基于眾源影像的三維重建方法
2022-05-19 13:04:34王志明劉丹
科學技術與工程 2022年12期
王志明, 劉丹
(東華理工大學測繪工程學院, 南昌 330013)
隨著中國城市化建設的日新月異,城鎮化進程日益加速,國家建設、城市管理、交通、旅游等眾多領域都在積極響應的數字化、智能化的號召[1-2],而其中,作為三維空間數據的三維模型占據著重要地位。眾源影像具有來源范圍廣,信息量大,數據形式豐富,數據獲取門檻低等特點[3],已成為三維重建的一種重要數據源。研究基于眾源影像的三維重建在攝影測量與遙感等領域,具有重要的理論和實際意義。
20世紀90年代至今,基于影像數據進行三維重建的方法數見不鮮。Schindler等[4]利用線特征來進行匹配以及重建,但是線特征比較稀疏,導致幾何結構不夠穩定的問題。Xiao等[5]和Sudipta等[6]從配準后的多張影像中利用滅點計算提取出主方向,這些方法能得到較好的建筑物模型,但是需要大量的人工交互,難以應用于大規模的建筑物建模工作。Irschara等[7]提出了一種增量式的大規模街景建模方法。王偉等[8]提出了一種快速交互式三維場景算法,能夠快速重建出多種復雜曲面的場景結構,如各種球面、柱面等結構。Hao等[9]提出了一種從三維點云重建城市建筑幾何的綜合策略,根據窗戶的排列規律,通過分析窗戶的相似性和重復性設計一種模板匹配的方法來恢復建筑立面的結構。Alidoost等[10]提出了一種基于深度學習的方法,用于從航拍圖像中獲取建筑物特征點,從而進行重建工作。陳占軍等[11]運用圖像特征提取與匹配、相機位置姿態計算與估計、三維點云生成、紋理映射等一整套的方法,完成了古建筑的三維場景重建。Li等[12]開發了一種將多種關系嵌入到程序建模過程中的方法,用于從攝影測量點云生成3D重建建筑物。Sebastian等[13]提出了一種通過求解整數線性優化問題,從具有定向法線的非結構、未過濾的室內點云重建參數化、體積化、多層建筑模型的新方法。孫保燕等[14]兼顧了獲取數據的范圍與效率,結合了地面拍攝與無人機傾斜攝影測量這兩種數據采集方式,提出了一種能夠自主融合地攝數據影像與航拍數據影像的三維數字化場景重建方法。袁一等[15]以互聯網眾源影像數據為數據源,進行三維場景重建,以達到地理定位的目的。王瑞玲等[16]提出了一種基于眾源數據的數字化重構思路,針對廣武明長城月亮門上已倒塌的場景進行場景重建。這些方法都著重于模型構建的部分,但是眾源影像來源廣泛,圖像質量參差不齊,容易導致生成的模型精度低、噪聲大。
基于此,首先采用眾源影像需求端與網站服務器交互的方式實現圖像獲取,然后借助深度學習,實現對搜集到的眾源影像進行過濾,最后通過SFM構建三維模型并對比生成的點云模型精度,以改進眾源影像數據在構建三維模型時的弊端。
1 研究方法
如圖1所示,三維重建流程主要包括:①檢索眾源影像數據:通過基于網頁解析和基于網站API的方法,檢索并獲取到目標地點、目標建筑物的圖片數據集;②篩選圖像:通過構建的深度網絡模型,對搜集到的圖片數據集進行篩選,提取數據集中包含或者包含大部分目標地物的影像;③構建三維模型:采用運動恢復結構方法(structure from motion,SFM)[17],以篩選結果數據集為數據源進行場景重建,得到三維點云模型。
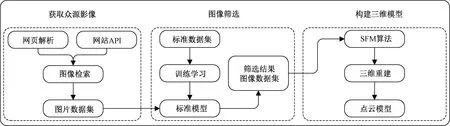
API:application programming interface圖1 三維重建流程圖Fig. 1 The flow chart of 3D reconstruction
1.1 眾源影像的檢索
隨著網絡發展的日新月異,互聯網服務端口的開放性也隨之逐步提高。目前,獲取眾源影像的常見渠道有圖片分享網站、社交網站和專業攝影網站[18-19]。圖片分享網站使用者基數大,影像數量豐富。為獲得豐富的眾源數據,根據數據源不同,分別采用不同的方法進行檢索獲取數據。以坐標點為數據源時,采用基于網站API的數據檢索方案;而以一幅影像為數據源時,采用基于網頁解析的方案。
1.1.1 基于網站API的眾源影像檢索
在基于網站API的數據檢索方法中,選擇能提供API服務的網站作為程序抓取的目標服務器,其中包括百度街景地圖平臺、騰訊街景地圖平臺等。上述平臺都以文本描述的形式開放了API請求的端口,部分第三方源網站還提供了地理信息查找服務,比如指定坐標直接鏈接目標地區影像的接口以及利用地理范圍查詢興趣點(point of interest,POI)數據集的接口[20]。
百度街景數據采集車在采集街景數據時,所設定的采集間距為10 m。因此,論文在采樣街景數據時,與采集車的預設參數保持一致,設定為10 m。
人在觀察周圍事物時的視角約為15°仰角,因此爬取時與其保持一致,設置預設仰角為15°。全景街景影像的尺度范圍為360°,在分割時,以45°為一個間隔。以這種方案,在每個采樣點上,能夠獲取8張的影像數據。
百度地圖API針對用戶,開放了街景爬取的端口。用戶在獲取街景影像數據時,需要訪問網絡傳輸協議下的一個(uniform resource locator,URL)地址,具體參數屬性如表1所示。

表1 百度地圖API爬取街景圖片數據的參數屬性Table 1 Parameters for Baidu map to crawl street view images
1.1.2 基于網頁解析的眾源影像檢索
在基于網頁解析的數據獲取時,針對性到了研究了需要網頁解析才能獲取影像的網站,包括百度地圖相冊、百度圖庫、百度貼吧等[21]。首先,在客戶端交互界面提供一定類型的信息關鍵詞,在網站端口中構建模擬搜索結果的URL,并通過唯一標記方法解析出輸出界面中包含的每個圖像的詳細鏈接;然后轉入此鏈接,深入分析此鏈接對應源代碼所包含的原始影像URL[22]。按照這樣的思路,在模擬搜索條件下,遍歷輸出接口中包含的所有特定鏈接以獲得所有圖像。該方法獲得的圖像數據通常具有更好的相關性和清晰度。
1.2 圖像的篩選
深度學習(deep learning)[23]與傳統的淺層學習有很大的不同,其突出點不僅在于神經元計算節點的設計建立,還在于多層運算的層次結構。深度學習算法采用針對性的輸入層與輸出層,不斷地進行迭代和優化,生成輸入層與輸出層的網絡聯系,得到兩者之間的函數框架,以此來進行高難度任務的處理。卷積神經網絡(convolutional neural networks,CNN)[24]是深度學習中的一種常用模型,其特點在于針對每個卷積層采用池化的處理,這種處理方式能夠深層次得挖掘數據的多尺度特征。因此,卷積神經網絡在文本識別、模式定性、圖像分類篩選等領域,已經成為常用的模型之一。
基于卷積神經網絡和遷移學習的方法[25],采用如圖2的VGG-16[26]深度卷積網絡模型完成眾源影像的篩選。首先通過標準影像數據生成標準數據集,并利用標準數據集采用VGG-16模型進行訓練學習,訓練成功后得到標準數據集的訓練模型,再依據訓練模型來剖析眾源影像的相關度,將相關度大的影像優先篩選出來。
VGG-16網絡將待篩選圖像集導入網絡,經過卷積層、池化層、全連接層的多層處理、識別和篩選,得到篩選影像集。模型設置輸入圖像的分辨率為224*224,卷積層的屬性參數為64個3*3的卷積核;而池化層是針對卷積后的數據進行池化的,尺寸參數設置為2*2;全連接層共有三層,第3個全連接層參數設置為區分兩類影像,分別識別重建對象影像和非重建對象影像。
1.3 三維模型的構建
SFM算法對于相機在獲取影像數據時的位置信息并不存在嚴格要求,僅要求獲取的目標物為具有三維的非動態物體即可,在拍攝過程中籠蓋目標建筑物,在包含目標建筑物的二維影像中獲取特征信息來進行三維場景重建的過程,這種方法也是恢復三維結構時的常用方法之一。
基于SFM方法首先利用篩選得到的眾源影像數據,首先通過特征點匹配恢復相機的外方位元素,然后利用攝像機的外方位元素求解特征點的空間三維坐標,從而從獲取的圖像數據中生成大量的點云,由此得到目標建筑物的三維重建模型。
2 實驗結果與分析
2.1 實驗數據獲取
選取東華理工大學南昌校區的圖書館作為重建對象,如圖3所示。
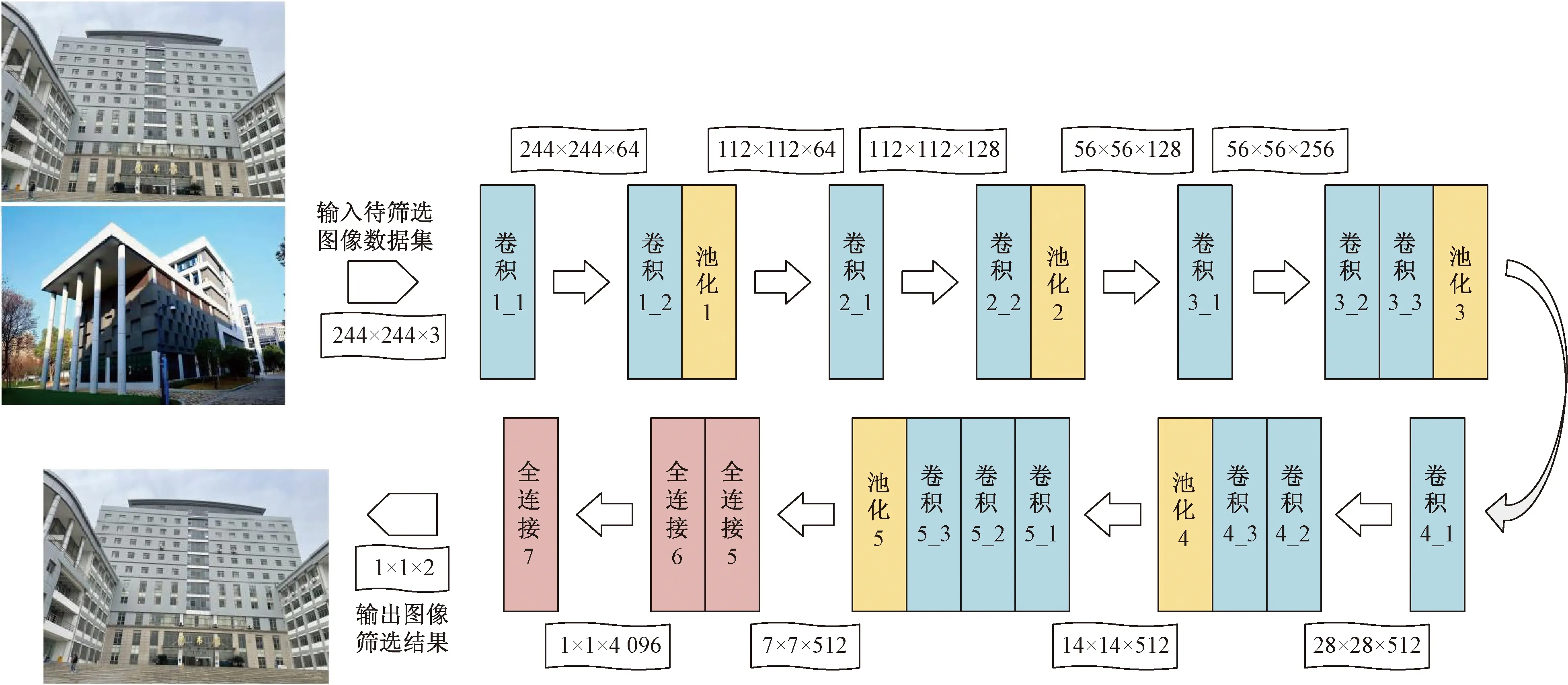
圖2 VGG-16卷積網絡模型Fig.2 VGG-16 convolutional network
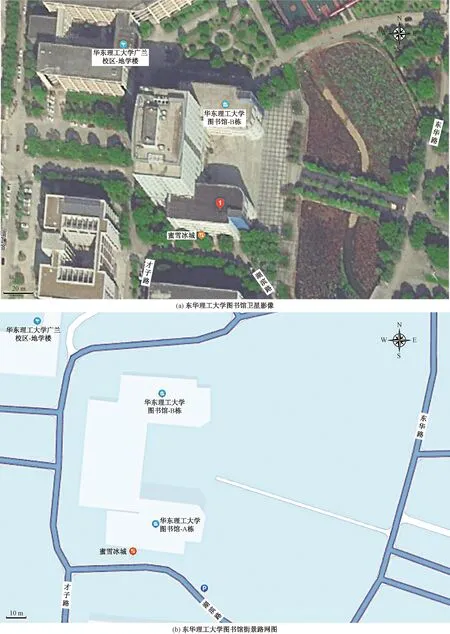
圖片來源:百度地圖(https://map.baidu.com/search/%E4%B8%9C%E5%8D%8E%E7%90%86%E5%B7%A5%E5%A4%A7%E5%AD%A6%E5%9B%BE%E4%B9%A6%E9%A6%86-a%E6%A0%8B/@12894491.925,3319992.34,20.29z?querytype=s&da_src=shareurl&wd=%B6%AB%BB%AA%C0%ED%B9%A4%B4%F3%D1%A7%CD%BC%CA%E9%B9%DD-A%B6%B0&c=163&src=0&wd2=%C4%CF%B2%FD%CA%D0%C7%E0%C9%BD%BA%FE%C7%F8&pn=0&sug=1&l=12&b=(12867400.55,3285239.29;12928840.55,3345271.29)&from=webmap&biz_forward=%7B);1表示東華理工大學圖書館-A棟圖3 研究區域Fig.3 Study area
首先利用基于網站API和基于網頁解析的數據檢索方案,獲取了近300張目標區域的影像(圖4),作為三維重建的數據源。但是這些影像中,有部分影像與重建對象圖書館的相關性較小,因此需要進一步對其進行篩選,獲取得到高質量的眾源影像數據。
此外,為了評價點云模型質量的好壞,論文采用高質量的標準模型進行對比參照。標準模型是在目標地區實地拍攝建筑物圖片,并生成標準圖片集(圖5,圖片數量為39張)。由于是有針對性的定點選角度拍攝,獲取到的圖片集不僅數量少,且精度高質量好。

圖4 未經篩選的東華理工大學圖書館眾源影像縮略圖Fig.4 Unselected crowd-sourced images thumbnails in the library of East China University of Technology

圖5 標準圖片集縮略圖Fig.5 Standard photo gallery thumbnail
2.2 眾源影像篩選結果
采用卷積神經網絡VGG-16網絡模型對上述獲取得到的眾源影像進行篩選。為驗證該模型的有效性,利用K均值聚類算法進行比較。運用VGG-16網絡篩選后的東華理工大學圖書館影像數據集如圖6所示,經篩選得到了187張影像數據。從篩選得到的數據集來看,與K均值聚類算法相比,利用VGG-16網絡篩選結果更為準確,數據集達到了重建的要求。
2.3 基于眾源影像的三維重建結果與分析
在實驗的整體流程中,僅控制篩選時所采用的兩種算法這一變量,篩選時所輸入的待篩選數據集、三維重建時所采用的重建算法保持一致。對上述獲取得到的標準圖像集,由VGG-16網絡篩選后的影像數據集以及采用K均值聚類算法篩選后得到的影像數據分別進行三維場景的構建,由此生成的三維模型如圖7所示。圖7中,標準模型是由上述獲取得到的標準圖像集通過SFM算法生成的三維模型,點云模型A是由VGG-16網絡篩選后的數據集生成的三維模型, 點云模型B則是采用K均值聚類算法篩選得到的圖像集生成的三維模型。
為驗證方法的有效性,論文對標準模型與重建后的模型的點云數量以及點云之間的距離進行比較。點云數量越接近,點云距離越小,則說明篩選算法越好,重建模型精度越高。分析不同圖像篩選算法下篩選后的三維重建的時間和生成建筑物三維點云的數量統計結果(表2)發現,圖像篩選算法的不同使得篩選后的圖片數量不同,從而影響三維重建的時間和重建點云數量。

圖6 經VGG-16網絡篩選后的圖書館影像數據集縮略圖Fig.6 Thumbnail of Library image data set screened by VGG-16 network

圖7 不同篩選算法篩選數據集生成的重建模型Fig.7 Different filtering algorithms filter the reconstruction model generated by the data set

表2 場景重建時間和模型點云數量比較Table 2 Comparison of scene reconstruction time and number of model point clouds
如表2所示,對比重建時間和點云數量,經VGG-16網絡篩選過的數據集圖片數量較多,模型重建的質量高于K均值聚類算法組(圖7)。能夠發現,針對同一個待篩選數據集,VGG-16網絡算法和K均值聚類算法的篩選結果不同,由于VGG-16網絡算法能夠過濾出更多相關影像,所以使得建模質量更高。
計算標準模型和點云模型A之間的點云距離,將結果生成距離直方圖和距離高斯分布圖,用同樣的方法處理點云模型B,以此得到模型重建質量評價數據和圖表依據,如圖8所示。可以看出,無論是高精度點云數量方面、點云的密集程度方面,還是整體點云數量方面,模型A都是超過模型B的,說明模型A的重建效果好于模型B。
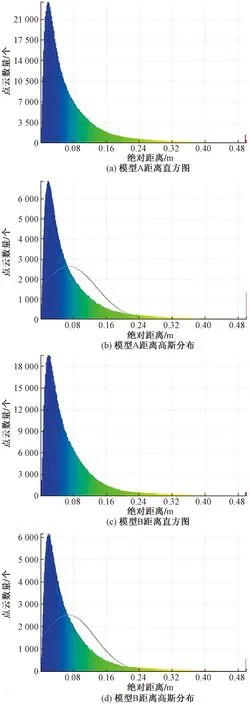
圖8 距離直方圖和距離高斯分布Fig.8 Range histogram and range Gaussian distribution
計算點云模型A與點云模型B之間的點云距離,生成了點云距離熱力圖(圖9)。可以看出,大樓中部主體部分幾乎沒有出現熱力點云,但是大樓兩側的副樓生成了大量熱力點云的情況,則說明大樓中部圖片數據集獲取程度相近,而兩側部分數據集差異較大,導致了重建效果的不同。

圖9 點云距離熱力圖Fig.9 Point cloud distance heat map
將點云模型A和點云模型B的點云距離進行對比,能夠發現,較模型A而言,模型B的重建效果確實不佳,也從側面反映了由K均值聚類算法篩選得到的圖片數據集質量不如運用VGG-16網絡篩選的圖片集質量。
3 結論
通過基于網站API和基于網頁解析的數據檢索這兩種方案,能夠得到數量眾多的目標影像數據,實現了眾源影像的獲取,針對眾源數據的獲取需求也得到了滿足。通過對比構建的模型精度,研究深度學習算法與K均值聚類算法篩選后的數據集生成的點云模型結果,發現K均值聚類算法的缺點明顯,體現了深度學習算法對影像數據進行針對性識別的效果更佳,在篩選檢索結果的工作中,能夠剔除與數據集內相似度不高的影像數據,使得處理后的影像數據保持高度的相關度,使得后期建立的模型精度更高。由此可見,深度學習算法更適用于三維重建。
目前,對于基于眾源影像的三維重建來說,已有的圖像篩選算法都不具有針對性和專一性,不能很好地過濾大量冗余的影像和低質量的影像,不能夠很好地服務于場景的重建。在未來的工作中,筆者將改進已有的圖像篩選算法,來提升篩選算法的篩選效率和效果,旨在服務于以眾源影像為數據源進行場景的重建工作。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
