基于極限梯度爬升算法與支持向量回歸算法變權(quán)組合模型致密油的采收率預(yù)測
2022-05-19 13:37:20張金水田冷黃詩慧董鵬舉
科學(xué)技術(shù)與工程 2022年12期
關(guān)鍵詞:模型
張金水, 田冷, 黃詩慧, 董鵬舉
(中國石油大學(xué)(北京)石油工程學(xué)院, 北京 102200)
非常規(guī)油氣藏作為中外日益?zhèn)涫苤匾暤挠蜌赓Y源,各國對致密油藏等非常規(guī)油氣藏都加大了勘探開發(fā)力度,而可采儲量是油氣田開發(fā)動態(tài)分析的基礎(chǔ),可評估油氣藏開采潛能大小,不同采出程度可表征當前油氣田的不同開發(fā)階段,中后期可根據(jù)采收率預(yù)測的變化對生產(chǎn)措施實時調(diào)控,更好地適應(yīng)油藏的開采,為油田的進一步提高采收率提供戰(zhàn)略性的部署。以中國某致密油藏為例,儲層巖性和孔隙結(jié)構(gòu)復(fù)雜、滲透率低,其儲層為裂縫—孔隙雙重介質(zhì),裂縫所占的儲集空間遠小于基巖的儲集空間,滲流特征難以表征,可采儲量影響因素復(fù)雜多變,導(dǎo)致難以準確計算儲層壓裂后采收率,因此需要建立一種動態(tài)監(jiān)測可反映出該致密油藏壓裂水平井開發(fā)的生產(chǎn)動態(tài)分析和采收率預(yù)測方法,一是可以評估當前儲層改造程度[1],二是可實時獲取施工參數(shù)對產(chǎn)量的直接影響,便于動態(tài)指導(dǎo)施工。
以往對致密油藏的研究表明,對致密油的采收率預(yù)測可分為宏觀平衡法和微觀實驗法。宏觀平衡法是根據(jù)油藏的類型,進行物質(zhì)平衡分析,從宏觀上來預(yù)測油藏的可采儲量,孫賀東等[2]建立冪函數(shù)形式的高壓、超高壓氣藏物質(zhì)平衡方程,分析了視儲層壓力衰竭程度和采出程度對儲量計算可靠性的影響;畢海濱等[3]以物質(zhì)平衡時間法來評估試采階段出現(xiàn)邊界流動特征的單井可采儲量。微觀實驗法是根據(jù)巖心滲流實驗、試井解釋、水驅(qū)特征曲線的變化進程等來進行微觀儲量分析。Clarkson等[4]研究了經(jīng)典速率瞬變技術(shù)(流動狀態(tài)分析、類型曲線方法和模擬)在致密油儲層分析的應(yīng)用;Cook[5]以遞減曲線回歸法完成了三叉形地層石油資源的評估;耿站立等[6]將具有唯一解的常用水驅(qū)特征曲線優(yōu)選問題轉(zhuǎn)化為廣適水驅(qū)特征曲線與丙型、丁型曲線聯(lián)合求取唯一解問題,提高了不同水驅(qū)方式下采收率預(yù)測精度。但致密油儲層滲透率低、單井產(chǎn)能低的特性決定了其開發(fā)大多伴隨著壓裂施工改造過程,對于多因素分析的致密儲層壓裂改造后的采收率預(yù)測模型研究尚有不足,而微觀實驗法所需要的成本高昂且步驟復(fù)雜,易受到外界因素干擾。
人工智能作為一種新興的熱門領(lǐng)域,因其同時兼?zhèn)浯髷?shù)據(jù)分析與精細模擬的優(yōu)勢,被廣泛應(yīng)用于圖像音色識別[7]、無人系統(tǒng)駕駛[8-9]以及智能計算芯片[10]等,在各個行業(yè)領(lǐng)域中不斷得到傳播和發(fā)展[11]。近年來,機器學(xué)習被廣泛應(yīng)用于石油行業(yè),如儲層酸壓性能預(yù)測[12]、壓裂縫網(wǎng)表征[13]、裂縫處理[14]、注采井間連通性識別[15]等,機器學(xué)習可以有效承接油氣勘探形成的海量地質(zhì)信息、井信息以及生產(chǎn)數(shù)據(jù)信息,支撐精細油氣藏描述模型的建立,為致密油藏的采收率實時、精準預(yù)測提供了可能。李磊等[16]在算法研究領(lǐng)域,運用加速遺傳組合算法,根據(jù)最小二乘原理提出了最優(yōu)離合點,優(yōu)化了以往以平均數(shù)群決策的綜合意愿不足的缺點;段友祥等[17]利用多種弱分類器組合算法進行巖性分類建立模型來預(yù)測儲層屬性參數(shù),從而計算油藏采收率,為融合算法在石油行業(yè)的發(fā)展提供了參考。但這類方法難以處理高維復(fù)雜數(shù)據(jù)、提取數(shù)據(jù)之間的深層關(guān)聯(lián)信息,在特征識別方面存在一定的不足。
為此,在多種弱分類器組合算法基礎(chǔ)之上提出一種新的融合算法,將極限梯度爬升算法(extreme gradient boosting algorithm,XGBoost)與支持向量回歸(support vector regression algorithm,SVR)算法以殘差自適應(yīng)性方式賦值單模型加權(quán)系數(shù)組合,建立致密油儲層壓裂后采收率預(yù)測模型。因機器學(xué)習中SVR算法可有效降低泛化誤差和計算復(fù)雜度,且具備高維度映射預(yù)測的優(yōu)勢,XGBoost算法可解釋性較強,多個決策樹模型可減小誤差相關(guān)度,因此XGBoost-SVR模型可以有效地利用單模型的優(yōu)勢所在,同時還能減小SVR單模型對核函數(shù)的敏感依賴大、XGBoost單模型數(shù)據(jù)集存在空間復(fù)雜度過高等結(jié)構(gòu)和功能上的缺陷。在模型中借鑒了殘差進化算法思想,不斷基于單模型殘差誤差分析更新模型的結(jié)構(gòu)參數(shù)和融合模型的加權(quán)系數(shù)[18-19],實現(xiàn)了不同模型間加權(quán)系數(shù)的最優(yōu)組合。從地質(zhì)、流體和工程三方面分析影響采收率的相關(guān)因素,原始數(shù)據(jù)集經(jīng)過數(shù)據(jù)預(yù)處理之后導(dǎo)入融合模型,通過特征識別來確定各影響因素排序,再經(jīng)過4折交叉驗證來驗證采收率的預(yù)測準確度,可通過實際工程數(shù)據(jù)和生產(chǎn)信息來實時反映采收率的變化指標,更有效地實現(xiàn)現(xiàn)場施工參數(shù)的動態(tài)調(diào)控,基于生產(chǎn)大數(shù)據(jù)可有效得模擬地質(zhì)構(gòu)造背景,反映真實的地下儲層改造情況,實現(xiàn)模型與實際工程間的仿真交互環(huán)境,實現(xiàn)對致密油的采收率動態(tài)預(yù)測。
1 研究方法
1.1 XGBoost原理
XGBoost算法[20]是一種集成的并行決策樹模型,是Boosting算法的一種結(jié)構(gòu)拓展和優(yōu)化,由多個決策樹弱分類器基于熵的組合形成一種具有預(yù)測性能的強分類器,在損失函數(shù)推導(dǎo)過程中,使用了一階導(dǎo)數(shù)gi和二階導(dǎo)數(shù)hi(對損失函數(shù)做二階泰勒展開求解函數(shù)),經(jīng)過多個迭代生成M輪CART回歸樹,并在目標函數(shù)之外加入正則項整體求最優(yōu)解,用以權(quán)衡目標函數(shù)的下降和模型復(fù)雜程度,進而準確求取目標參數(shù)。
學(xué)習多顆分類回歸樹的梯度加法模型,預(yù)測結(jié)果等于所有單決策樹的得分總和。其理論公式可表示為
(1)
定義目標函數(shù),即損失函數(shù)和正則項,可分別表示為
(2)
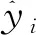
圖1中,所有弱分類器的結(jié)果相加等于預(yù)測值,然后下一個弱分類器氣擬合誤差函數(shù)對預(yù)測值的殘差。

y為單棵決策樹的預(yù)測目標值;fk(x)為第k棵決策樹所輸出的預(yù)測值圖1 XGBoost算法流程圖Fig.1 Flow chart of XGBoost algorithm
再將所定義的目標函數(shù)進行組合,并進行二階泰勒公式展開,求得最終目標函數(shù)為

(3)

1.2 SVR原理
SVR是一種劃分超平面方法,定義為特征空間上的間隔最大的線性分類器,即基本思想是實現(xiàn)多樣本數(shù)據(jù)點之間的間隔最大化原則,最終可轉(zhuǎn)化為一個凸二次規(guī)劃問題的求解[21]。SVR算法影響因素與預(yù)測數(shù)據(jù)之間的非線性擬合函數(shù)f(x,w)可表示為
f(x,w)=wφ(x)+b=(w,φ)+b
(4)
式(4)中:w為權(quán)值矢量;φ(x)為非線性映射,生成和輸入向量x同維的向量;b為偏差;(w,φ)為w和φ的內(nèi)積。
SVR也可用于非線性數(shù)據(jù)集的分類或回歸預(yù)測,存在數(shù)據(jù)樣本為線性不可分數(shù)據(jù)集時,提高空間維度來映射數(shù)據(jù)點,可引入適當?shù)暮撕瘮?shù)向高維空間進行映射,通過內(nèi)積函數(shù)從原始空間映射更高維空間,分析輸入因素與目標序列的特征關(guān)系組合,來實現(xiàn)非線性樣本分類或回歸預(yù)測。
核函數(shù)的最佳選擇是SVR模型最優(yōu)化問題的關(guān)鍵,在一定誤差允許內(nèi),預(yù)估目標輸出,同時最小化w模型參數(shù),使其具有更強的泛化能力。優(yōu)化目標等價于一個最基本的凸二次規(guī)劃問題,可表示為
(5)
(6)
式(6)中:ε為規(guī)定誤差;yi為目標值。
1.3 Pearson系數(shù)分析
Pearson相關(guān)系數(shù)是用來衡量定距不同因素變量之間的相互關(guān)聯(lián)程度。皮爾遜相關(guān)系數(shù)r表征的相互關(guān)聯(lián)程度為-1~1,系數(shù)越高,則不同變量之間的相互關(guān)聯(lián)程度越高。在分析多因素變量之間的影響相關(guān)度方面,更能反映出因素之間的冗余特征重合度,可實現(xiàn)多數(shù)據(jù)集的因素交互分析。
(7)

1.4 變權(quán)組合預(yù)測模型
構(gòu)建組合預(yù)測模型,關(guān)鍵參數(shù)是各單模型權(quán)重因子的賦值,采取的是殘差賦權(quán)法,基于雙模型預(yù)測參數(shù)與標準值的殘差分析,不斷更新其模型的適應(yīng)度,實現(xiàn)模型間的有效交互模式,達到準確預(yù)測回歸變量的目標。以XGBoost和SVR單模型預(yù)測數(shù)據(jù)與真實數(shù)據(jù)之間的殘差來確定組合模型的權(quán)重系數(shù),它融合各個模型的優(yōu)勢與特點,利用最優(yōu)化數(shù)學(xué)模型來求出各模型組合賦權(quán)系數(shù),來構(gòu)造基于殘差的自適應(yīng)變權(quán)組合模型來進一步提高致密油的采收率預(yù)測精確度。
(8)
式(8)中:n為預(yù)測模型的總個數(shù);ωi(t′)為t′時刻第i個模型的權(quán)重;εt′(t′)為t′時刻第i個模型的預(yù)測誤差平方和;f(xt′)為t′時刻融合模型的預(yù)測值;fi(xt′)為t′時刻第i個模型的預(yù)測值。
2 數(shù)據(jù)預(yù)處理
2.1 數(shù)據(jù)選擇
該致密油藏為裂縫—孔隙型雙重介質(zhì)儲層,存在儲層流體滲流特征復(fù)雜、啟動壓力梯度高等開發(fā)難點,不能準確得確定采收率的影響因素。原始數(shù)據(jù)集從地質(zhì)因素、儲層因素和工程因素三方面來選取采收率影響參數(shù),巖石儲層的物性參數(shù)對油氣藏的采收率有直接的影響關(guān)系,該地區(qū)儲層間的巖石孔隙度決定了油氣資源的富集度,有效厚度、含油飽和度等因素直接影響了油層的采出程度,工程改造參數(shù)(如加砂量與支撐劑濃度等)都會直接影響人工裂縫的導(dǎo)流能力,壓裂簇數(shù)則決定了壓裂井井筒的泄流面積,采收率標定按油藏數(shù)值模擬來表征相應(yīng)參數(shù)。將收集后的數(shù)據(jù)進行歸類整理,剔除與采收率無關(guān)或偏差較大的數(shù)據(jù),留下與采收率影響因素相符的數(shù)據(jù),部分數(shù)據(jù)集如表1所示。

表1 致密油部分影響因素原始參數(shù)集Table 1 Original parameter set of some influencing factors of tight oil
2.2 數(shù)據(jù)清洗
2.2.1 離群點處理
選取的生產(chǎn)數(shù)據(jù)離群點一般分為“真異常”和“偽異常”兩種,前者是由于各種地質(zhì)因素、特定工程因素導(dǎo)致的數(shù)據(jù)量變化,比如酸化或者壓裂之后,地層滲透率明顯增高,產(chǎn)量規(guī)模大幅度提高,這些都是基于油藏正常狀態(tài),而不是數(shù)據(jù)本身的異常;而后者是地質(zhì)條件如若未發(fā)生改變,數(shù)據(jù)分布明顯不合理,存在極大的統(tǒng)計誤差,排除因地下油藏條件變異反應(yīng),即為“偽異常”。可以根據(jù)該離群點是否存在工程措施、地下儲層是否發(fā)生明顯突變來判斷真?zhèn)萎惓#賹⒄砗玫牟墒章氏嚓P(guān)數(shù)據(jù)集進行二次處理,對空白字段、無意義數(shù)據(jù)進行刪除,來確保采收率數(shù)據(jù)的有效性。
由圖2可知,滲透率、溫度等參數(shù)存在異常值和離群點,如正常溫度為80~110 ℃,而統(tǒng)計溫度存在65.23、67.25 ℃異常點;滲透率整體范圍低于5 mD,而統(tǒng)計滲透率存在8.56 mD異常點,可基于井位初步判斷其地下條件,可根據(jù)該井附近的地層中溫來進行溫度和滲透率的校正。

圖2 數(shù)據(jù)異常值分析圖Fig.2 Data outlier analysis diagram
2.2.2 缺失值處理
現(xiàn)場采集致密油采收率影響因素數(shù)據(jù)時,油井的地震、測井、壓裂、生產(chǎn)等數(shù)據(jù)因鉆井、井下作業(yè)及工程因素,會存在一定記錄缺失和字段信息缺失等情況,其對數(shù)據(jù)分析和模型精度會有較大的影響,導(dǎo)致最終采收率預(yù)測結(jié)果帶有不確定性,所以有必要對采集的現(xiàn)場數(shù)據(jù)進行缺失值處理。
在此對數(shù)據(jù)采取基于統(tǒng)計學(xué)的填充方法,均值填充,取附近地質(zhì)儲層數(shù)據(jù)相近的三口井的均值作為填充數(shù)據(jù),每一個影響因素的填補都需要考慮其本身的工程背景含義,要在排除“真異常”點基礎(chǔ)上綜合補充缺失數(shù)據(jù)集。
2.3 特征相關(guān)性分析
首先計算采收率與各特征影響因素的皮爾森相關(guān)系數(shù),結(jié)果如表2所示,這可以在一定程度上判斷特征對于預(yù)測的作用。相關(guān)系數(shù)大于0.85的特征量可以去除,保留其一即可,避免造成數(shù)據(jù)冗余。

表2 Pearson相關(guān)系數(shù)Table 2 Pearson correlation coefficient
Pearson相關(guān)性分析可以有效提高變量特征與采收率因素之間的可解釋性,增強對采收率和影響因素之間的理解。經(jīng)過分析,如圖3所示,總液量與總加砂量、每簇加液量與每簇加砂量兩因素之間相關(guān)系數(shù)大于0.75,兩變量因素之間特征重合度過高,會降低主控因素對采收率的影響因子排序。

圖3 Pearson相關(guān)系數(shù)圖Fig.3 Pearson correlation coefficient diagram
因總液量與總加砂量、每簇加液量與每簇加砂量因素間Pearson系數(shù)屬于極強相關(guān),存在特征重疊冗余現(xiàn)象,因此需篩選因素特征。如圖4、圖5所示,根據(jù)特征因素吻合度差異選擇總加砂量與每簇加液量即可。

圖4 總加砂量、總液量對比分析Fig.4 Comparative analysis of total sand addition and total liquid volume

圖5 毎簇加砂量、毎簇加液量對比分析Fig.5 Comparative analysis of sand addition and liquid addition per cluster
3 模型構(gòu)建與調(diào)試
3.1 組合預(yù)測模型構(gòu)建流程
圖6為XGBoost-SVR模型流程圖,具體步驟如下。

圖6 XGBoost-SVR模型流程圖Fig.6 Flow chart of XGBoost-SVR model
步驟1根據(jù)測井數(shù)據(jù)、巖心分析、地震以及壓裂數(shù)據(jù)等采集目標區(qū)塊采收率影響因素原始數(shù)據(jù)集,構(gòu)造模型訓(xùn)練所支撐的數(shù)據(jù)集。
步驟2對原始采收率數(shù)據(jù)集進行必要的預(yù)處理分析,重點包括真?zhèn)萎惓7治觥?shù)據(jù)清洗、判斷數(shù)據(jù)準確性等,在缺失值部分采用屬性相近井資料數(shù)據(jù)進行均值補充。
步驟3各類型數(shù)據(jù)進行了篩選與整理,構(gòu)建單個機器學(xué)習模型,輸入數(shù)據(jù)按訓(xùn)練集∶測試集=7∶3進行隨機數(shù)據(jù)劃分后,以此為基礎(chǔ)分別訓(xùn)練SVR單模型和XGBoost單模型,不斷調(diào)試單模型超參數(shù),達到最優(yōu)之后保存各個訓(xùn)練模型。以訓(xùn)練好的模型來預(yù)測測試集數(shù)據(jù),最終得到SVR與XGBoost單模型預(yù)測結(jié)果。
步驟4對單模型預(yù)測值進行回歸分析,與實際值偏差滿足一定條件前提下,可進行組合模型構(gòu)建。
步驟5利用已訓(xùn)練好的單模型來基于殘差分析賦值各個單模型權(quán)重比例,不斷更新迭代其權(quán)重系數(shù),最終可得到組合模型最終預(yù)測結(jié)果。通過二者基于殘差自適應(yīng)變權(quán)組合形成的模型來進行致密油的采收率預(yù)測。
步驟6模型評價分析,根據(jù)模型評價指標比較模型預(yù)測能力,分析模型預(yù)測效果。
3.2 單模型調(diào)參
以采集的致密油藏采收率以及影響采收率的13種因素共122組生產(chǎn)數(shù)據(jù)集,作為樣本庫,其中隨機97組數(shù)據(jù)作為訓(xùn)練集,剩余25組作為測試集,建立XGBoost-SVR采收率預(yù)測模型。這是一個目標變量回歸預(yù)測問題,不同的模型原理和所得結(jié)果之間是存在差異的。此次融合了XGBoost以及SVR兩個模型,其中第一類可以看作是決策樹模型,SVR為支持向量機模型。這兩類模型原理相差較大,產(chǎn)生的結(jié)果相關(guān)性較低,融合有利于提高預(yù)測準確性。
XGBoost模型根據(jù)數(shù)據(jù)大小和種類以及影響采收率參數(shù)來參數(shù)尋優(yōu),模型參數(shù)最終設(shè)置為:決策樹的深度max_depth=5,學(xué)習率learning_rate=0.01,最大迭代次數(shù)n_estimators=200,隨機采樣的比例subsample=0.7,每棵隨機采樣的列數(shù)的占比colsample_bytree=0.8,靜默模式silent=True,線程數(shù)nthread=0.2。SVR模型確定固定值向量機結(jié)構(gòu)參數(shù)中,懲罰因子C=24.83,單個樣本的影響波及范圍g=5.77來開始支持向量機模型的訓(xùn)練與預(yù)測。
3.3 XGBoost-SVR組合模型構(gòu)建與調(diào)試
在進行模型構(gòu)建過程中,要避免影響因素與采收率之間發(fā)生過擬合現(xiàn)象,即模型在訓(xùn)練樣本中表現(xiàn)優(yōu)越,但是在驗證數(shù)據(jù)集以及測試數(shù)據(jù)集中表現(xiàn)不佳,可采用特征樣本隨機訓(xùn)練,減少樹深度和正則化參數(shù)后等有效方法來降低過擬合。
兩個單模型的超參數(shù)調(diào)整對于模型的表現(xiàn)有很大的影響,在不斷地調(diào)試之后,結(jié)合誤差值分析確定參數(shù)范圍內(nèi)最優(yōu)的參數(shù)組合,在確定結(jié)構(gòu)參數(shù)后,對于單模型再次在訓(xùn)練中使用交叉驗證,一方面是可以對比不同模型的效果,另一方面是在4折交叉驗證中,每折訓(xùn)練結(jié)束后的模型,結(jié)合本折交叉驗證都對采收率進行一次預(yù)測。對XGBoost-SVR組合模型進行4折交叉驗證,得出4個采收率預(yù)測數(shù)值,最終組合模型的預(yù)測結(jié)果是4次預(yù)測結(jié)果的平均值,基于抽樣化的樣本可以提高精準度,最終結(jié)果實際上是4個組合模型結(jié)果的融合,抽樣和融合可以減少過擬合,可對預(yù)測精度有所提高。
3.4 預(yù)測結(jié)果分析
在驗證基于殘差自適應(yīng)組合模型精確度的同時,分別對XGBoost單模型和SVR單模型進行預(yù)測輸出進行對比試驗,各個模型預(yù)測結(jié)果如圖7、圖8、表3所示。由圖7、圖8可知,采收率值實際值處于平均水平時,各模型預(yù)測值和實際值的擬合度都較高,而對于實際值遠小于或遠大于平均水平的擬合效果均較差(W87井、W31井)。相比于單機器學(xué)習模型,組合模型與實際值的擬合效果最好,起伏程度更加接近采收率變化的范圍趨勢,偏差較小。
利用保存好的組合模型對輸入變量重要性分析評價,變量重要性結(jié)果如圖9所示。采收率預(yù)測變量重要性結(jié)果為儲層變量因素大于工程變量重要性,重要性順序為簇數(shù)、有效厚度、滲透率、含油飽和度等。儲層變量因素中有效厚度和滲透率的重要性相對較高,反映了儲油層和致密油滲流通道的影響度,表明在采收率的影響因素中,裂縫發(fā)育程度、儲層自身性質(zhì)以及滲流通道都占了較大比重。

圖7 XGBoost預(yù)測結(jié)果Fig.7 XGBoost prediction result

圖8 SVR預(yù)測結(jié)果Fig.8 SVR prediction result

表3 各模型預(yù)測結(jié)果對比Table 3 Comparison of prediction results of various models
4 模型評估
對組合模型可從精準度和離散程度兩方面評估模型性能,均方誤差(mean square error,MSE)和均方根誤差(root mean squared error,RMSE)反映了采收率模型預(yù)測值和真實采收率之間的偏離程度,R2可評估該模型預(yù)測數(shù)據(jù)的離散程度,如圖10所示,從基本理論方面揭示了評估模型的精準度和離散程度差異性。
MSE和RMSE計算公式為
(9)

對上述3種模型預(yù)測方法進行模型評估,回歸模型評估如表4所示。
如圖11所示,相比于單模型,基于殘差確定的組合模型可充分利用不同的定性預(yù)測模型或定量預(yù)測模型的優(yōu)勢,可以基于誤差分析,不斷提升組合模型的預(yù)測精度,模型類型相差比較大的兩模型間優(yōu)勢互補,不同的預(yù)測方法從不同的角度挖掘到的信息也不一致,因此組合模型進一步提高了模型的泛化能力。

圖9 特征影響因素重要性排序Fig.9 Ranking of the importance of feature influencing factors

圖10 理論模型精確度和離散程度評估圖Fig.10 Evaluation of the accuracy and dispersion degree of the theoretical model

表4 模型評估值結(jié)果Table 4 Model evaluation results

圖11 融合模型預(yù)測值殘差圖Fig.11 The residual plot of the predicted value of the fusion model
5 結(jié)論
引進機器學(xué)習之中的模型融合技術(shù)來預(yù)測致密油的采收率,可以有效地提高回歸預(yù)測的準確性,相比于單模型,融合模型在穩(wěn)定性和精確度方面體現(xiàn)出了一定的優(yōu)勢。得出如下結(jié)論。
(1)經(jīng)過對致密油的采收率影響特征重要性分析,儲層因素的相對重要性高于施工參數(shù)的重要性,其中簇數(shù)、有效厚度和滲透率因素相對重要性高,而加砂量和加液量相對重要性較低,證明了儲層物性、裂縫(天然裂縫、人工裂縫)的發(fā)育程度對采收率的影響非常重要。
(2)XGBoost-SVR組合模型可充分利用XGBoost單模型可解釋性強和SVR單模型高維度映射的優(yōu)勢,同時也增加了一定容錯率,對于致密油藏的采收率預(yù)測精度達到94.63%,可為致密油藏的開發(fā)措施調(diào)整提供良好的指導(dǎo)作用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
