基于ResNet和遷移學(xué)習(xí)的古印章文本識別
2022-05-19 13:28:02陳婭婭劉全香王凱麗易堯華
計(jì)算機(jī)工程與應(yīng)用 2022年10期
陳婭婭,劉全香,王凱麗,易堯華
武漢大學(xué) 印刷與包裝系,武漢 430079
文本識別領(lǐng)域中,現(xiàn)代文本識別技術(shù)已經(jīng)趨于成熟,在諸多方面取得了商業(yè)化應(yīng)用,如掃描文檔的智能識別[1]、手寫文本的數(shù)字化轉(zhuǎn)換[2]與場景文本的自動翻譯[3]等。古文本識別研究中,數(shù)量較為豐富的書法[4]、印刷古籍等的識別研究[5]相對較多,由于識別困難和數(shù)據(jù)有限,較少有人涉及古印章文本的識別。
作為中華文化的重要組成部分,印章在古籍書畫中廣泛存在,承載著大量史實(shí)和人文信息。古印章文本的自動識別可以實(shí)現(xiàn)古籍中印章的輔助閱讀和數(shù)字化轉(zhuǎn)換,對歷史文化的傳承具有重要意義。古印章文本的主要識別難點(diǎn)如下:(1)結(jié)構(gòu)復(fù)雜,字符集大且類間相似度高。(2)類內(nèi)差異大。如圖1(a)所示,同類字符在結(jié)構(gòu)上相差很大。(3)圖像退化和邊框影響。如圖1(b)所示,模糊、粘連、隨機(jī)噪聲和不規(guī)則邊框等會影響準(zhǔn)確的特征提取。此外,部分訓(xùn)練樣本不足且類間分布不均衡,會降低深度學(xué)習(xí)算法的性能。

圖1 古印章圖像樣本Fig.1 Historical Chinese seal samples
古印章文本識別相關(guān)研究中,Sun等人[6]提出一種基于圖模型匹配的印章文本識別方法,通過提取印章的骨架特征并計(jì)算最相似矩陣,在59個類別上實(shí)現(xiàn)分類。該方法使用手工設(shè)計(jì)圖像特征的傳統(tǒng)機(jī)器學(xué)習(xí)實(shí)現(xiàn),分類數(shù)量較少且識別準(zhǔn)確率不高,限制了古印章文本識別的推廣應(yīng)用。在古印章前處理方面,Dai等人[7]通過提取印章圖像的邊界寬度特征和結(jié)構(gòu)特征去除邊框干擾并建立決策樹分類模型,將古印章分為陰刻和陽刻兩類,但沒有進(jìn)行單字符分割的工作。Wang等人[8]將深度學(xué)習(xí)應(yīng)用到古印章的圖像識別中,建立了古印章圖像數(shù)據(jù)庫,并提出基于多任務(wù)學(xué)習(xí)和自動背景生成的印章圖識別方法。該方法將整張圖而不是印章中的字符作為識別對象,未考慮古印章中所蘊(yùn)含的具有意義的文本信息。
近年來,很多優(yōu)秀的卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)在多分類任務(wù)中取得了良好效果[9],AlexNet[10]、VGGNet[11]、Inception[12]、ResNet[13]等網(wǎng)絡(luò)被廣泛應(yīng)用于基于分割的文本識別任務(wù)中。例如,Zhong等人[14]利用多融合池化(multi-pooling)的CNN網(wǎng)絡(luò)識別多字體的印刷漢字,并結(jié)合數(shù)據(jù)增強(qiáng)技術(shù)提升了CNN的性能。Wang等人[15]結(jié)合Inception_v4等多種CNN網(wǎng)絡(luò),提出基于多模型融合的方法并應(yīng)用于多場景古漢字的識別任務(wù)中。深度學(xué)習(xí)方法需要大量有效樣本,遷移學(xué)習(xí)的引入可以提高學(xué)習(xí)的性能,緩解數(shù)據(jù)不足問題[16]。例如,姚可欣等人[17]在手寫簡筆畫識別中,利用遷移學(xué)習(xí)解決樣本數(shù)據(jù)量小的問題,有效提高了識別精度。
本文針對古印章文本標(biāo)注數(shù)據(jù)不足等問題,提出使用深度殘差網(wǎng)絡(luò)并引入遷移學(xué)習(xí)實(shí)現(xiàn)古印章文本的識別。主要工作如下:
(1)自建古印章文本識別數(shù)據(jù)集,通過基于投影和統(tǒng)計(jì)的前處理方法分割出字符區(qū)域,選用ResNet作為基礎(chǔ)識別網(wǎng)絡(luò),并對比不同網(wǎng)絡(luò)下的識別結(jié)果,驗(yàn)證了本文所用網(wǎng)絡(luò)的優(yōu)越性。
(2)通過預(yù)訓(xùn)練人工合成樣本,引入遷移學(xué)習(xí)進(jìn)行目標(biāo)域的訓(xùn)練,從而建立文本識別分類模型,同時利用數(shù)據(jù)增強(qiáng)和標(biāo)簽平滑進(jìn)一步優(yōu)化模型。實(shí)驗(yàn)結(jié)果表明,引入遷移學(xué)習(xí)可以有效提升古印章文本的識別準(zhǔn)確率。
1 數(shù)據(jù)集簡介和前處理
1.1 數(shù)據(jù)集簡介
古印章文本識別數(shù)據(jù)集(historical Chinese seal text recognition,HCSTR)通過網(wǎng)絡(luò)爬蟲獲取,共包括印章拓本圖像27 520幅,覆蓋了從夏商至近現(xiàn)代的各個歷史時期。印文以姓名、字號、鑒藏、齋館名等為主,包含2 602個字符類別,其中收錄于GB2312字符集的字符占約95%。數(shù)據(jù)集中的字體主要有大篆、小篆、方篆、九疊篆、鳥蟲篆5類,還包括隸書、楷書、行草書等書體以及部分裝飾性文字,如圖2所示,不同字體間結(jié)構(gòu)相差較大。

圖2 HCSTR數(shù)據(jù)集中的字體分類Fig.2 Font classification of HCSTR dataset
1.2 數(shù)據(jù)集前處理
為了準(zhǔn)確提取古印章的字符特征,本文通過數(shù)據(jù)集前處理分割出單字符樣本。如圖3所示,前處理包括去邊框和字符分割兩部分。先根據(jù)圖像像素投影特點(diǎn)將圖像分成陰刻和陽刻,利用邊緣結(jié)構(gòu)特征去除邊框區(qū)域,然后通過垂直投影輪廓確定兩個相鄰字符之間的分割點(diǎn)實(shí)現(xiàn)單字符分割。

圖3 印章圖像前處理階段Fig.3 Preprocessing phase of seal images
1.2.1 去邊框
采用最大類間方差法[18]和開運(yùn)算進(jìn)行二值化及去噪處理,處理后的圖像記為Xo。參考文獻(xiàn)[7]中的方法,遍歷Xo每行每列并計(jì)算所在列或行第一個和最后一個黑色像素線段長度s i,則s i的平均概率密度為:
式中,r為s i的數(shù)量,Hist(·)表示直方圖操作,S為s i的集合。判斷為陰刻印章的條件為:
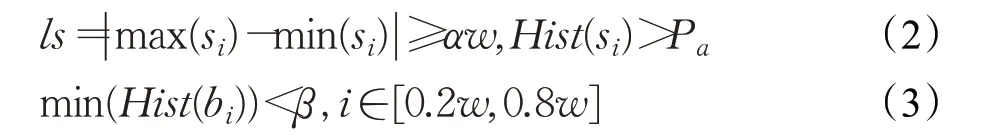
其中,ls表示邊框跨度,b i為Xo每列的亮度值,w為圖像寬度。本文中α=0.25,β=0.2,為自定義參數(shù)。最佳邊框?qū)挾榷x為當(dāng)邊框概率分布在50%以上的最大寬度,作為最終需去除的邊框?qū)挾龋?/p>

1.2.2 字符分割
對于陽刻印章,設(shè)去邊框后每個像素位置(x,y)對應(yīng)的像素值為f(x,y),當(dāng)圖像為白色像素時,f(x,y)=0,否則f(x,y)=1。設(shè)H、W分別為去邊框后的高度和寬度,其垂直投影函數(shù)可以表示為:

垂直和水平像素投影如圖5所示,其中垂直投影各部分由式(6)~(8)給出:

其中,A為平均投影密度,wi為第i列位置字符的寬度值,投影圖與μA交叉點(diǎn)處的平均值定義為Wiavg,μ取0.2。行分割采取同樣的投影方式,鑒于字符位置的不確定性,對此進(jìn)行人工干預(yù),設(shè)每列字符數(shù)為j,公式如下:

2 基于ResNet和遷移學(xué)習(xí)的文本識別
本文提出基于ResNet和遷移學(xué)習(xí)的古印章文本識別方法,識別流程如圖4所示。

圖4 古印章文本識別流程Fig.4 Text recognition process of seal images
2.1 基于ResNet的特征提取網(wǎng)絡(luò)
傳統(tǒng)CNN網(wǎng)絡(luò)在層數(shù)加深時,面臨網(wǎng)絡(luò)退化的問題,本文選用ResNet作為預(yù)訓(xùn)練和微調(diào)模型的特征提取網(wǎng)絡(luò),該網(wǎng)絡(luò)增加層數(shù)的方式是在淺層網(wǎng)絡(luò)上疊加恒等映射層,從而構(gòu)建出殘差學(xué)習(xí)單元。殘差單元結(jié)構(gòu)如圖5所示,通過學(xué)習(xí)殘差,將部分原始輸入的信息經(jīng)過恒等映射層直接輸?shù)较乱粚樱谝欢ǔ潭壬媳苊饬司矸e層在進(jìn)行信息傳遞時的特征丟失,可以在輸入特征的基礎(chǔ)上學(xué)習(xí)到新的特征,擁有更好的性能。
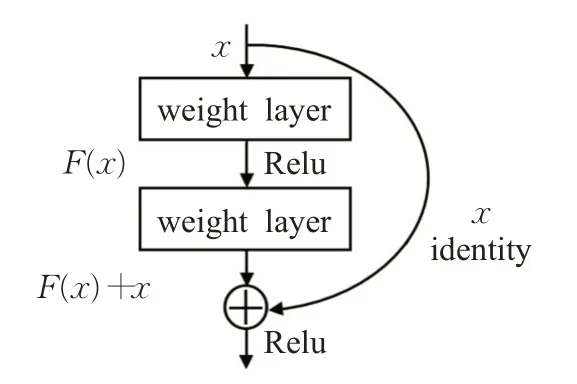
圖5 殘差單元結(jié)構(gòu)Fig.5 Residual unit structure
設(shè)輸入為x時所學(xué)特征為H(x),F(x)=H(x)-x為網(wǎng)絡(luò)學(xué)習(xí)殘差,則殘差單元可以表示為:

其中,x l、y l表示第l層的輸入和輸出,W l為權(quán)重矩陣,f(·)表示Relu激活函數(shù)。對于L層殘差單元,從淺層到深層的學(xué)習(xí)特征為:


表1 ResNet_152結(jié)構(gòu)設(shè)置Table 1 Architecture of ResNet_152
2.2 引入遷移學(xué)習(xí)的模型訓(xùn)練
為了充分利用有效的數(shù)據(jù)資源,緩解古印章部分字符對應(yīng)樣本不足問題,本文在訓(xùn)練過程中引入遷移學(xué)習(xí)。
使用人工合成樣本作為源域D s,數(shù)據(jù)增強(qiáng)后的訓(xùn)練集為目標(biāo)域Dt,源域和目標(biāo)域樣本遵循相同的標(biāo)簽分布。來自D s的數(shù)據(jù)經(jīng)過預(yù)訓(xùn)練模型并保存參數(shù),記權(quán)重參數(shù)矩陣為W s,使用W s對目標(biāo)網(wǎng)絡(luò)的參數(shù)進(jìn)行初始化,用目標(biāo)域數(shù)據(jù)重新訓(xùn)練整個網(wǎng)絡(luò),通過微調(diào)得到新的模型,預(yù)訓(xùn)練和微調(diào)模型可以表示為:

其中,n表示訓(xùn)練次數(shù),Train(·)表示模型訓(xùn)練過程。訓(xùn)練過程中將損失值進(jìn)行反向傳播從而進(jìn)行參數(shù)更新,權(quán)重參數(shù)可以很快適應(yīng)目標(biāo)域的數(shù)據(jù),從而加快微調(diào)模型性能提高的速度。
2.3 分類預(yù)測與損失函數(shù)

式中,c為預(yù)測標(biāo)簽,N為批處理大小。由于標(biāo)注錯誤的樣本會抑制識別準(zhǔn)確率的提升,本文引入標(biāo)簽平滑策略來避免標(biāo)簽錯誤產(chǎn)生的影響。設(shè)r(x i)為樣本xi的邏輯表達(dá)式,當(dāng)預(yù)測標(biāo)簽正確時r(xi)=1,標(biāo)簽錯誤時r(x i)=0。采用標(biāo)簽平滑后的損失函數(shù)表示如下:

式中,標(biāo)簽平滑參數(shù)ε=0.1,該損失函數(shù)通過為標(biāo)簽加入噪聲,減少真實(shí)樣本在損失計(jì)算時的權(quán)重來提升整體性能。
2.4 算法時間復(fù)雜度分析
通常以浮點(diǎn)運(yùn)算次數(shù)(floating point operations,F(xiàn)LOPs)來表示算法的時間復(fù)雜度。預(yù)訓(xùn)練模型的時間成本體現(xiàn)在特征提取和分類上,主要為通過卷積層和全連接層的時間,其他附加層可以忽略不計(jì)。通過單個卷積層的通過全連接層的FLOPs=O(2I-1)[20]。其中Ml為特征圖的邊長,Kl為卷積核窗口邊長,Cin和Cout分別表示該層輸入通道數(shù)和輸出通道個數(shù),I代表全連接層輸入維度,O代表輸出維度。以O(shè)(·)代表時間復(fù)雜度函數(shù),則單層卷積的時間復(fù)雜度為全連接層的時間復(fù)雜度為O(IO)。總時間復(fù)雜度可以表示為
引入遷移學(xué)習(xí)后的微調(diào)模型在不改變網(wǎng)絡(luò)結(jié)構(gòu)和初始參數(shù)的基礎(chǔ)上,對整個網(wǎng)絡(luò)進(jìn)行了微調(diào)。因此,微調(diào)模型的時間復(fù)雜度與預(yù)訓(xùn)練模型復(fù)雜度相比,減少了參數(shù)初始化的時間消耗,整體的時間復(fù)雜度數(shù)量級與預(yù)訓(xùn)練模型相當(dāng)。
對于教師而言,要和學(xué)生打成一片、親密無間,要了解他們的喜怒哀樂,觀察學(xué)生的能力差異,弄清每個學(xué)生的個性特長,這是優(yōu)秀教師的重要標(biāo)志。
3 實(shí)驗(yàn)
3.1 數(shù)據(jù)集
本文實(shí)驗(yàn)中使用到的數(shù)據(jù)集分布如表2所示,其中“HCSTR+DA”表示HCSTR中的訓(xùn)練集和數(shù)據(jù)增強(qiáng)之后的總樣本數(shù)據(jù),即目標(biāo)域數(shù)據(jù)。目標(biāo)域數(shù)據(jù)通過對訓(xùn)練集添加椒鹽噪聲、高斯模糊和隨機(jī)裁剪進(jìn)行數(shù)據(jù)增強(qiáng)得到。

表2 本文使用的數(shù)據(jù)集Table 2 Datasets used in this paper
本文提出了基于人工設(shè)計(jì)規(guī)則的單字符數(shù)據(jù)集(SYNTH_26)作為預(yù)訓(xùn)練樣本,具體合成方法如下:
(1)選擇與印章文本相近的字體文件獲取古漢字圖像,本文共篩選出26種字體文件合成所需字符,像素大小設(shè)為80×80。
(2)隨機(jī)添加顏色反轉(zhuǎn)模擬陰刻和陽刻。對樣本進(jìn)行邊緣隨機(jī)裁剪模擬字符位置的變化,裁剪大小控制在10像素以內(nèi)。
(3)通過控制參數(shù)添加椒鹽噪聲,隨機(jī)執(zhí)行膨脹或腐蝕變換,模擬不同程度的結(jié)構(gòu)殘缺和筆畫粗細(xì)。
3.2 評價(jià)指標(biāo)
本文采用字識別準(zhǔn)確率作為模型測試的評價(jià)標(biāo)準(zhǔn),字識別準(zhǔn)確率反映了所有識別正確的樣本數(shù)占總測試樣本數(shù)的百分比,具體公式如下:
其中,M為所有測試集樣本數(shù)量,Y i代表測試樣本n i∈{n1,n2,…,n k}的預(yù)測標(biāo)簽集合,G i代表ni的真值標(biāo)簽集合。

3.3 實(shí)驗(yàn)環(huán)境及參數(shù)設(shè)置
本文實(shí)驗(yàn)的運(yùn)行環(huán)境均為Ubuntu 16.04,運(yùn)行內(nèi)存為8 GB,GPU設(shè)備為GTX1080ti,并在TensorFlow框架[21]上進(jìn)行訓(xùn)練與測試。選擇RMSProp作為預(yù)訓(xùn)練和微調(diào)網(wǎng)絡(luò)的優(yōu)化函數(shù),動量(momentum)設(shè)為0.9,初始與終止學(xué)習(xí)率(learning rate)分別為10-2和10-4,衰減因子為0.94,指數(shù)衰減步數(shù)為4×105,網(wǎng)絡(luò)訓(xùn)練的迭代次數(shù)為10萬,批尺寸(batch size)大小均設(shè)置為64。
實(shí)驗(yàn)中SYNTH_26作為源域全部用于預(yù)訓(xùn)練,在ResNet_v2_152網(wǎng)絡(luò)上迭代10萬次得到預(yù)訓(xùn)練模型。使用HCSTR+DA作為目標(biāo)域參與微調(diào)訓(xùn)練。模型測試過程全部使用測試集樣本。
4 實(shí)驗(yàn)結(jié)果與分析
4.1 識別結(jié)果對比
為了評估不同網(wǎng)絡(luò)的識別性能,在相同訓(xùn)練和測試條件下,將本文網(wǎng)絡(luò)與其他較為流行的CNN網(wǎng)絡(luò)識別結(jié)果進(jìn)行對比,結(jié)果如表3所示。可以看出,相比其他網(wǎng)絡(luò),ResNet_v2_152網(wǎng)絡(luò)的Top-1、Top-3和Top-5的識別準(zhǔn)確率均取得了最優(yōu)的結(jié)果。AlexNet_v2由于提取不到深層特征,準(zhǔn)確率最低。Inception_v4和Inception_ResNet_v2網(wǎng)絡(luò)下的Top-1準(zhǔn)確率介于ResNet_v2_50和ResNet_v2_101網(wǎng)絡(luò)之間。
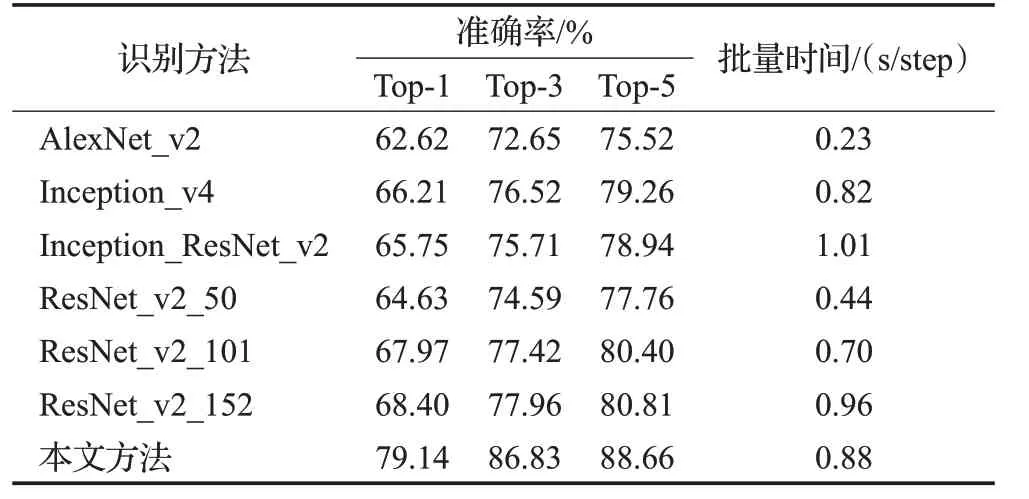
表3 識別結(jié)果對比Table 3 Comparison of recognition results
表3中批量時間指模型迭代一個批尺寸所用的時間。從批量時間對比可以看出,AlexNet_v2網(wǎng)絡(luò)的時間復(fù)雜度最低,Inception_ResNet_v2由于結(jié)合了兩種網(wǎng)絡(luò)結(jié)構(gòu),時間復(fù)雜度最高。ResNet_v2_152網(wǎng)絡(luò)直接進(jìn)行訓(xùn)練所需的時間成本相比較高,但可以取得優(yōu)于其他網(wǎng)絡(luò)的效果。本文方法的批量時間指引入遷移學(xué)習(xí)后的微調(diào)模型的批處理時長,預(yù)訓(xùn)練的時間成本不計(jì)入在內(nèi)。微調(diào)模型的批處理時長相比引入遷移學(xué)習(xí)前有所降低,并且在相同的迭代步數(shù)下,本文方法可以使損失值下降更快。因此,在已有預(yù)訓(xùn)練模型的情況下,引入遷移學(xué)習(xí)有利于提前終止訓(xùn)練,降低了時間成本,可以有效提升訓(xùn)練的效率。
4.2 遷移學(xué)習(xí)有效性分析
為了證明遷移學(xué)習(xí)的有效性,分析標(biāo)簽平滑、數(shù)據(jù)增強(qiáng)策略對結(jié)果的影響,本文在ResNet_v2_152網(wǎng)絡(luò)上進(jìn)行了消融實(shí)驗(yàn),結(jié)果如表4所示。三種策略均對準(zhǔn)確率提升有所幫助,只使用標(biāo)簽平滑時結(jié)果提升1.10個百分點(diǎn),只使用數(shù)據(jù)增強(qiáng)的結(jié)果提升了5.53個百分點(diǎn),人工合成樣本與真實(shí)樣本具有相似的結(jié)構(gòu)特征,引入遷移學(xué)習(xí)有效提升了識別準(zhǔn)確率,相比引入遷移學(xué)習(xí)前提升了9.94個百分點(diǎn)。兩兩融合的對比實(shí)驗(yàn)中,遷移學(xué)習(xí)和標(biāo)簽平滑結(jié)合的結(jié)果可以有效提升準(zhǔn)確率。本文方法,即三種策略融合的實(shí)驗(yàn)中,相比引入遷移學(xué)習(xí)前的Top-1準(zhǔn)確率提升了10.74個百分點(diǎn),相比只使用標(biāo)簽平滑和數(shù)據(jù)增強(qiáng)的結(jié)果提升了4.63個百分點(diǎn),其他Top-2到Top-5的結(jié)果提升了0.51個百分點(diǎn)~3.96個百分點(diǎn),充分證明了本文有效地學(xué)習(xí)到了可以進(jìn)行知識遷移的信息。

表4 消融實(shí)驗(yàn)結(jié)果Table 4 Ablation experiment results
4.3 識別置信度分析
本文還分別對引入遷移學(xué)習(xí)前后樣本的識別置信度分布做出分析,結(jié)果分別如圖6(a)和圖6(b)所示。圖中的散點(diǎn)代表樣本,曲線表示具有不同置信度的樣本量。可以看出,Top-1樣本的置信度相對較高,相比引入遷移學(xué)習(xí)前的結(jié)果,基于ResNet和遷移學(xué)習(xí)的方法的置信度有所提高,其中Top-1的置信度更接近于1.0,說明本文在一定程度上提升了模型的魯棒性,也反映出置信度高的樣本一般具有較高的識別準(zhǔn)確率。
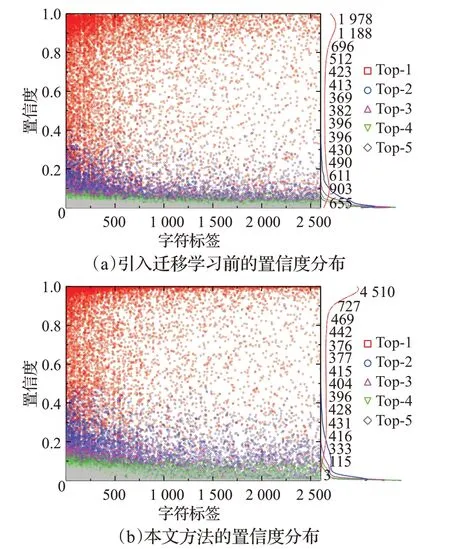
圖6 測試集樣本置信度分布Fig.6 Confidence distribution of test set samples
部分識別錯誤樣本及其置信度如圖7所示,圖中文字部分分別為“真值標(biāo)簽-識別結(jié)果(置信度)”,每一行代表一種錯誤類型。(1)低分辨率、嚴(yán)重模糊或殘缺的樣本。此類樣本無法有效提取到有效特征,一般置信度較低,如“長-良(0.21)”“字-丹(0.20)”。(2)具有不規(guī)則邊框的樣本。難以去除的不規(guī)則邊框會影響特征的準(zhǔn)確提取,造成分類錯誤,如“巖-樂(0.28)”“峽-悔(0.18)”。(3)字符分割有誤的樣本。印章存在字符之間和字符內(nèi)部間隙一致的情況,不可避免地會產(chǎn)生欠分割或者過分割,提取到錯誤的文本特征,如“十-春(0.30)”。(4)結(jié)構(gòu)相似的樣本。部分樣本的結(jié)構(gòu)相似,如“閉-開(0.78)”“處-代(0.65)”等,容易造成分類錯誤。因此,需要更靈活的前處理和更具魯棒性的識別方法來提升這些錯誤樣本的準(zhǔn)確率。

圖7 錯誤識別結(jié)果圖Fig.7 Wrong recognition results
部分識別正確的單字符樣本及其置信度如圖8所示,可以看出,細(xì)邊框?qū)μ卣魈崛∮绊戄^小,如“嘉(0.78)”“奴(0.62)”,具有少量噪聲的樣本依然可以正確識別,具有較高的置信度,如“從(0.77)”“寧(0.88)”。以上結(jié)果表明,本文在一定程度上實(shí)現(xiàn)了古印章文本的識別,樣本具有筆畫清晰、結(jié)構(gòu)相對完整的特點(diǎn),也說明本文在前處理和特征提取方面還具有一定的局限性。

圖8 正確識別結(jié)果圖Fig.8 Correct recognition results
5 結(jié)束語
本文提出基于ResNet和遷移學(xué)習(xí)的古印章文本識別方法。該方法首先自建數(shù)據(jù)集并完成前處理,其次使用人工合成樣本在ResNet_v2_152網(wǎng)絡(luò)上獲取預(yù)訓(xùn)練參數(shù),最后利用可遷移參數(shù)學(xué)習(xí)目標(biāo)域特征,將源域知識遷移到目標(biāo)域,從而提升識別準(zhǔn)確率和模型泛化性能。下一步的工作中,考慮改進(jìn)數(shù)據(jù)擴(kuò)充方法,利用置信度決策函數(shù)實(shí)現(xiàn)更具有魯棒性的模型性能,在此基礎(chǔ)上,實(shí)現(xiàn)古印章文本端到端的數(shù)字化識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
