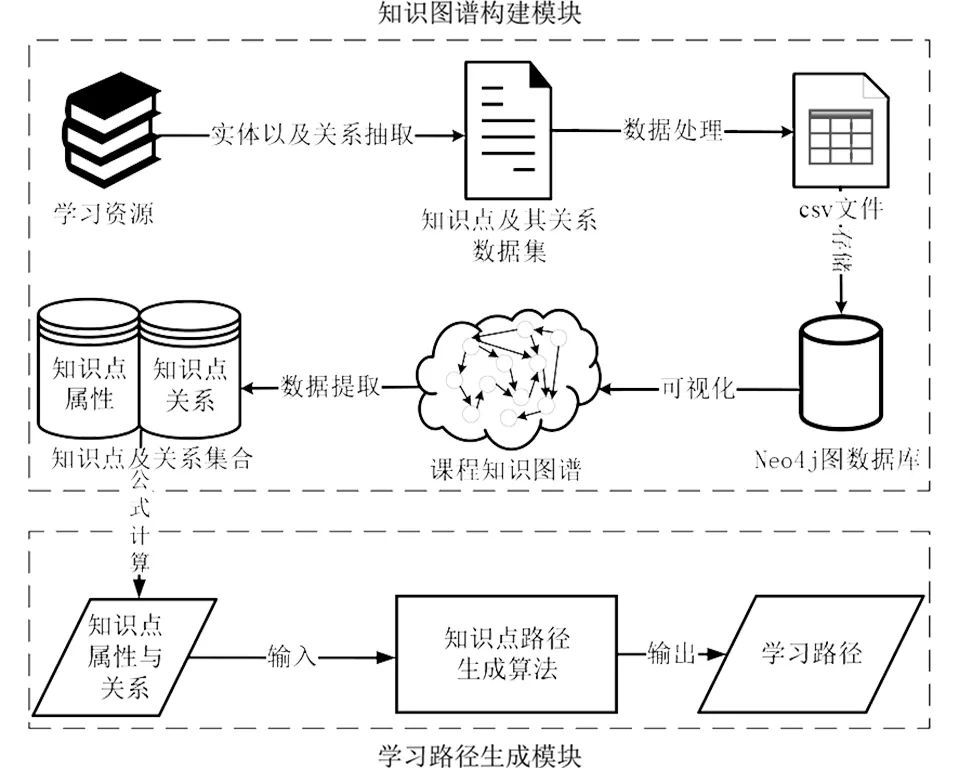
圖4 基于知識圖譜的通用學習路徑生成方法Fig.4 General learning path generation method based on Knowledge graph
學習路徑生成是從知識圖譜到通用學習路徑,最終生成個性化的學習路徑.本研究重點討論基于知識圖譜的通用學習路徑自動生成方法如圖4所示,分為兩部分.第一部分是知識圖譜創建模塊,此部分采用以機器為主、人工為輔的方式構建知識圖譜;第二部分是學習路徑生成模塊,將第一部分知識圖譜中相關信息作為輸入,結合算法實施與參數調試得到通用學習路徑.本研究構建的知識圖譜為大學本科計算機科學與技術專業必修課程“C語言程序設計”.
2.1 課程知識圖譜

為確保知識圖譜構建的質量,采取人工設計概念層、自動提取關鍵詞以及由學科專家手動篩選知識點及知識點間關系的方法構建課程知識圖譜.此外,還充分考慮知識圖譜中實體類型、屬性及關系,設計出知識圖譜的模式層,其結構如表1所示.
基于知識特征的最優學習路徑規劃(節點排序)研究的關鍵是節點之間的關系.例如,知識點的難度、中心度及關系權重的確定等[13].因此,在設計學習路徑自動生成時,充分考慮知識點在知識圖譜中的屬性及關系.知識圖譜中需要包含對知識點之間的父子及兄弟關系的記錄,父子關系即知識點之間的包含關系,用以描述知識點之間整體與局部的關系;兄弟關系即平行關系,用以描述處在同一個層面上的多個知識點,且彼此之間不存在任何依賴關系.
知識點屬性方面,除id和名稱屬性外,還添加了知識點的重要度、難度、中心度和拓撲層級四個屬性,以此豐富知識圖譜模式層的構建,提高知識圖譜設計的質量.
2.2 學習路徑生成算法
本研究設計了知識點拓撲排序算法,按照知識點的重要度由高到低、難度由易到難、中心度由大到小和拓撲層級由淺至深原則,結合知識圖譜的結構及知識點間的關系對知識點進行排序,生成通用學習路徑.
2.2.1 知識點屬性特征值計算 利用TextRank關鍵詞提取算法對文本資源進行處理,得到知識點集合及知識點重要度.其公式表示為:
(1)
式中:Ws(Vi)為節點Vi的權重;Ws(Vj)為上次迭代后的節點Vj的權重;wji為節點Vj與節點Vi之間的相似度;d為阻尼系數,一般取值為0.85.
知識點難度的定義參考課程要求,將其分為了解、理解、掌握與應用四個等級,并分別賦予1到4的權重.
根據知識圖譜的性質,利用知識點的入度與出度的比值計算知識點的中心度,比值越大,說明知識點的中心度越高,其對后續學習的貢獻越大[14].知識點入度與出度的定義如下.
(2)
中心度計算公式如下:
(3)
式中:C(v)為節點Vi的入度與出度的比值;Pre(Vi)為知識點Vi的一階前驅知識點集合;Suc(Vi)為知識節點Vi的一階后繼知識點集合.
知識點拓撲層級可根據知識圖譜的結構設計直接獲取.
利用上述屬性值計算知識點排序指標Wkpi,如公式(4)所示.其中重要度Impkpi利用公式(1)中Ws(Vi)節點的權重值.
Wkpi=wimp×Impkpi+wdiff×Diffkpi+wcent×Centkpi+wtp×Tpkpi
(4)
式中:Impkpi、Diffkpi、Centkpi、Tpkpi分別為知識點kpi的重要度、難度、中心度與拓撲層級,而wimp、wdiff、wcent、wtp為人工賦予的屬性權重值.

圖5 學習路徑生成算法流程圖Fig.5 Flow chart of learning path generation algorithm
2.2.2 算法流程 通用學習路徑生成算法流程如圖5所示.
圖中:
①待排序的知識點集合KG,本研究將知識圖譜中所有知識點都列為待排序的知識點集合,并且,為了后續的分析與計算,本研究手動指定了一個初始知識點KP0.
③知識點及關系的三元組列表L,可直接從Neo4j圖數據庫中導出.列表L的記錄信息為(KPm,R,KPn),表示知識點KPm與KPn的關系為R.
④知識點重要度、難度、中心度與拓撲層級屬性特征數據Impkpi、Diffkpi、Centkpi、Tpkpi以及知識點排序指標Wkpi.
⑥結合知識圖譜及知識點屬性特征數據,利用拓撲排序算法生成學習路徑.
最后,算法的輸出為通用的學習路徑Pathkp,Pathkp=(KP1,KP2,…,KPn).
3 實驗分析

實驗環境及設備工具的選擇對實驗結果有較大的影響,為了盡可能產生最好的實驗效果,主要使用的系統開發環境如表2所示.
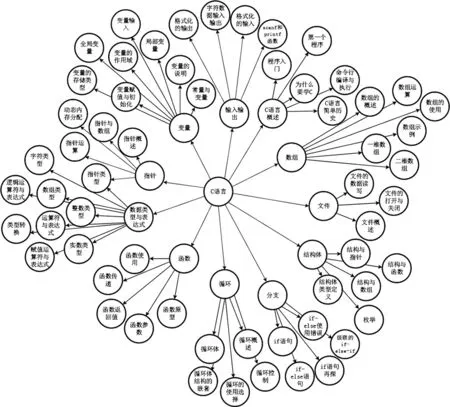
圖6 《C語言程序設計》知識圖譜Fig.6 Knowledge graph of C language programming
從某在線學習平臺隨機爬取某大學本科必修課程“C語言程序設計”,將其處理后轉為文本.利用TextRank提取關鍵詞算法得到500個待排序知識點集合及其重要度值Impkpi,經篩選后添加知識節點關系屬性,同時結合專業課程書籍將知識點與知識點之間的關系整理成CSV文件,并將文件導入到Neo4j圖數據庫中形成可視化的知識圖譜,如圖6所示.
根據知識圖譜中知識點屬性及其之間的關系,分別計算得到知識點難度、中心度、拓撲層級屬性特征值Diffkpi、Centkpi、Tpkpi.利用公式(4)計算并調試參數后得到知識點排序指標Wkpi,其計算結果如表3所示.

表3 屬性特征及排序指標的值Tab.3 Attribute characteristics and values of sorting indicators
結合上述步驟,并使用設計的知識點拓撲排序算法自動生成基于知識圖譜的通用學習路徑,將路徑可視化后如圖7(a)所示.同時,邀請相關領域專家對知識點進行路徑設計,生成了專家路徑,如圖7(b)所示.

圖7(a) 自動生成路徑Fig.7(a) Auto-generate path圖7 (b)專家路徑Fig.7(b) Expert path
完成算法實現與參數調試后,為得到學習路徑自動生成質量,將其與專家路徑做效果對比.路徑相似度計算公式如下所示.
(5)
式中:pathep、pathat分別為專家路徑與自動生成路徑;KPmatched為專家路徑與自動生成路徑相匹配的學習路徑個數;KPtotal為學習路徑總數.
由公式(5)計算得到自動生成的學習路徑與專家設計的路徑相似度為81.94%,說明本研究設計的基于知識圖譜自動生成的學習路徑的規劃方法是可行的.
此外,還利用了學習路徑評估指標fitness[10],進一步檢驗自動生成路徑的質量.fitness評估指標的計算公式如下所示.
(6)
式中:penaltyadi為學習路徑違背知識點間相鄰原則的數量;penaltyorder為學習路徑違背知識點間先修后繼原則的數量.學習路徑違背規則的數量越少,fitness數值就越小,說明路徑生成的質量越高.

根據公式(6)計算專家路徑與自動生成路徑的fitness評估指標如表4所示.可見,自動生成路徑的fitness值偏小,與專家路徑的fitness指標值差距也較小,說明自動生成路徑的質量較高,接近專家設計路徑的水準.
通過兩種方法生成的路徑評測表明,本研究設計的基于知識圖譜的通用學習路徑的自動生成方法是合理的、可解釋的,且路徑生成的質量較高.
與采用多重智能型算法生成的個性化學習路徑相比[3],通用學習路徑的生成受到稀疏問題的影響較小,無需事先得到大量學習者信息才能為其提供路徑推薦;本研究應用TextRank算法與使用BiLSTM+CRF模型[12]進行實體抽取相比,直接獲取了知識節點的重要度,降低了算法時間復雜度.
4 結論
本研究設計了一種從知識圖譜到通用學習路徑自動生成的方法,為個性化學習路徑的生成與學習資源的推薦乃至個性化學習系統的構建打下堅實基礎.實驗表明通用學習路徑生成方法的可行性較高,質量也較好,在線學習過程中可替代專家制定的路徑,為在線學習者提供一條通用、合理與可解釋的學習路徑,從而提高在線學習者的學習效率與質量.
在進一步的研究中可以考慮,如知識圖譜中難度屬性可從歷史學習者的知識點得分記錄,學習時間成本等角度考慮,實現難度取值多元化;對比實驗環節,組織被試人員依據路徑開展學習,進一步驗證自動生成路徑的質量與效果.后續研究將主要針對以上方面進行更為深入的探討與分析.
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
