動態(tài)場景中的單目視覺里程計
2022-05-25 15:46:48傅彬,金棋
電視技術(shù) 2022年4期
傅 彬,金 棋
(紹興職業(yè)技術(shù)學(xué)院,浙江 紹興 312000)
0 引 言
隨著城市現(xiàn)代化的發(fā)展,交通變得愈加擁堵,能源浪費嚴(yán)重,因而自動駕駛汽車在人們的生活中就顯得尤為重要。自動駕駛至關(guān)重要的任務(wù)是自動駕駛汽車對三維環(huán)境的感知和定位。自動駕駛汽車感知環(huán)境時用到多種傳感器,如激光雷達(dá)、毫米波雷達(dá)等。攝像頭相比于激光雷達(dá)等距離傳感器有價格低廉、重量輕、耗能少等優(yōu)點,因此基于攝像頭的定位和三維環(huán)境感知成為研究的熱點。車載環(huán)境是復(fù)雜的動態(tài)環(huán)境,環(huán)境中不僅有正在運動的行人、車輛等目標(biāo),還有房屋和樹木等靜止的背景,因此,自動駕駛技術(shù)需要在三維環(huán)境中獲得自身的位置信息、靜態(tài)障礙物位置估計以及三維運動目標(biāo)的位置和角度估計,來保證行車安全。
視覺同步定位與建圖(Simultaneous Localization and Mapping,SLAM)[1]算法能夠?qū)崿F(xiàn)靜態(tài)環(huán)境中的定位和地圖構(gòu)建,但是在動態(tài)環(huán)境如車載環(huán)境中,視覺SLAM精確度會變差。因為視覺SLAM采用靜態(tài)特征點計算相機運動,如果不能區(qū)分圖像中靜止和運動的特征點,計算得到的相機位姿將會出錯。視覺SLAM中常常采用RANSAC[2]算法剔除異常特征點,如果圖像中僅有少量運動特征點,RANSAC根據(jù)大部分符合模型的靜態(tài)特征點剔除運動特征點使得估計相機運動較為準(zhǔn)確。RANSAC這種方法在低動態(tài)場景中比較適用,但是在車載環(huán)境中,運動車輛占圖像大部分面積或被前車大量遮擋,將會降低SLAM的魯棒性。現(xiàn)有的multibody SFM[3]和multibody SLAM[4]提出基于運動分割SFM和SLAM用于動態(tài)環(huán)境中相機定位,但是需要事先得到運動目標(biāo)和靜止背景的先驗信息或者從運動物體占大面積的圖像中得到幾何約束的缺點,所以不能很好地解決未知的車載環(huán)境下視覺SLAM定位問題。
現(xiàn)有的單目視覺的測距方法中,任工昌等人[5]提出一種由變焦鏡頭獲得焦距與像距的雙脈沖數(shù),利用神經(jīng)網(wǎng)絡(luò)計算物距的單目視覺測距。朱丙麗等人[6]將裁剪后的圖像輸入多通道卷積神經(jīng)網(wǎng)絡(luò),得到多個深度圖候選對象,并將其映射合并為一個深度映射候選對象,最后通過傅里葉反變換生成最終估計深度圖。STEIN等人[7]根據(jù)投影幾何關(guān)系估計地面上物體深度和垂直物體高度。基于深度神經(jīng)網(wǎng)絡(luò)的單目深度估計雖然能夠得到相對深度但是無法得到絕對深度,而幾何測距方法存在需要事先標(biāo)定相機安裝外參參數(shù)的缺點。
目前,基于深度卷積網(wǎng)絡(luò)的目標(biāo)檢測和分割已經(jīng)達(dá)到了很高的精度,目標(biāo)檢測算法、語義分割算法及實例分割算法都能達(dá)到高檢測精度。雖然二維圖像目標(biāo)檢測能夠精確地在圖像中檢測目標(biāo)的位置,但是不能直接得到目標(biāo)物體的三維信息。因此有人提出單目3D目標(biāo)檢測算法。現(xiàn)有的單目3D目標(biāo)檢測算法通過帶有目標(biāo)3D信息的標(biāo)簽有監(jiān)督訓(xùn)練端到端的神經(jīng)網(wǎng)絡(luò),直接通過神經(jīng)網(wǎng)絡(luò)輸出目標(biāo)6自由度姿態(tài)和尺寸,但是3D標(biāo)簽標(biāo)注獲取困難,會對網(wǎng)絡(luò)訓(xùn)練樣本數(shù)量帶來影響,并且這類方法只能得到可能運動的物體,但是不能確定物體目前是否在運動。
本文針對以上不足,提出使用深度學(xué)習(xí)對圖像實例分割,結(jié)合慣性傳感器單元(Inertial Measurement Unit,IMU)預(yù)測得到的運動信息在分割結(jié)果上分離得到靜止目標(biāo)、運動目標(biāo),利用靜止特征點進(jìn)行視覺定位和三維重建。
1 相關(guān)工作
在動態(tài)環(huán)境中實現(xiàn)相機定位、靜態(tài)目標(biāo)定位以及動態(tài)目標(biāo)深度和角度估計,需要分割圖像中的運動目標(biāo),靜態(tài)特征點用于視覺定位,估計運動目標(biāo)深度和角度。
基于深度神經(jīng)網(wǎng)絡(luò)的圖像目標(biāo)檢測和分割算法,能夠精準(zhǔn)識別圖像中物體并用框或者像素級掩模標(biāo)記目標(biāo)在圖像中的位置。深度卷積網(wǎng)絡(luò)能夠檢測和分割車載環(huán)境下拍攝得到的目標(biāo),可以從預(yù)測標(biāo)簽中用人類先驗知識判斷目標(biāo)是否會運動,比如樹木和建筑物標(biāo)簽的物體是不會運動的,但是根據(jù)標(biāo)簽無法得知車輛、行人等可能會運動的目標(biāo)是否在運動。在固定攝像頭的情況下,JAIN等人[8]提出幀間差分法,該方法運算速度快,但一般不能完全檢測出運動物體的所有像素點并且常常在檢測到的運動物體內(nèi)部出現(xiàn)“空洞”現(xiàn)象。針對幀間差分法的不足,人們提出基于統(tǒng)計的背景建模,WREN等人[9]提出單高斯模型的背景建模,STAUFFER等人[10]提出高斯混合模型背景建模方法,能夠更好地適應(yīng)復(fù)雜場景。基于非概率的背景建模方法中,LONG等人[11]提出基于樣本一致性(SACON)的背景建模方法,BARNICH等人[12]提出ViBe算法,不需要假定任何的概率模型,計算速度快。靜止的攝像機在監(jiān)控環(huán)境下應(yīng)用廣泛,但是在車載環(huán)境中,攝像機在運動,圖像中物體的運動來源于物體獨立運動和相機運動的疊加,因此固定攝像頭運動目標(biāo)分割的方法在運動攝像頭下大部分都失效。在運動攝像頭情況下,基于動態(tài)物體先驗知識的運動分割方法中,WANG等人[13]將運動物體上的SURF描述子構(gòu)成一個集合,在SURF特征點檢測時通過與集合中的描述比較來確定運動物體。雖然基于運動物體先驗知識方法對退化運動比較有效,但是需要事先得到運動目標(biāo)和靜止背景的信息。基于幾何約束的方法中,JUNG等人[14]采用隨機投票的方式選出滿足同一對極幾何約束的特征點。基于幾何約束的方法雖然不需要先驗知識,通過跟蹤以前幀中靜止特征點計算運動,但是在運動物體占大面積的圖像中靜止特征點將會跟蹤失敗,因此在運動物體占大面積的圖像中將失效。
目前,單目視覺SLAM根據(jù)特征點是否需要匹配可以分為特征點法和直接法兩類。PTAM算法提出并實現(xiàn)了跟蹤與建圖并行處理,是第一個后端非線性優(yōu)化的算法。ORB-SLAM算法繼承了PTAM算法多線程的優(yōu)點,采用ORB特征并使用三個線程(tracking,local mapping和loop closing)完 成SLAM。基于直接法的SLAM被提出用于克服基于特征點優(yōu)化的SLAM在特征點提取匹配上比較耗時、特征點比較稀疏等缺點。ENGEL等人[15]提出的LSD_SLAM描述了像素梯度與直接法的關(guān)系以及像素梯度與極線方向在半稠密重建中的角度關(guān)系。直接法容易受到光照、曝光時間等影響,導(dǎo)致算法魯棒性降低。ENGEl等人[16]提出了光度標(biāo)定,認(rèn)為對相機的曝光時間、暗角、伽馬響應(yīng)等參數(shù)進(jìn)行標(biāo)定后,能夠提高魯棒性。但在實際車載環(huán)境中,實際行車路線和數(shù)據(jù)集采集過程中采集車的行車路線有著不同之處,在實際行車過程中很少形成閉環(huán),如果閉關(guān)檢測錯誤,將引入很大的誤差。
本文通過深度神經(jīng)網(wǎng)絡(luò)實例分割得到目標(biāo)類型的先驗知識,區(qū)分出靜止的背景和可能會運動的目標(biāo);采用IMU信息估計相機運動,在可能會運動的物體中分類正在運動的目標(biāo)和靜止目標(biāo),利用靜止特征點同時定位和地圖重建,并且估計道路平面方程,得到可行駛區(qū)域。
2 理論基礎(chǔ)
2.1 符號與定義
在本文中,定義(·)w為世界坐標(biāo)系,z軸方向與重力對齊。為采樣第kth幀圖像時攝像機坐標(biāo)系,為采樣第kth幀圖像時的IMU坐標(biāo)系,如圖1所示。
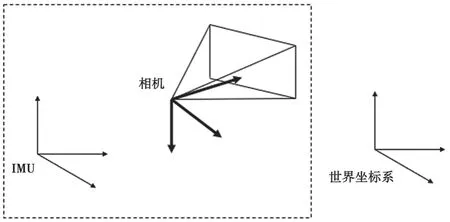
圖1 坐標(biāo)系
本文使用旋轉(zhuǎn)矩陣R表示旋轉(zhuǎn),用下標(biāo)表示旋轉(zhuǎn)方向,如Rcw表示世界坐標(biāo)系到攝像機坐標(biāo)系的旋轉(zhuǎn)。位移用P來表示,Pcw表示在世界坐標(biāo)系下攝像機的位置。重力用gw=[0 0g]T表示,g=-9.81 m·s-2為重力加速度大小。用Spc表示攝像機坐標(biāo)系下三維點坐標(biāo),Spw表示世界坐標(biāo)系下三維點坐標(biāo)。表示第kth幀相機運動狀態(tài),。本文用表示測量值。記李代數(shù)到李群的指數(shù)映射和李群到李代數(shù)的對數(shù)映射:
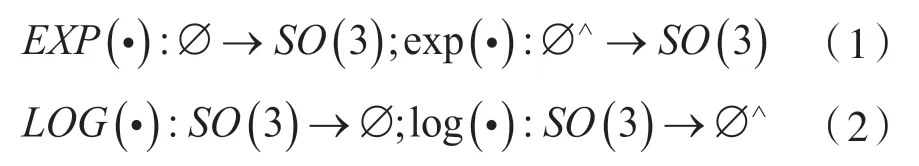
式 中:?∈R3,?∧為反對稱矩陣運算,。
2.2 IMU運動狀態(tài)
慣性傳感器單元(Inertial Measurement Unit,IMU)包含三軸加速度計和三軸陀螺儀,分別測量得到IMU坐標(biāo)系下加速度和三維角速度。
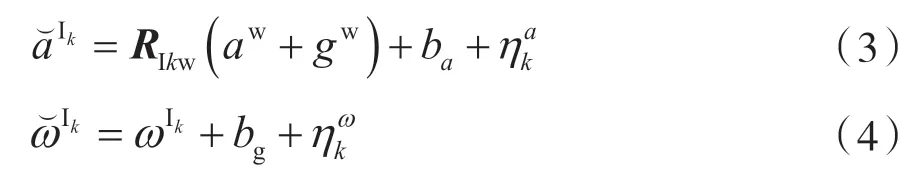
此處忽略地球旋轉(zhuǎn)的影響,認(rèn)為地球為慣性參考系。
根據(jù)IMU運動學(xué)模型,假設(shè)在?t時間內(nèi)和是常數(shù)且IMU采樣與攝像機采樣同步,由于IMU采樣速率比攝像機快,因此需要計算兩幀之間IMU采樣值的計算。第k幀和第k+1幀之間IMU采樣j-i次,IMU運動方程如下:
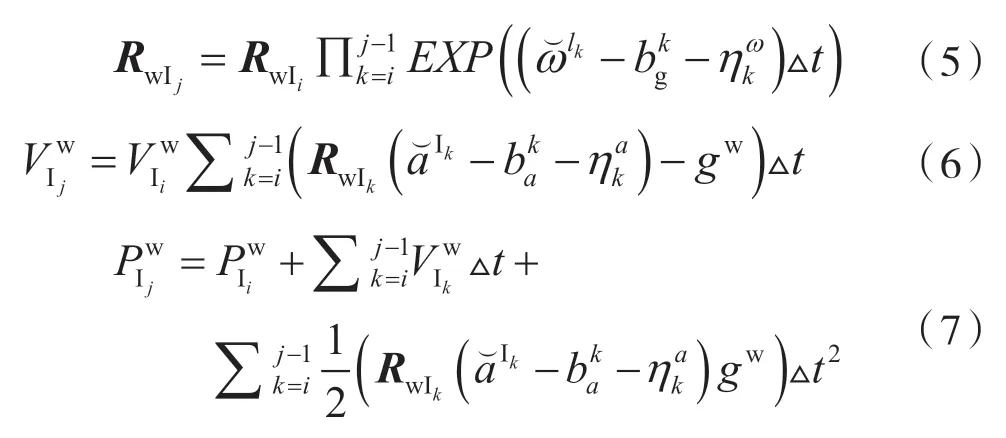
2.3 攝像機投影模型
投影三維點到圖像平面,首先要將世界坐標(biāo)系中的點轉(zhuǎn)換到攝像機坐標(biāo)系中,如式(8)所示。

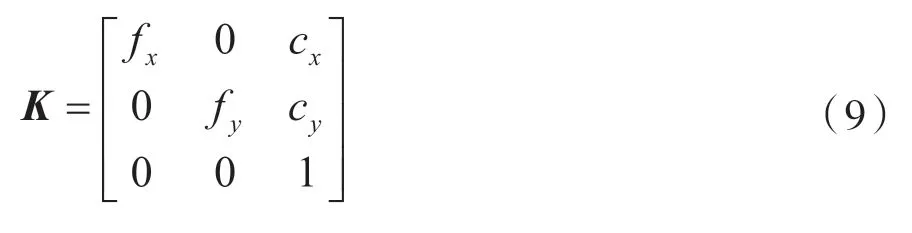
本文采用針孔攝像機模型,攝像機內(nèi)參矩陣K事先標(biāo)定得到式(9)。
3 系統(tǒng)框架
本文實現(xiàn)的視覺定位、三維重建與運動目標(biāo)定位系統(tǒng),總共由運動分割模塊和視覺慣性里程計模塊兩個部分組成,如圖2所示。
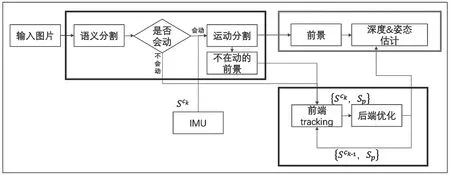
圖2 系統(tǒng)框圖
場景中有靜止的背景如房子、道路,交通燈等,也有可能會運動的物體,如車輛和行人。運動分割模塊的作用是將運動物體和靜止物體分離出來,分離得到靜止的背景、靜止的物體以及運動的物體,從而將圖像中的特征點分為運動物體上的特征點和靜止物體上的特征點。運動分割模塊為視覺慣性里程計提供靜止的特征點,幫助視覺慣性里程計更具有魯棒性。深度神經(jīng)網(wǎng)絡(luò)對圖像進(jìn)行實例分割,得到物體的分割掩模,沒有被分割的部分為道路、房子等背景,被分割出來的物體為交通牌、行人和車輛等目標(biāo),通過先驗知識可以判斷物體能不能運動,但是實例分割不能判斷當(dāng)前幀物體是不是在運動。本文利用IMU估計運動和對極幾何約束區(qū)分當(dāng)前時刻正在運動的物體和靜止物體。靜止物體和背景上的特征點作為視覺慣性里程計的輸入。
基于特征點的視覺里程計估計相機運動、特征點三維點位置以及IMU偏置。視覺里程計接收靜止特征點作為輸入,減少RANSAC迭代次數(shù)。每來一幀新圖像,先用IMU預(yù)測相機運動Sck,用于運動分割。優(yōu)化后得到的相機運動輸出作為運動目標(biāo)深度估計模塊的輸入。
4 運動分割
車載環(huán)境下,攝像機采集的圖像有著三維環(huán)境場景大、攝像機運動速度快、圖像中有大塊快速運動物體等特點。視覺SLAM算法通過多幅圖像中靜止的特征點根據(jù)多視角幾何關(guān)系完成同時定位與三維重建的任務(wù),但是兩幀圖像中的特征點可能是誤匹配,也可能是運動物體,視覺SLAM常常采用RANSAC算法排除這些異常值。
RANSAC算法是一種從帶有異常值的數(shù)據(jù)中估計模型參數(shù)的算法。視覺SLAM利用RANSAC算法從圖像匹配好的特征點對中估計相機旋轉(zhuǎn)R和位移t,其中異常值為誤匹配的特征點對和位于運動物體上的特征點。RANSAC算法從觀測的特征點對中隨機采樣最小點對集合,通過最小點對集合計算模型假設(shè),通過其他點對驗證模型假設(shè),反復(fù)采樣N次之后,選擇最符合其他點對的模型假設(shè)作為最佳模型。采樣次數(shù)N是RANSAC算法成功與否的非常重要的參數(shù),如式(10)所示:

式中:s為隨機采樣最小點對集合的大小,ε為異常值占所有數(shù)據(jù)的比例,p為置信度。在置信度為p的情況下,N次采樣中,至少有一次采樣得到的最小點對集合中的點對全部為正常值。以八點法為例,s=8,異常值比例ε=60%,要達(dá)到p=99%的置信度,需要迭代至少7 025次。當(dāng)靜止特征點在圖像中占主要部分時,RANSAC算法能發(fā)揮用處,但是在車載環(huán)境中,攝像機前有大量動態(tài)物體或者被運動物體遮擋大部分畫面時,RANSAC算法將會失效,因此,找出圖像中正在運動的物體顯得尤為重要。
4.1 基于幾何約束的運動目標(biāo)分割
圖像上二維點的運動是二維點對應(yīng)的三維點在空間中的獨立運動和相機運動造成的。因此,想要找出獨立運動的物體,需要排除相機運動的干擾。對極幾何約束是兩個視角之間的投影幾何關(guān)系,如圖3所示,對于靜止的三維點P在兩幀的投影x1、x1′滿足x1′TFx1=0。其中F矩陣為基本矩陣(fundamental matrix),,對極線l2=Fx1。對于非退化的運動,若P點運動到P′點,P′在第二幀上的投影x2′將不滿足對極幾何約束。
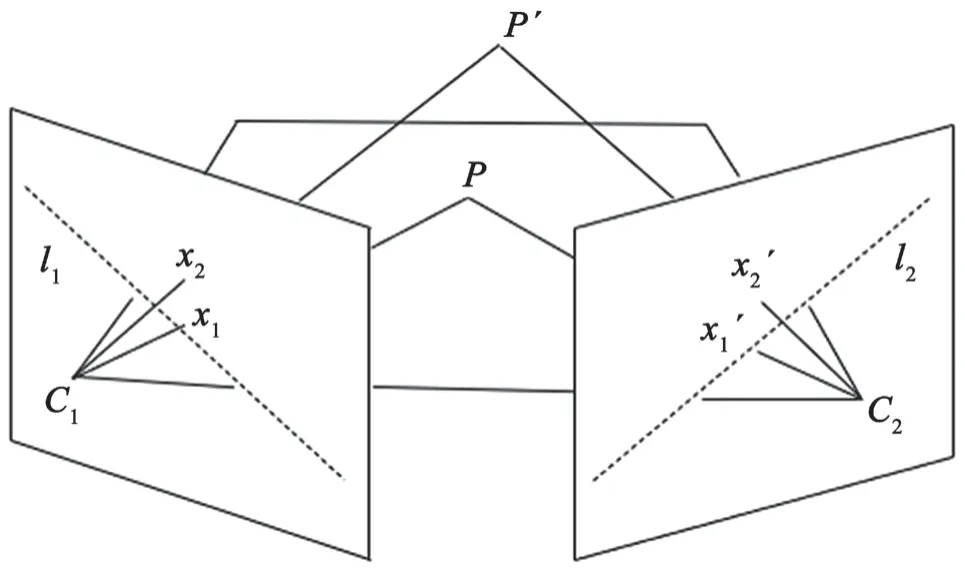
圖3 對極幾何約束
本文采用基于卷積神經(jīng)網(wǎng)絡(luò)的物體分割方法,用Mask R-CNN對圖像中的物體進(jìn)行實例分割,確定圖像中的物體,如圖4所示。通過Mask R-CNN輸出的物體標(biāo)簽,將物體分為不會運動的物體(如交通燈)和會運動的物體(如汽車),但是還不能確定這輛汽車是停靠在路邊的汽車還是開動的汽車。

圖4 語義分割和運動分割的對比圖
在不知道兩幀運動之前,視覺SLAM算法采用八點法或五點法,用RANSAC的方法從特征點集中計算基本矩陣F并分解得到相機運動,同時分辨出異常值。但是這在高動態(tài)環(huán)境中是不適用的,在不知道相機運動的情況下無法得到基本矩陣F,在沒有基本矩陣F的情況下不能得到正常值計算相機運動。本文利用慣性傳感器信息,在視覺慣性里程計優(yōu)化之后用IMU測量得到的加速度和角速度估計相機運動,得到下一幀圖像的旋轉(zhuǎn)R和位移t,用于計算基本矩陣F。
本文采用圖像上特征點到對極線的距離來評價3D點運動與否,如式(11)所示。
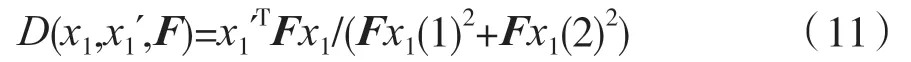
式中:Fx1(i)表示Fx1向量第i個元素。圖像經(jīng)過Mask R-CNN實例分割的多個剛體,對于同一物體上的特征點滿足相同基本矩陣F,因此采用RANSAC算法去除同一個物體上錯誤的特征點匹配。第k個物體上的特征點到對極線的平均距離如式(12)所示。
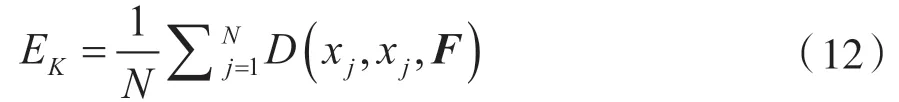
若同一個物體上特征點到對極線的平均距離EK>threshold則判定物體為獨立運動物體。判決閾值threshold的選取如圖5所示,選取運動目標(biāo)與靜止目標(biāo)最開始相交的點作為判決閾值。
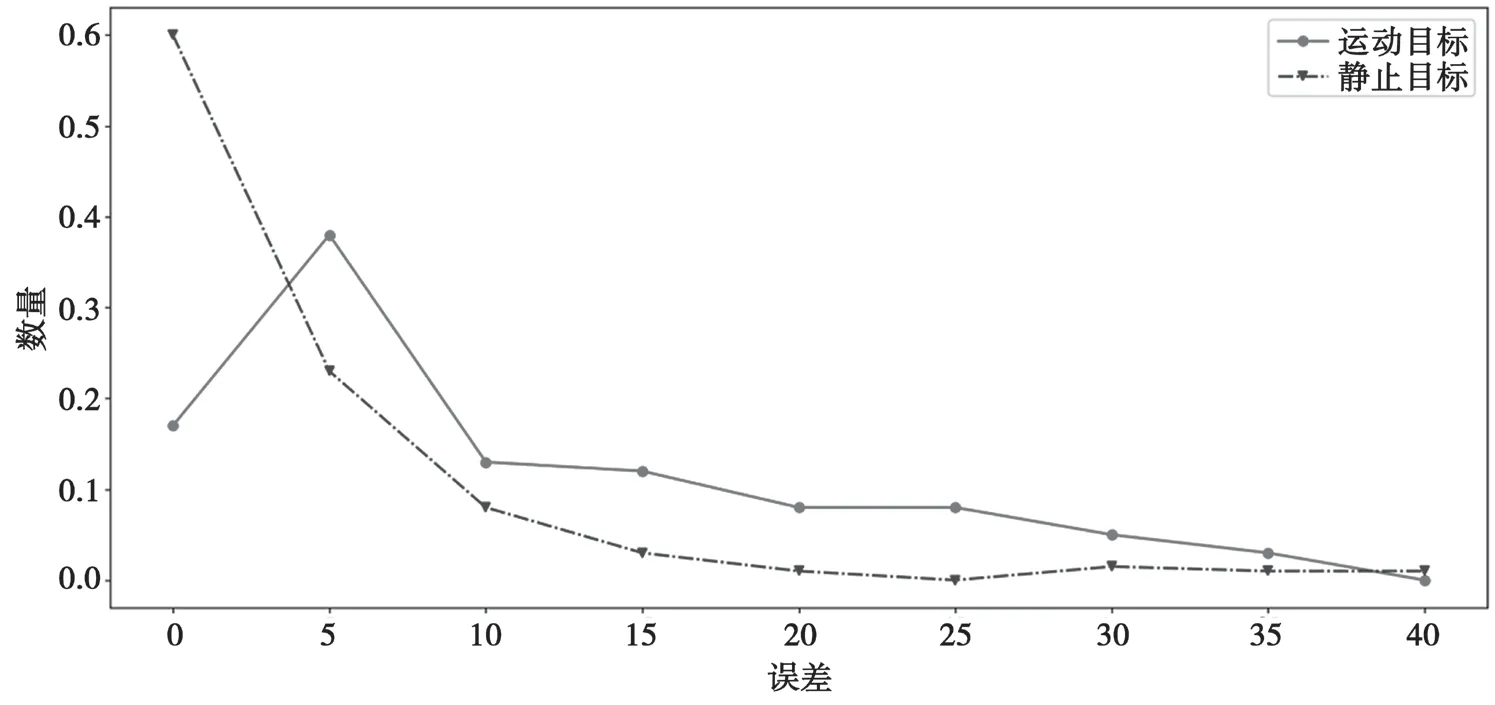
圖5 對極幾何約束誤差直方圖
4.2 攝像機運動估計和地面建模
由于車載視頻攝像機運動較大,直接法容易陷入局部最優(yōu)解,并且直接法容易受到室外光照變化的影響,因此本文選擇較為魯棒的基于特征點的視覺SLAM。由于應(yīng)用場景不同,與室內(nèi)場景和AR應(yīng)用不同,在車輛行駛過程中很少有閉合回路的情況出現(xiàn),在高速公路上更不可能閉合回路,因此回環(huán)檢測線程對于車載環(huán)境來說是沒有必要的。本文去除回環(huán)檢測線程,保留前端跟蹤線程和后端優(yōu)化線程。
視覺里程計前端跟蹤模塊用于計算兩幀之間的相機運動,包括旋轉(zhuǎn)和位移。前端跟蹤模塊將地圖中的三維點投影到當(dāng)前幀并與當(dāng)前幀特征點匹配,通過優(yōu)化當(dāng)前幀j上所有匹配上的特征點的重投影誤差得到相機運動。
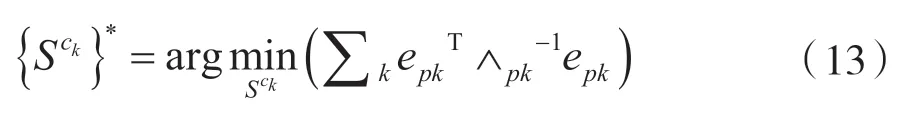
后端優(yōu)化模塊的作用是減少誤差累積。后端優(yōu)化是對連續(xù)n個關(guān)鍵幀狀態(tài)和h個關(guān)鍵幀能觀測到的三維點進(jìn)行優(yōu)化。當(dāng)有新的一幀被確認(rèn)為關(guān)鍵幀時,開啟后端local BA優(yōu)化地圖中n個關(guān)鍵幀能夠觀測到的三維點和相機狀態(tài)。
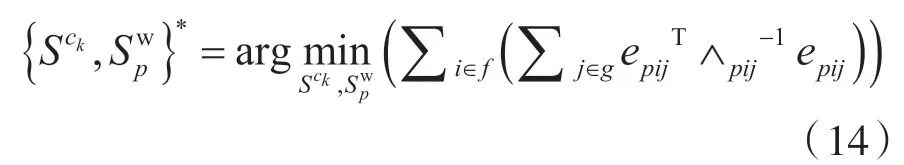
式中:f為待優(yōu)化幀的集合,g為待優(yōu)化三維點的集合。
假設(shè)圖像中下方1/3、中間1/5的位置是地面,且地面是一個平面。視覺SLAM根據(jù)靜態(tài)背景的特征點已經(jīng)估計出兩幀之間相機相對位姿{(lán)R,p}。圖像中位于地面上的特征點在三維中處于同一個平面,根據(jù)平面單應(yīng)性質(zhì),第i幀同一個平面特征點映射到第j幀xj′=Hxi,其中H為單應(yīng)矩陣,{n,d}為平面方程。第j幀與第i幀匹配特征點得到觀測量xk。為了得到路面方程,以重投影誤差建立目標(biāo)函數(shù),優(yōu)化目標(biāo)函數(shù)得到地平面方程{n,d}。


式中:eHk=xj′-xj。估計得到路面的平面方程y=nTx+d。距離地面10 cm以上的三維點被認(rèn)定為靜態(tài)障 礙物。
4.3 基于運動分割的單目視覺定位
本文構(gòu)建的系統(tǒng)在KITTI數(shù)據(jù)集[17]上測試。KITTI是無人駕駛數(shù)據(jù)庫,包含長達(dá)將近50 km不同場景下的行車圖像以及激光雷達(dá)和IMU信息。這個歷程及序列中,相機旋轉(zhuǎn)和位移速度較快,還包含部分運動目標(biāo),對于單目視覺具有一定挑戰(zhàn)性。序列00-10提供每幀相機位置和姿態(tài),通過相似變換讓每幀軌跡與真實軌跡對齊,測量絕對路徑誤差。所有實驗在Intel Core i7-4810MQ(2.8 GHz,4 cores)的CPU和8 GB內(nèi)存的筆記本電腦上運行,可以達(dá)到實時的要求。
表1顯示了每幀估計的軌跡均方根誤差(Root Mean Square Error,RMSE)以及真實地圖的大小。本文分別比較了不做任何處理的ORB-SLAM算法和運動分割的ORB-SLAM算法的軌跡RMSE。由表1可知,有運動分割比沒有運動分割的ORBSLAM算法在序列02-06、08-10上的RMSE好1.91%~23.75%,序列00、07分別變差6.78%、13.2%。運動分割有助于車載環(huán)境下提高單目SLAM的魯棒性和精確度。圖6為顯示相機運動軌跡對比圖。

圖6 相機運動軌跡
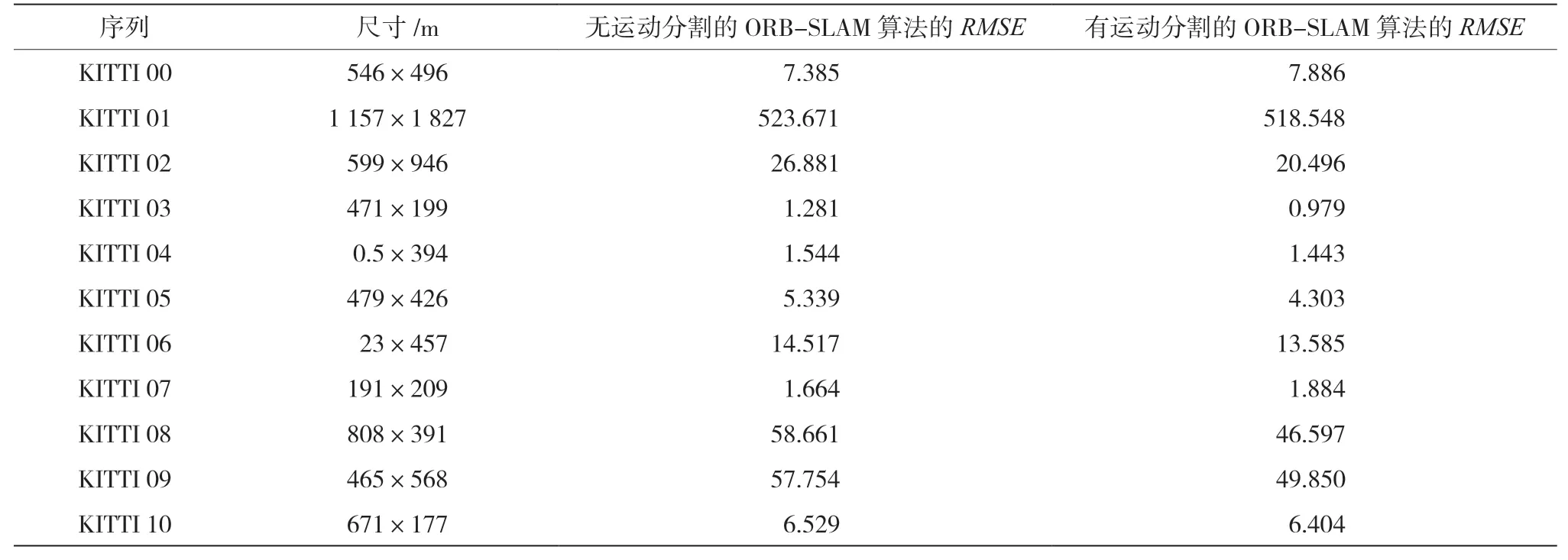
表1 KITTI視覺里程計測試
5 結(jié) 語
本文提出的深度神經(jīng)網(wǎng)絡(luò)實例分割結(jié)合IMU可以有效實現(xiàn)運動對象、靜止對象及靜止背景的分離,克服圖像中運動物體占圖像大部分面積時無法運動分割的缺點。在KITTI車載數(shù)據(jù)庫上的實驗表明,本文提出的方法可以精確地估計自身運動,重建靜態(tài)三維場景。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學(xué)學(xué)報(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀(jì)智能(英語備考)(2019年12期)2020-01-13 06:07:18
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
